
vllm分析(五)——pd分离kv cache的处理过程
分析vllm pd分离场景,从远程拉取 kv cache的处理流程
KVConnectorBase_V1
vllm定义的kv cache load 和 store 的接口: KVConnectorBase_V1 。
Scheduler侧方法:
- get_num_new_matched_tokens: 获取能从远程KV cache匹配的新token数(在已有本地计算的token之外)。返回(匹配数, 是否异步加载)。
- update_state_after_alloc: 在block分配后更新状态。
- build_connector_meta: 构建发送给worker的元数据。
- update_connector_output: 接收worker返回的输出。
- request_finished: 请求结束时调用,决定是否异步释放blocks。
- take_events: 获取KV事件。
Worker侧方法:
- bind_connector_metadata: 设置scheduler传来的元数据。
- start_load_kv: 开始加载KV cache(可能异步)。
- wait_for_layer_load: 等待特定层加载完成。
- save_kv_layer: 开始保存某层KV cache。
- wait_for_save: 等待所有保存完成。
- get_finished: 获取已完成异步传输的请求ID。
- handle_preemptions: 处理被抢占的请求。
- build_connector_worker_meta: 构建返回给scheduler的元数据。
交互时序图
Scheduler Worker
| |
|-- get_num_new_matched_tokens()
|-- update_state_after_alloc()
|-- build_connector_meta() --|
| |
| (SchedulerOutput) |
|--------------------------->| bind_connector_metadata()
| | start_load_kv()
| | (for each layer)
| | wait_for_layer_load()
| | compute attention
| | save_kv_layer()
| | wait_for_save()
| | build_connector_worker_meta()
|<---------------------------| (KVConnectorWorkerMetadata)
| |
|-- update_connector_output()|
|-- (request finished) |
|-- request_finished() |
|-- ...later... |
|-- get_finished() <-------->| get_finished()
get_num_new_matched_tokens
Scheduler 通过 get_num_new_matched_tokens 这一查询接口获知远程 KV 缓存的存在,整个过程涉及调度决策、状态管理与异步加载。
┌─────────────────────────────────────────────────────────────────┐
│ Scheduler.schedule() │
│ │
│ 遍历 waiting / skipped_waiting 队列 │
│ for each request: │
│ if request.num_computed_tokens == 0: │
│ # 1. 获取本地缓存命中 │
│ new_computed_blocks, num_local = │
│ kv_cache_manager.get_computed_blocks(request) │
│ # 2. 查询远程缓存 │
│ ext_tokens, async_flag = │
│ connector.get_num_new_matched_tokens( │
│ request, num_local) │
│ │
│ if ext_tokens is None: │
│ # 连接器暂无法确定 → 跳过此请求,下次再查 │
│ queue.pop(); step_skipped.prepend(request) │
│ continue │
│ │
│ if ext_tokens > 0: │
│ # 远程存在 KV 缓存 │
│ num_external_computed_tokens = ext_tokens │
│ load_kv_async = True │
│ else: │
│ # 远程无缓存 │
│ num_external_computed_tokens = 0 │
│ load_kv_async = False │
└─────────────────────────────────────────────────────────────────┘
│
┌─────────────────────┴─────────────────────┐
│ │
▼ (存在远程 KV) ▼ (不存在)
┌───────────────────────────────┐ ┌───────────────────────────┐
│ 异步加载路径 │ │ 正常调度(本地计算) │
│ │ │ │
│ # 分配 KV blocks(占位) │ │ 分配 slots,计算 token │
│ new_blocks = allocate_slots( │ │ 请求进入 RUNNING │
│ delay_cache_blocks=True) │ └───────────────────────────┘
│ │
│ # 通知连接器分配信息 │
│ connector.update_state_after_alloc(...)
