
LangChain之Memory
在 LangChain 中,Memory(记忆) 是用于在多轮对话或连续任务中保存和管理上下文信息的核心组件。它解决了大模型 “无状态” 的问题 —— 默认情况下,模型无法记住前序对话内容,而 Memory 能将历史交互数据(如用户提问、模型回答)存储起来,供后续步骤调用,从而实现连贯的多轮对话或任务上下文依赖。例如,在聊天机器人场景中,用户说 “帮我推荐一本科幻小说”,模型推荐《三体》后,用户接
在 LangChain 中,Memory(记忆) 是用于在多轮对话或连续任务中保存和管理上下文信息的核心组件。它解决了大模型 “无状态” 的问题 —— 默认情况下,模型无法记住前序对话内容,而 Memory 能将历史交互数据(如用户提问、模型回答)存储起来,供后续步骤调用,从而实现连贯的多轮对话或任务上下文依赖。
例如,在聊天机器人场景中,用户说 “帮我推荐一本科幻小说”,模型推荐《三体》后,用户接着问 “它的作者是谁”——Memory 会保存 “推荐《三体》” 的历史,让模型知道 “它” 指《三体》,而非其他书籍。
ConversationBufferMemory(基础对话缓存)
特点:简单粗暴地存储所有历史对话消息(用户 + 模型),不做任何压缩或删减,适合短对话场景。
适用:对话轮次少、上下文简单的场景(如客服咨询、简单问答)。
支持两种返回格式(通过 return_messages 参数控制输出格式)
- return_messages=True 返回消息对象列表( List[BaseMessage]
- return_messages=False (默认) 返回拼接的 纯文本字符串
示例一:使用PromptTemplate
#获取大模型
llm = ChatOpenAI(model="gpt-4o")
template = """你可以与人类对话。
当前对话: {history}
人类问题: {question}
回复:
"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferMemory()
chain = LLMChain(llm=llm, prompt=prompt,memory=memory)
# 提问
res1 = chain.invoke({"question": "我的名字叫Tom"})
print(res1)
res = chain.invoke({"question": "我的名字是什么?"})
print(res)
# {
# 'question': '我的名字叫Tom',
# 'history': '',
# 'text': '你好,Tom!很高兴认识你,请问有什么我可以帮你的吗?'
# }
# {
# 'question': '我的名字是什么?',
# 'history':
# 'Human: 我的名字叫Tom\n'
# 'AI: 你好,Tom!很高兴认识你,请问有什么我可以帮你的吗?',
# 'text': '你的名字是Tom。'
# }
示例二:使用ChatPromptTemplate 和 return_messages
#获取大模型
llm = ChatOpenAI(model="gpt-4o")
prompt = ChatPromptTemplate.from_messages([
("system","你是一个与人类对话的机器人。"),
MessagesPlaceholder(variable_name='history'),
("human","问题:{question}")
])
memory = ConversationBufferMemory(return_messages=True)
chain = LLMChain(llm=llm, prompt=prompt, memory=memory)
res1 = chain.invoke({"question": "中国首都在哪里?"})
print(res1,end="\n\n")
res2 = chain.invoke({"question": "我刚刚问了什么"})
print(res2)
#
# {
# 'question': '中国首都在哪里?',
# 'history': [
# HumanMessage(content='中国首都在哪里?', additional_kwargs={}, response_metadata={}),
# AIMessage(content='中国的首都是**北京**。北京是中国的政治、文化、教育和国际交流中心,也是历史悠久的城市之一。', additional_kwargs={}, response_metadata={})
# ],
# 'text': '中国的首都是**北京**。北京是中国的政治、文化、教育和国际交流中心,也是历史悠久的城市之一。'
# }
#
# {
# 'question': '我刚刚问了什么',
# 'history': [
# HumanMessage(content='中国首都在哪里?', additional_kwargs={}, response_metadata={}),
# AIMessage(content='中国的首都是**北京**。北京是中国的政治、文化、教育和国际交流中心,也是历史悠久的城市之一。', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='我刚刚问了什么', additional_kwargs={}, response_metadata={}),
