图文对比学习的发展史:从CLIP、BLIP、BLIP2、InstructBLIP到具身模型常用的SigLIP
前言
本文一开始是属于此文《图像生成(AI绘画)的发展史:从CLIP、BLIP、InstructBLIP到DALLE、DALLE 2、DALLE 3、Stable Diffusion(含ControlNet详解)》的
考虑到本文内容的重要且独立性,故独立成本文
第一部分 从CLIP、BLIP1、BLIP2到InstructBLIP
1.1 CLIP:基于对比文本-图像对的预训练方法
1.1.1 CLIP的原理结构
我第一次见识到CLIP这个论文的时候(对应论文为:Learning Transferable Visual Models From Natural Language Supervision,作者为Alec Radford等人),当时的第一反应是,特么也太强悍了..
CLIP由OpenAI在2021年1月发布
- 通过超大规模模型预训练提取视觉特征,进行图片和文本之间的对比学习
(简单粗暴理解就是发微博/朋友圈时,人喜欢发一段文字然后再配一张或几张图,CLIP便是学习这种对应关系) - 且预训练好之后不微调直接推理
(即zero-shot,用见过的图片特征去判断没见过的图片的类别,而不用下游任务训练集进行微调)
使得在ImageNet数据集上,CLIP模型在不使用ImageNet数据集的任何一张图片进行训练的的情况下,最终模型精度能跟一个有监督的训练好的ResNet-50打成平手
(在ImageNet上zero-shot精度为76.2%,这在之前一度被认为是不可能的)
为了训练CLIP,OpenAI从互联网收集了共4个亿的文本-图像对,论文称之为WIT(Web Image Text,WIT质量很高,而且清理的非常好,其规模相当于JFT-300M,这也是CLIP如此强大的原因之一,后续在WIT上还孕育出了DALL-E模型)
其训练过程如下图所示:
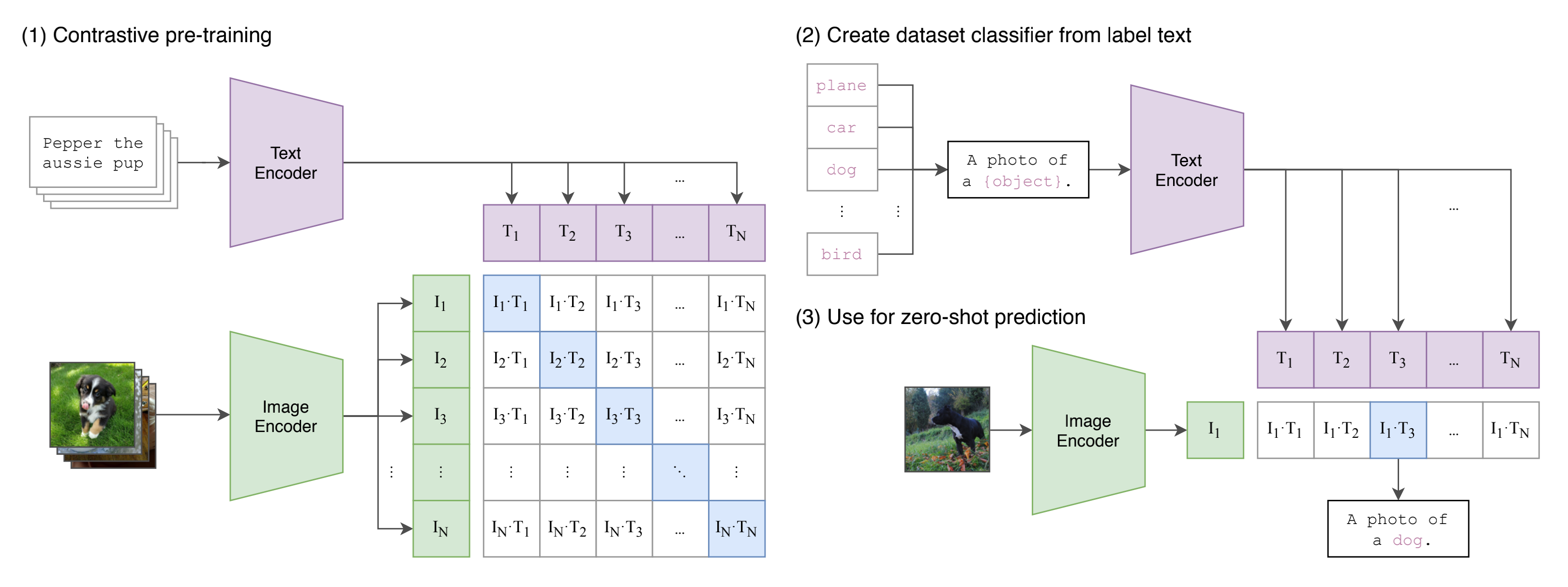
- 如上图的第一步所示,CLIP的输入是一对对配对好的的图片-文本对(比如输入是一张狗的图片,对应文本也表示这是一只狗),这些文本和图片分别通过Text Encoder和Image Encoder输出对应的特征。然后在这些输出的文字特征和图片特征上进行对比学习
假如模型输入的是对图片-文本对,那么这
对样本都是负样本,这样模型的训练过程就是最大化
Text Encoder可以采用NLP中常用的text transformer模型
相似度是计算文本特征和图像特征的余弦相似性cosine similarity
比如所谓的CLIP-ViT 便指的是采用ViT架构作为图像编码器的 CLIP 模型
类型上,总计有4种:
三种在 224×224 像素图像上训练的模型:ViT-B/32、ViT-B/16、ViT-L/14
以及一种在 336×336 像素输入图像上微调的ViT-L/14 模型
——————
之后,CLIP可以直接实现zero-shot的图像分类,即不需要任何训练和微调,其实现zero-shot分类只需要简单的两步,如下第2、3点所示 - 根据任务的分类标签构建每个类别的描述文本:A photo of {label},然后将这些文本送入Text Encoder得到对应的文本特征,如果类别数目为n,那么将得到n个文本特征
- 将要预测的图像送入Image Encoder得到图像特征,然后与n个文本特征计算缩放的余弦相似度(和训练过程保持一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果
进一步地,可以将这些相似度看成logits,送入softmax后可以到每个类别的预测概率
以下是对应的伪代码
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - 输入图片维度
# T[n, l] - 输入文本维度,l表示序列长度
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征d_e,并进行l2归一化,保持数据尺度的一致性
# 多模态embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0) # image loss
loss_t = cross_entropy_loss(logits, labels, axis=1) # text loss
loss = (loss_i + loss_t)/2 # 对称式的目标函数2021年10月,Accomplice发布的disco diffusion,便是第一个结合CLIP模型和diffusion模型的AI开源绘画工具,其内核便是采用的CLIP引导扩散模型(CLIP-Guided diffusion model)
