
Qwen 3.6 在 AMD GPU 的 Day 0 支持
相较前代 Qwen3.5-35B-A3B ,它在 agentic 编程与推理任务上获得显著提升。我们很高兴宣布:阿里巴巴最新的Qwen3.6 系列模型,Qwen3.6-35B-A3B 与 Qwen3.6-35B-A3B-FP8,已在 AMD GPU 实现 Day 0 支持。2. 访问ROCm AI 开发者中心: https://www.amd.com/zh-cn/developer/resourc
Qwen 3.6 在 AMD GPU 的 Day 0 支持
原文作者:Andy Luo,Haichen Zhang

我们很高兴宣布:阿里巴巴最新的Qwen3.6 系列模型,Qwen3.6-35B-A3B 与 Qwen3.6-35B-A3B-FP8,已在 AMD GPU 实现 Day 0 支持。本文将基于 AMD ROCm 7.0 与 vLLM 上游优化,提供在 AMD GPU 上部署 Qwen 3.6 模型家族的 Day 0 实操指南。
本指南面向正在构建下一代agentic 工作流的 AI 开发者、系统架构师与 DevOps。通过在 AMD GPU 上支持 Qwen 3.6 家族,开发者可在仅 3B 激活参数下,在几个业界重要的编程基准测试上获得对齐甚至优于 dense 27B 的 Qwen3.5-27B 的表现。同时,这一模型本身具备小尺寸、轻量化的特点,也适合部署在 AMD 本地客户端硬件上,包括 Radeon GPU 和 基于 Strix Halo 的 Ryzen AI Max 平台。相较前代 Qwen3.5-35B-A3B ,它在 agentic 编程与推理任务上获得显著提升。

模型概览
Qwen3.6-35B-A3B 是完全开源的 MoE 模型(总参数 35B / 激活 3B),具备:
- 面向 agentic 编程场景的强大能力,表现可与更大规模模型竞争。
- 较强的多模态感知与推理能力。
其在多任务、多模态的同量级对比评测中显示出良好表现。
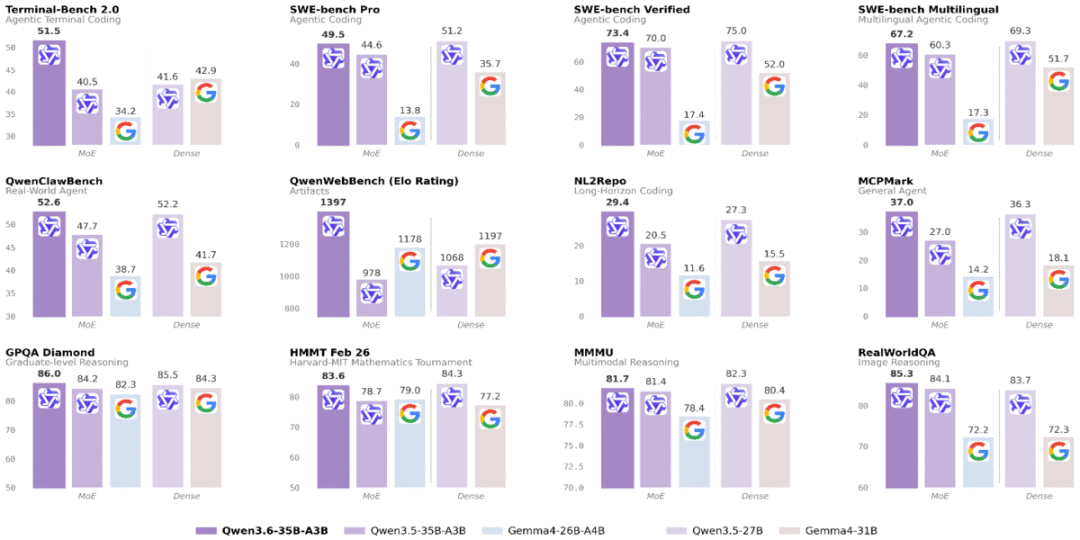
图1:Coding Agent 与推理基准表现
在AMD GPU 上用 vLLM/SGLang 运行 Qwen3.6
ROCm 7 与 vLLM 的集成,充分利用AMD GPU 的 大显存容量。
- 成本优化:单卡即可服务完整上下文(两种精度数据类型均可),满足仓库级编程任务对超长上下文的需求。
- 吞吐优化:通过张量并行(tensor parallelism),在 IDE 实时集成(如 Qwen Code)中获得低时延响应。
开始前,请确保已具备AMD GPU 环境并正确安装 ROCm 驱动。
Step 1. 使用 SGLang 起步
请在AMD GPU 上使用最新的上游预构建 Docker 镜像:
docker run -d -it \ --ipc=host \ --network=host \ --privileged \ --cap-add=CAP_SYS_ADMIN \ --device=/dev/kfd \ --device=/dev/dri \ --device=/dev/mem \ --group-add video \ --cap-add=SYS_PTRACE \ --security-opt seccomp=unconfined \ --shm-size 32G \ -v ~/.cache/huggingface:/root/.cache/huggingface \ -v /:/work \ --entrypoint "/bin/bash" \ --name qwen3.6 \lmsysorg/sglang-rocm:v0.5.10rc0-rocm720-mi35x-20260414
部分型号需要使用以下镜像:
lmsysorg/sglang:v0.5.10-rocm720-mi30x
Step 2. 启动 SGLang 服务
单卡部署:
sglang serve --model-path Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 1 \ --enable-flashinfer-allreduce-fusion \ --attention-backend triton \ --mem-fraction-static 0.8 \ --disable-radix-cache \--trust-remote-code
多卡部署:
sglang serve \ --model-path Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 4 \ --ep-size 1 \ --trust-remote-code \--enable-aiter-allreduce-fusion \ --attention-backend triton \ --disable-radix-cache \ --mem-fraction-static 0.8
启用MTP:
sglang serve \ --model-path Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 4 \ --ep-size 1 \ --trust-remote-code \ --speculative-algorithm EAGLE \ --speculative-num-steps 3 \ --speculative-eagle-topk 1 \ --speculative-num-draft-tokens 4 \--enable-aiter-allreduce-fusion \ --attention-backend triton \ --disable-radix-cache \ --mem-fraction-static 0.8
Step 3. Chat Completions API
curl http://localhost:8888/v1/chat/completions \ -H "Content-Type: application/json" \ -d '{ "model": "Qwen/Qwen3.6-35B-A3B", "messages": [ {"role": "user", "content": "Write a Python function to calculate fibonacci numbers"} ], "max_tokens": 512, "temperature": 0.7 }'
服务启动成功后,可见类似如下输出:
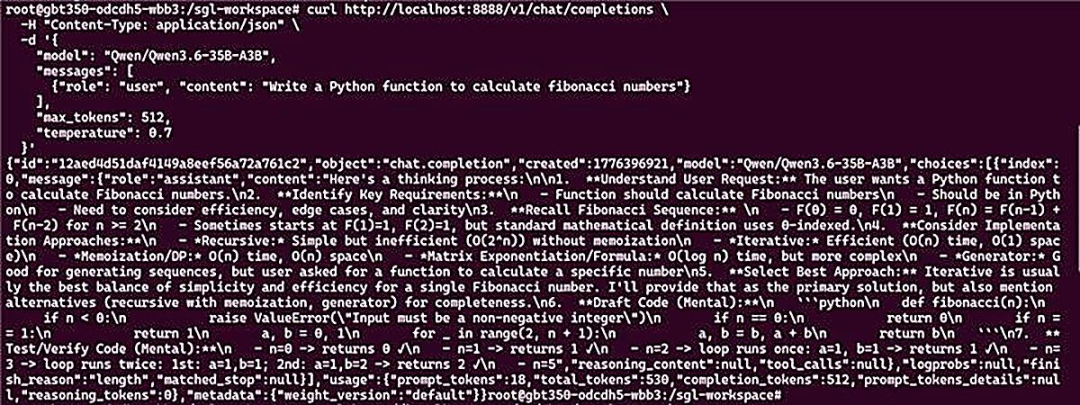
图2:服务输出
Step 1. 使用 vLLM 起步
请使用最新的vLLM 上游预构建镜像:
docker run -d -it --ipc=host --network=host --privileged --cap-add=CAP_SYS_ADMIN --device=/dev/kfd --device=/dev/dri --device=/dev/mem --group-add video --cap-add=SYS_PTRACE --security-opt seccomp=unconfined --shm-size 32G -v ~/.cache/huggingface:/root/.cache/huggingface -v /:/work --entrypoint "/bin/bash" --name qwen3.6 vllm/vllm-openai-rocm:latest
Step 2. 启动 vLLM 服务
单卡部署:
vllm serve Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3
多卡部署:
vllm serve Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3
启用MTP:
