
《Nano-vLLM 源码解读》第 23 篇 · 张量并行(三)Embedding / LM Head / KV Cache 的 TP
nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
上一篇把 Linear 的 weight 按输入维、输出维切完了——列切、行切、合并的双重切。
但模型里还有两处不是普通 Linear,切法也不一样:几万行的词表(embed_tokens、lm_head),以及注意力的多个 head。词表沿「词」切,注意力沿「头」切。本篇补齐这两种切法,张量并行的三种切法(weight、vocab、head)就齐了。
import torch
from torch import nn
import torch.nn.functional as F
2. 总览

weight 切上一篇讲过。本篇按切法组织:先 vocab 切——词表 [vocab, dim] 沿词(行)切,每卡只存一段词;再 head 切——注意力的 head 各自独立,沿头切,每卡只算几个头。Qwen3-0.6B 在 tp=2 下,词表 151936→75968、q 头 16→8、kv 头 8→4。
3. VocabParallelEmbedding:vocab 切
词表是模型里最大的表(Qwen3 151936 × 1024)。按词切到各卡,每卡只存 vocab/tp 个词。
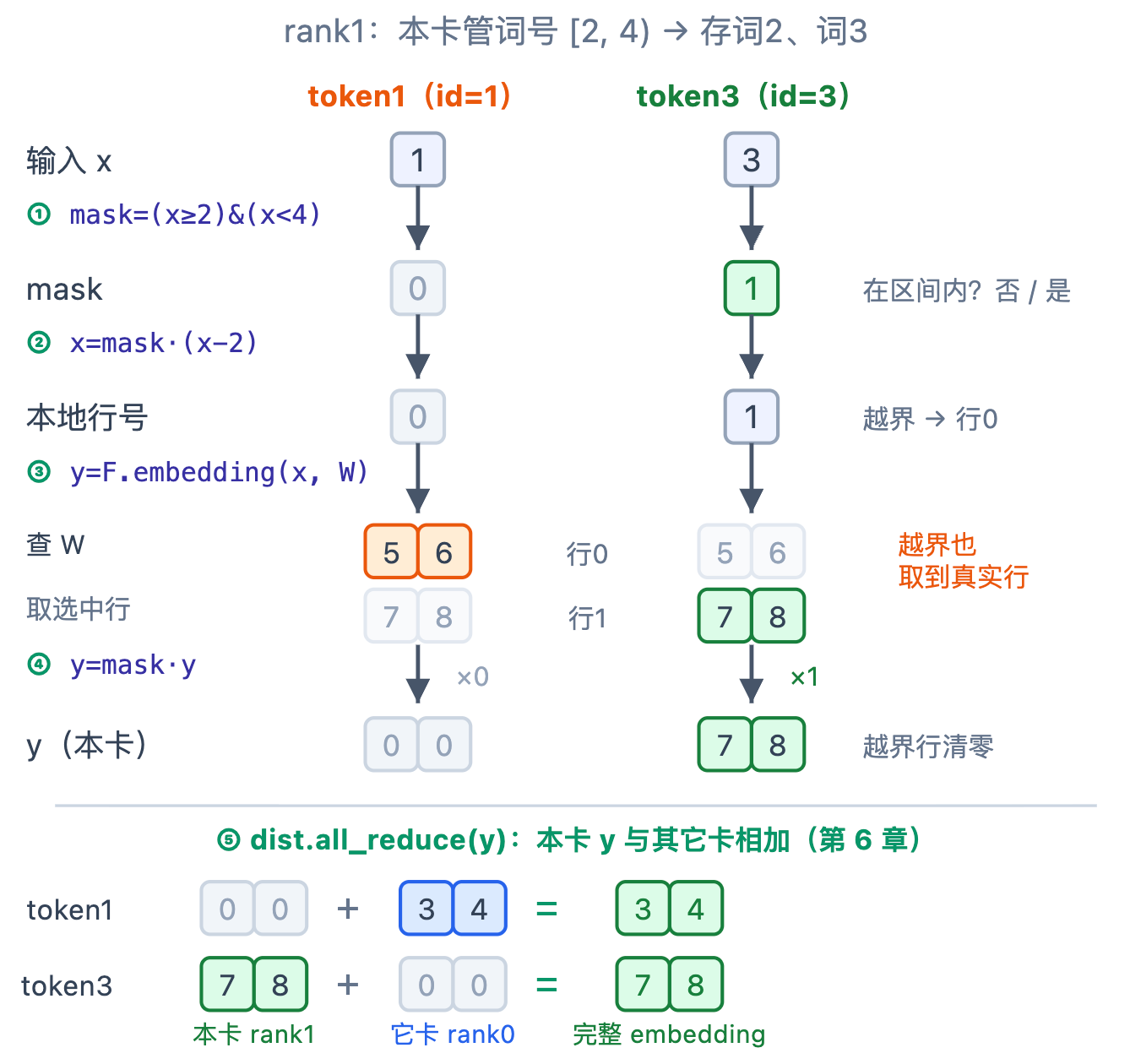
__init__:词数除以卡数,本卡负责 [vocab_start, vocab_end) 这一段词号,权重建成 [vocab/tp, dim]。
weight_loader:沿词维(dim 0)从磁盘整份切出本卡那段词。
forward 里,本卡只认自己那段词的 token,认不出的输出 0,最后各卡求和拼回。像把每个词交给专管它的图书管理员:你报一个词号,只有管它的人取得到书,别人交白卷(0),把各人手里的叠起来就是你要的那本。五步:
mask:标出落在本卡词号区间内的 token。x = mask * (x - vocab_start):本卡的 token 平移到局部索引[0, vocab/tp);越界的被乘成 0(先占位到第 0 行)。F.embedding:查本卡这段词表。mask.unsqueeze(1) * y:把越界 token 占位的那一行清零。all_reduce求和:每个 token 只有一张卡查得到、其余卡是 0,相加就拼回完整 embedding。
