
《Nano-vLLM 源码解读》第 16 篇 · Linear 投影
上一篇里 RoPE 旋转的 q、k,是从一次投影、再split出来的。q、k、v 本是三个独立的线性投影,nano-vllm 把它们合并成了一次。本篇解读qkv_proj所属的 Linear 家族,讲清一件事:把 q/k/v、gate/up 合并成一次投影,为什么能省一次 kernel 启动。linear.py支持张量并行(多卡切分)。本篇着重介绍投影,简单起见统一按单卡解读,多卡切分后续单开篇幅
nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
1. 介绍
上一篇里 RoPE 旋转的 q、k,是从 self.qkv_proj(hidden) 一次投影、再 split 出来的。q、k、v 本是三个独立的线性投影,nano-vllm 把它们合并成了一次。
本篇解读 qkv_proj 所属的 Linear 家族,讲清一件事:把 q/k/v、gate/up 合并成一次投影,为什么能省一次 kernel 启动。
linear.py 支持张量并行(多卡切分)。本篇着重介绍投影,简单起见统一按单卡解读,多卡切分后续单开篇幅介绍。
2. Linear 的本质
一个线性层把输入的一组数,重新加权组合成输出的另一组数——输出里的每个数,都是输入那组数的一次加权求和,写成式子是 y = Wx + b。
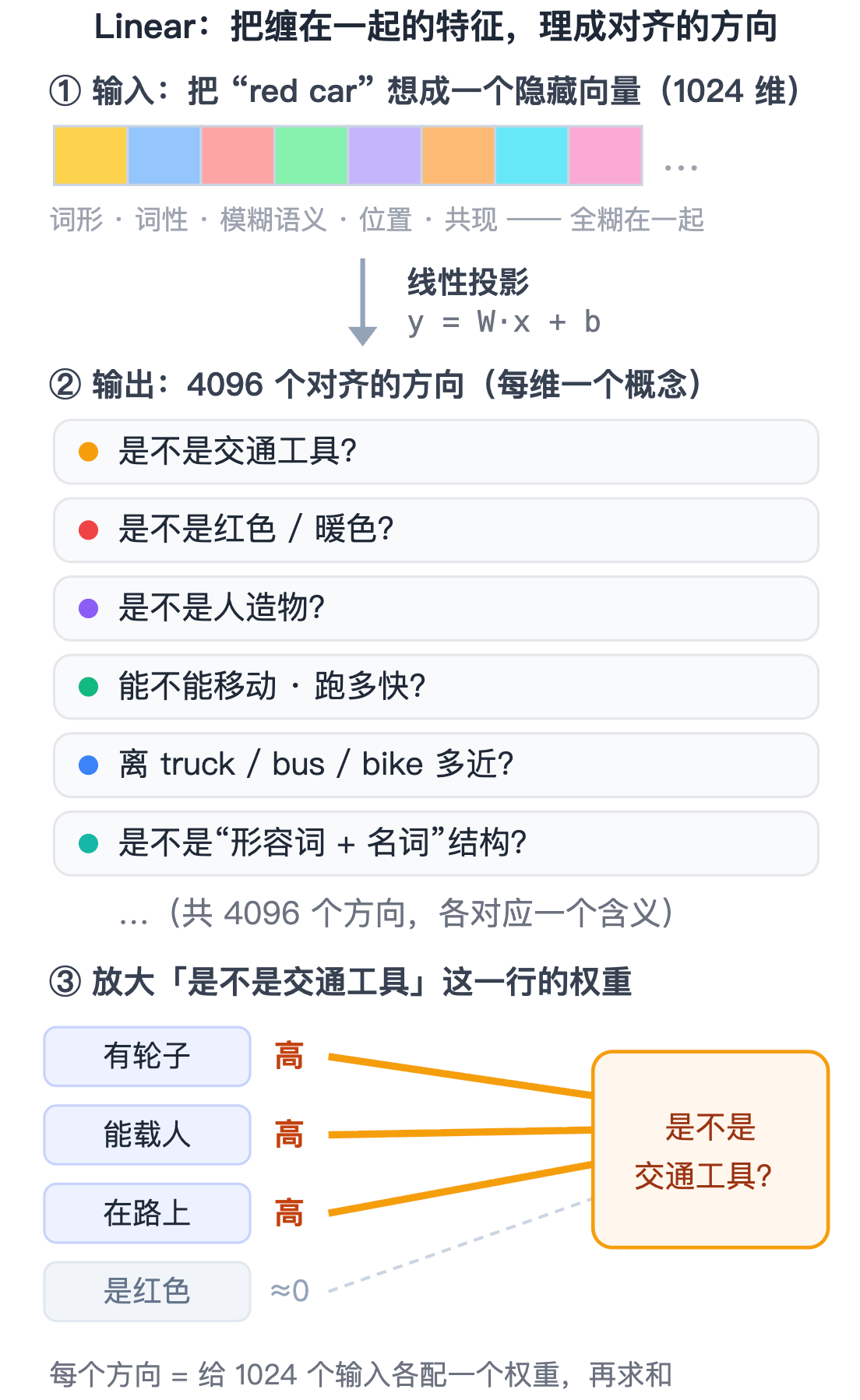
为什么需要:模型里每个 token 的隐藏向量,是一团「缠在一起」的信息——词形、粗粒度词性、模糊的语义、位置顺序全揉在同一组数里,杂乱无章。后面的计算想用上其中某一类,得先把这团乱麻「解开、对齐」成明确具体的特征。
解决了什么:Linear 把这团乱麻投影成一组「对齐好」的新方向,每个方向对应一个有意义的问题、彼此分开。拿 “red car” 举例(真实里它是两个 token,这里理想化成一个 1024 维隐藏向量),投影出 4096 维后,可能其中一维问「是不是交通工具」、一维问「是不是红色 / 暖色」、一维问「是不是人造物」、一维问「能不能移动、跑多快」……
怎么解决:每个输出方向就是 W 的一行——一个「概念提取器」:它给输入的每个特征分配一个权重,再加权求和。「是不是交通工具」那一行,会给「有轮子」「能载人」「在路上」这些输入特征高权重,给「是不是红色」近乎零权重。W 是 d_out × d_in 的权重矩阵、b 是偏置,前向就一句 y = Wx + b。
import torch
import torch.nn.functional as F