│ │
│ # 请求状态转为等待远程 KV │
│ request.status = WAITING_FOR_REMOTE_KVS
│ │
│ # 记录已分配 blocks 但暂不缓存 │
│ request.num_computed_tokens = │
│ num_local + ext_tokens │
│ │
│ # 当前 step 不分配计算 token │
│ num_new_tokens = 0 │
└───────────────────────────────┘
delay_cache_blocks=True 使得分配出的 blocks 虽然已从空闲池中取出、引用计数增加,但不会被写入前缀缓存哈希表(即未标记为全局可复用的缓存)。这些 blocks 处于“已预留、但未正式缓存”的状态。
Worker和Scheduler的交互
当 Worker 侧完成异步加载,会通过 KVConnectorOutput.finished_recving 上报。
Worker 侧 Scheduler 侧 KVCacheManager
│ │ │
│ KV加载完成 │ │
│ (finished_recving) │ │
│──────────────────────────>│ │
│ │ _update_from_kv_xfer_finished│
│ │ └─ 加入 finished_recving │
│ │ _kv_req_ids │
│ │ │
│ │ 下一轮 schedule() │
│ │ └─ _try_promote... │
│ │ ├─ 检查 ID 是否在集合中 │
│ │ └─ _update_waiting... │
│ │ │ │
│ │ └─ cache_blocks() ──>│
│ │ │ 注册到前缀缓存
│ │ 状态变为 WAITING │
│ │ │
│ │ 继续分配新 tokens │
│ │ └─ allocate_slots() ─────────>│ 返回已有 blocks
│ │ │
│ │ 生成 SchedulerOutput │
│<──────────────────────────│ │
│ 执行推理(使用填充好的 KV)│ │
接收 Worker 侧完成信号
┌─────────────────────────────────────────────────────────────┐
│ GPUModelRunner.execute_model() │
│ │ │
│ ▼ │
│ 返回 ModelRunnerOutput │
│ └─ kv_connector_output (KVConnectorOutput) │
│ │ │
│ ▼ │
│ Scheduler.update_from_output() │
│ │ │
│ ▼ │
│ _update_from_kv_xfer_finished(kv_connector_output) │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ _update_from_kv_xfer_finished 处理逻辑 │
├─────────────────────────────────────────────────────────────┤
│ for req_id in kv_connector_output.finished_recving: │
│ req = self.requests[req_id] │
│ if req.status == WAITING_FOR_REMOTE_KVS: │
│ self.finished_recving_kv_req_ids.add(req_id) │
│ else: │
│ # 请求已结束,直接释放 blocks │
│ self._free_blocks(req) │
└─────────────────────────────────────────────────────────────┘
│
▼
┌──────────────────────┐
│ finished_recving_kv │
│ _req_ids 集合 │
│ (存储已完成接收的ID) │
└──────────────────────┘
v1定义的GPUModelRunner.execute_model
Scheduler.update_from_output
_try_promote_blocked_waiting_request
┌─────────────────────────────────────────────────────────────┐
│ Scheduler.schedule() │
│ │
│ 遍历等待队列 (waiting / skipped_waiting) │
│ while token_budget>0 and 有空闲槽位: │
│ request = queue.peek_request() │
│ │
│ if _is_blocked_waiting_status(request.status): │
│ # 尝试提拔阻塞状态的请求 │
│ if not _try_promote_blocked_waiting_request(): │
│ # 提拔失败,跳过本次调度 │
│ continue │
└─────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────┐
│ _try_promote_blocked_waiting_request(request) │
├─────────────────────────────────────────────────────────────┤
│ if request.status == WAITING_FOR_REMOTE_KVS: │
│ # 检查是否已完成接收 │
│ if req_id not in finished_recving_kv_req_ids: │
│ return False # 未完成,不可调度 │
│ │
│ # 完成接收后的处理 │
│ _update_waiting_for_remote_kv(request) │
│ │
│ # 状态转换 │
│ if request.num_preemptions: │
│ request.status = PREEMPTED │
│ else: │
│ request.status = WAITING │
│ return True │
└─────────────────────────────────────────────────────────────┘
_update_waiting_for_remote_kv
┌─────────────────────────────────────────────────────────────┐
│ _update_waiting_for_remote_kv(request) │
├─────────────────────────────────────────────────────────────┤
│ if req_id in failed_recving_kv_req_ids: │
│ # 部分块加载失败 │
│ if request.num_computed_tokens > 0: │
│ # 缓存有效的 tokens │
│ kv_cache_manager.cache_blocks(request, │
│ request.num_computed_tokens) │
│ else: │
│ # 完全失败,释放所有分配块 │
│ kv_cache_manager.free(request) │
│ failed_recving_kv_req_ids.remove(req_id) │
│ else: │
│ # 全部成功 │
│ # 正式将 blocks 注册到前缀缓存(若启用) │
│ kv_cache_manager.cache_blocks(request, │
│ request.num_computed_tokens) │
│ │
│ # 全提示命中的特殊处理:需重算最后一个 token │
│ if request.num_computed_tokens == request.num_tokens: │
│ request.num_computed_tokens = request.num_tokens-1 │
│ │
│ finished_recving_kv_req_ids.remove(req_id) │
└─────────────────────────────────────────────────────────────┘
请求重新进入正常调度流程
┌─────────────────────────────────────────────────────────────┐
│ 请求状态变为 WAITING(或 PREEMPTED)后,继续当前 schedule() │
