
LangChain之结合RAG使用
大模型的 “幻觉”(Hallucination)是指模型在生成内容时,输出的信息。这种现象是当前大语言模型(LLM)的核心挑战之一,本质是模型 “记忆偏差” 与 “推理缺陷” 的综合体现,而非真正的 “欺骗”—— 模型本身无法判断输出的 “真实性”,仅基于训练数据的统计规律生成内容。可以说,当应用需求集中在利用大模型去,且知识库足够大,那么除了微调大模型外,就是非常有效的一种缓解大模型推理的“幻觉
大模型的幻觉问题
大模型的 “幻觉”(Hallucination)是指模型在生成内容时,输出看似合理、逻辑通顺,但与事实不符、无中生有或存在误导性的信息。这种现象是当前大语言模型(LLM)的核心挑战之一,本质是模型 “记忆偏差” 与 “推理缺陷” 的综合体现,而非真正的 “欺骗”—— 模型本身无法判断输出的 “真实性”,仅基于训练数据的统计规律生成内容。
可以说,当应用需求集中在利用大模型去 回答特定私有领域的知识 ,且知识库足够大,那么除了微调大模型外, RAG就是非常有效的一种缓解大模型推理的“幻觉”问题的解决方案。
Retrieval流程
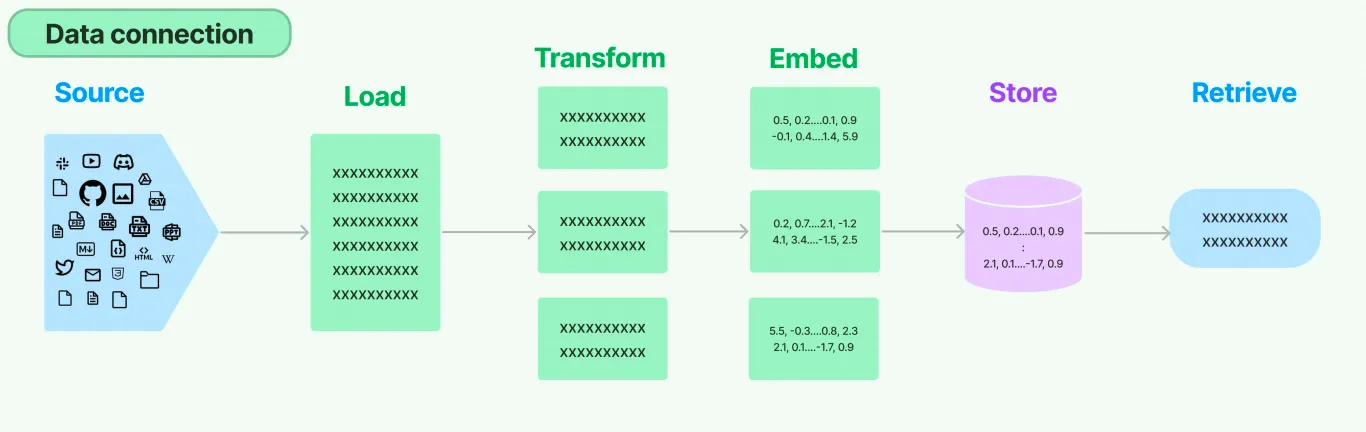
环节1:Source(数据源)
指的是RAG架构中所外挂的知识库,原始数据源类型多样:比如csv文件、json文件、也可以是某一个业务流程的API、实时的数据等等…
环节2:Load(加载)
文档加载器(Document Loaders)负责将来自不同数据源的非结构化文本,加载到内存,成为文档(Document)对象 。
from langchain_community.document_loaders import TextLoader
text_loader = TextLoader("./test.txt")
docs = text_loader.load() #返回List列表(Document对象)
print(docs)
#输出:[Document(metadata={'source': './test.txt'}, page_content='123456')]
由输出信息可知,文档对象包含文档内容(page_content)和相关元数据信息(metadata)。
环节3:Transform(转换)
文档转换器(Document Transformers) 负责对加载的文档进行转换和处理,以便更好地适应下游任务的需求。文档转换器提供了一致的接口(工具)来操作文档,主要包括以下几类:
- 文本拆分器(Text Splitters) :将长文本拆分成语义上相关的小块,以适应语言模型的上下文窗口限制。