# 把图里那团 1024 维隐藏向量,理想化成 5 个看得懂的特征(0~1 表强弱)
# 有轮子 能载人 在路上 是红色 会发光
x = torch.tensor([ 1., 1., 1., 1., 0. ])
# W 的每一行 = 一个「对齐方向 / 概念」:给各特征配权重,再加权求和
W = torch.tensor([
[1., 1., 1., 0., 0.], # 是不是交通工具:看重 有轮子/能载人/在路上
[0., 0., 0., 2., 1.], # 是不是红色暖色:看重 是红色/会发光
])
b = torch.tensor([0., 0.])
y = F.linear(x, W, b) # 投影出两个方向的打分
print("交通工具分, 红色分 :", y) # tensor([3., 2.])
print("维度变换 :", x.shape[0], "->", y.shape[0]) # 5 -> 2
交通工具分, 红色分 : tensor([3., 2.])
维度变换 : 5 -> 2
这种「把一组特征线性重组成另一组」的操作,是深度学习里最高频、最吃算力的环节——Transformer 一层里 qkv、o、gate、up、down 全是 Linear(Linear 只做线性重组,要有非线性表达力,还得在两层之间夹一个激活函数)。本篇要拆的 qkv_proj,就是一次 1024 → 4096 的线性投影,只是它对齐出的方向供注意力当 q、k、v 用。
3. 总览
Linear 家族在 nano-vllm 里就一个文件 linear.py:一个基类 LinearBase 派生出五个子类。Qwen3 一层 decoder 里,四处线性投影各用其中一个。
| 类 | 用在哪 | 投影 |
|---|---|---|
ReplicatedLinear |
- | — |
ColumnParallelLinear |
仅作基类 | — |
QKVParallelLinear |
qkv_proj(合并 q/k/v) |
1024 → 4096 |
MergedColumnParallelLinear |
gate_up_proj(合并 gate/up) |
1024 → 6144 |
RowParallelLinear |
o_proj / down_proj |
2048→1024 / 3072→1024 |
按 forward 出场顺序,四处投影是 qkv_proj → o_proj → gate_up_proj → down_proj。其中两个是「合并投影」(表中的 QKV、Merged)——把本该分开的几次投影并成一次,正是本篇要介绍的。
