
大模型“瘦身”秘籍:知识蒸馏如何让小模型学会大模型的“思考”
别再以为只有大模型才配谈智能!知识蒸馏让轻量级学生模型“偷师”大模型的判断力,既省资源又不失精度。本文系统拆解白盒与黑盒蒸馏的核心原理、技术演进与实战陷阱,带你搞懂:小模型如何聪明地“抄作业”,又为何有时越学越歪?

前言
在AI落地的战场上,大模型如同重型坦克,火力猛、视野广,却也笨重耗油。企业真正需要的,往往是能塞进手机、跑在边缘设备、响应毫秒级的小巧“特工”。但小模型能力有限,如何让它在不增加算力的前提下,拥有接近大模型的判断力?答案就是——知识蒸馏(Knowledge Distillation)。
这项技术听起来像魔法:让一个“老师”模型把毕生所学,浓缩成一套可传授的“心法”,教给一个结构简单、参数稀疏的“学生”模型。学生虽小,却能举一反三,甚至在某些场景下表现媲美老师。但魔法背后,是严谨的数学、巧妙的训练策略,以及无数工程师踩过的坑。
本篇作为“企业大模型落地之道”专栏的关键一环,不讲虚的,只讲实操。我们将深入知识蒸馏的两种主流范式——白盒与黑盒,剖析它们各自的适用边界、技术细节与前沿演进。无论你是算法工程师、技术决策者,还是对模型压缩感兴趣的实践者,都能从中获得可落地的洞察。毕竟,在算力即成本的今天,让模型“又小又聪明”,不是锦上添花,而是生存必需。
1. 知识蒸馏:从“抄答案”到“学思路”的智能压缩术
1.1 为什么需要知识蒸馏?大模型的“落地困境”
大型语言模型动辄百亿、千亿参数,训练一次耗电堪比一个小城。推理时,单次请求可能需要多张高端GPU协同工作。这种资源消耗,在云端或许尚可承受,一旦走向终端——智能手机、IoT设备、车载系统、工业传感器——立刻水土不服。
延迟高、功耗大、部署成本高,三大痛点让大模型难以真正“走进千行百业”。企业需要的不是最强模型,而是“刚刚好够用”的模型。知识蒸馏应运而生,其本质是一种模型能力迁移技术:用大模型生成的“软标签”或中间特征,指导小模型学习,使其在保持轻量化的同时,逼近大模型的性能。
1.2 “蒸馏”之名从何而来?一个化学隐喻的AI转译
“蒸馏”本是化学术语,指通过加热蒸发再冷凝,提取液体中的精华成分。Hinton等人在2015年将这一概念引入深度学习,寓意从复杂模型中“提取”知识精华,注入简单模型。教师模型如同高温下的原液,学生模型则是冷凝后得到的高纯度产物——体积小,浓度高。
这种类比极为贴切。原始训练数据提供的“硬标签”(如“这是猫”)信息有限,而教师模型输出的“软标签”(如“80%猫,15%狗,5%狐狸”)蕴含了类别间的语义关联与置信度分布。学生模型学习的不是孤立答案,而是整个判断逻辑的“概率地形图”。
2. 白盒知识蒸馏:窥探“老师”内心的深度教学
2.1 什么是白盒蒸馏?全透明的知识传递
白盒知识蒸馏的前提是:学生模型可以访问教师模型的全部内部信息,包括权重参数、激活值、梯度流等。这种“开卷考试”式的教学,允许学生不仅模仿输出,还能对齐中间层的特征表示。
典型做法是在教师与学生网络的对应层之间添加特征对齐损失(Feature Alignment Loss)。例如,使用均方误差(MSE)或余弦相似度,迫使学生某一层的输出向量尽可能接近教师同层的输出。这种逐层模仿,让学生不仅“答对题”,还“用同样的思路解题”。
2.2 软标签与温度缩放:让概率分布更“柔软”
标准蒸馏的核心是软目标(Soft Targets)。教师模型的最终输出经过一个“温度”(Temperature, T)参数调整后的softmax函数处理:
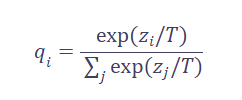