第 4 步为什么要 unsqueeze(1)?这一步要把越界 token 那一整行 embedding 清零,而 mask 形状是 [N](每个 token 一个 0/1),y 是 [N, dim](每个 token 一行)——直接相乘维度对不上。unsqueeze(1) 在第 1 维插一根长度为 1 的轴,把 mask 变成 [N, 1];相乘时它沿 dim 方向广播,第 i 行整行乘以 mask[i]:命中行(×1)原样保留,越界行(×0)整行归零。
为什么求和能拼回?一个 token 落在哪段词,就只有存那段的卡查得到值,别的卡全是 0;叠加时 0 不影响结果,正好得到那个 token 的 embedding。
class VocabParallelEmbedding(nn.Module):
def __init__(self, num_embeddings, embedding_dim,
tp_size, tp_rank):
super().__init__()
self.tp_size = tp_size # 真实代码:dist.get_world_size()
self.tp_rank = tp_rank # 真实代码:dist.get_rank()
per = num_embeddings // tp_size # 每卡词数
self.vocab_start_idx = per * tp_rank # 本卡词号区间 [start, end)
self.vocab_end_idx = self.vocab_start_idx + per
self.weight = nn.Parameter(torch.empty(per, embedding_dim))
self.weight.weight_loader = self.weight_loader
def weight_loader(self, param, loaded_weight):
# 沿词维(dim0)切出本卡那段词(同上一篇列切)
shard = param.size(0)
start = self.tp_rank * shard
param.data.copy_(loaded_weight.narrow(0, start, shard))
def forward(self, x):
