无缝融入,即刻智能[1]:MaxKB知识库问答系统,零编码嵌入第三方业务系统,定制专属智能方案,用户满意度飙升
无缝融入,即刻智能[1]:MaxKB知识库问答系统,零编码嵌入第三方业务系统,定制专属智能方案,用户满意度飙升
1.简介
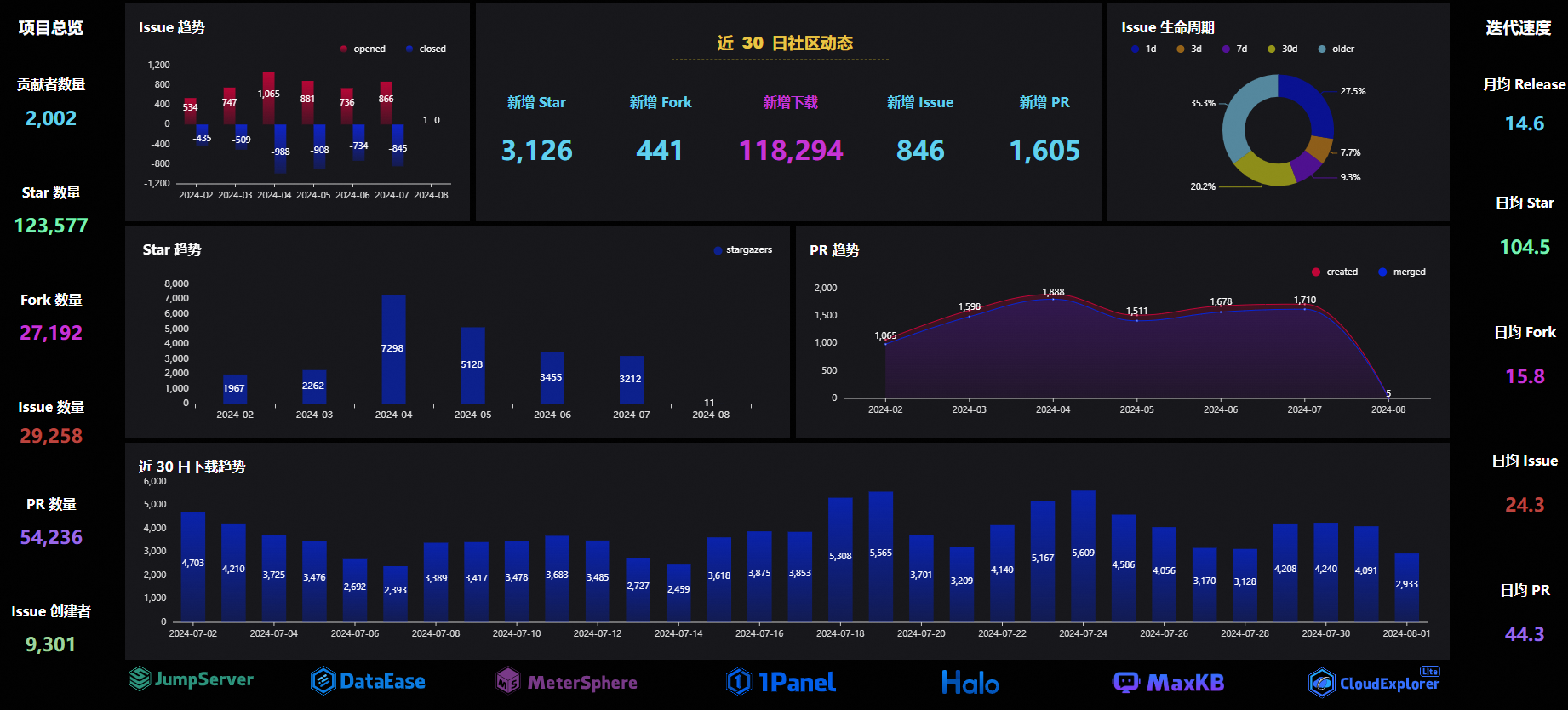
MaxKB(Max Knowledge Base)是一款基于 LLM 大语言模型的开源知识库问答系统,
飞致云是中国领先的开源软件公司。飞致云旗下开源产品包括 1Panel 开源面板、JumpServer 开源堡垒机、DataEase 开源数据可视化分析工具、MeterSphere 开源测试工具、Halo 开源建站工具、MaxKB 开源知识库问答系统等,涵盖运维面板、运维审计、BI 分析、软件测试、CMS 建站、知识库问答等多个领域。飞致云旗下的开源项目在开源社区表现出了卓越的成长性,在代码托管平台 GitHub 上所获得的 Star 总数已经超过 12 万。
-
官方网址:https://maxkb.cn/
1.1 产品优势
- 开箱即用:支持直接上传文档、自动爬取在线文档,支持文本自动拆分、向量化、RAG(检索增强生成),智能问答交互体验好;
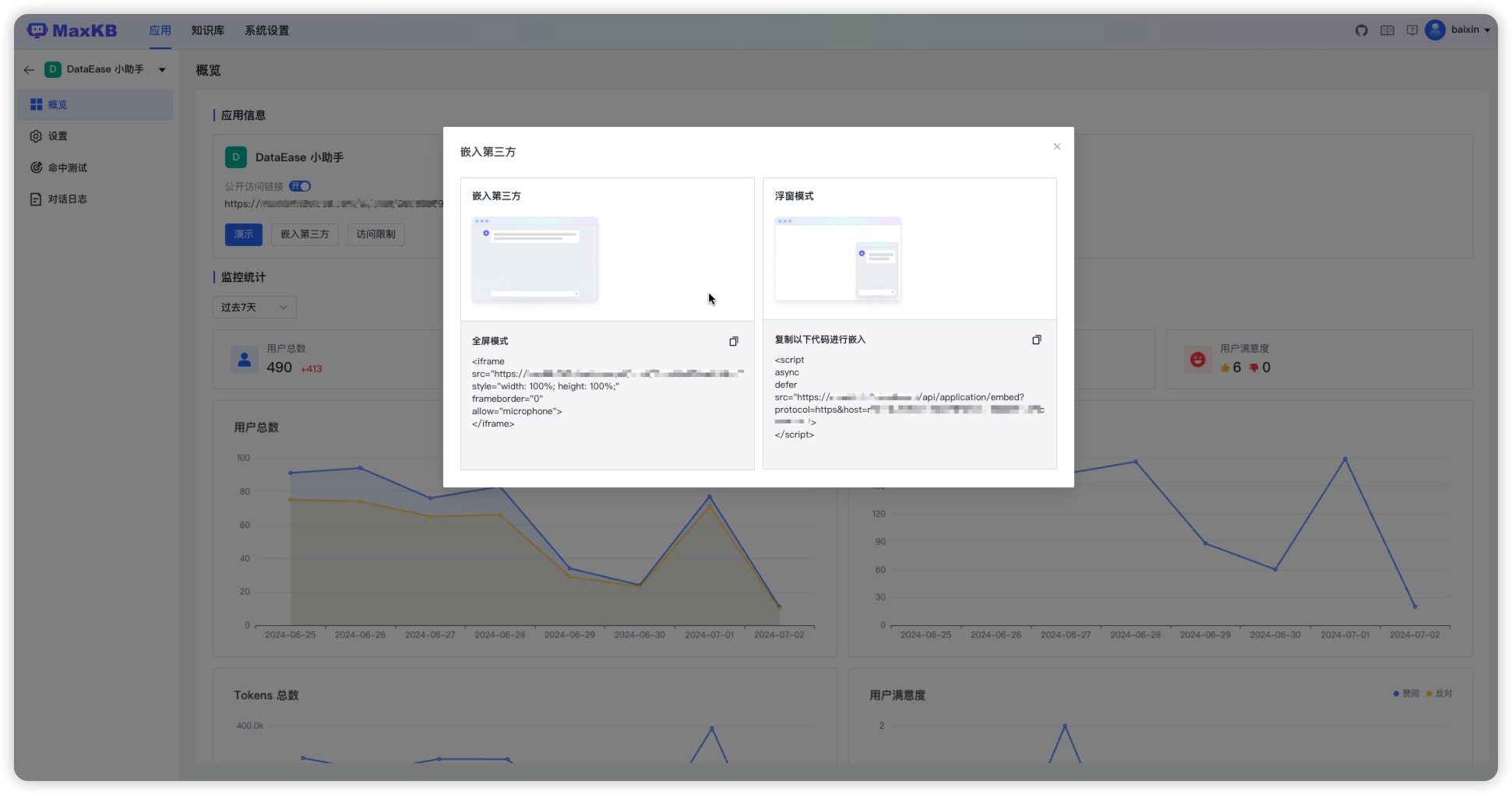
- 无缝嵌入:支持零编码快速嵌入到第三方业务系统,让已有系统快速拥有智能问答能力,提高用户满意度;
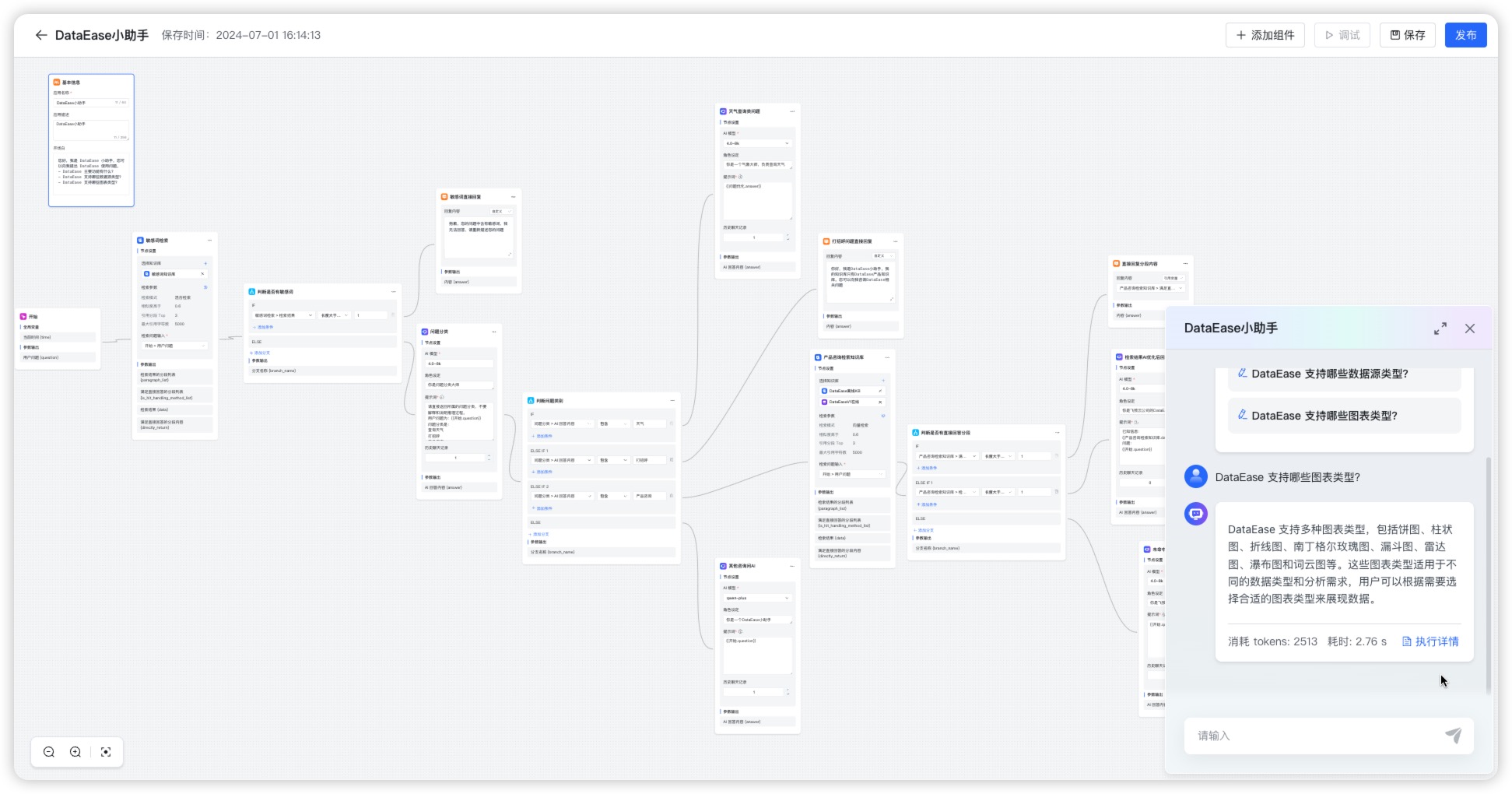
- 灵活编排:内置强大的工作流引擎,支持编排 AI 工作流程,满足复杂业务场景下的需求;
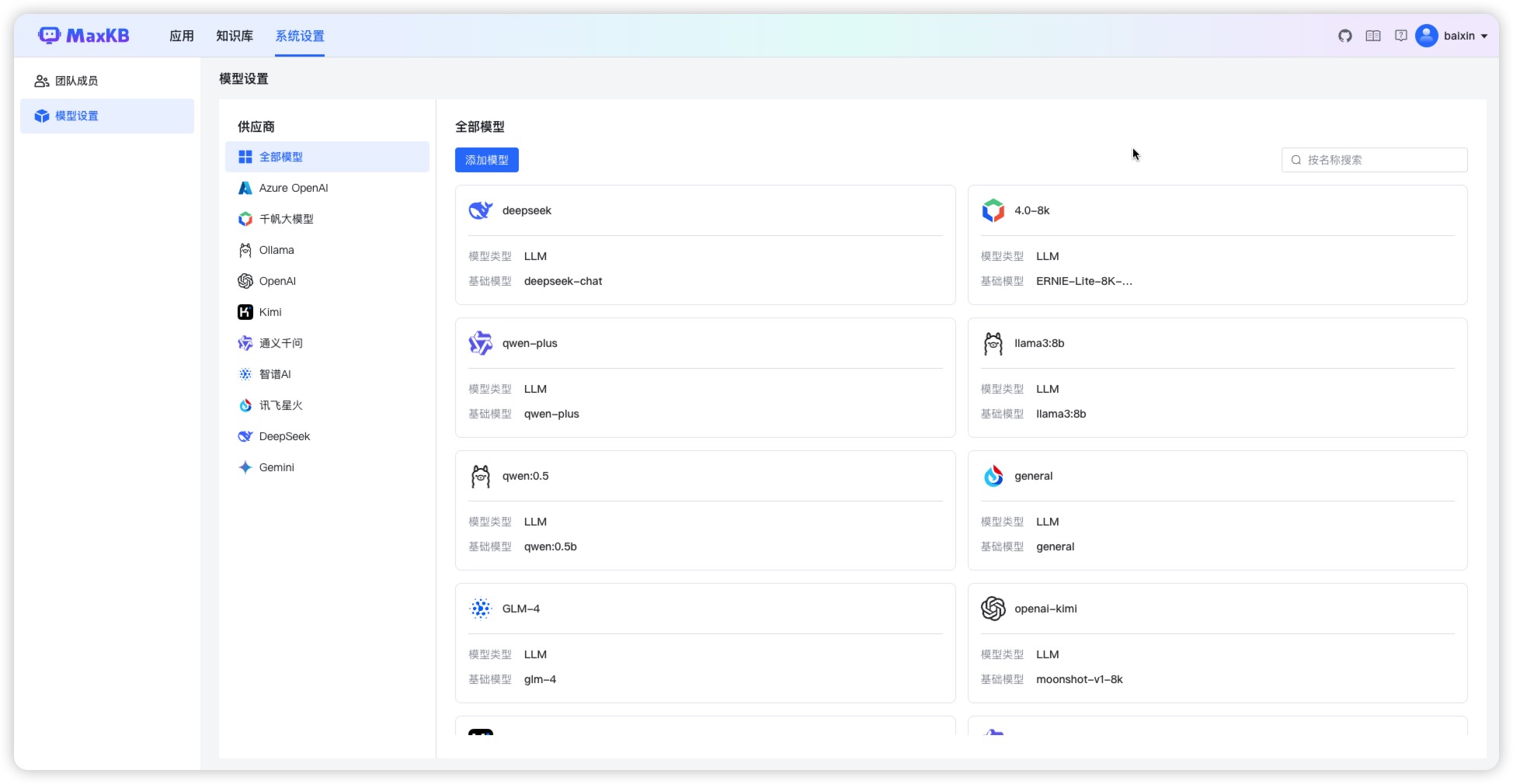
- 模型中立:支持对接各种大语言模型,包括本地私有大模型(Llama 3 / Qwen 2 等)、国内公共大模型(通义千问 / 智谱 AI / 百度千帆 / Kimi / DeepSeek 等)和国外公共大模型(OpenAI / Azure OpenAI / Gemini 等)。
记得使用最新版本!!
