
从标注优化到全流程落地:Python+YOLOv8 打造 YOLO模型训练 一体化平台
本文介绍了一款针对电力单线图AI识别的全流程一体化平台,解决了传统碎片化工具链在数据标注、模型训练和设备检测中的痛点。平台整合了项目管理、手动标注、图元提取、素材合成、迭代训练、智能检测和报表导出七大功能,实现了从原始图纸到统计报表的自动化处理。通过人工标注与自动合成相结合的数据扩充方式,以及支持迭代训练的可视化操作界面,显著降低了AI技术使用门槛,使电力运维和设计人员也能独立完成整套流程。该方案
在上一篇博客《解决了一个困扰我们团队3个月的AI训练数据问题》中,我们针对性解决了多人协作标注时类别 ID 混乱、标签格式不统一的问题,优化了数据标注环节的规范性。
但在智能化识别的实际落地过程中,仅优化标注流程远远不足以支撑业务闭环。现场普遍存在真实样本数量不足、模型训练操作复杂、迭代优化门槛高、检测统计依赖人工等一系列问题,传统「标注工具 + 独立训练脚本 + 第三方检测程序」的组合模式,工具碎片化严重、上手难度大,非算法人员很难独立完成整套流程。
基于此,我在原有标注能力的基础上,从零重构开发了 YOLO 模型训练一体化桌面平台,整合项目管理、手动标注、图元提取、素材合成、迭代训练、智能检测、结果导出七大核心能力,实现从原始图纸到最终统计报表的全流程自动化,无需复杂环境配置、无需拆分多工具,真正做到低门槛落地、可持续迭代。
一、行业背景与现存痛点
1.1 行业背景
电力单线图是变电站、电网运维、电力设计领域的核心资料,图纸中包含断路器、隔离开关、互感器等数十类电气设备。传统工作模式下,设备数量统计、类型核对、台账录入完全依靠人工逐图清点:
- 单张复杂单线图人工清点耗时 10~30 分钟;
- 大批量图纸统计人力成本高、效率低下;
- 长时间人工目视检查极易出现漏检、错检,数据准确性无法保障。
利用 AI 目标检测技术自动识别图纸设备,是解决以上问题的最优方案,但 AI 落地链路长、环节多,传统模式阻碍了技术普及。
1.2 传统方案全链路痛点
结合项目落地经验,梳理出传统碎片化工具链的核心问题:
- 数据层面 真实现场标注样本少,单纯依靠人工标注难以满足模型训练需求;标注文件、图片、模型分散存放,多项目数据互相干扰,管理混乱。
- 标注层面 即便统一了类别 ID,标注后仍需手动拷贝文件、划分训练集 / 验证集,重复操作多;无法快速从标注样本中提取独立设备图元,不支持数据扩充。
- 训练层面 训练脚本依赖命令行操作,日志分散在终端窗口,无法直观查看训练状态;不支持便捷的迭代训练,每次优化模型都需要重新配置参数、寻找历史模型。
- 使用层面 训练完成的模型需要单独加载至检测程序,链路割裂;检测结果无法二次人工复核,也不能一键导出标准化报表,无法对接业务台账。
- 门槛层面 整套流程依赖算法人员操作,电力运维、设计等一线人员无法独立使用,AI 技术落地受限。
二、整体架构与技术栈
2.1 整体功能架构
平台采用模块化分层设计,各模块串行联动、数据互通,形成完整闭环,架构流程图如下:
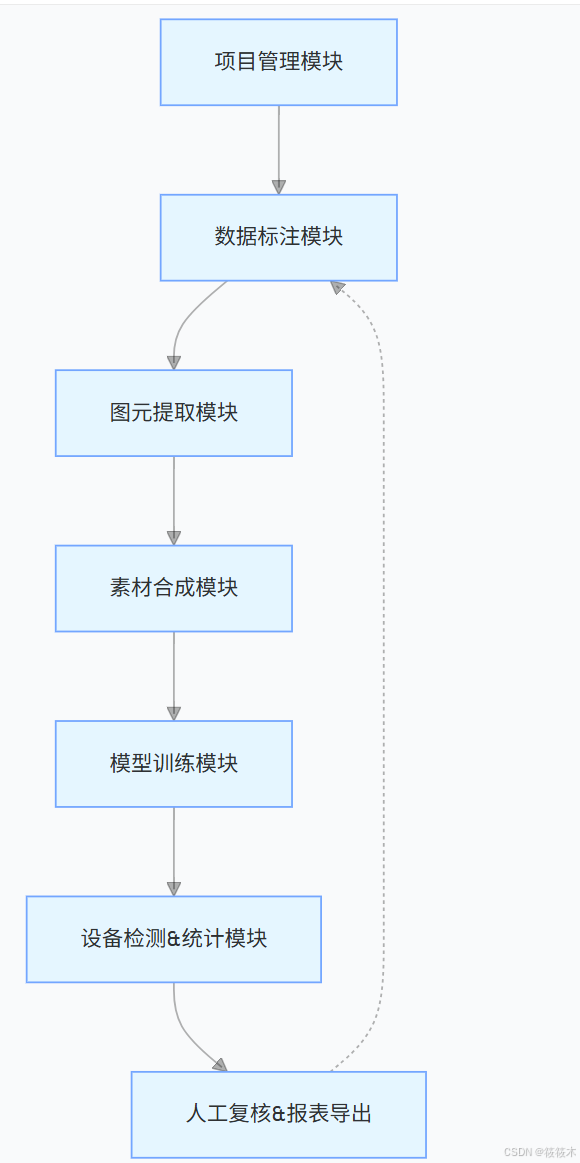
流程说明:
- 以独立项目为单位隔离数据,保证多项目并行使用;
- 手动标注真实图纸,并提取设备透明底图元;
- 基于图元 + 背景图自动合成海量训练样本,扩充数据集;
- 支持「从头训练」「迭代训练」两种模式完成模型训练,实时查看训练日志;
- 加载训练好的模型完成单线图批量检测、设备统计;
- 人工修正检测结果,一键导出 Excel 报表;
- 检测发现的难样本可回流至标注环节,持续扩充数据集,迭代优化模型。