单卡下,ColumnParallelLinear / RowParallelLinear / ReplicatedLinear 的 forward 都退化成一句 F.linear,类名里的「Parallel」代表支持多卡并行。
4. 合并投影
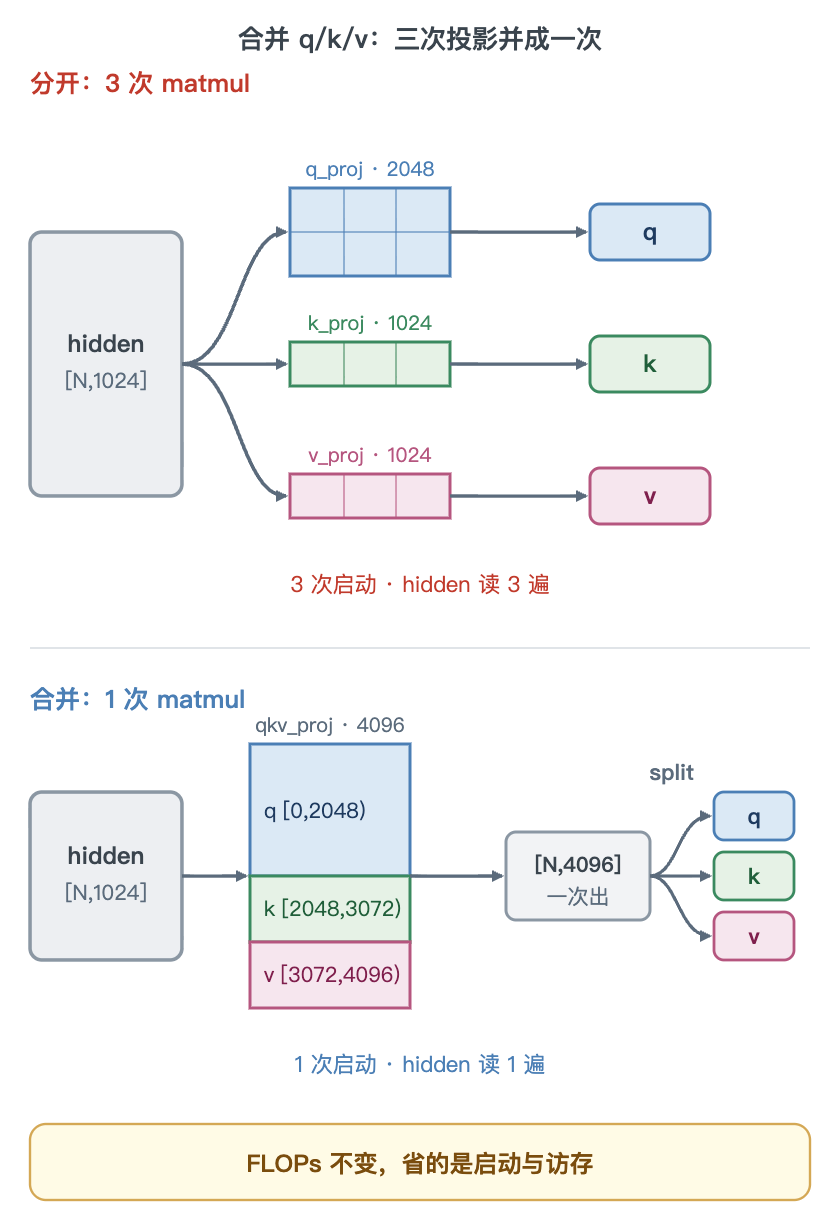
q、k、v 三个投影输入的是同一个 hidden。把三个权重矩阵在输出维上拼成一个大矩阵,一次 F.linear 算出 [N, 4096],再按 split([2048, 1024, 1024]) 切回 q、k、v。gate、up 同理,拼成一次 [N, 6144] 再切两半。
打个比方:三个人各跑一趟去同一个仓库取货,不如开一辆大车一趟拉回来再分。
为什么需要:分开做是三次独立的矩阵乘,等于三次 kernel 启动、hidden 从显存读三遍。decode 每步只算一个 token,矩阵很小,这时启动一个 kernel 的开销甚至比算它本身还久——三次启动就是三倍的固定开销。
解决了什么:固定开销与显存读写都降到原来的三分之一;一个大矩阵乘也比三个小的更能喂饱 GPU。
怎么解决:权重在输出维拼接成 [2048+1024+1024, 1024],前向一次 F.linear,输出再 split 切回。三次投影的总输出维不变,所以算的乘加次数(FLOPs)一点没少,省下的是 kernel 启动和显存读写——和 L14 把加法融进归一化是同一个道理:省的是访存与启动,不是算力。
# 直观看「合并 == 分开,但只一次 matmul」
torch.manual_seed(0)
x = torch.randn(3, 1024) # 3 个 token 的 hidden:[3, 1024]
wq = torch.randn(2048, 1024) # q 权重:[2048, 1024]
wk = torch.randn(1024, 1024) # k 权重:[1024, 1024]
wv = torch.randn(1024, 1024) # v 权重:[1024, 1024]
# 分开:三次 F.linear(三次 kernel 启动)
q, k, v = F.linear(x, wq), F.linear(x, wk), F.linear(x, wv)
# shape: q [3, 2048] k [3, 1024] v [3, 1024]
# 合并:权重在输出维 cat 成一个,一次 F.linear,再 split 切回
w_qkv = torch.cat([wq, wk, wv], dim=0) # [2048+1024+1024, 1024] = [4096, 1024]
qkv = F.linear(x, w_qkv) # [3, 1024] → [3, 4096],一次!
