
在本地运行万亿参数LLM:基于AMD Ryzen AI Max+ 的集群实战指南
在本地运行万亿参数LLM:基于AMD Ryzen AI Max+ 的集群实战指南
原文作者:Abdullah Malik, AMD Custom Software Engineering

01
引言
本文演示如何基于AMD Ryzen AI Max+ AI PC 平台,搭建一个小型分布式推理集群,并通过 llama.cpp 的 RPC 能力本地运行“一万亿参数级”的大语言模型(LLM)。
我们采用四台Framework Desktop 组成的集群,在本地分布式推理开源模型 Kimi K2.5。Kimi K2.5 是 Moonshot AI 的开放推理模型,重点面向代码、长程推理、以及 agent 工作流,同时原生支持多模态(文本、图像、视频)。
文章覆盖从系统和驱动配置、在ROCm 上构建 llama.cpp,到最终跨四台机器编排多节点推理的完整流程,使四台机器像一个“逻辑上的统一 AI 加速器”来使用。

02
配置详情

03
技术设置
以下步骤需在每台Ryzen AI Max+ 系统上执行。
通过 TTM 扩展 VRAM 分配
3a
注意
在继续之前,请在 BIOS 中将 iGPU Memory Size 设为512MB
对于Framework Desktop Ryzen AI Max+ 395 128GB 的配置,系统 BIOS 中每个节点最多可设置 96GB 作为专用 VRAM(四节点合计 384GB)。
在Linux 中,我们可以利用内核的 Translation Table Manager(TTM)[2] 参数,将每节点的 VRAM 最大分配提升至 120GB(四节点合计 480GB)。通过以下命令修改内核参数并重启系统:
sudo nano /etc/default/grub
找到如下行:
GRUB_CMDLINE_LINUX_DEFAULT=
在引号内追加以下参数:
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash ttm.pages_limit=30720000 amdgpu.gttsize=120000"
保存并退出(Ctrl+O,Enter,Ctrl+X),然后更新并重启:
sudo update-grubsudo reboot
注意
TTM 的限制以 4KB 页计。计算公式:
([size in GB] * 1024 * 1024) / 4.096
例如 120GB:
(120 * 1024 * 1024) / 4.096 = 30720000
系统重启后,可用如下命令验证AMD GPU 驱动是否已按 120GB 配置成功:
$ sudo dmesg | grep "amdgpu.*memory"[drm] amdgpu: 512M of VRAM memory ready[drm] amdgpu: 120000M of GTT memory ready.
选项 1:推荐设置(Lemonade SDK)
3b
为获得“即用型”的最简体验,建议使用 Lemonade SDK 提供的预编译二进制。Lemonade SDK 项目提供集成 AMD ROCm 7 加速的 llama.cpp 夜构版本,支持包括 gfx1151(Strix Halo / Ryzen AI Max+ 395)在内的近期 Radeon 架构。
安装步骤:访问最新发布页面Lemonade SDK [3],在 Release 资产中下载与你平台和 GPU 目标匹配的压缩包,例如:
- llama-bxxxx-ubuntu-rocm-gfx1151-x64.zip
下载后,解压并准备可执行文件:
unzip llama-bxxxx-ubuntu-rocm-gfx1151-x64.zipcd llama-bxxxx-ubuntu-rocm-gfx1151-x64chmod +x llama-cli llama-server rpc-server
该目录包含已为Ryzen AI Max+ 预编译的 ROCm 版本 llama-cli、llama-server 和rpc-server。要验证llama.cpp 是否正确使用 Radeon GPU,可执行llama-cli 二进制:
$ ./llama-cli --list-devicesggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx1151 (0x1151), VMM: no, Wave Size: 32Available devices:ggml_backend_cuda_get_available_uma_memory: final available_memory_kb: 127697544 ROCm0: AMD Radeon Graphics (120000 MiB, 124704 MiB free)
每个节点准备完成后,继续第4 步“推理方案,配置RPC 端点并在集群上启动 Kimi K2.5。
选项 2:手动设置(源码构建)
3c
1-安装 ROCm 7.0.2
开始前,请确认你的kernel version [8] 与 ROCm system requirements [9] 支持的发行版匹配。更详细安装说明参见 ROCm on Linux detailed installation overview [10]。
Ubuntu 24.04.3 安装 ROCm 7.0.2:
wget https://repo.radeon.com/amdgpu-install/7.0.2/ubuntu/noble/amdgpu-install_7.0.2.70002-1_all.debsudo apt install ./amdgpu-install_7.0.2.70002-1_all.debsudo apt updatesudo apt install python3-setuptools python3-wheelsudo usermod -a -G render,video $LOGNAME # Add the current user to the render and video groupssudo apt install rocm
export PATH=$PATH:/opt/rocm-7.0.2/binexport LD_LIBRARY_PATH=/opt/rocm-7.0.2/lib
重启系统以应用所有设置。安装完成后,请查看Post-installation instructions [11]。如遇安装问题,请参考 Troubleshooting [12]。
2-构建 llama.cpp
前置依赖
Git、CMake
我们可以通过git克隆并进入llama.cpp仓库,步骤如下:
git clone https://github.com/ggml-org/llama.cppcd llama.cpp
在Ryzen AI Max+ 395 系统上使用如下构建参数:
cmake -B rocm -DGGML_HIP=ON -DGGML_RPC=ON -DGGML_HIP_ROCWMMA_FATTN=ON -DAMDGPU_TARGETS="gfx1151"cmake --build rocm --config Release -j$(nproc)
说明
- -DGGML_HIP=ON:启用ROCm 软件栈
- -DGGML_RPC=ON:启用分布式推理所需的RPC 能力
- -DGGML_HIP_ROCWMMA_FATTN=ON:启用基于rocWMMA 的 Flash Attention,在 AMD GPU 上优化注意力性能
- -DAMDGPU_TARGETS="gfx1151":指定Ryzen AI Max+ 395 的 Radeon 8060S 作为构建目标
- 更多参数详解,请参阅llama.cpp build documentation [4]
验证构建结果并检测GPU:
cd rocm/bin$ ./llama-cli --list-devicesggml_cuda_init: found 1 ROCm devices: Device 0: AMD Radeon Graphics, gfx1151 (0x1151), VMM: no, Wave Size: 32Available devices:ggml_backend_cuda_get_available_uma_memory: final available_memory_kb: 127697544 ROCm0: AMD Radeon Graphics (120000 MiB, 124704 MiB free)