- 冗余过滤器(Redundancy Filters) :识别并过滤重复的文档。
- 元数据提取器(Metadata Extractors) :从文档中提取标题、语调等结构化元数据。
- 多语言转换器(Multi-lingual Transformers) :实现文档的机器翻译。
- 对话转换器(Conversational Transformers) :将非结构化对话转换为问答格式的文档。
Text Splitting(文档拆分)
- 拆分/分块的必要性 :文档必须切块后才能向量化存入数据库中。
- 文档拆分器的多样性 :LangChain提供了丰富的文档拆分器,可以切分普通文本、markdown、JSON、HTML、代码等。
- 拆分/分块的挑战性 :实际拆分操作中需要处理许多细节问题, 不同类型的文本 、 不同的使用场景都需要采用不同的分块策略。
- 可以按照 数据类型 进行切片处理,比如针对 文本类数据,可以直接按照字符、段落进行切片; 代码类数据则需要进一步细分以保证代码的功能性;
- 可以直接根据 token 进行切片处理
文本切分可视化网页:https://chunkviz.up.railway.app/
环节4:Embed(嵌入)
文档嵌入模型(Text Embedding Models)负责将文本转换为向量表示 ,即模型赋予了文本计算机可理解的数值表示,使文本可用于向量空间中的各种运算,大大拓展了文本分析的可能性,是自然语言处理领域非常重要的技术。
关键特性:相似的词在向量空间中距离相近。
文本嵌入为LangChain中的问答、检索、推荐等功能提供了重要支持。具体为:
- 语义匹配 :通过计算两个文本的向量余弦相似度,判断它们在语义上的相似程度,实现语义匹配。
- 文本检索 :通过计算不同文本之间的向量相似度,可以实现语义搜索,找到向量空间中最相似的文本。
- 信息推荐 :根据用户的历史记录或兴趣嵌入生成用户向量,计算不同信息的向量与用户向量的相似度,推荐相似的信息。
- 知识挖掘 :可以通过聚类、降维等手段分析文本向量的分布,发现文本之间的潜在关联,挖掘知识。
- 自然语言处理 :将词语、句子等表示为稠密向量,为神经网络等下游任务提供输入。
环节5:Store(存储)
把文本嵌入存储到向量存储或临时缓存,以避免需要重新计算它们。这里就出现了数据库,支持这些嵌入的高效存储和搜索的需求。
环节6:Retrieve(检索)
检索器(Retrievers)是一种用于 响应非结构化查询 的接口,它可以返回符合查询要求的文档。LangChain 提供了一些常用的检索器,如 向量检索器 、 文档检索器 、 网站研究检索器 等。
文档拆分器 Text Splitters
为什么要拆分/分块/切分?
