
大模型长期规划能力不够?试试用强化学习优化提示词!
摘要:RPO框架通过强化学习优化提示词提升大模型多轮交互能力,无需修改模型参数。该框架采用时序差分反馈和经验回放机制,在Text-to-SQL、任务型对话等场景显著提升性能(准确率提高54.2%),特别适合API调用的闭源模型。虽然对专业领域(如中医)效果有限,但为多轮对话规划提供了高效解决方案,通过迭代优化提示词规则实现低成本性能提升。
作为程序员,咱平时用大模型写代码、调接口挺顺手,但一到多轮交互场景就头疼 —— 比如让它帮用户逐步完成酒店预订,或者根据零散需求生成 SQL 查询,经常因为早期假设错了,后面越聊越偏,用户要的东西根本没跟上。这不是咱用得不对,而是大模型本身在 “长期规划” 上有点拉胯。
之前做对话系统的哥们儿就说过,想搞定多轮交互,必须得让模型有规划能力。但传统方法要么得微调模型参数,本地算力扛不住;要么靠频繁调用 API 搞自我反馈, latency 高得离谱。最近看到一篇预印本论文,提出了个叫 “强化提示优化(RPO)” 的框架,不用改模型参数,就靠迭代优化提示词,居然把大模型的多轮规划能力提上去了,还能在 Text-to-SQL、任务型对话这些场景里通用,咱来好好唠唠。
先说说为啥大模型多轮交互不行。现在主流的大模型,比如 GPT、Llama 这些,训练时用的 RLHF(基于人类反馈的强化学习),大多是给单轮回复打分,没考虑整个多轮对话的质量。就像你写代码只测单个函数,不管整个流程跑不跑得通,到实际用的时候,用户一开始没说清需求,模型后面就跟着错,连锁反应直接 gg。
之前也有人想解决这个问题,比如用 LoRA 微调,或者搞 “连续提示”,但这些方法要么得改模型权重,API 调用型的大模型根本用不了;要么像 TextGrad 那种,靠生成文本反馈优化提示,但只盯着单轮任务,没考虑多轮的时序性。RPO 这方法厉害的地方在于,它把强化学习里的 “时序差分(TD)” 和 “经验回放” 思路搬进了提示词优化,全程只改提示词,不用碰模型参数。