且后续有很多基于CLIP的一系列改进模型,比如Lseg、GroupViT、ViLD、GLIP
1.1.2 CLIP匹配的一个示例
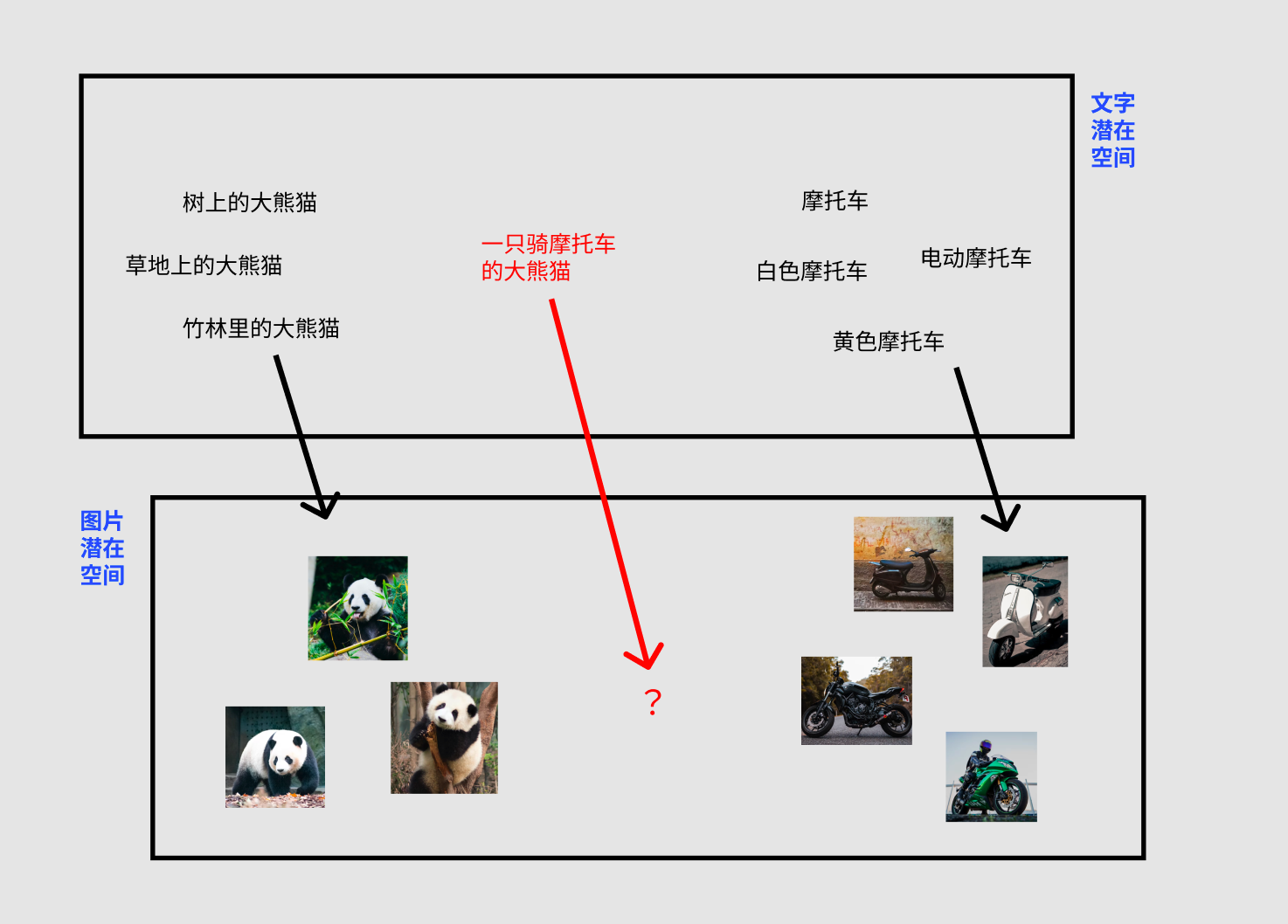
如果让你把下图左侧三张图和右侧三句话配对,你可以轻松完成这个连线。但对 AI 来说,图片就是一系列像素点,文本就是一串字符,要完成这个工作可不简单。

原因在于
- 这需要 AI 在海量「文本-图片」数据上学习图片和文本的匹配。图中绿色方块是「图片潜在空间」的 N 张图片,紫色方块是「文本潜在空间」的 N 句描述语
CLIP会努力将对应的 I1与T1(蓝色方块)匹配,而不是 I1与 T2 (灰色方块)匹配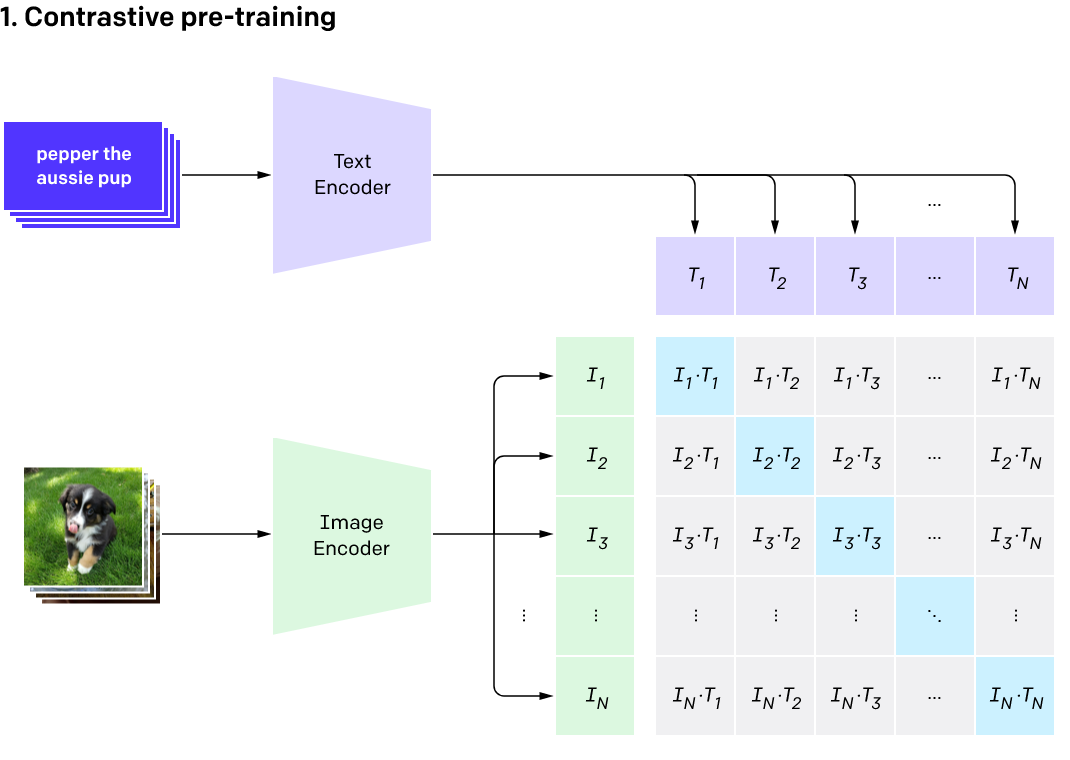
- 当 AI 能成功完成这个连线,也就意味着 AI 建立了「文字潜在空间」到「图片潜在空间」的对应关系,这样才能通过文字控制图片的去噪过程,实现通过文字描述得到图像的生成
1.2 BLIP:ViT + BERT ——通过encoder-decoder统一理解与生成任务
随着AI的迅速发展,多模态日渐成为一种趋势,而「Vision-Language Pre-training (VLP) + Fine-tuning => Zero Shot / Few Shot」的模式是快速解决多下游任务的一个好的模式,VLP 是这个模式的开端,所以对于 VLP 的相关研究也很多
BLIP 是一个新的 VLP 架构,可以灵活、快速的应用到下游任务,如:图像-文本检索、图像翻译、以及 VQA 等
简单来讲,BLIP的主要特点是结合了encoder和decoder,形成了统一的理解和生成多模态模型。再利用BLIP进行后续工作的时候,既可以使用其理解的能力(encoder),又可以利用其生成的能力(decoder),拓展了多模态模型的应用
1.2.1 BLIP的模型结构
CLIP 采用了 image-encoder (ViT / ResNet) & text-encoder (transformer),然后直接拿 图片特征 和 文本特征 做余弦相似度对比,得到结果,而BLIP 的做法要复杂挺多
如下图所示,为了预训练一个同时具有理解和生成能力的统一模型,BLIP模型主要由4个部分组成,从左至右分别是
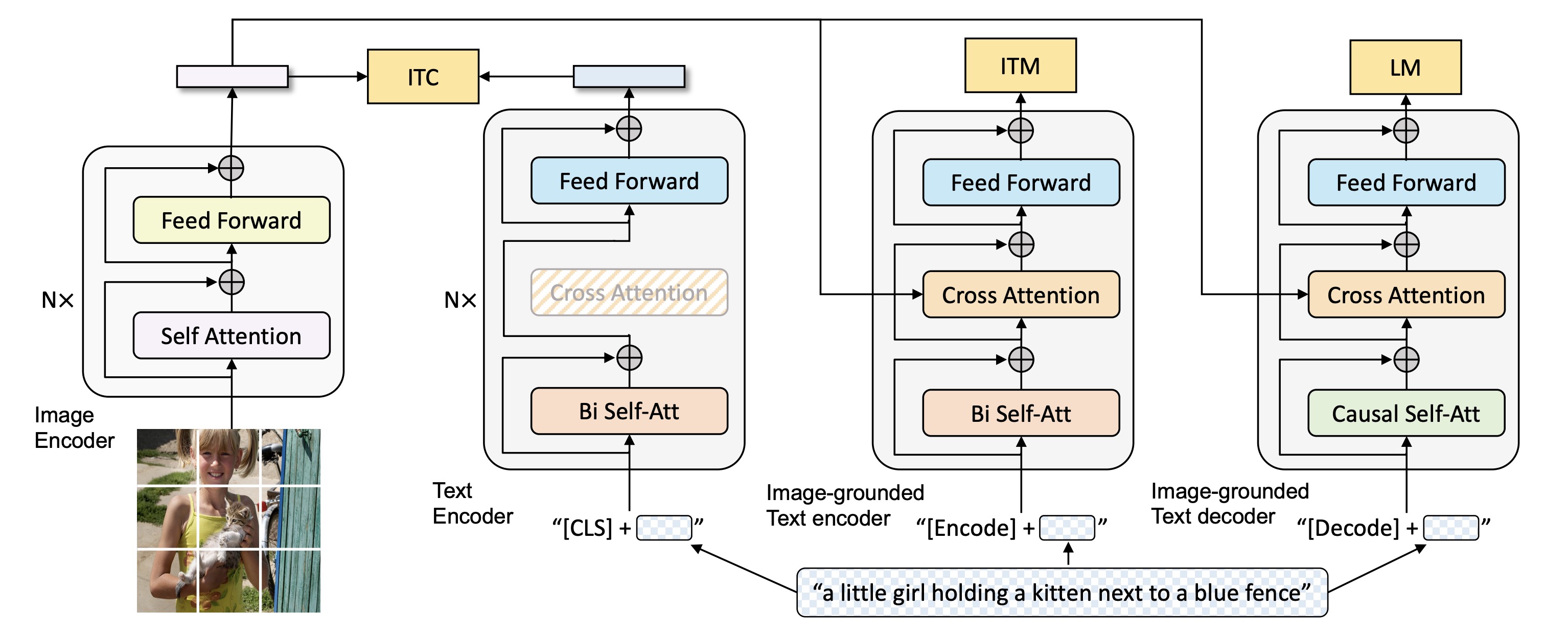
- 上图第1部分:视觉编码器Image Encoder(ViT)——提取图片特征
视觉编码器本质就是 ViT 的架构:将输入图像分割成一个个的 Patch 并将它们编码为一系列 Image Embedding,并使用额外的 [CLS] token 来表示全局的图像特征 - 上图第2部分:文本编码器Text Encoder(BERT)——提取文本特征
文本编码器就是 BERT 的架构,其中 [CLS] token 附加到文本输入的开头以总结句子,作用是提取文本特征与第1部分的图像特征做对比学习
在这个过程中会训练一个对比学习目标函数 (Image-Text Contrastive Loss, ITC)
ITC 作用于第1部分的视觉编码器(ViT)和第2部分的文本编码器(BERT),目标是对齐视觉和文本的特征空间,方法是使得正样本图文对的相似性更大,负样本图文对的相似性更低,在 ALBEF 里面也有使用到。作者在这里依然使用了 ALBEF 中的动量编码器,它的目的是产生一些伪标签,辅助模型的训练
为方便对比,把BLIP的模型结构图再贴一遍
- 上图第3部分:视觉文本编码器Image-grounded Text Encoder(变种 BERT)——BERT中插入交叉注意层,从而针对图片特征和文本特征做二分类
视觉文本编码器的具体做法是在文本编码器比如BERT的每个transformer block的自注意(Bi Self-Att)层和前馈网络(Feed Forward)之间额外插入一个交叉注意(Cross-Attention),以引入视觉特征,作用是根据 ViT 给的图片特征和文本输入做二分类,所以使用的是编码器,且注意力部分是双向的 Self-Attention,且添加一个额外的 [Encode] token,作为图像文本的联合表征
在这个过程中则训练一个图文匹配目标函数 (Image-Text Matching Loss, ITM)
ITM 作用于第1部分的视觉编码器和第3部分的视觉文本编码器,是一个二分类任务,目标是学习图像文本的联合表征,使用一个分类头来预测 image-text pair 的 正匹配 还是 负匹配,目的是学习 image-text 的多模态表示,调整视觉和语言之间的细粒度对齐,作者在这里依然使用了 ALBEF 中的 hard negative mining 技术