- 信息有效性问题:即便 Query 答案存在于某一 Document 中,直接将完整 Document 放入 Prompt 也非最优选择 —— 因文档会包含大量与 Query 无关的无效信息,而无效信息越多,会对大模型后续的推理准确性、逻辑性产生越大的干扰。
- Token 容量限制问题:所有大模型都有输入 Token 的最大上限,若 Document 体积过大(如几百兆的 PDF),其对应的 Token 数量会远超模型承载能力,导致大模型无法完整接收并处理这些信息。
Chunking拆分的策略
方法1:根据句子切分:这种方法按照自然句子边界进行切分,以保持语义完整性。
方法2:按照固定字符数来切分:这种策略根据特定的字符数量来划分文本,但可能会在不适当的位置切断句子。
方法3:按固定字符数来切分,结合重叠窗口(overlapping windows):此方法与按字符数切分相似,但通过重叠窗口技术避免切分关键内容,确保信息连贯性。
方法4:递归字符切分方法:通过递归字符方式动态确定切分点,这种方法可以根据文档的复杂性和内容密度来调整块的大小。
方法5:根据语义内容切分:这种 高级策略 依据文本的语义内容来划分块,旨在保持相关信息的集中和完整,适用于需要高度语义保持的应用场景。
CharacterTextSplitter
参数情况说明:
- chunk_size :每个切块的最大token数量,默认值为4000。
- chunk_overlap :相邻两个切块之间的最大重叠token数量,默认值为200。
- separator :分割使用的分隔符,默认值为"\n\n"。
- length_function :用于计算切块长度的方法。默认赋值为父类TextSplitter的len函数。
示例一:
# 1.导入相关依赖
from langchain.text_splitter import CharacterTextSplitter
# 2.示例文本
text = """
LangChain 是一个用于开发由语言模型驱动的应用程序的框架的。它提供了一套工具和抽象,使开发者
能够更容易地构建复杂的应用程序。
"""
# 3.定义字符分割器
splitter = CharacterTextSplitter(
chunk_size=50, # 每块大小
chunk_overlap=5,# 块与块之间的重复字符数
#length_function=len,
separator="" # 设置为空字符串时,表示禁用分隔符优先
)
# 4.分割文本
texts = splitter.split_text(text)
# 5.打印结果
for i, chunk in enumerate(texts):
print(f"块 {i+1}:长度:{len(chunk)}")
print(chunk)
print("-" * 50)
# 块 1:长度:49
# LangChain 是一个用于开发由语言模型驱动的应用程序的框架的。它提供了一套工具和抽象,使开
# 发
# --------------------------------------------------
# 块 2:长度:22
# 象,使开发者能够更容易地构建复杂的应用程序。
# --------------------------------------------------
separator优先原则:当设置了 separator (如"。"),分割器会首先尝试在分隔符处分割,然后再考虑 chunk_size。这是为了避免在句子中间硬性切断。是为了:
- 优先保持语义完整性(不切断句子)
- 避免产生无意义的碎片(如半个单词/不完整句子)
- 如果 chunk_size 比片段小,无法拆分片段,导致 overlap失效。
- chunk_overlap仅在合并后的片段之间生效(如果 chunk_size 足够大)。如果没有合并的片段,则 overlap失效。
RecursiveCharacterTextSplitter:最常用
遇到 特定字符 时进行分割。默认情况下,它尝试进行切割的字符包括 [“\n\n”, “\n”, " “, “”] 。具体为:根据第一个字符进行切块,但如果任何切块太大,则会继续移动到下一个字符继续切块,以此类推。
有些书写系统没有单词边界,例如中文、日文和泰文。使用默认分隔符列表[”\n\n", “\n”, " ", “”]分割文本可能导致单词错误的分割。为了保持单词在一起,可以自定义分割字符。
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=200,
chunk_overlap=20, # 增加重叠字符
separators=["\n\n", "\n", "。", "!", "?", "……", ",", ""], # 添加中文标点
length_function=len,
keep_separator=True #保留句尾标点(如 ……),避免切割后丢失语气和逻辑
)
SemanticChunker
