
《Nano-vLLM 源码解读》第 21 篇 · 张量并行(一)数学基础
nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
上一篇 CUDA Graph 把单卡的 decode 提了速,但有些模型大到一张卡的显存根本放不下,或者我们想让多张卡一起算,这就要把模型「切」到多张卡上,这套机制叫张量并行(Tensor Parallelism,简称 TP)。
本篇只讲数学基础:每一层按什么维度切到多卡、哪些地方必须让多卡互相交换数据(通信)。换句话说,就两个问题——切在哪、何时通信。后文会详细介绍如何把权重切开(weight_loader 分片)、Linear 家族具体怎么改、embed/head/kv 怎么切、多张卡的进程怎么起怎么协作。
2. 总览
为什么要切? 一张大试卷,一个人从头做到尾要很久,桌上也摆不下所有参考书;分给几个人,每人负责一部分题、各带自己那部分参考书,最后把答案拼到一起,又快又放得下。把模型切到多卡也是这个意思:每张卡只存一部分权重(参考书)、只算一部分(题),算得也更快。代价是中间得有人「对答案」——这就是通信。
一次前向自上而下走一遍,每层右侧的小方格图就是它把矩阵切到 2 卡的样子(蓝=卡0、黄=卡1):
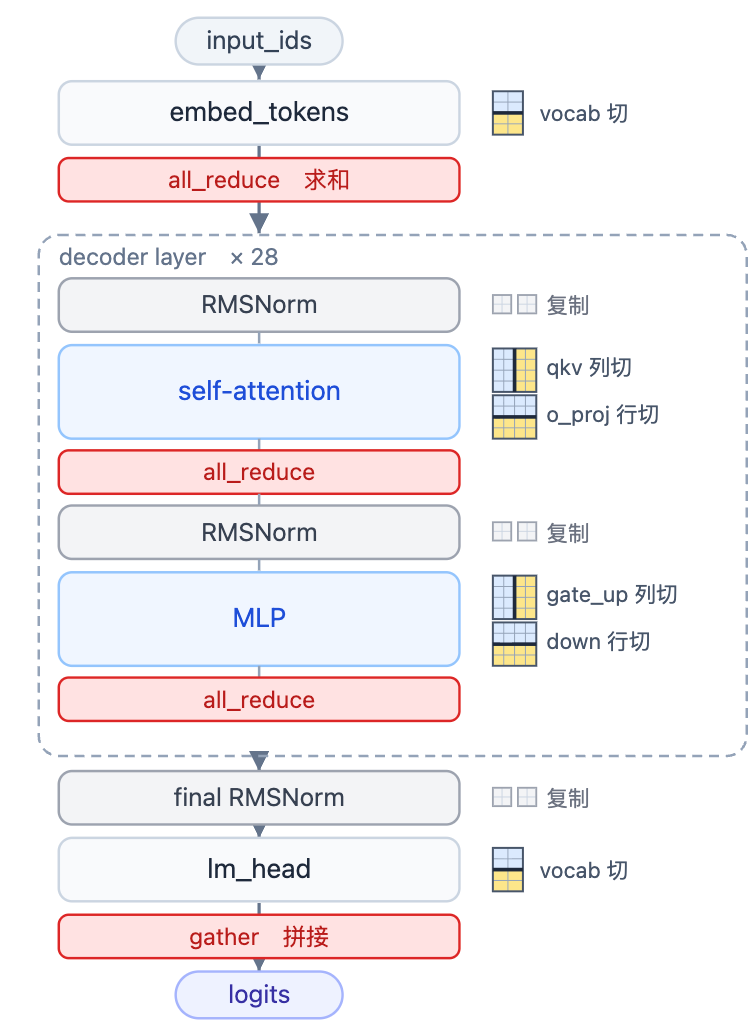
列切把方格竖着切——按输出维度切,左半列归卡0、右半列归卡1(attention 的 qkv、MLP 的 gate_up);行切把方格横着切——按输入维度切,上半行归卡0、下半行归卡1(attention 的 o_proj、MLP 的 down)。这两种切法第 3、4 章细讲。vocab 切是把词表切开(embed 和 lm_head,第 5 章);复制是两卡各存一份、根本不切(RMSNorm 和残差流,第 6 章)。
红色横条是通信点,只有两种:all_reduce(把各卡的部分结果加起来)和 gather(把各卡的片段拼起来)。
以 Qwen3-0.6B、切到 2 卡(tp=2)为例:
| 维度 | 切前 | 每卡(tp=2) | 切法 |
|---|---|---|---|
| 注意力头 q heads | 16 | 8 | 按 head 列切 |
| KV 头 kv heads | 8 | 4 | 按 head 列切 |
| MLP 中间维 intermediate | 3072 | 1536 | gate_up 列切 / down 行切 |
| 词表 vocab | 151936 | 75968 | vocab 切 |
| 隐藏维 hidden | 1024 | 1024 | 不切(RMSNorm / 残差流复制) |
3. 列切 vs 行切
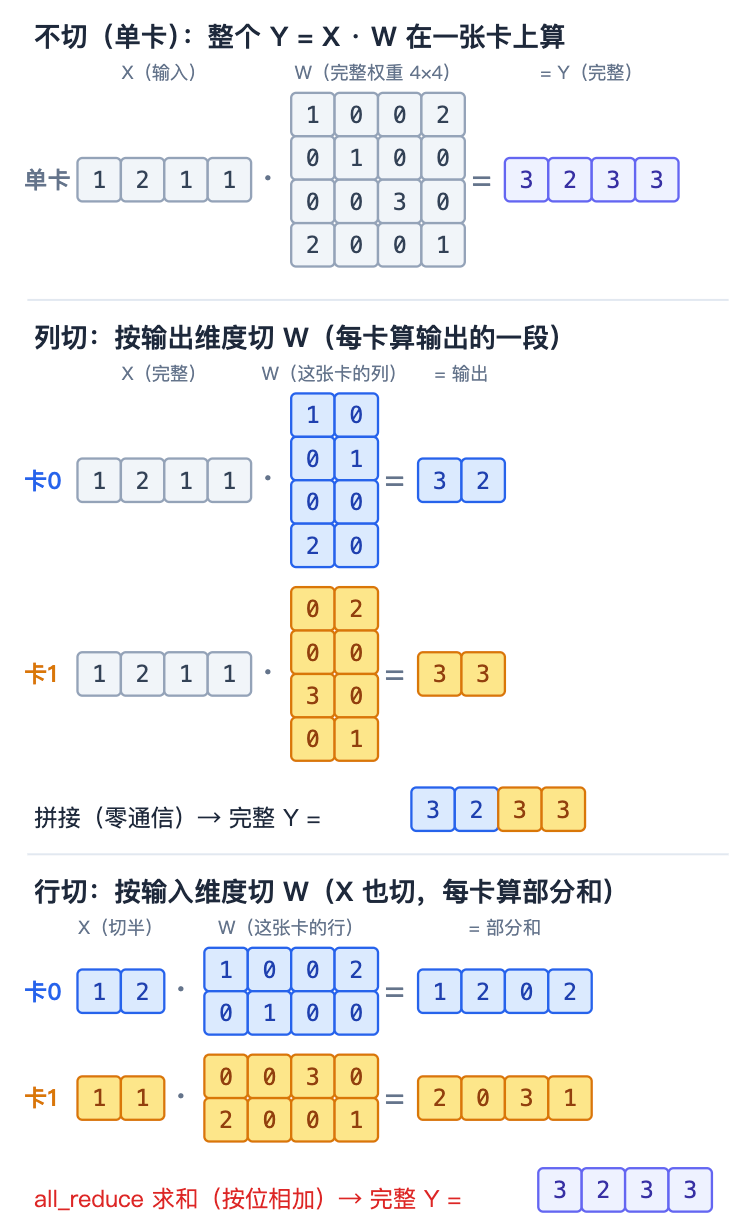
模型里绝大部分参数都在线性层 Y = X ⋅ W Y = X \cdot W Y=X⋅W( X X X 是输入、 W W W 是权重、 Y Y Y 是输出)。要把一个线性层拆到多卡,只有两种切 W W W 的方式:列切和行切。
列切——按输出维度切。 把 W W W 的列(输出那一维)分给各卡, X X X 每张卡都保留完整的一份。各卡各算输出的一段:
Y = [ X ⋅ W 0 ∣ X ⋅ W 1 ] Y = [\,X \cdot W_0 \;\mid\; X \cdot W_1\,] Y=[X⋅W0∣X⋅W1]
卡 0 算出 Y Y Y 的左半、卡 1 算出右半,算的时候谁也不用问谁——matmul 阶段零通信。代价是每张卡输出的是「分片」:完整的 Y Y Y 散在两张卡上,拼起来才完整。
行切——按输入维度切。 把 W W W 的行(输入那一维)分给各卡, X X X 也跟着按同一维切开。各卡各算一个「半成品」:
Y = X 0 ⋅ W 0 + X 1 ⋅ W 1 Y = X_0 \cdot W_0 \;+\; X_1 \cdot W_1 Y=X0⋅W0+X1⋅W1