所有节点准备就绪后,继续第4步“推理配方”,配置RPC 端点并在集群上启动 Kimi K2.5。
04
推理配方
在每台机器上启动 RPC 端点
4a
为了将四台机器作为单一、协调的推理运行时使用,我们利用llama.cpp 的 RPC 引擎。RPC(Remote Procedure Call)使单个llama.cpp实例能够通过网络将模型的部分任务卸载到远程工作节点,同时保持一个统一的执行图。
实际运行中:一台机器作为主控制器,负责tokenizer、调度与编排;其余机器运行轻量级 RPC 服务器,向控制器暴露本地 GPU 的内存与算力。从模型的角度来看,可以放置在任意设备上(本地或远程),加载时自动进行分片,推理过程中由RPC 透明地处理张量传输与同步。
这与Ryzen AI Max+ 的系统架构非常契合:每个节点都贡献大量“GPU 可寻址内存与计算资源”,llama.cpp 在加载时跨节点分片。模型加载完成后,推理过程就如同在一个单一的超大型加速器上运行一样。
网络拓扑示意:

在远程主机(机器2–4)创建端点
在机器2–4 上启动 rpc-server,供主机(机器 1)连接:
./rpc-server -p 50053 -c --host 0.0.0.0
说明
- -p:RPC 服务器监听端口
- -c:启用本地缓存,存储大张量,避免模型加载时的重复网络传输
- --host:RPC 服务器绑定的 IP
- 更多参数详解,请参阅llama.cpp rpc documentation [5]
模型启动命令
4b
当远程RPC 主机就绪后,可在主机(机器 1)通过两种接口启动 Kimi K2.5 的推理。
llama-cli
llama-cli 是轻量的终端交互界面,适合基准测试、调试与低层试验,便于观察启动耗时、Prompt 处理行为与 token 生成性能。启动命令示例:
./llama-cli \ -m /path/to/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \ -c 32768 \ -fa on \ -ngl 999 \ --no-mmap \ --rpc <RPC_WORKER_1_IP>:50053,<RPC_WORKER_2_IP>:50053,<RPC_WORKER_3_IP>:50053
说明
- -m:gguf 模型文件路径(Kimi K2.5 的 00001-of-00008.gguf)
- -c:context 长度(上下文 token 数),越大内存占用越高
- -fa on:启用基于rocWMMA 的 Flash Attention(性能对比见第5步)
- -ngl:GPU 层数(存入 VRAM 的层数),设为 999 以确保模型完全 offload 到 Radeon 8060S
- --no-mmap:禁用模型内存映射;当模型大小超过系统内存而未超过VRAM 时,可显著降低加载时间
- --rpc:远程主机的IP 与端口(见第4a步)
- 更多参数详解,请参阅llama.cpp cli documentation [6]
llama-server
llama-server 基于同一推理引擎,但以常驻服务运行,带有 Web UI,并提供 OpenAI 兼容的 HTTP API,适合长时运行、多用户访问与工具集成。启动命令示例:
./llama-server \ -m /path/to/Kimi-K2.5-UD-Q2_K_XL-00001-of-00008.gguf \ -c 32768 \ -fa on \ -ngl 999 \ --no-mmap \ --host 0.0.0.0 \ --port 8081 \ --rpc <RPC_WORKER_1_IP>:50053,<RPC_WORKER_2_IP>:50053,<RPC_WORKER_3_IP>:50053
说明
- -m:gguf 模型文件路径(Kimi K2.5 的 00001-of-00008.gguf)
- -c:context 长度(上下文 token 数),越大内存占用越高
- -fa on:启用基于rocWMMA 的 Flash Attention(性能对比见第5步)
- ngl:GPU 层数(存入 VRAM 的层数),设为 999 以确保模型完全 offload 到 Radeon 8060S