SemanticChunking(语义分块)是 LangChain 中一种更高级的文本分割方法,它超越了传统的基于字符或固定大小的分块方式,而是根据 文本的语义结构 进行智能分块,使每个分块保持语义完整性 ,从而提高检索增强生成(RAG)等应用的效果。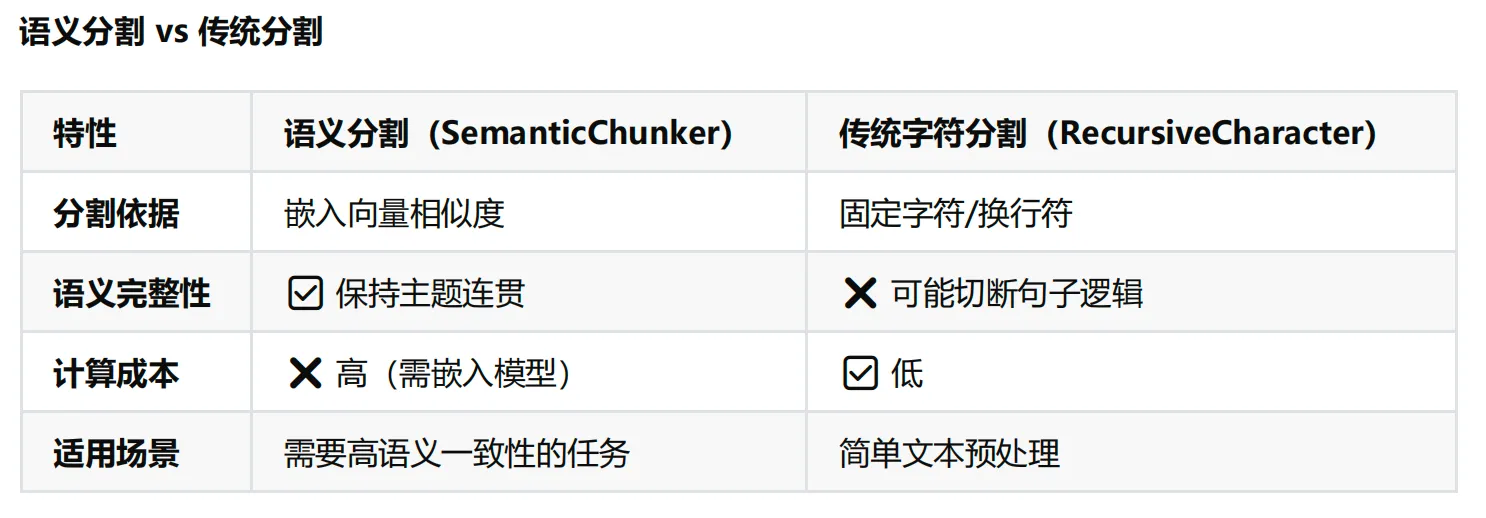
embed_model = OpenAIEmbeddings(
model="text-embedding-3-large"
)
# 获取切割器
text_splitter = SemanticChunker(
embeddings=embed_model,
breakpoint_threshold_type="percentile",#断点阈值类型:字面值["百分位数", "标准差", "四分位距", "梯度"] 选其一
breakpoint_threshold_amount=65.0 #断点阈值数量 (极低阈值 → 高分割敏感度)
)
关于参数的说明:
-
breakpoint_threshold_type (断点阈值类型)
作用:定义文本语义边界的检测算法,决定何时分割文本块。
-
breakpoint_threshold_amount (断点阈值量)
作用:控制分割的粒度敏感度,值越小分割越细(块越多),值越大分割越粗(块越少)。

文档嵌入模型 Text Embedding Models
Text Embedding Models:文档嵌入模型,提供将文本编码为向量的能力,即 文档向量化。文档写入和用户查询匹配前都会先执行文档嵌入编码,即向量化。
LangChain中针对向量化模型的封装提供了两种接口,一种针对文档的向量化(embed_documents) ,一种针对句子的向量化embed_query。
句子的向量化embed_query:
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 待嵌入的文本句子
text = "What was the name mentioned in the conversation?"
# 生成一个嵌入向量
embedded_query = embeddings_model.embed_query(text = text)
# 使用embedded_query[:5]来查看前5个元素的值
print(embedded_query[:5])
print(len(embedded_query))
# [0.005329647101461887, -0.0006122003542259336, 0.0389961302280426, -0.002898985054343939, -0.008904732763767242]
# 1536
文档的向量化(embed_documents) :
import os
import dotenv
from langchain_openai import OpenAIEmbeddings
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
embeddings_model = OpenAIEmbeddings(model="text-embedding-ada-002")
# 待嵌入的文本列表
texts = [
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
# 生成一个嵌入向量
embeddings = embeddings_model.embed_documents(texts)
for i in range(len(texts)):
print(f"{texts[i]}:{embeddings[i][:3]}",end="\n\n")
# Hi there!:[-0.020325319841504097, -0.007096723187714815, -0.022839006036520004]
#
# Oh, hello!:[0.004446744918823242, -0.014353534206748009, 0.0019785689655691385]
#
# What's your name?:[-0.004887457471340895, -0.009618516080081463, 0.007236444391310215]
#
# My friends call me World:[-0.004588752053678036, -0.014497518539428711, 0.01022490207105875]
#
# Hello World!:[0.002393412170931697, 0.0002737858740147203, -0.0023398753255605698]
向量存储(Vector Stores)
简单说:向量 = 用数字描述 “相似性”,而 “判断相似性” 是很多 AI 场景的核心需求(如 RAG 中 “找与 Query 相似的文档”、推荐系统中 “找与用户兴趣相似的商品”)。
为什么传统数据库存不了、查不快?
