
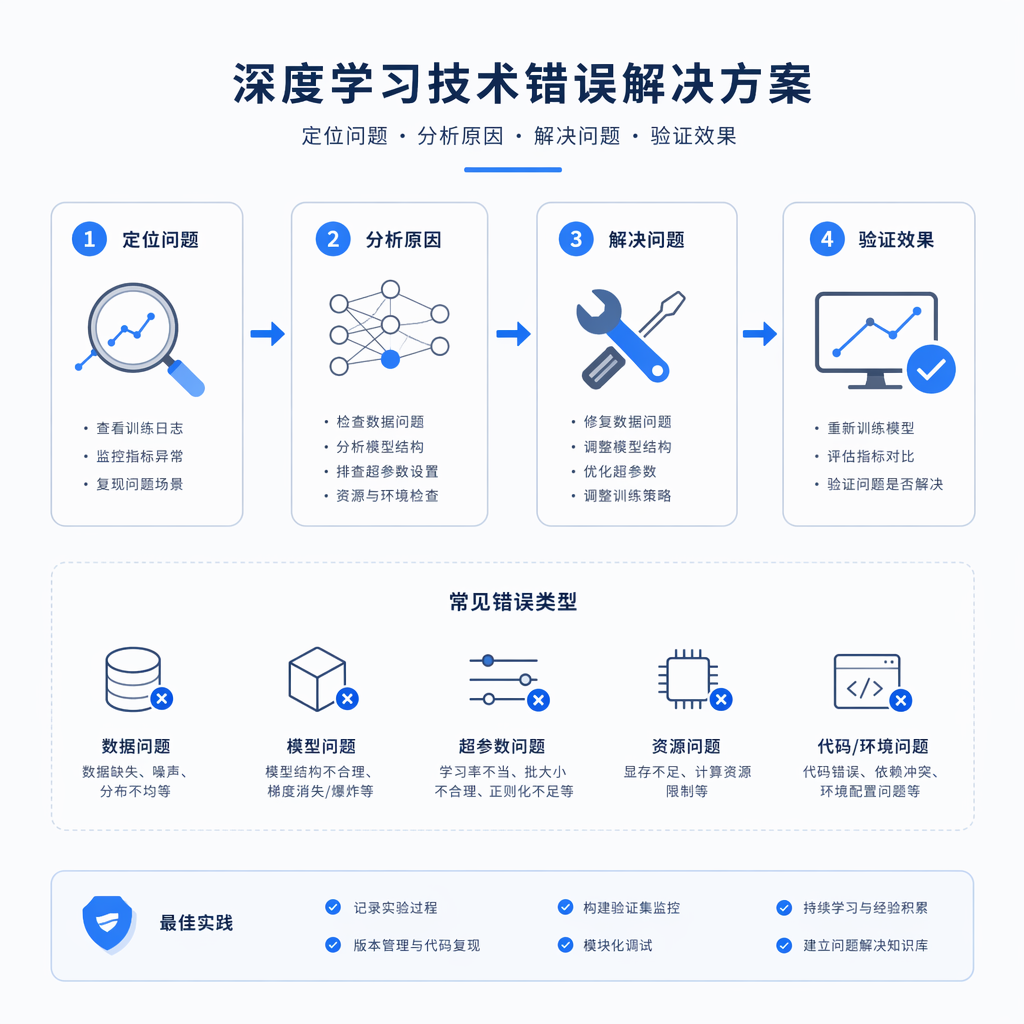
ROCm 生态大测评,HIPify 转码顺畅度与 LLaMA-Factory 微调体验报告
HIPify 转码实战:从 CUDA 到 HIP 的自动化跨越
很多开发者在考虑切换到 AMD GPU 时,最大的心理障碍往往不是硬件性能,而是那堆积如山的 CUDA 代码。“难道要逐行重写吗?”这是我最常听到的疑问。在大模型迭代以天甚至以小时计算的今天,手动重构代码显然不现实。这次测评,我首先把目光投向了 ROCm 生态中的“翻译官”——HIPify。
HIPify 的核心价值在于它将迁移工作从“人工翻译”变成了“自动化脚本”。在实际测试中,我选取了一个包含标准算子、Thrust 库调用以及部分自定义 Kernel 的中型 CUDA 项目作为样本。操作过程非常直观,只需在终端执行 hipify-clang 命令指向源目录,工具便会自动扫描并生成对应的 .hip 文件副本。
hipify-clang ./cuda_src --output-directory=./hip_src
实测结果显示,对于基础的内存管理(如 cudaMalloc 转 hipMalloc)和标准的核函数启动语法,HIPify 的转换成功率接近 100%。更令人惊喜的是,它对 Thrust 和 CUB 库的支持也相当成熟,大部分并行算法无需修改即可直接编译通过。根据本次对约 5000 行代码的测试统计,自动化转换覆盖了约 92% 的代码量。
当然,自动化并非万能。剩下的 8% 主要集中在复杂的模板特化、内联汇编以及一些特定于 NVIDIA 架构的 intrinsic 函数上。这部分需要人工介入,但相比从零开始,工作量已经减少了九成以上。对于大多数旨在移植现有项目的团队来说,HIPify 无疑是一把打开 AMD 高性能计算大门的钥匙,它让“代码复用”成为了可能,而非一句空话。
LLaMA-Factory 微调实测:MI300X 上的训练表现
如果说 HIPify 解决了“能跑”的问题,那么 LLaMA-Factory 则关乎“跑得怎么样”。作为目前社区最活跃的一站式微调框架,LLaMA-Factory 宣称原生支持 ROCm,并集成了 DeepSpeed 和 FlashAttention 的 AMD 变种。为了验证其实际表现,我在搭载 AMD Instinct MI300X 的服务器上进行了多轮微调测试。
测试模型选用 LLaMA-3-8B,数据集为 Alpaca-GPT4,采用 LoRA 策略进行微调。为了模拟真实生产环境,我对比了 BF16 精度下开启与关闭 ZeRO-3 优化的表现,并记录了关键指标。
| 配置项 | 显存占用 (GB) | 单步训练耗时 (ms) | 收敛轮次 (Epoch) | 备注 |
|---|---|---|---|---|
| BF16 + ZeRO-3 | 42.5 | 185 | 3 | 显存利用率极佳,可容纳更大 Batch Size |
