
显存低配福音!llama.cpp本地AI编程免费部署
上篇给大家分享了但是,日常写代码、调试项目很影响效率!针对的电脑,今天直接上终极优化方案!搭配 CCSwitch + Claude Code 完整复刻云端AI编程体验,,8G显存、16G内存也能流畅跑代码大模型,全程零Token、无联网、代码本地绝对安全!
上篇给大家分享了Ollama小白零基础本地AI编程方案
但是Ollama好用,就是显存占用高、低配显卡跑起来卡顿、推理速度慢,日常写代码、调试项目很影响效率!
针对低显存、有独显但配置一般的电脑,今天直接上2026最新llama.cpp正式版(b9334)终极优化方案!
搭配 CCSwitch + Claude Code 完整复刻云端AI编程体验,比Ollama更省显存、速度更快、硬件适配性更强,8G显存、16G内存也能流畅跑代码大模型,全程零Token、无联网、代码本地绝对安全!
适合人群:有独立显卡但显存不高、嫌弃Ollama低效、想要本地AI编程提速、私密项目防泄密的开发者
一、为什么选 llama.cpp?(碾压Ollama的核心优势)
llama.cpp 是目前本地大模型推理轻量化天花板,和Ollama小白方案形成完美互补:
✅ 极致省显存:支持多级量化、GPU分层加载,2G显存可跑7B代码模型
✅ 推理性能更强:纯C/C++底层开发,无冗余开销,代码生成/调试速度比Ollama提升30%-80%
✅ 全硬件兼容:N卡CUDA、A卡ROCm、Mac Metal、CPU全适配,老旧电脑也能盘活
✅ 高度可定制:自由调整上下文、GPU加载层数、推理参数,适配不同配置设备
✅ 依旧零成本:永久免费、无调用限制、无云端泄密风险
二、保姆级部署教
步骤 1:下载 llama.cpp 官方预编译包
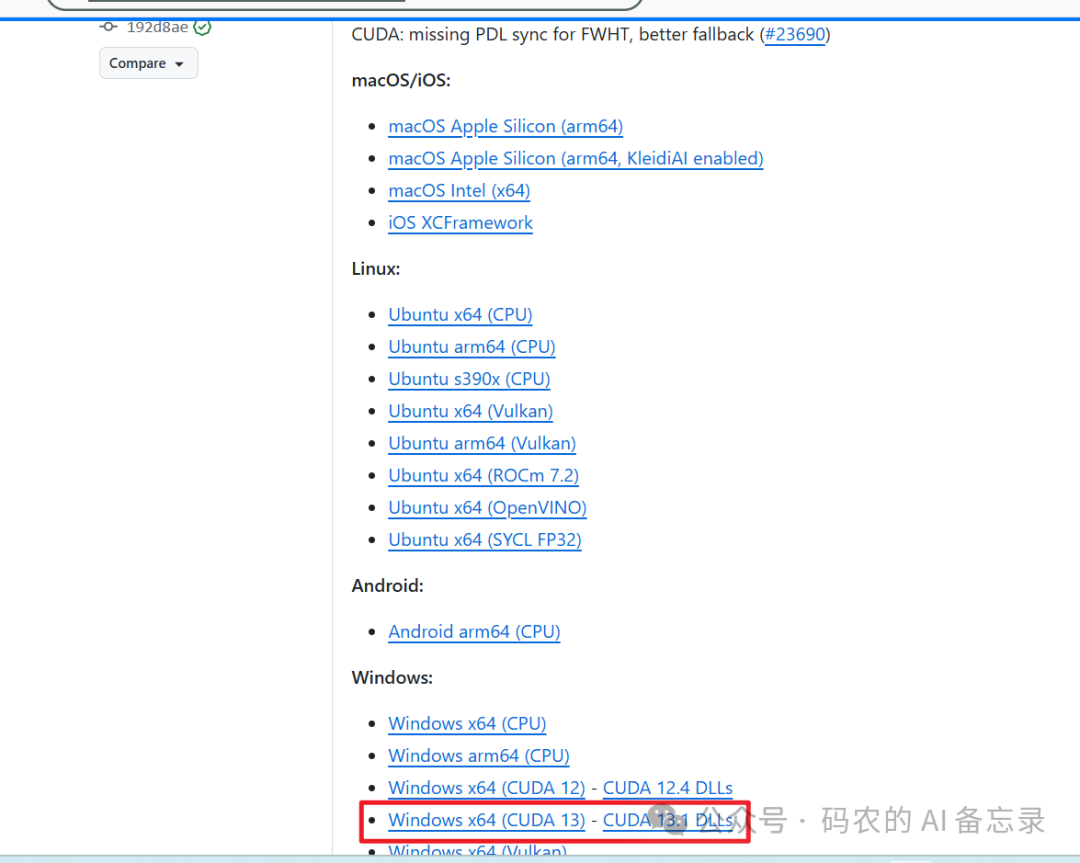
