
Llama Factory入门指南:零基础学会微调LLaMA、Qwen等主流模型
本文介绍了如何在星图GPU平台上自动化部署Llama Factory镜像,实现主流大模型的零代码微调。该平台简化了部署流程,用户可快速搭建微调环境。Llama Factory作为一个一站式工具箱,其核心应用场景是让用户通过可视化界面,轻松为LLaMA、Qwen等模型注入领域知识,从而定制专属的AI助手,如客服机器人或写作助手。
Llama Factory入门指南:零基础学会微调LLaMA、Qwen等主流模型
1. 前言
想自己动手训练一个能理解你业务、回答你专业问题的大模型吗?是不是觉得大模型微调听起来特别复杂,需要写很多代码、懂很多底层原理?
其实,现在有个工具能让这件事变得像用手机App一样简单。
今天要介绍的Llama Factory,就是一个让你不用写一行代码,就能在本地电脑上微调各种主流大模型的神器。无论是阿里的Qwen、Meta的LLaMA,还是智谱的ChatGLM,它都能轻松支持。
你可能听说过微调大模型需要很高的技术门槛,但Llama Factory把这个过程彻底简化了。它提供了一个清晰的可视化界面,你只需要点点鼠标、上传数据,就能完成从数据准备到模型训练的全过程。
最让人惊喜的是,就在Llama-3发布三天后,Llama Factory就宣布支持了。这种对新模型的快速兼容能力,意味着你总能用到最新、最好的模型。
下面这张图展示了Llama Factory强大的模型兼容性:
无论你是想做个能回答专业问题的客服助手,还是想训练一个懂你行业的写作助手,Llama Factory都能帮你实现。接下来,我就带你从零开始,一步步学会怎么用这个工具。
2. Llama Factory是什么?
2.1 核心功能一览
简单来说,Llama Factory是一个大模型训练和微调的“一站式工具箱”。它把那些复杂的命令行操作、繁琐的配置过程,全都包装成了简单易懂的界面和选项。
想象一下,以前你要微调一个模型,可能需要:
- 学习复杂的Python代码
- 理解各种训练参数的含义
- 处理令人头疼的环境配置问题
- 调试各种莫名其妙的错误
现在有了Llama Factory,这些都不需要了。它主要提供这些功能:
可视化操作界面 所有操作都在网页上完成,像用办公软件一样简单。上传数据、选择模型、设置参数,点点鼠标就行。
支持多种训练方式
- 全参数微调:调整模型的所有参数,效果最好,但需要更多计算资源
- 高效微调(LoRA/QLoRA):只调整一小部分参数,节省资源,效果也不错
- 多种训练任务:不仅支持监督微调,还支持强化学习等高级训练方式
广泛的模型兼容 从几亿参数的小模型,到上千亿参数的巨无霸,它都能支持。特别是对中文模型的支持很友好,比如阿里的Qwen系列、智谱的ChatGLM系列。
2.2 为什么选择Llama Factory?
你可能会有疑问:市面上微调工具也不少,为什么选Llama Factory?
我根据自己的使用经验,总结了几个关键理由:
对新模型支持快 就像前面提到的,Llama-3发布三天就支持了。这意味着你不用担心工具落后于技术发展。
中文社区友好 很多教程、文档都有中文版本,遇到问题在中文社区更容易找到解决方案。
资源要求相对灵活 虽然大模型训练确实需要一定的显卡资源,但Llama Factory支持QLoRA等高效微调方法,让8GB显存的显卡也能训练70亿参数的模型。
完全开源免费 不用担心授权费用,所有功能都可以免费使用,代码完全开放。
3. 快速开始:环境准备
3.1 基础环境要求
在开始之前,我们先看看需要准备什么。其实要求并不高:
硬件要求
- 显卡:至少8GB显存(推荐12GB以上)
- 内存:16GB以上
- 硬盘:至少50GB可用空间(用于存放模型和数据)
软件环境
- 操作系统:Linux(推荐Ubuntu 20.04+)或Windows
- Python:3.8及以上版本
- CUDA:11.8及以上(如果你用NVIDIA显卡)
我是在CentOS 7 + CUDA 12.2 + Python 3.10的环境下测试的,整个过程很顺利。
3.2 安装步骤详解
创建Python虚拟环境
首先,我们需要创建一个独立的Python环境。这样能避免不同项目之间的依赖冲突。
如果你还没有安装Anaconda,可以从清华大学开源软件镜像站下载:
# 下载Anaconda安装包
wget https://repo.anaconda.com/archive/Anaconda3-2023.03-1-Linux-x86_64.sh
# 运行安装脚本
bash Anaconda3-2023.03-1-Linux-x86_64.sh
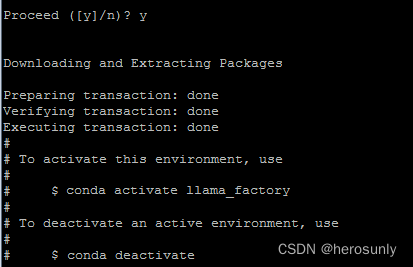
安装过程中,系统会问你是否要初始化Anaconda,记得输入yes:

安装完成后,创建一个专门用于Llama Factory的虚拟环境:
# 创建名为llama_factory的虚拟环境,指定Python版本为3.10
conda create -n llama_factory python=3.10
你会看到类似这样的输出,输入y确认:
安装Llama Factory
激活刚创建的环境,然后下载Llama Factory的源代码:
# 激活虚拟环境
conda activate llama_factory
# 下载Llama Factory源码
git clone https://github.com/hiyouga/LLaMA-Factory.git
如果下载速度慢,可以试试这个镜像地址:
git clone https://hub.yzuu.cf/hiyouga/LLaMA-Factory.git
进入项目目录,安装所有必需的依赖:
cd LLaMA-Factory/
pip install -r requirements.txt
这个过程可能需要几分钟,取决于你的网络速度。看到Successfully installed就说明安装成功了。
4. 准备你的第一个微调任务
4.1 选择适合的模型
模型选择是个技术活,但我们可以用一些简单原则来决策:
根据任务复杂度选择
