
系统设计练习 - 全球特征标签配置平台
业务背景
你的团队需要构建一个全球统一的feature flag平台。有数千个backend service和mobile app都需要通过这个平台控制feature rollout。例如:
EnableNewCheckout = true
if (FeatureFlag.isEnabled(userId, "EnableNewCheckout")) {
...
}系统需求
功能需求
1. Configuration:支持:
1.1 创建Feature Flag
1.2 修改Feature Flag
1.3 删除Feature Flag
1.4 Version history
1.5 Rollback
2. Evaluation API
2.1 GET /evaluate
input:
userId, country, device, appVersion
output:
true/false
3. Gradual Rollout
支持: 0% -> 1% -> 5% -> 20% -> 50% -> 100%
基于:consistent hashing, 保证同一个user一直得到一样的结果
4. Targeting
支持:
country == US
AND
appVersion > 20
AND
employee == true
AND
premium == true
任意组合。
5. Feature Kill Switch
如果feature出问题,要求5秒内全球所有机器全部关闭。
6. SDK:提供Java,Python,Go, Node, Android,SDK。 SDK应该尽可能减少网络调用。
非功能需求
假设:
2000 services
500 mobile apps
100 million DAU
1000 QPS config update
要求:
- High Availability
- Multi-region
- Eventually Consistent
- Audit Log
- Low Latency
API设计
1. 设置feature flag:
POST: /feature-flag
BODY: {
"featureId": "<featureId>",
"version": "1",
"ratio": "20",
"condition": "{'contury': 'USA', 'regin': 'US-EAST'}"
}2. 查询feature flag:
GET feature-flag?device=iphone&version=3&feature-id=ai-agent-chatbot系统框架设计
系统架构图如下:
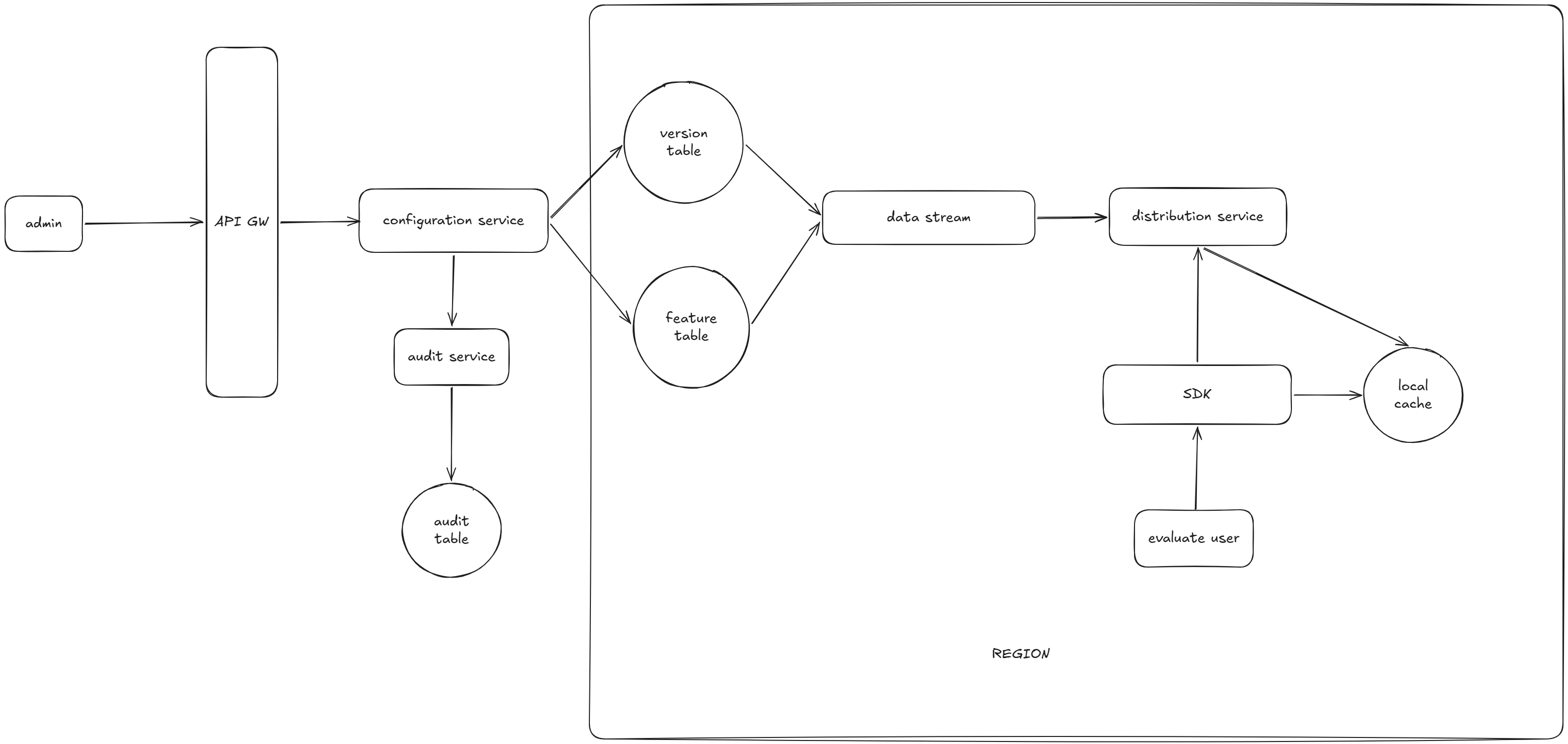
对该架构图说明如下:
1. admin,也就是设置feature flag的人,通过configuration service setup feature flag。
2. configuration service会调用audit-service,保存audit的信息。audit部分的详细信息暂时忽略。