具体咋做的呢?整个框架分三步:先搞个初始提示词(可以是专家写的,也能让模型自动生成),然后让模型用这个提示词和环境(比如模拟用户、真实用户)交互,生成多轮对话轨迹;接着找个 “反馈器”(人或者另一个大模型),给每一轮对话出反馈;最后用 “重写器” 根据反馈和历史经验,迭代优化提示词。流程大概长这样,一目了然:
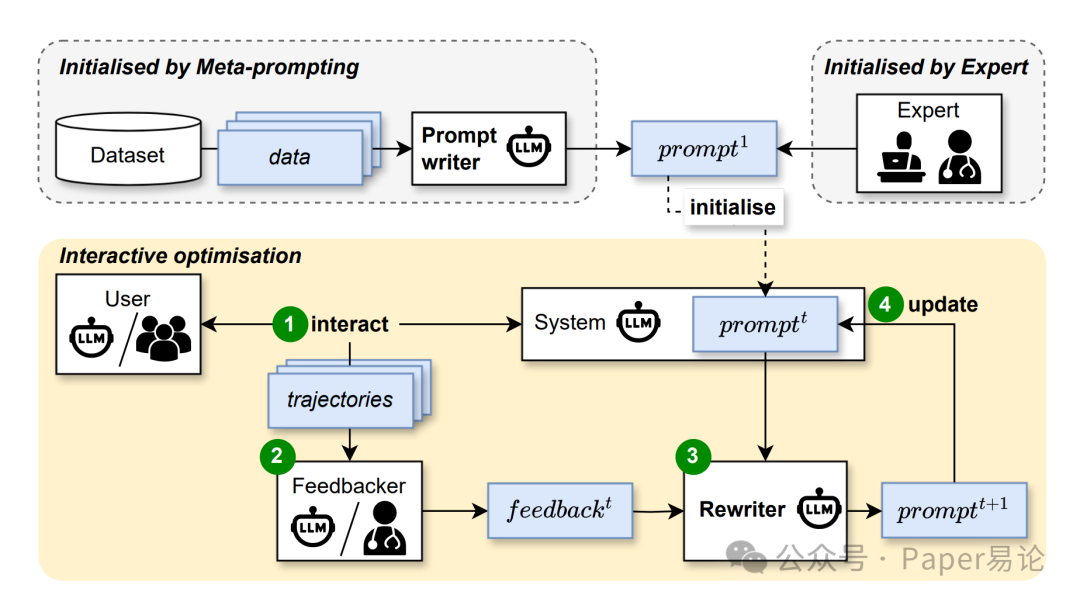
图 1:RPO 框架结构
这里面有两个关键设计,咱得重点说。第一个是 “反馈生成”,论文里对比了两种方式:Monte Carlo(MC)式和 TD 式。MC 式是等整个对话结束了才给反馈,比如用户订完酒店,才说 “刚才没问清入住时间,导致订错日期”,适合单轮任务,但多轮场景里,前面错了后面没法及时调整。TD 式就不一样了,每一轮对话结束就给反馈,还会预测下一轮用户情绪、对话能不能成,再给具体建议。比如用户说 “想住市中心便宜酒店”,模型回复 “有 XX 酒店,200 元 / 晚”,TD 反馈会立刻说 “用户可能满意,但没确认入住天数,下一轮得问,不然后续预订会出错”—— 这就像写代码时每步加日志,及时发现问题,不用等整个流程崩了才调试。
给大家看个具体例子,左边是 MC 反馈,右边是 TD 反馈,差距很明显:
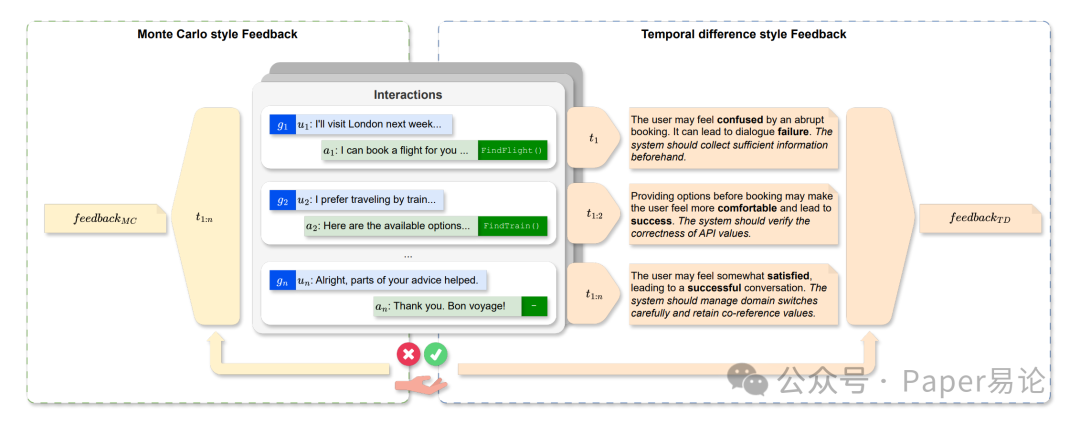
图 2:MC 式与 TD 式反馈对比
第二个关键是 “经验回放”。玩强化学习的都知道,经验回放能让模型利用历史数据,减少训练波动。RPO 里的重写器优化提示词时,不只用当前轮的反馈,还会把之前几轮的 “提示词 - 反馈” 对拿过来参考。比如优化第 3 轮提示词时,会回头看第 1、2 轮的反馈,避免重复踩坑。就像你改 bug 时,会翻之前的测试报告,不用每次都从零开始排查。
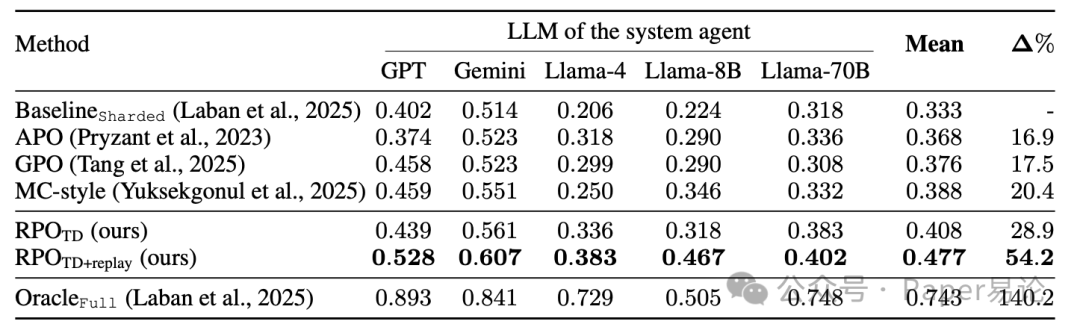