- --no-mmap:禁用模型内存映射;当模型大小超过系统内存而未超过VRAM 时,可显著降低加载时间
- --host:llama-server 服务绑定的 IP
- --port:llama-server 服务监听端口
- --rpc:远程主机的IP 与端口(见第4a步)
- 更多参数详解,请参阅llama.cpp server documentation [7]
启动后,访问主机的IP 与端口(如 http://<HOST\_IP>:8081)即可进入 Web UI。
通过 OpenAI API 集成第三方应用
4c
llama-server实例提供了一个与OpenAI兼容的API,这意味着它实现了与OpenAI的聊天补全和嵌入端点相同的请求和响应模式。这使得为OpenAI的API设计的现有应用程序只需很少修改甚至无需修改就能正常运行。从客户端的角度来看,唯一需要修改的是基础URL和API密钥。基础URL设置为您的llama-server实例的地址,而API密钥可以是任意值,因为身份验证是在本地处理的。为了能在第三方兼容OpenAI的程序(如Open WebUII)中使用llama-server实例,你只需将应用指向本地服务器,而非OpenAI的端点即可。
- Base URL:你的llama-server 地址(例如 http:// :8081)
- API key:任意占位字符串(如none),鉴权由本地服务处理
示例:将Open WebUI [13] 指向你的本地 llama-server,即可直接使用。
05
性能优化参数调优
Flash Attention
Attention 是 LLM 能够“跟随指令、维持上下文一致性”的关键机制,也是在推理时最昂贵的计算之一。随着上下文增长,模型需要持续引用更长的历史 token,计算与内存压力同步增加,Attention 往往成为解码阶段的瓶颈。
Flash Attention 通过“融合、分块”的计算方式显著减少内存读写,降低此瓶颈。在 Ryzen AI Max+ 300 系列上,我们通过 llama.cpp 的 rocWMMA 路径启用 Flash Attention。rocWMMA 是 ROCm 的矩阵算子 API,让attent ion的核心计算高效运行在 AMD Radeon 8060S 的 RDNA 3.5 计算单元上。
启用方式:构建时加入-DGGML_HIP_ROCWMMA_FATTN=ON,启动时加入-fa on(示例见第4b步)。
测试结果(Text Generation throughput,序列长度 8192)
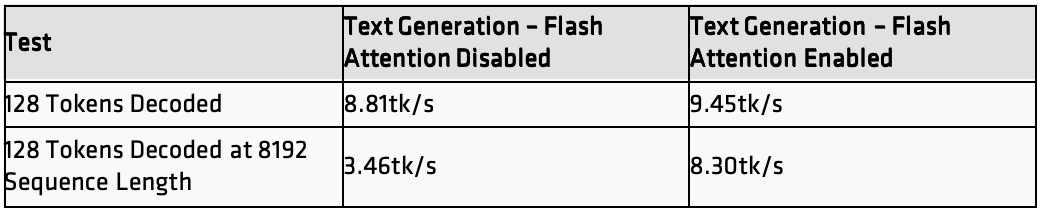
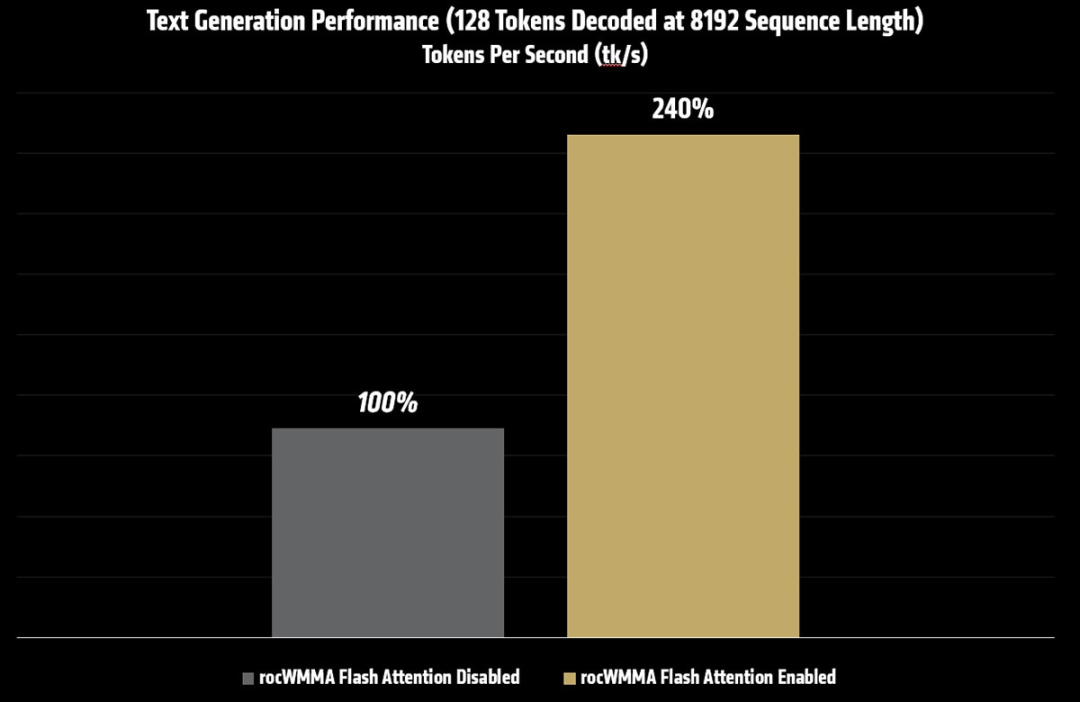
Batch 与 UBatch
Prompt 处理时延(TTFT,time to first token)是 LLM 最显著的性能指标之一。模型在生成首个 token 前,需将整个输入 Prompt 通过所有层处理;对于长 context,该阶段会主导整体时延。
在llama.cpp 中,Prompt 处理性能主要受两个参数影响:n_batch 与n_ubatch。
- n_batch:API 层每步允许处理的最大 token 数。
- n_ubatch:设备实际每步处理的最大token 数(micro-batch)。
测试结果(Prompt Processing throughput)
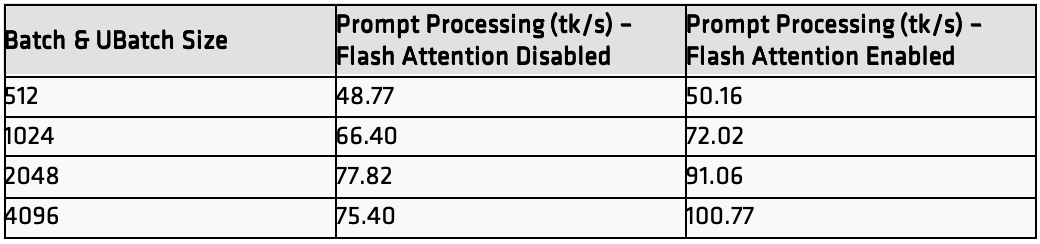
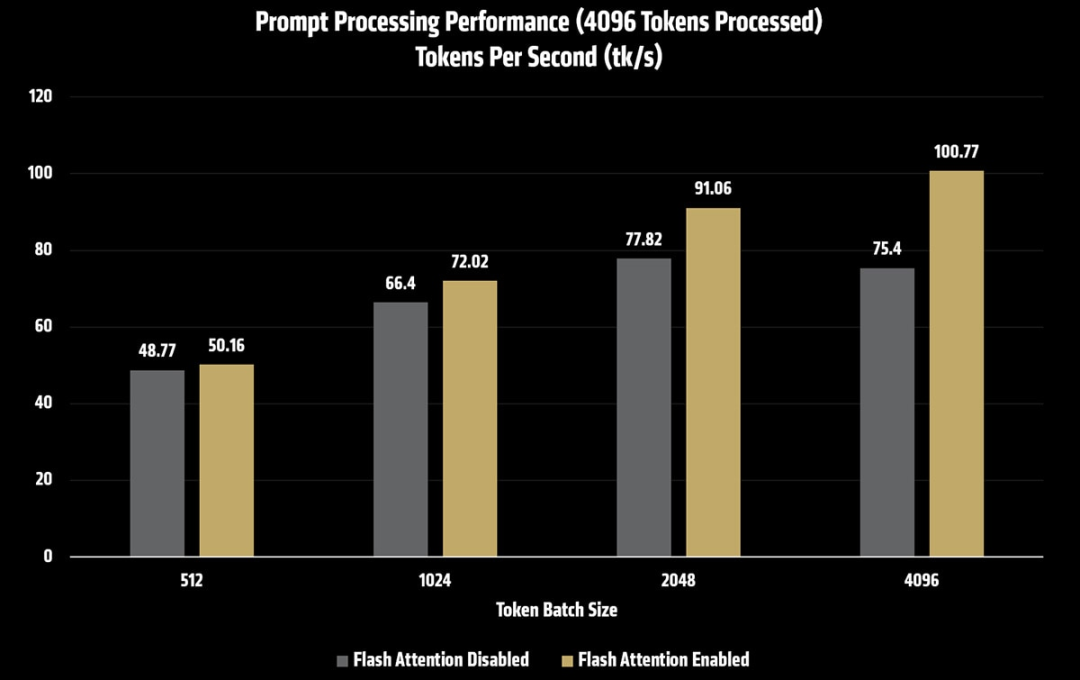

注意
TTFT 测试配置:n_batch=4096 与n_ubatch=4096
随着批次(batch)与微批(micro-batch)尺寸增大,Prompt 处理吞吐会提升。叠加基于 rocWMMA 的 Flash Attention,这种增益会进一步放大,显著降低长上下文 Prompt 的首个 token 时间(TTFT)。
在该配置下,调优n_batch 与n_ubatch,相较于基线设置(关闭Flash Attention,batch` 与 ubatch 为 512),Prompt 处理性能最高可提升至约 2×,使长上下文推理更为响应且更具实用性。