3. configuration service会将信息保存在两个数据库表中。一个是version table,保存有feature的全部历史version信息。这些信息可以用来做audit和rollback。另一个是feature table,保存有feature当前的version信息,比如当前active version,dial-up ratio,condition等。
4. 两个数据库表向下游发送data stream,例如kafka,或者kinesis。我们在这里使用global DDB table。这样我们的数据可以通过DDB自动同步到多个region。各个region有自己的distribution service,将configuration向下游同步到自己region内的SDK断点。以此方式增加整个系统的scale支持和latency的控制。
5. 每个region有多个SDK。evaluate user通过SDK或者某个feature的rollout信息。SDK主要查询local cache来获取feature的rollout信息。local cache的信息是又distribution service推送的。这样的好处在于SDK无需做remote query。这样既减少了service端的压力,又为客户端带来scale和latency的好处。同时SDK通过long pull的方式从distribution处获取feature flag的变化。这样的方式作为local cache没有命中的fallback方案。
讨论
1. 为什么我们要将configuration推送到local cache,而不是从数据库中直接读取?因为我们发现我们的情况是读操作的频率远远大于写操作。读操作有100百万级的active用户。假如所有这些操作都通过remote的方式访问remote service或者remote DB,将给service端带来巨大的压力。现在我们在写时做fanout,会大大减轻service的压力,也会给client带来available和低latency的好处。
2. 怎样支持部分rollout:这里要考虑的问题是对于同一个user,我们希望他在每次dial-up时状态是稳定的。也就是说如果feature已经enable了,我们希望在继续dial up时feature仍然是enable的。我们的算法是通过user的信息,比如user-id,feature-id,version,device等,通过稳定的hash算法映射到hash空间,比如0到100.然后dial-up可以从0%逐步提升到100%。用户的hash值被dial-up包括了就代表feature enable。
3. 怎样处理region失效的情况:如果一个region的distribution service失效了,比如无法获取最新的configuration,或者无法正常向SDK同步configuration,evaluate-user应该暂时被其它region接管。当本region的distribution-service重新开始工作,它应该首先通过data stream完成和最新数据的同步,然后重新接管本region内的user的同步工作。
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)