
RAG 不只是“向量库 + 大模型”:从普通 RAG 到 GraphRAG、LightRAG、HybridRAG
这篇文章围绕 RAG 技术的演进展开,介绍了普通 RAG 从文档解析、切片、Embedding、召回、重排到大模型生成的完整流程,并分析了它在复杂推理、跨文档关系理解等场景中的局限。
最近调研了很多RAG相关的内容,想发出来和大家分享一下。
一开始大家对 RAG 的理解很直接:把文档切片,丢进向量库;用户提问时,先检索几段相关内容,再让大模型基于这些内容回答。这是很多知识库问答系统的第一版架构。
但真做起来之后,很快就会发现,RAG 没有想象中那么“自动驾驶”。
有时检索出来的片段看着相关,实际答不上问题;有时答案需要跨好几份文档推理,向量检索却只捞到零散段落;还有些场景里,用户关心的不是某一句原文,而是实体之间的关系,比如“这个项目是谁负责的”“这个方案和哪个部门有关”“这些技术路线之间有什么联系”。
这时,普通的“向量检索 + 大模型生成”就有点吃力了。于是 KG-RAG、GraphRAG、LightRAG、HybridRAG 这些方向开始被越来越多地讨论。
这篇文章想做的事很简单:不把 RAG 讲成一堆名词,而是顺着一个工程问题往下拆:
为什么要用 RAG?普通 RAG 是怎么搭起来的?它为什么会失效?知识图谱为什么能补上这块短板?GraphRAG、LightRAG、HybridRAG 到底分别解决什么问题?
最后我也放了几段很小的代码例子,不追求生产可用,主要帮助你把流程跑通、把思路想清楚。
一、RAG 到底解决了什么问题?
大模型很强,但它有几个绕不开的限制。
第一,它不知道你的私有资料。公司的制度、项目文档、客户记录、内部 FAQ、业务数据库,这些内容通常不在模型训练语料里。
第二,它的知识不是实时更新的。模型训练完以后,内部知识基本就固定了。你今天刚发布的产品文档,它不会天然知道。
第三,直接把大量文档塞进 Prompt 并不现实。上下文再长,也不适合每次把整个知识库都塞进去。成本高,速度慢,还容易干扰模型判断。
第四,也是最麻烦的一点:模型会幻觉。它会把不确定的东西说得很肯定。如果没有外部资料约束,用户很难判断它到底是在回答,还是在编。
RAG 的思路就是把这个问题拆开:
检索系统负责找资料,大模型负责读资料、组织语言、进行推理。
也就是说,大模型不再单纯依赖“记忆”回答,而是先查资料,再回答。这一点听起来朴素,但对大模型落地非常重要。因为企业应用里,我们要的往往不是“模型很会聊”,而是“答案有依据、能更新、能追溯”。
二、RAG、微调、提示词,不是三选一
很多人刚接触大模型应用时,会纠结一个问题:我到底该做 Prompt、微调,还是 RAG?
这三个东西不是互相替代的关系,它们解决的问题不一样。
Prompt 更像是“临场指挥”。你告诉模型用什么角色、什么格式、什么口吻回答。它便宜、灵活、见效快,但它不能让模型凭空知道新知识。
微调更像是“训练习惯”。如果你希望模型长期稳定地完成某类任务,比如固定风格的分类、抽取、改写、客服话术,微调会有帮助。但微调不适合频繁更新事实知识,因为每次更新都重新训练,成本太高。
RAG 更像是“外挂资料库”。它适合处理私有知识、实时知识、需要引用来源的知识。资料更新了,重新入库即可,不必重新训练模型。
所以真实项目里,常见组合是:
Prompt 约束输出格式
RAG 提供外部知识
必要时用微调提升任务稳定性
如果你的问题是“模型不知道我的资料”,优先考虑 RAG。
如果你的问题是“模型输出格式不稳定”,先调 Prompt。
如果你的问题是“模型长期做不好某类固定任务”,再考虑微调。
三、普通 RAG 是怎么工作的?