注意这里是加号:卡 0 的 X 0 ⋅ W 0 X_0 \cdot W_0 X0⋅W0 和卡 1 的 X 1 ⋅ W 1 X_1 \cdot W_1 X1⋅W1 都是完整 Y Y Y 的形状,但各自只含一部分加项,是部分和。必须把两张卡的部分和加起来,才得到真正的 Y Y Y——这个跨卡求和,就是 all_reduce。
打个比方:列切像按题目分工,每人做不同的几道题,各自的答案直接拼起来就是完整答卷,互不打扰;行切像合算一道大题,每人算式子里的一段、各得一个半成品,最后必须把所有人的半成品加起来才是答案。
下面通过一个具体例子( X = [ 1 , 2 , 1 , 1 ] X=[1,2,1,1] X=[1,2,1,1]、 W W W 是 4×4)展示两种切法的计算过程:
col-row-split
一句话记住:通信只在行切之后出现(部分和要 all_reduce 求和);列切本身不通信,只是把输出留成了分片。
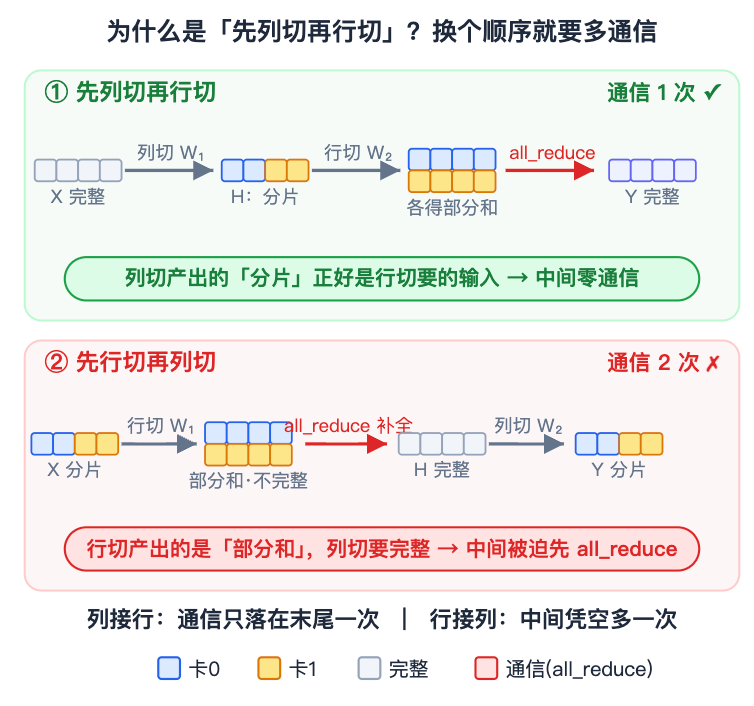
怎么选:列切还是行切
单看一个矩阵,列切不需要通信、行切需要,当然列切划算;可列切的输出是分片的,下游要用还得拼回来,又是一次通信。真正省通信的办法,是让一个列切紧跟一个行切:行切要的正是分片输入,刚好把上一个列切的分片直接吃掉,整对只在末尾做一次 all_reduce。
原则:成对的两个矩阵,前一个列切、后一个行切。
4. Transformer 块的两次「列接行」
第 3 章给了原则:前一个列切、后一个行切。这一章看它在一个 decoder 层里具体怎么接。行切层要的正是「按输入维度切开的 X X X」,而上一个列切层的分片输出,恰好就是这个形状——两者天衣无缝地接上,中间不需要任何通信,只在行切层的末尾做一次 all_reduce 把部分和求和。
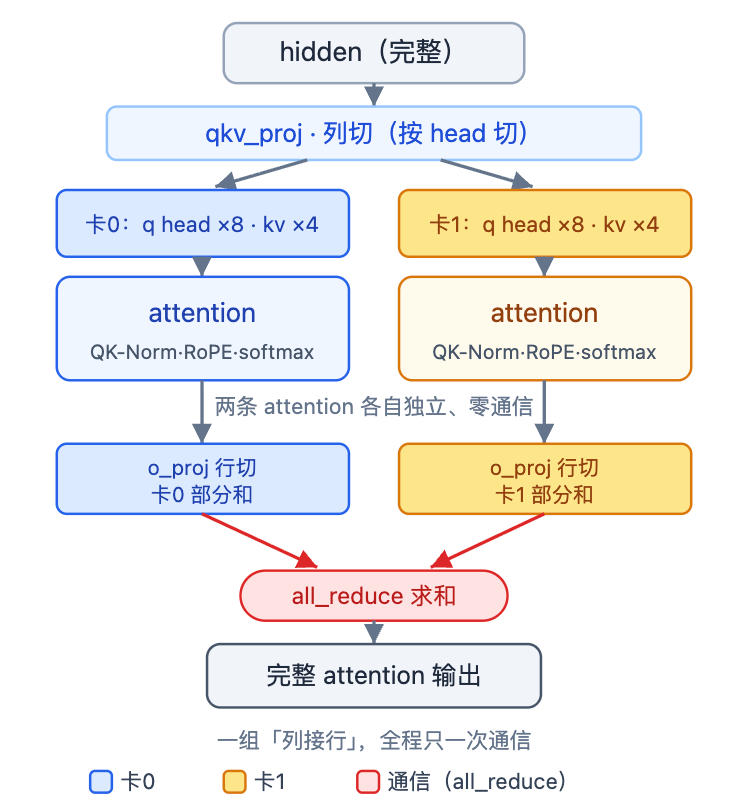
一个 decoder 层里恰好有两组这样的「列接行」配对:
- Attention:
qkv_proj(列切)→ 各卡独立算 attention →o_proj(行切)→ 1 次all_reduce。 - MLP:
