
RAGFlow智能体开发:实施深度研究
为 Agentic 推理实现深度研究。设置与大语言模型(LLM)的系统提示词(System Prompt)一起使用的变量。
实施深度研究
为 Agentic 推理实现深度研究。
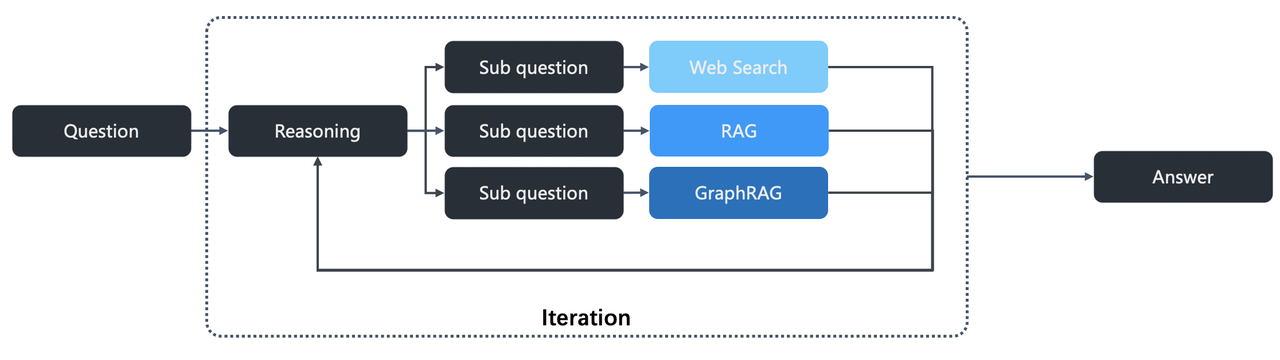
从 v0.17.0 版本开始,RAGFlow 支持在 AI 聊天中集成 Agentic 推理。下图展示了 RAGFlow 深度研究的工作流程。
要激活此功能
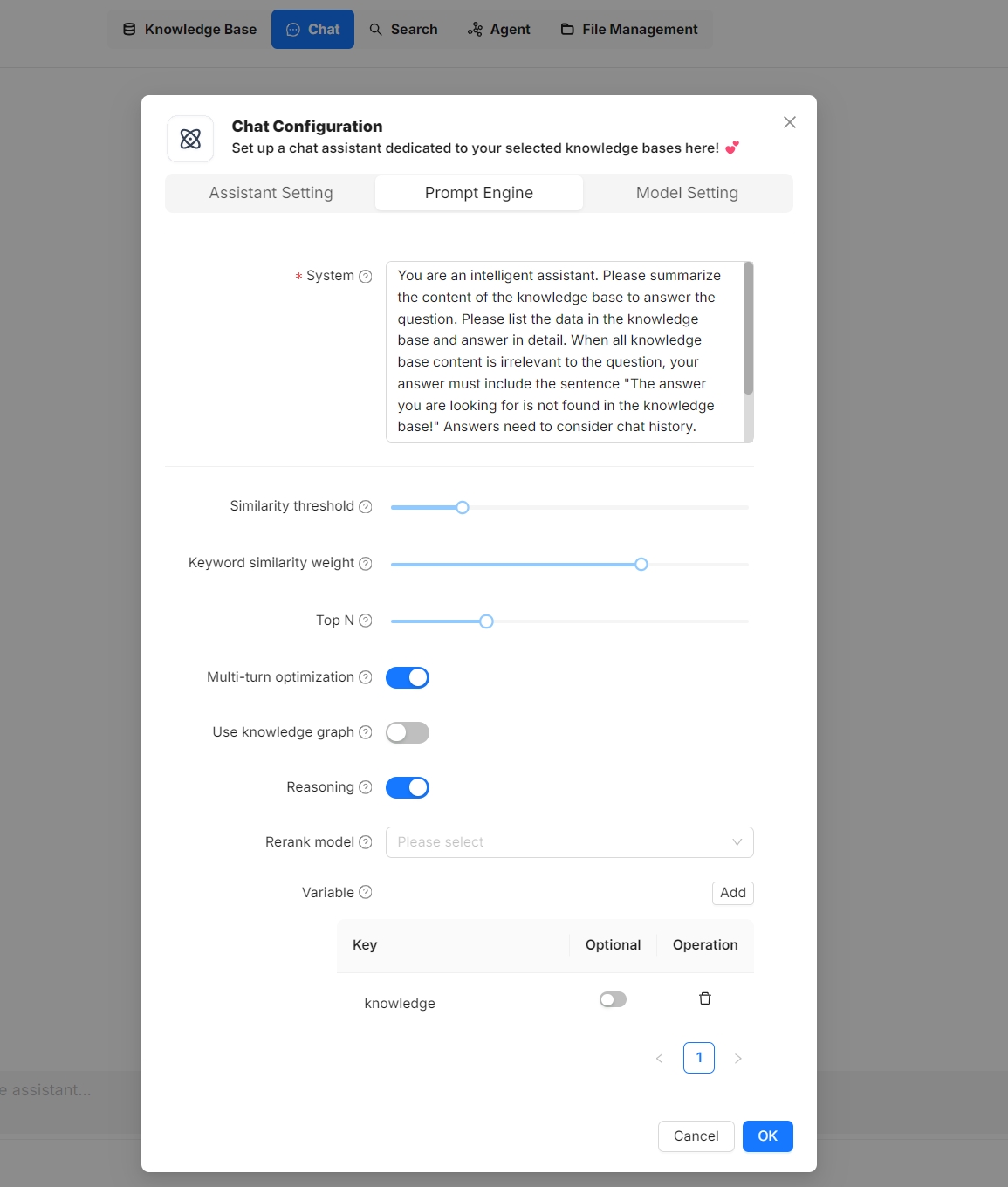
- 在聊天助手对话框的 Prompt 引擎 选项卡下,启用 推理 开关。
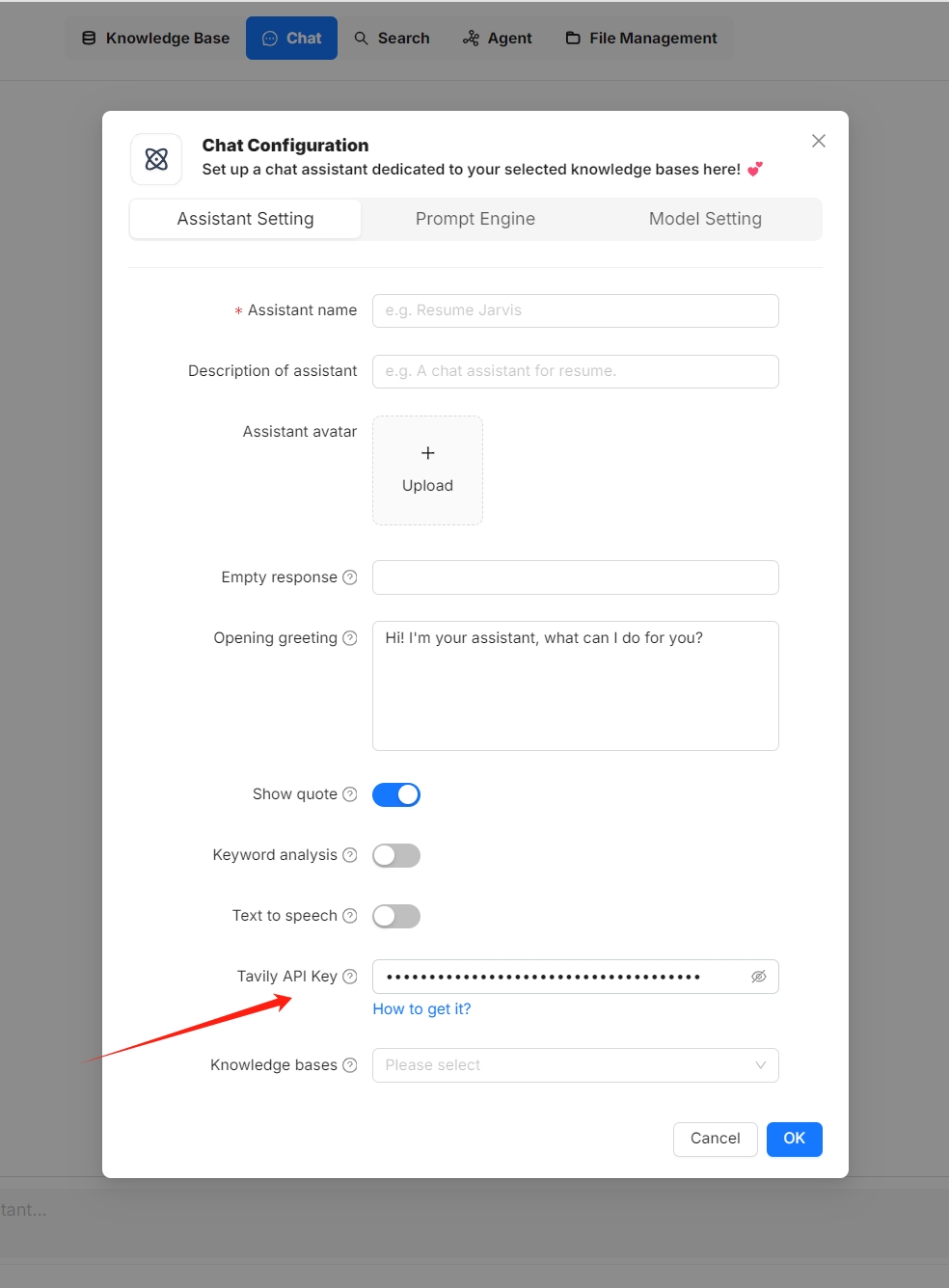
