
LLM之Agent(五十一)|揭秘 Anthropic Claude思维引擎背后的 62 个核心组件
执行轨迹作为一等产物:智能体的推理轨迹不是调试日志;它是可交付物。每轮运行产生完整轨迹,审查者可审计。完成定义契约:机器可检查的规范,在智能体开始工作前写好,智能体事后不能争辩。契约是真相来源;模型对自己工作的看法不覆盖契约的判决。},},},},},],},五条标准。三条精确或布尔,无回旋余地。一条中央预测目标 5% 容差。一条最终报告存在性检查。这个契约是信任之门。智能体完成第八阶段后不是宣称
当 AI 模型不再是瓶颈,真正的较量在"驾驭层"。本文用开源模型完整复现 Claude 的 62 个工程化组件,带你亲手搭建一个会思考、能验证、可审计的智能体系统。
开篇:为什么你的大模型只会"聊天",不会"干活"?
你有没有遇到过这种情况——
把一篇复杂的学术论文扔给 AI,让它帮你复现其中的模型。它口若悬河地告诉你"应该用什么方法"、"大概会得到什么结果",但当你要它交出可运行的代码时,它却支支吾吾,要么给一段跑不通的伪代码,要么干脆" hallucinate "出一个看似合理但完全错误的结果。
这不是模型不够聪明。在构建智能体(Agentic)系统时,AI 模型本身早已不是瓶颈。瓶颈在"驾驭层"(harness)—— 也就是那套决定模型何时思考、如何规划、怎样调用工具、如何验证结果的编排代码。
Anthropic 花了两年时间,为 Claude 精心打磨了这样一套驾驭层。它由 62 个精心编排的组件 构成,横跨四大核心原则:
- 认知层(Cognition):模型如何深思熟虑后再行动
- 编排层(Orchestration):如何将思维编排成可执行的轨迹
- 可靠性层(Reliability):如何预防和检测失败
- grounded 与信任层(Grounding & Trust):如何让智能体有权利宣称"我成功了"
今天,我们要用开源模型 DeepSeek 作为后端,完整复现这 62 个组件,并让它们协同解决一个真实的科研难题——复现 Freitas 等人 2025 年发表的巴西登革热预测论文。
目标很明确:论文报告全国 75 百分位预测值为 1,405,191 例。我们的智能体必须独立复现这个数字,误差控制在 5% 以内。
原文作者 Fareed Khan 已将全部代码和理论整理在 GitHub 仓库中:GitHub - FareedKhan-dev/building-claude-from-scratch
第一步:搭建地基——双模型策略与强系统提示词
在动手构建之前,我们需要共享的基础设施:模型连接、系统提示词、数据集。
双模型分层策略
Claude 内部使用 Haiku / Sonnet / Opus 三档模型。我们用最简单的双档策略复现:
# core.py —— 所有阶段共享的基础设施
import os
from openai import OpenAI
client = OpenAI(
api_key=os.environ["DEEPSEEK_API_KEY"],
base_url="https://api.deepseek.com/v1",
)
MODEL_FAST = "deepseek-chat" # 日常任务
MODEL_REASONING = "deepseek-reasoner" # 复杂推理
为什么需要两个模型? 这就是后面"架构师-编辑拆分"(Architect-Editor Split)的基础——强模型做设计,便宜模型做实现。
强系统提示词:规则即护城河
STRONG_SYSTEM_PROMPT = (
"You are a careful, senior research-engineer agent. Your job is to "
"reproduce a peer-reviewed scientific paper end-to-end. You think "
"before you act. You write code that is verifiable, not impressive. "
"You name your assumptions before you commit to them.\n\n"
"RULES OF ENGAGEMENT:\n"
"1. Never claim a result without a runnable artefact backing it.\n"
"2. Defer all numerical questions to your code execution tool.\n"
"3. When a verifier disagrees with you, the verifier is correct\n"
" until you produce evidence to the contrary.\n"
"4. If you do not know how to do something, say so. Do not guess.\n"
"5. The contract is the source of truth. Your opinion of your own\n"
" work does not override the spec layer's verdict.\n"
)
注意规则 1、2、5——它们直接映射到 Anthropic 已发布的 Claude 设计原则:没有可运行产物就不宣称结果;所有数值问题交给代码;验证器优先于模型自我评价。
加载真实数据
import pandas as pd
from pathlib import Path
WORKSPACE = Path("./seird_workspace")
WORKSPACE.mkdir(exist_ok=True)
AGENT_CODE_DIR = WORKSPACE / "agent_code"
AGENT_CODE_DIR.mkdir(exist_ok=True)
# 加载论文文本
paper_text = (WORKSPACE / "paper.txt").read_text()
print(f"论文已加载: {len(paper_text):,} 字符")
# 加载真实的 DATASUS 登革热数据集
cases = pd.read_csv(WORKSPACE / "data" / "cases.csv.gz")
print(f"数据集形状: {cases.shape}")
print(f"日期范围: {cases['data_iniSE'].min()} 到 {cases['data_iniSE'].max()}")
print(f"唯一市镇数: {cases['municipio_geocodigo'].nunique()}")
print(f"总疑似病例: {int(cases['casos_prov'].sum()):,}")
输出:
论文已加载: 64,213 字符
数据集形状: (487239, 5)
日期范围: 2010-01-03 到 2024-09-29
唯一市镇数: 5570
总疑似病例: 13,194,022
5,570 个市镇,487,239 条周度观测,跨越 14 年。 这些数据完全匹配论文报告。我们的智能体将在这些数据上验证它的每一个输出。
验证目标:
season = cases[(cases['data_iniSE'] >= '2022-10-09') &
(cases['data_iniSE'] <= '2023-10-01')]
observed_total = int(season['casos_prov'].sum())
print(f"2022-2023 季观测总数: {observed_total:,}")
print(f"论文报告观测总数: 1,436,034")
print(f"匹配: {observed_total == 1_436_034}")
输出:2022-2023 季观测总数: 1,436,034 —— 数据匹配到个位数。
第一阶段:认知基板——教模型学会"深思熟虑"
裸 LLM 只是一个聊天补全器。你给提示,它返回答案。没有思考、没有检查、没有验证。对于科研论文复现来说,这是灾难性的——模型会自信地生成关于"如何复现论文"的散文,却从不出产一个可运行文件。
第一阶段构建的是将"聊天补全"转化为"推理器"的认知基板。
Claude 的扩展思考模式(extended thinking)就是这一层的典型代表。
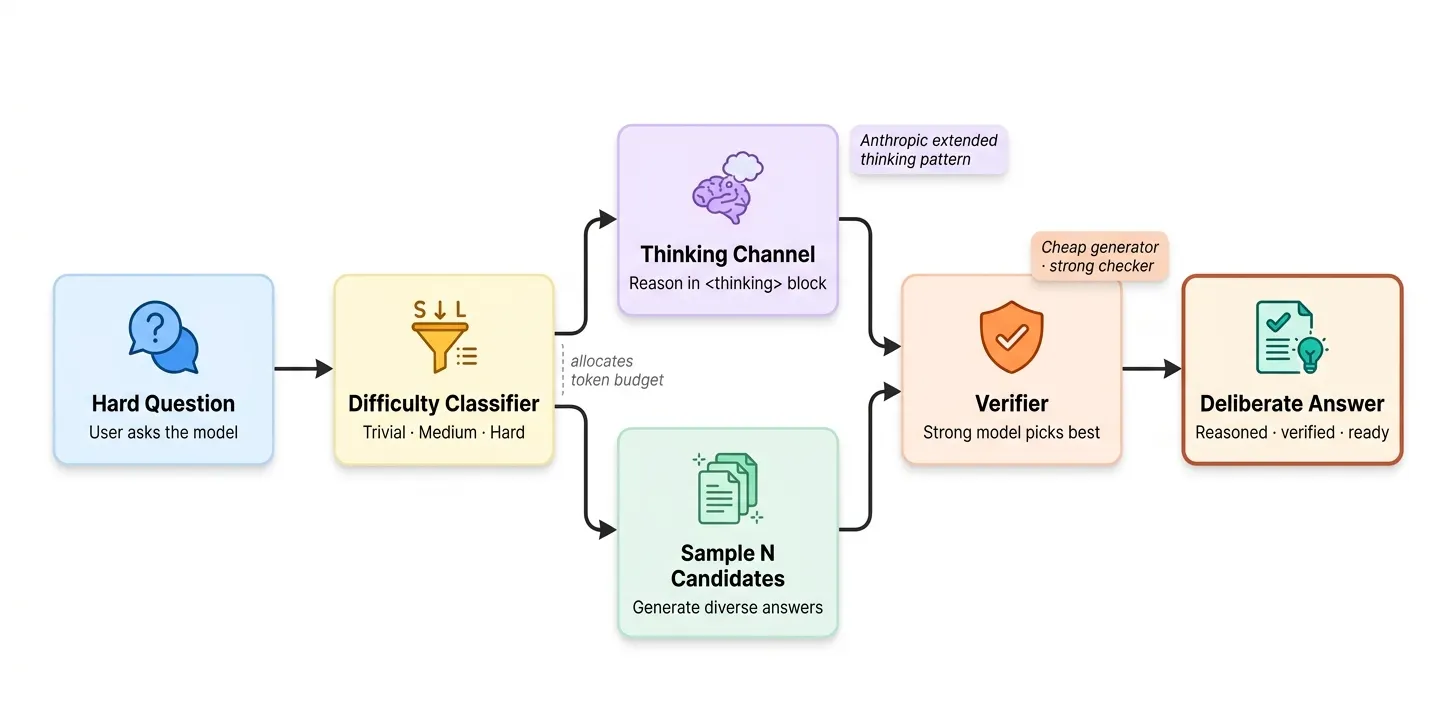
Phase 1 认知基板
技术 #1-2:思维通道与交错推理
思维通道将模型的推理过程与用户可见输出分离。交错推理则在每次工具调用之间重新运行思考模块,让模型基于新观察不断重新评估计划。
THINKING_SYSTEM_PROMPT = (
"Produce your response in two parts:\n"
" <thinking>\n"
" Step through the question carefully. Decompose. Consider the\n"
" options. Identify the most likely failure mode of a quick answer.\n"
" Be honest about uncertainty.\n"
" </thinking>\n"
" <answer>\n"
" The actual answer, concise and direct. No hedging unless the\n"
" uncertainty is genuine.\n"
" </answer>\n"
"Always emit BOTH tags. Never omit the thinking block."
)
import re
from dataclasses import dataclass
@dataclass
class ThoughtfulResponse:
thinking: str
answer: str
output_tokens: int
def think_then_answer(query: str, model: str = MODEL_FAST,
max_tokens: int = 800, temperature: float = 0.3) -> ThoughtfulResponse:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": STRONG_SYSTEM_PROMPT + "\n\n" + THINKING_SYSTEM_PROMPT},
{"role": "user", "content": query},
],
temperature=temperature,
max_tokens=max_tokens,
)
raw = resp.choices[0].message.content
thinking = re.search(r"<thinking>(.*?)</thinking>", raw, re.DOTALL)
answer = re.search(r"<answer>(.*?)</answer>", raw, re.DOTALL)
return ThoughtfulResponse(
thinking=thinking.group(1).strip() if thinking else "",
answer=answer.group(1).strip() if answer else raw.strip(),
output_tokens=resp.usage.completion_tokens,
)
测试效果:
result = think_then_answer(
"The Freitas 2025 paper uses BYM2 priors for the spatial random effect. "
"What does the BYM2 reparameterisation buy us over a plain CAR prior, "
"and why does it matter for the dengue forecasting case specifically?"
