
《Nano-vLLM 源码解读》第 20 篇 · CUDA Graph
nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
前文把 Qwen3 逐层拆完了——embed_tokens + N×Qwen3DecoderLayer + final RMSNorm + lm_head,每个子模块都能解释。模型本身读通了,但把它真跑起来会发现:decode 阶段偏慢,而且慢得不像是 GPU 算不动。
问题出在 CPU。decode 每个 step 每条序列只生成 1 个新 token,每个 GPU kernel 处理的数据极少、跑得飞快;可每个 kernel 都得 CPU 先 launch 才能上 GPU,一次前向要 launch 几百个 kernel,总时间甚至比 GPU 算的总时间还长——GPU 算完一个就空等 CPU launch 下一个 kernel。
本篇把 CUDA Graph 一次讲透:decode 为什么被 CPU 拖慢(瓶颈)、CUDA Graph 的原理(capture 一次 / replay 多次)、它在 nano-vllm 里怎么落地、建图时怎么按多种 batch 把图捕获出来(capture_cudagraph)、每步 replay 又怎么把数据对齐喂进固定 buffer。
2. 总览
同样一次 decode 前向,eager 和 CUDA Graph 两条路差在哪?eager 路由 CPU 一个个 launch kernel,小 kernel 下 launch 比 kernel 还久,GPU 频频空等;CUDA Graph 路把整串 kernel 录成一张图,一次 replay 连发出去,GPU 不再空等。
打个比方:eager 像开车每到一个路口都得停下、等人指路才能再走,走走停停;CUDA Graph 像先把整条路线录进导航,之后一路开到底。

3. decode 的 CPU launch 瓶颈
先弄清一次前向在 CPU 和 GPU 之间是怎么跑的。每个算子(matmul、norm、激活……)都是一个 GPU kernel。kernel 不会自己上 GPU,得 CPU 先做一串准备——排参数、进队列、通知驱动——再交给 GPU 执行。这串准备就是一次 launch,开销是固定的(微秒级),跟这个 kernel 要算多少数据无关。
decode 恰好把这个固定开销放大到了极致。每个 step 每条序列只算 1 个新 token,kernel 处理的数据极少、几微秒就算完;可它的 launch 也要几微秒。一次前向要走完 28 层、每层十来个 kernel,几百个 kernel 全靠 CPU 一个接一个地 launch。算一笔账:launch 是串行的、加起来几百微秒,GPU 算完一个就停下来等 CPU 发下一个,大部分时间在空转。这正是图1 上半部分的画面:CPU 的 launch 条比 GPU 的 kernel 条还长,kernel 之间全是空等的缝隙。瓶颈不在 GPU 算力,在 CPU 来不及喂。
打个比方:厨房(GPU)炒一盘小菜只要几秒,但每盘菜都得服务员(CPU)先跑回前台把菜名、桌号、口味口头报一遍(launch)才能开炒。菜小、报菜名的时间比炒菜还久,厨房炒完一盘就闲着等下一句。
prefill 不存在这个问题:它一次要算几百上千个 token,每个 kernel 处理的数据多、执行时间长,launch 那几微秒摊到长 kernel 上几乎可忽略。所以瓶颈是 decode 独有的——这也是prefill 直接走 eager、不用 graph 的原因。
4. CUDA Graph:capture 一次,replay 多次
CUDA Graph 把一连串 GPU 操作整体录成一张图(capture),之后用一次 replay 整体重放,不必再让 CPU 一个个 launch。
用最小的例子看清它录了什么。两步加法 a = x + 1、b = a + 1:capture 时 CUDA 并不算出数值,而是把这两个加法 kernel、它们的先后顺序、各自读写的显存地址,原样记进图里。中间结果 a 只在图内部过一手,分在一块图私有的显存上——这块就是 graph_pool。
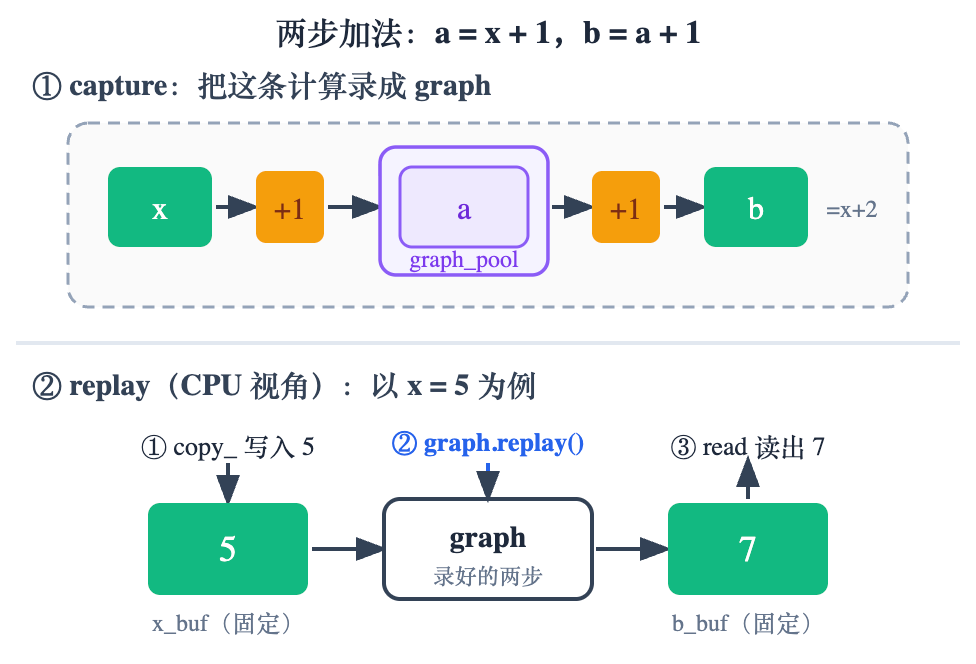
replay 怎么工作:每步 CPU 只做三件事——把新输入 copy_ 进固定的 x_buf、调一次 graph.replay()、再从固定的 b_buf 读结果(上图 x=5:写 5 → replay → 读 7)。