2.2 核心技术栈
表格
| 分类 | 技术选型 | 作用说明 |
|---|---|---|
| 桌面界面 | PyQt5 | 开发跨平台可视化桌面工具,轻量化、免复杂部署 |
| 核心算法 | Ultralytics YOLOv8 | 工业级目标检测框架,适配图纸小目标、密集目标识别 |
| 图像处理 | OpenCV-Python | 图像裁剪、图元提取、图像合成、可视化标注 / 检测框 |
| 深度学习 | Python + PyTorch | 模型训练、推理,自动适配 CPU/GPU 运行环境 |
| 数据处理 | 原生文件读写 | 生成标准 YOLO 标签、数据集划分、Excel 报表导出 |
| 日志处理 | Logging + 标准输出重定向 | 全量捕获 YOLO 训练日志,界面内实时展示 |
三、核心功能模块详解
平台共划分七大功能模块,每个模块各司其职且深度联动,下面逐一介绍核心能力。
3.1 项目管理模块
作为平台数据总入口,实现多项目隔离管理,是所有功能的前置模块。
- 支持新建、加载、切换独立项目,每个项目自动生成标准目录结构;
- 内置类别配置功能,自定义电气设备类别与 ID,从源头统一标注规范;
- 自动划分
data、runs等目录,标注图片、标签、训练模型、日志分目录存储,杜绝数据混乱。
3.2 数据标注模块
在原有统一类别 ID 的标注能力上全面升级,面向训练场景做深度适配:
- 可视化框选标注,标注完成后自动将图片与标签存入训练集,无需手动迁移文件;
- 内置标签合法性校验,训练前自动检测类别 ID 越界、空标签等问题,提前规避训练报错;
- 支持批量导入图纸、预览标注状态,标注效率大幅提升;
- 纯可视化操作,无代码、无命令行,零基础也可上手。
3.3 图元提取模块
专属电力图纸场景的特色功能,衔接标注与数据合成:
- 基于已标注的图纸,自动裁剪框选区域,去除背景生成透明底独立设备图元;
- 自动汇总所有提取的图元,统一管理,为后续批量合成样本提供素材;
- 解决「单张图纸样本单一」问题,为数据扩充打下基础。
3.4 素材合成模块
解决行业真实标注样本不足的核心痛点:
- 支持上传多张图纸背景图,搭配已提取的设备图元进行随机组合;
- 可自定义合成数量、图元分布密度、随机变换等参数,灵活生成多样化样本;
- 合成数据自动按照 8:2 划分训练集 / 验证集,完全符合 YOLO 训练标准格式;
- 合成的图片与标签直接并入项目数据集,和人工标注数据无缝融合。
3.5 模型训练模块(重点:支持迭代训练)
本模块是整套平台的核心亮点,彻底告别命令行训练,兼顾新手与算法迭代需求:
- 双训练模式
- 从头训练:首次建模使用,基于官方预训练模型初始化;
- 迭代训练:在已有模型基础上继续优化,系统自动推荐最优参数,适配模型微调场景。
- 模型自动扫描 自动检索项目根目录基础预训练模型、项目历史迭代模型,按训练时间排序展示,一键选择使用,无需手动查找模型路径。
- 全量日志捕获 重定向 Python 标准输出与 Logging 日志,YOLO 训练过程中的损失值、精度、硬件占用、进度信息全部在工具界面实时展示,无需切换终端。
- 全参数可视化配置 训练轮数、批次大小、输入尺寸、学习率、冻结层数、数据增强等参数可视化可调;迭代模式下自动预设低学习率、冻结网络层等专业参数。
- 训练联动能力 训练完成后自动刷新模型列表,同时弹窗提示「一键加载至检测模块」,训练、推理无缝衔接。
3.6 设备检测与统计模块
面向业务最终使用场景,实现 AI 落地价值:
- 支持单张图纸检测、批量图纸检测,适配不同使用场景;