gate_up_proj(列切)→SiluAndMul→down_proj(行切)→ 1 次all_reduce。
所以「每层两次 all_reduce」就是从这两组配对来的。
4.1 Attention:按 head 切
attention 的列切有个特别直观的名字——按 head 切。
为什么按 head 切如此自然?因为注意力头之间相互独立:算第 h h h 个 head 的注意力,只用到第 h h h 个 head 自己的 q、k、v,碰不到别的 head。既然各头互不相干,就把它们分给各卡——每张卡领走一部分 head,从 qkv_proj 投影、QK-Norm、RoPE,一直到 softmax 注意力,全程在自己这几个 head 上独立算完,中途谁也不用问谁。
4.2 MLP:gate_up 接 down
MLP 是同一个机制,把 head 换成 MLP 的中间神经元。
gate_up_proj(列切):把中间维(intermediate)的神经元分给各卡,gate 和 up 各分一半。tp=2 时 3072 个中间神经元每卡分到 1536,各卡只算自己那段。SiluAndMul(逐元素):算 silu ( gate ) × up \text{silu}(\text{gate}) \times \text{up} silu(gate)×up,是逐个神经元各算各的、不跨神经元混合。所以在各卡本地的分片上直接算就行,零通信——这正是「中间不通信」的关键。down_proj(行切):输入是上一步切开的中间分片,恰好对上行切要的形状;各卡算部分和,一次all_reduce求和。
拿一个最小例子(hidden 2、intermediate 4)把 tp=2 的整条计算走一遍——两卡各算一半,只在最后 all_reduce 一次:
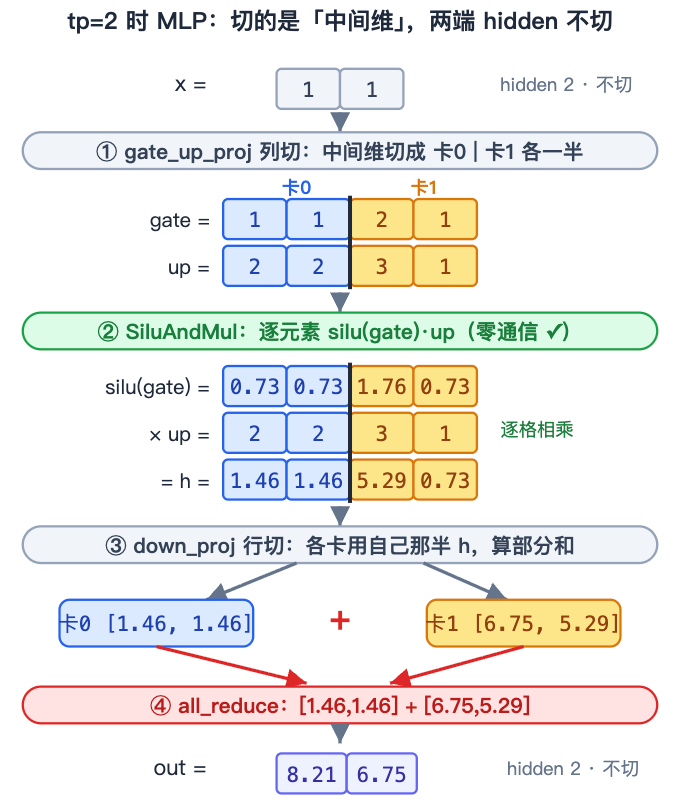
和 attention 一模一样的「列切 → 中间在分片上独立算 → 行切 → 一次 all_reduce」。
5. Embedding 与 LM Head