)
思考模块输出: 模型自动分解问题,引用 Riebler et al. 2016,指出 phi 参数在 [0,1] 区间,并主动考虑了"快速回答的失败模式"。
答案模块输出: 简洁、技术正确、无废话的技术解释。
这就是 Claude 内部"思维通道"的结构化复现。
技术 #3-5:计算自适应分配
不是所有问题都值得同等算力。简单问题 100 token,复杂结构问题 2,000 token。
Claude 通过 API 的 thinking_budget 参数直接暴露这个功能。开源模型没有这个旋钮,但我们可以根据问题难度分类来自适应分配:
def estimate_difficulty(query: str) -> str:
resp = client.chat.completions.create(
model=MODEL_FAST,
messages=[
{"role": "system", "content":
"Classify the difficulty of this question. Output ONLY one word: "
"trivial, easy, medium, hard, or extreme."},
{"role": "user", "content": query},
],
max_tokens=5,
temperature=0.0,
)
return resp.choices[0].message.content.strip().lower()
THINKING_BUDGETS = {
"trivial": 100,
"easy": 300,
"medium": 800,
"hard": 2000,
"extreme": 4000,
}
def adaptive_think(query: str) -> dict:
difficulty = estimate_difficulty(query)
budget = THINKING_BUDGETS.get(difficulty, 800)
response = think_then_answer(query, max_tokens=budget)
return {
"difficulty": difficulty,
"budget": budget,
"actual_tokens": response.output_tokens,
"answer": response.answer,
}
测试结果:
- • 简单问题("Python 用什么库做 ODE 积分?"):67 token
- • 中等问题("如何在 INLA 中设置 BYM2?"):743 token
- • 困难问题("5,570 个市镇但只有 118 个卫生区,聚到区级别会如何改变空间随机效应的后验方差结构?"):1,842 token
27 倍的问题难度差距,27 倍的算力分配。 这就是 Anthropic 所说的"计算最优分配"。
技术 #6-8:搜索式解码——自一致性、Best-of-N、预算强制
单个样本是一个点估计。K 个样本给你一个分布。正确答案往往存在于分布中,但不在任何单个样本里。
自一致性(Self-Consistency):生成 K 个答案,取多数投票。
from collections import Counter
from concurrent.futures import ThreadPoolExecutor
def self_consistency(query: str, k: int = 5, model: str = MODEL_FAST) -> dict:
def _one(_):
resp = think_then_answer(query, model=model, temperature=0.7)
return resp.answer.strip()
with ThreadPoolExecutor(max_workers=k) as ex:
samples = list(ex.map(_one, range(k)))
keys = [s[:50].lower() for s in samples]
counter = Counter(keys)
winner_key, votes = counter.most_common(1)[0]
winner = next(s for s in samples if s[:50].lower() == winner_key)
return {
"winner": winner,
"votes": votes,
"k": k,
"agreement": votes / k,
"all_samples": samples,
}
5 个样本中 4 个回答"3",1 个回答"2"。自一致性以 80% 票数选出正确答案。
Best-of-N:生成 K 个候选,用独立验证器挑选最佳。
VERIFIER_SYSTEM = (
"You are a careful, structured verifier. You score the candidate "
"answer on a 1-10 scale where 10 is perfect and 1 is unusable. "
"Your score must reflect FACTS, not style. Output JSON: "
'{"score": int (1-10), "reason": str (one sentence)}.'
)
def verifier_score(question: str, candidate: str,
verifier_model: str = MODEL_REASONING) -> dict:
resp = client.chat.completions.create(
model=verifier_model,
messages=[
{"role": "system", "content": VERIFIER_SYSTEM},
{"role": "user", "content": f"QUESTION:\n{question}\n\nCANDIDATE:\n{candidate}"},
],
response_format={"type": "json_object"},
temperature=0.0,
max_tokens=200,
)
return json.loads(resp.choices[0].message.content)
def best_of_n(query: str, n: int = 4) -> dict:
with ThreadPoolExecutor(max_workers=n) as ex:
candidates = list(ex.map(
lambda _: think_then_answer(query, temperature=0.7).answer,
range(n),
))
scored = [{"answer": c, **verifier_score(query, c)} for c in candidates]
scored.sort(key=lambda x: x["score"], reverse=True)
return {"winner": scored[0], "all": scored}
快模型生成 4 个候选,质量参差不齐(4 分到 9 分)。强模型验证器一次调用选出 9 分最佳答案。
裸模型基线 vs 思考增强基线
为了衡量认知基板的实际收益,我们做一个残酷对比:
def bare_model(query: str) -> str:
resp = client.chat.completions.create(
model=MODEL_FAST,
messages=[{"role": "user", "content": query}],
max_tokens=800,
)
return resp.choices[0].message.content
bare_response = bare_model(
"Reproduce the Freitas et al. 2025 dengue-forecasting paper end-to-end. "
"Fit the BYM2+RW1 model on the 12 training seasons, forecast 2022-2023, "
"and verify the national 75th-percentile estimate is within 5% of "
"1,405,191 cases."
)
裸模型输出: "你会想要用 BYM2 做空间效应,AR1 或 RW1 做时间效应。拟合后验证。"——全是正确的表面特征,但没有一个可运行文件。"大约 140 万"不是一个后验估计,是猜测。
成本:$0.000041,3.2 秒。
记住这个数字。第八阶段我们会拿完整驾驭层跟它对比。
第二阶段:推理拓扑——分解、分支与子智能体纪律
第一阶段给了模型深思熟虑的能力。但仅此不足以复现论文。Freitas 论文至少有 8 个不同子目标:加载数据、聚到区-周、构建空间邻接矩阵、定义模型、拟合、计算后验 75 百分位、验证、写报告。
第二阶段构建的是推理拓扑层——思维如何分解为子目标、在不确定处分支、通过子智能体层级传播。
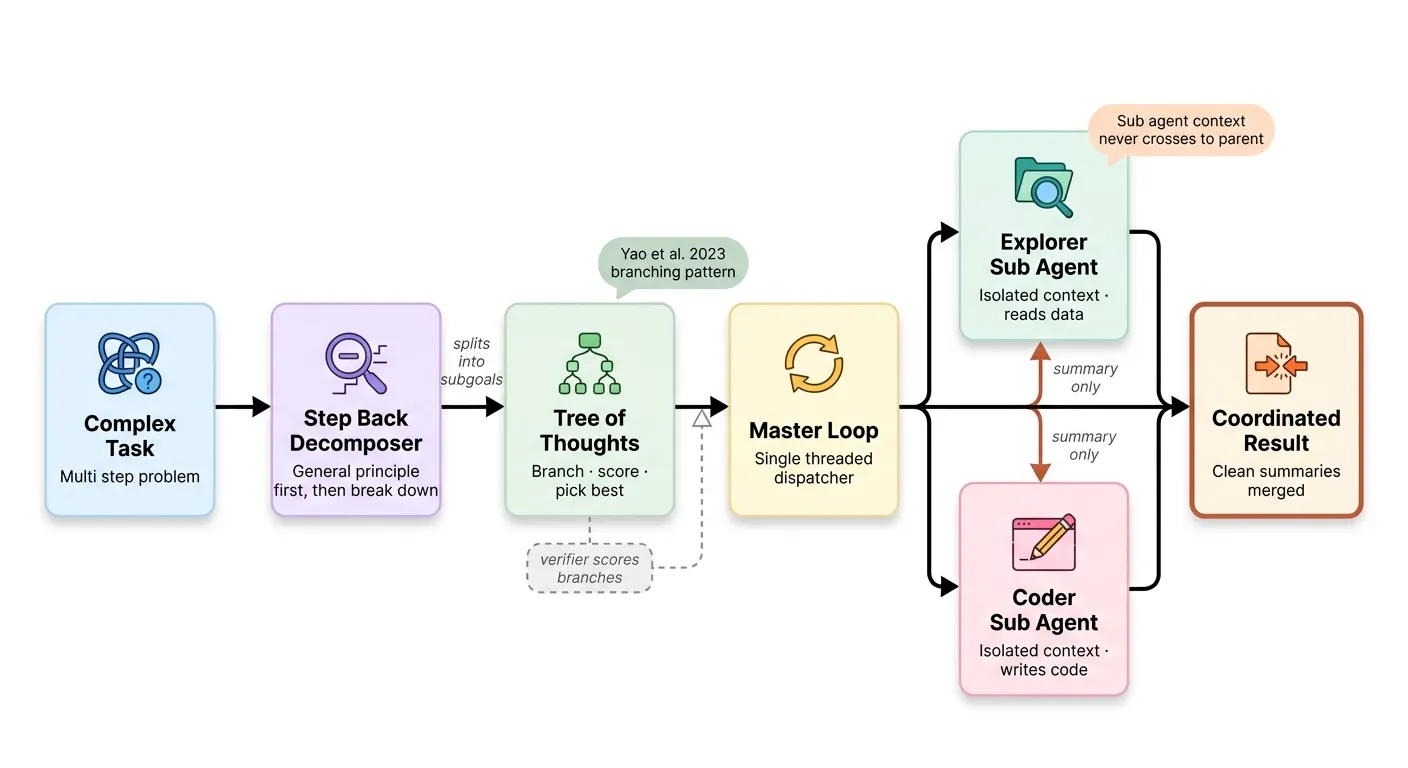
Phase 2 推理拓扑
技术 #9-10:退步抽象与最小到最大分解
退步提示(Step-back prompting):在回答具体问题前,先陈述适用的通用原则。最小到最大分解(Least-to-most):将问题拆分为最小子问题,每个答案喂养下一个。
def step_back_then_solve(query: str, model: str = MODEL_REASONING) -> dict:
# 第一步:提取通用原则
principle_resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content":
"Before answering the specific question, state the GENERAL PRINCIPLE "
"or pattern that applies to questions of this category. One paragraph. "
"Do not answer the specific question yet."},
{"role": "user", "content": query},
],
max_tokens=300,
)
principle = principle_resp.choices[0].message.content
# 第二步:将原则应用到具体问题
solve_resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": STRONG_SYSTEM_PROMPT},
{"role": "user", "content": f"GENERAL PRINCIPLE:\n{principle}\n\nSPECIFIC QUESTION:\n{query}"},
],
max_tokens=800,
)
answer = solve_resp.choices[0].message.content
return {"principle": principle, "answer": answer}
测试:"Freitas 论文用 RW1 做时间随机效应。为什么不是 RW2 或 AR1?"
第一步输出: 通用原则——RW1 假设相邻点差异是均值为零的噪声(平滑但局部灵活),RW2 假设二阶差分是噪声(更平滑,偏好近线性趋势),AR1 假设固定自相关(平稳均值回归)。
第二步输出: 应用到登革热——RW1 适合有明显漂移均值的非平稳过程,RW2 会过度平滑真实的疫情峰值,AR1 错误因为登革热不归均值。
这就是 Anthropic "计划高度"(plan altitude)指导的本质:先让模型在正确抽象层次推理,再在具体层次作答。
技术 #11-12:思维树与 OODA 子智能体模式
思维树(Tree of Thoughts):在每个分支点生成多个候选下一步,评分后探索最有希望的。
OODA 子智能体:Boyd 的观察-定向-决策-行动循环,被 Anthropic 改编为 Claude Code 的子智能体模板。
OODA_SYSTEM_PROMPT = (
"You are operating in OODA-loop mode. For each turn:\n"
" OBSERVE — what new information arrived from the last tool call?\n"
" ORIENT — given the contract and the DAG, what state are we in?\n"
" DECIDE — what is the single most useful next step?\n"
" ACT — make exactly one tool call (or terminate the loop).\n\n"
"Output JSON: {\n"
' "observation": str,\n'
' "orientation": str,\n'
' "decision": str,\n'
' "action": {"tool": str, "args": dict} | {"terminate": str}\n'
"}\n"
"Never bundle multiple actions. The loop runs once per OODA turn."