打开官方 Releases 页面:
https://github.com/ggml-org/llama.cpp/releases
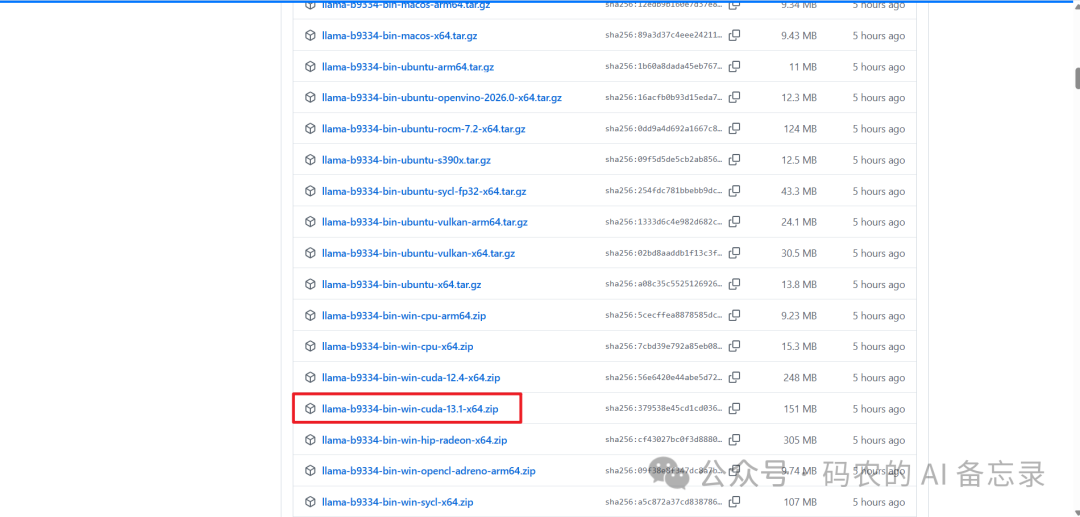
下载两个文件,并解压到同一个目录(比如 D:\llama):
对应系统的 CUDA 版本 DLL 压缩包(如 cudart-llama-bin-win-cuda-13.1-x64.zip)
对应系统的 llama.cpp 启动服务压缩包(含 llama-server.exe 等核心文件)
⚠️ 注意:两个包解压到同一文件夹,才能正常调用 CUDA 加速。
步骤 2:下载并准备大模型文件
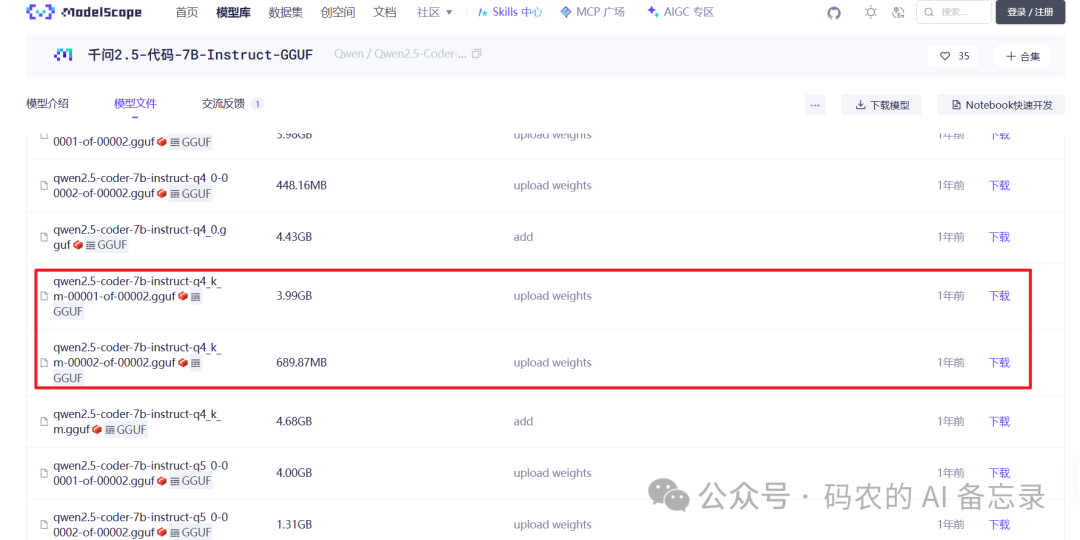