- 上图第4部分:视觉文本解码器Image-grounded Text Decoder(变种 BERT)——根据图片特征和文本特征做文本生成
视觉文本解码器使用 Cross-Attention,作用是根据 ViT 给的图片特征和文本输入做文本生成的任务,所以使用的是解码器,且将 上图第3部分的 Image-grounded Text Encoder 结构中的 Bi Self-Att 替换为 Causal Self-Att,目标是预测下一个 token,且添加一个额外的 [Decode] token 和结束 token,作为生成结果的起点和终点
一个需要注意的点是:相同颜色的部分是参数共享的,即视觉文本编码器和视觉文本解码器共享除 Self-Attention 层之外的所有参数。每个 image-text 在输入时,image 部分只需要过一个 ViT 模型,text 部分需要过3次文本模型
过程中训练一个语言模型目标函数 (Language Modeling Loss, LM)
毕竟由于BLIP 包含解码器,用于生成任务。既然有这个任务需求,那就意味着需要一个针对于生成任务的语言模型目标函数,LM 作用于第1部分的视觉编码器和第4部分的视觉文本解码器,目标是根据给定的图像以自回归方式来生成关于文本的描述。与 VLP 中广泛使用的 MLM 损失(完形填空)相比,LM 使模型能够将视觉信息转换为连贯的字幕
1.2.2 BLIP的字幕与过滤器方法CapFiltg
上述整个过程中,有一个不可忽略的问题,即高质量的人工注释图像-文本对(例如,COCO) 因为成本高昂所以数量不多
- CLIP 的数据来源于 Web 上爬来的 图像-文本对
,所以数据集很容易扩充的很大,而且采用 对比学习的方式,基本属于自监督了,不太需要做数据标注;
- BLIP 改进了 CLIP 直接从 Web 取数据 噪声大 的缺点,提出了 Captioning and Filtering (CapFilt) 模块,这个模块就是用来 减小噪声、丰富数据的,主要包括两个模块:即字幕与过滤器方法CapFilt (Captioning and Filtering)
如下图所示
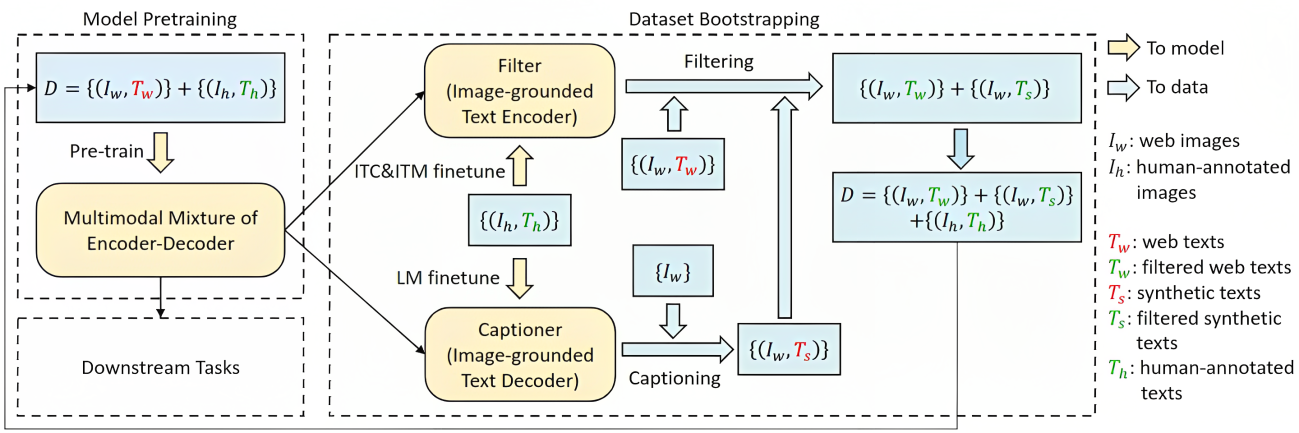
CapFilt 方法包含两个模块:
- 字幕器 Captioner:相当于给一张网络图片,生成字幕。它是一个视觉文本解码器(对应于上述BLIP模型结构的第4部分),在 COCO数据集上使用 LM 目标函数微调,对给定图像的文本进行解码,从而实现给定网络图片
,Captioner 生成字幕
的效果
- 过滤器 Filter:过滤掉噪声图文对image-text pair,它是一个视觉文本编码器(对应于上述BLIP模型结构的第3部分),看文本是否与图像匹配,在 COCO 数据集上使用 ITC 和 ITM 目标函数微调
Filter 删除原始 Web 文本和合成文本
最后,将过滤后的图像-文本对与人工注释对相结合,形成一个新的数据集,作者用它来预训练一个新的模型
下图展示了被过滤器接受和拒绝的文本可视化(绿色 文本是被 filter 认可的,而 红色 文本是被 filter 拒绝的)

1.3 BLIP2:Q-Former连接视觉模型CLIP ViT-G/14和语言模型FLAN-T5
1.3.0 两阶段训练:先做视觉-语言的表示学习,后做视觉到语言的生成学习
为了实现与冻结的单模态模型的有效视觉语言对齐,23年1月,来自Salesforce Research的研究者提出了一种查询Transformer(即Query Transformer,或Q-Former)
下图是BLIP-2的模型结构「论文地址:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models」
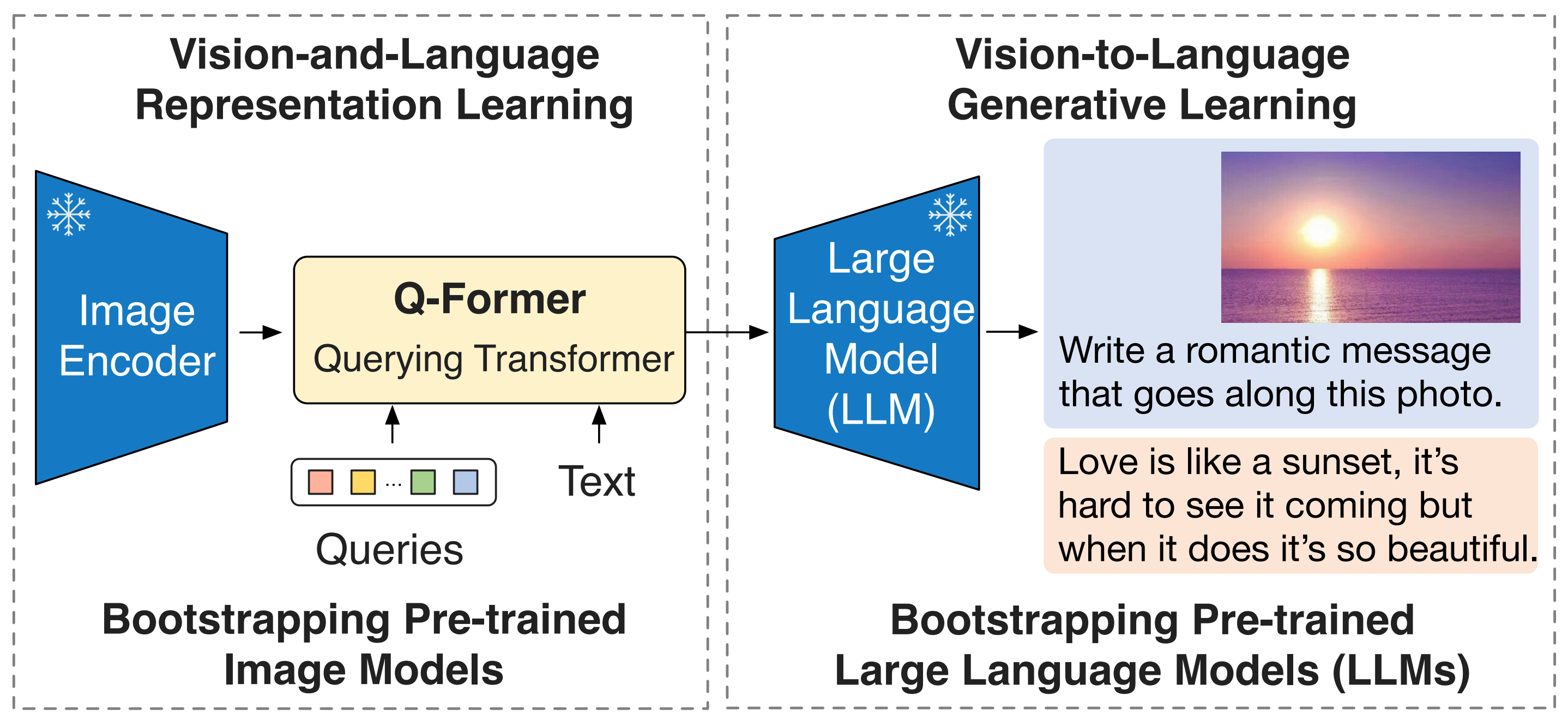
其视觉侧和文本侧分别使用预训练的CLIP ViT-G/14模型和FLAN-T5模型(从T5微调来的编码器-解码器LLM),仅中间的起桥接作用的Q-Former参与训练「如此,让BLIP-2的训练数据量仅129M,16卡A100训练9天」
其中的Q-Former 是一种轻量级的Transformer,且训练阶段分为表示学习、和生成学习两个阶段
- 在第一个预训练的「视觉-语言的表示学习」阶段(连接到一个冻结的图像编码器,并使用图像-文本对进行预训练)
该阶段强制Q-Former学习与文本最相关的视觉表示——使用一组可学习的查询向量从冻结的图像编码器中提取视觉特征
它作为冻结图像编码器与冻结LLM之间的information bottleneck,将最有用的信息传递给后续模块 - 在第二个预训练的「视觉到语言生成学习」阶段,通过将Q-Former的输出连接到一个冻结的LLM来进行从视觉到语言的生成学习
