
vLLM × ROCm:ROCm 已成为 vLLM 生态的一等支持平台
vLLM × ROCm:ROCm 已成为 vLLM 生态的一等支持平台
作者:Hongxia Yang, Peng Sun, Andy Luo, Tun Jian Tan, Pin Siang Tan, Kenny Roche, Gregory Shtrasberg, Doug Lehr, Simon Mo.

随着生成式AI 生态逐步成熟,vLLM 正在全面拥抱多厂商硬件生态。对开发者来说,无论使用哪家 GPU,都希望获得一致且高性能的推理体验。现在,我们很高兴地宣布:ROCm 现已成为 vLLM 生态的一等支持平台。
这一里程碑来自AMD 与 vLLM 社区多方工程团队的长期协作。大家打破各自为战的孤岛,跨越复杂依赖,一起交付了开发者一直期待的体验:在 AMD GPU 上,vLLM “开箱即用(it just works)”。
本文将分两部分展开:
- 先梳理近期 vLLM 核心版本中的新能力与性能优化;
- 再介绍一系列大幅改善开发者体验的关键节点:从 pip install vllm,到更可靠的上游 CI,再到同时支持 vLLM 与 vLLM-omni 的官方 Docker 镜像。
这些进展共同释放了AMD GPU 在 AI 推理上的全部潜力。

vLLM Core(v0.12.0 与 v0.13.0):新特性与性能优化
回顾近期的vLLM 版本,[vLLM v0.12.0][1] 和 [v0.13.0][2] 在 ROCm 上显著抬高了能力与性能上限。
量化相关:引入多项FP8、FP4 和低比特量化优化,包括:
- 原生 AITER FP8 kernel
- 融合 LayerNorm / SiLU 的 FP8 block 量化
-
Triton ScaledMM 回退路径
-
MXFP4 w4a4 MoE 推理
-
FP8 MLA decode
- 融合 RMSNorm 量化
性能优化:
- 通过优化 KV cache 与汇编实现的 Paged Attention,提升吞吐
- AITER sampling 算子优化
- 移除 DeepSeek MLA 不必要的 D2D 拷贝
- 融合 MoE 二值 mask
fastsafetensors加载优化
新能力:
- 支持 DeepSeek v3.2 + SparseMLA
- 支持 Whisper v1 的 AITER attention
- 支持 sliding window attention
- AITER MLA 的 multi-token prediction
- 支持非 gated 的 MoE 架构
更广的硬件支持:
- 将 bitsandbytes 量化扩展到 warp size 为 32 的 GPU,例如 RDNA 架构的 RX 7900 XTX。
完整细节可参考[v0.12.0 release notes][1] 与 [v0.13.0 release notes][2]。
vLLM Core(v0.14.0):稳定性的新标准
在[vLLM v0.14.0][3]版本中,ROCm 体验进入了一个更加成熟的阶段。社区开始从“补齐支持”转向“前瞻性优化”,重点在:CI 稳定性,官方Docker 镜像,Python wheel 发版和安装路径简化。这些改进让在ROCm 上使用 vLLM 的过程更加简单、快速、可靠。
v0.14.0 中的 ROCm 改进
在vLLM v0.14.0 中,ROCm 带来了多项关键增强 [1]:AITER RMSNorm fusion,AITER MLA 的 MTP 支持,moriio connector,xgrammar 上游集成,多处精度与性能回归修复。
同时,对AMD 开发者和用户影响最大的,是 Docker 与 wheel 构建流水线的完善:
- 更快的构建: 通过[启用 sccache 的 ROCm wheel pipeline][4]显著缩短构建时间。
- 正式发行流水线集成: ROCm 镜像构建已纳入 [vLLM 官方 release pipeline][5]。
更多内容可见[v0.14.0 release notes][3]。
可托付的CI 可靠性
在v0.14.0 发布前的两个月内,贡献者们集中精力修复 AMD CI pipeline 中大量之前失败或被跳过的测试用例,从而显著增强了上游可靠性。