当T > 1时,概率分布被“软化”,高概率类与低概率类之间的差距缩小,更多暗知识(Dark Knowledge)被暴露出来。学生模型通过最小化自身软输出与教师软输出之间的KL散度进行学习。
温度T是关键超参。T太小,分布接近硬标签,失去蒸馏意义;T太大,所有类别概率趋近均等,信息模糊。实践中常采用动态温度或多温度蒸馏策略优化。
2.3 大语言模型蒸馏的特殊挑战:空白区域问题
在文本分类等封闭任务中,输出空间有限,软标签蒸馏效果显著。但在开放域文本生成中,教师模型的高概率区域可能远超学生模型的表达能力。学生强行拟合这些区域,会在自己无法覆盖的“空白区域”赋予过高概率,生成教师绝不会产出的荒谬内容——这就是空白区域问题(Void Region Problem)。
MiniLLM提出用反向KL散度替代正向KL:
- 正向KL(标准蒸馏):鼓励学生覆盖教师所有高概率点,易导致过拟合空白区
- 反向KL:鼓励学生集中在自身能表达的高概率区域,同时尽量贴近教师分布
反向KL更保守,更适合能力受限的学生模型。其梯度可通过策略梯度法(Policy Gradient)近似计算,结合单步分解、教师混合采样、长度归一化等技巧,显著提升训练稳定性。
2.4 进阶白盒蒸馏:从特征对齐到任务感知
近年研究不再满足于简单层对齐。TED(Task-aware Embedding Distillation)在教师每层输出后添加任务特定过滤器,先训练过滤器提取关键任务特征,再冻结过滤器,指导学生对齐过滤后的特征。这种方式让蒸馏更聚焦于任务相关知识,避免冗余信息干扰。
MiniMoE则另辟蹊径,让学生模型采用混合专家(MoE)架构。MoE通过稀疏激活多个子网络(专家),在参数量不变的情况下大幅提升模型容量,缩小与教师的能力鸿沟,使蒸馏更高效。
KPTD(Knowledge-Preserving Task Distillation)更进一步,将外部知识库(如实体定义)融入蒸馏过程。它先用教师模型基于实体定义生成“知识转移集”,再让学生在该数据集上学习,确保其输出不仅模仿教师,还符合真实世界知识。
3. 黑盒知识蒸馏:看不见“老师”,却能模仿其“言行”
3.1 黑盒蒸馏的现实驱动力:API即服务时代
现实中,企业常通过API调用闭源大模型(如GPT-4、Claude)。这些模型是黑盒,无法获取内部参数。但企业仍希望用自己的小模型复现其能力。黑盒蒸馏正是为此而生——仅凭输入输出对,实现知识迁移。
这种模式高度契合当前AI即服务(AIaaS)生态。你不需要拥有大模型,只需会“提问”和“记录答案”,就能训练出专属小模型。
3.2 TAPIR框架:用课程学习“挑难题”蒸馏
TAPIR(Task-Aware Curriculum Planning for Instruction Refinement)代表了黑盒蒸馏的前沿思路。它不盲目蒸馏所有数据,而是动态构建课程,专攻学生薄弱环节。
流程如下:
- 初始化学生模型(如LLaMA-7B)
- 在开源指令集(如Alpaca)上测试,计算每条指令的模型拟合难度(MFD)——即学生输出与教师输出的差异
- 高MFD样本被选为“种子”,用教师模型生成更多同难度指令-响应对
- 引入思维链(CoT)或代码注释等回答风格,增强逻辑可解释性
- 多轮迭代:用裁判模型(如GPT-4)打分,筛选高质量蒸馏数据
TAPIR的本质是“因材施教”。它避免了在简单任务上浪费算力,集中资源攻克难点,显著提升蒸馏效率。
3.3 Distilling Step-by-Step:不仅要答案,还要推理过程
传统蒸馏只学“答案”,但复杂任务需要“推理链”。Distilling Step-by-Step要求教师模型在生成标签的同时,输出自然语言推理依据。例如:
- 输入:“巴黎是哪个国家的首都?”