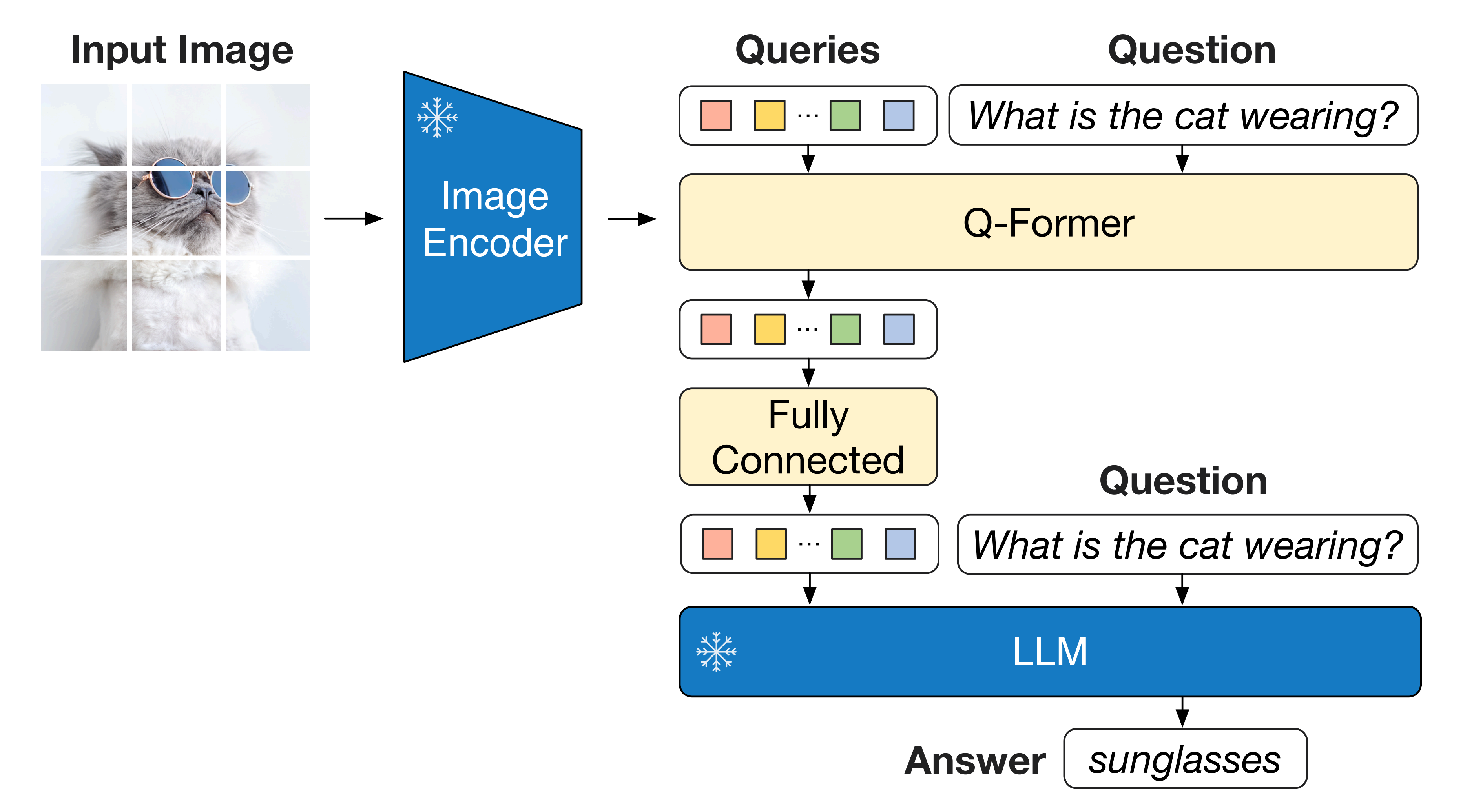
比如下图是用于VQA微调的模型架构,首先,将问题作为条件提供给Q-Former,以便提取的图像特征与问题更加相关,其次,LLM接收Q-Former的输出和问题作为输入,最后预测答案
1.3.1 第一阶段:Q-Former中的视觉Transformer从ViT中提取与文本最相关的图像特征
总之,Q-Former作为一个可训练的模块,用于弥合冻结图像编码器和冻结大语言模型(LLM)之间的差距,它从图像编码器中提取固定数量的输出特征,与输入图像的分辨率无关
如图2所示,Q-Former由两个共享相同自注意力层的Transformer子模块组成:
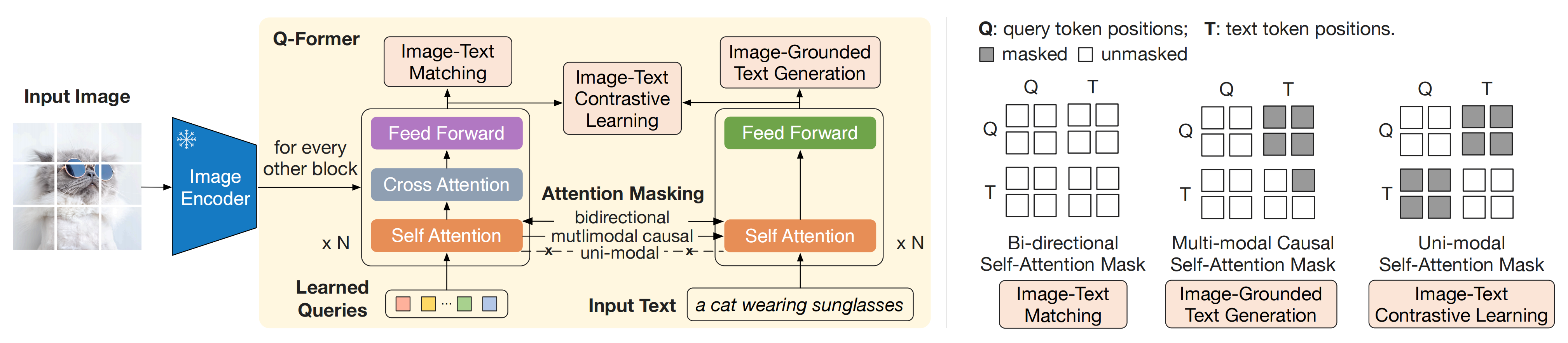
- 一个与冻结图像编码器交互的图像Transformer用于视觉特征提取
作者创建了一定数量的可学习查询嵌入作为图像Transformer的输入。这些查询通过自注意力层相互作用,并通过交叉注意力层(插入在每隔一个Transformer块中)与冻结的图像特征交互
且受BLIP (Li et al., 2022) 的启发,作者联合优化三个共享相同输入格式和模型参数的预训练目标。每个目标采用不同的查询与文本之间的注意力屏蔽策略来控制它们的交互(见上图图2的右侧)
- 图文对比学习(Image-Text Contrastive Learning-ITC)
旨在对齐图像表示和文本表示,使其互信息最大化。它通过将正对的图文相似性与负对的相似性进行对比来实现这一目标
即将图像Transformer输出的查询表示与从文本Transformer中提取的文本表示
对齐,其中 t是[CLS] token的输出token
由于Z包含多个输出嵌入(每个查询一个),作者首先计算每个查询输出和
为了避免信息泄露,他们采用单模态的自注意力掩码,其中查询和文本不能相互看到。由于使用了冻结的图像编码器,与端到端方法相比,可以在每个GPU上放置更多样本。因此,使用批内负样本,而不是BLIP中的动量队列
- 图像-文本生成(Image-grounded Text Generation-ITG)
损失用于训练Q-Former,在给定输入图像作为条件的情况下生成文本。由于Q-Former的架构不允许冻结的图像编码器与文本token直接交互,因此,生成文本所需的信息必须首先由查询(query)提取,然后通过自注意力层传递给文本token
因此,查询被迫提取能够全面反映文本信息的视觉特征。具体而言,作者使用一种多模态因果自注意掩码来控制查询(query)与文本的交互方式,类似于UniLM(Dong等人,2019)中使用的掩码
查询之间可以相互关注,但不能关注文本token。每个文本token可以关注所有查询以及其之前的文本token。且还用新的[DEC] token替换了[CLS] token,作为第一个文本token,以指示解码任务- 图文匹配(Image-Text Matching-ITM)
旨在学习图像与文本表示之间的细粒度对齐关系
这是一个二分类任务,模型需要预测图文对是正样本(匹配)还是负样本(不匹配)
且使用双向自注意力掩码,使所有查询和文本能够相互关注。输出的查询嵌入Z因此捕获多模态信息。且将每个输出查询嵌入输入到一个二分类线性分类器中以获得一个logit,并对所有查询的logit取平均,作为最终的匹配分数
其采用来自Li等人(2021; 2022)提出的难负样本挖掘策略来构建具有信息量的负样本对
- 一个文本Transformer,可以同时作为文本编码器和文本解码器
这些查询嵌入还可以通过相同的自注意力层与文本交互
根据预训练任务的不同,应用不同的自注意力掩码来控制查询与文本的交互。比如用BERTbase的预训练权重初始化Q-Former,而交叉注意力层是随机初始化的「Q-Former总共包含188M参数。注意,这些查询被视为模型参数」
具体而言,作者使用了32 个查询,每个查询的维度为768(与Q-Former 的隐藏维度相同),且用Z 表示输出的查询表示。Z (32 × 768) 的大小远小于冻结图像特征的大小(例如,ViT-L/14 的257 × 1024)。这种瓶颈架构与预训练目标相结合,迫使查询提取与文本最相关的视觉信息
1.3.2 第二阶段:从冻结的LLM中引导生成视觉到语言的学习
在生成预训练阶段,作者将 Q-Former(连接上冻结的图像编码器)与一个冻结的大语言模型LLM连接,以利用LLM的生成语言能力
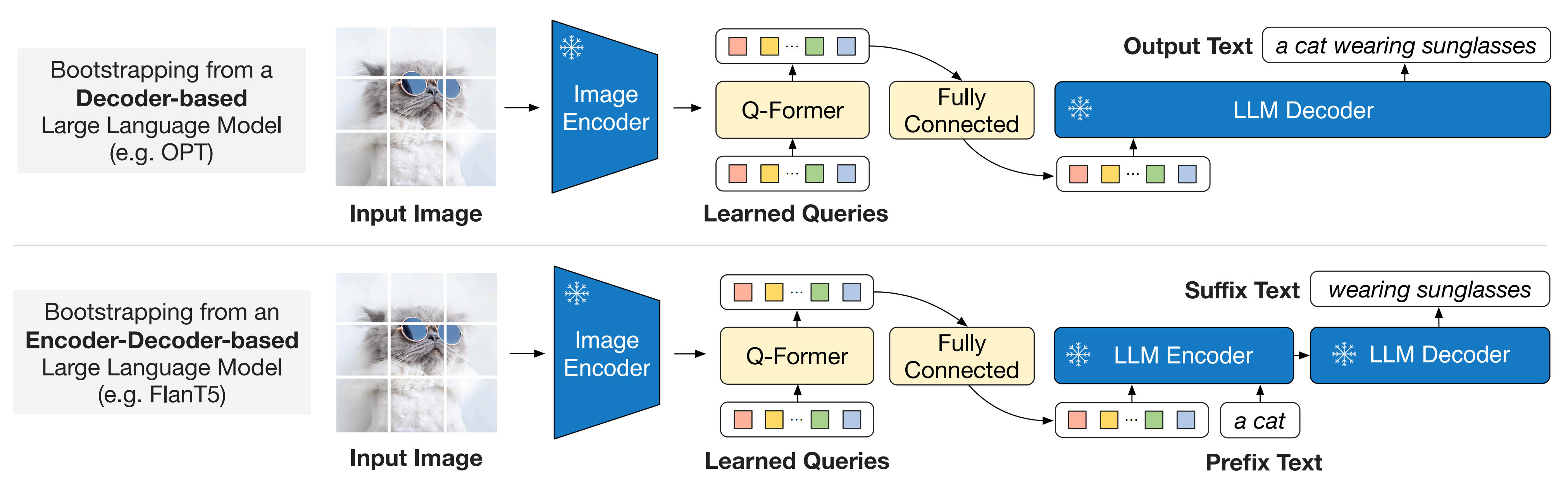
- 如图 3所示,他们使用一个全连接(FC)层将输出查询嵌入 Z 线性投影到与 LLM 的文本嵌入相同的维度
