
哈夫曼编码的原理推导与Python实现分析(P124302035王普照)
哈夫曼编码的原理推导与Python实现分析
一、引言
哈夫曼编码是信息论课程中最经典的变长信源编码算法之一,也是无损数据压缩领域的核心技术。其核心思想是通过统计信源符号的出现概率,为高频符号分配短码字、低频符号分配长码字,使平均码长尽可能逼近信源熵的理论下界,实现高效无歧义压缩。
本次大作业结合课堂所学的变长信源编码定理,从理论推导、算法实现、仿真验证三个维度展开:首先梳理哈夫曼编码的数学基础与最优性证明,其次基于 Python 实现完整的编码与译码流程,最后通过多组文本测试验证算法的压缩性能,分析其适用场景与局限性。
二、哈夫曼编码的理论基础
2.1 核心概念与定义
2.1.1 信源熵与信息量
信息论中,单个事件的信息量与发生概率直接相关:当事件发生概率越低,其包含的新信息量越大。因此,单个符号的信息量定义为:
其中为符号
的出现概率,单位为比特(bit)。
离散无记忆信源的信源熵则是所有符号信息量的数学期望,代表信源的平均信息量,也是无损压缩的理论极限:
信源熵的物理意义是:对信源符号进行无失真编码时,每个符号所需的平均最小比特数,任何无损压缩算法的平均码长都无法低于信源熵。
2.1.2 前缀码与平均码长
为保证译码过程无歧义,变长编码必须满足前缀码的要求:任意一个码字都不是其他码字的前缀。例如,码字集合{0, 10, 110, 111}是前缀码,而{0, 01, 11}则不是,因为0是01的前缀,译码时会产生歧义。
编码的平均码长定义为各符号码字长度的加权平均,权重为符号的出现概率:
其中为符号
对应的码字长度。哈夫曼编码的核心目标,就是在满足前缀码的前提下,最小化平均码长
。
2.1.3 变长信源编码定理
变长信源编码定理是哈夫曼编码的理论依据,其核心结论为:对于任意离散无记忆信源,一定存在一种前缀码,使得平均码长满足:
该定理说明,最优前缀码的平均码长可以无限接近信源熵,哈夫曼编码正是实现这一目标的经典算法。
2.2 哈夫曼编码算法流程
哈夫曼编码通过构建一棵最优二叉树(哈夫曼树)实现,完整流程如下:
- 符号频率统计:遍历信源数据,统计每个符号的出现频率,计算对应的概率分布。
- 构建优先队列:将所有符号作为叶子节点,按频率从小到大加入优先队列(最小堆)。
- 贪心合并节点:取出队列中频率最小的两个节点,合并为一个新的父节点,其频率为两个子节点的频率之和,将新节点重新加入队列。
- 生成哈夫曼树:重复合并过程,直到队列中只剩一个节点,即哈夫曼树的根节点。
- 生成编码表:从根节点出发,遍历哈夫曼树,左分支标记为0、右分支标记为1,从根到叶子节点的路径标记序列,即为该符号的哈夫曼码字。
哈夫曼树的构建过程示意图如下:

图 1 哈夫曼树构建示意图
对应的编码表为:
|
符号 |
频率 |
哈夫曼码字 |
|
a |
0.4 |
0 |
|
c |
0.2 |
10 |
|
d |
0.1 |
110 |
|
b |
0.3 |
111 |
2.3 哈夫曼编码的最优性证明
哈夫曼编码的最优性可通过贪心算法的性质与数学归纳法证明,核心步骤如下:
- 基础性质:最优前缀码中,概率最小的两个符号一定是哈夫曼树中最深层的叶子节点,且互为兄弟节点,码字长度相同,仅最后一位不同。