- 教师输出:
- 标签:法国
- 推理依据:“巴黎是法国的首都,这是基本地理常识。”
学生模型被训练同时预测标签和推理依据。这种多任务学习迫使模型理解因果逻辑,而非死记硬背。在数学推理、逻辑问答等任务上,性能提升显著。
3.4 黑盒蒸馏的数据瓶颈与合成策略
黑盒蒸馏严重依赖高质量指令-响应对。真实人类标注成本高,而随机采样教师输出可能包含噪声或低信息量样本。
解决方案包括:
- 对抗性数据生成:构造易错输入,逼出教师深层能力
- 多样性采样:确保覆盖不同任务类型、难度、领域
- 自反馈过滤:用初步训练的学生模型筛选高价值样本
黑盒蒸馏的成功,往往不取决于模型架构,而在于数据工程的艺术。
4. 白盒 vs 黑盒:一场关于“透明度”与“实用性”的权衡
4.1 核心差异对比
| 维度 | 白盒知识蒸馏 | 黑盒知识蒸馏 |
|---|---|---|
| 教师模型访问权限 | 完全访问(参数、梯度、中间层) | 仅输入输出接口 |
| 知识迁移深度 | 深(特征、逻辑、分布) | 浅(仅输出行为) |
| 适用场景 | 自研大模型内部压缩、模型加速 | 闭源API模型能力复现 |
| 训练数据需求 | 可用原始训练集或新数据 | 必须构造指令-响应对 |
| 学生模型上限 | 更接近教师性能 | 受限于输出模仿质量 |
| 典型技术 | 特征对齐、反向KL、MoE | 课程学习、推理链蒸馏 |
4.2 企业如何选择?
- 若你拥有教师模型的完全控制权(如自研百亿模型),白盒蒸馏是首选。它能榨取更多知识,实现更高压缩比。
- 若你依赖第三方大模型API(如调用GPT-4做客服),黑盒蒸馏是唯一路径。重点在于设计高效的数据合成与筛选流程。
混合策略也逐渐兴起:先用黑盒蒸馏获得基础能力,再用少量白盒信息微调关键层。
5. 落地陷阱与避坑指南
5.1 蒸馏不是万能药:能力鸿沟不可逾越
学生模型容量过小,再好的蒸馏也无济于事。一个100万参数的模型,无法学会千亿模型的全部知识。蒸馏前务必评估学生模型的理论上限。经验法则是:学生参数量至少达到教师的10%~30%,才可能获得可用性能。
5.2 数据分布偏移:教师强,学生弱
蒸馏数据若与真实应用场景分布不一致,学生上线后性能骤降。例如,用通用语料蒸馏的客服模型,在专业金融场景表现糟糕。蒸馏数据必须贴近目标领域,必要时加入领域自适应技术。
5.3 过拟合教师错误
教师模型并非完美。它可能在某些输入上犯错,或带有偏见。学生盲目模仿,会继承甚至放大这些缺陷。引入真实标签作为正则项,或使用对抗验证检测教师错误样本,可缓解此问题。
5.4 温度与损失函数的调参艺术
固定温度T往往次优。可尝试:
- 退火策略:训练初期高T(软分布),后期低T(硬分布)
- 多尺度蒸馏:不同层使用不同T
- 组合损失:KL损失 + 真实标签交叉熵 + 特征对齐损失
损失权重需精细调整,否则学生可能“偏科”——只学教师分布,忽略真实任务目标。
6. 前沿趋势:蒸馏正在走向“个性化”与“自动化”
6.1 个性化蒸馏:为每个设备定制小模型
未来,蒸馏不再是“一刀切”。针对不同设备算力、不同用户偏好,可动态生成定制化学生模型。例如,高端手机用较大模型,低端设备用极简版,但都从同一教师蒸馏而来。
6.2 自动蒸馏架构搜索(AutoKD)
人工设计学生架构效率低下。AutoKD结合神经架构搜索(NAS)与蒸馏,自动探索最优学生结构,在精度与延迟间找平衡。Google的TinyNAS、Meta的AutoDistill均在此方向取得进展。
6.3 蒸馏与量化、剪枝的协同
蒸馏常与模型量化(降低精度)、剪枝(移除冗余连接)结合,形成完整压缩流水线。顺序很重要:通常先蒸馏再量化,避免低精度干扰知识迁移。
知识蒸馏不是魔法,而是一门精密的工程艺术。它让大模型的智慧得以“平民化”,让AI真正走进边缘、终端与日常。白盒蒸馏如师徒面授,深得精髓;黑盒蒸馏似隔空学艺,重在神似。无论哪种路径,核心都是——在能力与效率之间,找到那个恰到好处的平衡点。
当我们不再迷信“越大越好”,转而追求“刚刚好够用”,AI的落地之路才真正开阔。小模型学会大模型的“思考”,不仅是技术的胜利,更是工程智慧的闪光。
更多推荐



 10
10 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)