│ 循环 │
├─────────────────────────────────────────────────────────────┤
│ # 请求现在可以被正常调度 │
│ # 分配新的 tokens(如果需要) │
│ num_new_tokens = min(request.remaining_tokens, token_budget)│
│ │
│ # KVCacheManager 会复用之前已分配的 blocks │
│ # (因为请求已持有 blocks) │
│ new_blocks = kv_cache_manager.allocate_slots(...) │
│ # 返回的是已存在的 KVCacheBlocks 对象 │
│ │
│ # 将请求移入 running 队列 │
│ self.running.append(request) │
│ request.status = RUNNING │
│ │
│ # 记录到 scheduler_output,发送给 Worker 执行 │
│ req_to_new_blocks[req_id] = new_blocks │
│ num_scheduled_tokens[req_id] = num_new_tokens │
└─────────────────────────────────────────────────────────────┘
GPUModelRunner中kv cache的加载流程
┌────────────────────────────────────────────────────────────────────┐
│ GPUModelRunner.execute_model │
└────────────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────────┐
│ pre_forward(): │
│ - bind_connector_metadata(meta) │
│ - start_load_kv(forward_context) │
│ │ │
│ └─── 为每个请求创建异步加载任务,但不等待 │
│ 数据传输在后台进行 │
└────────────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────────┐
│ 模型执行 (逐层) │
│ for each layer: │
│ ┌─────────────────────────────────────────┐ │
│ │ @maybe_transfer_kv_layer │ │
│ │ - wait_for_layer_load(layer_name) ◄───┼─ ─ ─ 阻塞等待该层数据│
│ │ - attention_forward(...) │ │
│ │ - save_kv_layer(...) │ │
│ └─────────────────────────────────────────┘ │
└────────────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────────┐
│ post_forward(): │
│ - wait_for_save() # 等待所有保存完成 │
│ - get_finished(finished_req_ids) │
│ │ │
│ └─── 返回 (finished_sending, finished_recving) │
└────────────────────────────────────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────────────────┐
│ 返回 ModelRunnerOutput 给 Scheduler │
│ - kv_connector_output.finished_recving │
│ - kv_connector_output.finished_sending │
└────────────────────────────────────────────────────────────────────┘
在很多connector的实现中,wait_for_layer_load为空。kv cache是否加载完成通过get_finished判断。
maybe_transfer_kv_layer
# https://github.com/vllm-project/vllm/blob/v0.20.1/vllm/model_executor/layers/attention/kv_transfer_utils.py#L15
def maybe_transfer_kv_layer(func: Callable) -> Callable:
"""Decorator that handles KV layer transfer prior and after execution of
an attention layer, if enabled. Otherwise, the wrapper is a no-op.
On entry: waits for the KV layer from the connector.
On exit: saves the KV layer to the connector.
"""
# Import at runtime to avoid circular dependency
from vllm.model_executor.layers.attention.attention import get_attention_context
# Inspect the signature ONCE when the decorator is applied.
sig = inspect.signature(func)
param_names = list(sig.parameters.keys())
# Find the index of 'layer_name' parameter.
try:
layer_name_index = param_names.index("layer_name")
except ValueError as e:
raise TypeError(
f"Function {func.__name__} must have a 'layer_name' parameter"
) from e
@wraps(func)
def wrapper(*args, **kwargs):
if not has_kv_transfer_group() or not is_v1_kv_transfer_group():
return func(*args, **kwargs)
layer_name = _resolve_layer_name(args[layer_name_index])
# Extract attention context (metadata, layer, kv_cache, layer_slot_mapping)
attn_metadata, _, kv_cache, _ = get_attention_context(layer_name)
connector = get_kv_transfer_group()
if attn_metadata is None or not connector.has_connector_metadata():
return func(*args, **kwargs)
# Wait for KV layer on entry
connector.wait_for_layer_load(layer_name)
# Execute the function
result = func(*args, **kwargs)
# Save KV cache layer on exit
connector.save_kv_layer(layer_name, kv_cache, attn_metadata)
return result
return wrapper
pre_forward和post_forward的代码
# https://github.com/vllm-project/vllm/blob/v0.20.1/vllm/v1/worker/gpu/kv_connector.py#L48
class ActiveKVConnector(KVConnector):
def __init__(
self, vllm_config: VllmConfig, kv_caches_dict: dict[str, torch.Tensor]
):
self.vllm_config = vllm_config
self.kv_connector = get_kv_transfer_group()
