
使用 TileLang 在 AMD GPU 上快速开发高性能 Flash Attention
使用 TileLang 在 AMD GPU 上快速开发高性能 Flash Attention
作者:Daniel Huang, George Wang

在AMD ROCm™ 软件生态快速发展的背景下,算子开发门槛长期以来一直是一个瓶颈。TileLang 的出现,为开发者提供了一条高效路径。
作为一个新兴的AI 算子开发框架,TileLang 用简洁的语法封装了底层 GPU 细节,让开发者无需深入掌握 HIP 等底层语言,也能充分挖掘 AMD GPU 的计算潜力。AMD GPU 作为面向 AI 工作负载的旗舰产品,具备超高带宽内存和强大的计算单元,但要真正发挥其实力,需要配套的高性能自适应算子。
本文以在大模型训练与推理中都至关重要的Flash Attention 为例,完整展示基于 TileLang 在AMD GPU上的开发流程,重点说明 TileLang 在 AMD 算子开发中带来的「开发效率」与「性能表现」双重收益。

了解TileLang:面向 GPU 的算子开发框架
TileLang 的核心定位
TileLang 是一个开源的 AI 算子编程领域特定语言(DSL),核心目标是:
- 简化复杂 GPU 算子开发流程
- 在此基础上,做到与手写底层代码相当的性能
它以“Tile(块)” 为核心编程单元,通过高层 API 封装 GPU 底层细节,使开发者在不深入掌握 HIP/CUDA 的前提下,仍能高效利用 GPU 共享内存和寄存器等硬件资源。
DeepSeek 团队已在其 V3.2-Exp 模型中开源了基于 TileLang 的算子,并推荐在研究实验中使用它做快速迭代和调试,这进一步验证了 TileLang 的工业级可用性。
对比Triton 的核心优势
OpenAI 的 Triton 首先推动了高层 kernel 编程,但在 AMD 生态适配和性能调优上仍存在局限。TileLang 在解决这些痛点方面具有明显优势:
- 更高的开发效率:通过tile 级抽象与内建优化原语,大幅减少代码量。TileLang 团队的数据显示:Flash Attention kernel 从 CUDA 的 500+ 行缩减到不到 80 行,性能仍保持相当水平。与 Triton 相比,TileLang 的 API 更贴近 kernel 优化思路,语法冗余更少。
- 更智能的Autotuning:内置灵活的autotuning 框架,支持多维参数组合搜索。能针对不同硬件和工作负载场景快速找到最优配置,免去大量手工调参。
- 优秀的生态兼容性:已适配多家国内及主流GPU,已被 DeepSeek 等主流大模型项目采用,生态成熟度持续提升。
- 更好的易用性和可扩展性:面向不同水平的开发者:新手、熟练工程师、领域专家都能找到合适的开发方式。相比之下,Triton 对初学者门槛更高。TileLang 通过分层 API 设计:新手可直接使用内建原语快速上手,专家可以下钻做底层自定义与极致优化。在易用性和可扩展性之间取得良好平衡。
Flash Attention 简介
Flash Attention 解决的核心痛点
传统Attention 机制的计算复杂度随序列长度呈二次增长;同时,大规模中间结果(如注意力分数矩阵)的频繁读写,使 GPU 内存容量与带宽成为性能瓶颈。
Flash Attention 通过:
- 分块(tiling)计算
- 重计算(recomputation)策略
将大部分访问从HBM(High Bandwidth Memory)转移到 GPU SRAM 中完成,大幅减少内存读写量;同时,通过更合理的并行策略提升计算单元利用率,最终获得约 2–4 倍的性能提升。
核心公式与计算流程
Flash Attention 的数学本质与传统 Attention 一致,但为了适配 tile 化机制,对计算顺序和数据组织做了重构。核心公式如下:
1. 注意力分数计算
对Query(Q)与 Key(K)的转置做矩阵乘,随后按维度开根号做归一化,避免 softmax 因数值过大而饱和:
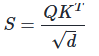
其中:Q ∈ ℝB×L×H×D(B=batch size,L=sequence length,H=head 数,D=特征维度),K ∈ R, d = 特征维度D。
2. 因果Mask(可选):在生成类任务中,通过下三角mask 屏蔽未来位置信息,保证因果性:
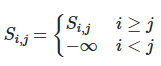
3. Softmax 归一化:对注意力分数做归一化,得到注意力权重:
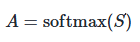
4. 输出计算:将注意力权重与值向量(V)进行矩阵乘法,得到最终输出结果:
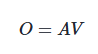
这里V ∈ R 并且 O ∈ R