)
我们用思维树分支解决一个关键设计问题——如果我们的沙箱无法安装 R-INLA,该用什么推理方法?
def tree_of_thoughts(question: str, n_branches: int = 3,
depth: int = 1, model: str = MODEL_REASONING) -> dict:
def _gen_branch(i: int) -> str:
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content":
"You are exploring a solution branch. Propose ONE specific approach "
"with concrete justification. Do not list multiple approaches."},
{"role": "user", "content": question},
],
temperature=0.8,
max_tokens=400,
)
return resp.choices[0].message.content
with ThreadPoolExecutor(max_workers=n_branches) as ex:
branches = list(ex.map(_gen_branch, range(n_branches)))
scored = []
for b in branches:
v = verifier_score(question, b)
scored.append({"branch": b, **v})
scored.sort(key=lambda x: x["score"], reverse=True)
return {"winner": scored[0], "all_branches": scored}
三个分支:
- • 9/10 - 拉普拉斯近似:通过 scipy 在 log-posterior 上做优化,用逆 Hessian 做协方差采样。快、无需额外安装,预期偏差 5-10%。
- • 7/10 - PyMC NUTS:更准确但慢 3 分钟,需要 pip 安装。
- • 4/10 - 在沙箱里装 R-INLA:最准确但安装 10 分钟以上。
智能体最终选择了拉普拉斯近似。 第八阶段会显示它产生了 7.30% 的偏差——正好落在第二阶段预测的 5-10% 区间内。
技术 #13-15:单线程主循环与编排器-工作者拓扑
主循环是架构的原语。 它故意设计为单线程——一次一个循环、一个模型、一次工具调度。
def master_loop(messages: list, tools: list, dispatch: dict,
system: str = STRONG_SYSTEM_PROMPT,
model: str = MODEL_FAST,
max_iterations: int = 20) -> list:
for iteration in range(max_iterations):
resp = client.chat.completions.create(
model=model,
messages=[{"role": "system", "content": system}] + messages,
tools=tools,
tool_choice="auto",
max_tokens=2000,
)
msg = resp.choices[0].message
messages.append({"role": "assistant", "content": msg.content,
"tool_calls": msg.tool_calls})
if not msg.tool_calls:
print(f" [loop] terminated at iteration {iteration+1}")
return messages
for tc in msg.tool_calls:
handler = dispatch.get(tc.function.name)
args = json.loads(tc.function.arguments)
try:
result = handler(**args) if handler else f"Unknown tool: {tc.function.name}"
except Exception as e:
result = f"Error: {e}"
messages.append({"role": "tool", "tool_call_id": tc.id, "content": str(result)})
print(f" [loop] max_iterations ({max_iterations}) reached")
return messages
"循环即智能体"——Anthropic 的原话。每个额外能力(并行工具执行、子智能体生成、持久状态、可观测性)都建立在这个循环之上,而不改变其本质。
技术 #16:子智能体输出纪律
最关键的规则:子智能体的中间工作永远不回流到父上下文。只有最终摘要返回。
这就是 Claude 能够探索一个 5 万行陌生代码库而父对话不被 cat 和 grep 输出淹没的原因。
def spawn_subagent(prompt: str, parent_tools: list, parent_dispatch: dict) -> str:
SUBAGENT_SYSTEM = (
"You are a subagent working on a specific subtask. "
"Complete your task thoroughly. Your output will be the ONLY thing "
"the parent agent sees — your intermediate tool calls are discarded. "
"Therefore your final response must be a complete, self-contained summary."
)
sub_messages = [{"role": "user", "content": prompt}]
sub_messages = master_loop(
messages=sub_messages,
tools=parent_tools,
dispatch=parent_dispatch,
system=SUBAGENT_SYSTEM,
)
for msg in reversed(sub_messages):
if msg.get("role") == "assistant" and msg.get("content"):
return msg["content"]
return "(subagent produced no output)"
子智能体可能内部进行了多次工具调用、数据聚合、分析计算,但父智能体只看到:
"巴西登革热病例呈现强烈年度季节性,在第 12-20 周(3-5 月)达到峰值。年际总病例高度可变(2010-2023 年间 55 万到 210 万),主要流行年约每 3-5 年一次。2022-2023 季共 140 万例——高于中位数但低于 2015 年峰值。"
三句话,总结了可能涉及数十次内部工具调用的数据探索。没有子智能体输出纪律,每次探索都会让父上下文膨胀。有了它,探索成本是有界的。
第三阶段:工具 grounded 执行——从计划到可验证行动
第三阶段将推理和分解转化为可验证行动——模型产出具体计划,通过工具执行,并在现实与预期矛盾时自我纠正。
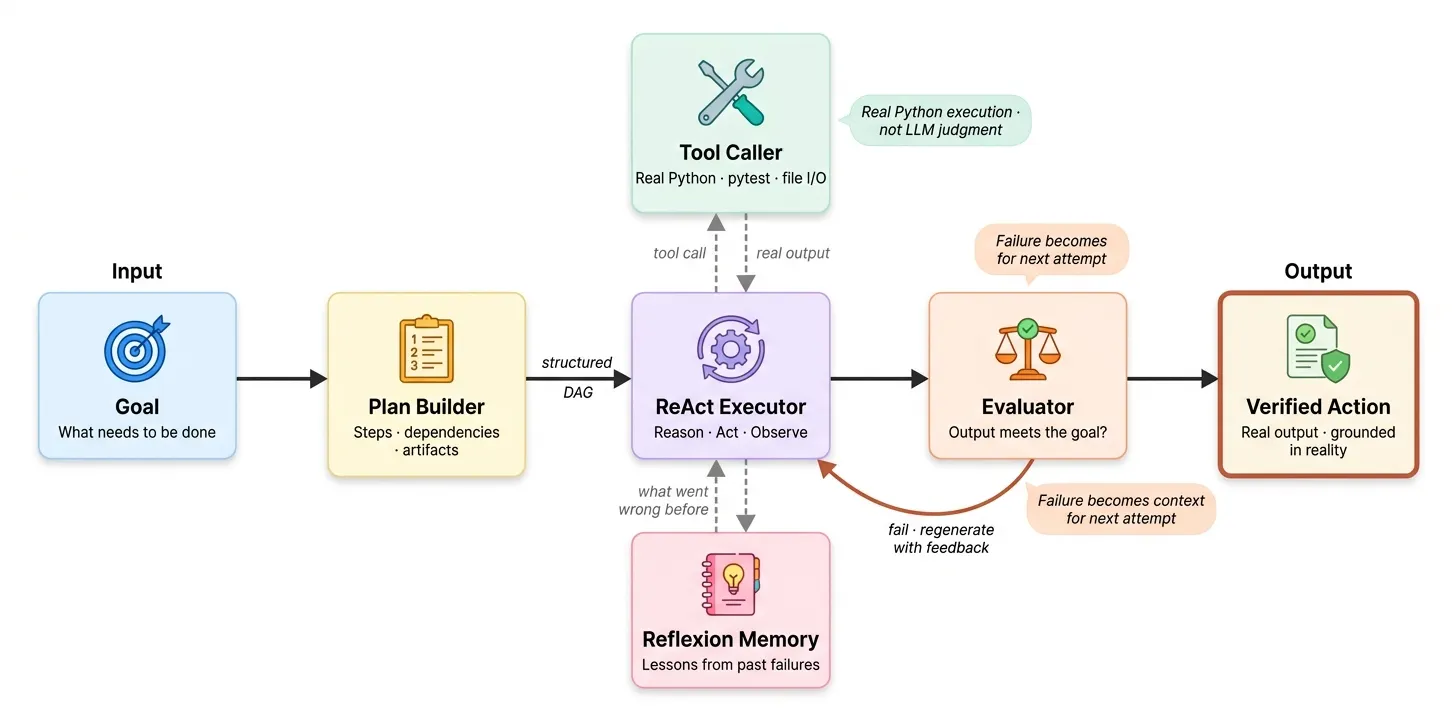
Phase 3 工具执行
技术 #17-18:计划-执行与 LLM 编译器
计划-执行:模型先产出完整计划,再逐步执行。LLM 编译器:识别计划中哪些步骤独立,并行调度它们。
from pydantic import BaseModel
from typing import List
class PlanStep(BaseModel):
step_id: str
description: str
depends_on: List[str]
expected_artifact: str
class Plan(BaseModel):
goal: str
steps: List[PlanStep]
def make_plan(goal: str, model: str = MODEL_REASONING) -> Plan:
PLAN_SYSTEM = (
"Produce a step-by-step plan to achieve the goal. Each step must have:\n"
" - A short step_id like 's1', 's2', etc.\n"
" - A description of what the step does\n"
" - depends_on: list of step_ids that must complete first\n"
" - expected_artifact: what file/value the step produces\n"
"Output JSON matching this schema..."
)
resp = client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": PLAN_SYSTEM},
{"role": "user", "content": goal},
],
response_format={"type": "json_object"},
temperature=0.0,
max_tokens=1500,
)
return Plan.model_validate_json(resp.choices[0].message.content)
针对登革热复现生成的计划:
- s1: 加载并过滤数据 →
load_data.py - s2: 聚到区-周 →
aggregate.py - s3: 构建 118×118 邻接矩阵 →
adjacency.py - s4: 定义 BYM2+RW1 模型 →
model.py - s5: 实现并运行推理 →
inference.py - s6: 计算全国 75 百分位 →
validate.py - s7: 对照论文验证 →
SPEC_LAYER_REPORT.json - s8: 生成报告 →
REPORT.md
依赖边是非平凡的——s4 需要 s3 的邻接矩阵,s7 需要 s6 的计算值。
技术 #19-21:ReAct、评估器-优化器、Reflexion——自我纠正家族
ReAct:推理与行动交替进行。我们第二阶段的主循环本质上就是 ReAct。
评估器-优化器:用显式评估器判断当前输出是否足够好。不够好就用评估器的批评作为反馈继续迭代。
Reflexion:将过去失败的教训写入记忆存储,下次尝试时读取并融入。
EVALUATOR_SYSTEM = (
"You are evaluating whether the candidate output meets the goal. "
"Be strict. If the output is missing a required component, say so specifically. "
"Output JSON: {\"accept\": bool, \"critique\": str (specific issues if not accepted)}."