-
新增功能
- 【知识库】支持创建空知识库。
- 【知识库】创建和设置知识库时支持选择不同的向量模型进行向量化。
- 【模型管理】支持添加 OpenAI 、Ollama 和本地的向量模型。
- 【模型管理】支持把模型权限设置为公用或私有。
- 【应用】高级编排的指定回复节点支持快捷问题输出:快捷问题。
- 【应用】支持设置浮窗模式的对话框入口图标。(X-Pack)
- 【应用】支持自定义对话框的AI回复的头像。(X-Pack)
- 【应用】支持设置浮窗模式的对话框是否可拖拽位置。(X-Pack)
- 【应用】支持设置对话框是否显示历史记录。(X-Pack)
- 【系统设置】支持LDAP单点登录。(X-Pack)
- 【系统设置】支持自定义主题外观,设置系统的网站 logo、登录 logo、主题色、登录背景图、网站名称、欢迎语等。(X-Pack)
- 【系统设置】开放系统 API。(X-Pack)
-
功能优化
- 【知识库】优化文档索引流程,提高知识点召回率。
- 【知识库】调整分段内容最大长度为 10 万个字符。
- 【应用】调整关联知识库时只能选择使用相同向量模型的知识库。
- 【应用】显示知识来源调整至显示设置中。
- 【模型管理】优化模型列表样式。
- 【关于】优化关于页面显示信息。
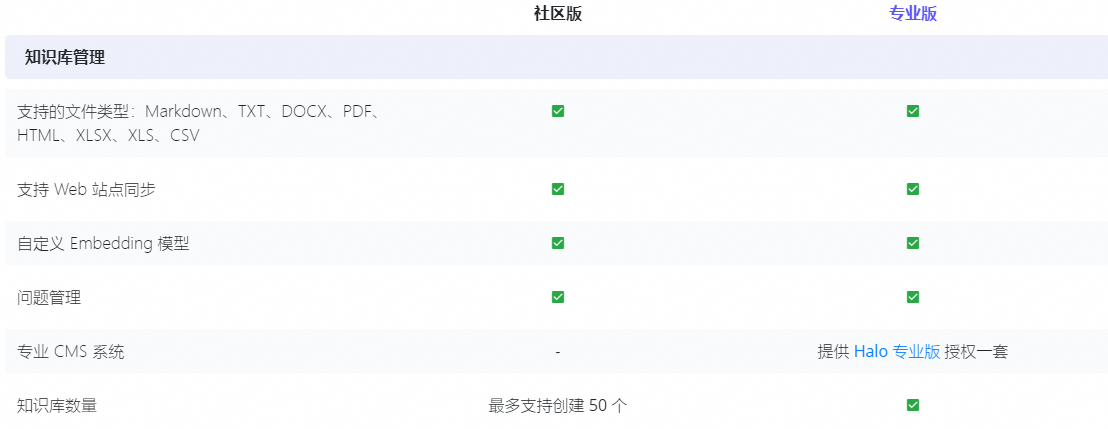
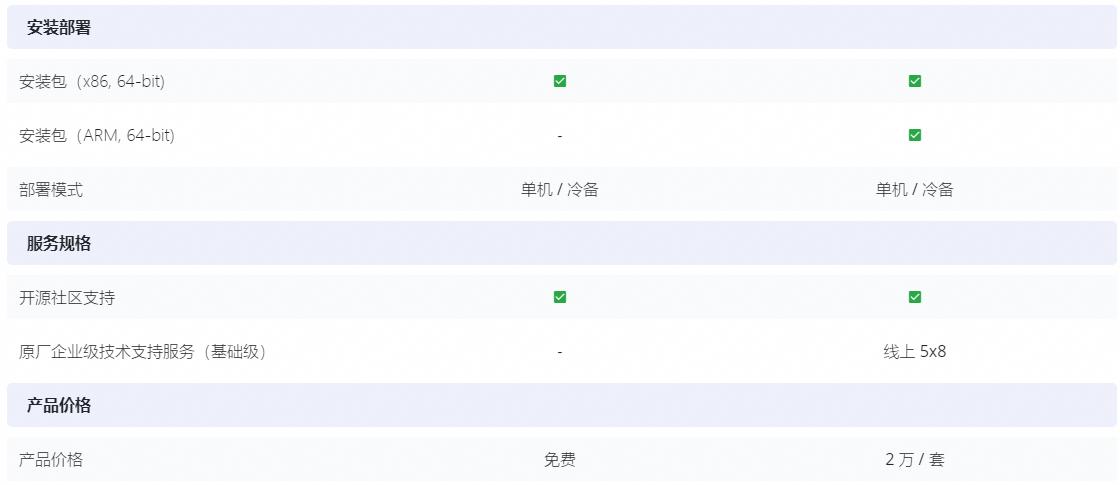
1.2 版本功能 VS版本对比
- 知识库管理
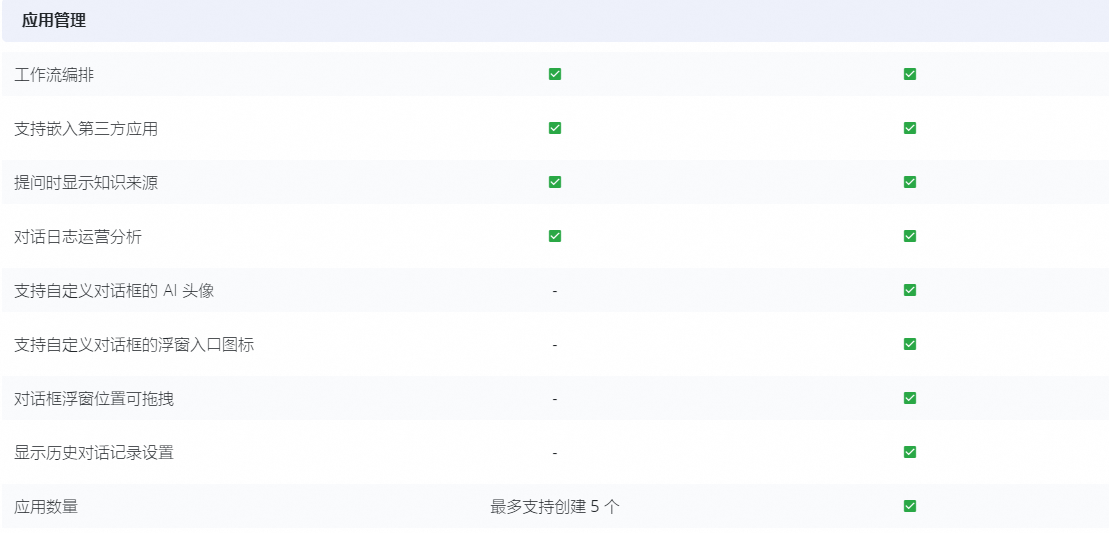
- 应用管理
- 大语言模型对接

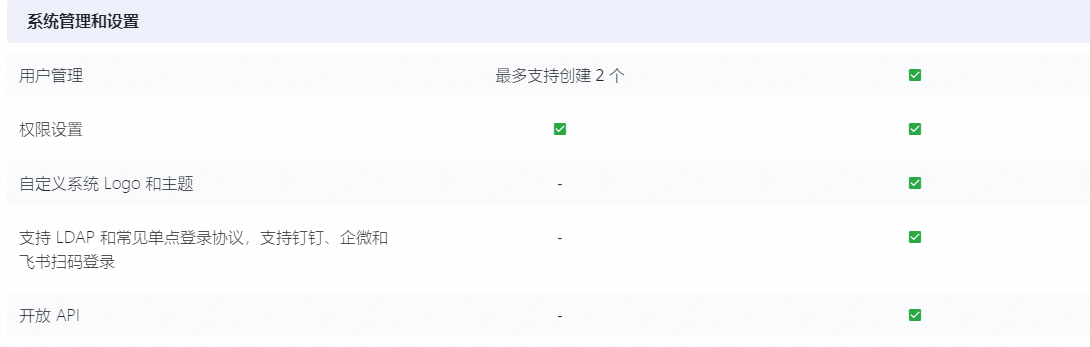
- 系统管理和设置
- 安装部署/服务规格/产品价格
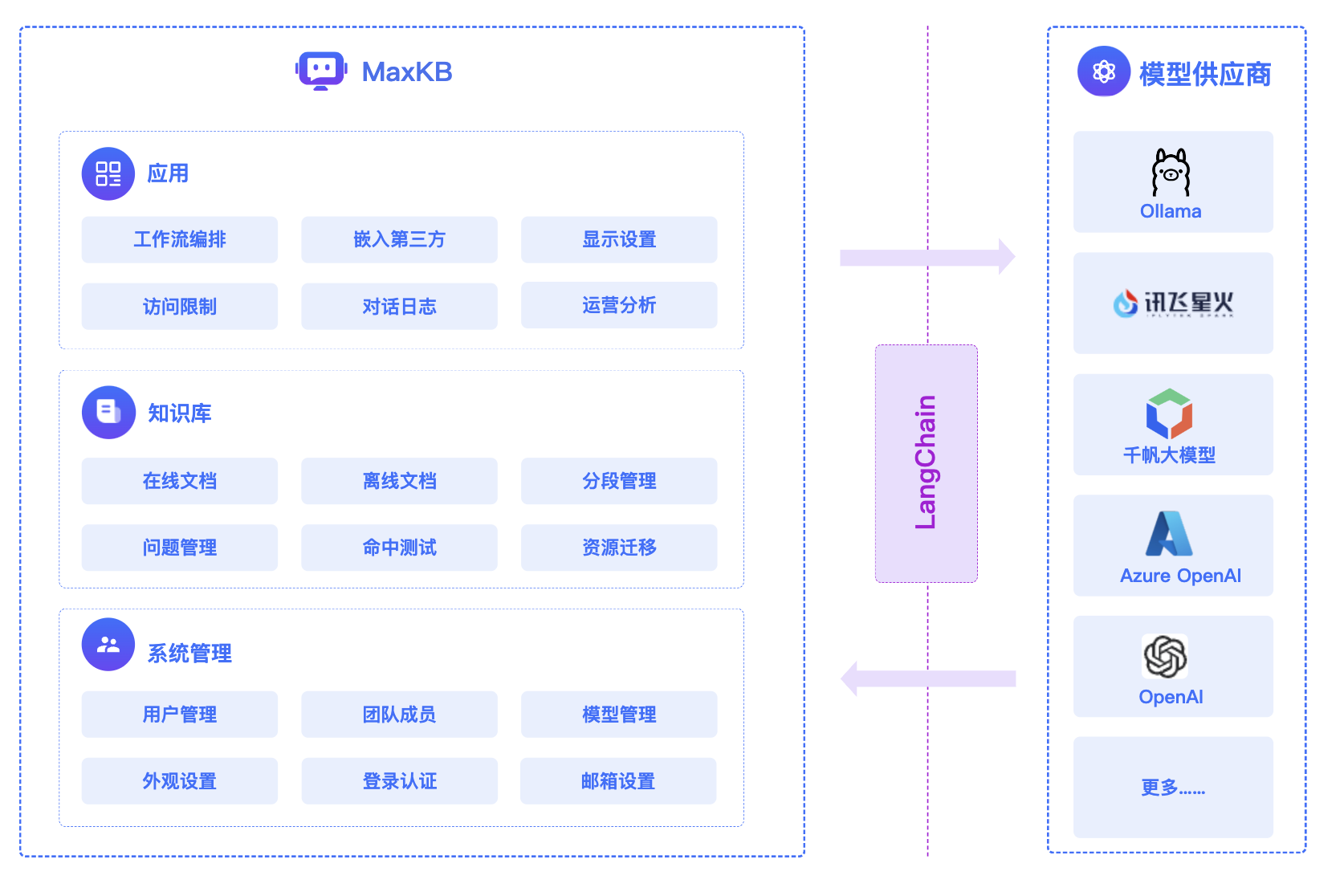
1.3 MaxKB系统架构
- 整体架构
- 实现原理
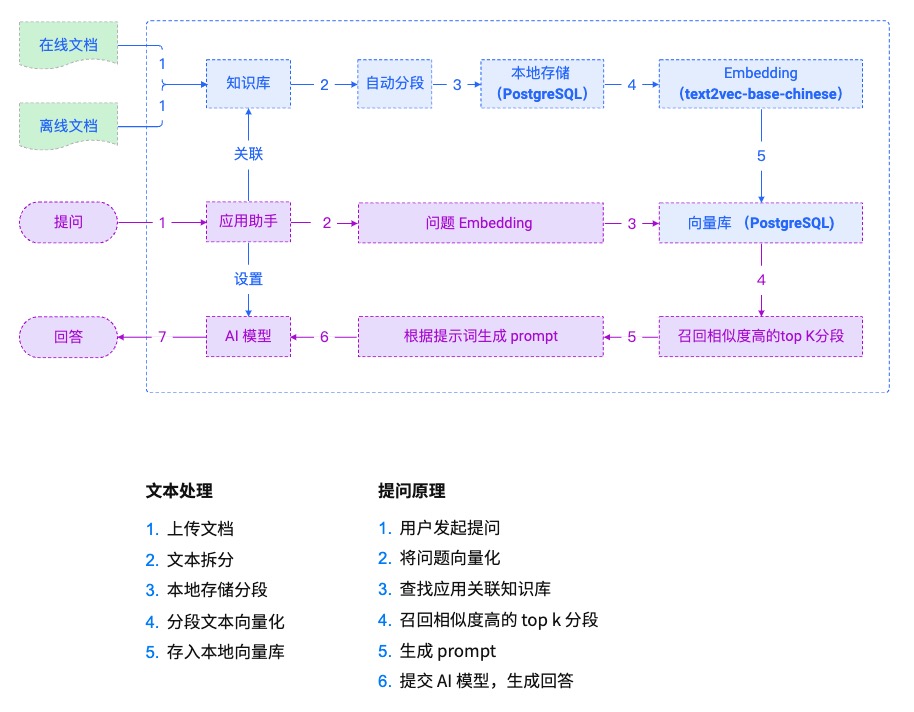
- 技术栈
- 前端:Vue.js、logicflow
- 后端:Python / Django
- Langchain:Langchain
- 向量数据库:PostgreSQL / pgvector
- 大模型:Ollama、Azure OpenAI、OpenAI、通义千问、Kimi、百度千帆大模型、讯飞星火、Gemini、DeepSeek等。
2.安装部署
2.1 离线安装
-
环境要求
安装前请确保您的系统符合安装条件:
-
操作系统:Ubuntu 22.04 / CentOS 7 64 位系统;
-
CPU / 内存: 推荐 2C/4GB 以上;
-
磁盘空间:100GB;
-
浏览器要求:请使用 Chrome、FireFox、Edge 等现代浏览器;
-
生产环境推荐使用离线部署。
-
离线部署 [✔]
注意:离线包仅支持 x86 服务器。
打开社区网站下载 MaxKB 离线包 社区版离线包
上传至服务器后进行解压缩,执行以下命令:
#maxkb-v1.2.0-offline.tar.gz替换成下载包的名字
tar -zxvf maxkb-v1.2.0-offline.tar.gz
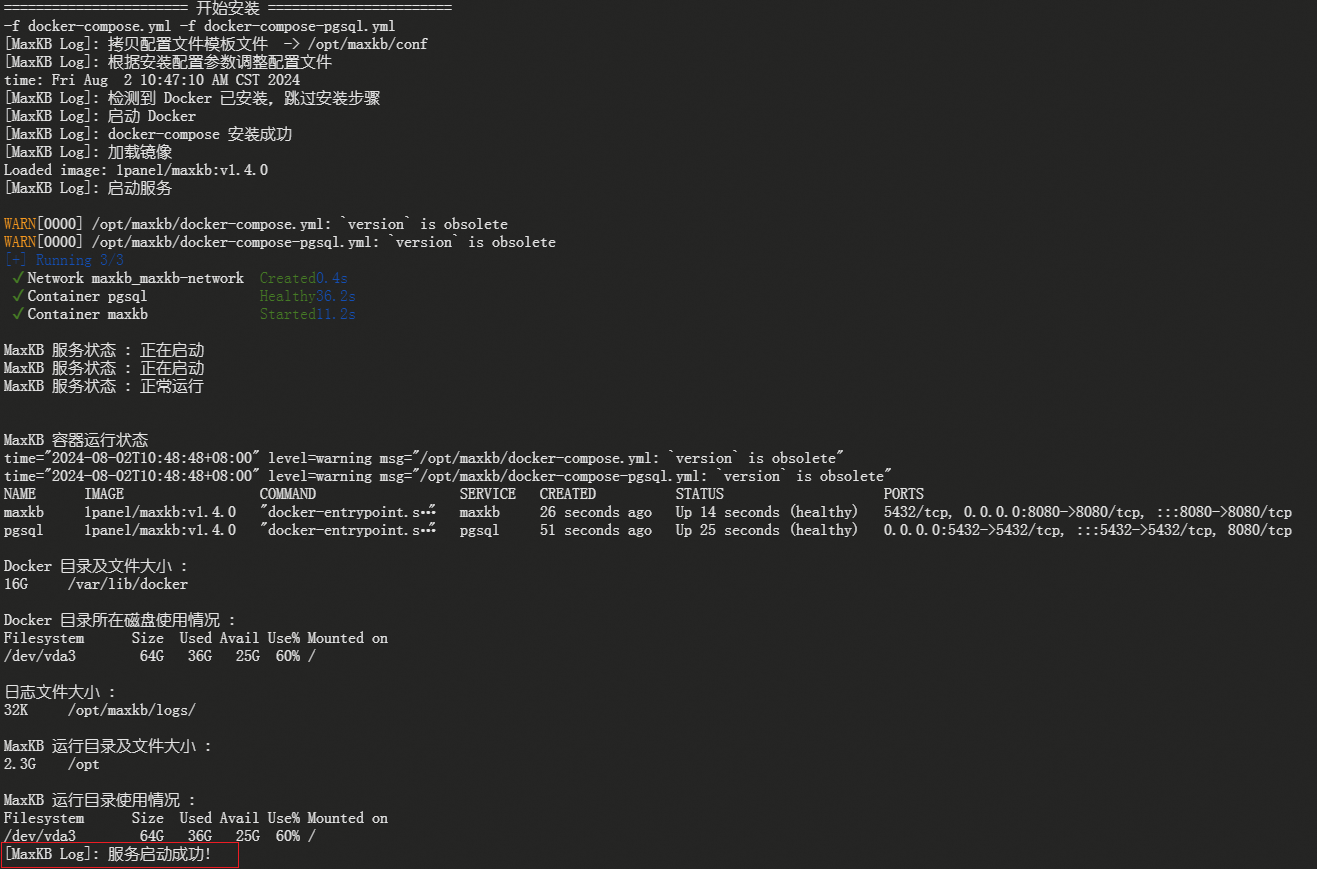
安装 MaxKB, 执行以下命令:
#进入安装包解压缩后目录
cd maxkb-v1.2.0-offline
#执行安装命令
bash install.sh
- 如果遇到docker安装相关问题可以参考下述链接:
一文带你入门向量数据库milvus:含docker安装、milvus安装使用、attu 可视化,完整指南启动 Milvus 进行了向量相似度搜索
安装成功后,可通过浏览器访问 MaxKB:
http://目标服务器 IP 地址:8080
默认登录信息
用户名:admin
默认密码:MaxKB@123..
- 离线升级
与 2 离线部署 执行步骤一样.
2.2 在线安装
- 环境要求
安装前请确保您的系统符合安装条件:
-
操作系统:Ubuntu 22.04 / CentOS 7 64 位系统;
-
CPU / 内存: 推荐 2C/4GB 以上;
-
磁盘空间:100GB;
-
浏览器要求:请使用 Chrome、FireFox、Edge 等现代浏览器;
-
可访问互联网。
-
在线快速部署
MaxKB 支持一键启动,仅需执行以下命令:
docker run -d --name=maxkb -p 8080:8080 -v ~/.maxkb:/var/lib/postgresql/data cr2.fit2cloud.com/1panel/maxkb
友情提示:社区版限制 1 个团队成员,5 个应用,50 个知识库。
安装成功后,可通过浏览器访问 MaxKB:
http://目标服务器 IP 地址:目标端口
默认登录信息
用户名:admin
默认密码:MaxKB@123..