传统数据库(如 MySQL、PostgreSQL)擅长存储 “结构化数据”(如表格中的姓名、年龄、订单号),查询时依赖 “精确匹配”(如 “查年龄 = 25 的用户”);但向量是 “高维数组”(常见维度 512-4096),核心需求是 “相似性查询”(如 “找与 Query 向量最像的 Top10 文档向量”),传统数据库存在两大短板:
- 存储效率低:传统数据库没有针对高维向量的压缩和索引优化,存储 100 万条 1024 维向量,会占用远超预期的空间;
- 查询速度慢:若用传统数据库查相似向量,需要 “遍历所有向量计算距离”(全量扫描),100 万条数据可能需要几秒甚至几分钟,完全无法满足实时场景(如 RAG 需要几百毫秒内返回结果)。
因此,向量数据库的核心价值:为高维向量提供 “高效存储” 和 “快速相似性查询” 的能力。
数据的存储
举例:加载数据,向量化后存储到Chroma数据库
# 1.导入相关依赖
from langchain_chroma import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
# 2.定义文档
raw_documents = [
Document(
page_content="葡萄是一种常见的水果,属于葡萄科葡萄属植物。它的果实呈圆形或椭圆形,颜
色有绿色、紫色、红色等多种。葡萄富含维生素C和抗氧化物质,可以直接食用或酿造成葡萄酒。",
metadata={"source": "水果", "type": "植物"}
),
Document(
page_content="白菜是十字花科蔬菜,原产于中国北方。它的叶片层层包裹形成紧密的球状,口
感清脆微甜。白菜富含膳食纤维和维生素K,常用于制作泡菜、炒菜或煮汤。",
metadata={"source": "蔬菜", "type": "植物"}
),
Document(
page_content="狗是人类最早驯化的动物之一,属于犬科。它们具有高度社会性,能理解人类情
绪,常被用作宠物、导盲犬或警犬。不同品种的狗在体型、毛色和性格上有很大差异。",
metadata={"source": "动物", "type": "哺乳动物"}
),
Document(
page_content="猫是小型肉食性哺乳动物,性格独立但也能与人类建立亲密关系。它们夜视能力
极强,擅长捕猎老鼠。家猫的品种包括波斯猫、暹罗猫等,毛色和花纹多样。",
metadata={"source": "动物", "type": "哺乳动物"}
),
Document(
page_content="人类是地球上最具智慧的生物,属于灵长目人科。现代人类(智人)拥有高度发
达的大脑,创造了语言、工具和文明。人类的平均寿命约70-80年,分布在全球各地。",
metadata={"source": "生物", "type": "灵长类"}
),
Document(
page_content="太阳是太阳系的中心恒星,直径约139万公里,主要由氢和氦组成。它通过核聚
变反应产生能量,为地球提供光和热。太阳活动周期约为11年,会影响地球气候。",
metadata={"source": "天文", "type": "恒星"}
),
Document(
page_content="长城是中国古代的军事防御工程,总长度超过2万公里。它始建于春秋战国时
期,秦朝连接各段,明朝大规模重修。长城是世界文化遗产和人类建筑奇迹。",
metadata={"source": "历史", "type": "建筑"}
),
Document(
page_content="量子力学是研究微观粒子运动规律的物理学分支。它提出了波粒二象性、测不准
原理等概念,彻底改变了人类对物质世界的认知。量子计算机正是基于这一理论发展而来。",
metadata={"source": "物理", "type": "科学"}
),
Document(
page_content="《红楼梦》是中国古典文学四大名著之一,作者曹雪芹。小说以贾、史、王、薛
四大家族的兴衰为背景,描绘了贾宝玉与林黛玉的爱情悲剧,反映了封建社会的种种矛盾。",
metadata={"source": "文学", "type": "小说"}
),
Document(
page_content="新冠病毒(SARS-CoV-2)是一种可引起呼吸道疾病的冠状病毒。它通过飞沫传
播,主要症状包括发热、咳嗽、乏力。疫苗和戴口罩是有效的预防措施。",
metadata={"source": "医学", "type": "病毒"}
)
]
# 3. 创建嵌入模型
embedding = OpenAIEmbeddings(model="text-embedding-ada-002")