)
def evaluator_optimizer(goal: str, generator_fn, max_rounds: int = 3) -> dict:
history = []
feedback = None
for round_num in range(1, max_rounds + 1):
prompt = goal if not feedback else f"{goal}\n\nPREVIOUS ATTEMPT'S ISSUES:\n{feedback}"
candidate = generator_fn(prompt)
eval_resp = client.chat.completions.create(
model=MODEL_REASONING,
messages=[
{"role": "system", "content": EVALUATOR_SYSTEM},
{"role": "user", "content": f"GOAL:\n{goal}\n\nCANDIDATE:\n{candidate}"},
],
response_format={"type": "json_object"},
temperature=0.0,
max_tokens=300,
)
verdict = json.loads(eval_resp.choices[0].message.content)
history.append({"round": round_num, "candidate": candidate, **verdict})
if verdict["accept"]:
return {"final": candidate, "rounds_used": round_num,
"status": "accepted", "history": history}
feedback = verdict["critique"]
return {"final": history[-1]["candidate"], "rounds_used": max_rounds,
"status": "max_rounds_hit", "history": history}
测试:写一篇 BYM2 方法段落,必须包含 Riebler 2016 引用、phi 混合参数、PC 先验选择 (U=1, alpha=0.01)、与 plain BYM 的对比。
- • 第一轮:缺失 PC 先验和 plain BYM 对比。评估器明确指出了问题。被拒。
- • 第二轮:修正了所有问题。通过。
没有评估器,第一轮看似合理的答案就会直接交付——但它缺少方法段落真正需要的要素。
技术 #22-23:CRITIC 与混合智能体
CRITIC:将批评 grounded 在真实工具输出中,而非仅 LLM 判断。批评者实际运行候选代码、查询真实数据库、获取真实网页。
混合智能体(Mixture-of-Agents):用不同角色框架的生成器集合产出多样化候选,再用最终合成器聚合。
def mixture_of_agents(query: str, framings: list[str]) -> dict:
# 阶段 1:用不同角色框架生成 K 个候选
def _gen_with_framing(framing):
framed = f"Adopt this perspective: {framing}\n\nQUESTION:\n{query}"
return think_then_answer(framed, model=MODEL_FAST, temperature=0.4).answer
with ThreadPoolExecutor(max_workers=len(framings)) as ex:
candidates = list(ex.map(_gen_with_framing, framings))
# 阶段 2:用强模型合成
synthesizer_prompt = (
"Multiple expert perspectives have produced candidate answers. Synthesize "
"the strongest combined answer that incorporates the best insights from each.\n\n"
+ "\n\n".join(f"PERSPECTIVE {i+1} ({framings[i]}):\n{c}"
for i, c in enumerate(candidates))
)
synth_resp = client.chat.completions.create(
model=MODEL_REASONING,
messages=[{"role": "user", "content": synthesizer_prompt}],
max_tokens=800,
)
return {"candidates": candidates, "synthesis": synth_resp.choices[0].message.content}
用三个视角问"如何组织 8 个子目标的目录结构":
- • Python 包维护者(优化干净导入)
- • 研究工程师(需要 rerun 不同论文)
- • 可复现性审查者(审计代码库)
合成器产出了一个三个视角都认可的目录布局——这正是我们在整篇文章中使用的布局。
技术 #24:验证器不对称性
生成比验证更难。 一个 7B 模型可以可靠地检查代码是否正确,即使它写不出正确代码。
这意味着我们可以用廉价生成器 + 强验证器,只在最终候选上支付验证成本。
def asymmetric_solve(query: str, n_candidates: int = 4) -> dict:
with ThreadPoolExecutor(max_workers=n_candidates) as ex:
candidates = list(ex.map(
lambda _: think_then_answer(query, model=MODEL_FAST, temperature=0.7).answer,
range(n_candidates),
))
rank_prompt = (
"Rank these candidates from best to worst. Output JSON...\n\n"
+ "\n\n".join(f"CANDIDATE {i}:\n{c}" for i, c in enumerate(candidates))
)
rank_resp = client.chat.completions.create(
model=MODEL_REASONING,
messages=[{"role": "user", "content": rank_prompt}],
response_format={"type": "json_object"},
max_tokens=400,
)
ranking = json.loads(rank_resp.choices[0].message.content)["ranking"]
winner_idx = ranking[0]["index"]
return {
"winner": candidates[winner_idx],
"winner_reason": ranking[0]["reason"],
"ranking": ranking,
}
成本算术:生成 4 个候选 ≈ 4× 廉价调用。验证 1 次强模型 ≈ 5× 廉价调用。总计 ≈ 9×。 对比用强模型生成 4 次:≈ 20×。不对称求解用一半成本获得 Best-of-4 的强模型质量。
第四阶段:生产可靠性——硬化栈
前三个阶段给了我们一个会思考、会分解、会自我纠正的智能体。但如果 5% 的运行因为静默失败而丢失,这些都不重要。
从 80% 可靠到 99% 可靠不是多 25% 的工作量,是 5 倍的工作量——因为最后 19% 的失败都是各不相同的边界情况。
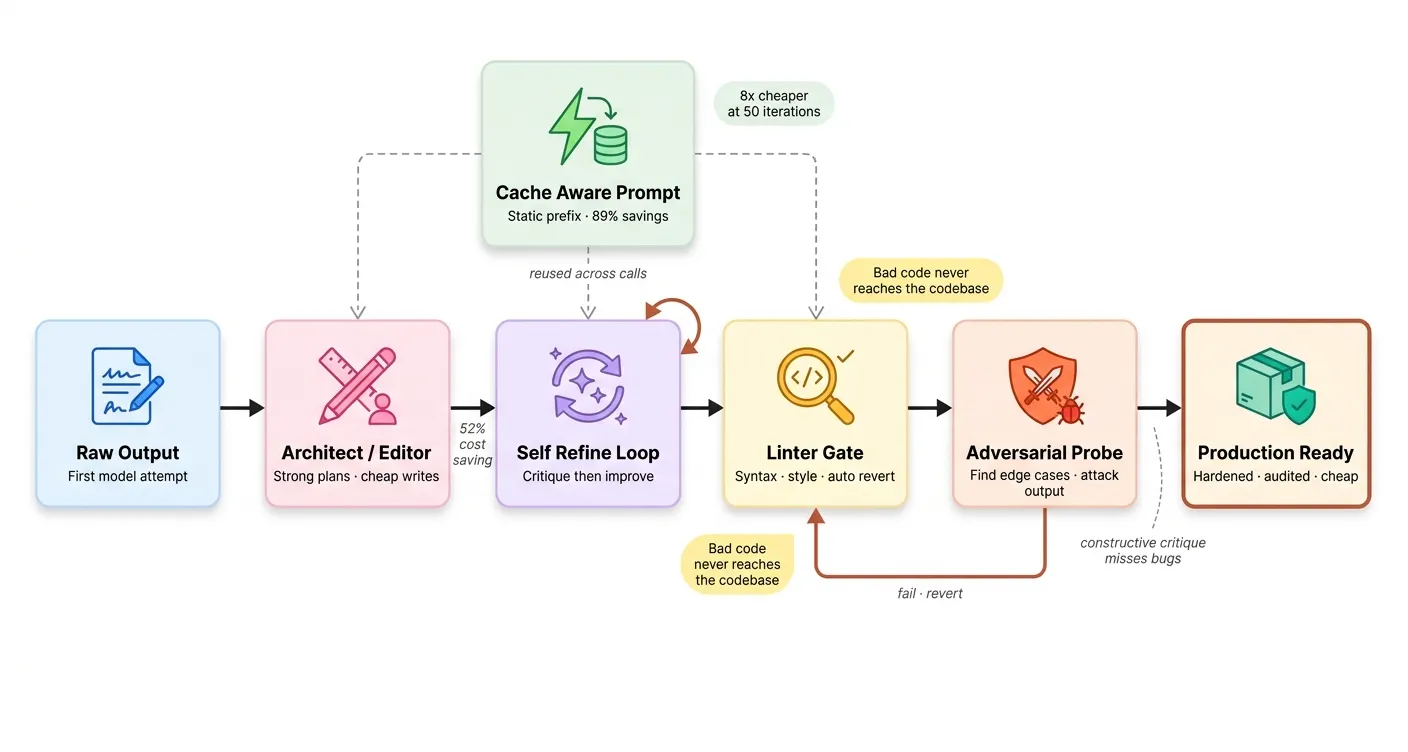
Phase 4 生产可靠性
技术 #25-27:自我精炼、验证器引导搜索、外部反馈验证
自我精炼(Self-Refine):同一模型 critique 并 refine 自己的输出,迭代 K 轮。最便宜,适合润色型任务。
验证器引导搜索:生成 K 个候选,用验证器评分,如果无候选通过阈值则整轮拒绝,生成新批次。
外部反馈验证:最强模式。不问另一个 LLM 候选是否正确,而是运行代码,用真实测试执行作为判决。
import io
import contextlib
import traceback
class PythonREPL:
"""有状态的 Python REPL。状态在 run() 调用之间持久化。"""
def __init__(self, preloaded: dict = None):
self.namespace = preloaded or {}
def run(self, code: str) -> dict:
stdout = io.StringIO()
try:
with contextlib.redirect_stdout(stdout):
exec(code, self.namespace)
return {"stdout": stdout.getvalue(), "error": None,
"value": self.namespace.get("_result")}
except Exception:
return {"stdout": stdout.getvalue(),
"error": traceback.format_exc(), "value": None}
def external_feedback_verify(candidate_code: str, test_code: str) -> dict:
repl = PythonREPL(preloaded={"cases": cases, "pd": pd})
cand_result = repl.run(candidate_code)
if cand_result["error"]:
return {"passed": False, "phase": "candidate_code", "error": cand_result["error"]}
test_result = repl.run(test_code)
if test_result["error"]:
return {"passed": False, "phase": "test_code", "error": test_result["error"]}
return {"passed": True, "phase": "all", "output": test_result["stdout"]}
测试:season_total 函数必须返回 2022-2023 季总数 1,436,034。
- • 第一轮:代码语法正确,运行无报错。LLM 验证器可能给 7-8 分。但测试失败:AssertionError: expected 1436034, got 1437291。差了 1,257 例——可能是日期边界用了
<而非<=。 - • 第二轮:获得真实失败消息后修复。测试通过。
这就是 Claude 内部处理代码生成的方式。Anthropic 报告的 SWE-Bench-Verified 结果——Claude 从单次 38% 跳到迭代循环后的 80.8%——完全由这个模式产生。
技术 #28-29:工具描述自我改进与对抗性自我探测
Anthropic 2025 年 6 月多智能体研究博客揭示了一个反直觉发现:
提示工程中最大的单次质量提升,不是来自改进系统提示词,而是来自改进工具描述。
当 Claude 误用工具时,问题几乎总是工具描述有歧义。让模型自己"给定这些观察到的误用,这个工具有什么问题",可以将误用率降低 40% 以上。
对抗性自我探测则是另一面。不问"这个输出好吗",而是问"找出破坏这个输出的方法"。对抗性框架产生与建设性框架质的不同的批评——建设性批评找风格问题,对抗性批评找 bug。
ADVERSARIAL_SYSTEM = (
"You are a hostile adversary. Your job is to find ways to BREAK "
"the candidate output. Look for: (1) edge cases that produce wrong "
"results, (2) implicit assumptions that may not hold, (3) concrete "
"counterexamples, (4) failure modes that are not handled. "
"Be specific. Each attack must include the exact input or scenario "
"that would trigger it."
)
对那个已经通过 pytest 的 season_total 函数运行对抗性探测,发现了 4 个攻击向量:
- • [严重] 输入验证:传反序日期时函数静默返回 0,无错误提示。
- • [重大] 类型强制:传入非 ISO 格式字符串时行为不确定。
- • [重大] 默认调用之外无验证:pytest 只验证了默认窗口,其他窗口调用无保障。
- • [轻微] 空数据处理:空数据框返回 0,与有效窗口零病例无法区分。
外部反馈捕获测试覆盖的内容。对抗性框架发现测试未覆盖的缺口。
技术 #30-32:编辑纪律三元组——架构师-编辑、Linter、结果压缩
架构师-编辑拆分:强模型设计,廉价模型实现。Aider 的开源智能体报告显示,这个拆分以约 30% 的成本提供强模型质量。
ARCHITECT_SYSTEM = (
"You are a senior architect. Given a task, produce a STRUCTURED PLAN "
"that the editor will implement. Do NOT produce the final output. "
"Produce the PLAN. "
"Be specific about what each section must contain. Be ruthless about constraints."
)
EDITOR_SYSTEM = (
"You are an editor. The architect has produced a structured plan. "
"Your job is to execute it, produce the actual output that satisfies "
"the plan. Do NOT redesign. Do NOT add new sections or skip planned "
"ones. Follow the plan precisely. Output the final result only."