q2, k2, v2 = qkv.split([2048, 1024, 1024], dim=-1)
# shape: q2 [3, 2048] k2 [3, 1024] v2 [3, 1024](与分开版逐一对应)
print("hidden x :", tuple(x.shape)) # (3, 1024)
print("分开 q/k/v :", tuple(q.shape), tuple(k.shape), tuple(v.shape))
print("合并 qkv :", tuple(qkv.shape)) # (3, 4096)
print("q 一致 :", torch.allclose(q, q2, atol=1e-4)) # True
print("k 一致 :", torch.allclose(k, k2, atol=1e-4)) # True
print("v 一致 :", torch.allclose(v, v2, atol=1e-4)) # True
hidden x : (3, 1024)
分开 q/k/v : (3, 2048) (3, 1024) (3, 1024)
合并 qkv : (3, 4096)
q 一致 : True
k 一致 : True
v 一致 : True
5. LinearBase
LinearBase 是 Linear 家族的基类——持有一张权重表 weight(外加可选 bias),并挂一个 weight_loader 钩子负责把磁盘权重填进来。
import torch
from torch import nn
import torch.nn.functional as F
class LinearBase(nn.Module):
def __init__(self, input_size, output_size, bias=False):
super().__init__()
# 权重矩阵 [输出维, 输入维]
self.weight = nn.Parameter(torch.empty(output_size, input_size))
self.weight.weight_loader = self.weight_loader # 挂加载钩子
if bias:
self.bias = nn.Parameter(torch.empty(output_size))
self.bias.weight_loader = self.weight_loader
else:
self.register_parameter("bias", None)
def weight_loader(self, param, loaded_weight): # 默认:整块直接拷
param.data.copy_(loaded_weight)
def forward(self, x): # 单卡:一句 F.linear
return F.linear(x, self.weight, self.bias)
# 三个非合并子类:单卡下都没有额外动作,forward 直接用基类那句 F.linear
class ReplicatedLinear(LinearBase): # 单卡=整份(Qwen3 未用)
pass
class ColumnParallelLinear(LinearBase): # 单卡=整份;多卡按输出维切(后续介绍)
pass
class RowParallelLinear(LinearBase): # 单卡=整份;多卡按输入维切(后续介绍)
pass
6. 实现合并类