重点是中间那一步:两个加法在 GPU 上仍是两个 kernel,但 CPU 只发一条指令。eager 下 CPU 要 launch 两次(发完第一个 +1、等它上 GPU,再发第二个);而 capture 时「先 a = x + 1、再 b = a + 1」的顺序和各自用的地址已经记进图里,graph.replay() 底层就是一次 cudaGraphLaunch——把整张图整体提交给 GPU,两个加法的先后和衔接全由 GPU 按记录自己跑完,CPU 不再插手。decode 那几百个 kernel 同理:几百次 launch 压成这一次 replay。
解决了什么:GPU 不再算完一个就空等下一个 launch,几百个小 kernel 背靠背连着跑,decode 提速。
和算子融合的区别:算子融合(比如把 silu(gate) * up 融成一个 kernel)是把几个算子并成一个——kernel 数量变少,还顺带省掉中间结果在显存里来回搬;它改的是「有几个 kernel、每个算什么」。CUDA Graph 一个 kernel 都不合并、也不改,只把「这串 kernel 怎么 launch」整体录下来、一次重放——省的是 launch 开销,计算本身原封不动。两者正交、能叠加:先融合让 kernel 少几个,再用 CUDA Graph 把剩下那几百次 launch 压成一次 replay。
4.1 为什么 I/O 必须是固定地址 buffer
graph 认死了 capture 时用的那些地址,replay 也不接收新参数。所以每步喂进去的输入、读出来的输出,都得落在 capture 时那同一块 buffer 上——不能图省事每步新建一个 tensor:新 tensor 在别的地址上,图根本不会去看它,replay 出来的还是上一次的老数据。
nano-vllm 为此备了一组常驻 buffer:input_ids、positions、slot_mapping、context_lens、block_tables、outputs 六个,capture 时绑定,每步 replay 前把当前数据拷进去、replay 后从里面读。
5. 建图:capture_cudagraph
单张图的原理清楚了,nano-vllm 把它用在 decode 上。图在引擎启动时一次性录完:ModelRunner.__init__ 里 warmup、分配 KV cache 之后,只要没开 enforce_eager,就调 capture_cudagraph 把 decode 的图全部捕获好,之后每步直接 replay。
难点是 decode 的 batch(同时解码的序列条数)每步都在变,1 条、5 条、几十条都可能,而一张图的形状在 capture 时就固定了。每种 batch 都录一张太多了,办法是分桶,只录有限几种——
graph_bs = [1, 2, 4, 8] + list(range(16, max_bs + 1, 16))
小 batch 单独列(1/2/4/8 最常见),大 batch 每 16 一档,一直到上限 max_bs = min(max_num_seqs, 512)。运行时把当前 batch 向上取整到最近的那一档。
捕获循环有两个工程细节:
- 从大到小捕获、共用一块 pool:每张图都要一块 graph_pool 放中间结果,但各档图从不会同时 replay,所以让它们共用一块就够了——N 张图不占 N 份中间显存。
reversed先录最大那张(512)把池子撑够,较小的图复用它。 - 先 warmup 再 capture:每个 batch 先在图外正常跑一遍前向(让 cuBLAS 等惰性初始化就绪),紧接着在
with torch.cuda.graph(graph, self.graph_pool):里再跑一遍——这一遍才被录进图。
import torch
@torch.inference_mode()
def capture_cudagraph(self):
config = self.config
hf_config = config.hf_config
max_bs = min(self.config.max_num_seqs, 512) # 捕获的 batch 上限
max_num_blocks = (config.max_model_len + self.block_size - 1) // self.block_size
# —— 六个常驻 buffer:按最大形状一次性开好,所有图共用(即第 4.1 节的固定地址)——
input_ids = torch.zeros(max_bs, dtype=torch.int64)
positions = torch.zeros(max_bs, dtype=torch.int64)
slot_mapping = torch.zeros(max_bs, dtype=torch.int32)
context_lens = torch.zeros(max_bs, dtype=torch.int32)
block_tables = torch.zeros(max_bs, max_num_blocks, dtype=torch.int32)