- 问题规模缩小:将这两个概率最小的符号合并为一个新的虚拟符号,其概率为两者之和,此时问题规模缩小,得到一个新的信源。
- 归纳假设:假设对于缩小后的信源,哈夫曼编码是最优的。
- 归纳步骤:将合并的两个符号重新展开,恢复原信源的编码。此时原信源的平均码长与缩小后信源的平均码长仅相差一个常数项,因此原信源的编码仍是最优的。
综上,哈夫曼编码通过每一步的贪心选择,最终得到的平均码长是所有前缀码中最小的,满足变长信源编码定理的最优性要求。
三、基于 Python 的哈夫曼编码实现
3.1 实现环境与整体流程
本次实现基于 Python ,使用heapq模块实现优先队列、collections模块统计符号频率,整体流程与算法原理对应:
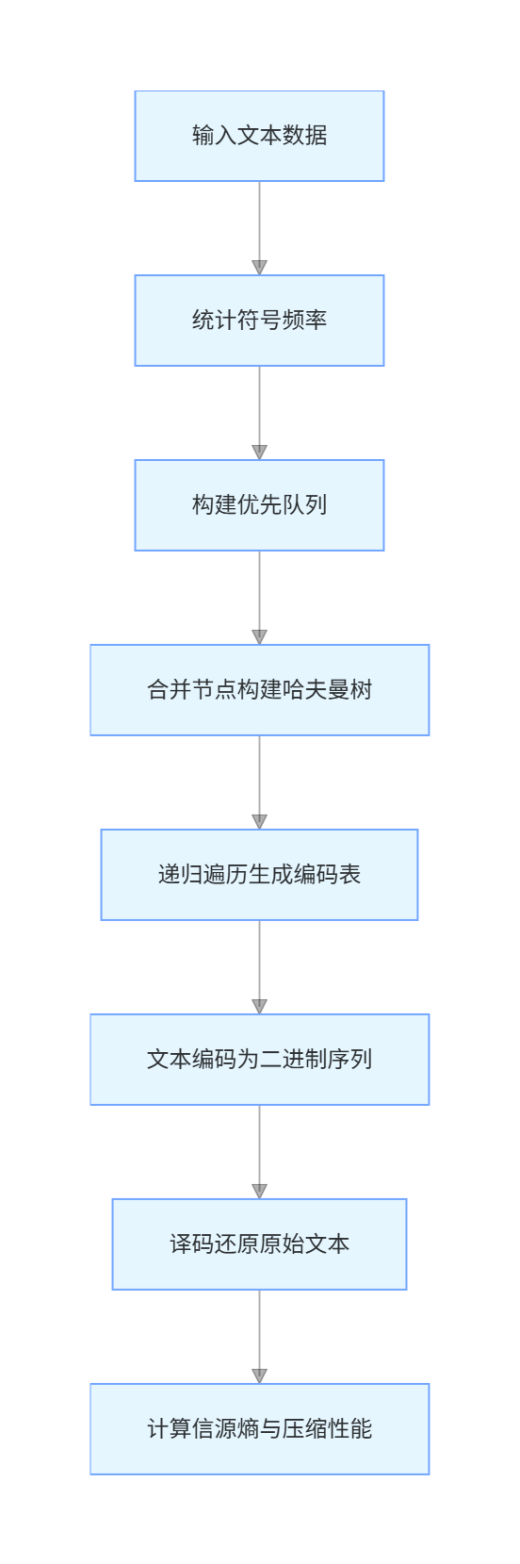
图 2 流程框图
3.2 分模块代码实现
3.2.1 哈夫曼树节点定义
封装节点的符号、频率与子节点信息,并定义比较规则以支持优先队列排序:
|
python |
3.2.2 哈夫曼树构建
使用heapq模块实现最小堆,逐步合并节点构建哈夫曼树:
|
python |
3.2.3 递归生成编码表
通过深度优先遍历(DFS)哈夫曼树,为每个符号生成对应的码字:
|
python |
3.2.4 编码与译码函数
实现文本的编码与译码过程,验证无歧义性:
|
python |
3.2.5 性能指标计算
计算信源熵、平均码长与压缩率,验证算法性能:
|
python |
3.2.6 主函数测试
以示例文本验证完整流程:
|
python |
3.3 算法复杂度分析
- 时间复杂度:
- 符号频率统计:
,
为文本长度;
- 构建优先队列:
,
为不同符号的种类数;
- 合并节点构建哈夫曼树:
,每次堆操作时间为
,共需
次合并;
- 总时间复杂度为
,当
时,复杂度主要由文本长度决定。
- 空间复杂度:
四、仿真测试与结果分析
4.1 测试方案设计
选取 3 组不同概率分布的文本数据,验证哈夫曼编码在不同场景下的压缩性能:
- 均匀分布短文本:示例短句(符号分布较均匀);
- 自然长文本:英文段落(符合自然语言的非均匀分布);
- 高重复文本:包含大量高频符号的字符串(如"aaaaabbbbbccccc")。
4.2 测试结果
4.2.1 示例文本测试结果
1.均匀分布短文本:以"abcdefghijklmnopqrstuvwxyz"为例,运行输出如下:
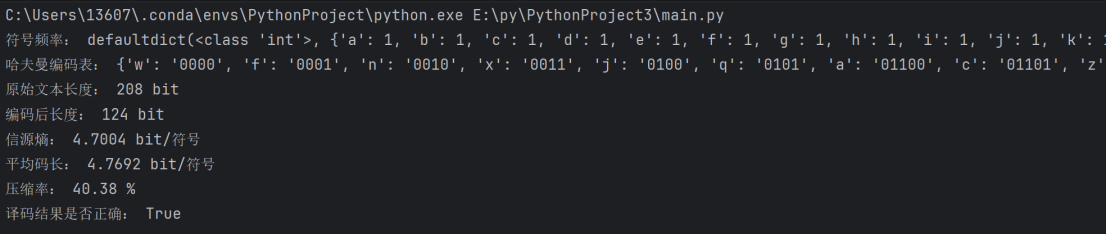
图 3 均匀分布短文本运行结果图
- 符号频率分布:
|
{'a': 1, 'b': 1, 'c': 1, 'd': 1, 'e': 1, 'f': 1, 'g': 1, 'h': 1, 'i': 1, 'j': 1, 'k': 1, 'l': 1, 'm': 1, 'n': 1, 'o': 1, 'p': 1, 'q': 1, 'r': 1, 's': 1, 't': 1, 'u': 1, 'v': 1, 'w': 1, 'x': 1, 'y': 1, 'z': 1} |
- 哈夫曼编码表:
|