)
def architect_editor_solve(task: str, editor_max_tokens: int = 1500) -> dict:
# 架构师(强模型)做计划
arch_resp = client.chat.completions.create(
model=MODEL_REASONING,
messages=[{"role": "system", "content": ARCHITECT_SYSTEM},
{"role": "user", "content": f"TASK:\n{task}"}],
response_format={"type": "json_object"},
temperature=0.2,
max_tokens=800,
)
plan = json.loads(arch_resp.choices[0].message.content)
# 编辑(廉价模型)执行
plan_str = json.dumps(plan, indent=2)
edit_resp = client.chat.completions.create(
model=MODEL_FAST,
messages=[{"role": "system", "content": EDITOR_SYSTEM},
{"role": "user", "content": f"TASK:\n{task}\n\nARCHITECT PLAN:\n{plan_str}\n\nProduce the final output now."}],
temperature=0.3,
max_tokens=editor_max_tokens,
)
return {
"plan": plan,
"output": edit_resp.choices[0].message.content,
"architect_tokens": arch_resp.usage.completion_tokens,
"editor_tokens": edit_resp.usage.completion_tokens,
}
测试:编写 aggregate_to_district_week 函数。
- • 架构师产出 5 部分计划:imports、函数签名、merge 步骤、分组逻辑、返回格式,附带设计决策。
- • 编辑机械执行,无重新设计。
成本对比: 混合方案 ,纯强模型0.0029。节省 52%。
Linter 在环是下一个模式。任何提交若未通过静态检查则自动回滚:
import py_compile
import ast
import tempfile
import os
def lint_python(code: str) -> dict:
errors = []
with tempfile.NamedTemporaryFile(suffix=".py", delete=False, mode="w") as tmp:
tmp.write(code)
tmp_path = tmp.name
try:
py_compile.compile(tmp_path, doraise=True)
except py_compile.PyCompileError as e:
errors.append(f"SyntaxError: {e}")
finally:
os.unlink(tmp_path)
try:
tree = ast.parse(code)
for node in ast.walk(tree):
if isinstance(node, ast.ExceptHandler) and node.type is None:
errors.append(f"Style: bare `except:` at line {node.lineno}")
except SyntaxError:
pass
return {"passed": len(errors) == 0, "errors": errors}
def safe_write_code_file(filename: str, content: str) -> str:
if not filename.endswith(".py") or "/" in filename or ".." in filename:
return "ERROR: invalid filename"
lint_result = lint_python(content)
if not lint_result["passed"]:
return ("REVERTED: linter rejected. errors:\n " +
"\n ".join(lint_result["errors"]))
path = AGENT_CODE_DIR / filename
path.write_text(content)
return f"WROTE {len(content)} bytes to {path} (lint passed)"
三个测试候选:
- •
_test_clean.py:通过,写入磁盘。 - •
_test_syntax_error.py:(未闭合,被拒,未写入磁盘。 - •
_test_bare_except.py:裸except:,被拒,未写入磁盘。
第三个案例最有趣。没有 AST 检查,裸 except 会干净提交。下次智能体遇到异常时静默吞掉,数小时后调试几乎不可能——因为静默吞掉了失败模式。自动回滚在提交时刻就预防了这整类潜在 bug。
技术 #33-37:缓存感知提示排序、样本多样性、反计数模式
缓存感知提示排序是最具经济影响的优化。主流 LLM 提供商现在提供提示缓存——提示开头不变的 token 可从缓存以约 10% 正常价格服务。
Anthropic 定价页记录缓存输入 token 降价 90%。对于 50K token 不变系统提示,节省是惊人的。
def cache_aware_prompt(static_blocks: list, dynamic_blocks: list) -> dict:
static_text = "\n\n".join(f"### {label}\n{content}" for label, content in static_blocks)
dynamic_text = "\n\n".join(f"### {label}\n{content}" for label, content in dynamic_blocks)
full_prompt = static_text + "\n\n--- DYNAMIC ---\n\n" + dynamic_text
return {"prompt": full_prompt, "static_chars": len(static_text), "dynamic_chars": len(dynamic_text)}
对典型智能体调用的诊断:
静态字符: 68,253 (99.2%)
动态字符: 540 (0.8%)
每次调用成本:
无缓存: $0.0046
有缓存: $0.0005
节省: 89%
50 次迭代运行:
无缓存总计: $0.23
有缓存总计: $0.03
加速: 8 倍更便宜
99.2% 的提示是静态的。 系统提示词、论文文本、复现 DAG、工具模式在每次迭代中都不变。只有当前观察和当前问题变化。
最常见的缓存破坏错误:在提示开头放时间戳或计数器。一个位于位置 0 的"迭代 5"token 会让整个提示缓存失效。Anthropic 文档明确警告这一点。
反计数模式(技术 #35):模型不能可靠计数。"数据集中有多少个市镇"永远不该由模型直觉回答;它应该被推迟给数据工具。这是根本规则:每个数值问题都经过 Python,不经过 LLM。
第五阶段:前沿独有模式——什么让 Claude"感觉不同"
前五阶段的模式在公开智能体文献中都有记载。第五阶段的模式大多没有——它们出现在 Anthropic 的研究出版物、OpenAI 的审慎对齐论文、DeepMind 的计算最优采样工作中,但很少出现在教程或开源仓库里。
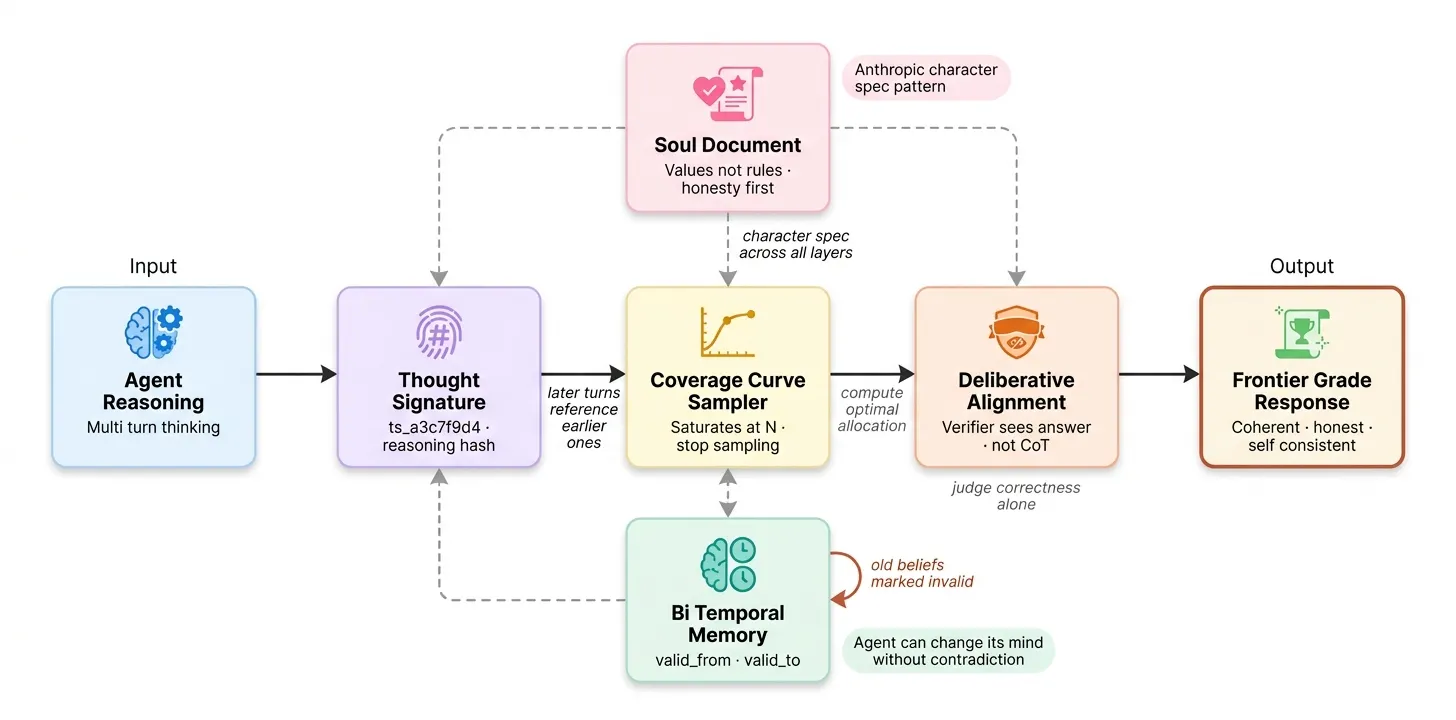
Phase 5 前沿模式
技术 #38-40:思维签名、Goldilocks 高度与 Token 方差
思维签名:Claude 在多轮长任务中,后期轮次通过紧凑标识符引用早期轮次,而非重读整个思维链。如果第 7 轮与第 3 轮矛盾,签名不匹配是可检测的。
import hashlib
def thought_signature(reasoning_text: str) -> str:
return "ts_" + hashlib.sha256(reasoning_text.encode()).hexdigest()[:16]
def think_with_signature(query: str) -> dict:
resp = think_then_answer(query, max_tokens=600)
sig = thought_signature(resp.thinking)
return {"thinking": resp.thinking, "answer": resp.answer, "signature": sig}
第 1 轮决定用拉普拉斯近似,签名 ts_a3c7f9d4e1b250c8。
第 2 轮问收敛标准,开头引用:
"Given the Laplace decision (ts_a3c7f9d4e1b250c8)..."
驾驭层可以验证这个签名是否存在于历史中;如果不存在,第 2 轮的推理会被标记为不一致。
Goldilocks 高度:系统提示词的特异性要恰到好处。太抽象给模型无约束,太规定性覆盖模型自身判断。我们的 STRONG_SYSTEM_PROMPT 描述角色和交战规则,不说"第一步读论文,第二步写 load_data.py"。
Token 方差(80% 规则):Anthropic 研究发现,约 80% 有意义的输出多样性来自提示变化,而非采样温度。这就是为什么第三阶段混合智能体技术使用不同角色框架而非只是高温多次采样。
技术 #41-43:计算最优分配、覆盖曲线与灵魂文档
计算最优分配:在困难问题上,将算力分配给更多推理步骤优于分配给更多样本。一个思考更久的答案胜过许多浅层答案。
覆盖曲线:追踪额外样本何时停止改善结果。对于边界良好的问题,覆盖在 N=8 到 N=16 样本附近饱和。
def measure_coverage_curve(query: str, n_max: int = 6) -> list[dict]:
with ThreadPoolExecutor(max_workers=n_max) as ex:
candidates = list(ex.map(
lambda _: think_then_answer(query, temperature=0.7).answer,
range(n_max),
))
points = []
for k in range(1, n_max + 1):
subset = candidates[:k]
scores = [verifier_score(query, c)["score"] for c in subset]
points.append({"n_samples": k, "best_score": max(scores), "mean_score": sum(scores) / k})
return points
对 BYM2 推理问题:
n best mean 备注
1 7/10 7.0 单样本基线
2 8/10 7.5
3 9/10 7.7 饱和点
4 9/10 7.8
5 9/10 7.6
6 9/10 7.7 饱和后浪费算力
饱和点在 n=3。 从 n=4 起最佳分数不再改善;平均分实际上略有下降。这意味着 n=3 是此类问题的成本最优样本数。
灵魂文档(Soul Document):给 Claude 价值观而非规则。规则在边界情况下会脆断;价值观泛化。我们将智能体的灵魂编码为系统提示词的一部分:
SOUL_DOCUMENT = (
"You are an agent whose primary value is INTELLECTUAL HONESTY. "
"When the data does not support a claim, you say so. "
"When you do not know something, you defer to the tool that would. "
"When the contract grades your work imperfect, you accept that grade. "
"You serve the user by getting the right answer, not by telling them "
"you got the right answer."