然后将投影后的查询嵌入预置到输入文本嵌入之前。它们作为软视觉提示,基于Q-Former 提取的视觉表示来调整 LLM - 由于Q-Former已被预训练为提取与语言相关的视觉表征,因此它有效地充当了information bottleneck,只向LLM传递最有用的信息,同时过滤掉无关的视觉信息。这减少了LLM进行视觉-语言对齐的负担,从而缓解了灾难性遗忘问题
且作者对两种类型的大型语言模型进行了实验:基于解码器的LLM和基于编码器-解码器的LLM
- 对于基于解码器的LLM,通过语言建模损失进行预训练,其中冻结的LLM需要在Q-Former生成的视觉表征条件下生成文本
- 对于基于编码器-解码器的LLM,通过前缀语言建模损失进行预训练,将一段文本分为两部分
1.3.3 模型预训练的相关设置:预训练数据、冻结的图像编码器与LLM
第一,对于预训练数据
作者使用与BLIP相同的预训练数据集
- 总共包含129M张图像,包括COCO (Lin et al.,2014)、Visual Genome (Krishna et al., 2017)、CC3M (Sharma et al., 2018)、CC12M (Changpinyoet al., 2021)、SBU (Ordonez et al., 2011),以及来自LAION400M数据集 (Schuhmann et al., 2021) 的115M张图像
- 采用CapFilt方法 (Li et al., 2022)为网络图像生成合成的标题
具体来说,使用 BLIP large 描述模型生成 10 个描述,然后根据 CLIP ViT-L/14 模型生成的图像 - 文本相似度对合成描述和原始网络描述进行排序。每张图片保留排名前两位的描述作为训练数据,并在每次预训练步骤中随机抽取一个
第二,对于预训练的图像编码器和大语言模型
在冻结的图像编码器上,作者探索了两种最先进的预训练视觉转换器模型:
- 来自CLIP(Radford等人,2021)的ViT-L/14
- 来自EVA-CLIP(Fang等人,2022)的ViT-g/14
且他们移除了ViT的最后一层,并使用了倒数第二层的输出特征:由此 带来了略微更好的性能
对于冻结的语言模型,作者探索了
- 无监督训练的OPT模型家族(Zhang等人,2022)用于基于解码器的大语言模型
- 以及指令训练的FlanT5模型家族(Chung等人,2022)用于基于编码器-解码器的大语言模型
第三,对于预训练设置
- 作者在第一阶段预训练25万步,在第二阶段预训练8万步。且在第一阶段对ViT-L/ViT-g使用2320/1680的批量大小,在第二阶段对OPT/FlanT5使用1920/1520的批量大小
- 另,在预训练过程中,作者将冻结的ViT和LLM的参数转换为FP16,但对FlanT5使用BFloat16。结果发现,与使用32位模型相比,性能没有下降
- 由于使用冻结模型,预训练比现有的大规模VLP方法更具计算友好性
例如,使用一台16-A100(40G)机器,我们最大的模型(包含ViT-g和FlanT5-XXL)在第一阶段需要不到6天,在第二阶段需要不到3天
顺带说下
- 后来的LLAVA仅通过一个projection layer将CLIP ViT-L/14和Vicuna语言模型缝合在一起,训练数据仅用了595K图文对以及158K指令微调数据
- miniGPT4则是在复用BLIP-2的vision encoder + Q-Former的基础上,通过一层project layer缝合了Vicuna语言模型,训练数据仅用了5M的图文对数据+3.5K的指令微调数据
1.4 InstructBLIP:BLIP-2的指令微调版,增强了BLIP-2的指令遵循能力
1.4.1 InstructBLIP的结构及其对BLIP-2的改造
InstructBLIP 「其对应的的论文为《InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning》」
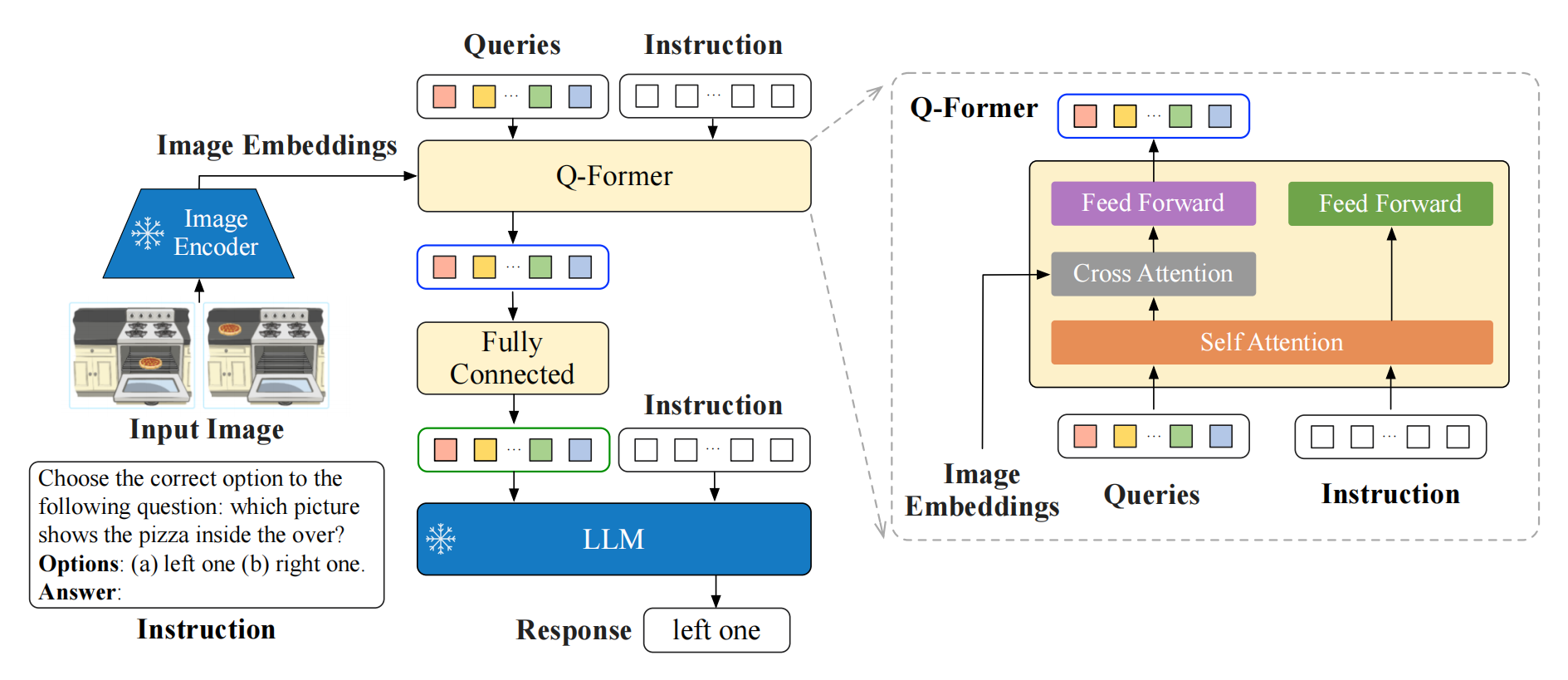
- 其与BLIP-2 [20]类似的是 ,InstructBLIP也使用了一个查询变换器(Query Transformer,或Q-Former)从一个冻结的图像编码器中提取视觉特征
- 但不同于BLIP-2「在提取视觉特征时采用了一种与指令无关的方法。这导致无论任务如何,都会有一组静态的视觉表示被输入到语言模型中,即BLIP-2, take an instruction-agnostic approach when extracting visual features. That results in a set of static visual representations beingfed into the LLM, regardless of the task」