vllm serve Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --speculative-config '{"method": "mtp", "num_speculative_tokens": 2}'
Qwen Code 部署与体验
本节演示如何在本地通过SGLang 部署Qwen3.6模型服务,并使用 Qwen Code 进行代码交互工作。
图3:Qwen Code 部署
Step 1. 安装 node.js
vllm serve Qwen/Qwen3.6-35B-A3B \ --tensor-parallel-size 8 \ --max-model-len 262144 \ --reasoning-parser qwen3 \ --speculative-config '{"method": "mtp", "num_speculative_tokens": 2}'
Step 2. 安装 Qwen Code
```bash# Install Qwen Codenpm install -g @qwen-code/qwen-code@latest#verifyqwen --version```
Step 3. 启动 Qwen Code
Step 1:设置OpenAI API 环境变量,并在AMD GPU 上本地指向前述服务
```bashexport OPENAI_API_KEY="EMPTY"export OPENAI_BASE_URL="http://localhost:8888/v1"export OPENAI_MODEL=" Qwen/Qwen3.6-35B-A3B "```
Step 2:启动Qwen Code
```bashqwen```
若一切正常,将出现本地界面:
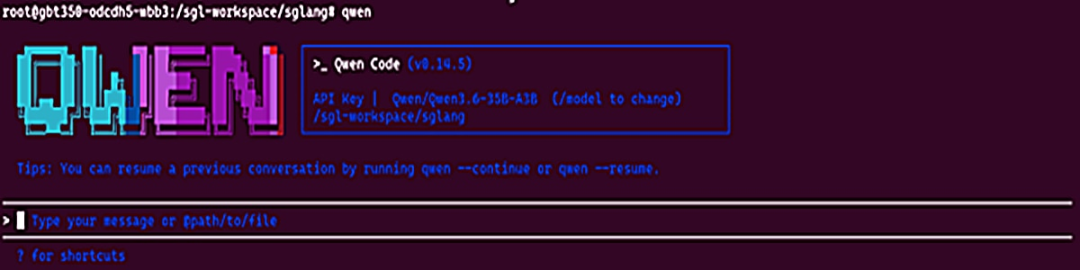
图4:Qwen Code 界面
Step 3:与Qwen Code Agent 交互
示例问题:

回答示例:
总结
本文展示了Qwen3.6 模型家族在 AMD GPU 上的 Day 0 支持。你可以使用 vLLM/SGLang 快速完成部署,并结合面向 agentic 任务的专用解析器,进一步通过 Qwen3.6-35B-A3B在本地跑通Qwen Code。
这项支持让团队能够即刻在最新AMD 硬件上构建稳健的、由智能体驱动的编码平台。后续我们将继续分享更深入的内核级分析、定制 attention 实现,以及 AMD ROCm 软件栈与 Qwen 模型优化的协同进展。
致谢
参与本次工作的AMD 团队成员:Andy Luo、Haichen Zhang、FangChun、Chang Liu、Bingqing Guo、Yi Gan、Hattie Wu、Tun Jian,以及 Qwen 团队。
更多资源
1. 加入AMD开发者计划: https://www.amd.com/en/developer/ai-dev-program.html,获取开发者云资源、专家支持、培训与社区。
2. 访问ROCm AI 开发者中心: https://www.amd.com/zh-cn/developer/resources/rocm-hub/dev-ai.html,查看更多教程、开源项目与技术博客。
-
AMD ROCm 软件: https://www.amd.com/zh-cn/products/software/rocm.html
-
AMD GPUs: https://www.amd.com/zh-cn/products/accelerators/instinct.html
5. 模型与代码下载:
-千问3.6-35B-A3B(Modelscope): https://modelscope.cn/models/Qwen/Qwen3.6-35B-A3B
- QwenLM/Qwen3.6(GitHub): https://github.com/QwenLM/Qwen3.6

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0


 已为社区贡献17条内容
已为社区贡献17条内容

所有评论(0)