一个完整的 RAG 系统,通常分成两个阶段:离线建库和在线问答。
离线阶段做的是“把资料整理成可以检索的样子”。在线阶段做的是“用户提问时,把最相关的资料找出来,再交给模型回答”。
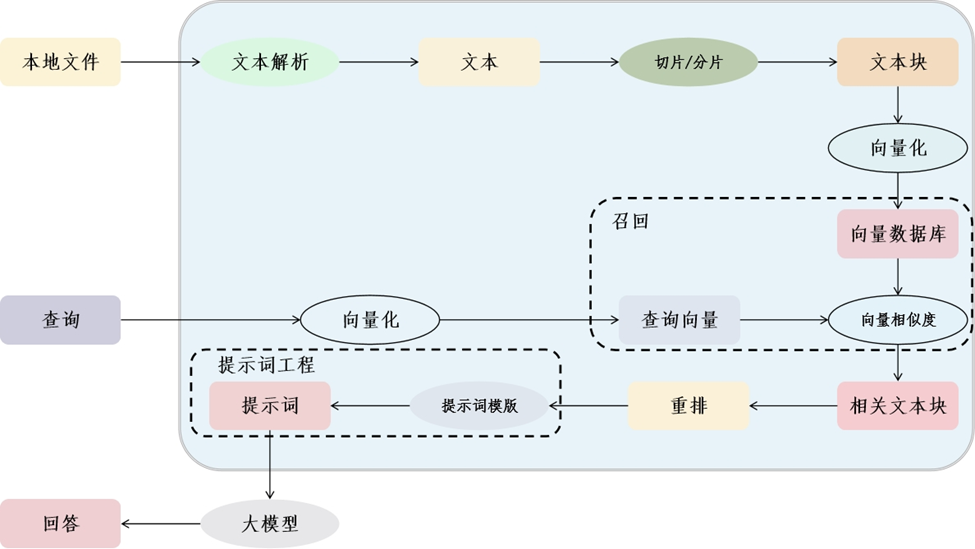
1. 文档解析:先把资料洗干净
RAG 的输入一般不是干净的纯文本,而是 PDF、Word、Excel、网页、扫描件、数据库记录等。
这一步经常被低估。很多 RAG 效果差,不是模型不行,而是文档解析就已经乱了。比如 PDF 表格被拆散,页眉页脚混进正文,标题层级丢失,扫描件 OCR 错字太多。这些问题都会影响后面的切片和检索。
常见工具包括:
• PDF:pdfplumber、PyMuPDF、unstructured
• Word/Excel:python-docx、openpyxl
• 网页:BeautifulSoup、爬虫或站点 API
• 扫描件:OCR,例如 Tesseract
• 数据库:ETL、SQL 抽取、字段拼接
如果是企业知识库,我建议文档解析阶段一定要保留元数据,比如文件名、章节标题、页码、更新时间、部门、权限范围。后面做溯源、过滤和权限控制都会用到。
2. Chunking:切片不是越细越好

文档太长,不能直接拿去检索和塞进上下文,所以要切成 chunk。
最简单的做法是按字数或 token 数切,比如每 500 个字一段,再加一点 overlap。这个方法好实现,但容易把完整语义切断。
更稳一点的做法是按段落、标题、章节切。结构清楚的 Markdown、Word 文档、技术手册,通常更适合这种方式。
不同切分方式大概可以这样理解:
|
切分方式 |
优点 |
问题 |
适合场景 |
|
按字数/token |
简单、均匀、容易实现 |
容易切断语义 |
通用场景 |
|
按段落 |
可读性好,语义更完整 |
长度不稳定 |
结构化文档 |
|
按章节 |
保留逻辑层级 |
粒度可能太粗 |
长报告、制度文档 |
|
按页码 |
方便引用来源 |
语义割裂明显 |
合同、法律、审计材料 |
|
语义切分 |
更贴近主题边界 |
实现成本更高 |
高质量知识库 |
这里有个经验:chunk 不是越小越好。太小,答案所需上下文不够;太大,检索不精准。实际项目里通常要反复评测,找到适合自己文档的粒度。
3. Embedding:把文本变成向量
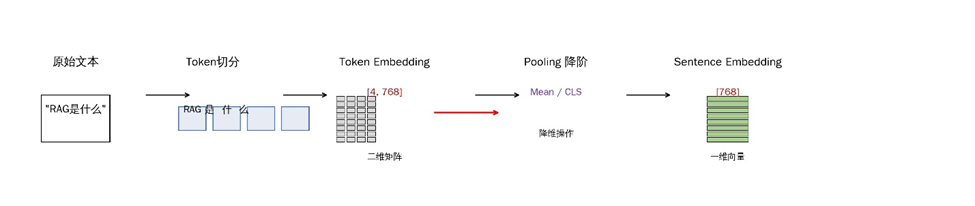
Embedding 的作用,是把文本转成向量。这样我们就可以用数学方式计算“这段文本和用户问题有多像”。
建库时,每个 chunk 会生成一个向量,并和原文、来源、页码等信息一起存起来。
查询时,用户问题也会被转成向量,然后去向量库里找距离最近的 chunk。
常见向量数据库包括 FAISS、Milvus、Chroma、Weaviate、Pinecone、Elasticsearch、pgvector 等。选型时不用一上来就追求复杂,小项目用 FAISS 或 Chroma 很方便;企业级系统再考虑 Milvus、ES、pgvector 这类更适合部署和管理的方案。
4. 召回:先从海量资料里捞一批候选
召回阶段的目标不是一次找出最终答案,而是从知识库里先捞出一批“可能相关”的材料。
常见召回方式有几种:
• 向量召回:按语义相似度找内容
• BM25:按关键词匹配找内容
• 混合召回:向量 + 关键词一起用
• 查询改写:把用户问题改写得更适合检索
• 多查询扩展:用多个问法提高召回率
• 元数据过滤:按时间、部门、权限、文档类型筛选