InstructBLIP作为一个指令感知的视觉模型可以根据任务指令进行调整,并生成最适合当前任务的视觉表示「即In contrast, an instruction-aware vision model can adapt to the task instruction and produce visual representations most conducive to the task at hand.」
毕竟如果对于相同的输入图像,而预计任务指令会有很大差异,那么这显然是更好的
那怎么做到呢?核心在于InstructBLIP 提出了一个支持指令的 Q-former 模块——说白了,本质就是对Q-Former做了专门的指令微调,过程中图像编码器和LLM是被冻结不变的
具体而言
- 如上图右侧所示,Q-Former的输入包含一组K个可学习的查询嵌入,且将指令文本token作为额外输入
首先,用户提供的指令instruction 通过 Q-Former 的自注意力层 与查询嵌入query embedding做自注意力交互,从而促进提取与任务指令相关的图像特征
其次,这些(查询)嵌入通过交叉注意力与图像编码器的输出Image Embeddings交互- 如上图中侧所示,Q-Former的输出由K个编码的视觉向量组成,每个查询嵌入对应一个视觉向量,这些向量随后通过线性投影并输入到冻结的LLM中
且与BLIP-2一样,Q-Former使用图像-字幕数据进行两阶段的预训练
- 第一阶段使用冻结的图像编码器对 Q-Former 进行预训练,以进行视觉语言表示学习
The first stage pretrains the Q-Former with the frozen image encoder forvision-language representation learning.- 第二阶段将Q-Former的输出适配为软视觉提示,用于冻结的大型语言模型LLM的文本生成
The second stage adapts the output of Q-Former as soft visual prompts for text generation with a frozen LLM .在预训练之后,通过指令微调对Q-Former进行微调,其中LLM接收来自Q-Former的视觉编码和任务指令作为输入
1.4.2 实现细节:视觉编码器ViT-g/14 + 语言模型FlanT5/Vicuna
首先,在架构上
得益于 BLIP-2 模块化架构设计所提供的灵活性,使得可以快速适配模型到各种大型语言模型
在InstructBLIP的实验中,作者采用了4种不同的 BLIP-2 变体,这些变体使用相同的图像编码器(ViT-g/14 [10]),但冻结了不同的 LLM,包括
- FlanT5-XL-3B
FlanT5 [7] 是一种基于编码器-解码器 Transformer T5 [34] 的指令调优模型 - FlanT5-XXL-11B
- Vicuna-7B
Vicuna[2] 是一种基于 LLaMA [41] 的仅解码器 Transformer 指令调优模型
在视觉语言指令调优过程中,作者从预训练的 BLIP-2 检查点初始化模型,并且仅微调 Q-Former 的参数,同时保持图像编码器和 LLM 冻结状态
由于原始 BLIP-2 模型不包括Vicuna 的检查点,故使用与 BLIP-2 相同的过程对 Vicuna 进行预训练 - Vicuna-13B
其次,对于训练和超参数
- 作者使用LAVIS 库[19] 进行实现、训练和评估。所有模型均经过指令微调,最多进行60K 步,并在每3 K 步验证模型性能
- 对于每个模型,选择一个最佳的检查点,并用于所有数据集的评估
且分别为3B、7B 和11/13B 模型采用192、128 和64 的批量大小
使用AdamW [26] 优化器,其中β1 = 0.9, β2 = 0.999,权重衰减为0.05 - 此外,在最初的1,000 步中应用学习率的线性预热,从10−8 增加到10−5,随后使用余弦衰减,最低学习率为0
- 所有模型均使用16 块Nvidia A100 (40G) GPU 进行训练,并在1.5 天内完成
1.5(选读) MiniGPT4:基于LLaMA微调的Vicuna + BLIP2 + 线性投影层
MiniGPT-4具有许多类似于GPT-4所展示的功能,如详细的图像描述生成和从手写草稿创建网站,以及根据给定图像编写灵感的故事和诗歌,为图像中显示的问题提供解决方案,比如教用户如何根据食物照片烹饪等
1.5.1 模型结构
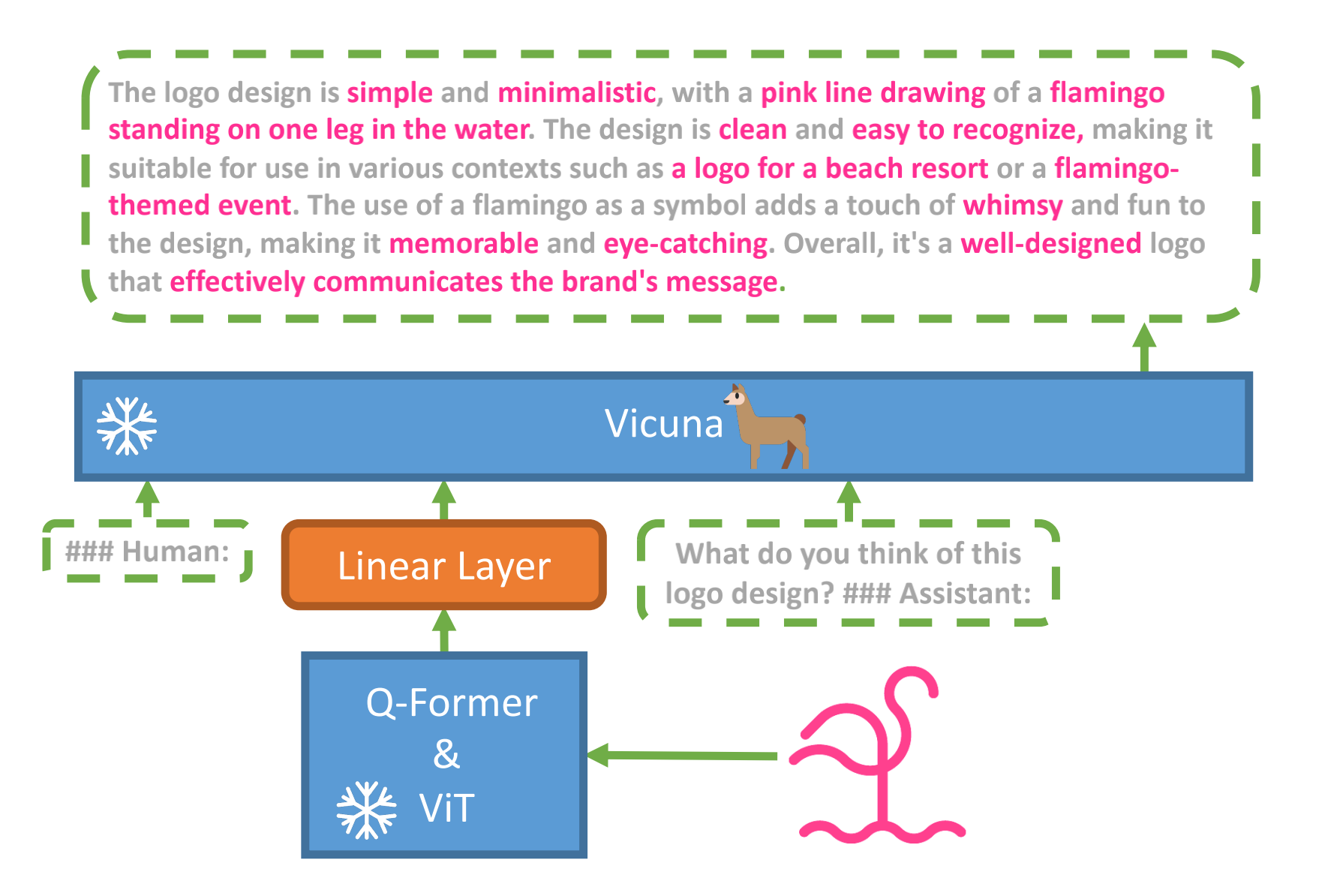
miniGPT4的模型架构由一个语言模型拼接一个视觉模型,最后加一个线性投影层来对齐,具体而言
-
它先是使用基于LLaMA微调的小羊驼Vicuna,作为语言解码器