打开魔塔大模型网站,找到模型下载页:https://www.modelscope.cn/models/Qwen/Qwen2.5-Coder-7B-Instruct-GGUF/files
-
选择一个显存友好的量化版本(推荐
Q4_K_M,平衡显存占用与推理精度) -
下载该版本的所有分片文件到本地
-
将所有分片文件合并成一个完整的 GGUF 模型文件
-
把合并好的模型文件,放到刚才的
llama.cpp解压目录中备用
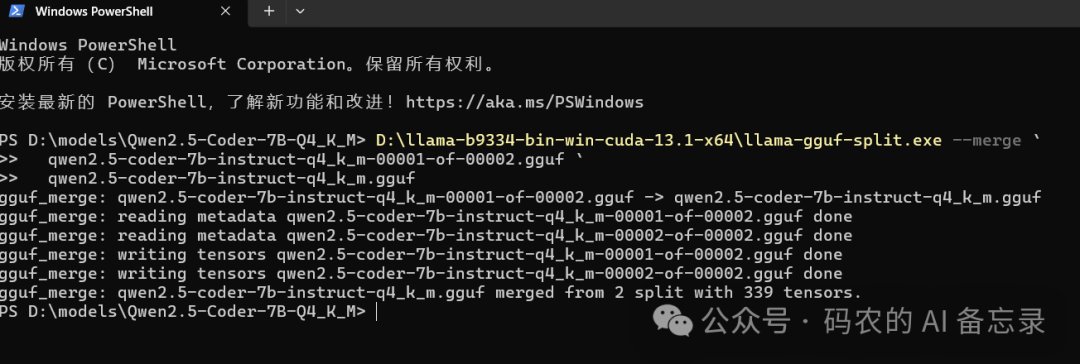
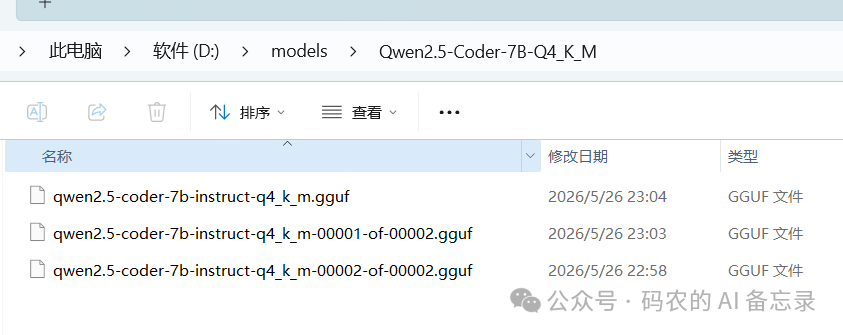
步骤 3:启动 llama.cpp 本地大模型服务
-
输入启动指令,让模型在本地运行API 服务
-
等待服务启动完成,看到提示成功运行后,你的本地 API 地址就准备好了
⚠️ 注意:显存较低的电脑,可以在启动时适当调整参数,以降低显存占用,避免卡顿或报错。