Flash Attention 的核心创新在于:将上述计算拆分为多个小 tile,通过「load-compute-update」流水线,在 SRAM 中完成大部分计算,仅将最终结果写回 HBM,从而突破内存带宽瓶颈。
基于TileLang 的 Flash Attention 实现:代码深度解析
以下内容基于给定源码,从功能模块角度分析TileLang 实现的 Flash Attention 核心逻辑。整体代码分为两大部分:
- 核心算子函数(kernel)
- 辅助工具函数
其中,核心算子利用TileLang 的高层 API 实现了 tile 化计算和硬件优化。
核心算子:主Flash Attention 函数
该函数是TileLang 实现 Flash Attention 的核心,通过 @tilelang.autotune 与@tilelang.jit 装饰器实现:自动调优(autotuning)和JIT 编译为实际运行在 GPU 上的 HIP kernel。整体逻辑可分为两部分:参数初始化和 kernel 定义。
装饰器与参数定义
@tilelang.autotune(configs=get_configs(), cache_input_tensors=True, supply_prog=supply_tensors_gpu)@tilelang.jit(out_idx=[3])def fast_flashattn( batch, heads, seq_len, dim, is_causal, groups, block_M: int, block_N: int, num_split_q: int, threads: int, num_stages: int, enable_rasterization: bool, k_pack: int, panel_size: int, qk_coalesced_width: int, v_coalesced_width: int,):
- @tilelang.autotune :开启autotuning,指定候选配置集、输入 tensor 缓存策略以及提供 GPU tensor 的函数。
-@tilelang.jit :开启JIT 编译,将 TileLang 代码编译为 GPU 可执行的 HIP kernel。out_idx=[3] 表示第 4 个参数(Output)是输出 tensor。
初始化与Kernel 入口
scale = (1.0 / dim)**0.5head_kv = heads // groupsq_shape = [batch, seq_len, heads, dim]kv_shape = [batch, seq_len, head_kv, dim]dtype = "float16"accum_dtype = "float"
@T.prim_funcdef main( Q: T.Tensor(q_shape, dtype), K: T.Tensor(kv_shape, dtype), V: T.Tensor(kv_shape, dtype), Output: T.Tensor(q_shape, dtype),): with T.Kernel(num_split_q, batch * heads, threads=threads) as (b_split, byz_combined): T.use_swizzle(panel_size, enable=enable_rasterization)
bz = byz_combined // heads by = byz_combined % heads
核心逻辑:
1.初始化:计算归一化因子(scale)和 KV 头的数量(head_kv),并定义张量形状和数据类型(计算使用 float16 以提升性能,累加使用 float 以保证精度)。
2.Kernel 定义:使用 @T.prim_func 定义核心计算函数,T.Kernel 指定并行维度,num_split_q(对 Q 的并行拆分)以及 batch*heads(将 batch 与 head 合并并行),同时 threads 指定每个线程块中的线程数量。
3.硬件优化:T.use_swizzle 启用内存重排优化,以提升AMD GPU 上的内存访问效率。将 byz_combined 分解为 batch 索引(bz)和 attention head 索引(by),从而实现 batch 与 head 维度的并行处理。
Q Tile 处理与缓存初始化
num_q_blocks = T.ceildiv(seq_len, block_M)bx = T.alloc_var("int32")bx = b_splitwith T.While(bx < num_q_blocks): # Initialize accumulators and numerical stability variables acc_o = T.alloc_fragment([block_M, dim], accum_dtype) # Output accumulator m_i = T.alloc_fragment([block_M], accum_dtype) # Row-wise maximum (for numerical stability) l_i = T.alloc_fragment([block_M], accum_dtype) # Row-wise sum (for numerical stability) T.fill(acc_o, 0) T.fill(m_i, -T.infinity(accum_dtype)) T.fill(l_i, 0)