如果使用的是云服务器,请至安全组开放目标端口。
- 在线升级
注意:升级前确认数据持久化目录(-v 后的目录),创建新容器时要跟上一次数据持久化目录保持一致,否则启动后数据为空。
执行以下命令:
1 下载最新镜像
docker pull cr2.fit2cloud.com/1panel/maxkb
2 确认上一次数据持久化目录,复制保存,第 4 步使用
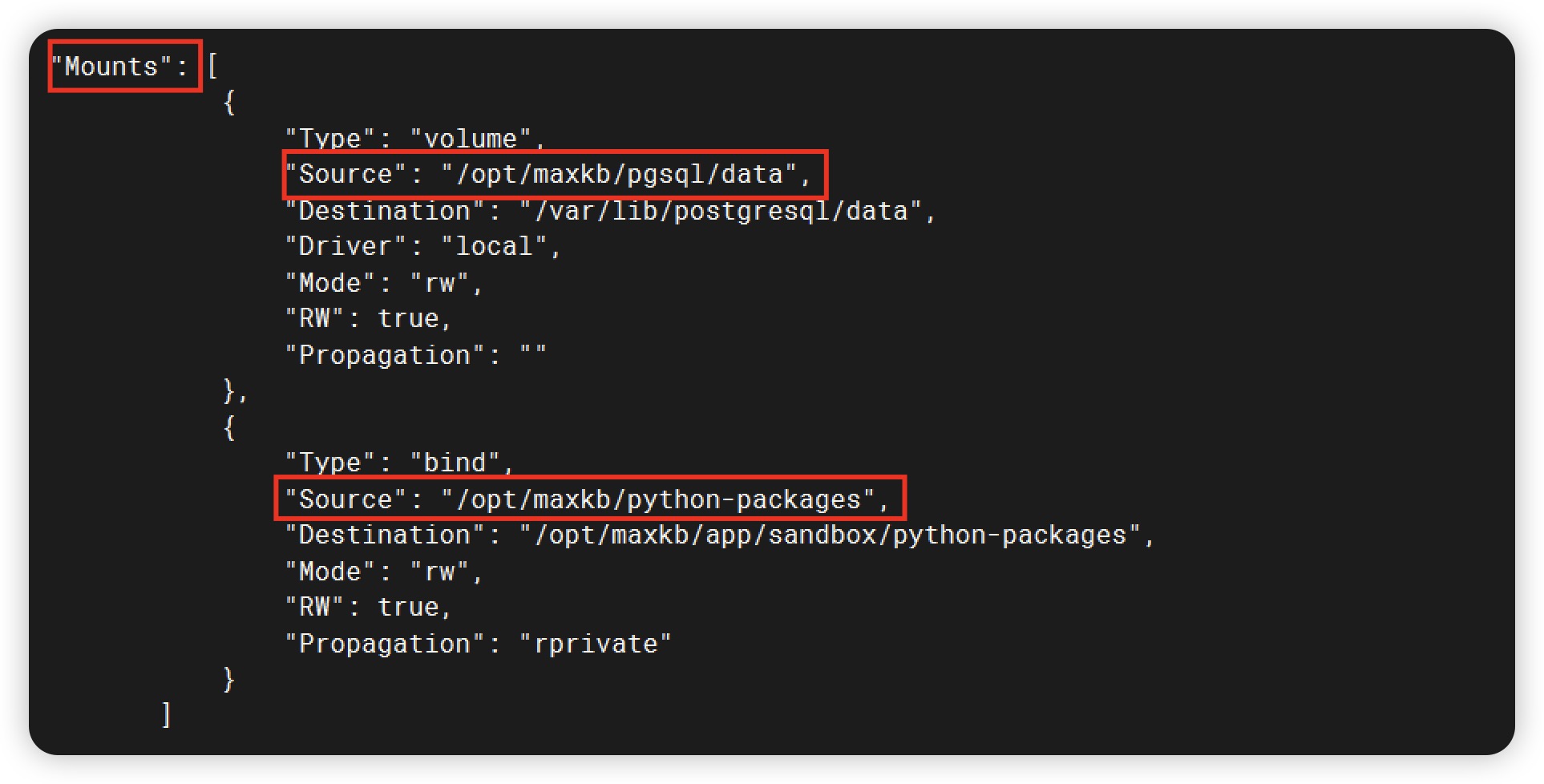
3 删除正在运行的 MaxKB 容器
4 创建并启动 MaxKB 容器
docker run -d --name=maxkb -p 8080:8080 -v /opt/maxkb/pgsql/data:/var/lib/postgresql/data cr2.fit2cloud.com/1panel/maxkb
#注意:确认数据持久化目录(-v后的目录)要跟【第 2 步】的目录保持一致,否则启动后数据为空。
2.3 1Panel安装
关于 1Panel 的安装部署与基础功能介绍,请参考 1Panel 官方文档。在完成了 1Panel 的安装部署后,根据提示网址打开浏览器进入 1Panel,如下界面。
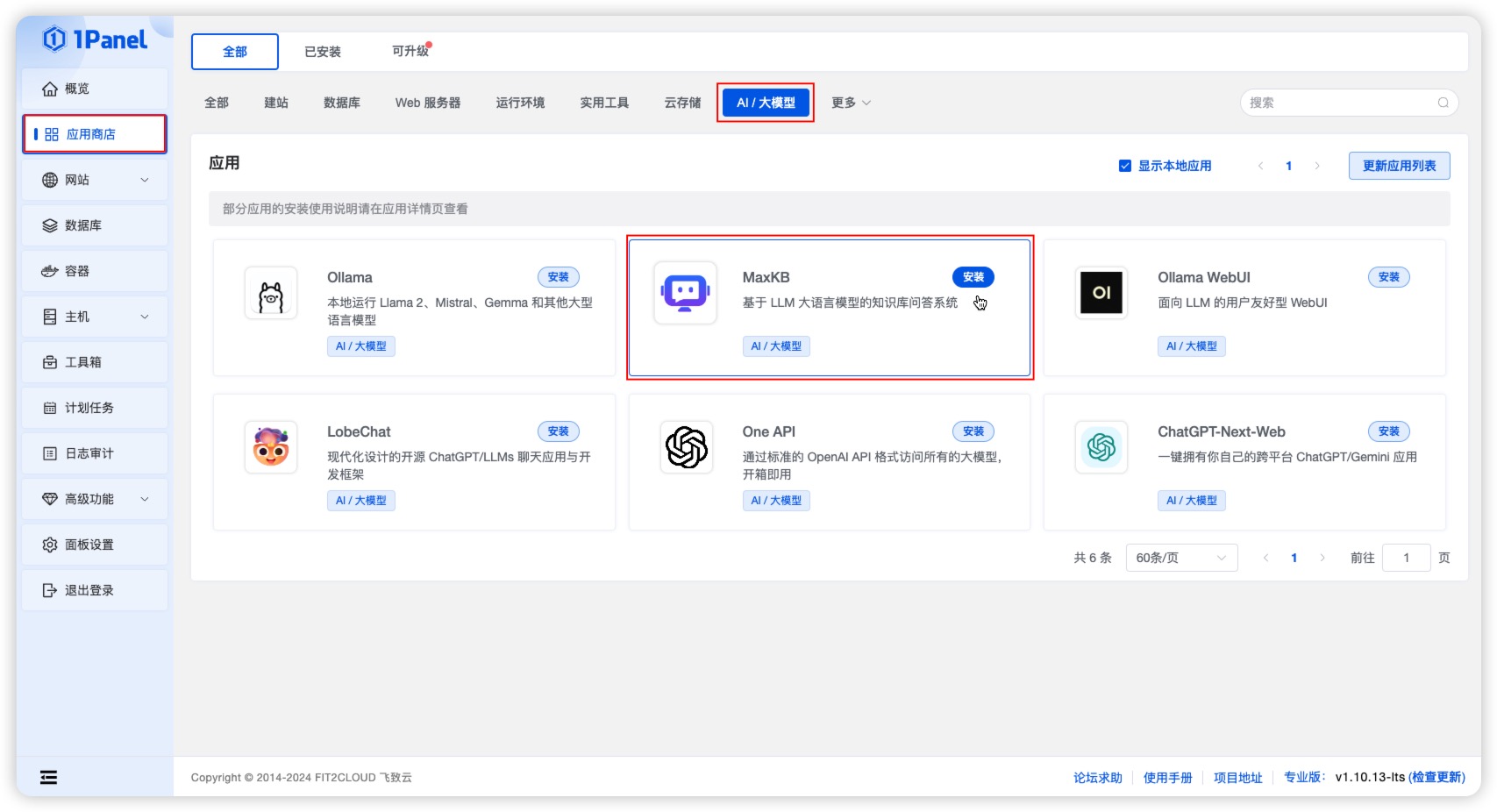
- 安装 MaxKB
进入应用商店应用列表,在【 AI / 大模型】分类下找到 MaxKB 应用进行安装。
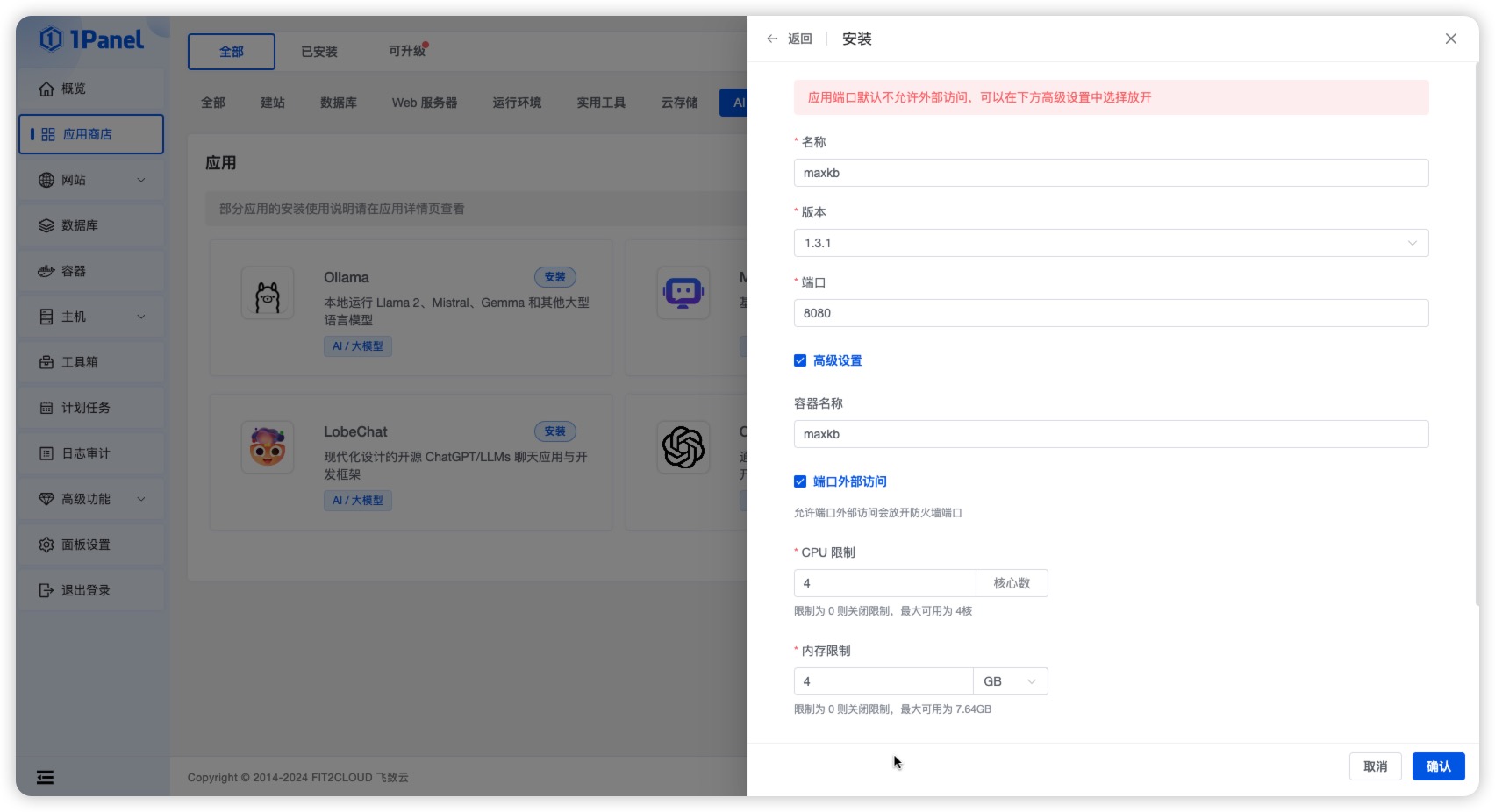
在应用详情页选择最新的 MaxKB 版本进行安装,进行相关参数设置。
- 名称:要创建的 MaxKB 应用的名称。
- 版本:选择 MaxKB 最新版本。
- 端口:MaxKB 应用的服务端口。
- 容器名称:MaxKB 应用容器名称。
- CPU 限制:MaxKB 应用可以使用的 CPU 核心数。
- 内存限制:MaxKB 应用可以使用的内存大小。
- 端口外部访问:MaxKB 应用可以使用 IP:PORT 进行访问(MaxKB 应用必须打开外部端口访问)。
点击开始安装后,页面自动跳转到已安装应用列表,等待安装的 MaxKB 应用状态变为已启动。
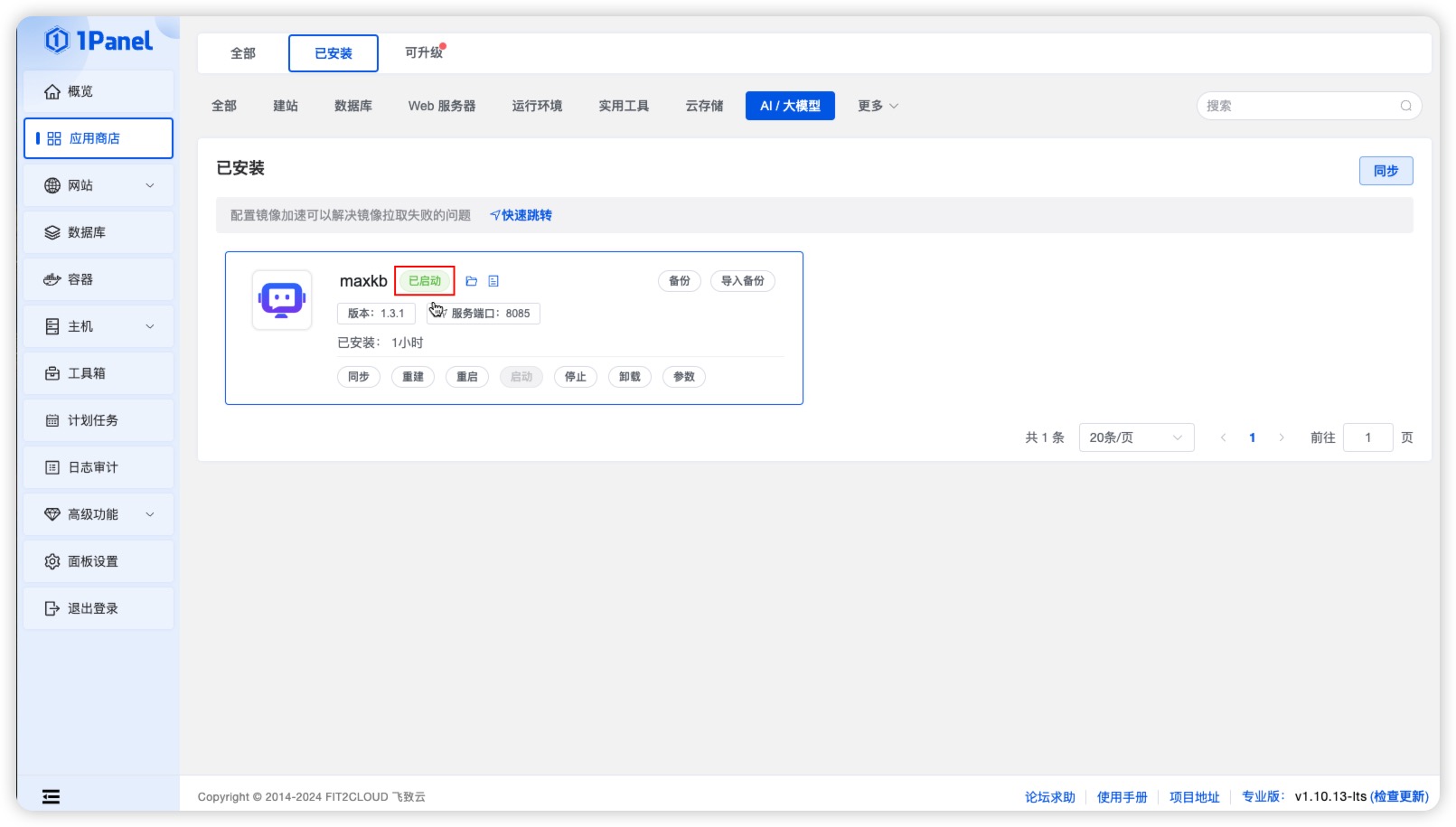
- 访问 MaxKB
安装成功后,通过浏览器访问如下页面登录 MaxKB:
地址: http://目标服务器IP地址:服务运行端口(默认 8080)
用户名: admin
密码: MaxKB@123..
第一次登录需修改 admin 用户的密码,修改密码后,重新登录系统即可使用 MaxKB。
2.4 kbctl运维工具
- kbctl 命令
MaxKB 离线安装包默认内置了命令行运维工具 kbctl,通过执行 kbctl help,可以查看相关的命令说明。
Usage:
kbctl [COMMAND] [ARGS...]
kbctl --help
Commands:
status 查看 MaxKB 服务运行状态
start 启动 MaxKB 服务
stop 停止 MaxKB 服务
restart 重启 MaxKB 服务
reload 重新加载 MaxKB 服务
uninstall 卸载 MaxKB 服务
upgrade 升级 MaxKB 服务
version 查看 MaxKB 版本信息
3. MaxKB快速实践
3.1 登录 MaxKB 系统
使用浏览器打开服务地址:http://目标服务器IP地址:目标端口。
默认的登录信息:
用户名:admin
默认密码:MaxKB@123..