- 简单任务(如文本分类、基础问答):选择7B(70亿)参数左右的模型
- 中等任务(如文档总结、代码生成):选择13B-32B参数的模型
- 复杂任务(如逻辑推理、创意写作):选择70B及以上参数的模型
根据资源情况选择
- 显存8GB:建议用Qwen1.5-7B或LLaMA-7B
- 显存16GB:可以尝试Qwen1.5-14B
- 显存24GB以上:可以考虑Qwen1.5-32B或更大模型
根据语言需求选择
- 主要用中文:优先选择Qwen、ChatGLM、Yi等中文优化模型
- 中英文混合:LLaMA系列表现不错
- 主要用英文:LLaMA、Mistral都是好选择
我长期测试发现,阿里的Qwen系列在中文任务上表现很出色,所以本文以Qwen1.5-7B-Chat为例进行演示。这个模型在7B参数级别中,中文理解能力数一数二,而且对资源要求相对友好。
4.2 下载模型文件
模型文件比较大,我们需要提前下载好。这里我提供一个自动下载脚本,可以帮你批量下载所有需要的文件。
首先,在你想要存放模型的目录下(比如/home/models/),创建一个下载脚本:
# 保存为 download_model.py
import os
import re
import time
import requests
from urllib.parse import urljoin
def download_qwen_model():
# 设置模型保存路径
model_path = '/home/models/Qwen1.5-7B-Chat'
# 如果目录不存在就创建
if not os.path.exists(model_path):
os.makedirs(model_path)
# 使用国内镜像加速下载
base_url = 'https://hf-mirror.com/Qwen/Qwen1.5-7B-Chat/tree/main/'
# 获取文件列表
response = requests.get(base_url)
file_urls = re.findall('download href="(.*?)"', response.text)
# 保存下载链接到文件
with open('download_list.txt', 'w') as f:
for url in file_urls:
full_url = 'https://hf-mirror.com' + url
f.write(full_url + '\n')
# 使用aria2多线程下载(如果没安装,先运行:sudo apt install aria2)
download_cmd = f'aria2c -c -d {model_path} -x 16 -j 3 -i download_list.txt'
os.system(download_cmd)
print(f"模型已下载到: {model_path}")
if __name__ == '__main__':
download_qwen_model()
运行这个脚本:
# 在后台运行下载任务
nohup python download_model.py > download.log &
下载过程可能需要一些时间,具体取决于你的网络速度。7B的模型大概需要15-20GB的磁盘空间。
4.3 准备训练数据
数据是微调成功的关键。Llama Factory支持多种数据格式,最常用的是JSON格式。
假设你有一个Excel文件,里面是问答对数据,格式如下:
| 问题 | 答案 |
|---|---|
| 什么是机器学习? | 机器学习是... |
| Python怎么安装? | 安装Python的步骤是... |
我们可以用Python脚本把它转换成Llama Factory需要的格式:
import pandas as pd
import json
def excel_to_llama_format(input_file, output_file):
"""
将Excel问答数据转换为Llama Factory训练格式
参数:
input_file: 输入的Excel文件路径
output_file: 输出的JSON文件路径
"""
# 读取Excel文件(支持多个sheet)
excel_data = pd.read_excel(input_file, sheet_name=None)
# 合并所有sheet的数据
all_data = pd.concat(excel_data.values(), ignore_index=True)
# 重命名列,符合Llama Factory格式要求
# instruction: 指令/问题
# input: 输入(可以为空)
# output: 输出/答案
all_data = all_data.rename(columns={
'问题': 'instruction',
'答案': 'output'
})
# 添加input列(如果没有额外输入,就留空)
all_data.insert(1, 'input', "")
# 只保留需要的列
all_data = all_data[['instruction', 'input', 'output']]
# 转换为字典列表
data_list = all_data.to_dict(orient='records')
# 保存为JSON文件
with open(output_file, 'w', encoding='utf-8') as f:
json.dump(data_list, f, ensure_ascii=False, indent=2)
print(f"数据转换完成,共{len(data_list)}条数据")
print(f"已保存到: {output_file}")
# 使用示例
excel_to_llama_format('我的问答数据.xlsx', 'train_data.json')
转换后的数据格式是这样的:
[
{
"instruction": "什么是机器学习?",
"input": "",
"output": "机器学习是人工智能的一个分支,让计算机从数据中学习规律..."