-
2025 年 11 月中旬:AMD CI 中仅有 37% 的vLLM 测试组通过。
-
2026 年 1 月中旬:已有 93% 的vLLM AMD 测试组通过,并进行每日回归维护,目标 100% 近在眼前。
我们在上游vLLM 社区新建了一个 公开项目 [6],方便社区参与 ROCm CI 相关工作。同时,我们正与维护者合作,使 AMD CI 与 vLLM 原生 CI 深度协调,通过上游测试分组 gating 和 label 触发机制,实现更细粒度的管控。
官方Docker 镜像发布
自v0.14.0起,vLLM 提供官方 ROCm Docker 镜像,用于在 AMD GPU 上进行无缝部署。
使用Docker 快速上手
vLLM ROCm OpenAI Docker 镜像已经支持标准的 vllm serve 入口。你只需:拉取 ROCm 镜像,使用适配 AMD 的 docker run 参数运行,即可在 AMD GPU 上快速启动 vLLM 服务。
下图(来源:vLLM 官网 [2])给出了稳定版本 ROCm Docker 的快速启动命令(Stable ROCm Docker Quick Start):
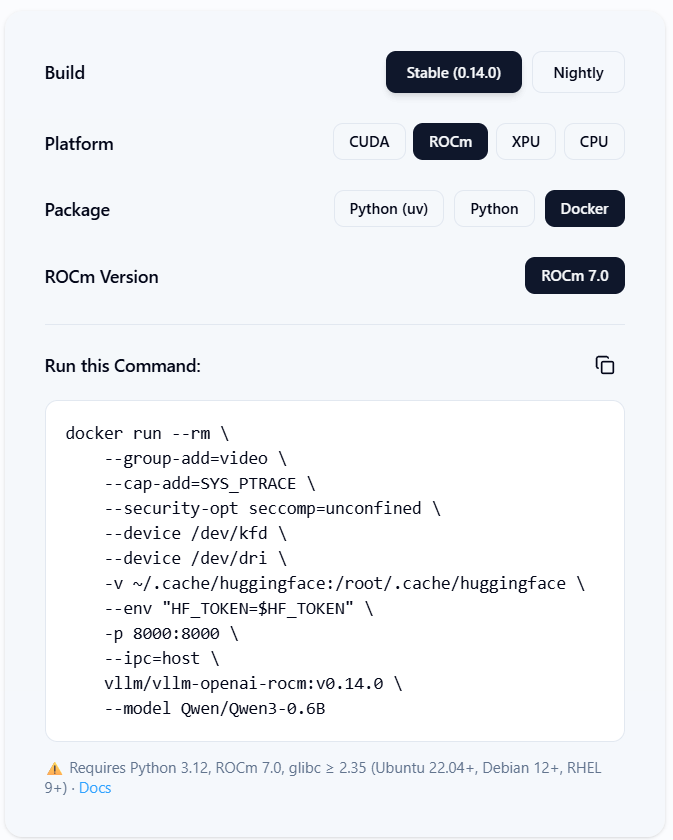
图1:稳定版本 vLLM ROCm Docker 快速启动
docker pull vllm/vllm-openai-rocm:v0.14.0
docker run --rm \--group-add=video \--cap-add=SYS_PTRACE \--security-opt seccomp=unconfined \--device /dev/kfd \--device /dev/dri \-p 8000:8000 \--ipc=host \-e “HF_TOKEN=$HF_TOKEN” \-e VLLM_ROCM_USE_AITER=1 \-v ~/.cache/huggingface:/root/.cache/huggingface \vllm/vllm-openai-rocm:v0.14.0 \--model Qwen/Qwen3-0.6B
使用vLLM wheel 一键安装
得益于ROCm wheel 发版流水线[4],安装 vLLM 已经被大幅简化。下图(来源:vLLM 官网 [2])展示了稳定版本 ROCm wheel 的快速安装方法。
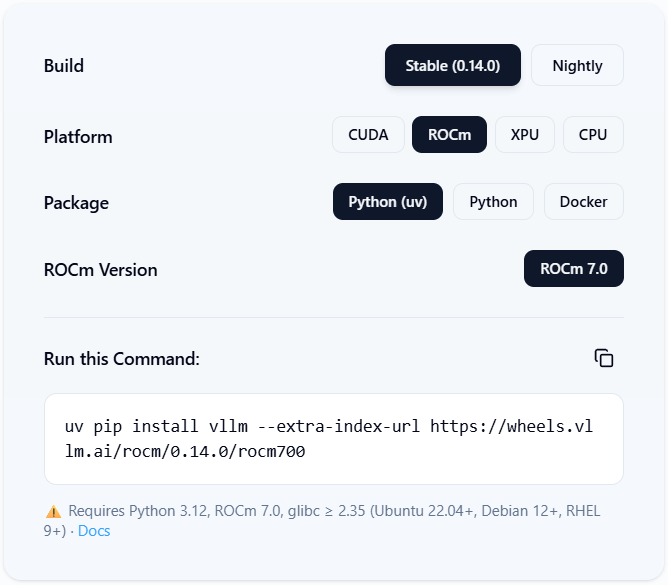
图2:稳定版本 vLLM ROCm wheel 快速安装
uv pip install vllm --extra-index-url https://wheels.vllm.ai/rocm/
该命令将安装最新vLLM 版本的 ROCm wheel,兼容:ROCm 7.0,Python 3.12,glibc ≥ 2.35
如果你希望安装指定的vLLM 版本与 ROCm 变体,可以使用如下 URL 格式:
uv pip install vllm --extra-index-url https://wheels.vllm.ai/rocm/<version>/<rocm-variant>/
示例:
uv pip install vllm --extra-index-url https://wheels.vllm.ai/rocm/0.14.0/rocm700/
这一节点标志着:在vLLM 生态中让 ROCm 成为一等平台的目标已基本实现。从 CUDA 切换到 ROCm 现在变得非常顺滑,用户可以放心地在 AMD GPU 上进行部署。
vLLM-omni:在 AMD 上高性能的全模态服务
vLLM-omni[7] 是 2025 年 11 月推出的一套 “易用、快速、成本友好” 的 omni-modality(全模态)模型服务与推理框架[3]。
在vLLM-omni 发布当天,社区就确保 AMD 用户“首发同享”:vLLM-omni 从一开始就为 AMD ROCm GPU 提供了稳定、可用于生产环境的支持,并将高性能的全模态模型服务带到 AMD 平台。
该框架已经在AMD GPU(gfx942 和 gfx950 架构)上完成充分验证,同时也支持所有 vLLM 已兼容的更广泛 AMD GPU。