mask = (x >= self.vocab_start_idx) & (x < self.vocab_end_idx) # 只计算落到本卡的token
x = mask * (x - self.vocab_start_idx) # 本卡token→局部索引,越界→0
y = F.embedding(x, self.weight)
y = mask.unsqueeze(1) * y # 越界token那行清零
# dist.all_reduce(y) # 真实代码:各卡求和; 单进程见第6章手动 y0+y1
return y
# 合成词表[4,2],每行填可辨认常数;两卡各 load 本卡词段
full = torch.arange(1, 9, dtype=torch.float).reshape(4, 2)
e0 = VocabParallelEmbedding(4, 2, tp_size=2, tp_rank=0)
e1 = VocabParallelEmbedding(4, 2, tp_size=2, tp_rank=1)
e0.weight_loader(e0.weight, full)
e1.weight_loader(e1.weight, full)
print('rank0 存词', e0.vocab_start_idx, e0.vocab_end_idx) # [0, 2]
tok = torch.tensor([1, 3])
print('rank0 partial\n', e0(tok)) # 只 token1 非零
print('rank1 partial\n', e1(tok)) # 只 token3 非零
4. ParallelLMHead:vocab 切
lm_head 把每个位置的向量投影成每个词的 logits,输出维就是词表大小。它继承 VocabParallelEmbedding,权重同样是 [vocab/tp, dim] 的本卡词段。
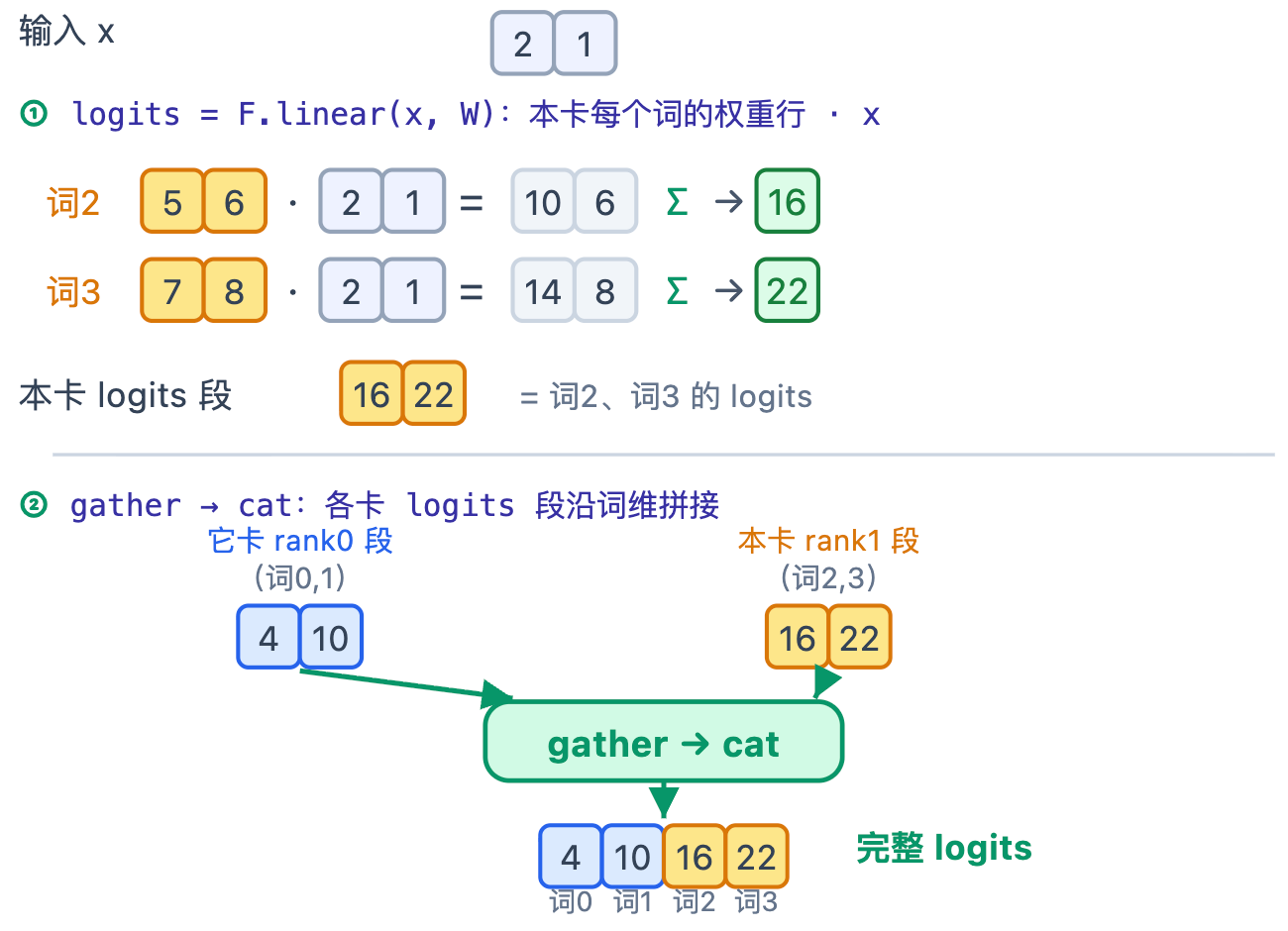
forward:本卡用自己那段词的权重,算出本卡负责的 vocab/tp 个词的 logits(F.linear);再 gather 到 rank0、沿词维 cat 拼成完整 vocab 维 logits。(prefill 只取每条序列最后一位算 logits。)
同是 vocab 切,为什么 embed 用 all_reduce(求和)、lm_head 用 gather(拼接)?