3.2 添加模型
3.2.1 添加千帆大模型
点击【添加模型】,选择供应商【千帆大模型】,直接进入下一步填写千帆大模型表单。 或者左侧供应商先选择【千帆大模型】,然后点击【添加模型】,则直接进入千帆大模型表单。
- 模型名称: MaxKB 中自定义的模型名称。
- 模型类型: 大语言模型。
- 基础模型: 为供应商的 LLM 模型,支持自定义输入官方模型,选项中列了的一些常用的大语言模型。 注意自定义基础模型名称需保证与供应商平台的模型名称一致才能校验通过。
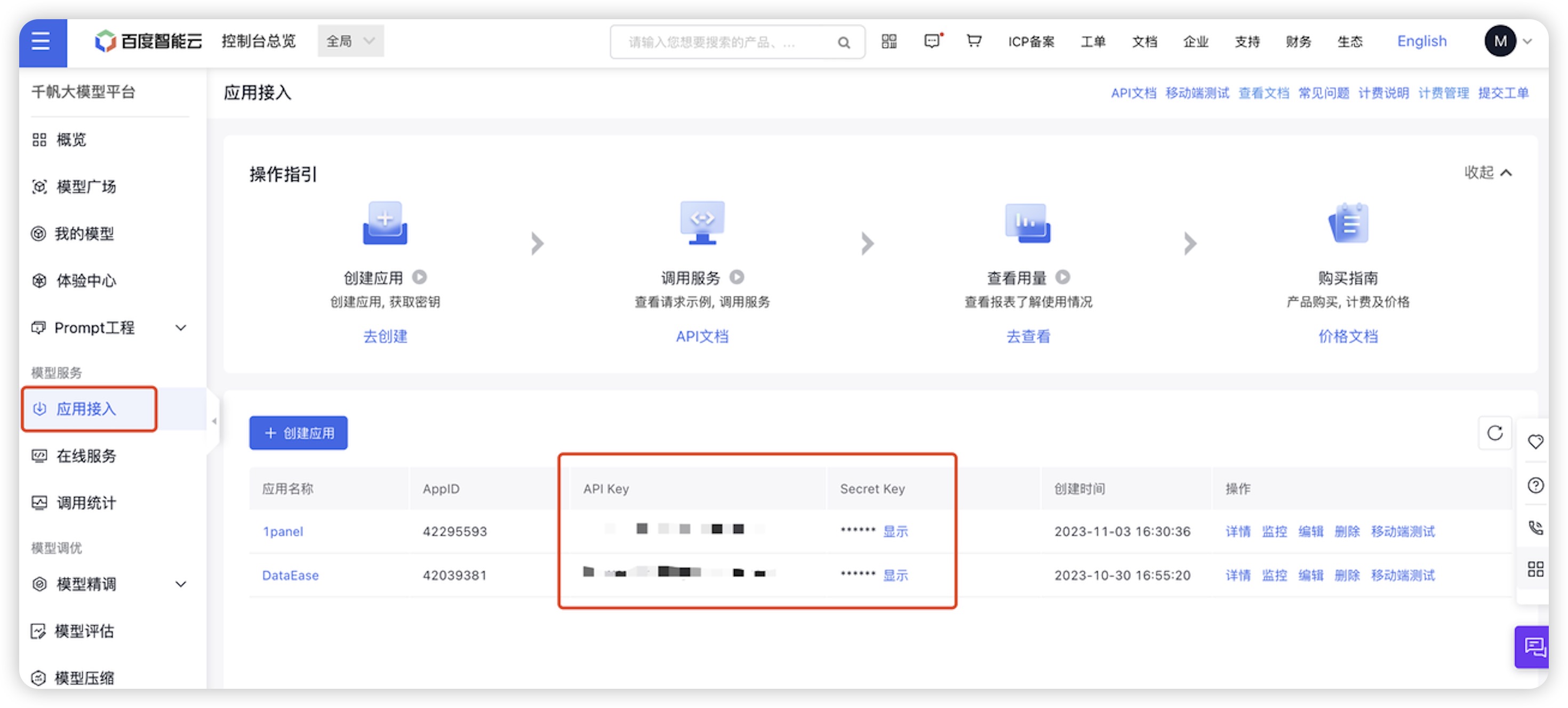
- API Key 和 Secret Key:千帆大模型中应用的 API Key 和 Secret Key(需要先创建应用)
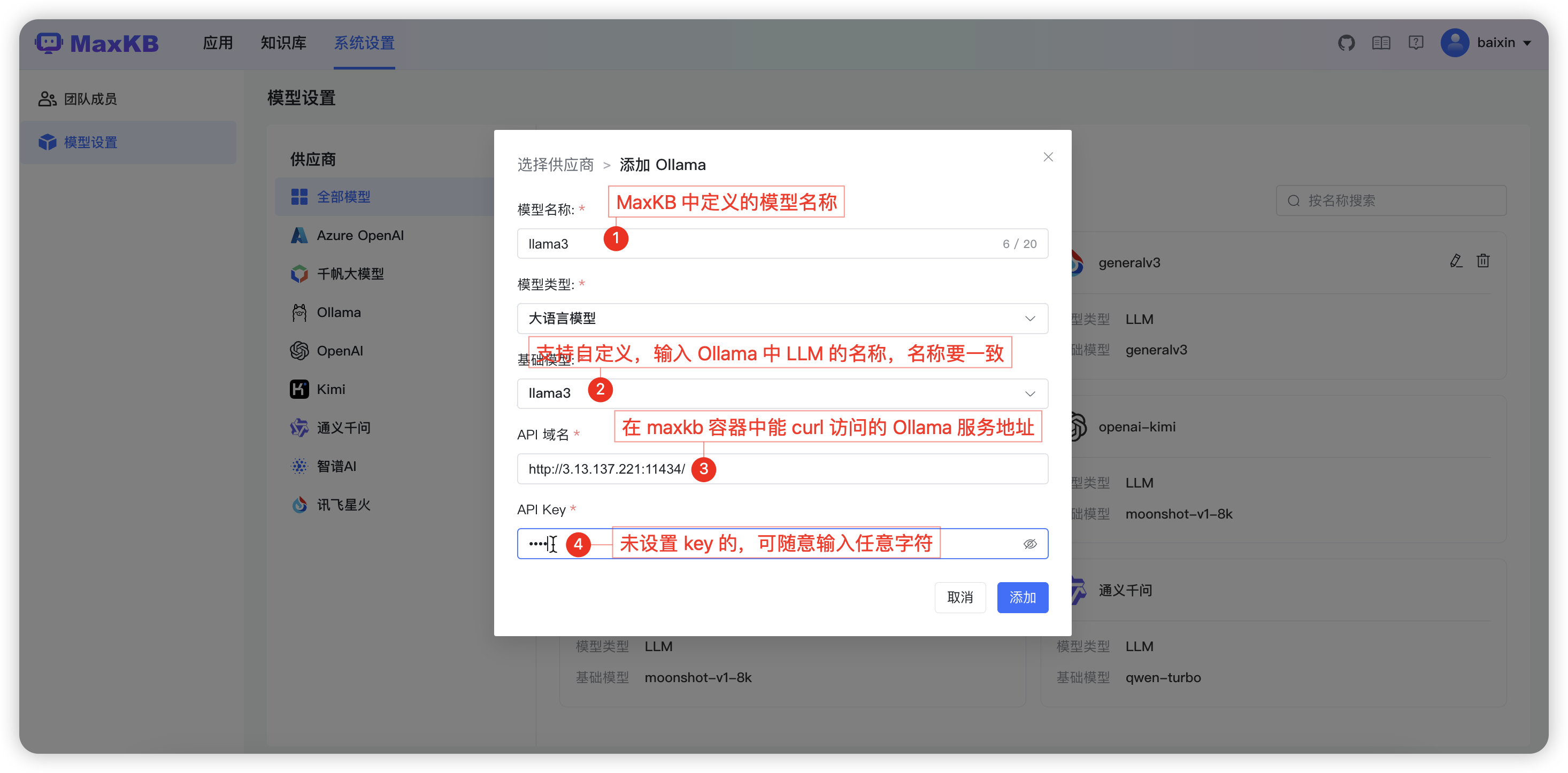
3.2.2 添加 Ollama 模型
API 域名和 API Key: 为供应商的连接信息(Ollama 服务地址, 如:http://42.92.198.53:11434/ )。若没有 API Key 可以输入任意字符。
点击【添加】后 校验通过则添加成功,便可以在应用的 AI 模型列表选择该模型。
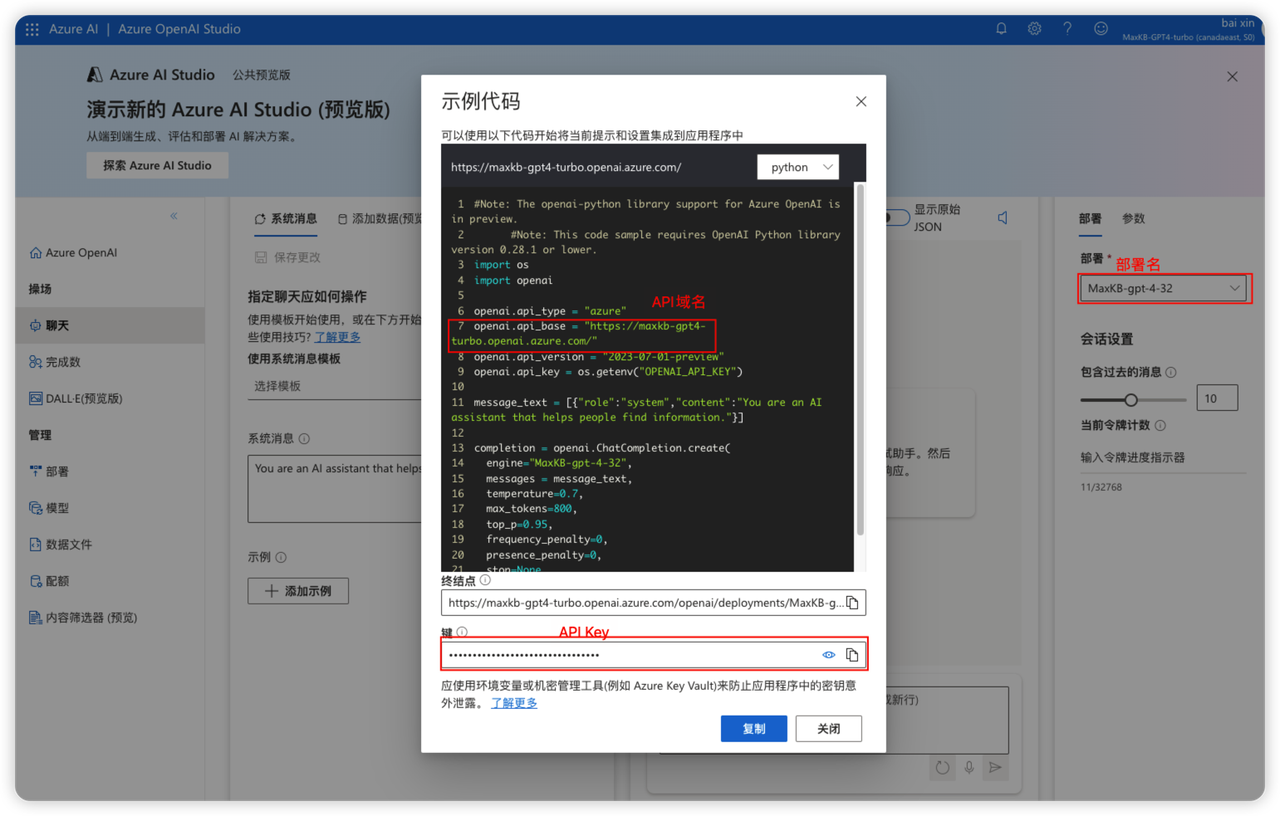
3.2.3 添加 Azure OpenAI 模型
基础模型: 为供应商的 LLM 模型,支持自定义输入和下拉选项,当前可下拉选择的大语言模型如:gpt-3.5-turbo-0613、gpt-3.5-turbo-0301、gpt-3.5-turbo-16k-0613 等。
API 域名、API Key、部署名称: 是 Azure OpenAI 的模型部署中提供的,需要填写一致,参考下图:
3.2.4 添加 OpenAI 大模型
基础模型: 为供应商的 LLM 模型,支持自定义输入,下拉选项是 OpenAI 常用的一些大语言模型如:gpt-3.5-turbo-0613、gpt-3.5-turbo、gpt-4 等。
API 域名(国外):https://api.openai.com/v1 。 API 域名:国内服务器反向代理地址 / v1。 API Key:访问 OpenAI 的 Key。