- 检测结果可视化展示,叠加设备框、类别名称、置信度,直观查看识别效果;
- 自动统计各类设备总数量,实时生成统计数据。
3.7 人工复核与报表导出
兼顾 AI 识别准确率与业务标准化输出:
- 支持手动新增、删除、修改检测框,修正模型漏检、误检问题;
- 复核完成后一键导出 Excel 统计报表,包含图纸名称、设备类型、数量、置信度等字段,可直接用于电力台账录入。
四、完整使用流程(新手友好版)
4.1 环境准备
- 依赖安装
pip install ultralytics pyqt5 opencv-python torch openpyxl
- 预训练模型准备:将 YOLOv8 系列预训练模型(
.pt)放入项目根目录models文件夹; - 启动程序:运行主程序
main.py,进入平台主界面。
4.2 分步操作流程
步骤 1:新建项目
进入「项目管理」标签,点击新建项目,填写项目名称、配置电气设备类别,系统自动生成全套目录结构,加载当前项目。
步骤 2:人工标注真实样本
切换至「数据标注」标签,导入电力单线图,框选设备并选择对应类别,完成后点击保存。标注文件自动存入训练集。
建议:优先标注 20~50 张真实图纸,保证基础数据质量。
步骤 3:提取设备图元
标注完成后,点击「一键提取图元」,系统自动从标注图纸中裁剪设备、生成透明底素材。
步骤 4:自动合成扩充数据集
切换至「素材合成」标签,上传图纸背景图,配置合成数量、图元密度等参数,启动合成。合成数据自动划分训练 / 验证集,与人工标注数据合并。
步骤 5:模型训练(含迭代训练)
- 首次训练:选择从头训练模式,在模型列表中选择 YOLO 预训练模型,按需调整参数,点击开始训练,实时查看界面日志;
- 迭代训练(模型优化):后续新增数据、优化模型时,选择迭代训练模式,系统自动适配微调参数,选择上一轮训练生成的
best.pt模型,继续训练即可; - 训练完成后,选择「自动加载模型」,跳转至检测模块。
步骤 6:图纸检测、复核与报表导出
- 导入待检测单线图,启动检测,查看识别结果与设备统计数据;
- 对误检、漏检设备进行人工修正;
- 确认无误后,一键导出 Excel 统计报表,完成全流程。
五、迭代训练标准方案(模型持续优化指南)
模型迭代是提升识别精度的核心,平台针对电力图纸场景定制了三套迭代方案,可直接套用:
5.1 阶段 1:首次从头训练(基础建模)
- 训练模式:从头训练
- 推荐参数:学习率 0.01、训练轮数 80~120、冻结层数 0
- 适用场景:第一次建模,数据集以人工标注 + 基础合成数据为主
5.2 阶段 2:第一轮迭代(浅层微调)
- 训练模式:迭代训练
- 推荐参数:学习率 0.001、训练轮数 40~60、冻结层数 10
- 适用场景:基于首轮最优模型,小幅优化特征,避免破坏预训练权重
5.3 阶段 3:第二轮迭代(全量微调)
- 训练模式:迭代训练
- 推荐参数:学习率 0.0005、训练轮数 20~30、冻结层数 0
- 适用场景:数据集已扩充完备,全网络微调,最大化提升模型精度
5.4 迭代优化通用技巧
- 每次迭代优先新增真实人工标注样本,再搭配合成样本,模型泛化能力更强;
- 开启 Mosaic 数据增强,提升密集设备、小目标的识别能力;
- 合理设置早停参数,防止模型过拟合;
- 优先选择每一轮训练生成的
best.pt(最优模型)作为下一轮迭代的基模型。
六、新旧方案对比(相较于上一版标注工具)
| 对比维度 | 上一版:协作标注工具 | 新版:全流程一体化平台 |
|---|---|---|
| 核心定位 | 解决多人标注类别 ID 混乱问题 | 电力单线图 AI 识别全业务闭环平台 |