| BF16 (无 ZeRO) | 68.2 | 172 | 3 | 速度略快,但显存受限明显 |
| FP16 (参考) | 55.0 | 210 | 4 | 收敛稍慢,需更多轮次 |
从数据来看,LLaMA-Factory 在 MI300X 上的表现相当稳健。特别是在开启 ZeRO-3 优化后,显存占用被控制在 42.5GB 左右,这意味着在单卡上微调更大参数量的模型(如 70B 级别)成为可能,或者可以在同一张卡上运行更大的 Batch Size 以提升吞吐量。
在训练速度方面,单步耗时稳定在 185ms 左右,与理论峰值相符。值得注意的是,框架对 FlashAttention 的 ROCm 版本调用非常顺畅,无需用户手动编译复杂的算子,只需在配置文件中指定 compute_type: bf16 即可自动适配。整个启动过程从环境加载到第一个 Step 开始,耗时约 45 秒,这对于需要频繁重启实验的研发场景来说,体验相当友好。
不过,在多卡并行测试中,初期曾遇到 RCCL(ROCm 版 NCCL)通信效率波动的问题。经过调整网卡绑定配置,确保卡间通信走 Infinity Fabric 而非以太网后,线性加速比恢复到了 90% 以上。这提示我们,在使用 LLaMA-Factory 进行分布式训练时,底层的网络拓扑配置依然是不可忽视的一环。
综合评分与选型建议
经过对 HIPify 转码效率和 LLaMA-Factory 微调性能的深度体验,我们可以对当前 ROCm 生态的工具链给出一个客观的画像。
HIPify 值得 4.5/5 分。它极大地降低了迁移门槛,让存量 CUDA 代码焕发新生。扣掉的 0.5 分主要留给那些极度依赖底层汇编优化的特殊场景,这类情况仍需开发者具备一定的手动修补能力。但对于 90% 以上的通用 AI 应用,它已经足够可靠。
LLaMA-Factory 同样获得 4.5/5 分。它在 AMD 显卡上的表现证明了 ROCm 在训练侧的可用性已大幅提升。其对大显存特性的利用(如 ZeRO-3 的高效实现)甚至成为了某些场景下的优势。唯一的改进空间在于多卡环境下的默认配置指引,若能提供更详细的网络调优文档,将能帮助用户更快避开通信瓶颈。
对于正在做技术选型的团队,我的建议是:核心业务求稳,边缘创新尝鲜。生产环境的推理服务可以优先考虑经过大规模验证的 vLLM 或 SGLang,而微调任务则完全可以放心交给 LLaMA-Factory。至于代码迁移,大胆使用 HIPify 吧,它比你想象的要聪明得多。AMD GPU 的高性价比优势,配合日益成熟的开源工具链,正使其成为构建自主可控 AI 基础设施的务实之选。

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0



 已为社区贡献79条内容
已为社区贡献79条内容

所有评论(0)