embed切在输入侧:token 索引落在词维。每个 token 只有一张卡查得到,各卡输出形状相同、位置互补——求和拼回。lm_head切在输出侧:logits 本身在词维。每卡算的是不同的词段(rank0 算前一半词、rank1 算后一半),各卡输出形状相同、内容不同——拼接才完整。
class ParallelLMHead(VocabParallelEmbedding):
def forward(self, x):
# prefill 取每条最后一位
logits = F.linear(x, self.weight) # 本卡词段 logits [*, vocab/tp]
# dist.gather → cat # 真实代码:收到rank0拼接
return logits
W = torch.arange(1, 9, dtype=torch.float).reshape(4, 2) # [vocab=4, dim=2]
h0 = ParallelLMHead(4, 2, tp_size=2, tp_rank=0)
h1 = ParallelLMHead(4, 2, tp_size=2, tp_rank=1)
h0.weight_loader(h0.weight, W)
h1.weight_loader(h1.weight, W)
x = torch.randn(3, 2)
print('rank0 logits 段', tuple(h0(x).shape), '→ 词 0,1')
print('rank1 logits 段', tuple(h1(x).shape), '→ 词 2,3')
rank0 logits 段 (3, 2) → 词 0,1
rank1 logits 段 (3, 2) → 词 2,3
5. attention 与 KV cache:head 切
注意力的每个 head 独立计算、互不交互,所以可以按 head 切到各卡,每卡只算自己那几个头,算的过程零通信。
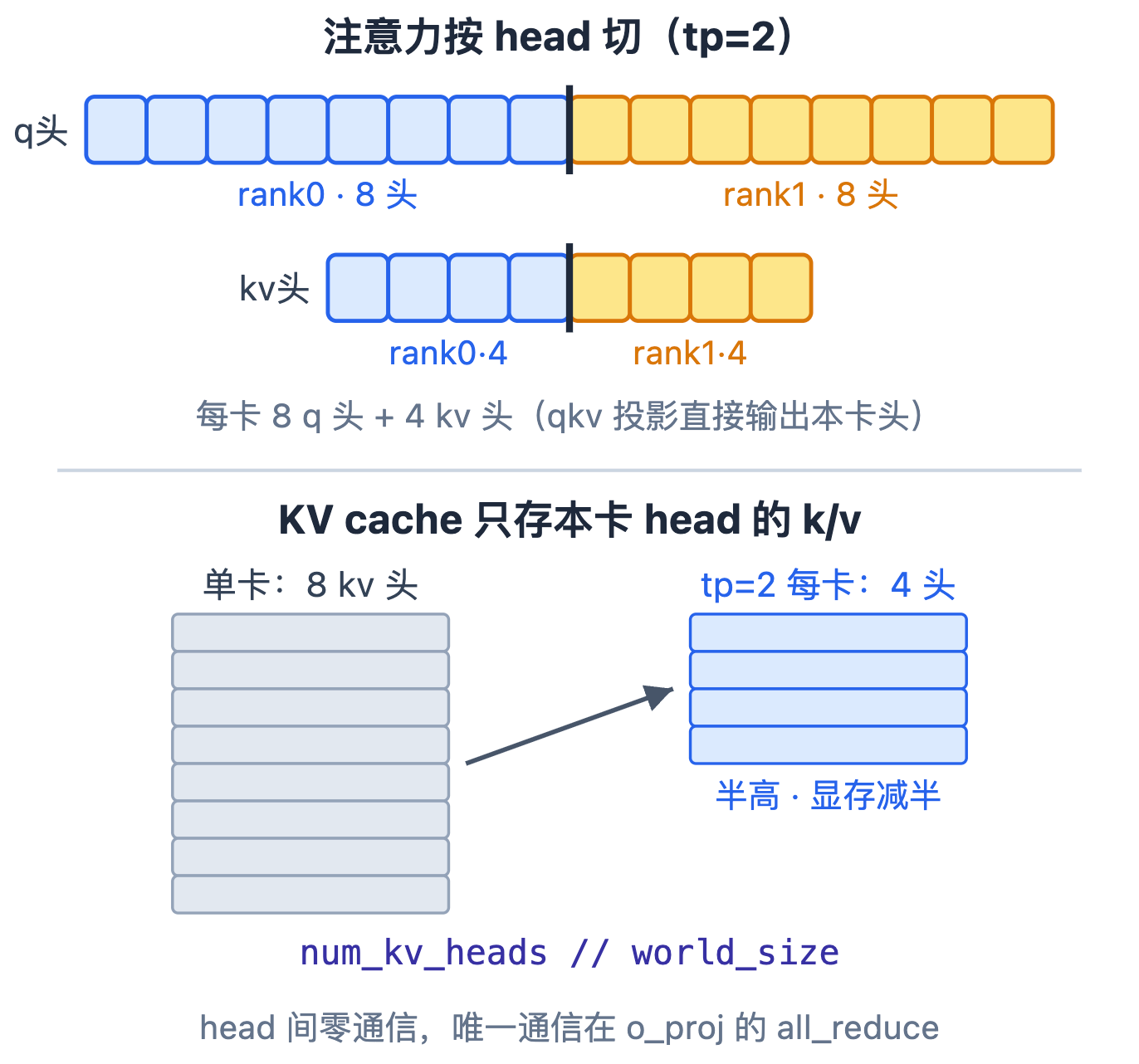
Qwen3Attention 构造时把头数按卡数整除:num_heads = total_num_heads // tp_size(16→8)、num_kv_heads = total_num_kv_heads // tp_size(8→4)。qkv_proj 用上一篇的 QKVParallelLinear,输出的就是本卡这几个头的 q/k/v;算完注意力,o_proj 用 RowParallelLinear,末尾 all_reduce 把各卡的输出按隐层维相加。
KV cache 跟着只存本卡的头。allocate_kv_cache 里 num_kv_heads = num_key_value_heads // world_size,cache 形状的头维就是本卡头数——本卡只算本卡的头,也只需存本卡头的历史 k/v,显存随卡数减半。
整条注意力里,唯一的跨卡通信是 o_proj 的 all_reduce;head 切本身不通信。
# attention 按 head 切(Qwen3Attention.__init__ 的核心)
total_num_heads, total_num_kv_heads, tp = 16, 8, 2
assert total_num_heads % tp == 0 and total_num_kv_heads % tp == 0
num_heads = total_num_heads // tp # 每卡 q 头
num_kv_heads = total_num_kv_heads // tp # 每卡 kv 头
print('每卡 q 头', num_heads, ' kv 头', num_kv_heads)