q_block_offset = bx * block_M # Allocate shared memory and registers Q_shared = T.alloc_shared([block_M, dim], dtype) # Q shared memory cache K_shared = T.alloc_shared([block_N, dim], dtype) # K shared memory cache V_shared = T.alloc_shared([block_N, dim], dtype) # V shared memory cache acc_s_cast = T.alloc_fragment([block_M, block_N], dtype) # Register cache (reduces LDS usage)
# Load Q tile to shared memory T.copy( Q[bz, q_block_offset:q_block_offset + block_M, by, :], Q_shared, coalesced_width=qk_coalesced_width)
核心逻辑:
1.Q Tile 遍历:先计算 Q 的分块数量(num_q_blocks),然后通过 While 循环依次遍历每一个 Q tile。
2.数值稳定性初始化:创建acc_o(输出累加器)、m_i(按行最大值)和 l_i(按行累加和),用于在 softmax 计算中解决数值溢出问题。
3.内存分配:分配共享内存(Q_shared / K_shared / V_shared)用于缓存当前 tile 的数据,同时分配寄存器(acc_s_cast)缓存中间结果,从而降低共享内存(LDS)的使用压力。
4.Q Tile 加载:将当前的 Q tile 从 HBM 加载到共享内存中;coalesced_width 用于指定访存合并宽度,以提升 AMD GPU 的内存带宽利用效率。
K/V Tile 遍历与核心计算
loop_end_k = T.ceildiv(q_block_offset + block_M, block_N) if is_causal else T.ceildiv(seq_len, block_N)
for k in T.Pipelined(loop_end_k, num_stages=num_stages): kv_idx = k * block_N
# Load K/V tiles to shared memory T.copy( K[bz, kv_idx:kv_idx + block_N, by // groups, :], K_shared, coalesced_width=qk_coalesced_width) T.copy( V[bz, kv_idx:kv_idx + block_N, by // groups, :], V_shared, coalesced_width=v_coalesced_width)
# Causal masking initialization if is_causal: for i, j in T.Parallel(block_M, block_N): acc_s[i, j] = T.if_then_else(q_block_offset + i >= kv_idx + j, 0, -T.infinity(acc_s.dtype)) else: T.clear(acc_s)
# QK^T matrix multiplication (attention score calculation) T.gemm( Q_shared, K_shared, acc_s, transpose_B=True, k_pack=k_pack, policy=GemmWarpPolicy.FullRow, )
# Numerical stability processing (stepwise softmax computation) T.copy(m_i, m_prev) T.reduce_max(acc_s, m_i, dim=1, clear=False) # Update row-wise maximum for i in T.Parallel(block_M): m_i[i] = T.max(m_i[i], m_prev[i]) sf = T.exp(m_prev[i] * scale - m_i[i] * scale) l_i[i] *= sf # Update row sum (scaling) scale_factor[i] = sf