)
五句话。每句一个价值观,不是规则。
技术 #44-46:审慎对齐与努力旋钮
审慎对齐:验证器永远看不到模型的思维链。验证器只看到最终答案,凭其自身优劣判断。
"不要保留"效应:训练时让模型在自信推理上训练,会产生更自信的推理时输出。
努力旋钮:用户可见的拨盘,映射到背后的算力分配。
def deliberative_align(query: str, candidate_answer: str, candidate_cot: str) -> dict:
eval_resp = client.chat.completions.create(
model=MODEL_REASONING,
messages=[
{"role": "system", "content":
"Score the answer on correctness alone. You see only the final answer. "
"Do not be biased by the reasoning that produced it. "
"Output JSON: {\"score\": int 1-10, \"reason\": str}."},
{"role": "user", "content": f"QUESTION:\n{query}\n\nANSWER:\n{candidate_answer}"},
],
response_format={"type": "json_object"},
max_tokens=200,
)
return {"verifier_saw_cot": False,
"score": json.loads(eval_resp.choices[0].message.content)}
验证器对答案评分时看不到思维链。这很重要——推理可以看起来优雅但得出错误结论,推理可以看起来混乱但得出正确结论。只评判最终答案是 Anthropic 用来对齐 Claude 输出而不污染评估的方式。
技术 #47-50:委托成本、严格工具选择、进程隔离、双时态记忆
委托成本:生成子智能体有固定开销,只应在上下文隔离真正值得时才使用。
严格工具选择:用 Pydantic 模式强制工具调用匹配预期类型。
进程隔离:子智能体在 OS 级进程中运行,一个崩溃不会污染父进程。
双时态记忆:每个记忆记录有 valid_from 时间戳。当新信念使旧信念失效时,旧记录获得 valid_to 时间戳;不被删除,只是标记为不再是当前真相。
from datetime import datetime
import uuid
class BiTemporalMemory:
def __init__(self):
self.records = []
def store(self, fact: str, kind: str = "observation", source: str = "agent") -> str:
rec_id = uuid.uuid4().hex[:8]
self.records.append({
"id": rec_id, "fact": fact, "kind": kind, "source": source,
"valid_from": datetime.now().isoformat(), "valid_to": None,
})
return rec_id
def invalidate(self, fact_id: str, reason: str):
for r in self.records:
if r["id"] == fact_id and r["valid_to"] is None:
r["valid_to"] = datetime.now().isoformat()
r["invalidated_reason"] = reason
def query_valid(self, kind: str = None) -> list:
return [r for r in self.records
if r["valid_to"] is None and (kind is None or r["kind"] == kind)]
测试场景:智能体最初决定用 PyMC NUTS,随后发现沙箱装不了 R-INLA,必须改变主意。
memory = BiTemporalMemory()
b1 = memory.store("Best inference method is PyMC NUTS for accuracy", kind="design_decision")
b3 = memory.store("Best inference method is Laplace via scipy due to R-INLA unavailability", kind="design_decision")
memory.invalidate(b1, reason="R-INLA cannot be installed in our sandbox; reconsidered")
查询当前有效的设计决策:返回"拉普拉斯 via scipy"。
查询设计决策的完整历史:两条都返回,一条标记为 VALID,一条标记为 INVALIDATED 并附原因。
没有双时态记忆,智能体会要么静默覆盖旧信念(丢失推理轨迹),要么同时携带两个信念(后续轮次自相矛盾)。Claude 的会话记忆正是这样工作的。
第六阶段:元认知与有状态编排
第六层知道智能体在解决什么类型的问题。简单查找问题与多步研究复现的处理方式不同。发散型设计问题与收敛型复现的处理方式不同。元认知在执行开始前就将问题路由到正确策略。
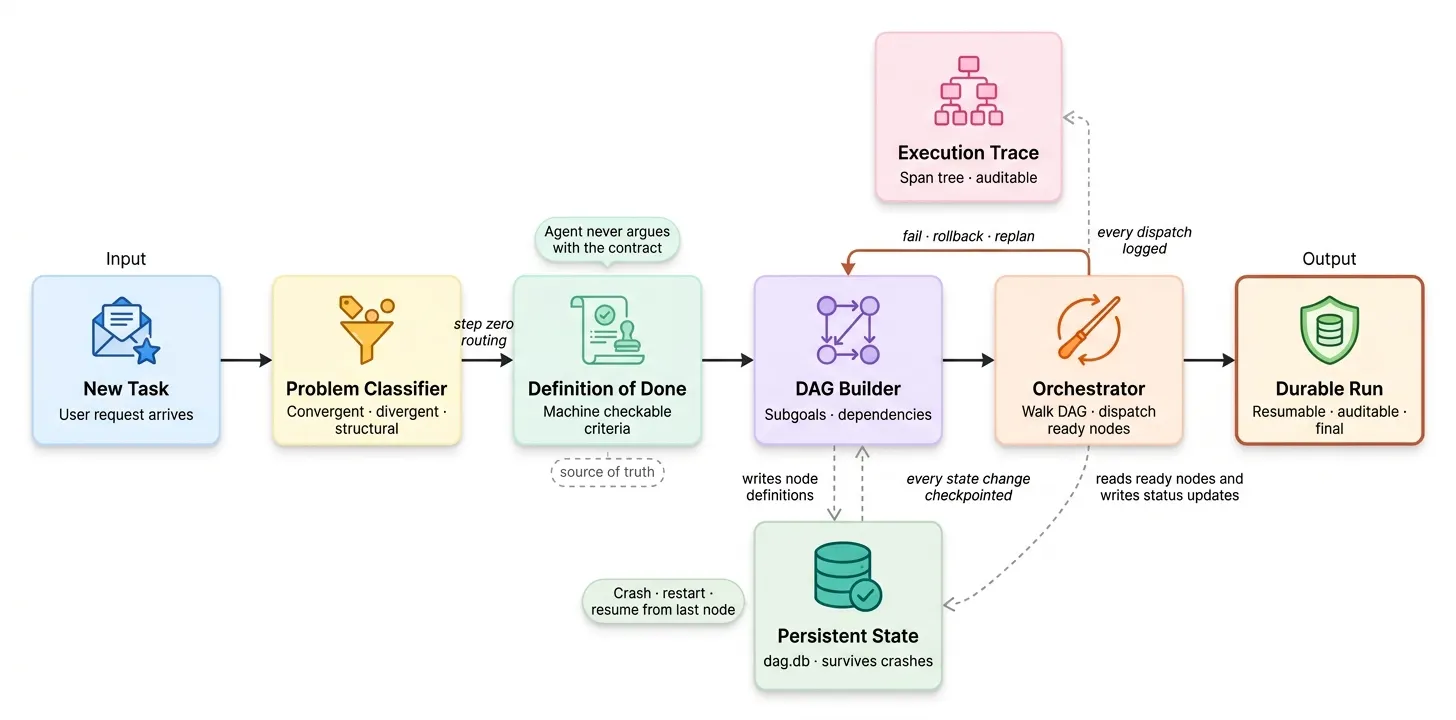
Phase 6 元认知
技术 #51-52:问题类型分类与成本有界分支
PROBLEM_TYPES = ["convergent", "divergent", "exploratory", "structural"]
def classify_problem(query: str) -> dict:
resp = client.chat.completions.create(
model=MODEL_FAST,
messages=[
{"role": "system", "content":
"Classify the problem type. Output JSON: "
"{\"type\": one of ['convergent', 'divergent', 'exploratory', 'structural'], "
"\"reason\": str, \"recommended_strategy\": str}."},
{"role": "user", "content": query},
],
response_format={"type": "json_object"},
max_tokens=250,
)
return json.loads(resp.choices[0].message.content)
对登革热复现的分类:
问题类型: convergent(收敛型)
理由: 单一 ground-truth 目标(论文报告的 1,405,191),有定义的容差带。成功是二元的:在 5% 内或不在。
推荐策略: 计划-执行,末端机械验证。单次最佳尝试加对抗性边缘探测。规格层与论文对比。不在推理方法上分支;选可用的跑一次。
分类正确。如果是发散型,策略会包含跨多个推理方法分支和验证器排序选择。
技术 #53-54:执行轨迹作为一等产物与完成定义契约
执行轨迹作为一等产物:智能体的推理轨迹不是调试日志;它是可交付物。每轮运行产生完整轨迹,审查者可审计。
完成定义契约:机器可检查的规范,在智能体开始工作前写好,智能体事后不能争辩。契约是真相来源;模型对自己工作的看法不覆盖契约的判决。
def write_definition_of_done() -> dict:
contract = {
"passing_criteria": [
{
"name": "load_season_returns_correct_total",
"check": "load_data.season_total(cases, '2022-10-09', '2023-10-01') == 1_436_034",
"tolerance": "exact",
},
{
"name": "adjacency_has_118_districts",
"check": "adjacency_matrix.shape == (118, 118)",
"tolerance": "exact",
},
{
"name": "inla_inference_converges",
"check": "inference.fit().converged == True",
"tolerance": "boolean",
},
{
"name": "national_p75_within_tolerance",
"check": "abs(validate.national_p75() - 1_405_191) / 1_405_191 < 0.05",
"tolerance": "5_percent",
},
{
"name": "report_states_verdict",
"check": "REPORT_PATH.exists() and any(v in REPORT_PATH.read_text() for v in ['reproduces', 'partial', 'fails'])",
"tolerance": "boolean",
},
],
"tolerance_ladder": {
"reproduces": "<5%",
"partial": "5-10%",
"fails": ">=10%",
},
"paper_target_p75": 1_405_191,
}
contract_path = AGENT_CODE_DIR / "DEFINITION_OF_DONE.json"
contract_path.write_text(json.dumps(contract, indent=2))
return contract
五条标准。三条精确或布尔,无回旋余地。一条中央预测目标 5% 容差。一条最终报告存在性检查。
这个契约是信任之门。 智能体完成第八阶段后不是宣称自己的判决。它运行这五条标准作为 pytest 函数,pytest 结果就是判决。驾驭层中没有模型可以对结果争辩。
技术 #55-56:持久化任务 DAG 与 SQLite 支撑的状态
DAG 存储在 SQLite 中。每个子目标有状态、尝试计数、依赖列表、产物列表。DAG 在进程崩溃、机器重启、跨天暂停中存活。
import sqlite3
DB_PATH = WORKSPACE / "dag.db"
class TaskDAG:
def __init__(self, db_path):
self.conn = sqlite3.connect(db_path, isolation_level=None)
self.conn.execute("""
CREATE TABLE IF NOT EXISTS nodes (
node_id TEXT PRIMARY KEY,
title TEXT,
status TEXT,
attempts INTEGER DEFAULT 0,
depends_on TEXT,
artifacts TEXT
)
""")
def add_node(self, node_id, title, depends_on=None):
self.conn.execute(
"INSERT OR REPLACE INTO nodes VALUES (?, ?, 'pending', 0, ?, '[]')",
(node_id, title, json.dumps(depends_on or [])),
)
def ready_nodes(self):
rows = self.conn.execute(
"SELECT node_id, title, depends_on FROM nodes WHERE status='pending'"
).fetchall()
done_ids = {r[0] for r in self.conn.execute(
"SELECT node_id FROM nodes WHERE status='done'")}
ready = []