outputs = torch.zeros(max_bs, hf_config.hidden_size)
self.graph_bs = [1, 2, 4, 8] + list(range(16, max_bs + 1, 16)) # 分桶:要录哪些 batch
self.graphs = {}
self.graph_pool = None
for bs in reversed(self.graph_bs): # 从大到小,便于共享显存池
graph = torch.cuda.CUDAGraph()
# 用 buffer 的前 bs 行拼一个 decode context(slot/context_lens/block_tables)
set_context(False, slot_mapping=slot_mapping[:bs],
context_lens=context_lens[:bs], block_tables=block_tables[:bs])
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # warmup:图外先跑一遍
with torch.cuda.graph(graph, self.graph_pool):
outputs[:bs] = self.model(input_ids[:bs], positions[:bs]) # capture:这一遍被录进图
if self.graph_pool is None:
self.graph_pool = graph.pool() # 第一张(最大)图的池子,后面都复用
self.graphs[bs] = graph
torch.cuda.synchronize()
reset_context()
# 六个 buffer 收进字典,run_model replay 时按名取用
self.graph_vars = dict(
input_ids=input_ids, positions=positions, slot_mapping=slot_mapping,
context_lens=context_lens, block_tables=block_tables, outputs=outputs,
)
6. replay graph
图建好了,每个 step 怎么用?run_model 是真正调用模型的地方(L11 讲过它在 run 主干里的位置:prepare_* 铺好张量 → run_model 算 logits → sampler 出 token)。它开头一行 if 就是 eager 与 graph 的分流——三个条件里任一成立就走 eager(老老实实一个个 launch),否则走 graph(replay):
is_prefill:prefill kernel 长、launch 占比本就小,用 graph 不划算;何况 prefill 每次长度不同,形状对不上固定 buffer 的图。self.enforce_eager:调试 / 对照开关,置 True 就全程 eager,既不捕获也不 replay。input_ids.size(0) > 512:这里的size(0)是 decode 的 batch(序列条数)。capture 时只录到max_bs = min(max_num_seqs, 512)那么大的 batch,超过 512 就没有对应的图,只能退回 eager。
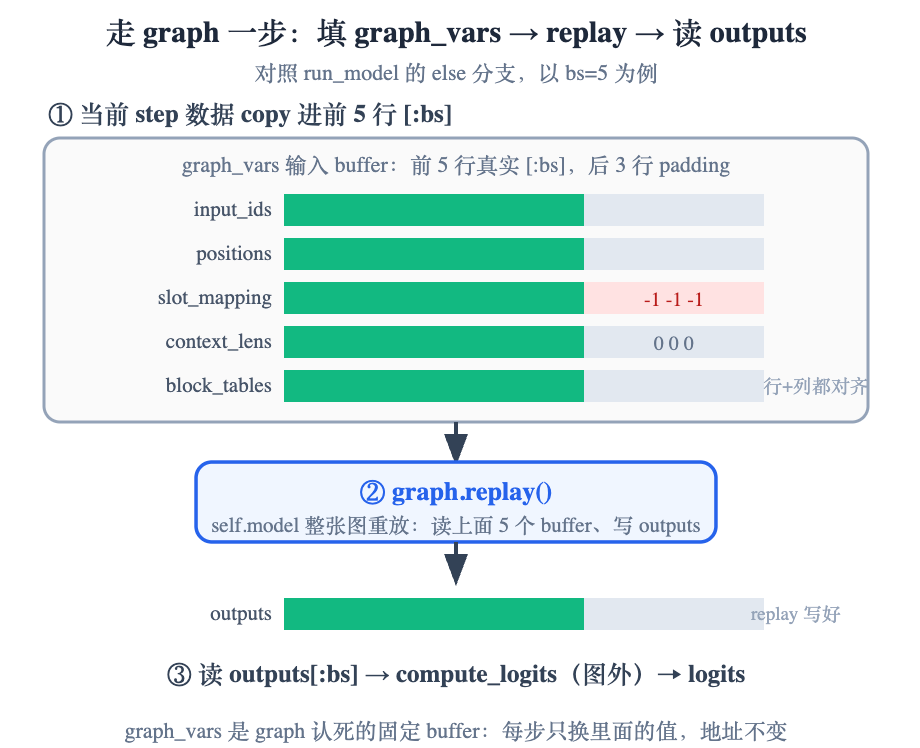
走 graph 时,关键是把当前 step 的数据对齐进固定 buffer。当前 batch 不一定正好等于某一档,于是先向上取整取一张 ≥ 当前 batch 的图:比如 bs=5,就用 batch=8 那张。这张图会按 8 行去算,可真实数据只有 5 行——多出来的 3 行是 padding,必须处理干净:
[:bs]拷贝:当前数据只写进 buffer 的前 bs 行(graph_vars["input_ids"][:bs] = input_ids等)。slot_mapping.fill_(-1)再写前 bs 行:padding 行的 slot 置 -1(无效槽),让被录进图的 KV 写入 kernel 对这几行写不进真实 KV cache,不污染别的序列。context_lens.zero_()再写前 bs 行:padding 行的上下文长度归 0,attention 对这几行不算。block_tables[:bs, :context.block_tables.size(1)]:既对齐 batch 行数,也对齐列宽——当前 step 的 block_table 列数往往比 buffer 的max_num_blocks窄,只覆盖左上角那块。