# KV cache 跟着只存本卡的头(allocate_kv_cache 的形状)
layers, blocks, block_size, head_dim = 28, 100, 256, 128
for t in (1, 2):
kvh = total_num_kv_heads // t
shape = (2, layers, blocks, block_size, kvh, head_dim)
print(f'tp={t} kv 头/卡={kvh} kv_cache 形状={shape}')
每卡 q 头 8 kv 头 4
tp=1 kv 头/卡=8 kv_cache 形状=(2, 28, 100, 256, 8, 128)
tp=2 kv 头/卡=4 kv_cache 形状=(2, 28, 100, 256, 4, 128)
6. 集成验证
单进程构造 rank0、rank1 两卡,手动合并两卡算出来的数据,对比单卡数据检查计算是否正确。
# embed 两卡求和(模拟 all_reduce)
table = torch.randn(4, 2)
a0 = VocabParallelEmbedding(4, 2, 2, 0); a0.weight_loader(a0.weight, table)
a1 = VocabParallelEmbedding(4, 2, 2, 1); a1.weight_loader(a1.weight, table)
ids = torch.tensor([0, 1, 2, 3])
allreduce = a0(ids) + a1(ids)
print('embed all_reduce == 单卡:',
torch.allclose(allreduce, F.embedding(ids, table)))
# lm_head 两卡cat(模拟 gather)
Wf = torch.randn(4, 2)
b0 = ParallelLMHead(4, 2, 2, 0); b0.weight_loader(b0.weight, Wf)
b1 = ParallelLMHead(4, 2, 2, 1); b1.weight_loader(b1.weight, Wf)
xx = torch.randn(3, 2)
gather = torch.cat([b0(xx), b1(xx)], dim=-1)
print('lmhead gather == 单卡:',
torch.allclose(gather, F.linear(xx, Wf)))
embed all_reduce == 单卡: True
lmhead gather == 单卡: True
7. 小结
至此,张量并行的三种切法已经介绍完毕:
- weight 切(上一篇):
Linear沿隐层维列切、行切,行切末尾all_reduce。 - vocab 切(本篇):词表沿词维切。
embed切输入侧、各卡互补数据,all_reduce求和拼回;lm_head切输出侧、各卡不同词段,gather拼接拼回。 - head 切(本篇):注意力沿头维切,每卡算自己的头、零通信,KV cache 也只存本卡头;唯一通信在
o_proj的all_reduce。
切分都讲完了,但代码到现在还是单进程模拟——真实的多卡靠多进程,每进程占一张卡,tp_size/tp_rank 从 dist 取。进程怎么起、卡间怎么传方法调用,将在下一篇介绍。

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 5
5 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)