Day-0 ROCm 支持
社区在vLLM-omni 上实现了Day-0 ROCm 支持:自2025 年 11 月项目上线那一刻起,就已经可以在 AMD 硬件上直接使用。这种从第一天就考虑多硬件平台的做法,充分体现了 vLLM 生态开放、包容的开源精神。
面向生产的基础设施
- CI 能力:得益于上游协作,专门的ROCm CI pipeline 已于 2025 年 12 月 29 日上线。每一次提交都会在AMD GPU 上运行测试,以防止回归,并为生产部署提供可靠保障。
- 官方Docker 镜像:自2026 年 1 月 6 日起,用户无需再从源码构建。首个官方pre-built ROCm vLLM-omni Docker 镜像已经发布在 Docker Hub 上:
o 镜像位置:Docker Hub(vllm/vllm-omni-rocm [8])
o Tag:vllm/vllm-omni-rocm:v0.12.0rc1
o 版本tag:对应底层vLLM 发布版本(如 v0.12.0rc1)
ROCm 配置
为ROCm 部署定制的配置文件可以开箱即用,在 CI/CD 环境下针对 AMD GPU 做了优化:
vllm_omni/model_executor/stage_configs/rocm/qwen2_5_omni.yamlvllm_omni/model_executor/stage_configs/rocm/qwen3_omni_moe.yaml
ROCm 上的模型支持情况
所有vLLM-omni 模型都已在 ROCm 上支持,包括:
- Qwen2.5-Omni:完整支持多阶段架构(thinker → talker → code2wav)
- Qwen3-Omni-MoE:支持Mixture-of-Experts(MoE)模型的张量并行(tensor parallelism)
- Diffusion 模型:包含文生图(text-to-image)能力
- 多模态模型:完整支持音频、图像、视频与文本的处理链路
支持的输入与输出模态

秒级上手
我们希望你把时间花在做应用上,而不是被环境配置困住。你可以直接拉起官方ROCm vLLM-omni Docker 镜像,立即开始服务模型。
docker pull vllm/vllm-omni-rocm:v0.12.0rc1
docker run --rm \ --group-add=video \ --ipc=host \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --device /dev/kfd \ --device /dev/dri \ -p 8091:8091 \ -e “HF_TOKEN=$HF_TOKEN” \ -v ~/.cache/huggingface:/root/.cache/huggingface \ vllm/vllm-omni-rocm:v0.12.0rc1 \ vllm serve --model Qwen/Qwen3-Omni-30B-A3B-Instruct --omni --port 8091
总结
vLLM 生态已经完成一个关键阶段:AMD ROCm 现已作为一等平台深度集成,在 AMD GPU 上提供一致且高性能的推理体验。这个成果来自 AMD 和 vLLM 社区长时间、深度的工程协作,目标只有一个:为开发者提供顺畅的开源体验。
本文主要回顾了:
-
新增的量化特性与性能优化;
-
扩展的模型能力;
-
以及显著改善易用性的基础设施升级:
o 可直接pip 安装的 wheel;
o 更强的上游 CI 稳定性;
o vLLM 与 vLLM-omni 的官方 Docker 镜像。
这一里程碑建立在vLLM 社区持续优化 AMD 硬件推理性能的工作之上。如果你关心具体部署策略和性能调优实践,可以参考以下相关文章:多模态推理加速(一行配置的优化)[4],MoE 并行策略(TP/DP/PP/Expert Parallelism 指南)[5], vLLM 0.9.x 在 AMD GPU 上的性能调优实践 [6]。
展望未来,我们的工作还在继续,重点方向包括:
- 提升开发体验:提供 nightly Docker 构建与 wheel,支持纯 Python 安装;