光说不练假把式,论文里做了三个任务的实验,结果都挺能打。第一个是 Text-to-SQL,就是让模型根据用户多轮输入生成 SQL 查询。比如用户先问 “查北京的订单”,后面补充 “要 2024 年的”,模型得把这两个条件整合进 SQL 里。实验用了 5 个不同的大模型(GPT-4o mini、Gemini-2.0-flash、Llama-3.1-8B/70B、Llama-4-scout),对比了 APO、GPO 这些传统方法,结果 RPO(尤其是加了经验回放的 RPO_TD+replay)表现最好,平均准确率比 baseline 高了 54.2%,连小参数的 Llama-3.1-8B 都快追上单轮全量输入的效果了。具体数据在这:
表 1:不同大模型在 Text-to-SQL 任务上的准确率
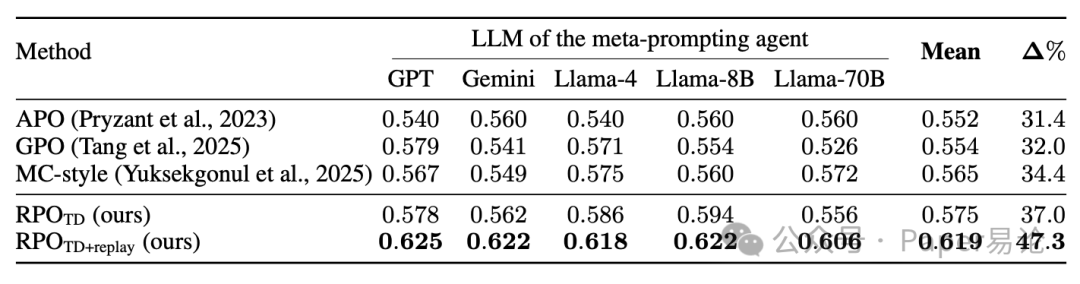
第二个任务是任务型对话,用 MultiWOZ 数据集,让模型帮用户订酒店、查景点。系统用的是 FnCTOD(一个分 “对话状态跟踪 + 回复生成” 两步的模型),同样测了 5 个大模型当 “元提示代理”(就是生成反馈和重写提示的模型)。结果 RPO_TD+replay 平均成功率到了 61.9%,比 baseline 高 47.3%,而且不管用闭源模型(GPT、Gemini)还是开源模型(Llama 系列),效果都稳,说明这方法不挑模型。数据在这:
表 2:不同元提示代理在任务型对话上的成功率
第三个任务是医疗问答,这个场景特别考验专业性,还得保证安全。论文用了 Huatuo-26M(通用医疗)和 ShenNong-TCM(中医)两个数据集,让模型给用户推荐药方、解答症状。结果挺有意思:在通用医疗里,RPO 优化后的模型居然比专门微调过的医疗大模型 HuatuoGPT-II 还受欢迎(专家偏好率 86.7%);但到了中医场景,偏好率掉了 41%。为啥?因为中医知识在大模型预训练数据里少,光靠优化提示词很难补全领域知识 —— 这也给咱提了个醒,提示词优化不是万能的,遇到小众领域,还是得结合外部知识库。具体的偏好对比图在这:
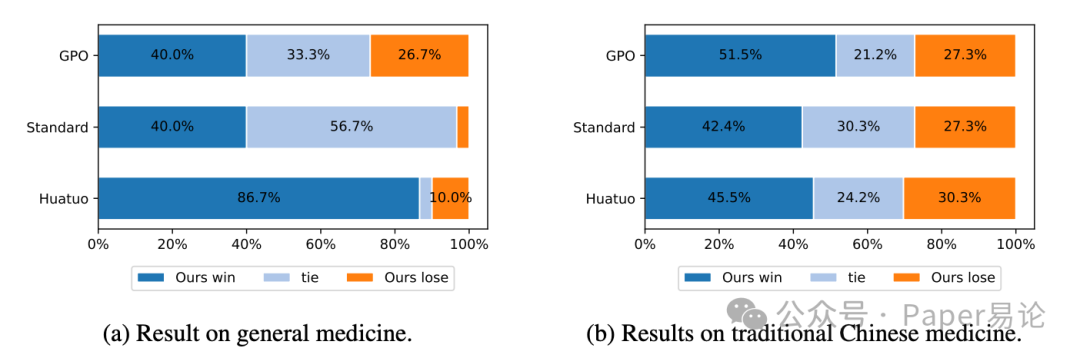
图 5:医疗问答任务中不同模型的专家偏好率