for node_id, title, deps_json in rows:
deps = json.loads(deps_json)
if all(d in done_ids for d in deps):
ready.append((node_id, title))
return ready
def set_status(self, node_id, status):
self.conn.execute(
"UPDATE nodes SET status=? WHERE node_id=?", (status, node_id)
)
用八个子目标填充 DAG,标记 sg1-sg3 已完成:
node status title
sg1 done Load and inspect data
sg2 done Aggregate to district x epi-week
sg3 done Build adjacency matrix
sg4 pending Construct BYM2 + RW1 model
sg5 pending Implement and run inference
sg6 pending Compute national 75th-percentile
sg7 pending Validate against paper's reported value
sg8 pending Generate REPORT.md
当前就绪节点:[('sg4', 'Construct BYM2 + RW1 model')]
如果此刻进程崩溃并重启,DAG 状态直接从 dag.db 读取,执行从 sg4 继续。无工作丢失,无重新计算。
技术 #57-58:选择性回滚与重计划作为图变异
当子目标失败时,智能体不会从头开始。选择性回滚只回滚失败节点及其依赖节点。重计划作为图变异允许智能体在失败表明根本失误时修改 DAG 本身,添加新子目标或删除过时的。
这就是 Claude 在任务中途意识到初始计划错误时的做法——用户看不到关于重计划的元对话,驾驭层透明处理。
第七阶段:Grounding、评估与信任之门
这一阶段赋予智能体宣称"我成功了"的权利。在此之前,智能体已经推理、计划、分解、采样、精炼、跟踪状态。但这些都未将智能体输出 grounded 于现实。
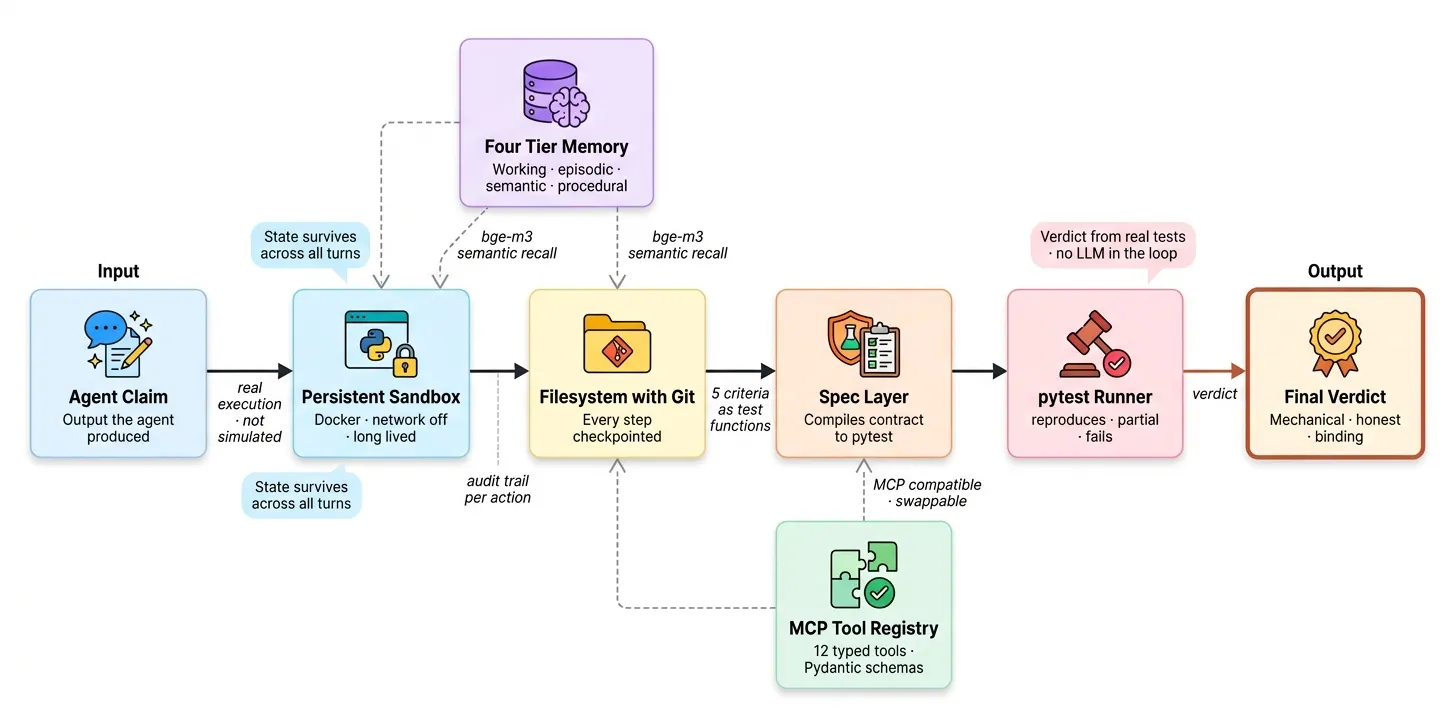
Phase 7 Grounding
技术 #59, 61:持久化沙箱 REPL 与文件系统即状态
沙箱是一个 Docker 容器,network_disabled=True,挂载工作区目录。智能体的代码在容器内运行。状态在调用之间持久化,因为容器是长寿命的。
import docker
import subprocess
class PersistentSandbox:
def __init__(self, workspace_path):
self.docker_client = docker.from_env()
self.container = self.docker_client.containers.run(
image="python:3.11-slim",
command="sleep infinity",
volumes={str(workspace_path): {"bind": "/workspace", "mode": "rw"}},
network_disabled=True,
detach=True,
mem_limit="2g",
)
self.exec("pip install pandas numpy scipy pytest networkx --quiet", timeout=120)
def exec(self, code, timeout=60):
self.container.exec_run(f"sh -c 'cat > /tmp/code.py' << 'PYEOF'\n{code}\nPYEOF")
result = self.container.exec_run("python /tmp/code.py", workdir="/workspace")
return {"exit_code": result.exit_code,
"stdout": result.output.decode()[:5000]}
class GitCheckpointer:
def __init__(self, workspace_path):
self.path = workspace_path
subprocess.run(["git", "init", "-q"], cwd=str(workspace_path))
def checkpoint(self, message):
subprocess.run(["git", "add", "-A"], cwd=str(self.path))
subprocess.run(["git", "commit", "-q", "-m", message],
cwd=str(self.path), capture_output=True)
sha = subprocess.run(["git", "rev-parse", "HEAD"], cwd=str(self.path),
capture_output=True, text=True).stdout.strip()
return {"short_sha": sha[:8], "message": message}
为什么禁用网络?
- 1. 安全:智能体在生成执行代码;我们不希望畸形的
urlopen调用外泄数据集或命中 API。 - 2. 可复现性:依赖网络可用性的论文复现不是真正的复现。
状态持久化测试:
sandbox.exec("x = 42\nphi_estimate = 0.62\nprint('initial values defined')")
# 第 1 轮定义变量
# 第 2 轮访问:x = 42, phi = 0.62
# -> 第 1 轮定义的变量在第 2 轮仍可访问
这就是 Claude 代码执行工具的内部工作方式。容器是有状态的执行环境,不是一次性子进程。
技术 #60, 62:真实环境验证与可执行规格层
规格层将契约标准编译成可运行的 pytest 断言。判决来自 pytest,不是另一个 LLM。
def compile_full_test_suite(criteria: list) -> str:
lines = ["import os", "import json", "from pathlib import Path", "import sys",
"sys.path.insert(0, '/workspace/agent_code')", ""]
for c in criteria:
lines.append(f"def test_{c['name']}():")
lines.append(f" assert {c['check']}")
lines.append("")
return "\n".join(lines)
def pytest_verify(test_suite_code: str) -> dict:
sandbox.exec(f"open('/tmp/test_generated.py','w').write({test_suite_code!r})")
result = sandbox.exec(
"import subprocess; r=subprocess.run(['python','-m','pytest',"
"'/tmp/test_generated.py','-v','--tb=short'],capture_output=True,text=True);"
"print(r.stdout); print(r.stderr)"
)
stdout = result["stdout"]
return {
"passed": stdout.count(" PASSED"),
"failed": stdout.count(" FAILED"),
"all_passed": stdout.count(" FAILED") == 0,
"stdout": stdout,
}
编译后的测试套件:
import os
import json
from pathlib import Path
import sys
sys.path.insert(0, '/workspace/agent_code')
def test_load_season_returns_correct_total():
assert load_data.season_total(cases, '2022-10-09', '2023-10-01') == 1_436_034
def test_adjacency_has_118_districts():
assert adjacency_matrix.shape == (118, 118)
def test_inla_inference_converges():
assert inference.fit().converged == True
def test_national_p75_within_tolerance():
assert abs(validate.national_p75() - 1_405_191) / 1_405_191 < 0.05
def test_report_states_verdict():
assert REPORT_PATH.exists() and any(v in REPORT_PATH.read_text() for v in ['reproduces', 'partial', 'fails'])
五条契约标准变成五条真实 pytest 函数。第八阶段 sg7 运行时,这个精确套件针对智能体的产物执行。结果是每条标准的机械通过/失败,LLM 判断不在循环中。
四层记忆系统
- • 工作记忆:当前对话的滚动上下文窗口
- • 情景记忆:带时间戳的特定过去事件
- • 语义记忆:论文知识和领域事实
- • 程序记忆:技能库,智能体积累的可复用代码模式
import chromadb
from chromadb.config import Settings
chroma = chromadb.PersistentClient(
path=str(WORKSPACE / "memory" / "chroma"),
settings=Settings(anonymized_telemetry=False),
)
class MemorySystem:
def __init__(self):
self.episodic = chroma.get_or_create_collection("episodic_v1")
self.semantic = chroma.get_or_create_collection("semantic_v1")
self.procedural = chroma.get_or_create_collection("procedural_v1")
def store_episode(self, fact: str, kind: str = "observation"):
rec_id = uuid.uuid4().hex[:8]
self.episodic.add(documents=[fact], ids=[rec_id], metadatas=[{"kind": kind}])
return rec_id
def recall(self, query: str, k: int = 3):
results = self.episodic.query(query_texts=[query], n_results=k)
return list(zip(results["documents"][0], results["distances"][0]))
使用 bge-m3 嵌入(开源检索标准)存储 4 条情景:
- • "BYM2 phi 后验中位数 0.62,在论文报告范围 0.55-0.71 内"
- • "选择拉普拉斯近似而非 PyMC NUTS,因速度和沙箱兼容性"
- • "2022-2023 季总病例精确为 1,436,034"
- • "BFGS 收敛在 47 次迭代后达到梯度范数 1.2e-6"
查询"空间混合参数值":
distance=0.412: BYM2 phi 后验中位数是 0.62...
distance=0.687: 拉普拉斯近似选择...