两个合并类都继承 ColumnParallelLinear,各做两件事:__init__ 把几路投影的输出维拼成一个大矩阵;weight_loader 在加载时把磁盘上分开存的几份权重,按段填回这块合并参数。
是什么:weight_loader 是挂在参数上的钩子,按一个 shard_id 把某一份磁盘张量,拷进合并参数里属于它的那一段行。
打个比方:合并参数像一个分格的抽屉柜,每份权重各自归位到对应格子;shard_id 是格子编号,weight_loader 是放进去的动作。
为什么需要:默认加载就一句 param.data.copy_(loaded_weight),要求名字与形状一一对应。合并把几份权重并成一块,破坏了这个对应,必须有钩子按段填。
怎么解决:weight_loader 先用 narrow 框出本段在合并参数里该占的行段,再把磁盘张量 copy_ 进去。两个合并类的区别只在分几段、偏移怎么算——gate/up 是相等的两段,qkv 是按头数算的三段。
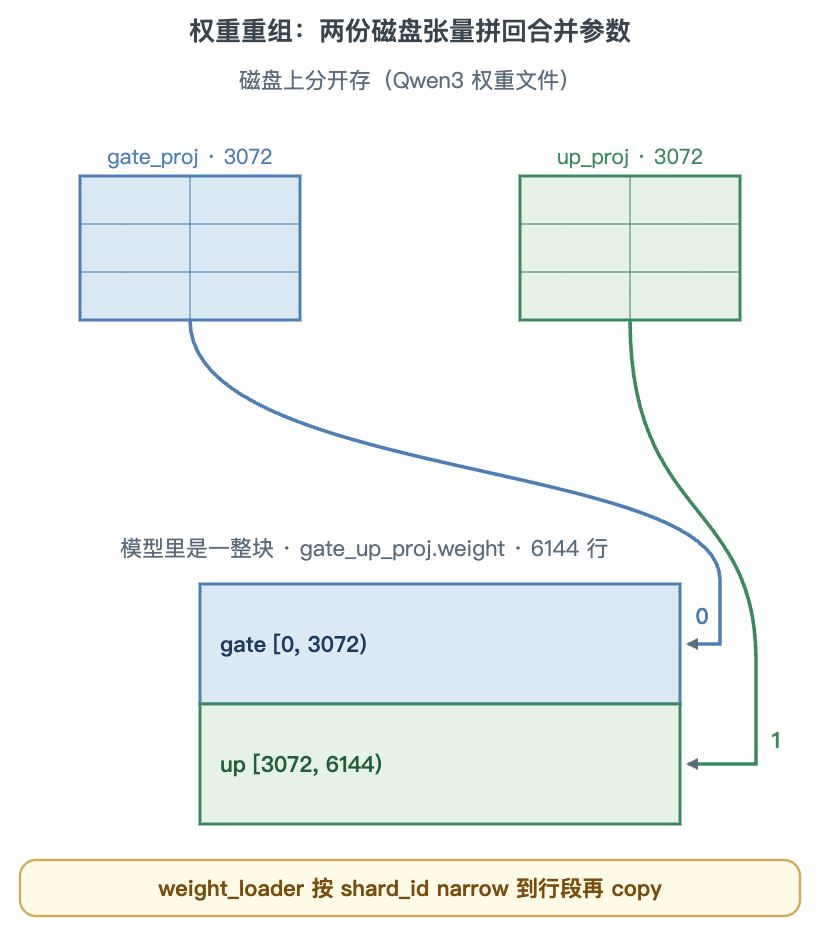
MergedColumnParallelLinear(gate/up,两段)
gate、up 两路输出维相等,合并成 gate_up_proj.weight(1024 → 6144)。weight_loader 按 output_sizes 累加偏移填段:gate 占 [0, 3072)(shard_id=0),up 占 [3072, 6144)(shard_id=1)。
# __init__ 把输出维求和,weight_loader 按 output_sizes 累加偏移填段。
class MergedColumnParallelLinear(ColumnParallelLinear):
def __init__(self, input_size, output_sizes, bias=False):
self.output_sizes = output_sizes # 各段输出维,如 [3072, 3072]
# 合并参数的输出维 = 各段之和
super().__init__(input_size, sum(output_sizes), bias)
def weight_loader(self, param, loaded_weight, loaded_shard_id):
# loaded_shard_id: 0=gate, 1=up
# 本段起始行 = 前面各段输出维之和(gate→0, up→3072)
shard_offset = sum(self.output_sizes[:loaded_shard_id])
shard_size = self.output_sizes[loaded_shard_id] # 3072
# narrow 框出该行段(dim0=按行=输出维),再拷进去
param_data = param.data.narrow(0, shard_offset, shard_size)
param_data.copy_(loaded_weight)
# ① __init__:合并权重输出维 = 各段之和
m = MergedColumnParallelLinear(1024, [3072, 3072]) # gate, up
print("gate_up 合并权重 :", tuple(m.weight.shape)) # (6144, 1024)
# ② weight_loader:两份"磁盘权重"用可辨认常数填,按 shard_id 落到对应段
gate_w = torch.full((3072, 1024), 1.)
up_w = torch.full((3072, 1024), 2.)