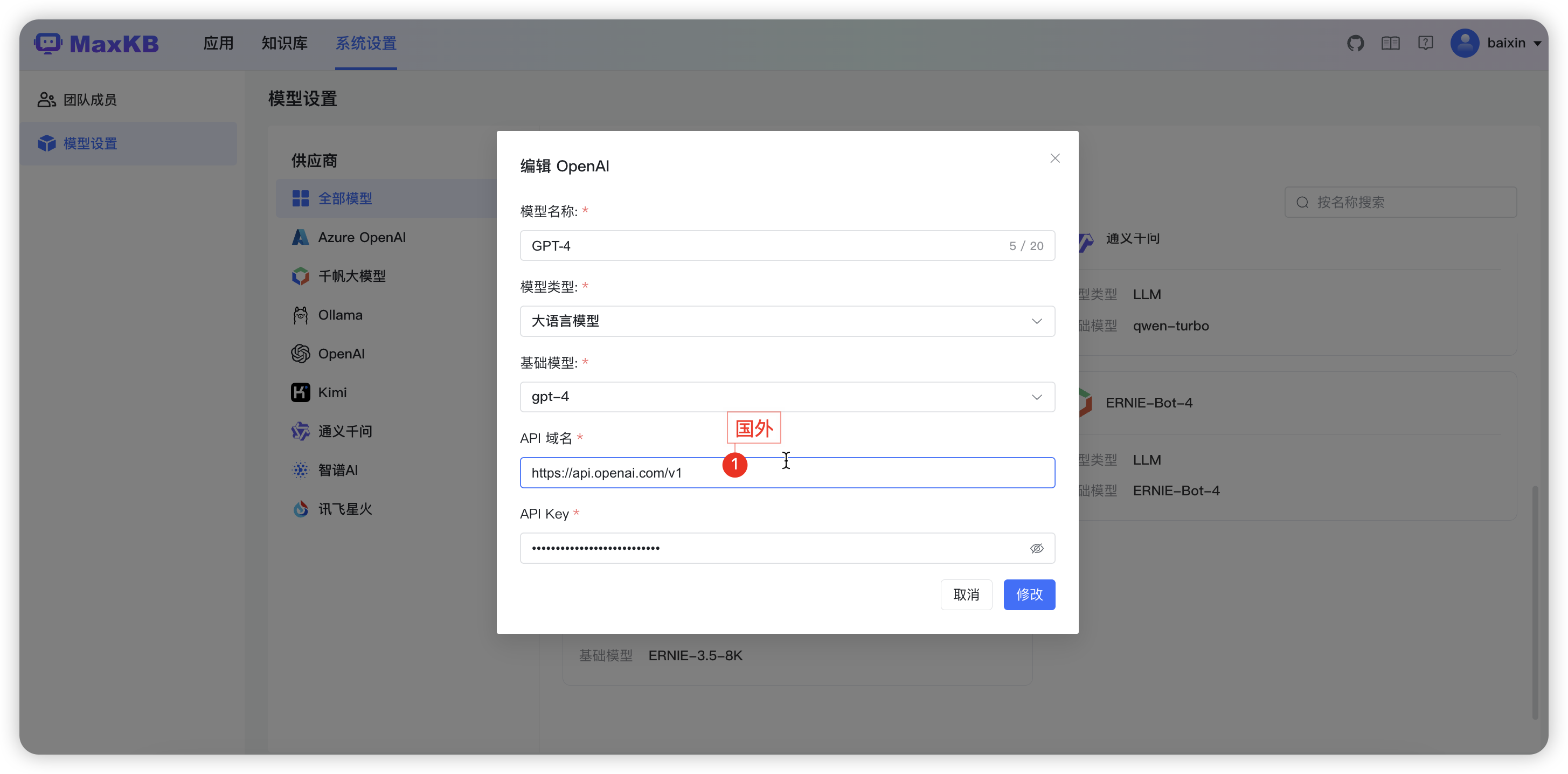
3.2.5 添加讯飞星火大模型
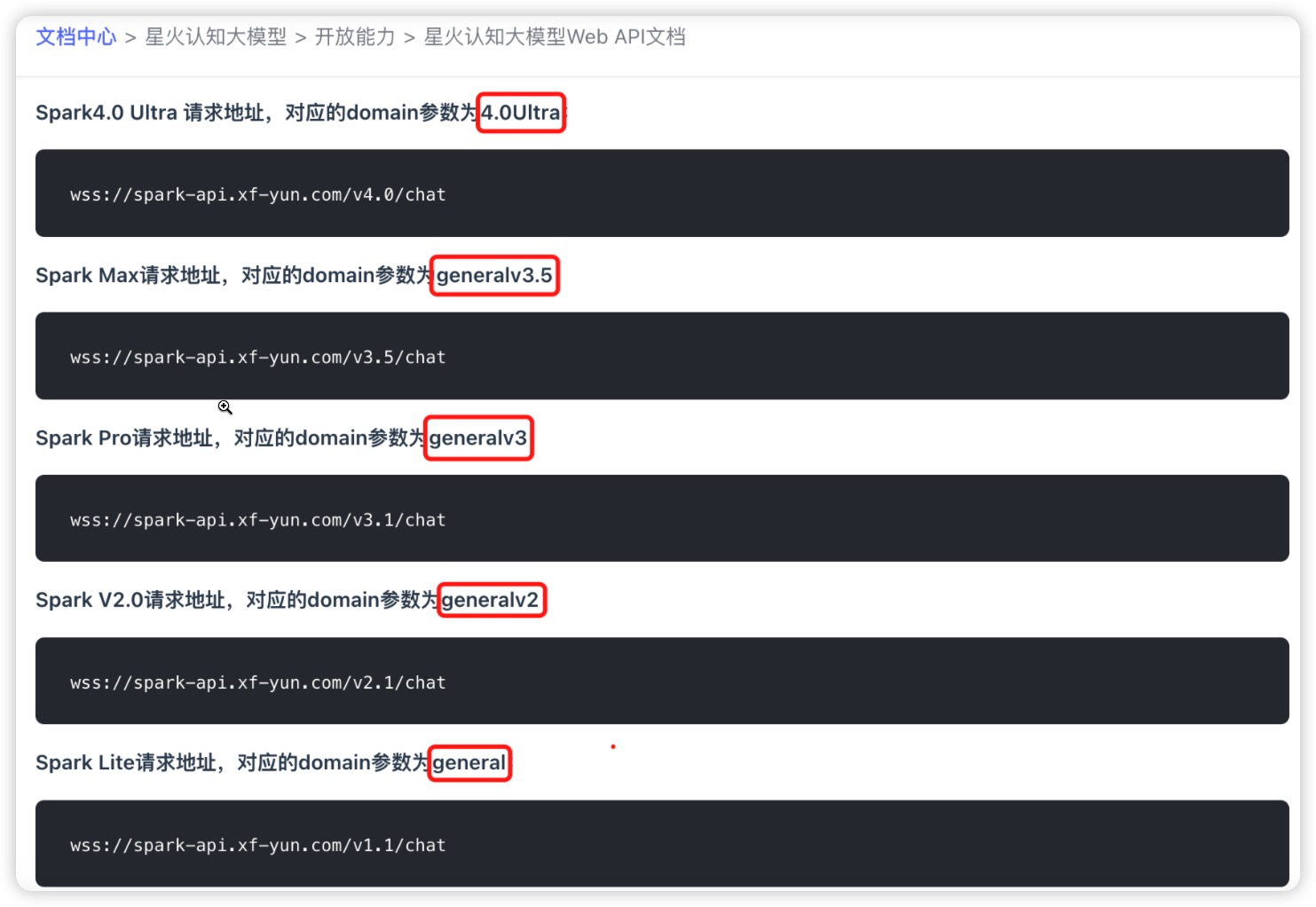
基础模型: 支持自定义输入,对应接口文档中 domain,下拉选项是讯飞星火常用的一些大语言模型。
API 域名:每个基础模型对应的 API 域名不同,请根据所选基础模型输入对应的 API 域名,参考讯飞星火官方文档。
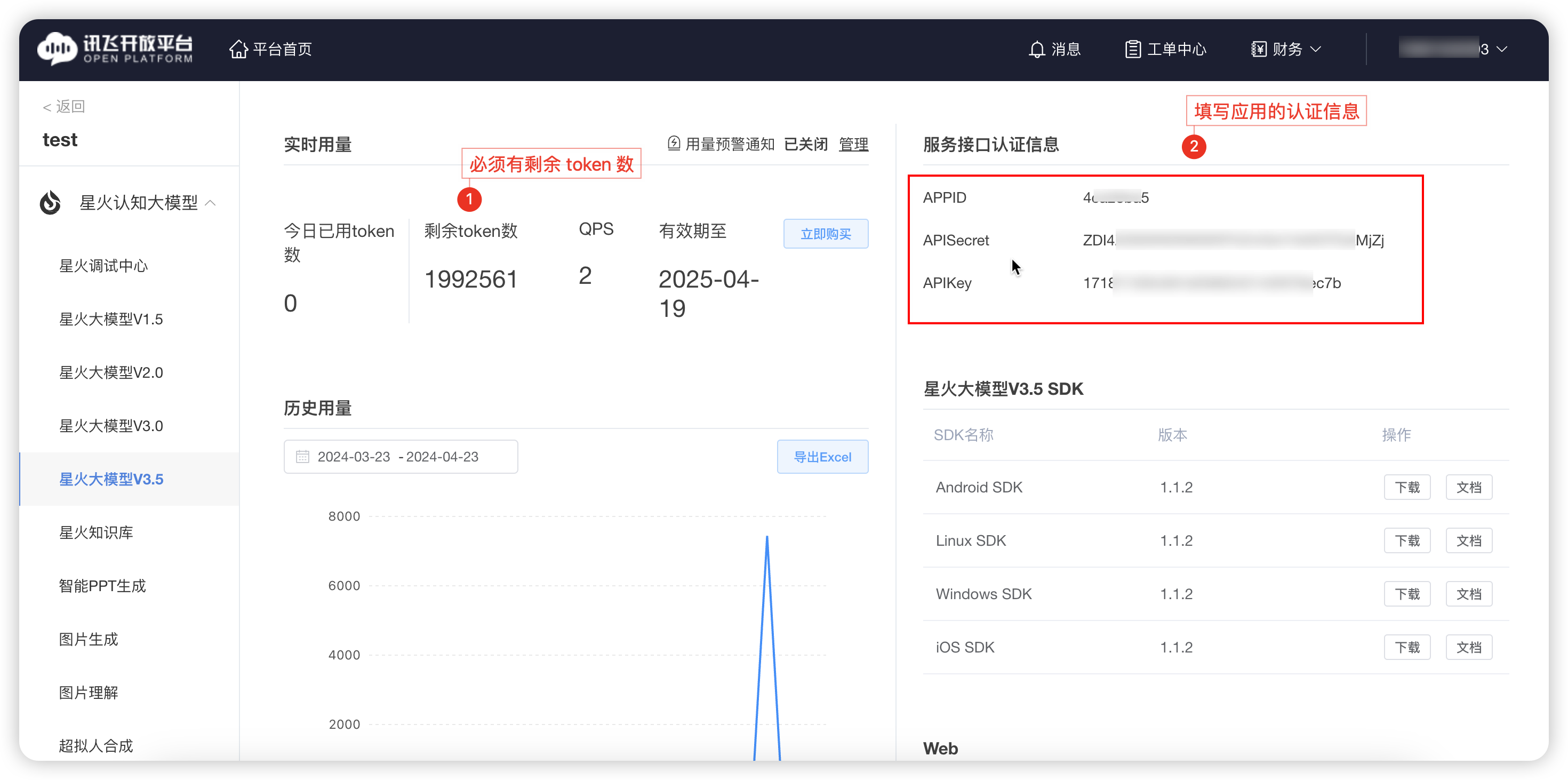
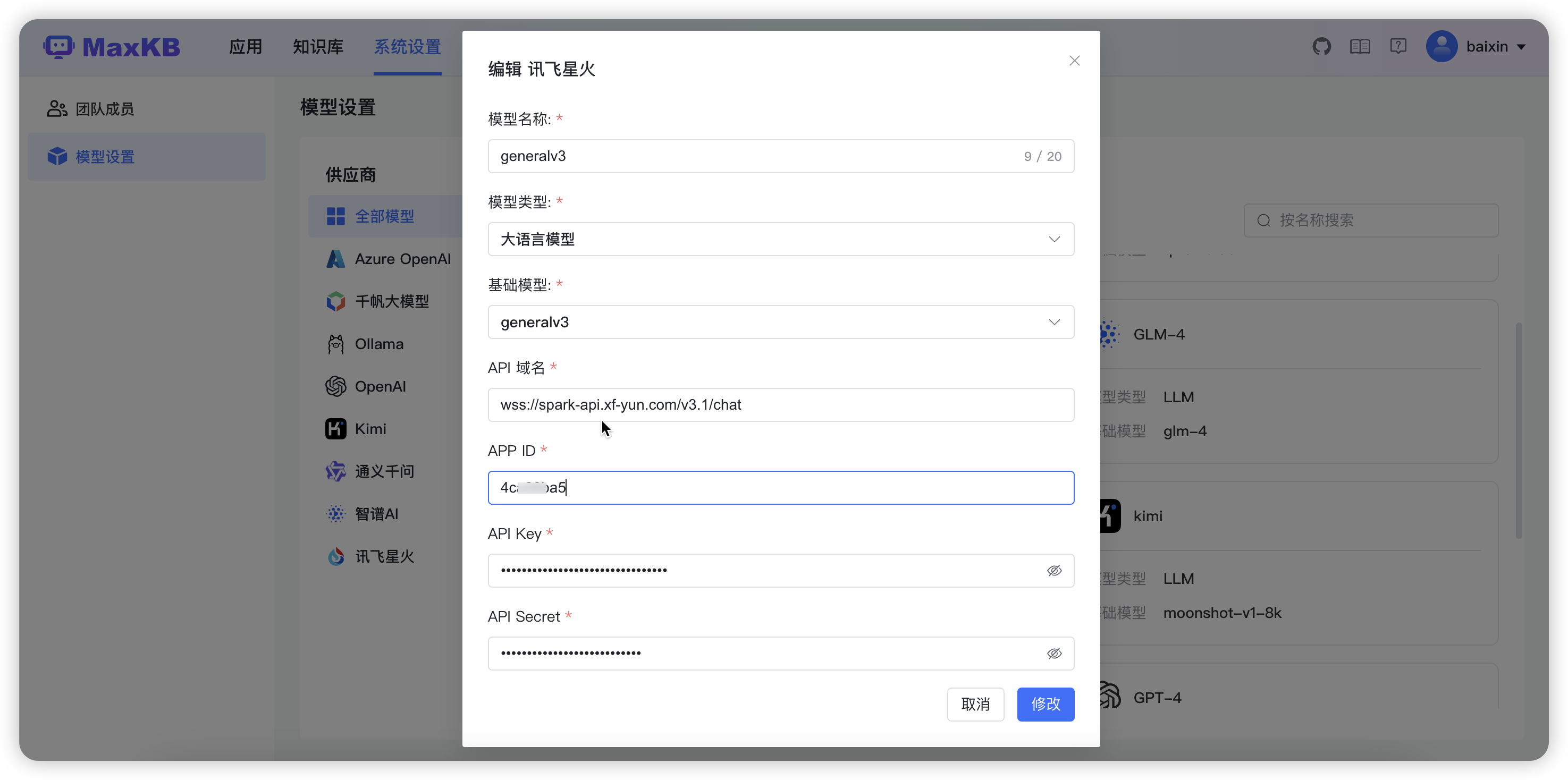
APP ID、API Key、Secret Key 需要现在讯飞星火开放平台创建应用,并且应用的剩余 tokens>0,才能添加成功。
3.2.6 添加智谱 AI 大模型
API Key: 需要现在智谱 AI 开放平台创建。
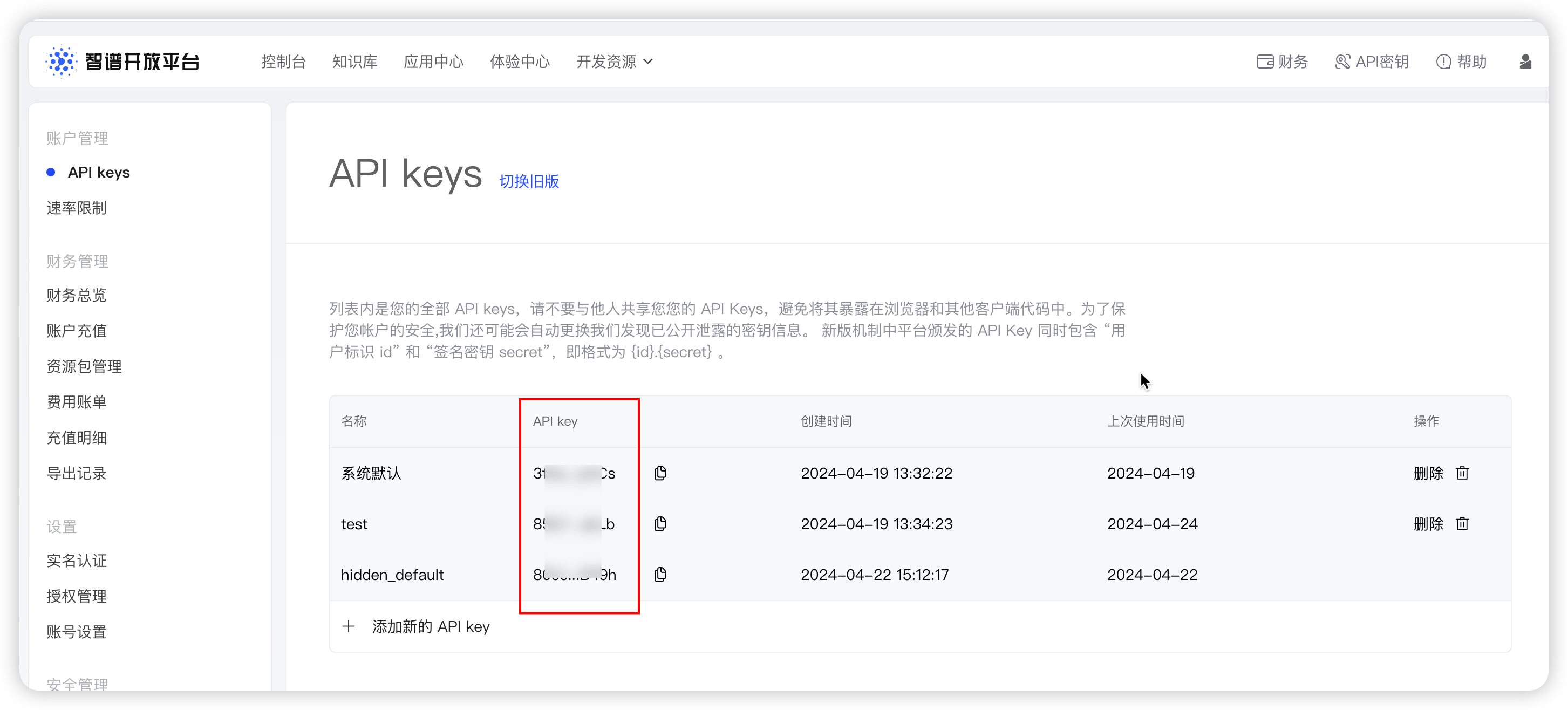
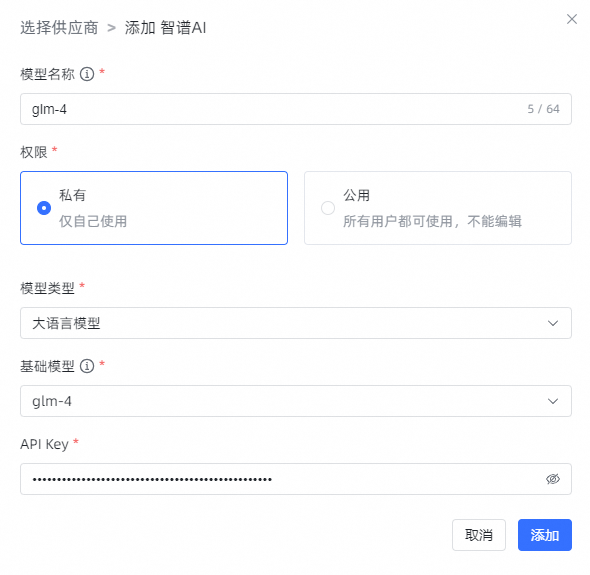
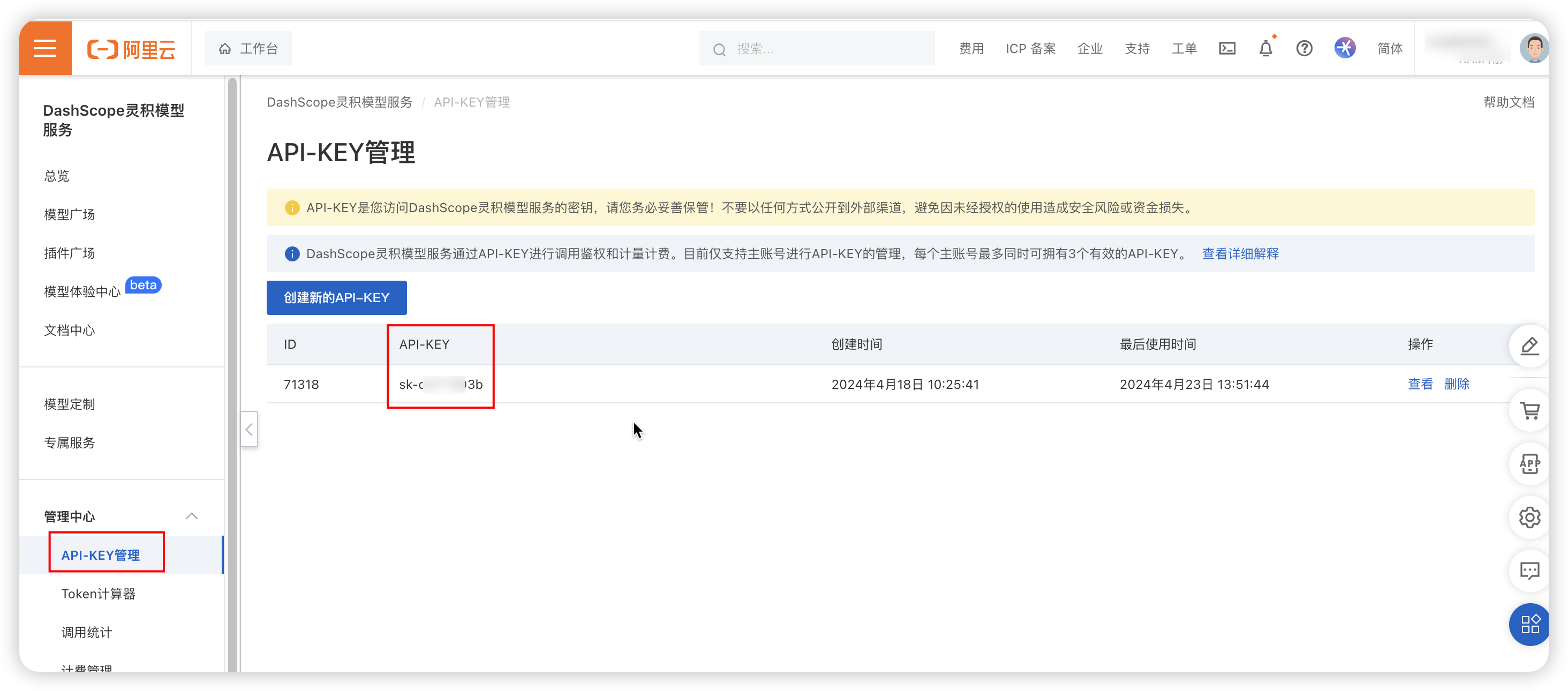
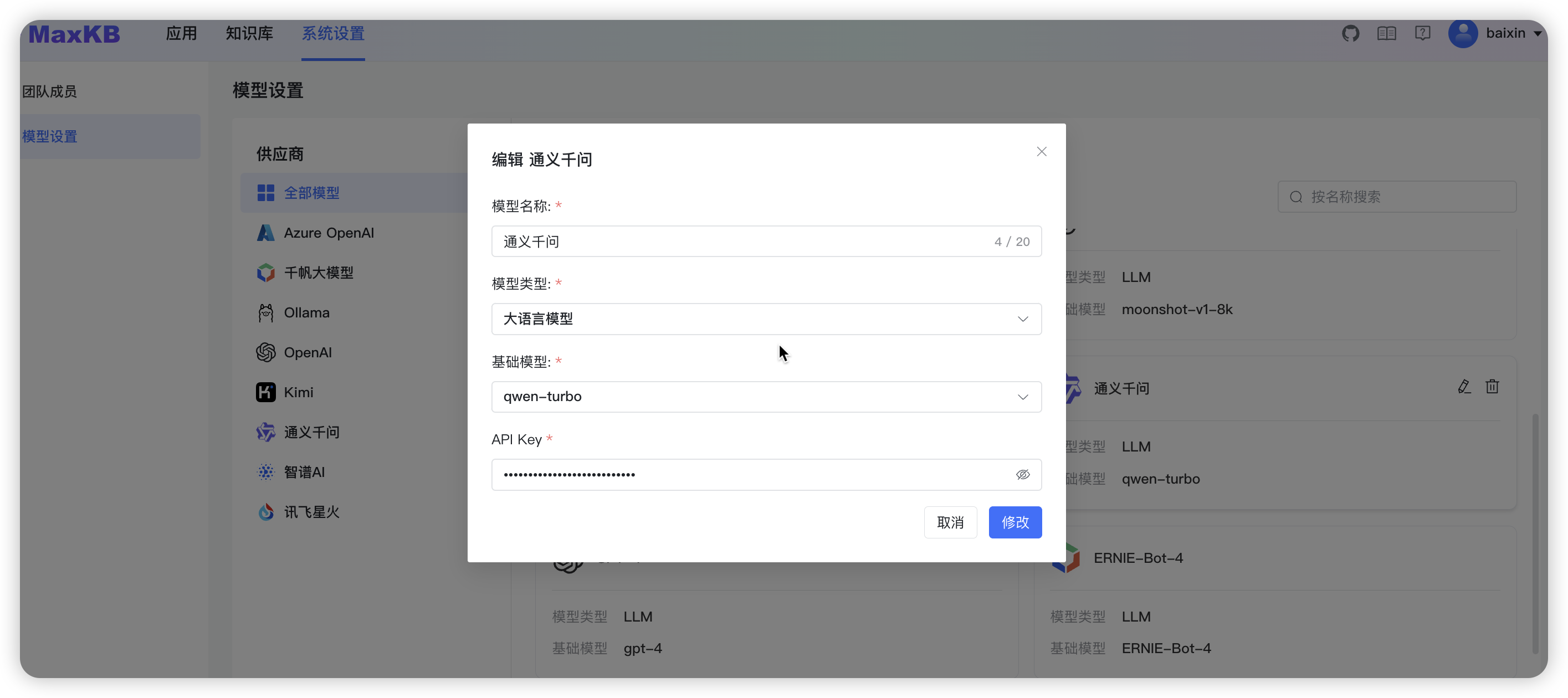
3.2.7 添加通义千问大模型
API Key: 需要在阿里云 ->DashScope 灵积模型服务 ->API Key 管理中获取。
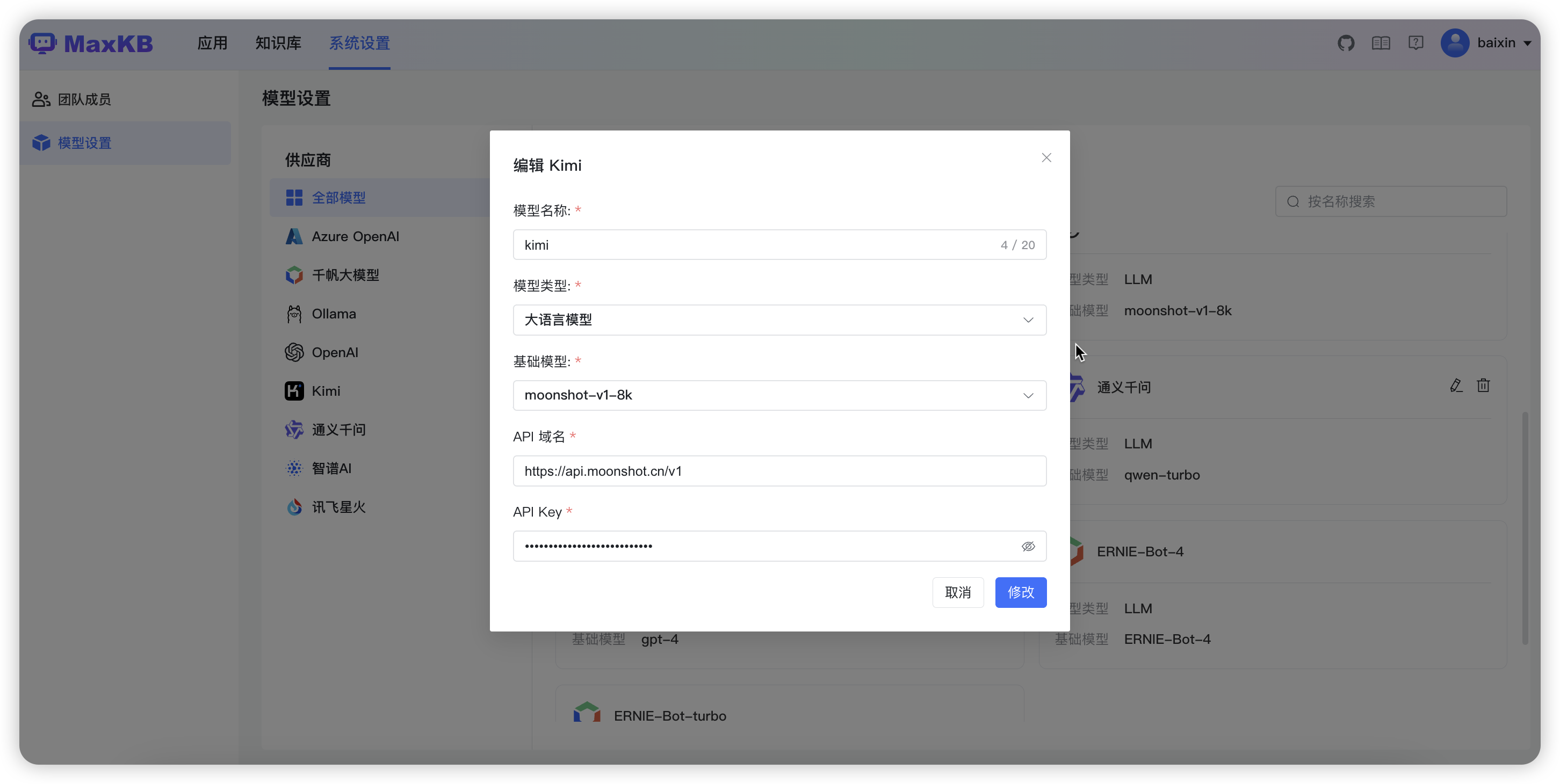
3.2.8 添加 Kimi 大模型
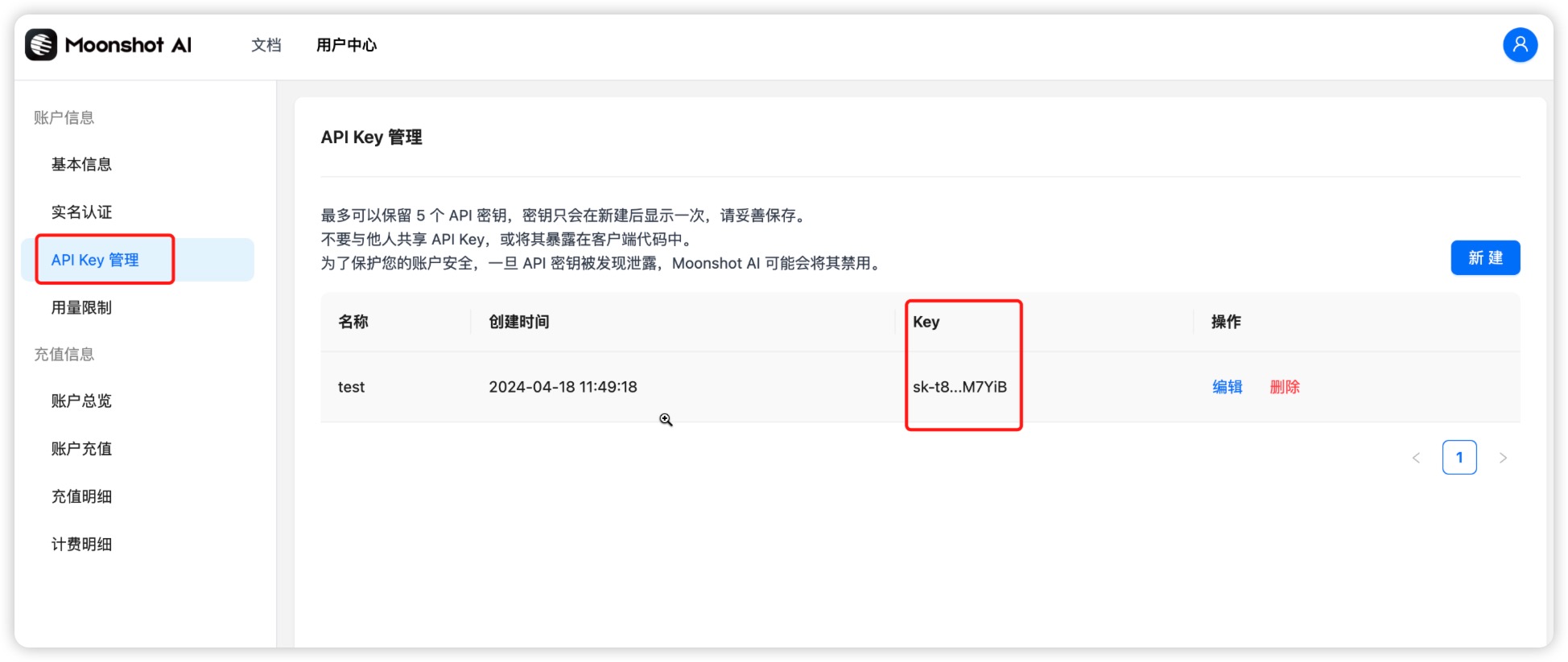
API 域名: https://api.moonshot.cn/v1
API Key: 在 Kimi 账户中心的 API Key 管理中获取 key。
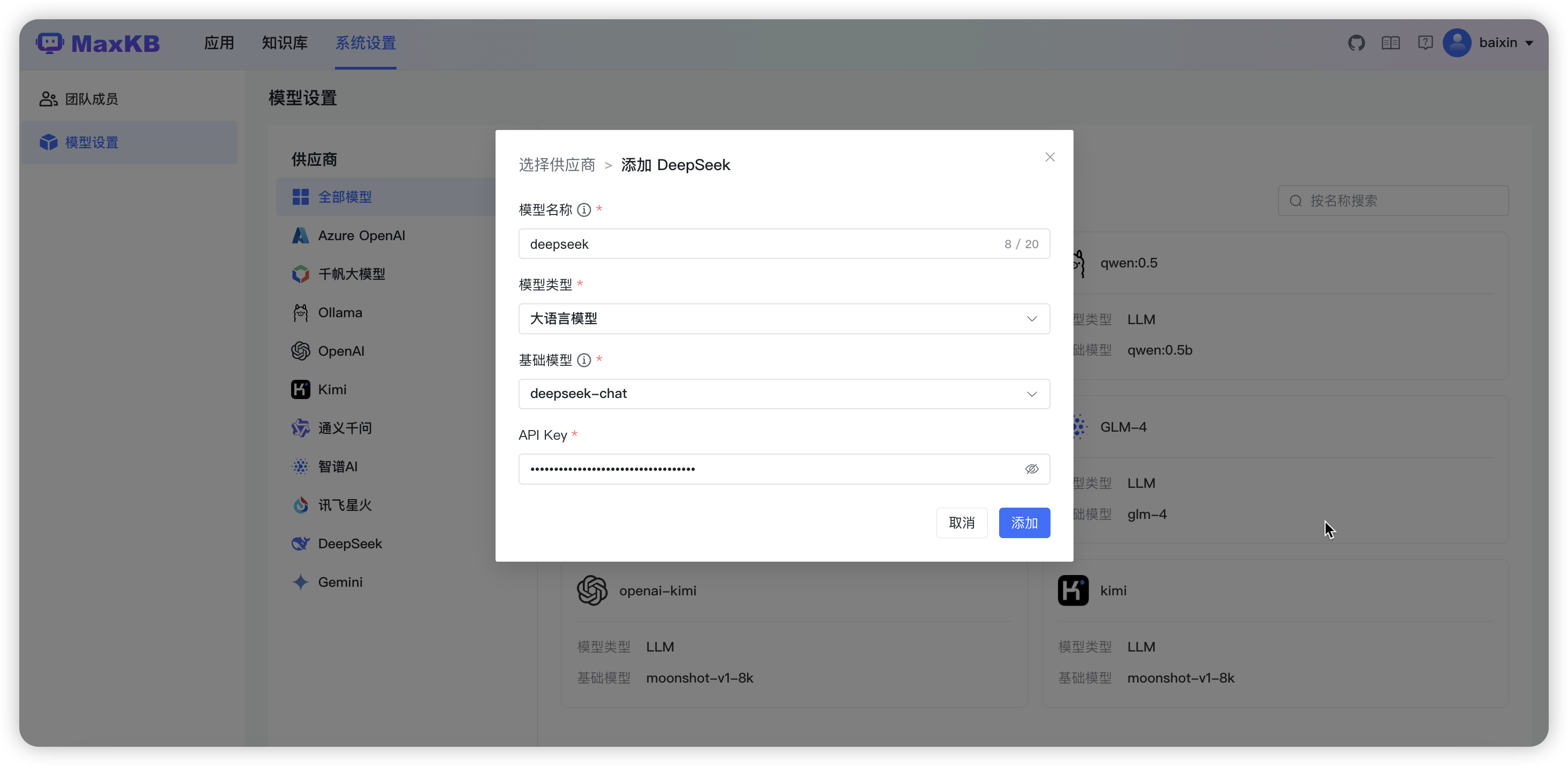
3.2.9 添加 DeepSeek 大模型
API Key: 在 DeepSeek 官方 获取 API Key。
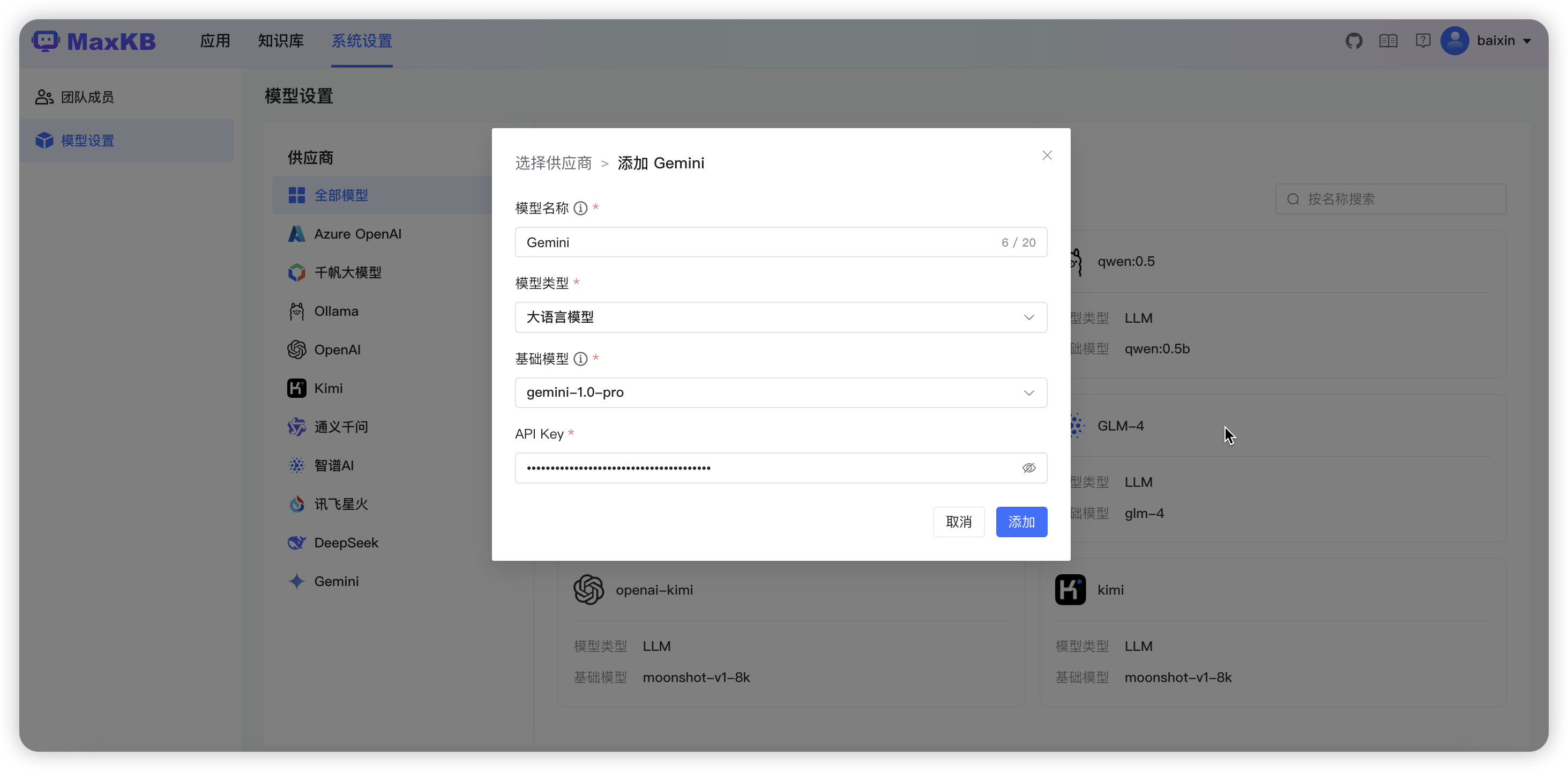