| 功能范围 | 仅标注、标签导出 | 项目管理 + 标注 + 图元提取 + 合成 + 训练 + 检测 + 报表导出 |
| 数据能力 | 仅支持人工标注 | 人工标注 + 自动数据合成,解决样本不足难题 |
| 训练能力 | 无训练模块,依赖外部脚本 | 可视化训练、日志展示、一键迭代训练 |
| 落地链路 | 碎片化工具组合,链路割裂 | 全模块联动,训练完成直接检测、导出报表 |
| 使用门槛 | 需配合命令行、第三方工具 | 纯可视化操作,一线业务人员可独立使用 |
| 迭代能力 | 无迭代训练支持 | 原生支持多轮迭代训练,模型可持续优化 |
| 应用人群 | 算法标注人员 | 算法工程师、电力运维、电力设计等全岗位人员 |
七、核心技术亮点总结
- 全流程闭环,一站式落地 告别多工具切换,从数据制作到业务报表输出全部在一个程序内完成,链路极简。
- 双数据源互补,解决样本痛点 人工标注保证真实场景特征,自动合成扩充样本数量,二者结合兼顾质量与数量。
- 训练日志全捕获,可视化监控 同时拦截
print标准输出与logging日志,YOLO 所有训练信息界面内可见,排查问题无需终端。 - 原生支持迭代训练,工程化友好 区分「从头训练 / 迭代训练」,自动适配参数,符合工业界模型持续优化的使用习惯。
- 低门槛易上手,业务场景适配 针对电力单线图场景定制功能,弱化 AI 技术门槛,让一线人员也能使用 AI 能力。
- 数据规范化管理 项目隔离、目录标准化、标签合法性校验,从源头规避数据错误,降低训练失败概率。
八、效果展示与应用场景
8.1 应用效果
- 效率提升:单张图纸设备统计从人工 10~30 分钟,缩短至 AI 检测 1~3 秒;大批量图纸统计效率提升百倍以上。
- 精度保障:人工复核机制 + 多轮迭代训练,设备识别准确率可满足电力运维、设计的业务要求。
- 标准化输出:统一 Excel 报表格式,无缝对接现有电力台账系统。
8.2 适用场景
- 变电站、配电网单线图设备数量统计与台账录入;
- 电力设计图纸设备复核、工程量统计;
- 老旧纸质图纸数字化、设备信息梳理;
- 电力 AI 模型训练、算法迭代与技术研究。
九、总结与后续扩展方向
9.1 项目总结
本平台是在上一版标注优化工具的基础上,结合电力行业真实落地需求完成的全链路升级。不再局限于单一标注环节,而是打造了一套面向业务、可落地、可迭代的 AI 一体化解决方案。
对于算法人员,它简化了数据制作、模型训练的重复工作;对于电力一线人员,它降低了 AI 技术的使用门槛,真正实现技术赋能业务。整套方案基于开源 YOLOv8 与 Python 生态开发,轻量化、易部署、可二次改造。
9.2 后续扩展方向
- 模型格式导出:支持导出 ONNX 等格式,适配嵌入式边缘设备部署;
- 图纸预处理:增加倾斜校正、污渍去除等图像预处理功能;
- 拓扑分析:基于设备检测结果,自动生成电网拓扑关系;
- 批量任务调度:支持后台静默批量处理海量图纸,提升并发能力;
- 多模型兼容:扩展支持 YOLOv5、YOLOv11 等主流检测模型。
写在最后 从解决一个标注小痛点,到搭建一整套行业 AI 落地平台,核心思路始终是贴合业务、简化流程、降低门槛。本文完整分享了平台架构、功能、使用方法与迭代方案,代码与思路均可二次开发与改造,欢迎同行交流探讨,共同推进 AI 在传统电力行业的落地应用。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 2
2 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)