- 在聊天助手对话框的 助手设置 选项卡下,输入正确的 Tavily API 密钥,以利用基于 Tavily 的网络搜索功能。
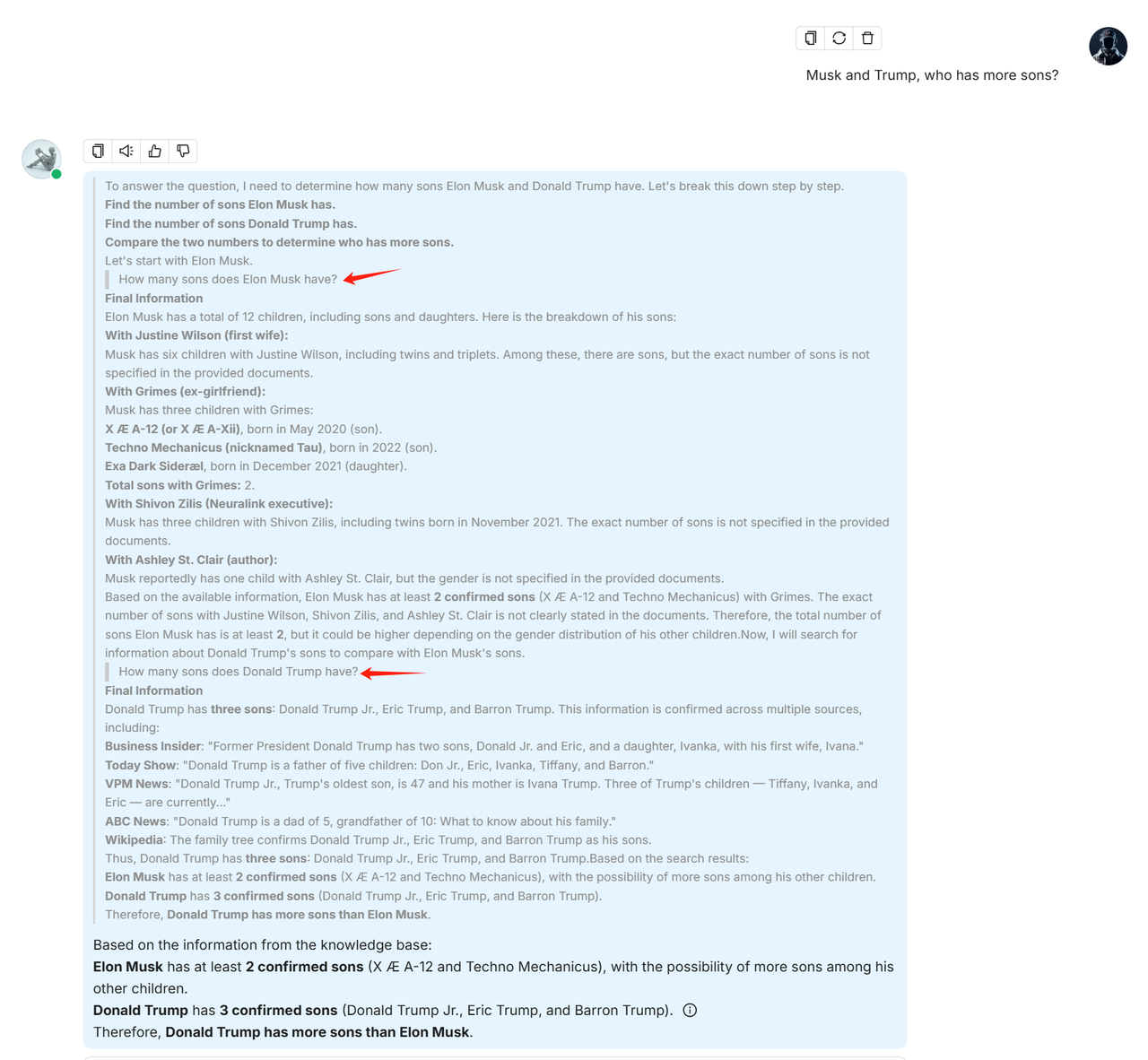
以下是集成了深度研究功能的对话截图:
设置变量
设置与大语言模型(LLM)的系统提示词(System Prompt)一起使用的变量。
在配置聊天模型的系统提示词时,变量在增强灵活性和可重用性方面扮演着重要角色。通过使用变量,您可以动态调整发送给模型的系统提示词。在 RAGFlow 中,如果您已在**对话配置**对话框中定义了变量(系统保留变量 {knowledge} 除外),则需要通过 RAGFlow 的 HTTP API 或其 Python SDK 为这些变量传入值。