注意
增大n_batch 与n_ubatch 会增加模型上下文的内存占用。
06
结论
本文演示了:大型推理不再局限于传统服务器级GPU 或云端。借助 AMD Ryzen AI Max+ 的统一内存架构与 llama.cpp 的 RPC 能力,我们可以在一组 AI PC 上,将一万亿参数级模型作为单一协调系统进行推理。
以上方法具备可拓展性:节点数量可随模型VRAM 需求与工作负载变动而扩缩。面向原型开发、科研与企业应用,本地自托管的开源 LLM(如 Kimi K2.5)有助于在不引入按 token 计费的前提下获得优秀的 AI 效果,同时将数据与计算留在本地,更易满足隐私与合规要求。
对于许多团队而言,四节点Ryzen AI Max+ 集群是一种成本友好、隐私保护的选择,可用于探索万亿参数模型、原型分布式推理策略,并在进入更大规模云端或生产环境前进行验证。
07
参考链接
-
Kimi-K2.5 (UD_Q2_K_XL):https://modelscope.cn/models/unsloth/Kimi-K2.5-GGUF
-
Translation Table Manager(TTM):https://www.kernel.org/doc/html/v4.14/gpu/drm-mm.html#the-translation-table-manager-ttm
-
Lemonade SDK(最新发布):https://github.com/lemonade-sdk/llamacpp-rocm/releases/latest/
-
llama.cpp build documentation:https://github.com/ggml-org/llama.cpp/blob/master/docs/build.md
-
llama.cpp rpc documentation:https://github.com/ggml-org/llama.cpp/tree/master/tools/rpc
-
llama.cpp cli documentation:https://github.com/ggml-org/llama.cpp/tree/master/tools/cli
-
llama.cpp server documentation:https://github.com/ggml-org/llama.cpp/tree/master/tools/server
-
ROCm kernel version(Prerequisites):https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/prerequisites.html#verify-kernel-version
-
ROCm system requirements:https://rocm.docs.amd.com/projects/install-on-linux/en/latest/index.html
-
ROCm on Linux detailed installation overview:https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/detailed-install.html#detailed-install-overview
-
Post-installation instructions:https://rocm.docs.amd.com/projects/install-on-linux/en/latest/install/post-install.html
-
Troubleshooting:https://rocm.docs.amd.com/projects/install-on-linux/en/latest/reference/install-faq.html
-
Open WebUI:https://github.com/open-webui/open-webui

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0


 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)