除了这些主实验,论文还做了些 ablation 研究,比如对比不同反馈输入对效果的影响。发现如果反馈里包含用户目标和系统的 API 调用信息(比如订酒店时调用的数据库查询参数),优化效果会更好。因为 API 调用错了,比如查错城市,后面全白搭,反馈里明确指出这个,重写器就能针对性优化提示词,比如加一句 “每次调用 API 前检查城市参数是否和用户输入一致”。训练曲线也能看出来,TD 式反馈比 MC 式收敛更快,加了经验回放后波动更小,像咱调模型参数时加了正则一样稳:
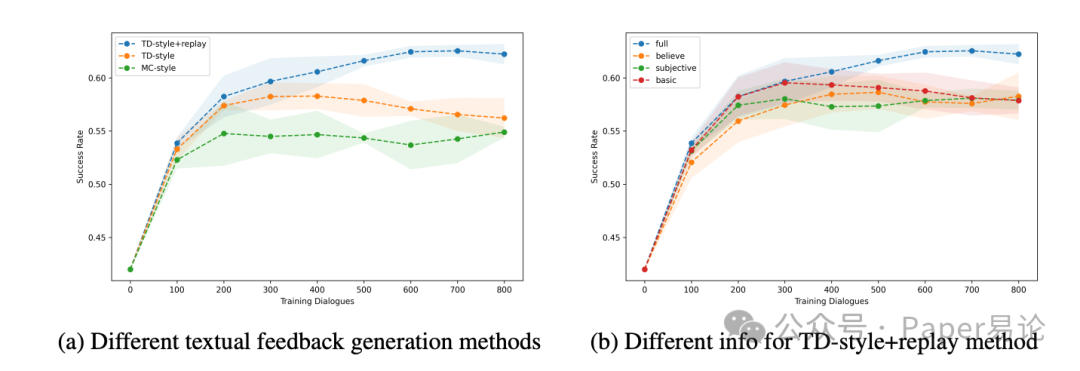
图 4:不同反馈方式的训练曲线
最后再唠唠实际用的时候要注意啥。RPO 的优点很明显:不用微调,API 型大模型也能用;反馈和重写的提示词是任务无关的,一次写好能复用;还能接人类反馈,灵活度高。但也有局限:目前优化后的效果离 “用户一次性说清需求” 的场景还有差距(比如 Text-to-SQL 里,RPO 平均准确率 0.477,全量输入是 0.743);遇到预训练数据里少的领域(比如中医),效果会打折扣。
不过对咱程序员来说,这方法已经很实用了。比如你做一个客服机器人,不用每次用户反馈新问题就微调模型,只要用 RPO 迭代优化提示词就行,省了算力又快。后续要是能把外部知识库整合进来,比如让反馈器参考专业文档,说不定能搞定更小众的场景。
论文里还放了优化前后的提示词例子,比如 FnCTOD 的初始提示词就一句话,优化后变成了 8 条具体规则,包括怎么跟踪用户目标、怎么验证 API 参数,特别详细。咱平时写提示词也能参考这思路,把模糊的要求拆成可执行的步骤,效果肯定不一样:

图 11:FnCTOD 初始提示词

图 12:RPO 优化后的 FnCTOD 提示词
总的来说,RPO 这方法给大模型多轮交互优化提供了个新方向 —— 不用死磕模型参数,把提示词当 “文本参数” 来强化学习优化,低成本又高效。咱下次再遇到大模型多轮聊崩的情况,不妨试试这思路,说不定能救场。
更多推荐

 10
10 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)