# Register kv caches with KV Connector if applicable.
# TODO: support cross_layers_kv_cache
# (see https://github.com/vllm-project/vllm/pull/27743)
self.kv_connector.register_kv_caches(kv_caches_dict)
self.kv_connector.set_host_xfer_buffer_ops(copy_kv_blocks)
self._disabled = False
def pre_forward(self, scheduler_output: "SchedulerOutput") -> None:
if self._disabled:
return
kv_connector_metadata = scheduler_output.kv_connector_metadata
assert kv_connector_metadata is not None
self.kv_connector.bind_connector_metadata(kv_connector_metadata)
self.kv_connector.handle_preemptions(kv_connector_metadata)
# TODO: sort out KV Connectors' use of forward_context
if is_forward_context_available():
self.kv_connector.start_load_kv(get_forward_context())
else:
with set_forward_context(None, self.vllm_config):
self.kv_connector.start_load_kv(get_forward_context())
def post_forward(
self,
scheduler_output: "SchedulerOutput",
wait_for_save: bool = True,
clear_metadata: bool = True,
) -> KVConnectorOutput | None:
if self._disabled:
return None
output = KVConnectorOutput()
if wait_for_save:
self.kv_connector.wait_for_save()
output.finished_sending, output.finished_recving = (
self.kv_connector.get_finished(scheduler_output.finished_req_ids)
)
output.invalid_block_ids = self.kv_connector.get_block_ids_with_load_errors()
output.kv_connector_stats = self.kv_connector.get_kv_connector_stats()
output.kv_cache_events = self.kv_connector.get_kv_connector_kv_cache_events()
output.kv_connector_worker_meta = (
self.kv_connector.build_connector_worker_meta()
)
if clear_metadata:
self.kv_connector.clear_connector_metadata()
return output
def no_forward(self, scheduler_output: "SchedulerOutput") -> ModelRunnerOutput:
if self._disabled:
return EMPTY_MODEL_RUNNER_OUTPUT
self.pre_forward(scheduler_output)
kv_connector_output = self.post_forward(scheduler_output, wait_for_save=False)
if kv_connector_output is None or kv_connector_output.is_empty():
return EMPTY_MODEL_RUNNER_OUTPUT
output = copy.copy(EMPTY_MODEL_RUNNER_OUTPUT)
output.kv_connector_output = kv_connector_output
return output
def set_disabled(self, disabled: bool) -> None:
# Ensure that layer-wise connector hooks aren't called when disabled.
kv_transfer_state._KV_CONNECTOR_AGENT = None if disabled else self.kv_connector
self._disabled = disabled
NO_OP_KV_CONNECTOR = KVConnector()
def get_kv_connector(
vllm_config: VllmConfig, kv_caches_dict: dict[str, torch.Tensor]
) -> KVConnector:
if not has_kv_transfer_group():