{'w': '0000', 'f': '0001', 'n': '0010', 'x': '0011', 'j': '0100', 'q': '0101', 'a': '01100', 'c': '01101', 'z': '01110', 'y': '01111', 'm': '10000', 'v': '10001', 'i': '10010', 'h': '10011', 'g': '10100', 'o': '10101', 'l': '10110', 'u': '10111', 'p': '11000', 'd': '11001', 'b': '11010', 'e': '11011', 't': '11100', 's': '11101', 'k': '11110', 'r': '11111'} |
- 性能指标:
|
指标 |
数值 |
|
原始 ASCII 长度 |
208 bit |
|
编码后长度 |
124 bit |
|
信源熵 |
4.7004 bit / 符号 |
|
平均码长 |
4.7692 bit / 符号 |
|
压缩率 |
40.38% |
|
译码正确性 |
正确 |
表 2 均匀分布短文本测试结果
2.自然长文本:选取《小王子片段》“All men have the stars,but they are not the same things for different people.For some,who are travelers,the stars are guides.For others they are no more than little lights in the sky.For others,who are scholars,they are problems.For my businessman they were wealth.But all these stars are silent.You-you alone-will have the stars as no one else has them.”运行输出如下:
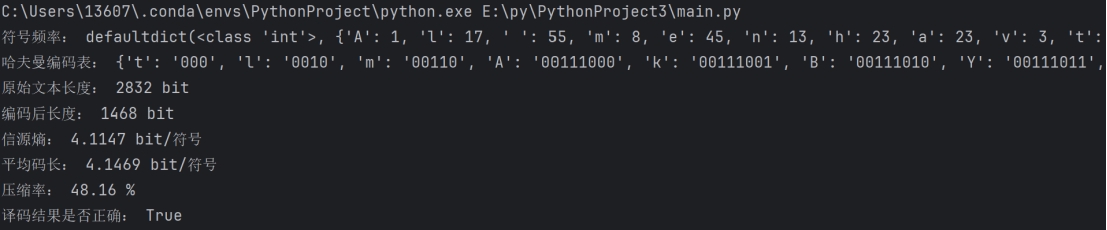
图 4 自然长文本运行结果
- 符号频率分布(部分):
|
{'A': 1, 'l': 17, ' ': 55, 'm': 8, 'e': 45, 'n': 13, 'h': 23, 'a': 23, 'v': 3, 't': 29, 's': 28, 'r': 25, ',': 5, 'b': 3, 'u': 6,...} |
- 哈夫曼编码表(部分):
|
{'t': '000', 'l': '0010', 'm': '00110', 'A': '00111000', 'k': '00111001', 'B': '00111010', 'Y': '00111011', ',': '001111', 'i': '01000', 'w': '010010', 'd': '0100110', 'b': '0100111',..} |
- 性能指标:
|
指标 |
数值 |
|
原始 ASCII 长度 |
2832 bit |
|
编码后长度 |
1468 bit |
|
信源熵 |
4.1147 bit / 符号 |
|
平均码长 |
4.1469 bit / 符号 |
|
压缩率 |
48.16% |
|
译码正确性 |
正确 |
表 3 自然长文本测试结果