很多系统只做向量召回,早期可以,但后面一定会遇到问题。比如用户问一个很精确的术语、编号、合同条款,关键词检索往往比向量检索更可靠。
5. 重排:召回之后还要精挑细选
向量召回速度快,但判断不够细。它适合“海选”,不适合“终面”。
所以常见做法是先召回 Top 20 或 Top 50,再用 reranker 重新排序,最终选 Top 3 到 Top 8 放进 Prompt。
召回和重排的区别可以这样理解:
|
阶段 |
作用 |
特点 |
|
召回 |
从海量文档里快速找候选 |
快,但判断粗 |
|
重排 |
对候选内容重新判断相关性 |
慢一点,但更准 |
典型 reranker 通常是 Cross-Encoder 模型。它会同时看“问题”和“候选片段”,判断两者是不是真的相关。
6. Prompt:别让模型自由发挥
检索到资料之后,还要把资料组织成 Prompt。这里也有很多细节。
一个最基础的 RAG Prompt 可以这样写:
你是一个严谨的知识库问答助手。
请只根据【参考资料】回答问题。
如果参考资料不足以回答,请明确说明“当前资料不足以回答”。
不要编造参考资料中不存在的信息。
【参考资料】
{context}
【用户问题】
{question}重点是两件事:
第一,告诉模型只能根据资料回答。
第二,告诉模型资料不足时要拒答。
很多 RAG 系统幻觉严重,不一定是检索差,也可能是 Prompt 没有把边界说清楚。
四、一个最小 RAG 代码例子
下面这个例子不用向量数据库,只用 TF-IDF 模拟一下“切片、向量化、召回、拼 Prompt”的流程。它不是生产方案,但很适合用来理解 RAG 的骨架。
安装依赖:
pip install scikit-learn
示例代码:
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
docs = [
"RAG 是检索增强生成技术,通过外部知识库增强大模型回答。",
"Chunking 是把长文档切成较小片段,便于检索和放入上下文。",
"Embedding 会把文本转换为向量,用于计算语义相似度。",
"GraphRAG 会从文档中抽取实体和关系,构建知识图谱。",
"LightRAG 通过图检索和文本检索双通道提升效率与效果。"
]
def chunk_text(text, chunk_size=40, overlap=10):
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start = end - overlap
return chunks
chunks = []
for doc in docs:
chunks.extend(chunk_text(doc))
vectorizer = TfidfVectorizer()
doc_vectors = vectorizer.fit_transform(chunks)
def retrieve(question, top_k=3):
query_vector = vectorizer.transform([question])
scores = cosine_similarity(query_vector, doc_vectors)[0]
ranked = sorted(enumerate(scores), key=lambda x: x[1], reverse=True)
return [(chunks[i], score) for i, score in ranked[:top_k]]
question = "GraphRAG 和普通 RAG 有什么区别?"