# AIMessage(content='你刚刚问的是:“中国首都在哪里?”', additional_kwargs={}, response_metadata={})
# ],
# 'text': '你刚刚问的是:“中国首都在哪里?”'
# }
二者对比:
ConversationBufferWindowMemory(窗口对话缓存)
特点:只保留最近 N 轮对话(窗口大小),丢弃更早的历史,避免提示过长(节省 Token)。
适用:对话轮次多、需要控制提示长度的场景(如多轮闲聊、复杂任务协作)。
支持两种返回格式(通过 return_messages 参数控制输出格式)
- return_messages=True 返回消息对象列表( List[BaseMessage]
- return_messages=False (默认) 返回拼接的 纯文本字符串
# 实例化ConversationBufferWindowMemory对象,设定窗口阈值
memory = ConversationBufferWindowMemory(k=1) #定义保留 “最近多少轮对话”(1 轮 = 1 次用户输入 + 1 次 AI 输出)
示例一:
#获取大模型
llm = ChatOpenAI(model="gpt-4o")
template = """你可以与人类对话,如果不知道就回复不知道。
当前对话: {history}
人类问题: {question}
回复:
"""
prompt = PromptTemplate.from_template(template)
memory = ConversationBufferWindowMemory(k=1)
chain = LLMChain(llm=llm, prompt=prompt,memory=memory)
res1 = chain.invoke({"question": "我的名字叫Tom"})
print(res1)
res2 = chain.invoke({"question": "我今年8岁了"})
print(res2)
res3 = chain.invoke({"question": "我的名字是什么?"})
print(res3)
# {
# 'question': '我的名字叫Tom',
# 'history': '',
# 'text': '你好,Tom!有什么我可以帮助你的吗?'
# }
# {
# 'question': '我今年8岁了',
# 'history': 'Human: 我的名字叫Tom\nAI: 你好,Tom!有什么我可以帮助你的吗?',
# 'text': '你好,Tom!8岁真是一个充满活力和好奇心的年龄!你有什么问题或者想聊的话题吗?'
# }
# {
# 'question': '我的名字是什么?',
# 'history': 'Human: 我今年8岁了\nAI: 你好,Tom!8岁真是一个充满活力和好奇心的年龄!你有什么问题或者想聊的话题吗?',
# 'text': '不知道。'
# }
ps:ConversationTokenBufferMemory是 LangChain 中一种基于 Token 数量控制 的对话记忆机制。如果 字符数量超出指定数目,它会切掉这个对话的早期部分,以保留与最近的交流相对应的字符数量。
ConversationSummaryMemory(对话摘要记忆)
特点:不存储完整历史对话,而是将历史消息压缩成一段 “摘要”(如 “用户喜欢跑步,每周 3 次,每次 5 公里”),大幅减少 Token 消耗。
适用:长对话场景(如咨询、访谈),需要保留核心信息但无需完整历史。
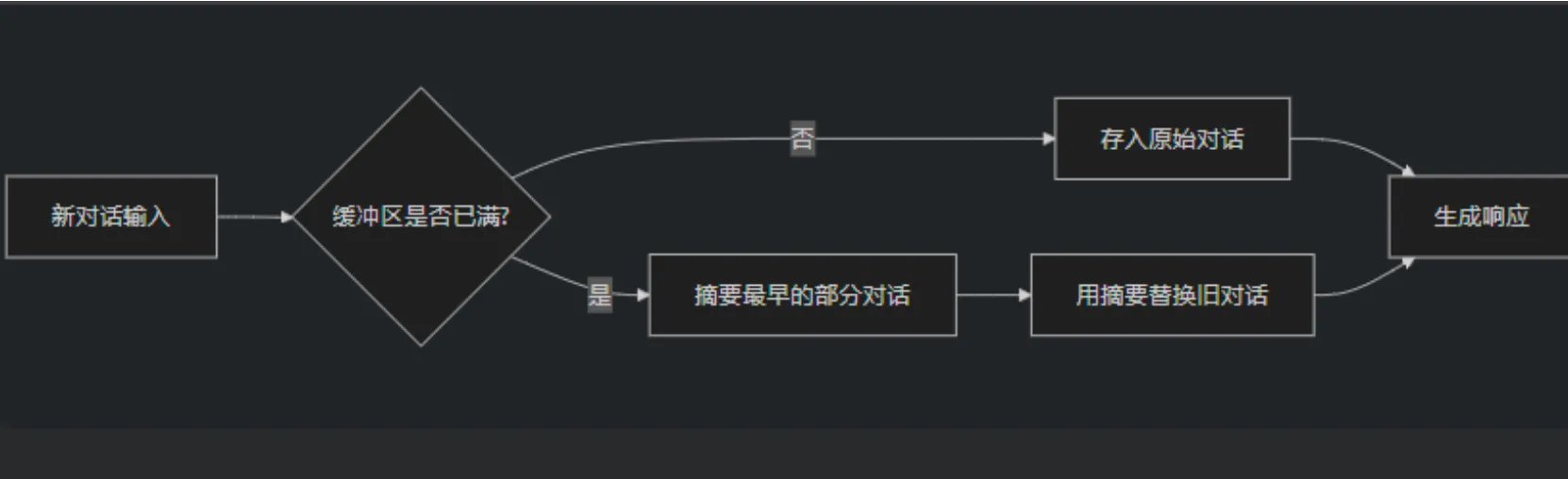
ConversationSummaryBufferMemory
ConversationSummaryBufferMemory 是 LangChain 中一种混合型记忆机制,结合ConversationBufferMemory(完整对话记录)和 ConversationSummaryMemory(摘要记忆)的优点,在保留最近 对话原始记录 的同时,对较早的对话内容进行 智能摘要 。
特点:
- 保留最近N条原始对话:确保最新交互的完整上下文
- 摘要较早历史:对超出缓冲区的旧对话进行压缩,避免信息过载
- 平衡细节与效率:既不会丢失关键细节,又能处理长对话
示例:
#获取大模型
llm = ChatOpenAI(model="gpt-4o",max_tokens=500)
prompt = ChatPromptTemplate.from_messages([
("system", "你是电商客服助手,用中文友好回复用户问题。保持专业但亲切的语气。"),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{input}")
])
memory = ConversationSummaryBufferMemory(
llm=llm,
max_token_limit=400,
memory_key="chat_history",
return_messages=True
)
chain = LLMChain(
llm=llm,
prompt=prompt,
memory=memory,
)
dialogue = [
"你好,我想查询订单12345的状态",
"这个订单是上周五下的",
"我现在急着用,能加急处理吗",