m.weight_loader(m.weight, gate_w, 0) # shard_id 0 → [0, 3072)
m.weight_loader(m.weight, up_w, 1) # shard_id 1 → [3072, 6144)
print("gate 段(前 3072) :", m.weight[:3072].unique().tolist()) # [1.0]
print("up 段(后 3072) :", m.weight[3072:].unique().tolist()) # [2.0]
gate_up 合并权重 : (6144, 1024)
gate 段(前 3072) : [1.0]
up 段(后 3072) : [2.0]
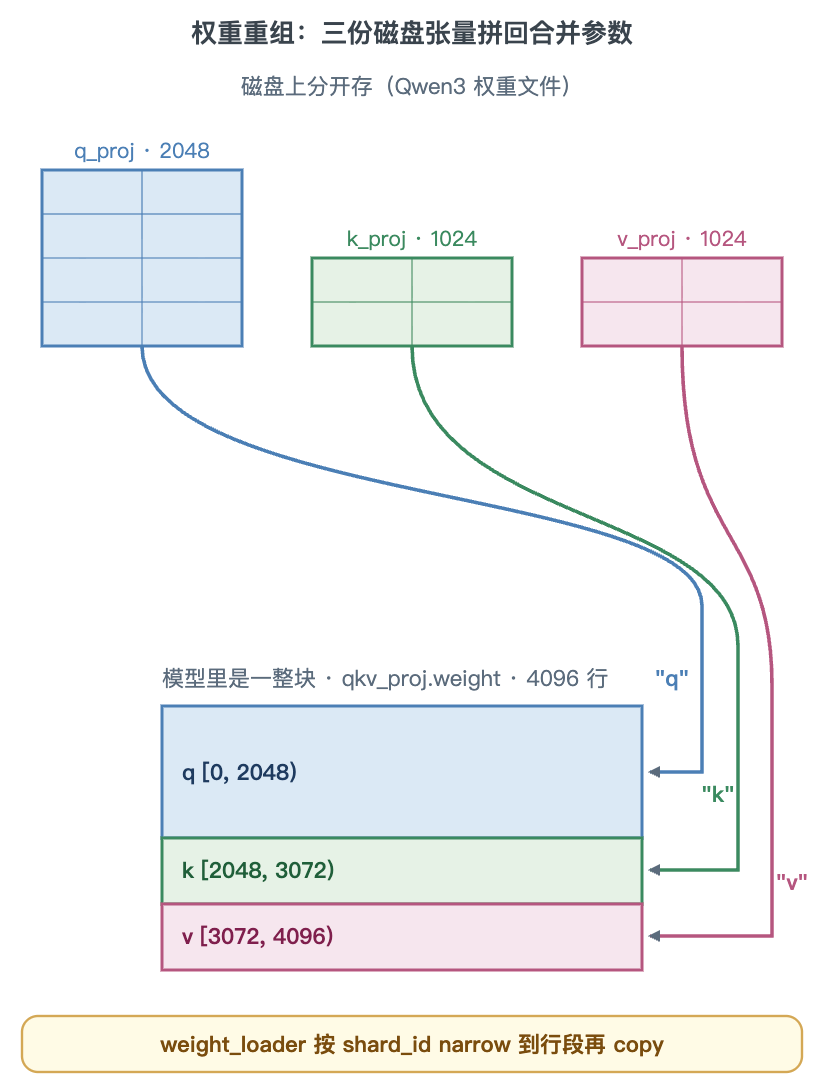
QKVParallelLinear(q/k/v,三段)
q、k、v 头数不同(q 16 头、k/v 各 8 头,每头 128 维),合并成 qkv_proj.weight(1024 → 4096)。weight_loader 按头数算偏移填段:q 占 [0, 2048)、k 占 [2048, 3072)、v 占 [3072, 4096),shard_id 分别为 "q"/"k"/"v"。
# __init__ 按头数算输出维,weight_loader 按 q/k/v 三段填。
class QKVParallelLinear(ColumnParallelLinear):
def __init__(self, hidden_size, head_size, total_num_heads,
total_num_kv_heads=None, bias=False):
total_num_kv_heads = total_num_kv_heads or total_num_heads
self.head_size = head_size
self.num_heads = total_num_heads # q 头数 16
self.num_kv_heads = total_num_kv_heads # k/v 头数 8
# 输出维 = (q头数 + k头数 + v头数) × head_size
output_size = (total_num_heads + 2 * total_num_kv_heads) * head_size
super().__init__(hidden_size, output_size, bias)
def weight_loader(self, param, loaded_weight, loaded_shard_id):
assert loaded_shard_id in ["q", "k", "v"]
if loaded_shard_id == "q":
shard_size = self.num_heads * self.head_size # 16×128 = 2048
shard_offset = 0
elif loaded_shard_id == "k":
shard_size = self.num_kv_heads * self.head_size # 8×128 = 1024
shard_offset = self.num_heads * self.head_size # 偏移 2048
else: # v
shard_size = self.num_kv_heads * self.head_size # 1024
# 偏移 = q 段 + k 段 = 3072
shard_offset = (self.num_heads + self.num_kv_heads) * self.head_size
# narrow 框出合并参数里这一段行,再拷进去
param_data = param.data.narrow(0, shard_offset, shard_size)
param_data.copy_(loaded_weight)
# ① __init__:Qwen3-0.6B,输出维 = (16 + 2×8) × 128
qkv = QKVParallelLinear(hidden_size=1024, head_size=128,
total_num_heads=16, total_num_kv_heads=8)
print("qkv 合并权重 :", tuple(qkv.weight.shape)) # (4096, 1024)
# ② weight_loader:q/k/v 三份"磁盘权重"用可辨认常数填,按 shard_id 落段
q_w = torch.full((2048, 1024), 1.) # q: 16×128