},
{
"instruction": "Python怎么安装?",
"input": "",
"output": "安装Python的步骤是:1. 访问官网下载安装包 2. 运行安装程序..."
}
]
数据准备小贴士:
- 数据量:至少准备100-200条高质量数据,效果会比较好
- 数据质量:确保问答对准确、无错误
- 数据多样性:覆盖你希望模型学会的各种问题类型
- 格式检查:转换后打开JSON文件看看,确保格式正确
5. 开始微调:可视化操作指南
5.1 启动Web界面
Llama Factory最方便的地方就是它的Web界面。启动方法很简单:
# 确保在Llama Factory项目目录下
cd LLaMA-Factory
# 启动Web服务
python src/web_demo.py
启动成功后,你会看到类似这样的输出:
Running on local URL: http://127.0.0.1:7860
在浏览器中打开这个地址,就能看到Llama Factory的界面了。
5.2 界面功能详解
第一次打开界面,你可能会觉得选项有点多。别担心,我带你一个个看:
主界面布局
- 左侧菜单:训练、评估、推理等主要功能
- 中间区域:当前功能的配置选项
- 右侧区域:日志输出和状态显示
关键配置选项
-
模型选择
- 点击"模型路径",选择你下载的模型位置(比如
/home/models/Qwen1.5-7B-Chat) - 模板选择:Qwen系列选
qwen,LLaMA系列选llama或llama2
- 点击"模型路径",选择你下载的模型位置(比如
-
训练数据设置
- 数据集路径:选择你准备好的JSON文件
- 验证集比例:一般留10%-20%的数据用于验证
-
训练参数配置
- 微调类型:推荐新手用
LoRA,节省显存 - 学习率:可以从
5e-5开始尝试 - 训练轮数:3-5轮通常就够了
- 批处理大小:根据显存调整,8GB显存可以设2-4
- 微调类型:推荐新手用
-
输出设置
- 输出目录:设置一个文件夹保存训练结果
- 保存步骤:每多少步保存一次检查点
5.3 开始训练
配置好所有选项后,点击"开始训练"按钮。你会看到右侧的日志区域开始滚动信息:
开始加载模型...
模型加载完成,开始准备数据...
数据准备完成,开始训练...