3.2.10 添加 Gemini 大模型
注意:使用 Gemini API 需要确保程序所在服务器位于 Gemini API 所支持的地区 ,否则无法调用 API,并且无法进入 Google AI Studio。
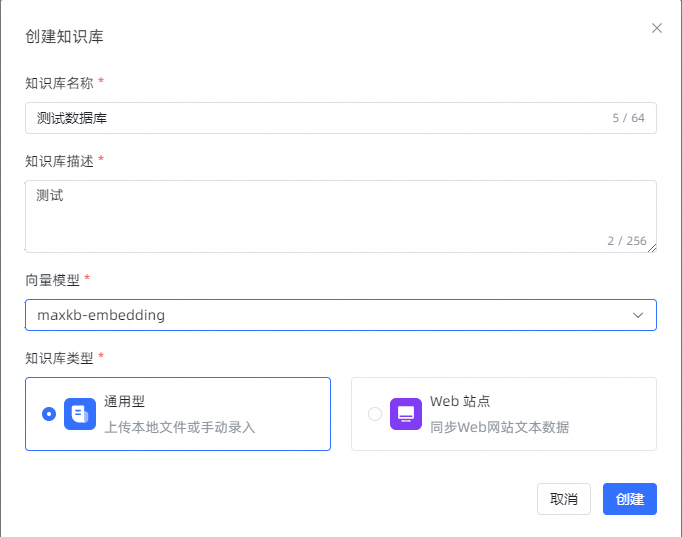
3.3 创建通用型知识库
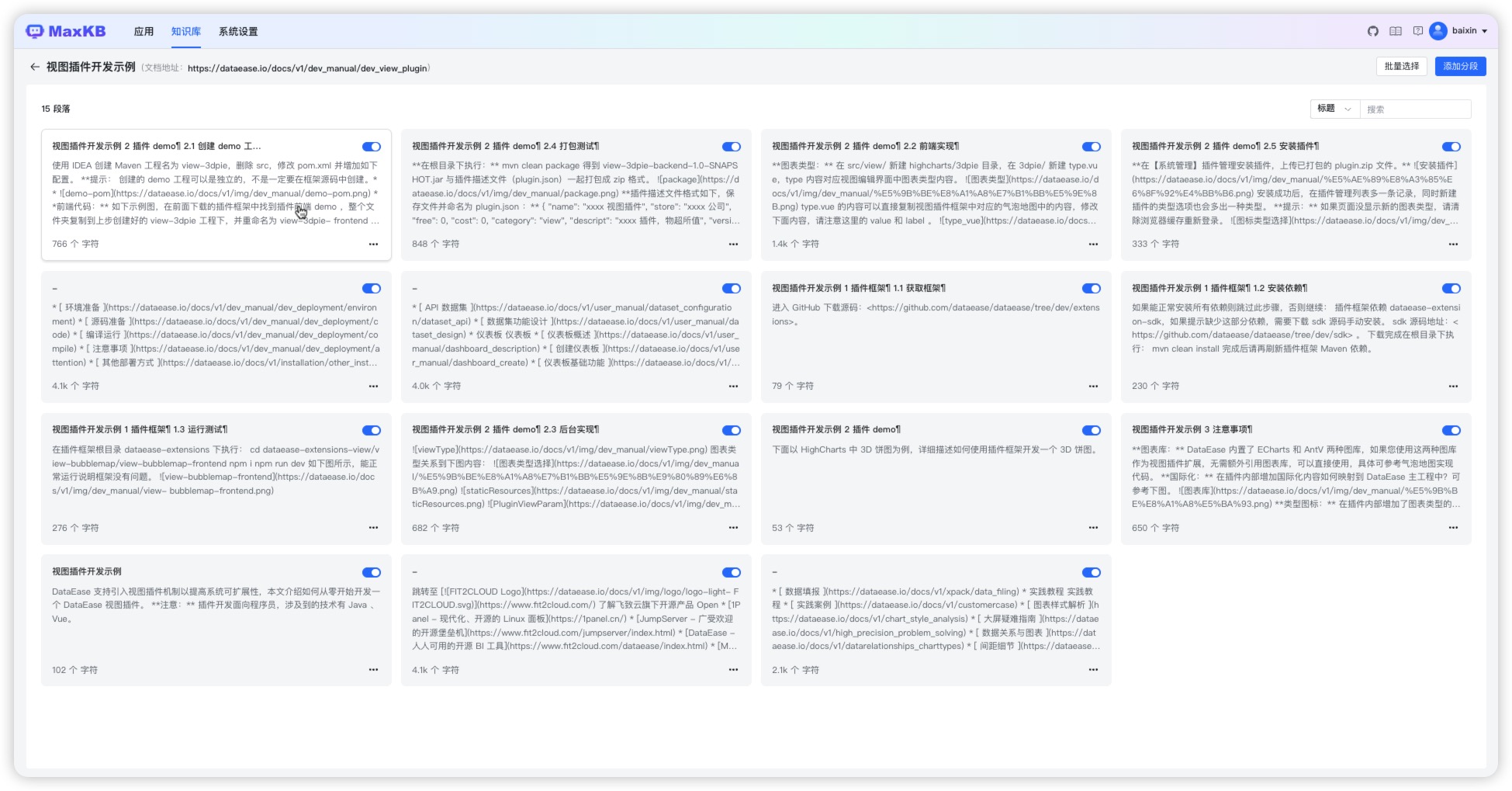
打开【知识库】页面,点击【创建知识库】,进入创建知识库页面。 输入知识库名称、知识库描述、选择通用型知识库类型。 然后将离线文档通过拖拽方式或选择文件上传方式进行上传。
-
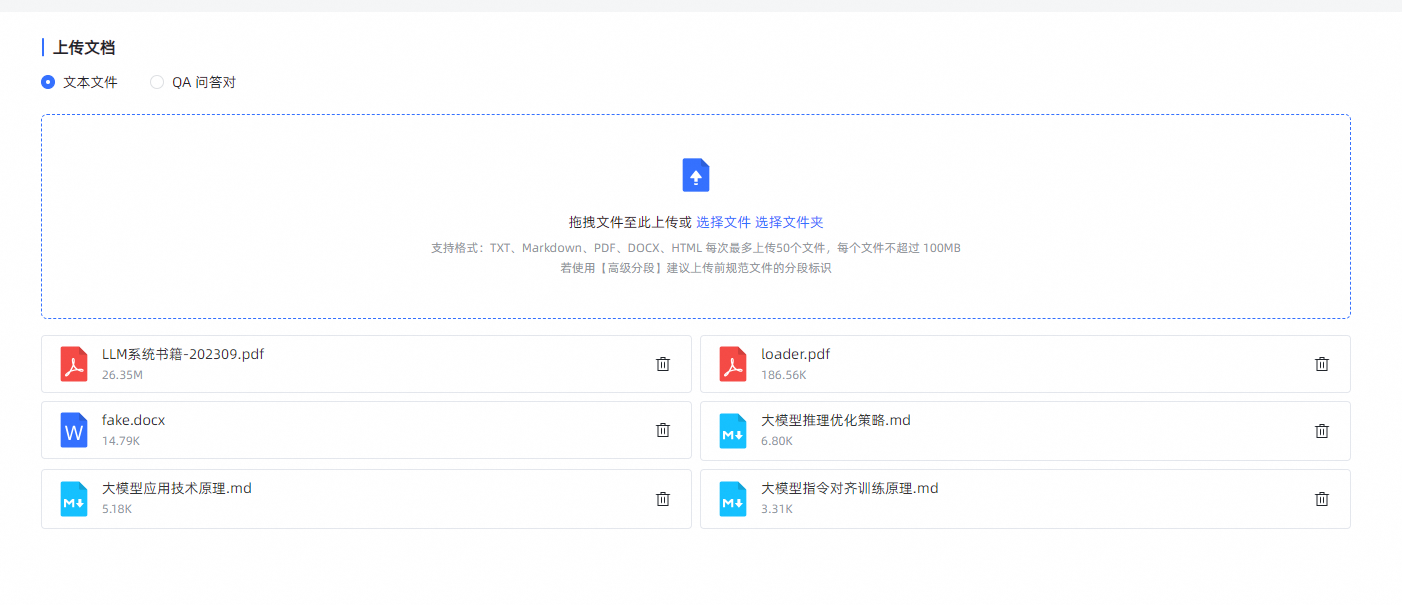
上传文档
- 上传文档要求:
- 支持文本文件格式为:Markdown、TXT、PDF、DOCX、HTML; 支持 QA 问答对格式为:Excel、CSV;
- 每次最多上传 50 个文件;
- 每个文件不超过 100 MB; 支持选择文件夹,上传文件夹下符合要求的文件。
- 上传文档要求:
-
文档规范建议:
- 规范分段标识:离线文档的分段标识要有一定规范,否则拆分出来的段落会不规整。
- 段落要完整:一个分段中最好能描述一个完整的功能点或问题。
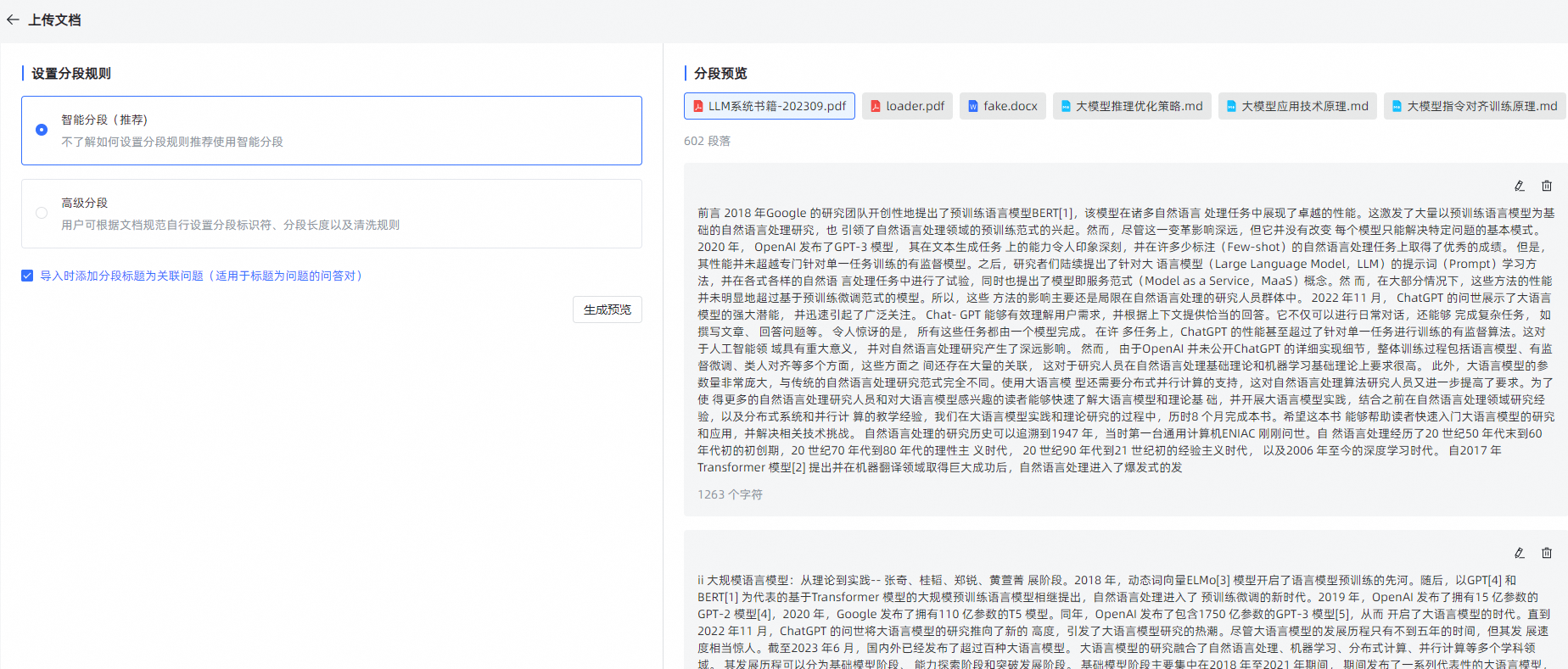
- 设置分段规则
智能分段
MarkDown 类型的文件分段规则为:根据标题逐级下钻式分段(最多支持 6 级标题),每段的字符数最大为 4096 个字符;
当最后一级的文本段落字符数超过设置的分段长度时,会查找分段长度以内的回车进行截取。
HTML、DOCX 类型的分段规则为:识别标题格式转换成 markdown 的标题样式,逐级下钻进行分段(最多支持 6 级标题)每段的字符数最大为 4096 个字符;
TXT和 PDF 类型的文件分段规则为:按照标题# 进行分段,若没有#标题的则按照字符数4096个字符进行分段,会查找分段长度以内的回车进行截取。
高级分段
用户可以根据文档规范自定义设置分段标识符、分段长度及自动清洗。
分段标识支持:#、##、###、####、#####、######、-、空行、回车、空格、分号、逗号、句号,若可选项没有还可以自定义输入分段标识符。