k_w = torch.full((1024, 1024), 2.) # k: 8×128
v_w = torch.full((1024, 1024), 3.) # v: 8×128
qkv.weight_loader(qkv.weight, q_w, "q") # → [0, 2048)
qkv.weight_loader(qkv.weight, k_w, "k") # → [2048, 3072)
qkv.weight_loader(qkv.weight, v_w, "v") # → [3072, 4096)
print("q 段 :", qkv.weight[:2048].unique().tolist()) # [1.0]
print("k 段 :", qkv.weight[2048:3072].unique().tolist()) # [2.0]
print("v 段 :", qkv.weight[3072:].unique().tolist()) # [3.0]
qkv 合并权重 : (4096, 1024)
q 段 : [1.0]
k 段 : [2.0]
v 段 : [3.0]
路由表 packed_modules_mapping
合并参数能从分开的磁盘张量拼出来,还差一张对照表:packed_modules_mapping 记录「磁盘上的 q_proj → 合并参数 qkv_proj」。加载时遍历权重文件里的每条权重,据此把磁盘名换成合并参数名、取出 shard_id,再用 model.get_parameter 拿到那块合并参数 param,调它的 weight_loader 把张量填进对应段。
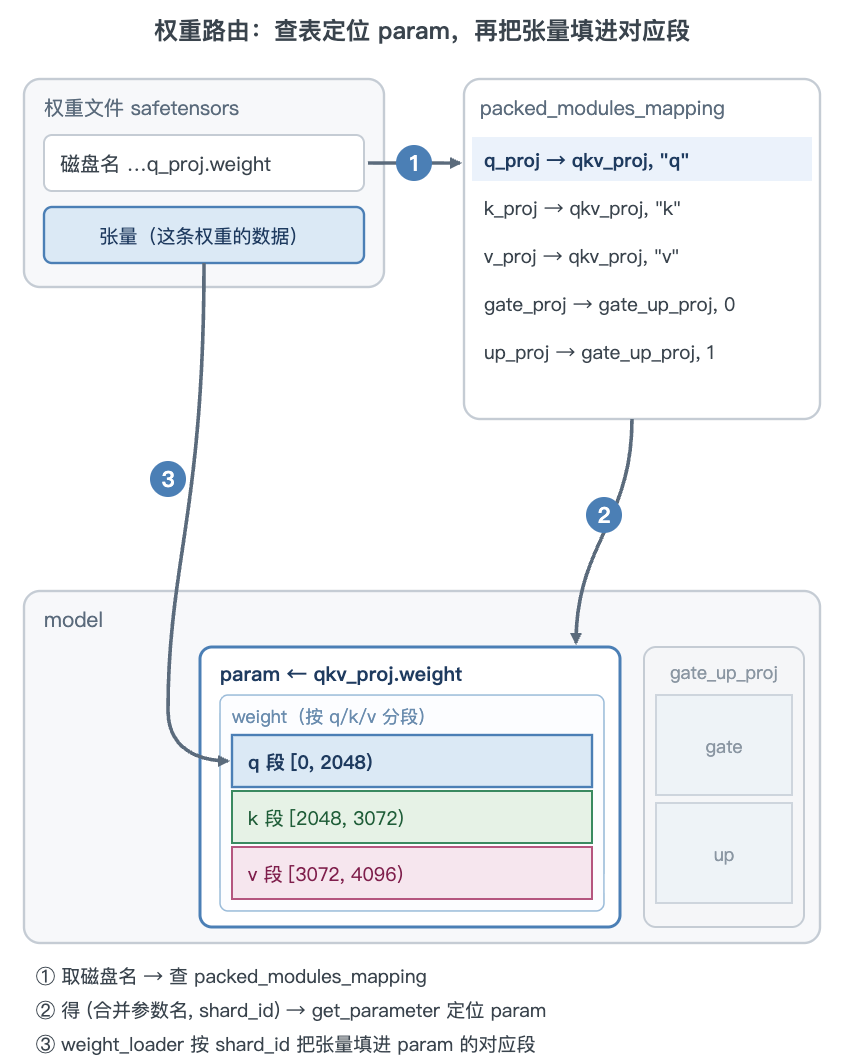
# Qwen3ForCausalLM.packed_modules_mapping:磁盘名 → (合并参数名, shard_id)
packed_modules_mapping = {
"q_proj": ("qkv_proj", "q"),
"k_proj": ("qkv_proj", "k"),
"v_proj": ("qkv_proj", "v"),
"gate_proj": ("gate_up_proj", 0),
"up_proj": ("gate_up_proj", 1),
}
# load_model 的路由逻辑(摘自 loader.py):
# for weight_name in 权重文件: # 如 "...q_proj.weight"
# for k in packed_modules_mapping: # 命中 "q_proj"
# if k in weight_name:
# v, shard_id = packed_modules_mapping[k] # ("qkv_proj", "q")
# param_name = weight_name.replace(k, v) # "...qkv_proj.weight"
# param = model.get_parameter(param_name)
# param.weight_loader(param, tensor, shard_id) # 带 shard_id 填段
# break
# else: # for 未 break(无命中)才进 else
# param.weight_loader(param, tensor) # 普通参数:默认 copy(无 shard_id)
print("q_proj 路由到 :", packed_modules_mapping["q_proj"]) # ('qkv_proj', 'q')
print("gate_proj 路由 :", packed_modules_mapping["gate_proj"]) # ('gate_up_proj', 0)
q_proj 路由到 : ('qkv_proj', 'q')
gate_proj 路由 : ('gate_up_proj', 0)
7. 集成验证
加载真实 Qwen3-0.6B,取第 0 层的 qkv_proj(一个真实 QKVParallelLinear),验证「合并一次 matmul + split」与「分开按段三次投影」逐元素一致——这正是合并省 launch 的前提:少两次启动,结果不变。
import torch
import torch.distributed as dist
import torch.nn.functional as F
from modelscope import snapshot_download
