
QMD:本地运行的智能文档搜索引擎
QMD:本地运行的智能文档搜索引擎
最近 GitHub 上出现了一个挺有意思的项目,叫 QMD,Star 数已经到了 2.7 万。它做的事情很明确,把你的 Markdown 笔记、会议记录、技术文档全部索引起来,然后用关键词或者自然语言去搜。
混合搜索是它的核心能力
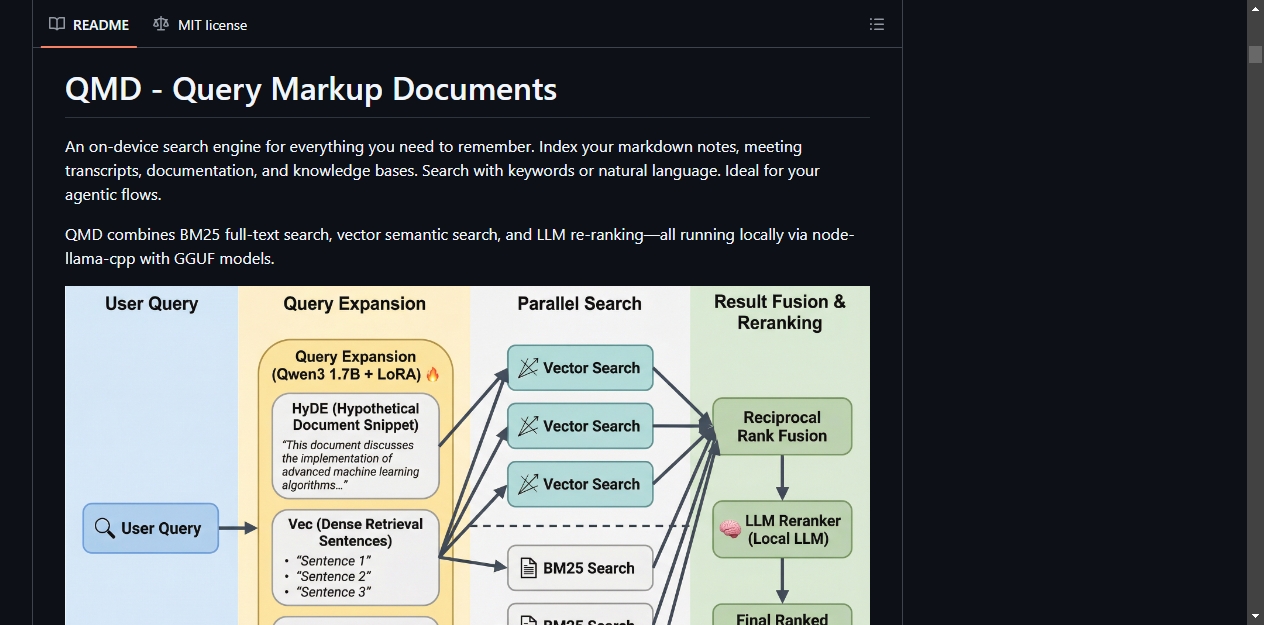
QMD 最大的特点不是单纯的全文检索,而是把三种搜索方式揉到了一起:BM25 全文检索、向量语义搜索、LLM 重排序。这三样东西全部跑在本地,通过 node-llama-cpp 加载 GGUF 模型实现,不需要联网。
搜索流程大概是这样的:你输入一个查询,QMD 先用微调过的 1.7B 参数模型自动扩展查询词,然后同时跑关键词搜索和语义搜索,再用 RRF(Reciprocal Rank Fusion)把结果合并,最后交给 reranker 模型做精排。整个过程对用户来说就是一条命令的事。
实际使用的时候有三种模式可选。search 是纯关键词搜索,速度最快。vsearch 是向量语义搜索,适合你记不清原文措辞的场景。query 是混合搜索加重排序,效果最好,但需要加载模型,第一次运行会慢一些。
接入方式
除了命令行直接用,QMD 还提供了 MCP Server,可以接入 Claude Desktop 或者 Claude Code。它暴露了四个工具:query(混合搜索)、get(获取单个文档)、multi_get(批量获取)、status(查看索引状态)。
如果你是做开发的,也可以把 QMD 当成 Node.js 库来用。npm 装完之后,几行代码就能创建索引、执行搜索、获取文档。SDK 的设计比较干净,支持内联配置、YAML 配置文件,也可以直接打开已有的数据库。
安装和使用
装起来很简单,Node 或者 Bun 环境下全局安装就行:
npm install -g @tobilu/qmd
装好之后,先建几个 collection,把你的文档目录加进去:
qmd collection add ~/notes --name notes
qmd collection add ~/work/docs --name docs
然后跑一次 qmd embed 生成向量索引。之后就可以搜索了:
qmd search "project timeline"
qmd query "quarterly planning process"
query 命令会自动扩展查询词,同时跑关键词和语义搜索,最后用 reranker 精排。如果你只想快速找关键词匹配,用 search 就够了。
本地模型
QMD 用到三个 GGUF 模型,首次使用时自动从 HuggingFace 下载。embedding 模型大概 300MB,reranker 大概 640MB,查询扩展模型大概 1.1GB。模型下载后缓存在 ~/.cache/qmd/models/ 目录下。
默认的 embedding 模型是 embeddinggemma-300M,英文效果不错。如果你主要搜中文、日文或者韩文内容,可以换成 Qwen3-Embedding-0.6B,支持 119 种语言,MTEB 排名靠前。换模型之后需要重新跑一次 qmd embed -f。
适合什么场景
QMD 比较适合两种人。一种是笔记很多、经常需要翻找历史记录的。把所有 Markdown 文件加进 collection,以后搜东西就不用翻文件夹了。另一种是做 AI Agent 开发的。QMD 的 --json 输出格式可以直接喂给 LLM,--files 模式可以批量导出匹配的文件路径。
搜索结果会显示文件路径、标题、上下文描述和相关度分数。路径在终端里是可以点击的超链接,支持 VS Code、Cursor、Zed 等编辑器。
其他细节
QMD 支持 AST 感知的代码分块,对 TypeScript、JavaScript、Python、Go、Rust 这几种语言,会按函数、类、import 边界来切分,而不是按固定字符数切。这对搜代码场景有帮助。
它还支持给 collection 设置上下文描述,搜到子文档的时候会把上下文一起返回,帮 LLM 做更好的判断。另外 collection 可以配置 update 命令,每次 qmd update 之前自动执行,比如 git pull --rebase,保持文档和远程仓库同步。
项目是 MIT 协议,代码全在 GitHub 上。如果你手头有大量 Markdown 文档需要管理,或者在做 AI 项目需要本地知识库,可以试试。
协议,代码全在 GitHub 上。如果你手头有大量 Markdown 文档需要管理,或者在做 AI 项目需要本地知识库,可以试试。
更多推荐



 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)