# 4.创建向量数据库
db = Chroma.from_documents(
documents=raw_documents,
embedding=embedding,
persist_directory="./asset/chroma-3",
)
数据检索
① 相似性检索(similarity_search)
# 5. 检索示例(返回前3个最相关结果)
query = "哺乳动物"
docs = db.similarity_search(query, k=3) # k=3表示返回3个最相关文档
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
# 查询: '哺乳动物' 的结果:
# 结果 1:
# 内容: 猫是小型⾁⻝性哺乳动物,性格独⽴但也能与⼈类建⽴亲密关系。它们夜视能⼒极强,擅⻓
# 捕猎⽼⿏。家猫的品种包括波斯猫、暹罗猫等,毛⾊和花纹多样。
# 元数据: {'source': '动物', 'type': '哺乳动物'}
# 结果 2:
# 内容: 狗是⼈类最早驯化的动物之⼀,属于⽝科。它们具有⾼度社会性,能理解⼈类情绪,常被⽤
# 作宠物、导盲⽝或警⽝。不同品种的狗在体型、毛⾊和性格上有很⼤差异。
# 元数据: {'source': '动物', 'type': '哺乳动物'}
# 结果 3:
# 内容: ⼈类是地球上最具智慧的⽣物,属于灵⻓⽬⼈科。现代⼈类(智⼈)拥有⾼度发达的⼤脑,
# 创造了语⾔、⼯具和⽂明。⼈类的平均寿命约70-80年,分布在全球各地。
# 元数据: {'source': '⽣物', 'type': '灵⻓类'}
② 支持直接对问题向量查询(similarity_search_by_vector)
搜索与给定嵌入向量相似的文档,它接受嵌入向量作为参数,而不是字符串。
query = "哺乳动物"
embedding_vector = embedding.embed_query(query)
docs = db.similarity_search_by_vector(embedding_vector, k=3)
print(f"查询: '{query}' 的结果:")
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
# 查询: '哺乳动物' 的结果:
# 结果 1:
# 内容: 猫是小型⾁⻝性哺乳动物,性格独⽴但也能与⼈类建⽴亲密关系。它们夜视能⼒极强,擅⻓
# 捕猎⽼⿏。家猫的品种包括波斯猫、暹罗猫等,毛⾊和花纹多样。
# 元数据: {'source': '动物', 'type': '哺乳动物'}
# 结果 2:
# 内容: 狗是⼈类最早驯化的动物之⼀,属于⽝科。它们具有⾼度社会性,能理解⼈类情绪,常被⽤
# 作宠物、导盲⽝或警⽝。不同品种的狗在体型、毛⾊和性格上有很⼤差异。
# 元数据: {'source': '动物', 'type': '哺乳动物'}
# 结果 3:
# 内容: ⼈类是地球上最具智慧的⽣物,属于灵⻓⽬⼈科。现代⼈类(智⼈)拥有⾼度发达的⼤脑,
# 创造了语⾔、⼯具和⽂明。⼈类的平均寿命约70-80年,分布在全球各地。
# 元数据: {'source': '⽣物', 'type': '灵⻓类'}
③ 相似性检索,支持过滤元数据(filter)
query = "哺乳动物"
docs = db.similarity_search(
query=query,
k=3,
filter={"source": "动物"}
)
for i, doc in enumerate(docs, 1):
print(f"\n结果 {i}:")
print(f"内容: {doc.page_content}")
print(f"元数据: {doc.metadata}")
# 结果 1:
# 内容: 猫是小型⾁⻝性哺乳动物,性格独⽴但也能与⼈类建⽴亲密关系。它们夜视能⼒极强,擅⻓
# 捕猎⽼⿏。家猫的品种包括波斯猫、暹罗猫等,毛⾊和花纹多样。
# 元数据: {'source': '动物', 'type': '哺乳动物'}
# 结果 2:
# 内容: 狗是⼈类最早驯化的动物之⼀,属于⽝科。它们具有⾼度社会性,能理解⼈类情绪,常被⽤
# 作宠物、导盲⽝或警⽝。不同品种的狗在体型、毛⾊和性格上有很⼤差异。
# 元数据: {'type': '哺乳动物', 'source': '动物'}
④ 通过L2距离分数进行搜索(similarity_search_with_score)
说明:分数值越小,检索到的文档越和问题相似。分值取值范围:[0,正无穷]
docs = db.similarity_search_with_score(
"量子力学是什么?"