# No-op connector.
return NO_OP_KV_CONNECTOR
return ActiveKVConnector(vllm_config, kv_caches_dict)
kv cache传输模式
vllm定义可各种connector,可以链接不同cache后端,比如LMCache, Mooncake
kv_connector/v1文件夹下有各种connector的实现。
目前KVc cache的传输主要有两种模式:中心存储和分布式。
LMCache和Mooncake就是一种中心式存储的模式。
分布式,使用P2P传递数据。各个实例分别管理自己的存储,比如一个P实例计算完成后,向目标D实例建立通信完成KV值传递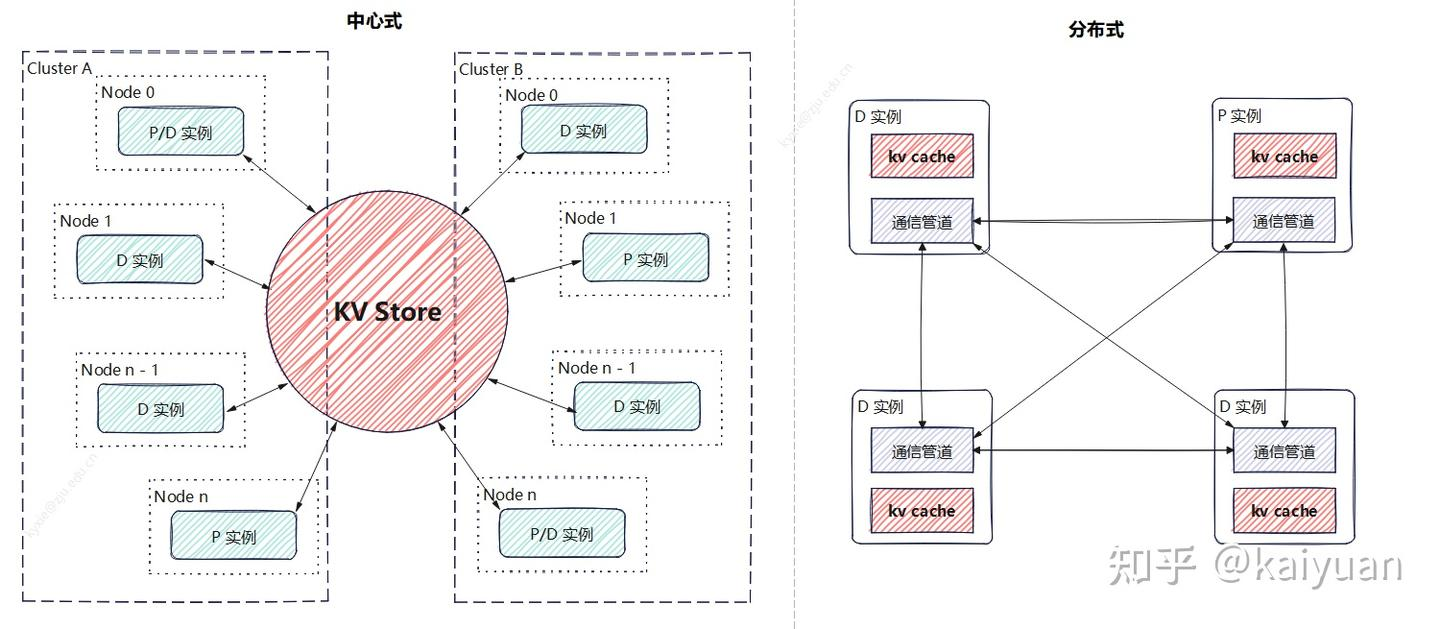
图片来源:vLLM PD分离KV cache传递机制详解与演进分析[1]。
p2p模式
Prefill 端(生产者)KV 发送流程
┌─────────────────────────────────────────────────────────────────────┐
│ Scheduler (调度器) │
│ - 为请求分配 KV blocks (allocate_slots) │
│ - 生成 P2pNcclConnectorMetadata (含 request_id, block_ids) │
│ - 通过 SchedulerOutput 发送给 Worker │
└─────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ GPUModelRunner (Prefill 实例) │
│ execute_model(): │
│ 1. pre_forward → bind_connector_metadata │
│ 2. 逐层执行 Attention │
└─────────────────────────────────────────────────────────────────────┘
│
┌───────────────┴───────────────┐
│ 每个 Attention 层计算完成后 │
▼ │
┌─────────────────────────────────────────────────────────────────────┐
│ @maybe_transfer_kv_layer 装饰器调用 save_kv_layer(layer_name, ...) │
└─────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ P2pNcclConnector.save_kv_layer() │
│ - 仅当 is_producer = True 时执行 │
│ - 遍历 connector_metadata.requests │
│ - 对每个请求: │
│ 1. extract_kv_from_layer(kv_layer, block_ids) → kv_cache切片 │
│ 2. 解析 request_id → 获取 Decode 端 IP 和端口 │
│ 3. 构造 tensor_id = request_id + "#" + layer_name │
│ 4. p2p_nccl_engine.send_tensor(tensor_id, kv_cache, remote_addr)│
└─────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ P2pNcclEngine.send_tensor()(默认 PUT_ASYNC) │
│ - 将 (tensor_id, remote_address, tensor) 放入 send_queue │
│ - 立即返回 (不阻塞) │
└─────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ 后台线程 _send_thread 消费队列 │
│ for each item in send_queue: │
│ 1. 通过 ZMQ DEALER 向 remote_address 发送 PUT 命令 │
│ (包含 shape, dtype, tensor_id) │
│ 2. 等待对端回复 b"0" (表示已准备好接收) │
│ 3. 调用 ncclSend() 启动 NCCL 异步传输 │
│ 4. 记录 tensor_id 到 send_request_id_to_tensor_ids │
│ 5. 继续下一个 item │
└─────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────┐
│ 请求完成时 │
│ Scheduler 调用 connector.request_finished(request, block_ids) │
│ → P2pNcclConnector.request_finished() 返回 (False, None) │
│ → 表示不需要延迟释放 blocks │
│ ⚠️ 风险: 异步 NCCL 传输可能尚未完成,但 blocks 会被立即释放, │
│ 可能导致 use-after-free │
└─────────────────────────────────────────────────────────────────────┘
Decode 端(消费者)KV 接收流程
┌─────────────────────────────────────────────────────────────────────────┐
│ Decode Worker 后台线程:listen_for_requests │