hits = retrieve(question)
context = "\n".join([f"- {text}" for text, score in hits])
prompt = f"""
请只根据参考资料回答问题。
参考资料:
{context}
问题:
{question}
"""
print(prompt)如果换成生产系统,核心结构不变,只是组件会升级:
• TF-IDF 换成 embedding 模型
• 内存矩阵换成向量数据库
• 简单 Top-K 换成召回 + 重排
• 手写 Prompt 换成模板化 Prompt
• 最后接入大模型 API 生成答案
五、普通 RAG 为什么会失效?
普通 RAG 的核心是“相似度检索”。它擅长回答事实型、局部型问题。
比如:
• 某个制度的报销标准是什么?
• 某个产品有哪些功能?
• 某篇论文提出了什么方法?
这类问题通常可以在某几个 chunk 里找到答案。
但如果问题变成下面这种,普通 RAG 就会吃力:
A 公司收购了 B 公司,B 公司的 CTO 毕业于哪所学校?
这个问题需要一条关系链:
A 公司 -> 收购 -> B 公司 -> CTO -> 某人 -> 毕业院校 -> 某大学
再比如:
这些项目文档中,哪些部门之间协作最频繁?
这就不是找一段相似文本了,而是要从大量文档里抽取实体、关系,再做全局统计和归纳。
向量检索的优势是语义匹配,但它并不天然理解“关系”。它知道两段话像不像,却不一定知道实体之间怎么连接、路径怎么走、全局结构是什么。
这就是知识图谱增强 RAG 的价值。
六、知识图谱:把文档从“片段”变成“关系网”
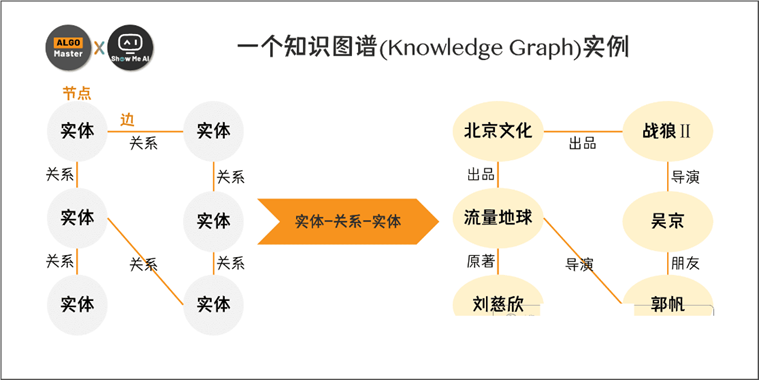
知识图谱的基本单位是三元组:
(实体, 关系, 实体)
例如:
(GraphRAG, 使用, 知识图谱)
(GraphRAG, 包含, 社区发现)
(LightRAG, 采用, 双通道检索)
(向量数据库, 支持, 相似度检索)
有了图谱之后,知识就不再只是一段段文本,而变成了一张关系网。
向量库擅长回答“哪些文本和这个问题相似”。
知识图谱擅长回答“这些实体之间有什么关系”。
它的优势很明显:
• 可以做多跳推理
• 可以输出推理路径
• 实体和关系更清楚
• 适合表达复杂关系网络
• 在医疗、金融、法律、供应链、企业知识库里很有用
但图谱也不是银弹。它需要实体抽取、关系抽取、实体对齐、冲突处理,还要维护图数据库。图谱质量不好,后面生成的答案也会跟着跑偏。
所以更现实的路线不是“用图谱替代向量库”,而是把两者结合起来。
七、KG-RAG:让 RAG 同时检索文本和关系
KG-RAG 可以理解为知识图谱增强版 RAG。
普通 RAG 检索的是文本 chunk。KG-RAG 除了检索文本,还会检索实体、关系、路径和子图。
一个典型流程是:
1. 用户提出问题
2. 系统识别问题里的关键实体
3. 在知识图谱中找到这些实体
4. 扩展一跳或多跳邻居,得到相关子图
5. 同时从向量库召回相关文本
6. 把图谱路径和文本片段一起交给大模型
7. 生成更有依据的答案
下面是一个极简的图检索例子:
pip install networkx
import networkx as nx
graph = nx.Graph()
graph.add_edge("GraphRAG", "知识图谱", relation="使用")
graph.add_edge("GraphRAG", "社区发现", relation="包含")
graph.add_edge("社区发现", "社区摘要", relation="生成")
graph.add_edge("LightRAG", "双通道检索", relation="采用")
graph.add_edge("双通道检索", "图检索", relation="包含")
graph.add_edge("双通道检索", "文本检索", relation="包含")
def graph_retrieve(entity, depth=2):
sub_nodes = nx.single_source_shortest_path_length(graph, entity, cutoff=depth)
triples = []
for source in sub_nodes:
for target in graph.neighbors(source):
if target in sub_nodes:
relation = graph[source][target]["relation"]
triples.append((source, relation, target))
return triples
for triple in graph_retrieve("GraphRAG"):
print(triple)可能输出:
('GraphRAG', '使用', '知识图谱')
('GraphRAG', '包含', '社区发现')
('社区发现', '生成', '社区摘要')
把这些三元组放进 Prompt,模型看到的就不再只是零散文本,而是一条更清楚的关系链。
八、GraphRAG:重点解决“全局理解”
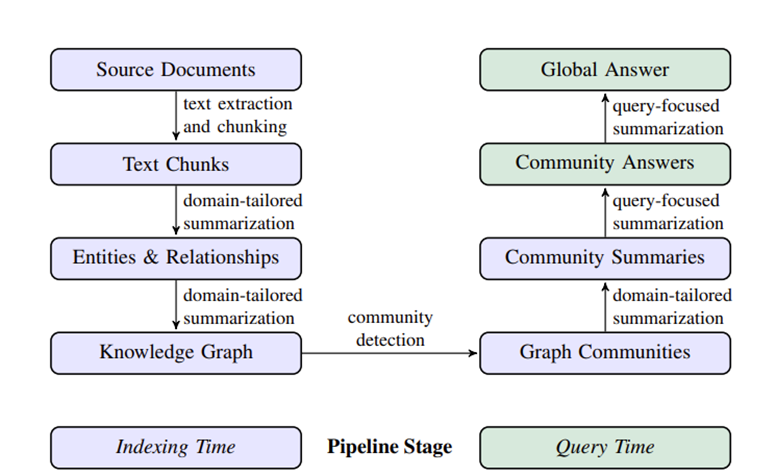
GraphRAG 是图增强 RAG 里很有代表性的方案。它的核心不只是“查图谱”,而是从文档中自动构建图,再通过社区发现和社区摘要,让系统具备更强的全局理解能力。
它一般分成两个阶段。
1. 构建阶段
GraphRAG 会先读取原始文档,比如 PDF、网页、数据库记录等。然后进行文本切分,再用大模型或信息抽取模型识别实体和关系。
接着,系统会把实体和关系组织成知识图谱。图谱建好后,再做社区发现。所谓社区,可以理解为图中连接比较紧密的一组节点。
比如一批企业内部文档,最后可能形成几个社区:
• 产品研发相关社区
• 客户交付相关社区
• 财务审批相关社区
• 法务合同相关社区
每个社区再由大模型生成摘要。这样系统就不只保存了底层文本,还保存了更高层次的知识结构。
2. 查询阶段
用户提问时,GraphRAG 可以先判断问题适合查哪个层级的社区,再检索相关社区摘要,最后综合多个社区的答案生成最终结果。
这类方法特别适合回答全局问题,比如:
这批材料主要讨论了哪些技术路线?