分段长度:支持最小 50个字符,最大 4096 个字符。
自动清洗:开启后系统会自动去掉重复多余的符号如空格、空行、制表符等。
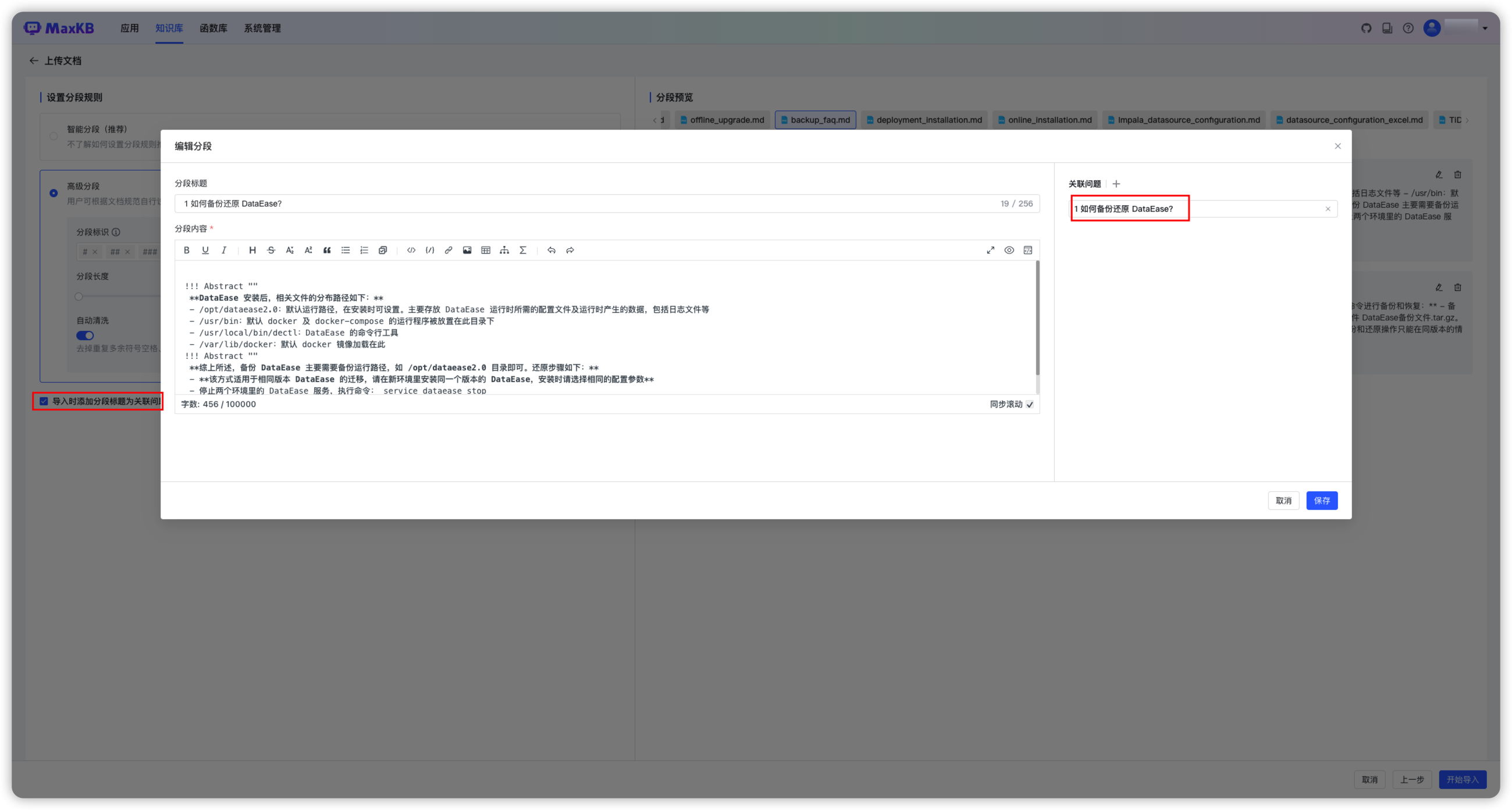
导入时添加分段标题为关联问题
勾选后会把所有分段的标题设置为分段的关联问题。
预览
- 分段规则设置完成后,需要点击【生成预览】查看最新规则的分段效果。
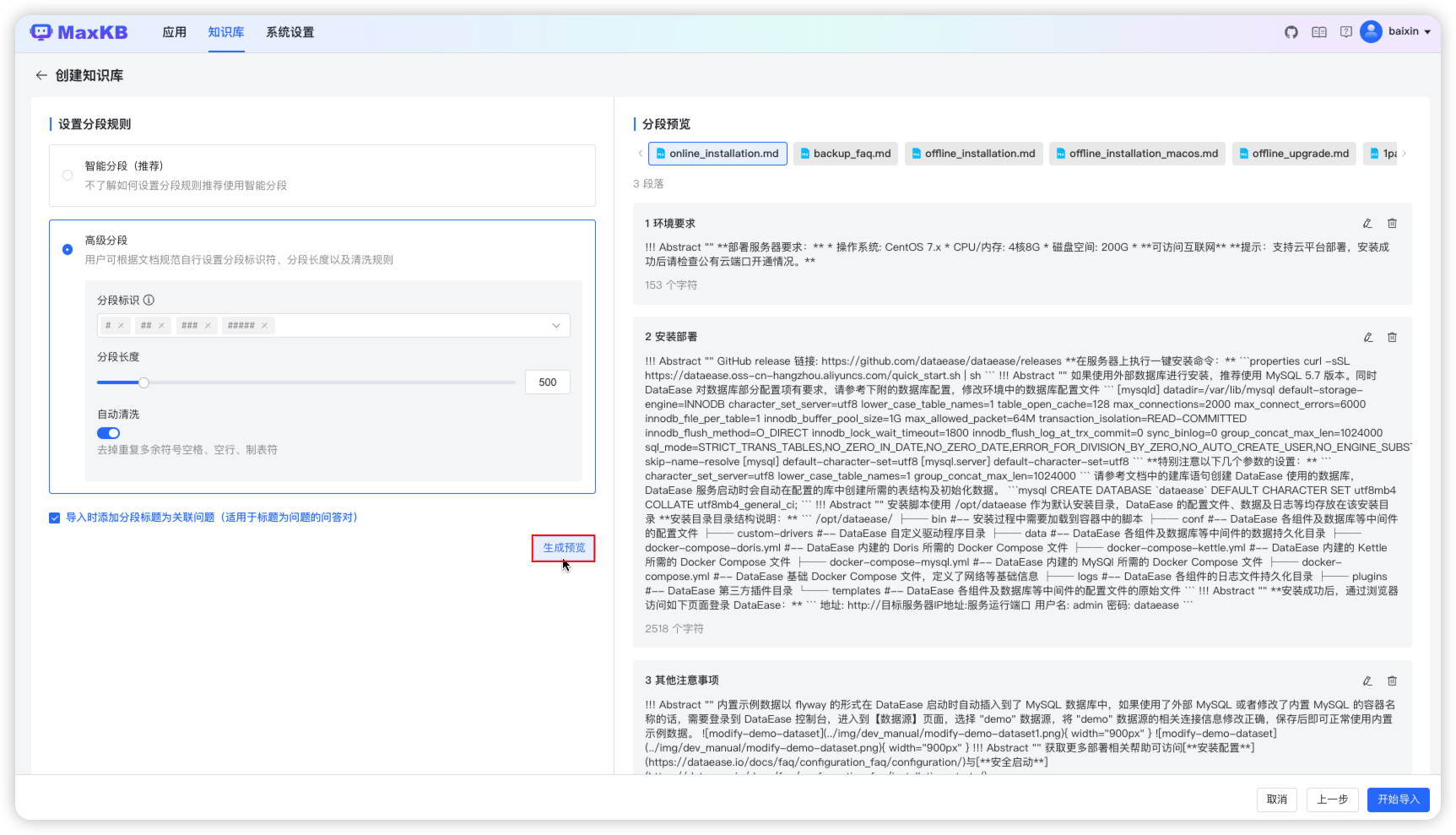
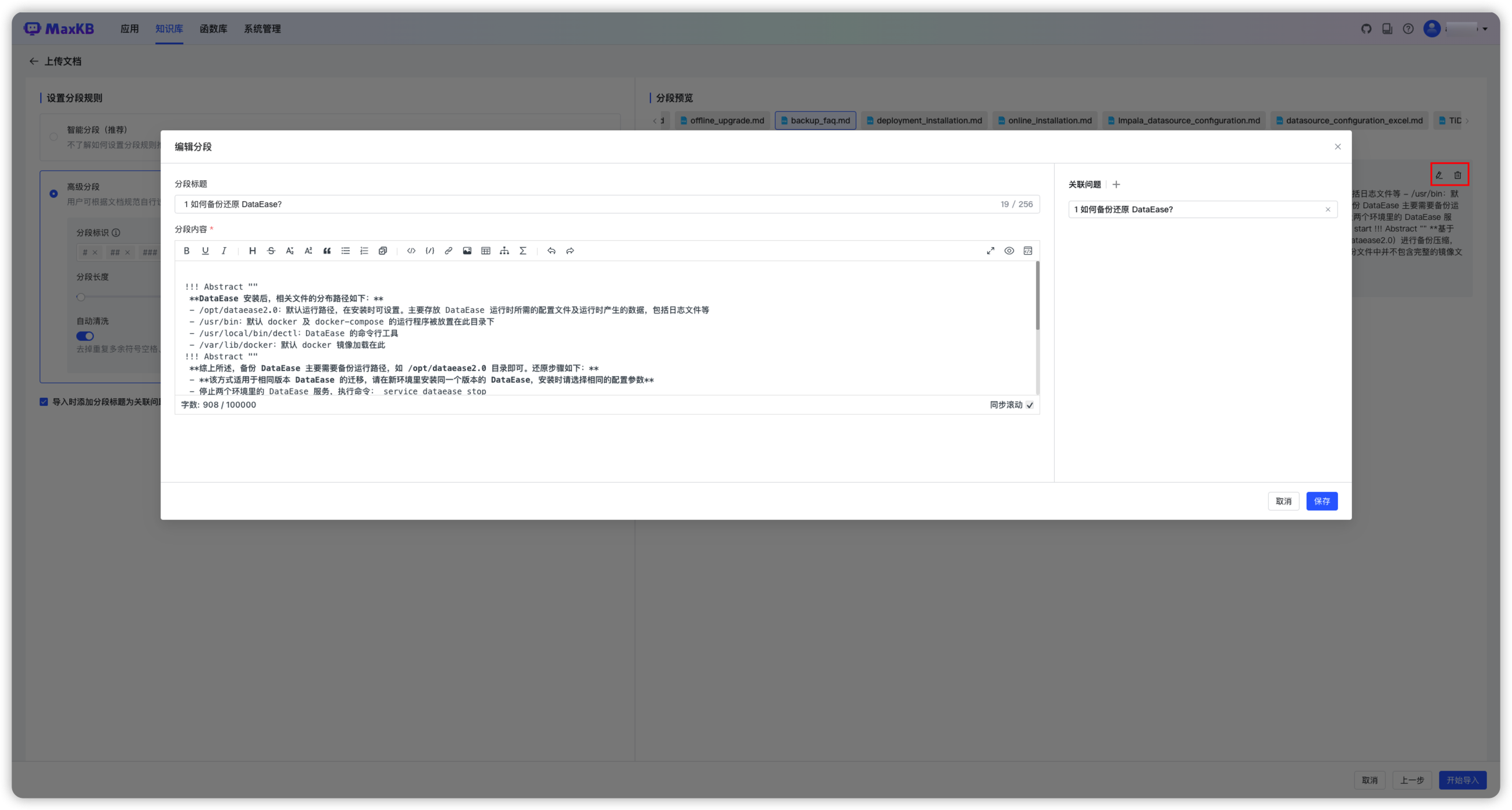
- 用户可在分段预览中对不合理的分段进行编辑和删除。
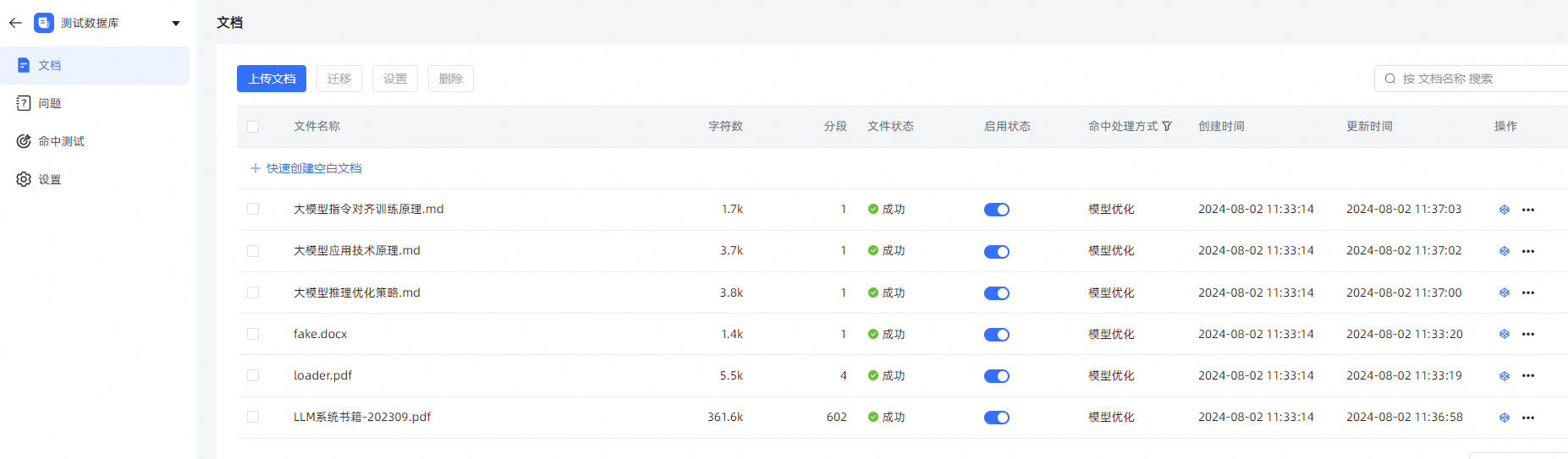
- 点击【创建并导入】后,系统会对文档进行自动分段 -> 存储 -> 向量化处理操作。在创建完成页面可以看到导入的文档数量、分段数量和字符数。
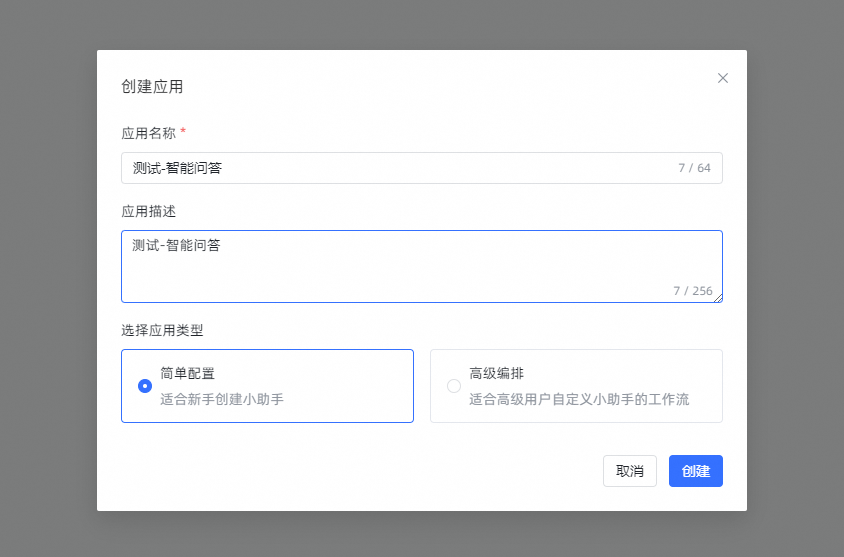
4. 创建应用
点击【创建应用】,输入应用名称,选择【简易配置应用】,点击【创建】
- 应用创建完成,进入简易配置应用的设置页面,左侧为应用信息,右侧为调试预览界面。
- 应用名称:用户提问时对话框的标题和名字。
- 应用描述:对应用场景及用途的描述。
- AI 模型: 在【系统设置】-【模型管理】中添加的大语言模型。
- 提示词:系统默认有智能知识库的提示词,用户可以自定义通过调整提示词内容,可以引导大模型聊天方向. 多轮对话: 开启时当用户提问携带用户在当前会话中最后 3 个问题;不开启则仅向大模型提交当前问题题。
- 关联知识库:用户提问后会在关联的知识库中检索分段。
- 开场白:用户打开对话时,系统弹出的问候语。支持 Markdown 格式;[-] 后的内容为快捷问题,一行一个。
- 问题优化:对用户提出的问题先进行一次 LLM 优化处理,将优化后的问题在知识库中进行向量化检索;
- 开启后能提高检索知识库的准确度,但由于多一次询问大模型会增加回答问题的时长。
应用信息设置完成后,可以在右侧调试预览中进行提问预览,调试预览中提问内容不计入对话日志。