# Output accumulator scaling for i, j in T.Parallel(block_M, dim): acc_o[i, j] *= scale_factor[i]
# Softmax normalization for i, j in T.Parallel(block_M, block_N): acc_s[i, j] = T.exp(acc_s[i, j] * scale - m_i[i] * scale) T.reduce_sum(acc_s, row_sum, dim=1) # Calculate row-wise sum for i in T.Parallel(block_M): l_i[i] += row_sum[i]
# Attention weight and V multiply-accumulate (output calculation) T.copy(acc_s, acc_s_cast) T.gemm(acc_s_cast, V_shared, acc_o, policy=GemmWarpPolicy.FullRow)
这是Flash Attention tile 化计算的核心逻辑,通过遍历 K/V tile 实现高效的「load-compute-update」流水线:
1.K/V Tile 范围:根据是否启用因果性来确定 K/V tile 的遍历终止位置。在因果模式下,只遍历当前位置之前的 K/V tile,避免泄露未来位置信息。
2.K/V 加载:将 K/V tile 加载到共享内存中,并采用与 Q 相同的内存访存合并策略。
3.因果Mask:通过并行循环给 acc_s(分数缓存)赋值,对不符合因果约束的位置设置为 -∞,从而实现因果约束。
4.GEMM 计算:调用 TileLang 内置的 GEMM 原语计算 QK,其中 transpose_B=True 指定对 K 做转置,k_pack 用于优化数据打包方式,GemmWarpPolicy.FullRow 则用于适配 AMD GPU 的 warp 调度策略以提升并行效率。
5.数值稳定性处理:分步执行softmax(先求最大值,再缩放,最后计算 exp),以避免直接对原始分数做 exp 时产生数值溢出。
6.OV 乘加:对归一化后的注意力权重(acc_s)与 V 进行 GEMM 计算,并将结果累加到 acc\_o 中,从而完成各 tile 结果的融合。
最终输出写回与Q tile 迭代
# Final normalization (reciprocal of row sum)l_inv = T.alloc_fragment([block_M], accum_dtype)for i in T.Parallel(block_M): safe_l = T.if_then_else(l_i[i] > 1e-6, l_i[i], 1.0) # Avoid division by zero l_inv[i] = 1.0 / safe_l# Write output results to HBMfor i, j in T.Parallel(block_M, dim): Output[bz, q_block_offset + i, by, j] = acc_o[i, j] * l_inv[i]# Iterate to next Q tilebx = current_bx + num_split_q
核心逻辑:
1. 计算每行 softmax 分母的倒数(l_inv),避免数值过小导致的除零问题
2. 用 l\_inv 对 acc\_o 做归一化,获得最终的 Attention 输出
3. 将结果写回 HBM 中的 Output 对应位置
4. 更新 bx,跳到下一个待处理的 Q tile,继续循环
辅助函数:算子周边模块
GPU 上的张量分配
这个函数是TileLang autotuning 框架的一个辅助接口。它确保输入的张量在 AMD GPU(ROCm/HIP 环境)上创建,从而避免由于设备不一致导致的计算错误。其核心逻辑是遍历所有输入参数:对于具有已定义 shape 和 dtype 的张量参数,在 "cuda" 设备上强制生成随机张量(在 ROCm 环境下与 AMD GPU 兼容);对于非张量参数,则直接原样返回。
参考实现(PyTorch 版本)
这是一个基于PyTorch 的标准 Attention 实现,用于:校验 TileLang 实现的正确性和做性能对比。
核心步骤包括:
1. 参数校验:保证 Q 的 head 数与 K/V 的 head 与分组数匹配
- KV head 展开:根据 groups 在 head 维度重复 K/V,使其与 Q 对齐
3. 分数计算与归一化:使用 einsum 完成 QK 计算,并按维度开根号归一化
4. 因果 Mask:在 is_causal=True 时构造下三角 mask,屏蔽未来位置
- Softmax 与输出计算:对分数做 softmax,然后与 V 相乘得到输出
Autotuning 配置生成
