mHC架构解析|如何将模型内部信息流稳定下来
字节跳动Seed团队提出Hyper-Connection(HC)架构扩展残差连接,但面临训练不稳定和硬件效率问题。DeepSeek团队提出mHC方案,采用双随机矩阵约束信息流,结合工程优化使27B参数模型训练更稳定高效。该研究为架构创新提供了约束与优化相结合的新范式。
还记得那个统治了深度学习近十年的“老古董”——残差连接(Residual Connection)吗?虽然简单,但它有一个超能力:恒等映射。不管网络多深,信息都能像在高速公路上一样直通,不会因为太深而“失忆”(梯度消失)或“发疯”(梯度爆炸),不过以目前大模型的发展速度,从性能角度上来说有点跟不上脚步了。
为此,字节跳动 Seed 团队提出了 Hyper-Connection (HC) 架构,将传统残差路径从一条扩展为多条并行连接,形成“宽通道”信息流。理论上,这显著增强了模型的表征灵活性和非线性建模能力。但现实是残酷的——HC 在实践中极易失稳。
“超连接(HC)”的致命Bug导致模型“崩溃”
俗话说的好 “没有规矩,不成方圆”,这句话放到现在深度学习中也是有很深刻的道理
当HC尝试同时管理多条信息“车道”时,由于缺乏适当的约束,各个车道间的信号强度开始出现不可预测的变化。在某些层,信号被过度放大;在另一些层,信号几乎消失
这种不稳定性直接反映在训练过程中:模型训练到一半突然“崩溃”,损失值急剧上升,梯度变得异常巨大或微小。
这是什么概念?
比如说,假如你是公司CEO,你有四个负责收集公司信息的下属,某一天有个同事请假了,结果这四个人都觉得此事重要,在互相沟通的同时加重此事的程度,到你耳朵里面就是公司所有人当天就要一起跑路了,这是过度放大;再比如说公司楼地基塌陷了(假如)经过四个下属时都觉得不重要不去做,可能到你这里也觉得没有问题,结果公司直接倒了,这就是信号消失可能产生的后果。
除了稳定性问题,HC还面临硬件效率挑战。扩展的残差流需要更多的内存访问,增加了通信成本,在大规模分布式训练中产生了显著的额外开销。
mHC:给信息流装上“稳压器”
为了驯服这匹野马,DeepSeek提出了 mHC(Manifold-Constrained Hyper-Connections,流形约束超连接)。
核心思路就一句话:路可以宽,但信号传输必须守恒。
mHC使用数学中的“双随机矩阵”作为约束条件。这类矩阵有两个关键特性:所有元素非负,且每一行和每一列的和都等于1。这确保了在信息流动过程中,不会有信号被过度放大或过度衰减。
mHC使用的Sinkhorn-Knopp算法可以将任意矩阵“投影”为双随机矩阵,就像为混乱的车流设立智能交通信号灯系统。
实验表明,mHC将信号增益的最大波动从3000倍降至1.6倍,实现了三个数量级的稳定化改进。
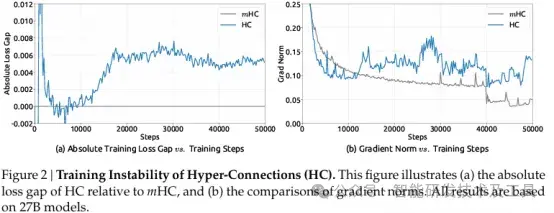
用大白话解释就是:
以前(HC): 信号在层与层之间传递,有时变成原来的10倍,有时变成0.1倍,几十层叠加后,结果不可控。
现在: mHC规定,不管你怎么混搭,输入信号的总值必须保持不变。这就像在每一层都装了一个自动稳压器,信号再怎么混合,整体幅度依然稳如泰山。
光有理论不够,DeepSeek还是那个极致抠细节的工程狂魔。
他们发现HC虽然计算量(FLOPs)没怎么变,但因为路宽了,搬运数据的开销(I/O)巨大。于是他们祭出了全套工程优化:
1、算子融合: 用TileLang手搓高性能Kernel,把读写的操作压缩到了极致。
2、重计算策略: 精打细算显存,该扔的扔,该算的算。
3、通信重叠: 优化了DualPipe调度,让数据传输和计算像打乒乓球一样无缝衔接。
在27B参数的超大模型上实测:
稳定性: mHC直接修好了HC的“路怒症”,Loss曲线平滑得像婴儿的皮肤,梯度再也不爆炸了。
性能: 相比标准基线,mHC在全跑赢;相比不稳定的HC,mHC不仅更稳,效果还更好(比如BBH基准提升了2.1%)。
成本: 即使开了四倍宽的通道,训练时间开销仅为 6.7%。这点成本换来模型的稳定性和性能提升,简直是用五菱宏光的成本开出了法拉利的推背感。
总结:架构创新需要结合约束条件形成新范式
DeepSeek这篇论文告诉我们:架构设计不能只顾着“加料”,还得注意“消化”。
通过数学约束和工程优化的双重buff,他们把一个原本“帅但短命”的超连接想法,变成了一个既强又稳、适合大规模落地的实用技术。这一框架为未来的架构创新提供了新范式。双随机矩阵只是众多可能的流形约束之一,研究人员可以探索其他类型的约束条件,以适应不同的学习目标和数据特性。

欢迎来到AMD开发者中国社区,我们致力于为全球开发者提供 ROCm、Ryzen AI Software 和 ZenDNN等全栈软硬件优化支持。携手中国开发者,链接全球开源生态,与你共建开放、协作的技术社区。
更多推荐

 24
24 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)