模型的头尾两层——把 token id 查成向量的 embed_tokens、把向量算成词表分数的 lm_head——切的都是词表维度(vocab):151936 个词分给各卡,tp=2 时每卡管 75968 个。但同样是 vocab 切,两者的通信方式相反,一个求和、一个拼接。
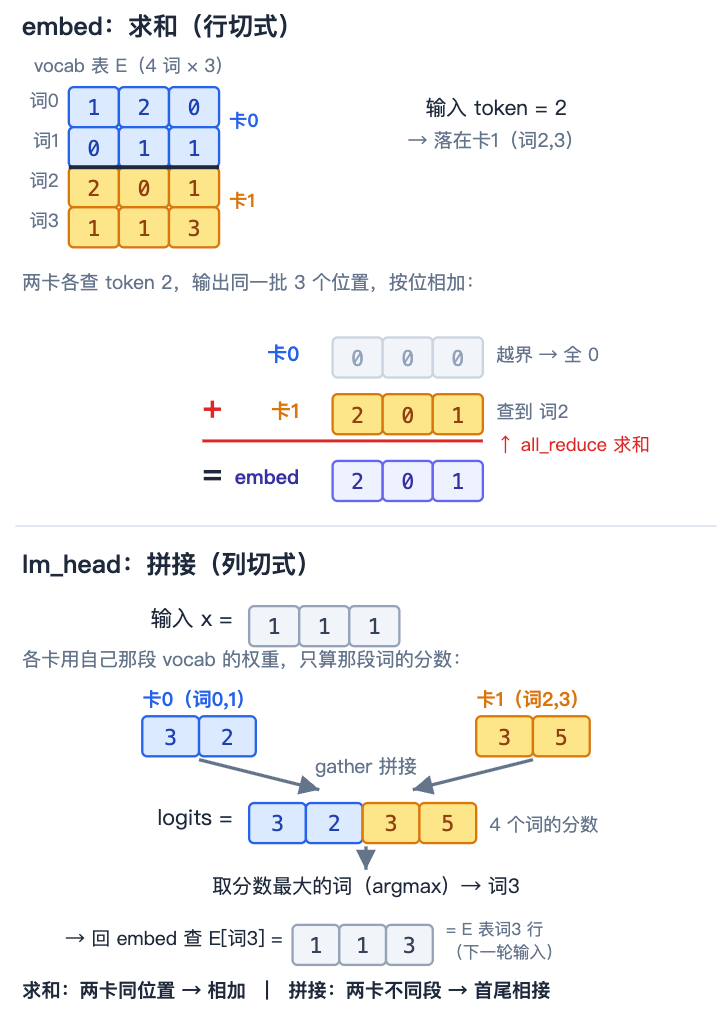
embed:求和。 每张卡只存自己那段 vocab 的 embedding 行。输入一个 token,如果它落在本卡负责的 vocab 段,就查到真向量;如果不在,本卡查不了,输出全 0(代码里用一个越界 mask 把 id 归零、再把输出清零)。每个 token 只会被一张卡「认领」——归属卡输出真向量、其余卡输出 0。这些向量都是完整的 hidden 宽、位置重叠,把各卡的结果 all_reduce 相加,0 不影响,就拼出了正确的 embedding。
lm_head:拼接。 每张卡用自己那段 vocab 的权重,算出那一段 vocab 的 logits。各卡算的是词表里不同的段,彼此不重叠;把它们 gather 到一张卡上首尾拼接,就是完整的 [151936] logits。
为什么一个求和、一个拼接? 这正是第 3 章那对原语:embed 各卡输出的是同一批位置的(真或零)向量、相互重叠 → 相加,是行切式;lm_head 各卡输出的是不同 vocab 段、互不重叠 → 拼接,是列切式。
6. RMSNorm 为何复制不切
切来切去,总览图里还剩两类「不切」的:RMSNorm 和它所在的残差流。为什么它们不切?
RMSNorm 要对整条 hidden 向量算均方根: rms = 1 d ∑ i x i 2 \text{rms} = \sqrt{\frac{1}{d}\sum_{i} x_i^2} rms=d1∑ixi2,再用它缩放每个元素。这个求和跑遍 hidden 的所有 d d d 个元素——需要完整的向量。