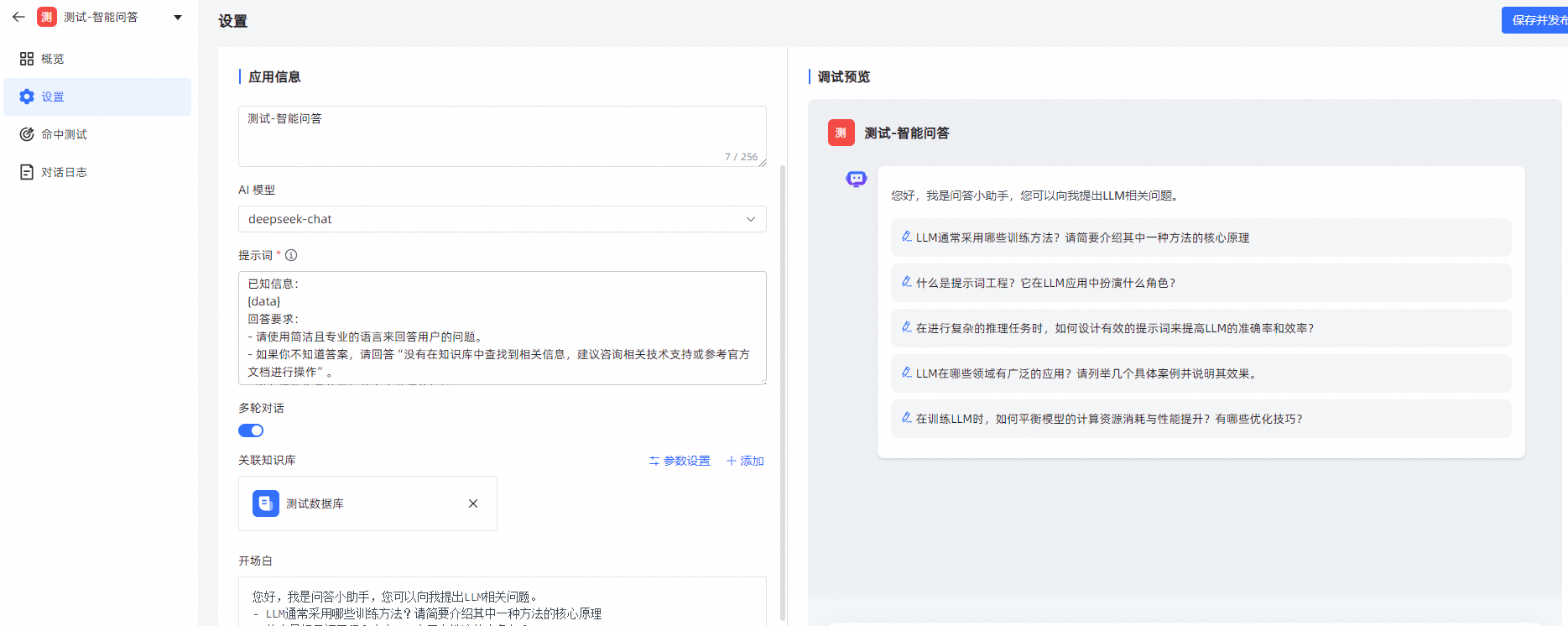
-
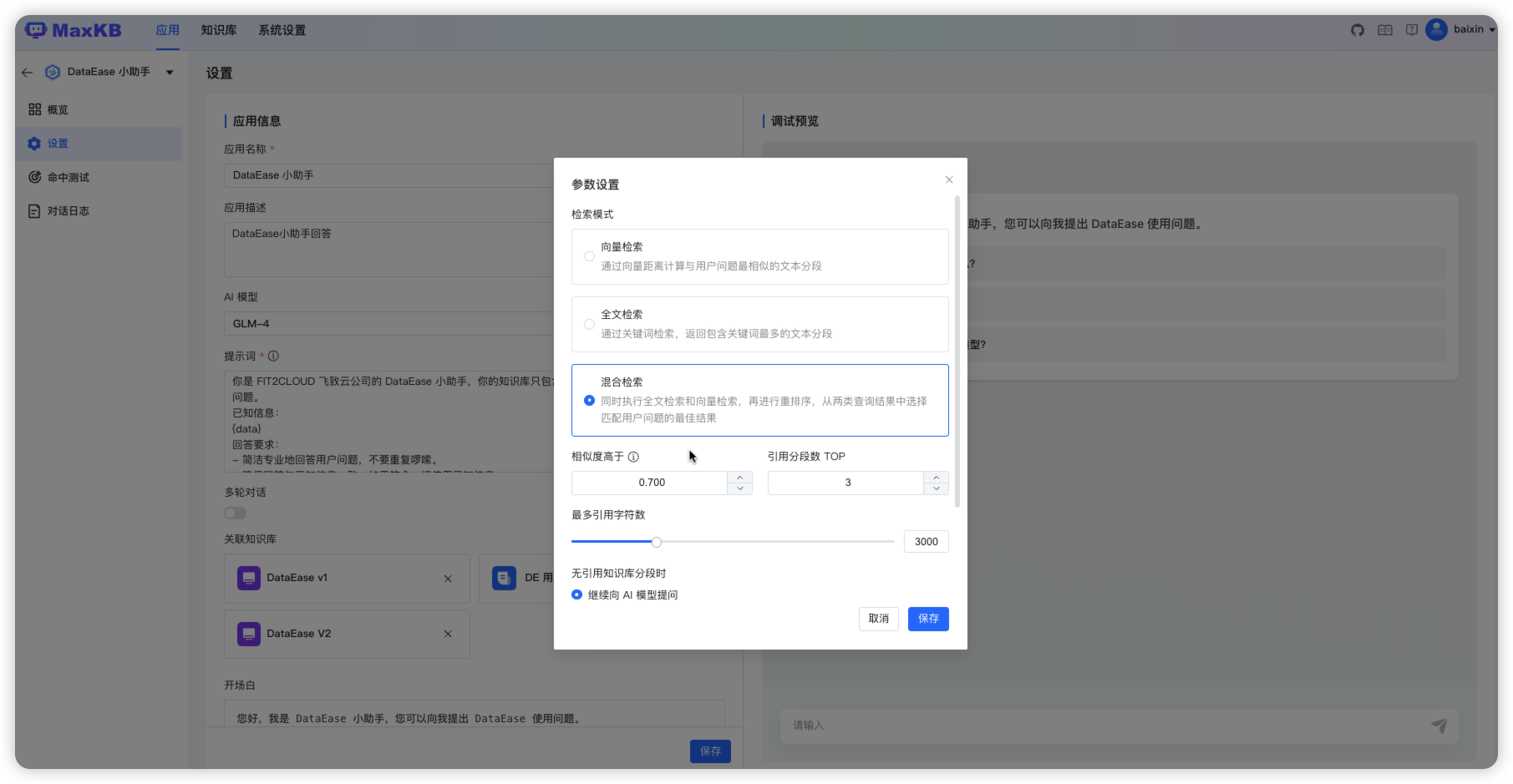
参数设置详细说明
-
检索模式:
向量检索:使用向量模型通过向量距离计算与用户问题最相似的文本分段;全文检索:通过关键词检索,返回包含关键词最多的文本分段;混合检索:同时执行全文检索和向量检索,再进行重排序,从两类查询结果中选择匹配用户问题的最佳结果。
-
相似度:
- 相似度越高代表问题和分段的相关性越强。
-
引用分段数:
- 提问时按相似度携带 N 个分段生成提示词询问 LLM 模型。
-
引用最大字符数:
- 引用分段内容设置最大字符数,超过时则截断。
-
无引用知识库时,有 2 种处理方式可设置:
继续提问:可以自定义设置提示词,需要有 {question} 用户问题的占位符,才会把用户问题发送给模型。指定回复内容:当没有命中知识库分段时可以指定回复内容。
-
以上 4 步完成后,便可进行问答对话了。
5. 效果展示
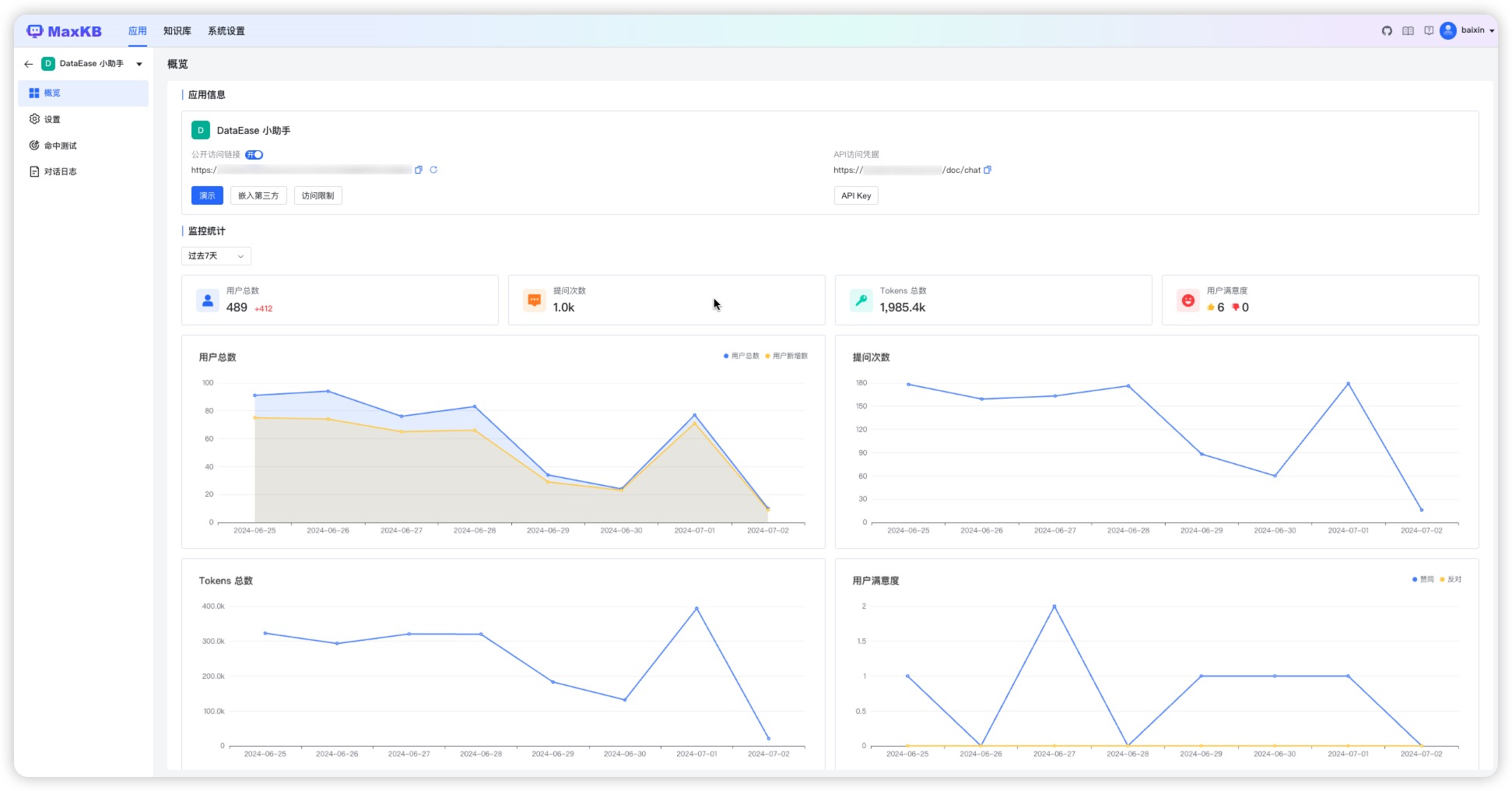
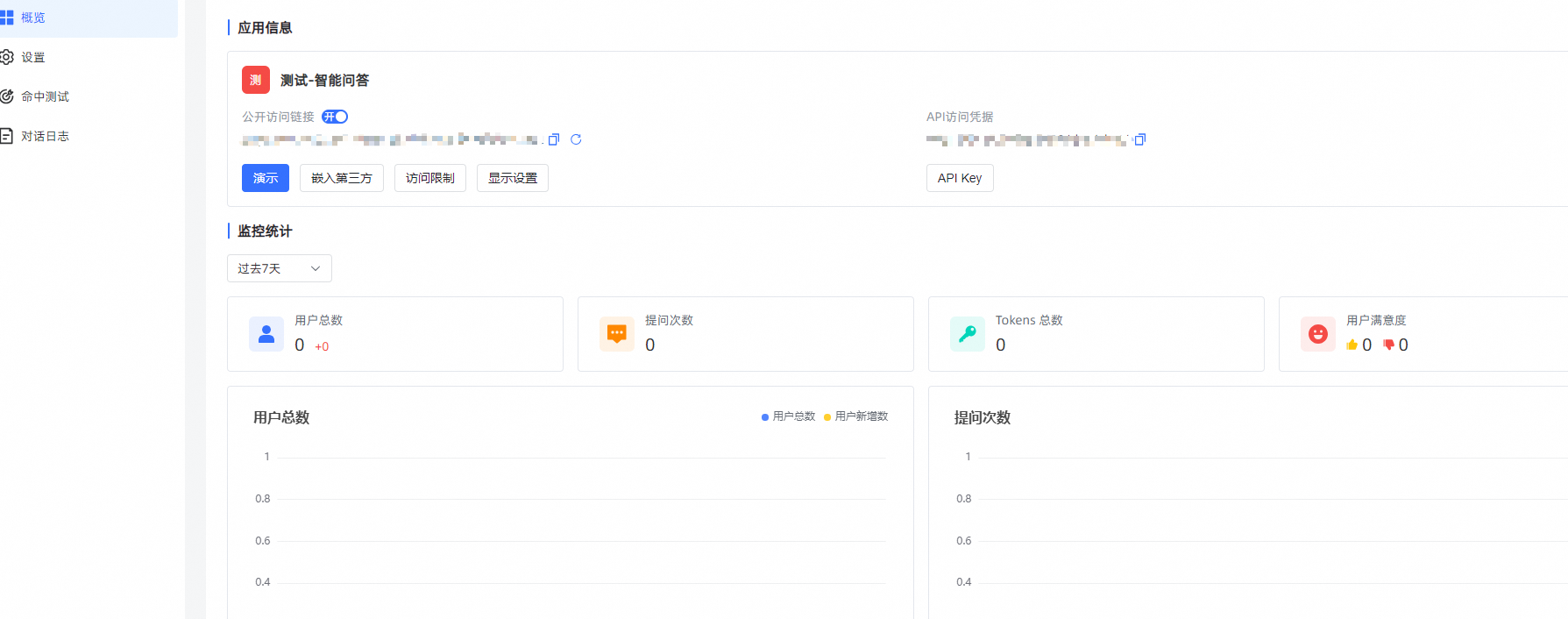
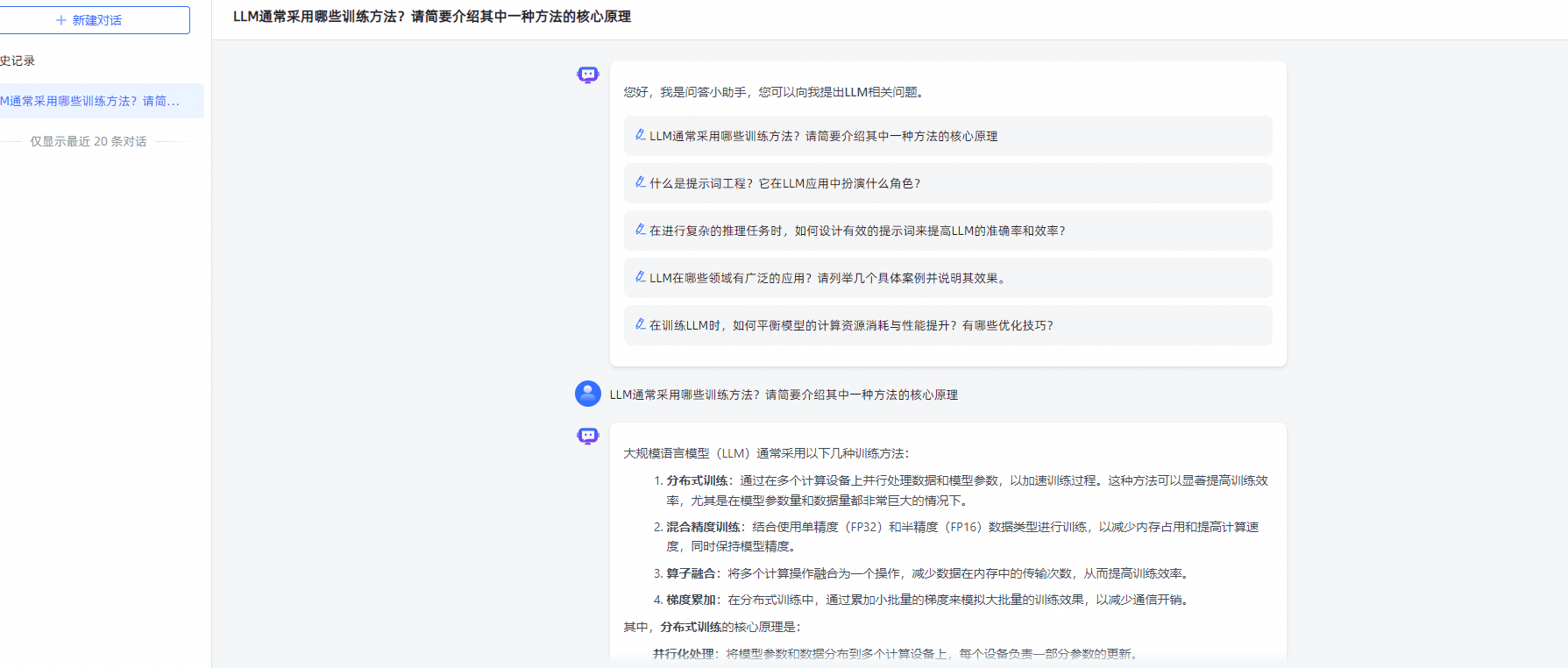
在应用列表页面,点击【演示】或者点击应用面板,在概览页面点击演示或复制公开访问链接至浏览器进入问答页面进行提问。
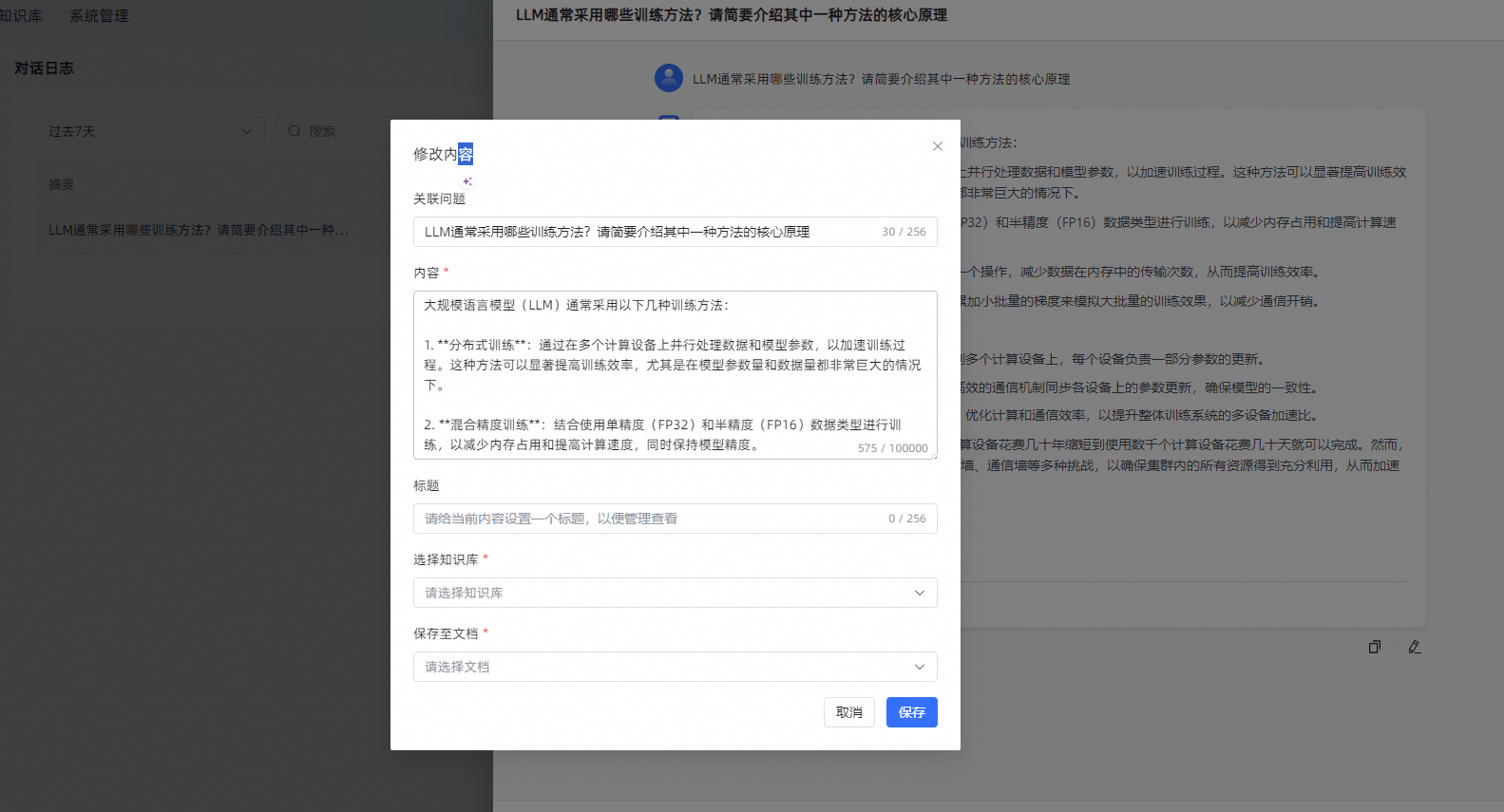
6. 对话日志
在对话日志钟记录了所有用户会话中的问答详情,包括用户对 AI 回答的反馈信息。 维护人员可以通过查看对话日志和用户反馈来修正答案。
更多优质内容请关注公号:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。
更多优质内容请关注CSDN:汀丶人工智能;会提供一些相关的资源和优质文章,免费获取阅读。

分享最新、最前沿的AI大模型技术,吸纳国内前几批AI大模型开发者
更多推荐



 0
0 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)