重要
在 RAGFlow 中,变量与系统提示词密切相关。当您在**变量**部分添加变量时,也请将其包含在系统提示词中。反之,删除变量时,请确保也从系统提示词中移除它,否则会发生错误。
在哪里设置变量
将鼠标悬停在您的聊天助手上,点击**编辑**打开其**对话配置**对话框,然后点击**提示词引擎**选项卡。在这里,您可以在**系统提示词**字段和**变量**部分处理您的变量。
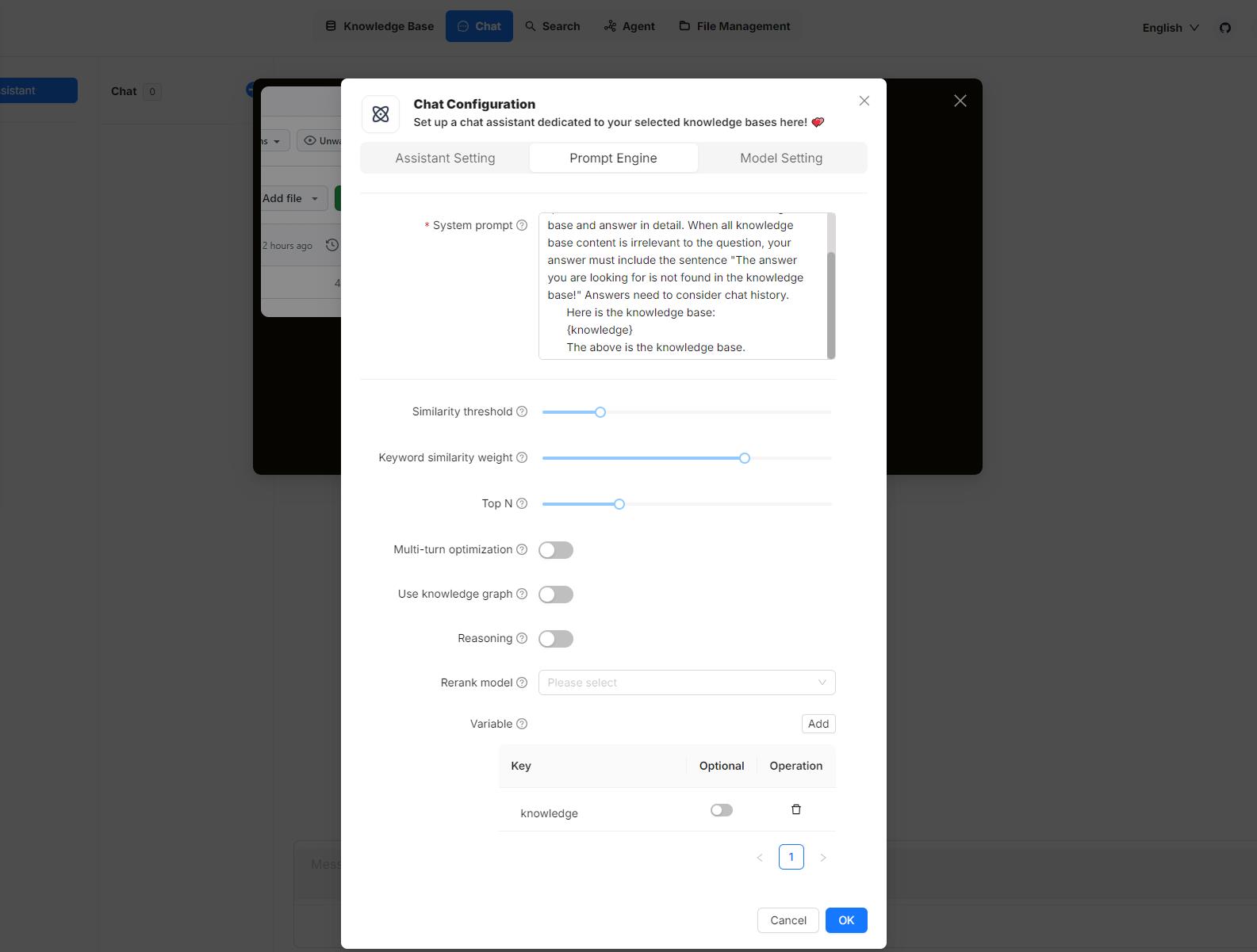
1. 管理变量
在**变量**部分,您可以添加、移除或更新变量。
{knowledge} - 保留变量
{knowledge} 是系统的保留变量,代表从**助手设置**选项卡下的**知识库**中检索到的知识区块(chunks)。如果您的聊天助手关联了特定的知识库,可以保留该变量。
注意
目前,将 {knowledge} 设置为可选或必选没有区别,但请注意,此设计将在适当的时候更新。
从 v0.17.0 版本开始,您可以在不指定知识库的情况下开始 AI 对话。在这种情况下,我们建议移除 {knowledge} 变量以防止不必要的引用,并保持**空回复**字段为空以避免错误。
自定义变量
除了 {knowledge} 之外,您还可以定义自己的变量与系统提示词配对使用。要使用这些自定义变量,您必须通过 RAGFlow 的官方 API 传入它们的值。**可选**开关决定了这些变量在相应的 API 中是否为必需项。
- 禁用(默认):该变量是必填项,必须提供。
- 启用:该变量是可选项,如果不需要可以省略。
2. 更新系统提示词
在**变量**部分添加或删除变量后,请确保您的更改也反映在系统提示词中,以避免不一致或错误。下面是一个示例:
You are an intelligent assistant. Please answer the question by summarizing chunks from the specified knowledge base(s)...
Your answers should follow a professional and {style} style.
...
Here is the knowledge base:
{knowledge}
The above is the knowledge base.