from nanovllm.config import Config
# 复用 L11 教学版 ModelRunner 加载真实权重
from topic11_model_runner import ModelRunner
torch.cuda.set_device(0)
if not dist.is_initialized():
dist.init_process_group(
"nccl", "tcp://localhost:2335", world_size=1, rank=0)
model_path = snapshot_download("Qwen/Qwen3-0.6B")
config = Config(model_path, enforce_eager=True, max_model_len=4096)
runner = ModelRunner(config)
model = runner.model # Qwen3ForCausalLM(权重 bf16)
Downloading Model from https://www.modelscope.cn to directory: /DATA/disk5/cache/modelscope/models/Qwen/Qwen3-0.6B
2026-06-07 19:12:53,732 - modelscope - INFO - Target directory already exists, skipping creation.
attn0 = model.model.layers[0].self_attn
qkv = attn0.qkv_proj # 真实 QKVParallelLinear
qs, kvs = attn0.q_size, attn0.kv_size # 2048, 1024
assert qkv.bias is None # Qwen3 用 QK-Norm 替代 qkv bias
# 造一份 hidden(dtype 跟权重一致)
torch.manual_seed(0)
hidden = torch.randn(4, 1024, device="cuda", dtype=qkv.weight.dtype)
with torch.inference_mode():
# 合并:一次 matmul,再 split
merged = qkv(hidden) # [4, 4096]
q, k, v = merged.split([qs, kvs, kvs], dim=-1)
# 分开:把合并权重按行段切出 q/k/v,各做一次 F.linear
W = qkv.weight
q2 = F.linear(hidden, W[0:qs])
k2 = F.linear(hidden, W[qs:qs + kvs])
v2 = F.linear(hidden, W[qs + kvs:qs + 2 * kvs])
print("合并输出维 :", tuple(merged.shape)) # (4, 4096)
print("q/k/v 偏移 :", 0, qs, qs + kvs) # 0 2048 3072
print("q 合并==分开 :", torch.allclose(q, q2, atol=1e-3)) # True
print("k 合并==分开 :", torch.allclose(k, k2, atol=1e-3)) # True
print("v 合并==分开 :", torch.allclose(v, v2, atol=1e-3)) # True
8. 小结
Linear 家族一个基类派生五个子类,共性是一个 weight 加一个 weight_loader 钩子。
两个合并类是本篇核心:QKVParallelLinear 把 q/k/v 拼成一次 1024→4096 的投影,MergedColumnParallelLinear 把 gate/up 拼成一次 1024→6144。合并不改变算的乘加次数,省下的是 kernel 启动与显存读写——三次小投影并成一次大的。代价是加载时要把磁盘上分开的 q_proj/k_proj/v_proj 按 shard_id 拼回合并参数,这由 weight_loader + packed_modules_mapping 完成。
下一篇讲解注意力层中,qkv 切出的 q、k、v 怎么过 QK-Norm、RoPE、attention,再经 o_proj 输出。

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 3
3 0
0- 0



 已为社区贡献12条内容
已为社区贡献12条内容

所有评论(0)