)
for doc, score in docs:
print(f" [L2距离得分={score:.3f}] {doc.page_content} [{doc.metadata}]")
# [L2距离得分=0.182] 量⼦⼒学是研究微观粒⼦运动规律的物理学分⽀。它提出了波粒⼆象性、测
# 不准原理等概念,彻底改变了⼈类对物质世界的认知。量⼦计算机正是基于这⼀理论发展而来。
# [{'type': '科学', 'source': '物理'}]
# [L2距离得分=0.447] 太阳是太阳系的中⼼恒星,直径约139万公⾥,主要由氢和氦组成。它通过核
# 聚变反应产⽣能量,为地球提供光和热。太阳活动周期约为11年,会影响地球⽓候。 [{'source':
# '天⽂', 'type': '恒星'}]
# [L2距离得分=0.463] ⼈类是地球上最具智慧的⽣物,属于灵⻓⽬⼈科。现代⼈类(智⼈)拥有⾼
# 度发达的⼤脑,创造了语⾔、⼯具和⽂明。⼈类的平均寿命约70-80年,分布在全球各地。
# [{'type': '灵⻓类', 'source': '⽣物'}]
# [L2距离得分=0.488] 新冠病毒(SARS-CoV-2)是⼀种可引起呼吸道疾病的冠状病毒。它通过⻜沫
# 传播,主要症状包括发热、咳嗽、乏⼒。疫苗和戴口罩是有效的预防措施。 [{'source': '医学',
# 'type': '病毒'}]
⑤ 通过余弦相似度分数进行搜索(_similarity_search_with_relevance_scores)
说明:分数值越接近1(上限),检索到的文档越和问题相似。
docs = db._similarity_search_with_relevance_scores(
"量子力学是什么?"