或者:
这些项目之间有什么共同风险?
普通 RAG 更像是在书里找相似段落。GraphRAG 更像是先给整本书画了一张知识地图,再沿着地图找答案。
当然,它的代价也更高。实体关系抽取、社区发现、摘要生成都需要计算资源,也会增加系统复杂度。所以 GraphRAG 更适合知识量较大、关系复杂、确实需要全局归纳的场景。
九、LightRAG:把图增强做得更轻一点
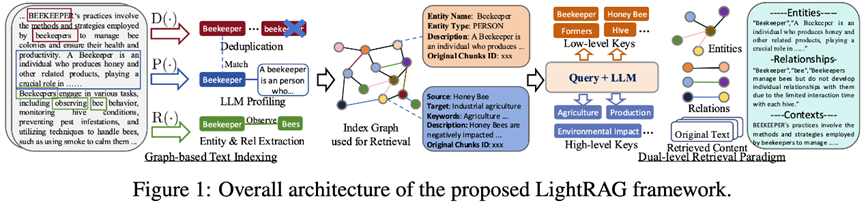
GraphRAG 能力强,但不一定每个项目都承受得起它的复杂度。LightRAG 的思路就是保留图增强的好处,同时尽量降低构建和查询成本。
LightRAG 比较强调双通道检索:
• 图检索:处理实体、关系、多跳路径
• 文本检索:处理语义相似和原文上下文
它还会把用户问题拆成两类线索。
一类是 Low-level Keys,也就是实体级关键词。比如 GraphRAG、LightRAG、向量数据库。这些适合去图里精确匹配节点。
另一类是 High-level Keys,也就是更抽象的语义主题。比如 复杂推理、知识增强、工程落地。这些适合去文本索引里做语义检索。
这样一来,系统既能利用图谱里的结构关系,又不会完全依赖复杂的图处理流程。
如果说 GraphRAG 更偏“完整知识地图”,LightRAG 就更偏“轻量图增强检索”。对于很多工程场景,LightRAG 的思路反而更容易落地。
十、HybridRAG:工程里最常见的折中方案
真实项目中,很少有系统只靠一种检索方式打天下。
向量检索适合语义相似,关键词检索适合精确命中,图检索适合关系推理,reranker 适合精排。既然它们各有优势,最自然的办法就是混合使用。
这就是 HybridRAG 的核心思想。
一个常见流程是:
1. 向量库召回语义相关 chunk
2. BM25 召回关键词命中的 chunk
3. 图谱召回相关实体、关系和路径
4. 合并结果并去重
5. 使用 reranker 重新排序
6. 构造最终上下文
7. 让大模型生成答案
下面是一个非常简化的融合示例:
def hybrid_merge(vector_hits, keyword_hits, graph_hits):
scores = {}
for doc_id, score in vector_hits:
scores[doc_id] = scores.get(doc_id, 0) + 0.5 * score
for doc_id, score in keyword_hits:
scores[doc_id] = scores.get(doc_id, 0) + 0.3 * score
for doc_id, score in graph_hits:
scores[doc_id] = scores.get(doc_id, 0) + 0.2 * score
return sorted(scores.items(), key=lambda x: x[1], reverse=True)
vector_hits = [("doc_1", 0.92), ("doc_2", 0.78)]
keyword_hits = [("doc_2", 0.88), ("doc_3", 0.70)]
graph_hits = [("doc_1", 0.85), ("doc_4", 0.80)]
print(hybrid_merge(vector_hits, keyword_hits, graph_hits))这个例子只是表达思路。真实系统里还要处理分数归一化、重复片段、权限过滤、上下文长度限制、reranker 成本等问题。
但大方向很清楚:不要把所有希望都压在单一检索器上。复杂业务问题,往往需要多路召回。