"等等,我可能记错订单号了,应该是12346",
"对了,你们退货政策是怎样的"
]
for user_input in dialogue:
response = chain.invoke({"input": user_input})
print(f"用户: {user_input}")
print(f"客服: {response['text']}\n")
print("\n=== 当前记忆内容 ===")
print(memory.load_memory_variables({}))
# {
# 'chat_history':
# [
# SystemMessage(content='The human greets in Chinese and inquires about the status of order 12345, which was placed last Friday. The AI responds politely, asking for more detailed order information, including the purchased item and delivery method, to provide a more accurate status update. It suggests checking the order\'s status through the official website or app using the "Order Tracking" feature. The AI also offers further assistance if needed. The human expresses urgency in needing the order, and the AI acknowledges this, offering to expedite the process if possible. It explains that if the item hasn\'t shipped, they might be able to arrange an urgent processing, but confirmation depends on the current order status. The AI reassures the human that they will contact the relevant department to check the possibility of prioritizing the order and coordinate for faster delivery if needed.', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='等等,我可能记错订单号了,应该是12346', additional_kwargs={}, response_metadata={}),
# AIMessage(content='没关系,感谢您的补充!我现在为您确认订单号12346的状态。如果方便的话,请您稍作等待,我们需要查询系统中的记录。\n\n您也可以同时登录我们的官网或App,在“我的订单”页面查看最新的物流状态哦!如果确实需要加急处理,请随时告诉我,我会尽力帮助您安排! 😊\n\n期待您的回复,我们会尽快为您解决问题!', additional_kwargs={}, response_metadata={}),
# HumanMessage(content='对了,你们退货政策是怎样的', additional_kwargs={}, response_metadata={}),
# AIMessage(content='感谢您的询问!我们的退货政策非常灵活,具体规则会根据商品类别有所不同,但通常我们会遵循以下原则:\n\n1. **退货时间**:大多数商品支持7天无理由退货,但必须确保商品及包装完好,未拆封、不影响二次销售。\n \n2. **退货条件**:如果商品存在质量问题、发错货或运输损坏等情况,您可以随时提交退货申请,我们会负责退货运费并快速处理。\n\n3. **特殊情况**:部分商品,例如定制类、特殊食品类或易耗品,可能不支持无理由退货,但如果商品存在质量问题,我们仍会妥善处理。\n\n您可以通过官网或App进入“我的订单”,找到对应订单并提交退货申请。如果需要进一步帮助,随时告诉我,我会协助您处理! 😊', additional_kwargs={}, response_metadata={})
# ]
# }
注意看SystemMessage,很明显前三轮对话已经被摘要到SystemMessage中,后两轮对话原始对话被保存到memory中。
ConversationKGMemory(对话知识图谱记忆)
特点:将对话中的实体(如人物、事件、关系)提取成知识图谱(如 “小明 - 是 - 学生”“小明 - 喜欢 - Python”),结构化存储上下文,适合需要精准关联实体的场景。
适用:需要处理复杂实体关系的场景(如客户需求梳理、事件分析)。
ConversationKGMemory的工作流程可分为知识提取、图谱构建和知识复用三个阶段:
- 知识提取(从对话到三元组)
- 实体识别:从用户输入和 AI 回复中识别关键实体(人物、物品、概念等)
- 关系提取:识别实体间的语义关系(如 “拥有”“喜欢”“位于” 等)