注意
如果您移除了 {knowledge},请确保彻底审查并更新整个系统提示词,以获得最佳效果。
API
为在**对话配置**对话框中定义的自定义变量传值的*唯一*方法是调用 RAGFlow 的 HTTP API 或通过其 Python SDK。
HTTP API
请参阅与聊天助手对话。下面是一个示例:
curl --request POST \
--url http://{address}/api/v1/chats/{chat_id}/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer <YOUR_API_KEY>' \
--data-binary '
{
"question": "xxxxxxxxx",
"stream": true,
"style":"hilarious"
}'
Python API
请参阅与聊天助手对话。下面是一个示例:
from ragflow_sdk import RAGFlow
rag_object = RAGFlow(api_key="<YOUR_API_KEY>", base_url="http://<YOUR_BASE_URL>:9380")
assistant = rag_object.list_chats(name="Miss R")
assistant = assistant[0]
session = assistant.create_session()
print("\n==================== Miss R =====================\n")
print("Hello. What can I do for you?")
while True:
question = input("\n==================== User =====================\n> ")
style = input("Please enter your preferred style (e.g., formal, informal, hilarious): ")
print("\n==================== Miss R =====================\n")
cont = ""
for ans in session.ask(question, stream=True, style=style):
print(ans.content[len(cont):], end='', flush=True)
cont = ans.content
加速问答
一份加速问答的检查清单。