十一、如果从 0 开始做 RAG,我建议这样升级
第一步,先把基础 VectorRAG 跑通。
不要一上来就做 GraphRAG。先完成文档解析、chunk、embedding、向量库、召回、Prompt、答案溯源。这个阶段最重要的是把闭环跑起来,并建立一套评测样例。
第二步,增强检索质量。
当基础链路可用后,再加 BM25、reranker、查询改写、多查询扩展、元数据过滤、父子 chunk 等能力。很多项目到这一步,效果已经会明显提升。
第三步,再考虑知识图谱。
如果你的问题经常涉及实体关系、多跳推理、路径解释、跨文档归纳,那就值得引入 KG-RAG 或 GraphRAG。小规模实验可以先用 NetworkX,大规模场景再考虑 Neo4j、NebulaGraph、TigerGraph 等图数据库。
第四步,走向 HybridRAG。
成熟的 RAG 系统一般会变成混合架构:普通事实问答走向量检索,精确术语走关键词检索,复杂关系走图检索,高价值答案再用 reranker 精排,最后由大模型统一生成。
十二、RAG 落地时最容易踩的坑
第一个坑,是只盯着模型,不看数据。
RAG 的上限经常不是大模型,而是数据质量。文档解析乱、chunk 不合理、元数据缺失,都会让后面的检索和生成变差。
第二个坑,是 chunk 策略一刀切。
制度文档、技术手册、合同、论文、网页,它们的结构完全不同。最好按文档类型设计切分方式,不要全库都按固定字数切。
第三个坑,是只做向量检索。
向量检索很重要,但不是万能的。编号、术语、专有名词、法律条款、产品型号这类问题,关键词检索往往更稳。
第四个坑,是没有处理“资料不足”。
RAG 不应该强行回答所有问题。如果知识库里没有依据,最好的答案就是告诉用户资料不足。这个规则要写进 Prompt,也要在评测里检查。
第五个坑,是图谱做得太重。
知识图谱很有价值,但它也很贵。先确认业务真的需要实体关系和多跳推理,再上图谱。否则很容易变成“系统很复杂,收益不明显”。
第六个坑,是没有评测。
RAG 系统一定要评测。至少要看:
• 答案依据有没有被召回
• 召回内容是不是真的相关
• 模型有没有忠实于资料
• 引用来源是否正确
• 延迟和成本能不能接受
没有评测,调 RAG 基本就是凭感觉。
十三、总结一下
RAG 的演进,其实是从“找相似文本”走向“组织知识”。
最早的 RAG 解决的是:怎么让大模型查到外部资料。
后来的 KG-RAG、GraphRAG、LightRAG、HybridRAG 解决的是:怎么让系统理解资料之间的关系,怎么让答案更完整、更可解释、更适合复杂业务。
VectorRAG 仍然是基础,它简单、稳定、成本低。
KG-RAG 适合需要实体关系和路径推理的场景。
GraphRAG 更适合大规模文档的全局理解和归纳。
LightRAG 更强调轻量化和工程效率。
HybridRAG 则是结合了图谱和向量库。
前段时间还参加了腾讯的私享会,他们推出的乐享知识库,其实是模仿OpenClaw运用了Agent RAG的技术,实现了反复迭代直到检索到模型满意答案的路径。
我认为RAG这个词越来越广义了,真正有价值的 RAG,是一整套知识处理链路。能把外部知识注入模型的方法,可能都能叫广义RAG。
参考资料
• Microsoft GraphRAG 官方项目与文档:https://github.com/microsoft/graphrag
• LightRAG 项目与论文资料:https://github.com/HKUDS/LightRAG
• HybridRAG 论文:https://arxiv.org/abs/2408.04948
更多推荐
 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)