- 三元组生成:将提取结果组织为(头实体, 关系, 尾实体)格式
例如,从对话 “我叫张三,住在北京,喜欢吃烤鸭” 中可提取:- (张三, 名字, 张三)
- (张三, 居住在, 北京)
- (张三, 喜欢, 烤鸭)
- 图谱构建(存储与更新)
- 使用图数据结构(如networkx的有向图或专业图数据库 Neo4j)存储三元组
- 每轮对话后自动更新图谱,新增或修改实体与关系
- 支持实体消歧(如区分 “苹果(水果)” 和 “苹果(公司)”)
- 知识复用(查询与推理)
- 对话时,将图谱中相关的实体关系转化为自然语言描述,注入提示词
- 支持通过实体关联进行推理(如已知 “张三住在北京” 和 “北京是中国首都”,可推出 “张三住在中国”)
示例:
# 导入必要的环境变量处理库
import os
import dotenv
# 加载.env文件中的环境变量(需确保项目根目录有.env文件,包含OPENAI_API_KEY和OPENAI_BASE_URL)
dotenv.load_dotenv()
# 从环境变量中获取OpenAI API密钥和基础URL,避免硬编码敏感信息
os.environ['OPENAI_API_KEY'] = os.getenv("OPENAI_API_KEY") # 读取API密钥
os.environ['OPENAI_BASE_URL'] = os.getenv("OPENAI_BASE_URL") # 读取API基础URL(如需使用代理或特定端点)
# 导入LangChain相关组件
from langchain.chains import ConversationChain
from langchain.prompts import PromptTemplate
from langchain.memory import ConversationKGMemory
from langchain_openai import ChatOpenAI
# 1. 初始化大模型(使用GPT-4o)
llm = ChatOpenAI(model="gpt-4o") # ChatOpenAI适用于聊天模型,如gpt-4o、gpt-3.5-turbo等
# 2. 初始化知识图谱记忆组件
memory = ConversationKGMemory(
llm=llm, # 传入语言模型,用于实体和关系提取
memory_key="knowledge_graph", # 在提示词中引用知识图谱的变量名
input_key="input" # 指定输入参数的键名,需与后续调用时的参数名一致
)
# 3. 定义用户输入(包含明确的实体和关系,便于提取)
user_input = "张三购买了一部iPhone 15,价格5999元"
# 4. 定义对话提示词模板
prompt = PromptTemplate(
input_variables=["knowledge_graph", "input"], # 需包含知识图谱和用户输入变量
template="""基于已知信息回答问题:
已知信息:{knowledge_graph} # 注入知识图谱中的实体关系
用户问:{input} # 注入当前用户输入
回答:"""
)
# 5. 初始化对话链(关联LLM、记忆和提示词)
conversation = ConversationChain(
llm=llm, # 语言模型
memory=memory, # 知识图谱记忆
prompt=prompt # 提示词模板
)
# 6. 执行对话(自动处理输入并更新记忆)
response = conversation.predict(input=user_input) # 传入用户输入,键名需与input_key一致
print("\n对话回答:", response)
# 7. 提取更新后的知识图谱内容(需传入最新输入以确保正确关联)
updated_kg = memory.load_memory_variables({"input": user_input})
print("\n更新后的知识图谱:")
print(updated_kg["knowledge_graph"]) # 输出提取的实体关系(如张三、iPhone 15、5999元之间的关联)
# 对话回答: 张三购买了一部iPhone 15,价格5999元。
# 更新后的知识图谱:
# On 张三: 张三 purchased iPhone 15.
# On iPhone 15: iPhone 15 costs 5999元.
Memory与LCEL
在 LangChain 中,Memory 与 LCEL 的结合存在 “非完全统一语法” 的情况:基础 LCEL 链(如 prompt | llm | parser)是纯管道串联,但 Memory 依赖 RunnableWithMessageHistory 这个 “包装器” 来管理上下文,无法像普通组件一样直接用 | 串联。
这是因为 Memory 的核心是 “状态管理”(需保存 / 读取历史上下文),而基础 LCEL 管道是 “无状态” 的(数据单向流转,不保留历史)。因此,带 Memory 的 Chain 需通过 RunnableWithMessageHistory 为无状态管道 “注入状态管理能力”,形成一种 “半统一” 的 LCEL 语法。
更多推荐

 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)