Epoch 1/3: 10%|██████▏ | 100/1000 [00:30<04:30, 3.33it/s]
Loss: 2.3456
训练过程中,你可以观察损失值(Loss)的变化:
- 正常情况:Loss值会逐渐下降
- 如果Loss波动很大:可能是学习率太高了
- 如果Loss基本不变:可能是学习率太低了
训练时间取决于数据量和模型大小。对于Qwen1.5-7B和1000条数据,大概需要1-2小时。
6. 命令行微调方法
虽然Web界面很方便,但有些高级用户可能更喜欢命令行方式。Llama Factory也提供了完整的命令行支持。
6.1 基础训练命令
这是最常用的训练命令模板:
CUDA_VISIBLE_DEVICES=0 python src/train.py \
--stage sft \ # 训练阶段:监督微调
--do_train \ # 执行训练
--model_name_or_path /home/models/Qwen1.5-7B-Chat \ # 模型路径
--dataset sft_data \ # 数据集名称
--template qwen \ # 模板类型
--finetuning_type lora \ # 微调类型:LoRA
--lora_target all \ # LoRA目标:所有层
--output_dir ./output/qwen_lora \ # 输出目录
--overwrite_cache \ # 覆盖缓存
--per_device_train_batch_size 4 \ # 每个设备的批大小
--gradient_accumulation_steps 1 \ # 梯度累积步数
--lr_scheduler_type cosine \ # 学习率调度器类型
--logging_steps 10 \ # 每10步记录一次日志
--save_steps 500 \ # 每500步保存一次
--learning_rate 5e-5 \ # 学习率
--num_train_epochs 3.0 \ # 训练轮数
--plot_loss \ # 绘制损失曲线
--fp16 # 使用半精度浮点数
参数解释:
per_device_train_batch_size:一次训练多少条数据。如果显存不够,可以调小这个值gradient_accumulation_steps:梯度累积步数。如果批大小设小了,可以用这个参数累积梯度learning_rate:学习率。一般从5e-5开始尝试,如果训练不稳定可以调小num_train_epochs:训练轮数。数据少可以多训几轮,数据多可以少训几轮
6.2 常见问题解决
问题1:显存不足(OOM)
# 解决方案:减小批大小,使用梯度累积
--per_device_train_batch_size 1 \
--gradient_accumulation_steps 4
问题2:训练速度太慢
# 解决方案:使用更高效的优化器,调整学习率
--optim adamw_8bit \ # 使用8位优化器
--learning_rate 1e-4 \ # 适当提高学习率
--max_grad_norm 0.3 \ # 梯度裁剪
问题3:过拟合(训练集Loss下降,验证集Loss上升)
# 解决方案:增加正则化,早停
--weight_decay 0.01 \ # 权重衰减
--early_stopping_patience 3 \ # 早停耐心值
6.3 训练监控和评估
训练过程中,你可以实时监控进度:
# 查看训练日志
tail -f train.log
# 查看GPU使用情况
nvidia-smi
# 查看损失曲线(如果开启了plot_loss)
# 训练结束后会在输出目录生成loss.png
训练完成后,评估模型效果:
python src/evaluate.py \
--model_name_or_path /home/models/Qwen1.5-7B-Chat \
--adapter_name_or_path ./output/qwen_lora \
--template qwen \
--task mmlu \ # 评估任务,可以是你的自定义任务
--split test
7. 使用微调后的模型
7.1 三种使用方式
训练好的模型有三种使用方式,适合不同场景:
方式一:命令行对话(最简单)
创建一个配置文件inference_config.yaml:
# inference_config.yaml
model_name_or_path: /home/models/Qwen1.5-7B-Chat
adapter_name_or_path: ./output/qwen_lora
template: qwen
finetuning_type: lora
然后启动对话:
llamafactory-cli chat inference_config.yaml
你会进入一个交互式对话界面,可以直接和模型聊天。
方式二:Web界面(最直观)
使用和训练时类似的Web界面:
python src/web_demo.py \
--model_name_or_path /home/models/Qwen1.5-7B-Chat \
--adapter_name_or_path ./output/qwen_lora \
--template qwen \
--finetuning_type lora
在浏览器中打开界面,就可以像用ChatGPT一样和模型对话了。
方式三:API服务(最灵活)
启动一个类似OpenAI的API服务:
llamafactory-cli api inference_config.yaml \
--port 8000 \
--api_prefix /v1
这样你就可以用HTTP请求调用模型了:
import requests
response = requests.post(
"http://localhost:8000/v1/chat/completions",
json={
"model": "qwen-7b",
"messages": [
{"role": "user", "content": "你好,请介绍一下机器学习"}
]
}
)
print(response.json()["choices"][0]["message"]["content"])
7.2 实际应用示例
假设我们微调了一个客服助手模型,下面看看怎么在实际中使用:
场景一:集成到现有系统
class CustomerServiceBot:
def __init__(self, model_config):
self.model_api = "http://localhost:8000/v1/chat/completions"
def answer_question(self, question, context=""):
"""回答客户问题"""
prompt = f"你是客服助手,请回答以下问题:{question}"
if context:
prompt += f"\n相关上下文:{context}"
response = requests.post(
self.model_api,
json={
"model": "customer-service",