对齐完 graph.replay() 重放整串,最后从 outputs[:bs] 把前 bs 行结果读出来。注意 graph 只包 self.model(...)(decoder 主体);compute_logits(lm_head)在图外 eager 算。
import torch
@torch.inference_mode()
def run_model(self, input_ids: torch.Tensor, positions: torch.Tensor, is_prefill: bool):
# 三条任一成立 → 走 eager:CPU 一个个 launch,直接 forward
# is_prefill:kernel 长、launch 占比小,且变长对不上固定 buffer
# enforce_eager:调试开关,全程 eager
# >512:超过捕获上限 max_bs=min(max_num_seqs,512),没那张图
if is_prefill or self.enforce_eager or input_ids.size(0) > 512:
return self.model.compute_logits(self.model(input_ids, positions))
else:
# 其余(decode、batch≤512)→ 走 graph
bs = input_ids.size(0)
context = get_context()
graph = self.graphs[next(x for x in self.graph_bs if x >= bs)] # 取 ≥bs 的那张图
graph_vars = self.graph_vars
# ↓ 当前 step 数据对齐进固定 buffer:
# [:bs] 只写前 bs 行;fill_(-1)/zero_() 把 padding 行置无效,不污染真实 KV
graph_vars["input_ids"][:bs] = input_ids
graph_vars["positions"][:bs] = positions
graph_vars["slot_mapping"].fill_(-1)
graph_vars["slot_mapping"][:bs] = context.slot_mapping
graph_vars["context_lens"].zero_()
graph_vars["context_lens"][:bs] = context.context_lens
graph_vars["block_tables"][:bs, :context.block_tables.size(1)] = context.block_tables
graph.replay() # 一次重放整串 kernel
# graph 只包 self.model(...)(decoder 主体);compute_logits(lm_head)在图外 eager
return self.model.compute_logits(graph_vars["outputs"][:bs])
7. 小结
decode 慢,慢在 CPU 来不及 launch:每 step 每条只算 1 token,几百个小 kernel 全靠 CPU 一个个下单,launch 比 kernel 还久,GPU 频频空等。CUDA Graph 的办法是 capture 一次、replay 多次——把整串 kernel 录成一张图,几百次 launch 压成一次 replay,GPU 背靠背连着跑。代价是图记地址不记值,所以 I/O 必须走固定 buffer。
工程化落到 nano-vllm 是两步。建图(capture_cudagraph,引擎启动时):开六个常驻 buffer,按 graph_bs 分桶、从大到小、共享一个 graph_pool 把多张 decode 图一次性录好。用图(run_model,每步):先过兜底判定(is_prefill、enforce_eager、batch >512 任一成立走 eager),其余 decode 取一张 ≥ 当前 batch 的图,把数据按 [:bs] 对齐进固定 buffer、padding 行用 -1/0 置无效,replay() 后从 outputs[:bs] 读结果;graph 只包 decoder 主体,compute_logits 始终在图外。
到这里,单卡 decode 的性能优化就讲完了。下一阶段换一个方向:当一张卡装不下、或想更快时,引擎怎么把模型切到多卡——每一层怎么切、进程间怎么协作。

免费领 150 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 10
10 0
0- 0



 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)