请注意,您的一些设置可能会消耗大量时间。如果您经常发现问答过程很耗时,这里有一份检查清单供您参考:
- 在您的**对话配置**对话框的**提示词引擎**选项卡中,禁用**多轮优化**将减少从大语言模型(LLM)获取答案所需的时间。
- 在您的**对话配置**对话框的**提示词引擎**选项卡中,将**Rerank 模型**字段留空将显著减少检索时间。
- 使用 Rerank 模型时,请确保您有 GPU 进行加速;否则,Rerank 过程会*极其*缓慢。
注意
请注意,Rerank 模型在某些场景下是必不可少的。速度和性能之间总需要权衡;您必须根据具体情况权衡利弊。
- 在您的**对话配置**对话框的**助手设置**选项卡中,禁用**关键词分析**将减少从大语言模型(LLM)接收答案的时间。
- 与聊天助手对话时,点击*当前*对话上方的灯泡图标,并向下滚动弹出窗口,即可查看每个任务所花费的时间:
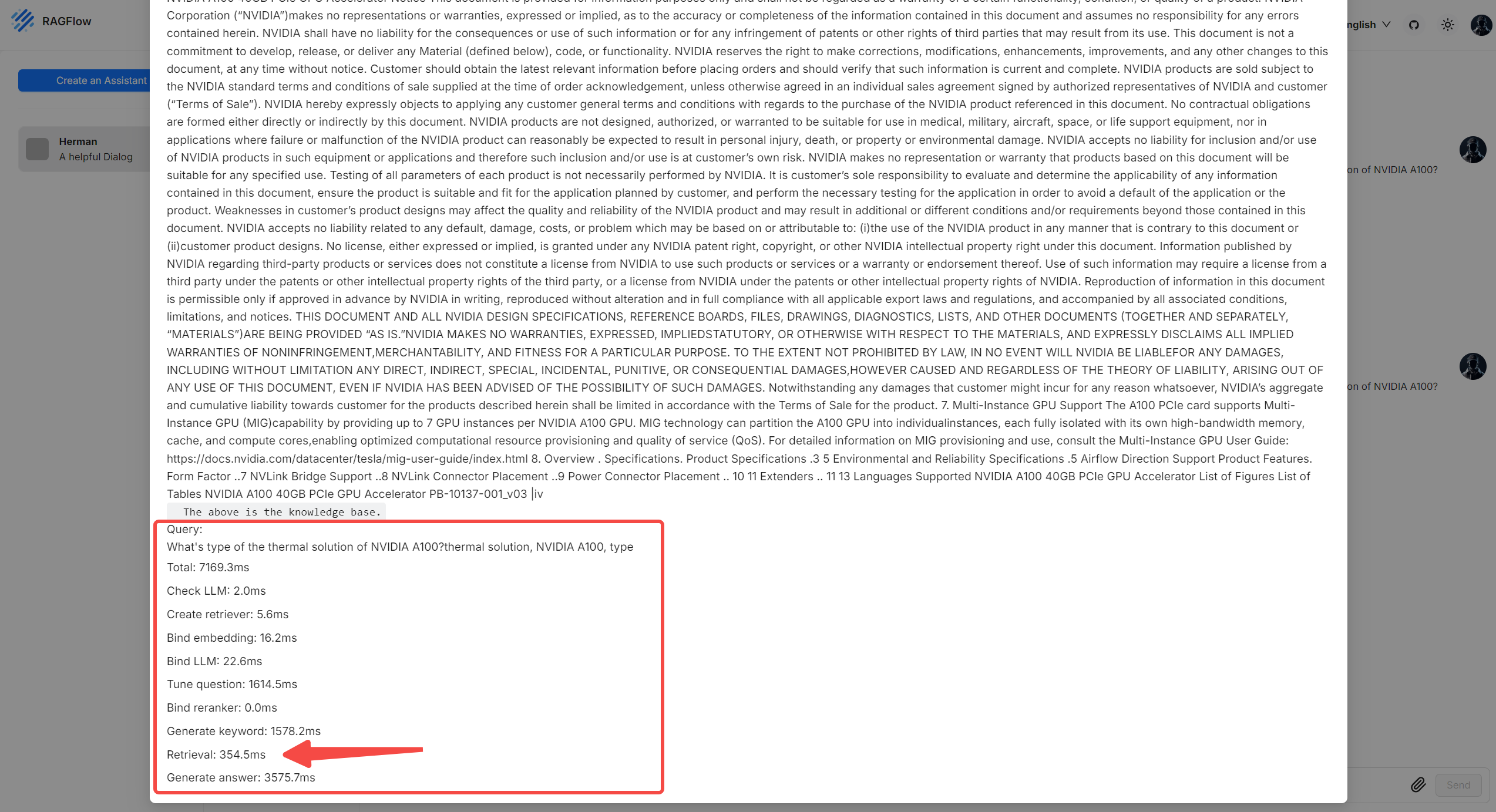
| 项目名称 | 描述 |
|---|---|
| 总计 | 本轮对话所花费的总时间,包括知识块检索和答案生成。 |
| 检查 LLM | 验证指定的大语言模型(LLM)所需的时间。 |
| 创建检索器 | 创建知识块检索器所需的时间。 |
| 绑定 Embedding | 初始化 Embedding 模型实例所需的时间。 |
| 绑定 LLM | 初始化大语言模型(LLM)实例所需的时间。 |
| 优化问题 | 利用多轮对话上下文优化用户查询所需的时间。 |
| 绑定 Reranker | 为知识块检索初始化 Reranker 模型实例所需的时间。 |
| 生成关键词 | 从用户查询中提取关键词所需的时间。 |
| 检索 | 检索知识块所需的时间。 |
| 生成答案 | 生成答案所需的时间。 |
《AI提示工程必知必会》为读者提供了丰富的AI提示工程知识与实战技能。《AI提示工程必知必会》主要内容包括各类提示词的应用,如问答式、指令式、状态类、建议式、安全类和感谢类提示词,以及如何通过实战演练掌握提示词的使用技巧;使用提示词进行文本摘要、改写重述、语法纠错、机器翻译等语言处理任务,以及在数据挖掘、程序开发等领域的应用;AI在绘画创作上的应用,百度文心一言和阿里通义大模型这两大智能平台的特性与功能,以及市场调研中提示词的实战应用。通过阅读《AI提示工程必知必会》,读者可掌握如何有效利用AI提示工程提升工作效率,创新工作流程,并在职场中脱颖而出。

更多推荐



 13
13 0
0- 0



 已为社区贡献91条内容
已为社区贡献91条内容

所有评论(0)