"messages": [{"role": "user", "content": prompt}],
"temperature": 0.7, # 控制创造性
"max_tokens": 500 # 最大生成长度
}
)
return response.json()["choices"][0]["message"]["content"]
场景二:批量处理任务
def batch_process_questions(questions_file, output_file):
"""批量处理问题文件"""
with open(questions_file, 'r', encoding='utf-8') as f:
questions = [line.strip() for line in f if line.strip()]
results = []
for question in questions:
answer = get_model_answer(question)
results.append(f"Q: {question}\nA: {answer}\n")
with open(output_file, 'w', encoding='utf-8') as f:
f.writelines(results)
8. 进阶技巧和最佳实践
8.1 数据质量决定模型质量
高质量数据的特征:
- 问题明确,没有歧义
- 答案准确,信息完整
- 覆盖各种场景和问题类型
- 格式统一,便于处理
数据增强技巧:
def augment_training_data(original_data):
"""数据增强:通过改写生成更多训练数据"""
augmented_data = []
for item in original_data:
# 原数据
augmented_data.append(item)
# 改写问题(同义句替换)
question = item['instruction']
augmented_question = synonym_replace(question)
if augmented_question != question:
new_item = item.copy()
new_item['instruction'] = augmented_question
augmented_data.append(new_item)
# 添加相关上下文
if not item['input']:
context = generate_context(question)
new_item = item.copy()
new_item['input'] = context
augmented_data.append(new_item)
return augmented_data
8.2 参数调优指南
学习率设置:
- 全参数微调:1e-5 到 5e-5
- LoRA微调:1e-4 到 5e-4
- QLoRA微调:2e-4 到 1e-3
批大小选择:
# 根据显存自动选择批大小
def auto_batch_size(available_vram_gb):
"""根据可用显存推荐批大小"""
if available_vram_gb < 8:
return 1 # 小批大小,配合梯度累积
elif available_vram_gb < 16:
return 2
elif available_vram_gb < 24:
return 4
else:
return 8
训练轮数建议:
- 小数据集(<1000条):5-10轮
- 中等数据集(1000-5000条):3-5轮
- 大数据集(>5000条):1-3轮
8.3 模型评估和迭代
训练完成后,如何知道模型效果好不好?
人工评估:
def manual_evaluation(model, test_questions):
"""人工评估模型回答质量"""
evaluation_results = []
for question in test_questions:
answer = model.generate(question)
# 从多个维度评分(1-5分)
scores = {
"相关性": rate_relevance(question, answer),
"准确性": rate_accuracy(answer),
"完整性": rate_completeness(answer),
"流畅性": rate_fluency(answer)
}
evaluation_results.append({
"question": question,
"answer": answer,
"scores": scores
})
return evaluation_results
自动评估:
# 使用标准评测集
python src/evaluate.py \
--model_name_or_path ./output/qwen_lora \
--task ceval \ # 中文评测集
--split test
# 自定义评测
python src/evaluate.py \
--model_name_or_path ./output/qwen_lora \
--eval_file my_eval_data.json \ # 自定义评测数据
--metrics accuracy,bleu,rouge
9. 总结
通过这篇指南,你应该已经掌握了使用Llama Factory微调大模型的基本流程。让我们回顾一下关键要点:
核心收获
- 零代码入门:Llama Factory让大模型微调变得像用普通软件一样简单,不需要深厚的编程基础
- 广泛兼容:支持LLaMA、Qwen、ChatGLM等主流模型,总能找到适合你需求的模型
- 资源友好:通过LoRA、QLoRA等高效微调技术,让普通显卡也能训练大模型
- 完整流程:从数据准备、模型训练到效果评估,提供一站式解决方案
给新手的建议
- 从小开始:先用小模型(如Qwen1.5-7B)和小数据集练手
- 重视数据:花时间准备高质量的训练数据,这是成功的关键
- 耐心调参:学习率、批大小等参数需要根据实际情况调整
- 多次迭代:微调很少一次成功,需要多次尝试和优化
下一步学习方向
- 尝试不同的微调方法(全参数微调 vs LoRA)
- 探索更多模型(从7B到70B,感受规模带来的差异)
- 学习提示工程,进一步提升模型效果
- 将微调好的模型部署到生产环境
大模型微调不再是只有大公司才能玩转的技术。有了Llama Factory这样的工具,每个人都可以根据自己的需求定制专属的AI助手。无论是做客服机器人、写作助手,还是专业领域的问答系统,现在都可以轻松实现。
最重要的是开始动手尝试。选一个你感兴趣的领域,准备一些数据,跟着本文的步骤操作一遍。遇到问题不用怕,Llama Factory有活跃的社区,很多问题都能找到解决方案。
祝你训练出第一个属于自己的大模型!
获取更多AI镜像
想探索更多AI镜像和应用场景?访问 CSDN星图镜像广场,提供丰富的预置镜像,覆盖大模型推理、图像生成、视频生成、模型微调等多个领域,支持一键部署。

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)