)
for doc, score in docs:
print(f"* [余弦相似度得分={score:.3f}] {doc.page_content} [{doc.metadata}]")
# * [余弦相似度得分=0.871] 量子力学是研究微观粒子运动规律的物理学分支。它提出了波粒二象性、测不
# 准原理等概念,彻底改变了人类对物质世界的认知。量子计算机正是基于这一理论发展而来。 [{'type':
# '科学', 'source': '物理'}]
# * [余弦相似度得分=0.684] 太阳是太阳系的中心恒星,直径约139万公里,主要由氢和氦组成。它通过核
# 聚变反应产生能量,为地球提供光和热。太阳活动周期约为11年,会影响地球气候。 [{'source': '天文',
# 'type': '恒星'}]
# * [余弦相似度得分=0.672] 人类是地球上最具智慧的生物,属于灵长目人科。现代人类(智人)拥有高度
# 发达的大脑,创造了语言、工具和文明。人类的平均寿命约70-80年,分布在全球各地。 [{'source': '生
# 物', 'type': '灵长类'}]
# * [余弦相似度得分=0.655] 新冠病毒(SARS-CoV-2)是一种可引起呼吸道疾病的冠状病毒。它通过飞沫
# 传播,主要症状包括发热、咳嗽、乏力。疫苗和戴口罩是有效的预防措施。 [{'source': '医学', 'type': '病
# 毒'}]
⑥ MMR(最大边际相关性,max_marginal_relevance_search)
MMR 是一种平衡 相关性 和 多样性 的检索策略,避免返回高度相似的冗余结果。
docs = db.max_marginal_relevance_search(
query="量子力学是什么",
lambda_mult=0.8, # 侧重相似性
)
参数说明: lambda_mult 参数值介于 0 到 1 之间,用于确定结果之间的多样性程度,其中 0 对应最大多样性,1 对应最小多样性。默认值为 0.5。
Agent+RAG的结合代码示例
import os
import dotenv
from langchain import hub
from langchain.agents import create_tool_calling_agent, AgentExecutor
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.tools import TavilySearchResults
from langchain_community.vectorstores import FAISS
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.runnables import RunnableWithMessageHistory
from langchain_core.tools import create_retriever_tool
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain_text_splitters import RecursiveCharacterTextSplitter
dotenv.load_dotenv()
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY")
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL")
os.environ["TAVILY_API_KEY"] = os.getenv("TAVILY_API_KEY")
embedding_model = OpenAIEmbeddings(model="text-embedding-ada-002")
#工具一: 查询 Tavily 搜索 API
search = TavilySearchResults(max_results=1)
#工具二:百度百科搜索猫 RAG
loader = WebBaseLoader("https://baike.baidu.com/item/猫/22261")
docs = loader.load()
splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200
)
documents = splitter.split_documents(docs)
vector = FAISS.from_documents(documents, embedding_model)
retriever = vector.as_retriever()
retriever_tool = create_retriever_tool(
retriever=retriever,
name="baidu_search_cat",
description="搜索百度百科的猫",
)
###########创建工具集
tools = [search, retriever_tool]
###########获取大模型
model = ChatOpenAI(model="gpt-4o")
###########获取prompt
prompt = hub.pull("hwchase17/openai-functions-agent")
###########创建Agent对象
agent = create_tool_calling_agent(model, tools, prompt)
###########创建AgentExecutor对象
agent_executor = AgentExecutor(agent=agent, tools=tools,verbose=True)
###########添加记忆
# 调取指定session_id对应的memory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
agent_with_chat_history = RunnableWithMessageHistory(
runnable=agent_executor,
get_session_history=get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
测试,sessionId为123
###########测试 session_id:123
response = agent_with_chat_history.invoke(
{"input": "Hi,我的名字是Cyber,上海今天天气怎么样?"},
config={"configurable": {"session_id": "123"}},
)
print(response)
response = agent_with_chat_history.invoke(
{"input": "我叫什么名字?"},
config={"configurable": {"session_id": "123"}},
)
print(response)
# 最后一次输出:
# {
# 'input': '我叫什么名字?',
# 'chat_history': [HumanMessage(content='Hi,我的名字是Cyber,上海今天天气怎么样?', additional_kwargs={}, response_metadata={}),
# AIMessage(content='你好,Cyber!据我查到的资料显示,截至2023年10月,上海的天气常见平均最高温度在18°C到25°C之间。不过,具体今天的天气气温或者降雨情况还需要更为精准的实时天气信息。你可以查看当地产生的最新天气报告以获得精确的信息。', additional_kwargs={}, response_metadata={})],
# 'output': '你刚才告诉我你的名字是Cyber。'
# }
测试,sessionId为456
###########测试 session_id:456
response = agent_with_chat_history.invoke(
{"input": "我叫什么名字?"},
config={"configurable": {"session_id": "456"}},
)
print(response)
# 最后一次输出:
# {
# 'input': '我叫什么名字?',
# 'chat_history': [],
# 'output': '对不起,我无法知道你的名字。你可以告诉我你的名字,或者让我知道还有什么我可以帮助你的。'
# }
更多推荐

 23
23 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)