而残差流里的 hidden 一直是完整的:每次 all_reduce 之后,每张卡手里都是同一份完整的 hidden 向量。所以 RMSNorm 根本不用切——每张卡拿完整向量各算一遍,算的是同一件事、结果也相同,复制一份权重即可(权重才 hidden_size=1024 个,几乎不占显存)。
反过来,要是强行把 hidden 切给各卡,算均方时就得先跨卡把各段的平方和加起来——每个 RMSNorm 都要凭空多一次 all_reduce。一层两个 norm、28 层就是 56 次额外通信,纯亏。
这就是张量并行的取舍:只切大矩阵乘法(qkv/o/gate_up/down,切了实打实省算力和显存、通信还能摊薄),而 norm、残差这类又小又依赖完整向量的部分,一律复制、不切。
7. 小结
张量并行就两个问题:切在哪、何时通信。
切在哪。 一个线性层 Y = X ⋅ W Y = X \cdot W Y=X⋅W 只有两种切法:列切(按输出维度切,输入完整、输出分片、matmul 不通信)和行切(按输入维度切,输入分片、各卡只得部分和)。Transformer 的每个块把它们配成两组「列接行」——attention 的 qkv(列)→o_proj(行)、MLP 的 gate_up(列)→down(行),中间在分片上独立算、零通信。attention 的列切就是按 head 切(head 独立,各卡本地算完)。头尾的 embed/lm_head 切词表。RMSNorm 和残差流要完整向量,一律复制不切。
何时通信。 通信只在两处:行切之后要 all_reduce 把部分和求和;vocab 输出要把各卡的片段处理掉——embed 重叠相加(all_reduce 求和)、lm_head 不重叠拼接(gather)。
本篇把「为什么这么切、为什么在这通信」讲清了;接下来的篇幅实现张量并行。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 5
5 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)