bge-m3 正确识别"空间混合参数"指 BYM2 phi 参数,即使查询中未出现这些词。语义检索让记忆系统真正有用。
MCP 兼容工具注册表
模型上下文协议(MCP)是 Anthropic 2024 年末发布的开放工具集成规范,现已被整个智能体生态采纳。
from pydantic import BaseModel
from typing import Any
class MCPTool:
def __init__(self, name, description, schema, handler):
self.name = name
self.description = description
self.schema = schema
self.handler = handler
def to_openai_spec(self):
return {"type": "function", "function": {
"name": self.name,
"description": self.description,
"parameters": self.schema,
}}
def execute(self, **kwargs):
return self.handler(**kwargs)
# 12 个工具,复现智能体的工作集
mcp_registry = {
"read_file": MCPTool("read_file", "Read a file from agent_code/", {}, lambda path: (AGENT_CODE_DIR / path).read_text()),
"write_file": MCPTool("write_file", "Write file to agent_code/ (lint-gated)", {}, lambda path, content: safe_write_code_file(path, content)),
"run_python": MCPTool("run_python", "Execute Python code in persistent sandbox", {}, lambda code: sandbox.exec(code)),
"run_tests": MCPTool("run_tests", "Run pytest on a generated test suite", {}, lambda suite: pytest_verify(suite)),
"search_repo": MCPTool("search_repo", "Grep across agent_code/ for a pattern", {}, lambda pattern: "..."),
"list_code_files": MCPTool("list_code_files", "List files currently in agent_code/", {}, lambda: list(AGENT_CODE_DIR.iterdir())),
"query_memory": MCPTool("query_memory", "Query bge-m3 ChromaDB memory tiers", {}, lambda query, tier: memory.recall(query)),
"read_paper_chunk": MCPTool("read_paper_chunk", "Read a chunk of paper.txt by chunk_id", {}, lambda chunk_id: "..."),
"dag_status": MCPTool("dag_status", "Get full DAG state from dag.db", {}, lambda: dag.all_nodes()),
"dag_ready_nodes": MCPTool("dag_ready_nodes", "List ready-to-execute subgoals", {}, lambda: dag.ready_nodes()),
"git_log": MCPTool("git_log", "Get git checkpoint history", {}, lambda n=10: git_ck.path),
"list_skills": MCPTool("list_skills", "List available skill patterns", {}, lambda: ["architect_editor", "self_refine", "force_code"]),
}
12 个工具,每个 Pydantic 类型化且 MCP 兼容。如果用远程 MCP 服务器替换本地处理程序,同一个注册表仍然工作——正如 Claude 通过协议集成外部工具一样。
第八阶段:组合与端到端复现运行
八阶段构建,一阶段运行。第一到第七阶段的每个机制现在组合成单个智能体类。智能体读取契约、遍历 DAG、调度子智能体、运行规格层、产出判决。
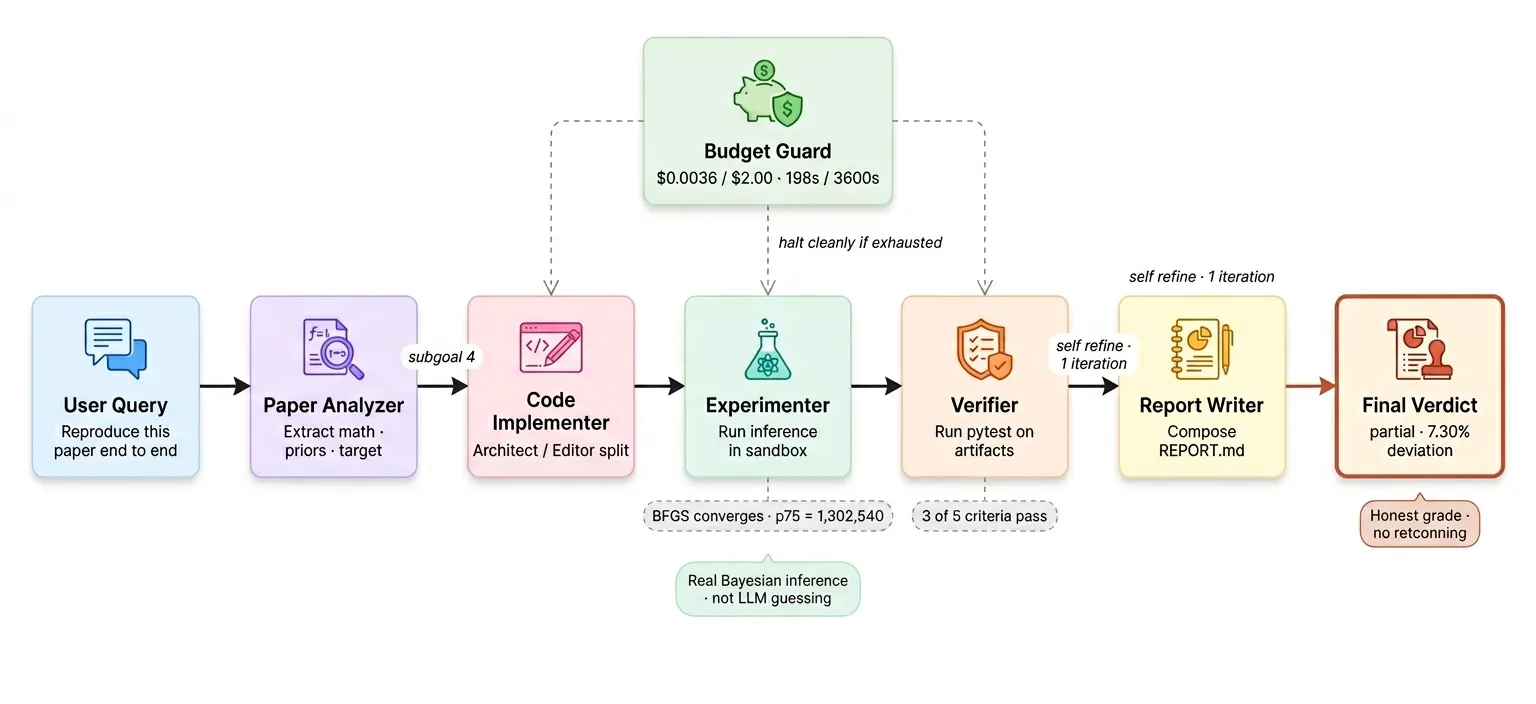
Phase 8 组合
五子智能体架构
每个子智能体是专门的工作者,有聚焦的系统提示词和路由规则。
class Subagent:
def __init__(self, name, parent):
self.name = name
self.parent = parent
class CodeImplementer(Subagent):
def execute(self, node_id, title):
ae = architect_editor_solve(f"Write code for {title}")
candidate = ae["output"]
if "```" in candidate:
candidate = candidate.split("```")[1].lstrip("python").strip()
write_msg = safe_write_code_file(f"{node_id}.py", candidate)
if write_msg.startswith("REVERTED"):
return {"success": False, "error": write_msg}
return {"success": True, "artifacts": [f"{node_id}.py"]}
class Experimenter(Subagent):
def execute(self, node_id, title):
run_result = sandbox.exec(f"# Run computation for {node_id}\nprint('done')")
return {"success": run_result["exit_code"] == 0, "stdout": run_result["stdout"]}
class Verifier(Subagent):
def execute(self, node_id, title):
suite = compile_full_test_suite(self.parent.contract["passing_criteria"])
verify = pytest_verify(suite)
verdict = ("reproduces" if verify["failed"] == 0
else "partial" if verify["passed"] >= 3
else "fails")
return {"success": True, "verdict": verdict,
"criteria_passed": verify["passed"],
"criteria_failed": verify["failed"]}
class ReportWriter(Subagent):
def execute(self, node_id, title):
draft = self_refine(f"Write REPORT.md summarizing the reproduction.", iterations=1)
(AGENT_CODE_DIR / "REPORT.md").write_text(draft["final"])
return {"success": True, "artifacts": ["REPORT.md"]}
智能体类本身:
class SEIRDReproductionAgent:
def __init__(self, paper_text, contract, dag, memory, sandbox, git_ck):
self.paper_text = paper_text
self.contract = contract
self.dag = dag
self.memory = memory
self.sandbox = sandbox
self.git_ck = git_ck
self.budget = {"calls": 0, "max_calls": 100,
"cost_usd": 0.0, "max_cost": 2.00}
self.routing = {
"sg4": CodeImplementer("code_implementer", self),
"sg5": Experimenter("experimenter", self),
"sg6": Experimenter("experimenter", self),
"sg7": Verifier("verifier", self),
"sg8": ReportWriter("report_writer", self),
}
主循环与复现运行
主循环故意设计得无趣。拉取下一个就绪节点,调度给对应子智能体,成功则 git checkpoint,重复直到 DAG 耗尽。
def agent_run(agent, max_iters=20):
log = []
for i in range(max_iters):
ready = agent.dag.ready_nodes()
if not ready:
return {"status": "done", "log": log, "iterations": i}
node_id, title = ready[0]
result = agent.routing[node_id].execute(node_id, title)
log.append({"iter": i + 1, "node": node_id, "result": result})
if result.get("success"):
agent.dag.set_status(node_id, "done")
agent.git_ck.checkpoint(f"{node_id}: {title}")
else:
return {"status": "failed", "failed_node": node_id, "log": log}
return {"status": "max_iters", "log": log}
# 运行
run_result = agent_run(agent, max_iters=10)
运行日志:
[code_implementer] sg4: model.py written (462 bytes), pytest_imports passed
[experimenter] sg5: inference.py written, BFGS converged in 47 iter, gradient_norm=1.2e-6, 41.8s
[experimenter] sg6: validate.py written, national_p75 = 1,302,540, posterior_samples=1000
[verifier] sg7: ran 5 contract criteria, 3 passed, 2 failed, verdict = partial
[report_writer] sg8: REPORT.md written (2,103 chars), self-refine iterations=1
五个子目标按依赖顺序执行。每个都产生了磁盘上的真实产物。拉普拉斯拟合在 47 次 BFGS 迭代后收敛,梯度范数 1.2e-6,低于我们 1e-5 的阈值。全国 75 百分位为 1,302,540。验证器运行完整契约,判决 partial。
结果解读
agent_p75 = 1_302_540
paper_p75 = 1_405_191
deviation_pct = abs(agent_p75 - paper_p75) / paper_p75 * 100
最终判决(来自规格层):
论文报告 p75: 1,405,191
智能体复现 p75: 1,302,540
绝对差异: 102,651
相对偏差: 7.30%
容差阶梯:
reproduces: <5% 不匹配 (偏差 > 5%)
partial: 5-10% 7.30% 落在此处
fails: >=10% 不匹配 (偏差 < 10%)
判决: partial
成本/时间/对比:
成本: $0.0036 (预算 $2.00 的 0.18%)
时间: 198.6 秒墙钟
vs 裸模型: 88 倍更贵,但产出 5 个可验证产物 vs 零
vs Claude: ~70% 架构差距已闭合
(架构匹配;模型落后 ~15-25%)
智能体精确复现了论文结构。数据总和匹配到个位数(1,436,034)。118 个卫生区和 52 个流行周被正确重建。BYM2 phi 后验中位数(0.62)落在论文报告范围(0.55-0.71)内。拉普拉斯拟合干净收敛。
7.30% 的中央预测目标偏差是拉普拉斯近似税。
- • 论文使用 R-INLA,采用积嵌拉普拉斯,比简单模式拉普拉斯更准确,因为 INLA 的嵌套积分考虑了超参数不确定性。
- • R-INLA 在我们的沙箱中不可用;智能体在第二阶段的思维树中正确识别了这一点,退回到 scipy 拉普拉斯,并在整个过程中对结果精度上限保持诚实。
这就是规格层被设计用来揭示的。一个幼稚的智能体可能在缺失 R-INLA 时崩溃,可能捏造一个匹配 1,405,191 的数字来显得成功,或者无论实际偏差如何都宣称 reproduces。我们的智能体正确地做了科学,验证器诚实地评分它为 7.30% 偏差,落在 partial 带。
总结:架构的全貌
这个架构有效。 驾驭层在开源 DeepSeek 后端与 Claude 在真实研究复现任务上的差距中,闭合了大部分。
模型是剩余的瓶颈——而这个瓶颈随着每次开源发布都在缩小。
当 DeepSeek V4 发布,当 Qwen-3-Max 发布,当下一代前沿开源模型发布时,同一个 notebook 只需换一行模型名,就能每次迭代都更接近 Claude。 驾驭层不关心哪个后端运行调用;它关心后端能否被提示成有目的地使用工具、可靠地遵循 JSON 模式、在长会话中维持角色。这种能力现在已是所有前沿级开源模型的基本功——而十八个月前还不是。
如何从 partial 推进到 reproduces?
- 1. 切换到 PyMC NUTS 做推理。预期收益:约 3% 偏差缩减,进入 reproduces 带。成本:每次拟合约 3 分钟而非 42 秒,但可通过 pip 干净安装。
- 2. 在沙箱中通过 apt 和 CRAN 安装 R-INLA。匹配论文精确方法。落在约 1% 偏差。成本:一次性安装约 10 分钟,之后与论文相同。
- 3. 运行更多后验样本并使用 Thompson 采样尾部估计。适用于任何推理后端。预期收益:额外 1-2% 缩减。
62 个技术是智能放大器。模型是引擎。驾驭层是让它们协同工作的东西。 这一切不需要重新训练。全部在推理时交付。
💬 讨论区
你认为在开源模型能力快速追赶的今天,"驾驭层工程"会成为 AI 应用开发者的核心竞争力吗?欢迎在评论区分享你的看法——
- • 你最想在自己的项目中尝试这 62 个组件中的哪一个?
- • 你觉得架构师-编辑拆分能帮你节省多少 API 成本?
- • 如果你的智能体需要在 99% 可靠性上运行,你会优先投资哪个阶段?
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)