该函数用于为TileLang autotuning 工具生成一组候选配置,结合 Flash Attention V2 的并行特性设计了一组参数维度,包括:
- Tile 大小(block_M / block_N):控制 Q 与 K/V 的 tile 维度,影响 SRAM 利用率与计算/访存平衡。
- 线程数(threads):每个 GPU thread block 中的线程数量,需匹配 AMD GPU 的计算单元架构。
- 并行拆分(num_split_q):Q 序列方向的并行分割数量,决定多 SM/GCD 的利用率。
- 流水线阶段数(num_stages):控制 T.Pipelined 的 pipeline 深度,调整数据预取与计算重叠程度。
- 访存合并宽度(qk_coalesced_width / v_coalesced_width):控制 QK 与 V 拷贝时的 memory coalescing 宽度,影响有效内存带宽。
通过 itertools.product 穷举组合,生成 108 组候选配置,交由 autotuning 过程在真实硬件上测试,选出最佳方案。
主函数:性能测试与正确性验证
主函数负责:
1. 计算量统计:根据 batch、heads、seq_len、dim 等参数计算整体 FLOPs,用于换算 TFLOPS
2. 触发 autotuning:调用 fast_flashattn 时,TileLang 会对 108 组配置进行快速搜索,在 AMD GPU 上,每组配置只需极短时间,总搜索约 1 秒量级。
3. 正确性验证:使用 profiler.assert_allclose 对比 TileLang 实现与 PyTorch 参考实现,验证精度误差是否在可接受范围内(例如 rtol=0.01, atol=0.01)
4. 性能测试:使用 do_bench 分别测试两种实现的延迟与算力,设置 warmup=100,确保 GPU 进入稳定状态后再统计
性能对比:TileLang 实现的优势
在AMD GPU 上,对典型配置(batch=1, heads=8, seq_len=4096, dim=128)进行测试,结果如下表所示。
表1:batch=1, heads=8, seq_len=4096, dim=128 场景下的性能结果
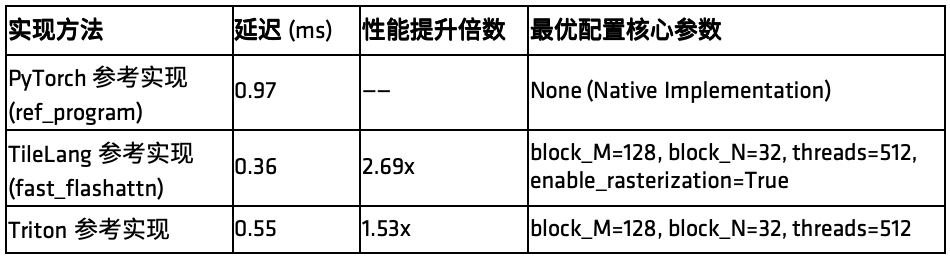
关键结论:
-
延迟大幅下降:TileLang 实现的延迟仅为 PyTorch 实现的约 37.1%,为 Triton 实现的约 65.5%,相较 PyTorch 提升约 2.7×,相较 Triton 提升约 1.53× [1],充分体现了面向 AMD GPU 特性进行 tile 化与硬件优化的价值。
-
Autotuning 高效:108 组配置搜索耗时约 1 秒,最优配置选择了 128×32 的 tile 和 512 线程,实现 SRAM 利用率与并行效率的平衡。
-
精度可靠:与PyTorch 参考实现结果高度一致,验证了 TileLang 实现的数值正确性。
总结
通过在AMD GPU 上使用 TileLang 实现 Flash Attention 的完整案例,本文验证了 TileLang 作为高层算子开发框架的核心价值。在代码简洁的前提下,性能可以接近手写底层代码,同时显著降低 AMD GPU kernel 的开发门槛。与 PyTorch 原生实现相比,TileLang 版本通过分块计算、内存优化和 autotuning,实现了约 2.7 倍的性能提升,同时代码更精简、可维护性更强。
未来,随着TileLang 在 AMD 生态中的进一步适配(例如支持 AMD GPU 上的 Tensor Core 加速)以及 autotuning 算法的持续优化,它在大模型核心算子开发中的应用前景将更加广阔。对开发者而言,TileLang 提供了一种全新的算子开发范式,在“不需要深入理解硬件细节”的前提下,就可以高效利用硬件性能,加速大模型在 AMD GPU 上的部署和性能释放。
尾注
[1] 测试环境
硬件:
-
AMD GPU
-
Intel® Xeon® Platinum 8568Y+
软件:
-
ROCm v7.0.1
-
PyTorch v2.9.0
-
Triton v3.0.0
-
TileLang v0.1.7
输入配置:
-
batch_size = 1
-
head_nums = 8
-
seq_len = 4096
-
dim = 128
声明
第三方内容由第三方直接授权给用户,AMD 不对该等内容向用户授予任何许可。所有链接的第三方内容均以 “AS IS(按现状)” 方式提供,AMD 不就此作出任何形式的保证。
用户自行决定是否使用该等第三方内容,因使用该等内容造成的任何后果由用户自行承担,AMD 对此不承担任何责任。
参考链接
- ROCm Blogs – 本文原文所在站点:https://rocm.blogs.amd.com/

免费领 200 小时云算力,进群参与显卡、AI PC 幸运抽奖
更多推荐
 0
0 0
0- 0


 已为社区贡献19条内容
已为社区贡献19条内容

所有评论(0)