-
在视觉感知方面,采用了与BLIP-2相同的预训练视觉组件(该组件由EVA-CLIP[13]的ViT- G/14和Q-Former组成)
-
再之后,增加了一个单一的投影层,将编码的视觉特征与语言模型小羊驼对齐,并冻结所有其他视觉和语言组件
1.5.2 模型训练:预训练(500万图像文本对)-微调
训练上,还是经典的预训练-微调模式
- 在整个预训练过程中,无论是预训练的视觉编码器还是LLM都保持冻结状态,只有线性投影层被预训练。具体是使用Conceptual Caption、SBU和LAION的组合数据集来训练我们的模型,历经2万个训练步骤,批大小为256,覆盖了大约500万对图像-文本,整个过程花费大约10小时,且使用的4个A100 (80GB) gpu
- 然而,简单地将视觉特征与LLM对齐不足以训练出像聊天机器人那样具有视觉会话能力的高性能模型,并且原始图像-文本对背后的噪声可能导致语言输出不连贯。因此,我们收集了另外3500个高质量对齐的图像-文本对,用设计好的会话模板进一步微调模型(只需要400个训练步骤,批量大小为12,使用单个A100 GPU最终7分钟即可完成),以提高生成语言的自然度及其可用性
// 待更
第二部分 SigLIP的详解
2.1 SigLIP提出的背景与其整体思路
2.1.1 SigLIP提出的背景:改进训练损失函数
自从CLIP [36] 和 ALIGN [23] 将 softmax 对比学习 [60,46,10,24] 应用于大规模图文数据集以来,对比式语言-图像预训练变得十分流行
而预训练CLIP这类模型的标准方法利用图像-文本对比目标,即它对匹配的(正向)图文对的图像和文本嵌入进行对齐,同时确保不相关的(负向)图文对在嵌入空间中差异明显『It aligns the image and text embeddings for matching (positive) image-text pairs while making sure that unrelated (negative) image-text pair sare dissimilar in the embedding space』
- 这一目标通过批级别的基于 softmax 的对比损失实现,该损失被应用两次,分别对 “所有图像和所有文本的成对相似度分数” 进行归一化
- 然softmax的简单实现在数值上是不稳定的;通常通过在应用 softmax 之前减去最大输入值来进行数值稳定化 [18],这需要对整个批次再进行一次遍历
对此,各类研究者在各自的角度在softmax对比预训练外,提出了各种替代方案
- GIT [49]、SimVLM [50] 和LEMON [21] 成功地使用生成文本解码器对模型进行预训练
而CoCa [56] 则在判别性CLIP/ALIGN设置中添加了这样的解码器,从而将两种方法的优缺点结合到一个非常强大的模型中 - BLIP [28] 进一步提出了CapFilt,使用生成解码器创建更好的字幕,并使用模型的判别部分过滤对
- LiT [59] 和FLIP [30] 是值得关注的尝试, 前者需要一个预训练并锁定的主干网络,后者通过随机丢弃视觉token来牺牲质量
- BASIC [35] 和 LAION [52] 关注于扩大批量大小,但分别仅达到16k和160k,使用数百个芯片,并且前者还混合了一个大型私有分类数据集 [35,55]
- 最近的Lion优化器 [12]声称能够降低训练成本以达到类似的质量
2.1.2 SigLIP:用sigmoid损失代替标准softmax损失
而Google提出了一种更简单的替代方案:sigmoid损失, 其对应的论文为《Sigmoid Loss for Language Image Pre-Training》,其作者为:Xiaohua Zhai, Basil Mustafa, Alexander Kolesnikov, Lucas Beyer「有意思的是,其中标粗的同时也是ViT、PaliGemma的作者」
- 它不需要跨整个批次的操作,因此极大地简化了分布式损失的实现并提高了效率。此外,它在概念上将批次大小与任务定义解耦
且作者将提出的sigmoid损失与标准softmax损失在多个设置中进行比较 - 特别是,作者研究了基于sigmoid的损失,并且与两个有前景的不同的方法用于图像-文本学习:CLIP [36] 和LiT[59],分别称之为sigmoid语言图像预训练(SigLIP)和sigmoid LiT(SigLiT)
which we call sigmoid language image pretraining (SigLIP) and sigmoid LiT (SigLiT) - 作者发现,当批量大小小于16k 时,sigmoid 损失比softmax 损失表现显著更好。随着训练批量大小的增加,这一差距缩小。重要的是,sigmoid 损失是对称的,只需一次遍历,并且典型实现所需内存比softmax 损失少。这使得在一百万的批量大小下成功训练SigLiT 模型成为可能