│ (持续监听 ZMQ ROUTER 套接字,接收 Prefill 发来的 PUT 命令) │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 收到 PUT 命令(包含 tensor_id, shape, dtype) │
│ - remote_address 为 Prefill 端地址 │
│ - tensor_id 格式: "request_id#layer_name" │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 1. 分配临时接收缓冲区 │
│ tensor = torch.empty( │
│ data["shape"], │
│ dtype=getattr(torch, data["dtype"]), │
│ device=self.device) # 在当前 GPU 上分配 │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 2. 发送确认信号(表示已准备好接收) │
│ self.router_socket.send_multipart([remote_address, b"0"]) │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 3. 使用 NCCL 接收数据 │
│ comm, rank = self.comms[remote_address.decode()] │
│ self.recv(comm, tensor, rank ^ 1, self.recv_stream) │
│ - 阻塞直到 tensor 被完全填充 │
│ - 数据直接从远端 GPU 内存传输到本地的 tensor 中 │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 4. 将接收到的 tensor 存入 recv_store,并通知等待者 │
│ with self.recv_store_cv: │
│ self.recv_store[tensor_id] = tensor │
│ self.recv_store_cv.notify() # 唤醒 recv_tensor │
└─────────────────────────────────────────────────────────────────────────┘
接收缓冲区
- 后台线程 listen_for_requests 收到 PUT 命令后,会调用 torch.empty() 分配一个临时的接收缓冲区(与发送端 shape/dtype 一致,位于当前 GPU)。
- 然后通过 ncclRecv 将远程的 KV 数据直接接收到这个临时缓冲区中。
- 缓冲区填充完成后,将其存入 recv_store,并通知等待的 recv_tensor。
- start_load_kv 中的 inject_kv_into_layer 再将这个临时缓冲区的内容 复制到预分配的 KV blocks 中(即 vLLM 的 paged KV cache)。
start_load_kv的处理过程
┌─────────────────────────────────────────────────────────────────────────┐
│ Decode Worker:start_load_kv │
│ (在模型执行前的 pre_forward 中调用,同步等待每一层数据) │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 1. 调用 p2p_nccl_engine.recv_tensor(tensor_id, remote_address) │
│ → 阻塞等待 recv_store 中出现该 tensor_id(由后台线程填充) │
│ → 获取到临时 tensor 后返回 │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 2. 调用 inject_kv_into_layer(layer, kv_cache, block_ids, request_id) │
│ - 根据 Attention 后端布局(MLA/FlashInfer/FlashAttention) │
│ - 使用 block_ids 将临时 tensor 中的 KV 数据写入本地预分配的 blocks │
│ │
│ 示例(FlashAttention 布局): │
│ layer[:, block_ids, ...] = kv_cache │
│ 示例(MLA / FlashInfer 布局): │
│ layer[block_ids, ...] = kv_cache │
│ │
│ - 此时 KV 数据已正式进入 vLLM 的分页 KV 缓存 │
│ - 临时 tensor 后续会被释放(引用计数减少或 pool.free) │
└─────────────────────────────────────────────────────────────────────────┘
│
▼
┌─────────────────────────────────────────────────────────────────────────┐
│ 3. 该层接收完成,继续下一层或结束(若所有层已处理) │
└─────────────────────────────────────────────────────────────────────────┘
reference
[1] vLLM PD分离KV cache传递机制详解与演进分析
[2] vLLM PD分离方案浅析
[3] P2P NCCL 连接器

免费领 100 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 6
6 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)