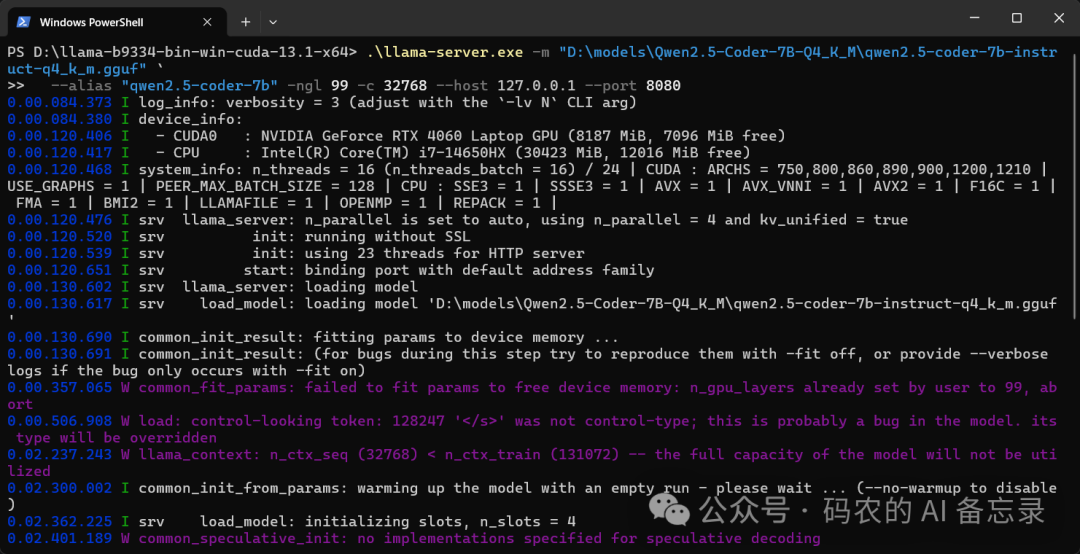
步骤 4:在 CCSwitch 中配置转发
-
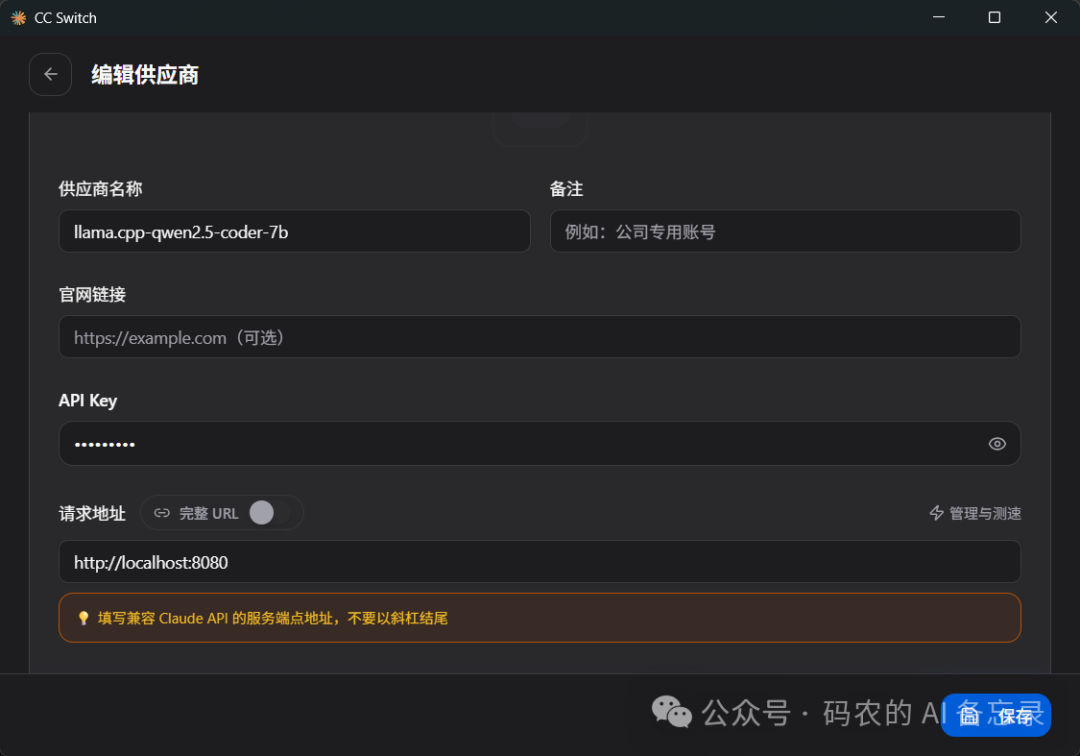
打开 CCSwitch 软件,点击「新增供应商」,选择「自定义」类型
-
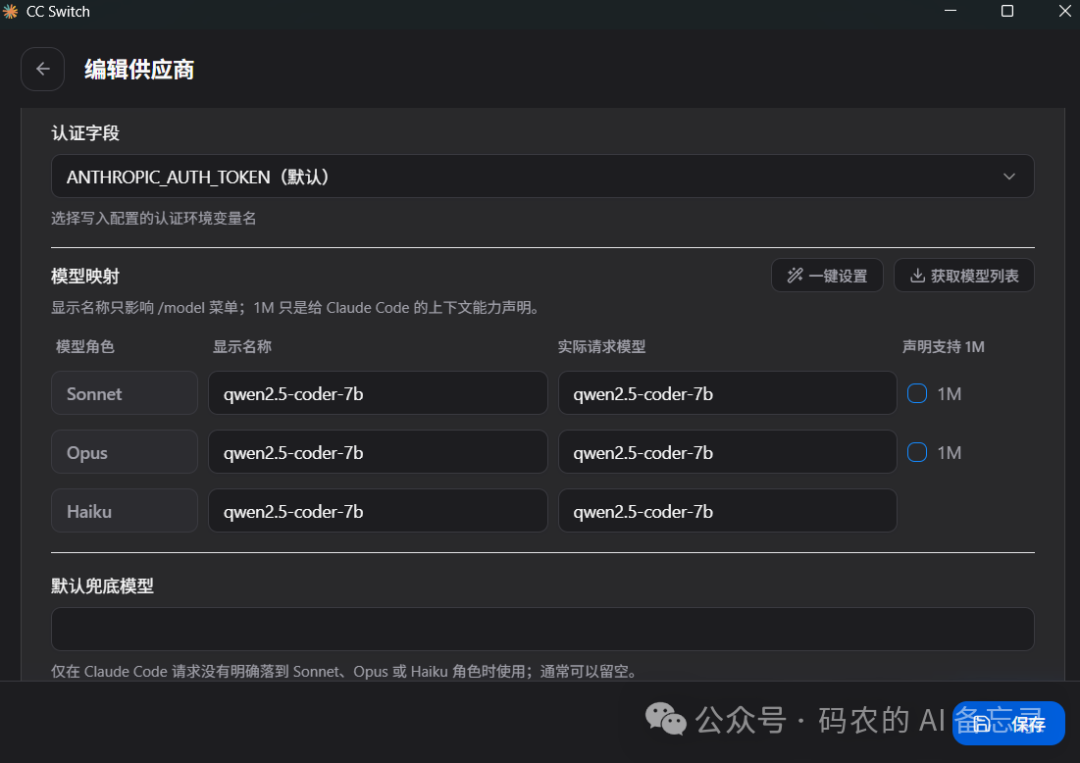
填写你的本地模型配置信息:
-
给服务起一个好记的名字(比如
llama.cpp-本地模型) -
把刚才启动服务时显示的本地 API 地址填进去
-
API Key 可以随便填一个,本地服务无需验证
-
-
保存配置,点击「启动转发」,让工具把请求转发到你的本地模型
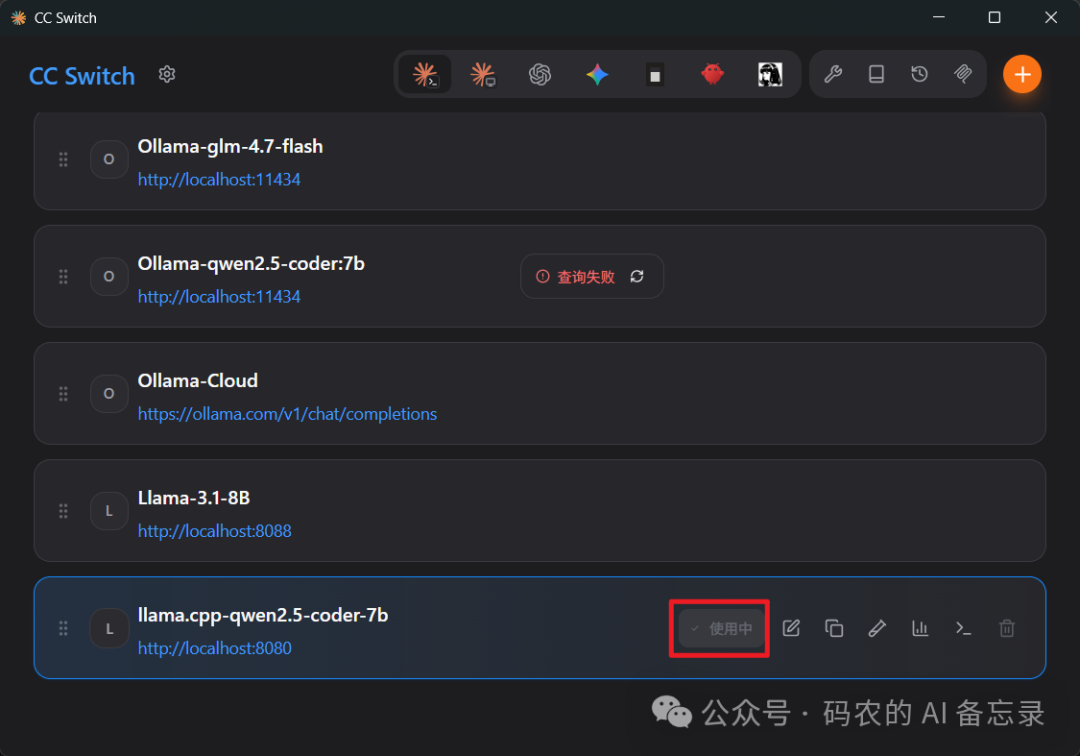
步骤 5:VSCode + Claude Code 测试本地模型
-