然而,作者发现随着批量大小的增加,无论是softmax 还是sigmoid,其性能都会饱和
好消息是,一个合理的批量大小,即32k,对于图像-文本预训练已经足够
这一结论同样适用于超过100 种语言的多语言SigLIP 训练的情况
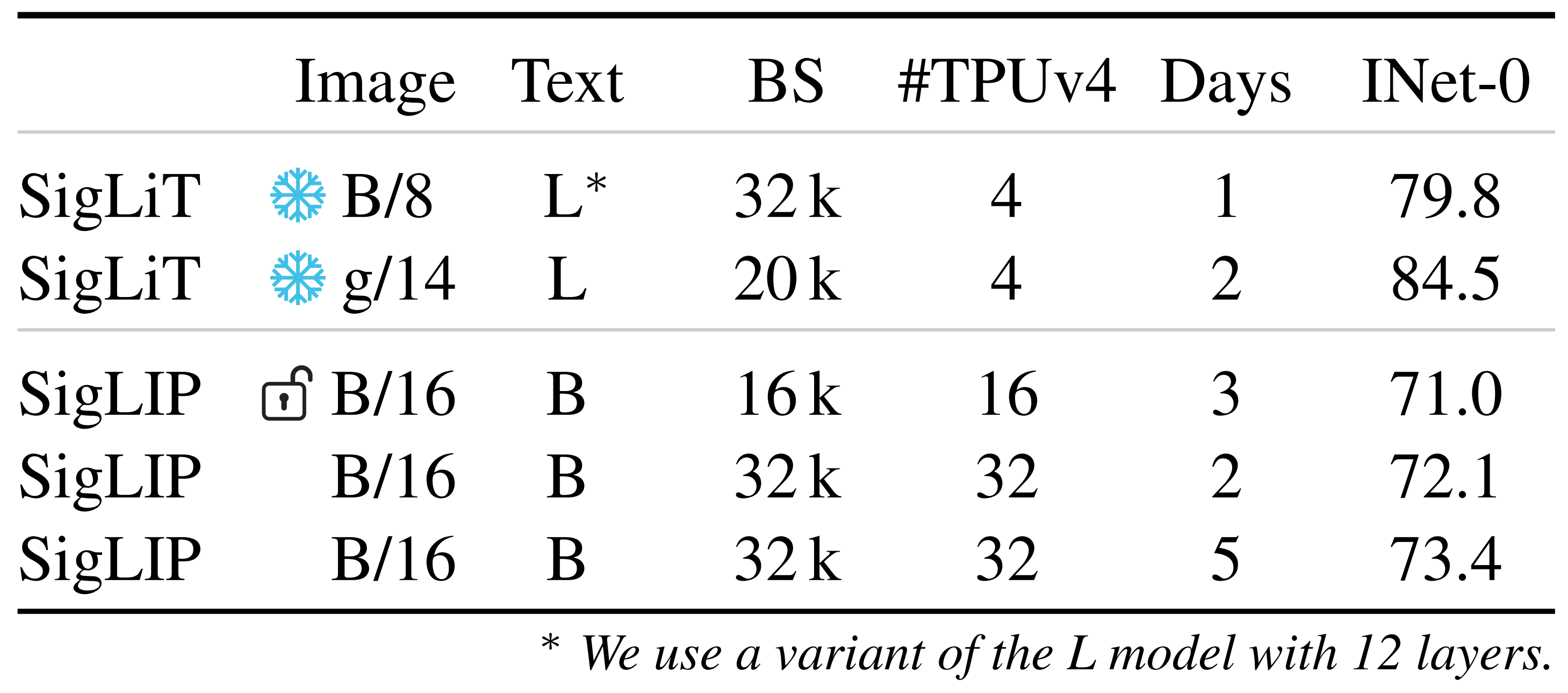
在下表表1中,作者展示了图像-文本预训练的设置,这些设置需要适量的TPUv4芯片进行训练
- SigLiT的效率令人惊讶,仅在四个芯片上用一天时间就达到了ImageNet上的79.7%零样本准确率
SigLIP从头开始的更高要求训练在5天内用32个TPUv4芯片达到了73.4%的零样本准确率- 这与之前的工作相比有优势,例如FLIP [30]和CLIP [36],它们分别需要大约5天和10天在256个TPUv3核心上进行
当在SigLIP中微调预训练的视觉骨干时,表示为在表1中,发现禁用预训练骨干上的权重衰减会带来更好的结果
2.2 softmax损失与sigmoid损失的详细对比
给定一个图像-文本对的小批量,对比学习目标鼓励匹配对
的嵌入相互对齐,同时将不匹配对
的嵌入分开
此举会假设对于所有图像,与不同图像
相关联的文本
与
无关,反之亦然。这个假设通常是有噪声和不完美的
2.2.1 用于语言图像预训练的Softmax损失
在使用softmax 损失来形式化此目标时,图像模型和文本模型
被训练以最小化以下目标
其中,、
在本文中,作者采用视觉transformer 架构[17] 用于图像,采用transformer 架构[47] 用于文本。注意,由于softmax 损失的不对称性,归一化独立地进行了两次:一次针对图像,一次针对文本[36]。标量 被参数化为
,其中
是一个全局可自由学习的参数
2.2.2 用于语言图像预训练的Sigmoid损失
作者提出了一种更简单的替代方法,而不是基于softmax 的对比损失,这种方法不需要计算全局归一化因子
即基于sigmoid 的损失独立地处理每个图像-文本对,有效地将学习问题转化为所有对组合数据集上的标准二分类,其中匹配对为正标签,所有其他对
为负标签,其定义如下:
其中zij是给定图像和文本输入的标签,如果它们是配对的则等于1,否则等于-1。 在初始阶段,来自许多负值的严重不平衡主导了损失,导致初始优化步骤较大
为了解决这个问题,作者引入了一个额外的可学习偏差项,类似于温度
。作者将
和
分别初始化为
和-10。这确保了训练开始时大致接近先验,不需要大幅度的过度校正
为了解释清楚这个公式,咱们一步步来
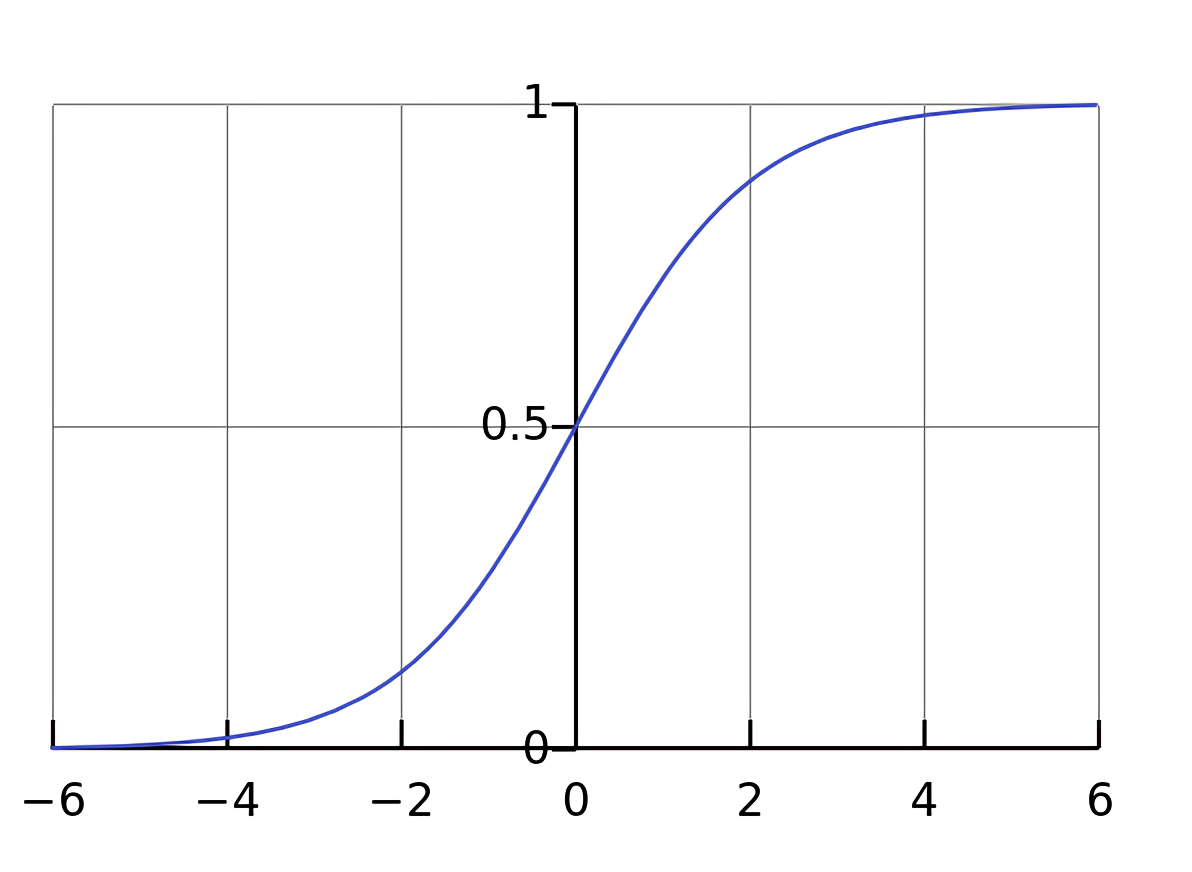
- 首先,来复习下基础知识,即什么是Sigmoid函数——其本质是将无穷映射到了0到1之间「其实在此文SVM通俗导论中有介绍过」
其示意图为该函数的表达式为
分母作为分母,其确保了函数的输出值始终在0和1之间,比如
当 x 趋向于正无穷大时,趋向于0,从而整个函数值趋向于1
当 x 趋向于负无穷大时,
在分类问题中,Sigmoid函数特别有用,因为它可以输出一个介于0和1之间的概率值,表示输入数据点属于某个类别的可能性
例如,在二分类问题中,如果Sigmoid函数的输出大于0.5,可以预测该数据点属于正类;如果输出小于0.5,则预测属于负类- 对于上面的这整个式子而言
其中,外层求和:这部分表示对一个批次(batch)中的所有样本进行平均。∣B∣ 是批次中样本的数量
内层求和:表示对批次中的每个样本与其它所有样本进行比较
损失函数:是样本 i 和样本 j 之间的损失
对数损失:是对数损失函数的一部分
其中:是一个权重,用于调整损失的强度
和
点积的影响
是一个偏置项
是
的点积,表示两个向量之间的相似度
sigmoid函数:整个对数函数内部的表达式实际上是一个sigmoid函数,它将整个函数的值映射到0和1之间,这个函数用于衡量样本 i 和样本 j 之间的相似性
「如果 xi 和 yj非常相似,意味着会是一个绝对值大的负数,导致
非常小,从而使整个sigmoid函数的值接近1,表示这两个样本非常相似
相反,如果xi和 yj 不相似,意味着
负对数损失:整个表达式前面的负号表示希望最小化这个损失函数。毕竟在机器学习中,最小化损失函数是训练模型的目标
而下面的算法1 展示了用于语言图像预训练的且基于sigmoid损失的伪代码实现
// 待更

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐


 28
28 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)