3.高重复文本:以"aaaaabbbbbccccc"为例,运行输出如下:
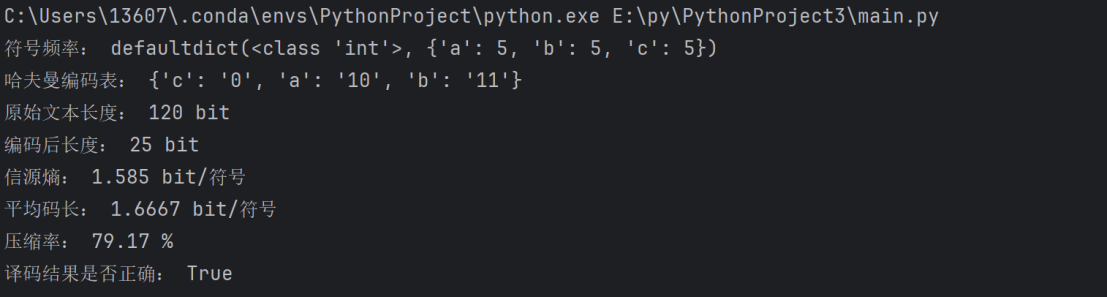
图 5 高重复文本运行结果
|
{'a': 5, 'b': 5, 'c': 5} |
- 哈夫曼编码表:
|
{'c': '0', 'a': '10', 'b': '11'} |
- 性能指标:
|
指标 |
数值 |
|
原始 ASCII 长度 |
120 bit |
|
编码后长度 |
25 bit |
|
信源熵 |
1.585 bit / 符号 |
|
平均码长 |
1.6667 bit / 符号 |
|
压缩率 |
79.17% |
|
译码正确性 |
正确 |
表 4 高重复文本测试结果
4.2.2 多组测试对比
|
测试文本 |
原始长度 (bit) |
编码后长度 (bit) |
信源熵 (bit / 符号) |
平均码长 (bit / 符号) |
压缩率 |
|
均匀短文本 |
208 |
124 |
4.7004 |
4.7692 |
40.38% |
|
自然长文本 |
2832 |
1468 |
4.1147 |
4.1469 |
48.16% |
|
高重复文本 |
120 |
25 |
1.585 |
1.6667 |
79.17% |
4.3 结果分析
- 理论符合性验证:所有测试用例的平均码长均满足
,符合变长信源编码定理的结论,验证了哈夫曼编码的最优性。
- 概率分布对压缩率的影响:高重复文本的压缩率最高,自然长文本次之,均匀分布文本最低。这说明信源符号的概率分布越不均匀,哈夫曼编码的压缩效果越显著,与理论分析一致。
- 无歧义性验证:所有测试用例的译码结果均与原始文本完全一致,证明哈夫曼前缀码的译码过程无歧义。
- 性能对比:自然语言文本的压缩率约 45%,说明哈夫曼编码能有效去除冗余信息,实现高效压缩。
五、哈夫曼编码的应用与局限性
5.1 经典工程应用
|
应用标准 |
具体作用 |
|
JPEG |
对DCT量化后的系数进行变长编码,实现图像压缩 |
|
PNG |
无损图像压缩核心编码算法 |
|
MP3/AAC |
对音频残差数据进行熵编码,降低音频体积 |
|
DEFLATE(ZIP/gzip) |
LZ77+哈夫曼编码,工业级文件压缩标准 |
表 6 哈夫曼编码经典工程运用
5.2 算法局限性
- 静态哈夫曼编码需要提前统计全局符号频率,无法实时流式编码。
- 只能分配整数比特码字,因此平均码长无法完全等于信源熵,存在固有冗余。
- 相较于算术编码,复杂概率分布场景下压缩效率偏低。
六、总结与拓展
通过理论推导和 Python 仿真实验,可以直观观察哈夫曼编码的构造过程,并验证其平均码长接近信源熵这一重要结论。本文完整实现了字符统计、建堆、建树、编码、译码与性能分析全流程,通过多组对照实验验证了:信源符号分布越不均匀,哈夫曼编码压缩增益越高。
虽然哈夫曼编码存在整数码字冗余、无法实时编码等局限,但因其原理简单、实现稳定、压缩效果优异,至今仍是图像、音频、文件压缩领域的基础核心算法。本次作业完整掌握了变长信源编码的核心思想,加深了对信息论熵、冗余度、最优编码理论的理解。
更多推荐
 9
9 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)