- 解锁 vLLM-omni 的 graph-capture 性能潜力;
- 针对 vLLM-omni 的 kernel 进一步优化;
- 将更广泛支持扩展到 AMD Radeon 消费级 GPU。
欢迎参与:如果你有功能需求或想法,可以:在vLLM GitHub Issues[9]中提需求,或在 vLLM Slack[10] 中 @ 我们参与讨论。
致谢
让ROCm 成为 vLLM 生态中的一等平台,是多支团队共同努力的结果。作者在此特别感谢 AMD 合作伙伴:Satya Ramji Ainapurapu、Randall Smith、Alexei Ivanov、Qiang Li、Charlie Fu、Divakar Verma、Andreas Karatzas、Yida Wu、Ryan Rock、Matt Wong、Micah Williamson、Omkar Kakarparthi、Divin Honnappa、Keerthana Bidar,以及更广泛的 ROCm 组织。同时也感谢 Kevin Luu、Roger Wang、Hongsheng Liu、Simon Mo,以及 vLLM 和 vLLM-Omni 的维护者。这个里程碑展示了:当我们在开源社区中协作时,项目可以以多快的速度向前推进。
参考链接
[1]: vLLM v0.12.0 release notes:https://github.com/vllm-project/vllm/releases/tag/v0.12.0
[2]: vLLM v0.13.0 release notes / vLLM Quick start page:https://github.com/vllm-project/vllm/releases/tag/v0.13.0、https://vllm.ai/
[3]: vLLM v0.14.0 release note:https://github.com/vllm-project/vllm/releases/tag/v0.14.0
[4]: ROCm wheel pipeline(sccache):https://github.com/vllm-project/vllm/pull/32264
[5]: ROCm image build release pipeline:https://github.com/vllm-project/vllm/pull/31995
[6]: vLLM ROCm CI 项目板:https://github.com/orgs/vllm-project/projects/39
[7]: vLLM-omni GitHub 仓库:https://github.com/vllm-project/vllm-omni
[8]: vLLM-omni ROCm Docker Hub:https://hub.docker.com/r/vllm/vllm-omni-rocm/tags
[9]: vLLM GitHub Issues:https://github.com/vllm-project/vllm/issues
[10]: vLLM Slack(vllm-dev):https://vllm-dev.slack.com/archives/C084RNJ0VV1
[11]: 多模态推理优化博文:Accelerating Multimodal Inference in vLLM: The One-Line Optimization for Large Multimodal Models https://rocm.blogs.amd.com/
[12]: MoE 并行策略博文:引用《vLLM MOE 调优手册(上下册)》
[13]: vLLM 0.9.x 性能调优博文:Accelerated LLM Inference on AMD GPUs with vLLM 0.9.x and ROCm https://rocm.blogs.amd.com/

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0


 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)