打开 VSCode,确保你已经安装了 Claude Code 插件
-
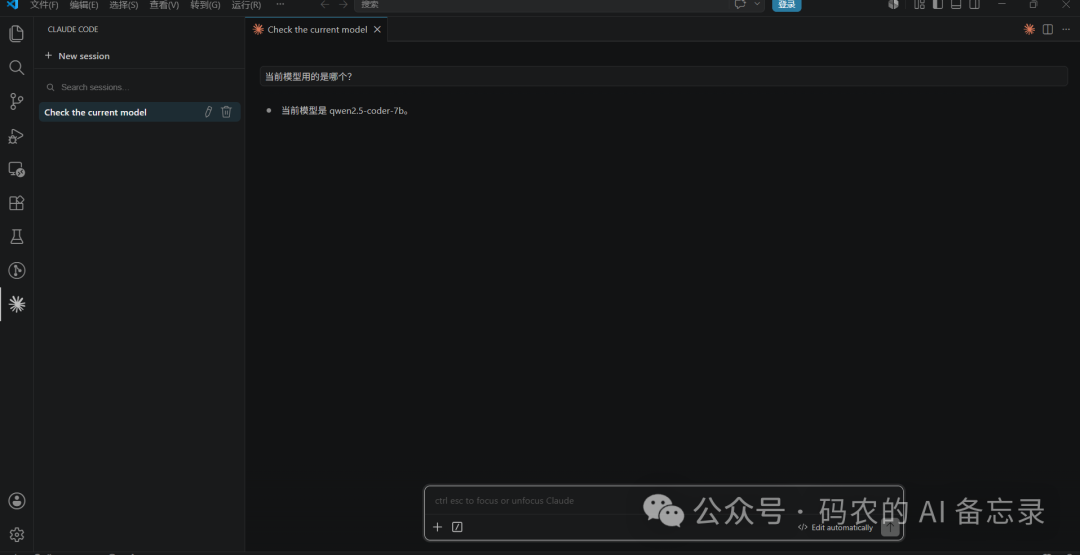
在 Claude Code 的设置里,选择你刚配置好的本地模型
-
然后进行对话测试
三、三套本地AI编程方案定位区分
🥇 Ollama方案(第一篇):纯小白专属,零配置、一键部署,适合新手入门、轻度编码
🥈 llama.cpp方案(本篇):低配显存专属,性能更强、资源更省,适合个人日常开发、老旧设备盘活
🥉 vLLM方案(下篇预告):生产级高性能,高并发、低延迟,适合服务器部署、团队协作、项目量产开发

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐

 4
4 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)