
懒懒笔记 | 课代表带你梳理【RAG 课程 17&18:企业级安全 + 多智能体协同,打造可控、智能的 RAG 系统】
相比个人项目,企业级 RAG 的系统搭建面临更严苛的挑战。样样都不能少。这节课我们从企业的出发,总结出企业级 RAG 的三大核心痛点,并用 LazyLLM 提供的机制逐个击破👇。
企业级 RAG,做 “可控” 的 RAG 系统!
相比个人项目,企业级 RAG 的系统搭建面临更严苛的挑战。权限管理、数据隔离、共享机制、信息安全样样都不能少。
这节课我们从企业的真实业务需求出发,总结出企业级 RAG 的三大核心痛点,并用 LazyLLM 提供的机制逐个击破👇
权限机制:从文件分组到权限注入,RAG 如何控 “谁能看”
在企业中,知识不是 “谁想看就能看” 的公共资源,而是必须具备访问边界、隔离机制与安全标签的内部资产。
这一节,我们重点讲解如何在 LazyLLM 中实现企业级权限管理能力,从 “部门隔离” 到 “精细化访问控制”,帮你搞定复杂组织下的 RAG 系统权限策略!
支持多部门独立知识运营
企业中的文档通常分布在多个部门、团队或项目中,常见挑战包括:
- 如何高频更新各部门文档,保持知识库同步?
- 同一份文档被多个部门使用,是否要重复上传?
- 如何避免跨部门访问,确保敏感内容不外泄?
LazyLLM 提供了灵活的文档管理服务,通过 UI 或 API 即可完成文档的增删改查、实时检索与多分组管理:
from lazyllm.tools import Document
docs = Document("path/to/docs", manager='ui') # 启用文档管理界面
Document(path, name='法务文档组', manager=docs.manager)
Document(path, name='产品文档组', manager=docs.manager)
docs.start()启动后将生成一个可视化界面,展示每个管理组的文档结构,支持在线上传、删除与修改。

权限细粒度控制:标签驱动 + 动态筛选
不同岗位、团队、项目成员的权限不一样,LazyLLM 提供了基于标签的权限控制机制,实现文档级访问控制:
上传文档时打标签(Metadata)
CUSTOM_DOC_FIELDS = {
"department": DocField(data_type=DataType.VARCHAR),
"permission_level": DocField(data_type=DataType.INT32, default_value=1)
}上传文档同时标记权限等级:
files = [('files', ('普通文档.pdf', io.BytesIO(...)),
('files', ('敏感文档.pdf', io.BytesIO(...))]
metadatas=[{"department": "法务一部", "permisssion_level": 1},
{"department": "法务一部", "permisssion_level": 2}]))📌 实现内容分类 + 安全等级绑定
检索时使用过滤条件(Filter)
nodes = retriever(query, filters={'department': ['法务一部'], "permission_level": [1,2]} )📌 同一知识库中可按需 “查自己能看的”,实现安全隔离。
后端统一鉴权机制
在生产部署中,推荐将权限管理逻辑全部交由后端集中控制,而非由算法侧处理:

- 用户登录态决定其 filter 权限范围
- 检索模块仅调用带有 filter 的接口,不处理权限判断
- 保障安全、避免绕过、便于审计
多知识源统一检索:一库多召回,跨库协作不冲突
除了权限控制,企业在知识共享方面也面临多样化需求:一方面,不同团队间常需共享算法资源以提升复用效率;另一方面,多个部门之间也存在知识库交叉使用的需求,支持多对多的知识复用关系。这些场景对灵活的共享机制提出了更高要求。
共享灵活性:支持多源知识与算法自由适配
在企业中,各部门业务领域不同,存在两种情况。即 “一算法对多知识库” 和 “多算法对一知识库” 两种需求,系统需同时支持以适配业务。
📈 以金融公司为例,风控与市场分析部门或共用文本解析和嵌入算法预处理数据,前者知识库含历史交易与客户信用记录,后者含市场动态与竞品情报,系统需支持算法在不同知识库复用。
☕ 以电商企业为例,推荐系统与搜索优化部门分别用协同过滤嵌入、词向量相似度排序算法处理同一用户行为数据集,系统需支持在同一知识库独立运行不同算法以生成针对性结果。
同一套算法在多个知识库中的应用场景已在前面权限的部分讨论过。 接下来,我们实现在同一知识库中,通过不同文档分组实现算法多样化的场景。
为同一知识库注册分组,并模拟上传两篇文档:
docs = Document(path, manager=True, embed=OnlineEmbeddingModule())
# 注册分组
Document(path, name='法务文档管理组', manager=docs.manager)
Document(path, name='产品文档管理组', manager=docs.manager)
# 模拟文档上传
docs.start()files = [('files', ('产品文档.txt', io.BytesIO("这是关于产品的信息。该文档由产品部编写。\n来自产品文档管理组".encode("utf-8")), 'text/plain'))]files = [('files', ('法务文档.txt', io.BytesIO("这是关于法律事务的说明。该文档由法务部整理。\n来自法务文档管理组".encode("utf-8")), 'text/plain'))]为同一知识库的不同文档组,分别定义不同的切分算法:
# 为 产品文档管理组 设置切分方式为按 段落 切分
doc1 = Document(path, name=‘产品文档管理组', manager=docs.manager)
doc1.create_node_group(name="block", transform=lambda s: s.split("\n") if s else '')
retriever1 = Retriever([doc1], group_name="block", similarity="cosine", topk=3)
# 为 法务文档管理组 设置切分方式为按 句子 切分
doc2 = Document(path, name=‘法务文档管理组’, manager=docs.manager)
doc2.create_node_group(name=“line”, transform=lambda s: s.split(“。") if s else ‘’)
retriever2 = Retriever([doc2], group_name="line", similarity="cosine", topk=3)召回解耦:支持知识库与召回服务灵活协同
为应对复杂的知识共享与复用需求,企业越来越需要灵活而高效的知识组织结构与管理能力:
- 需要多对多的知识组织结构
- 需要多业务场景的知识复用能力
为满足上述需求,LazyLLM 不仅提供灵活的文档管理模块,还将文档管理与 RAG 召回服务进行完全解耦,来满足企业知识管理和召回需求的多样性,这样做的好处具体体现在:
- 多对多管理模式:一个文档管理服务可以同时管理多个知识库,支持不同业务部门的知识存储需求。
- 多 RAG 适配:同一个知识库可以适用于多个 RAG 召回服务,一个 RAG 召回服务可以从多个知识库中检索数据。
得益于这种解耦设计,确保了企业能够在不同业务场景下,动态调整知识库和 RAG 召回服务的绑定关系,满足个性化的知识管理需求。
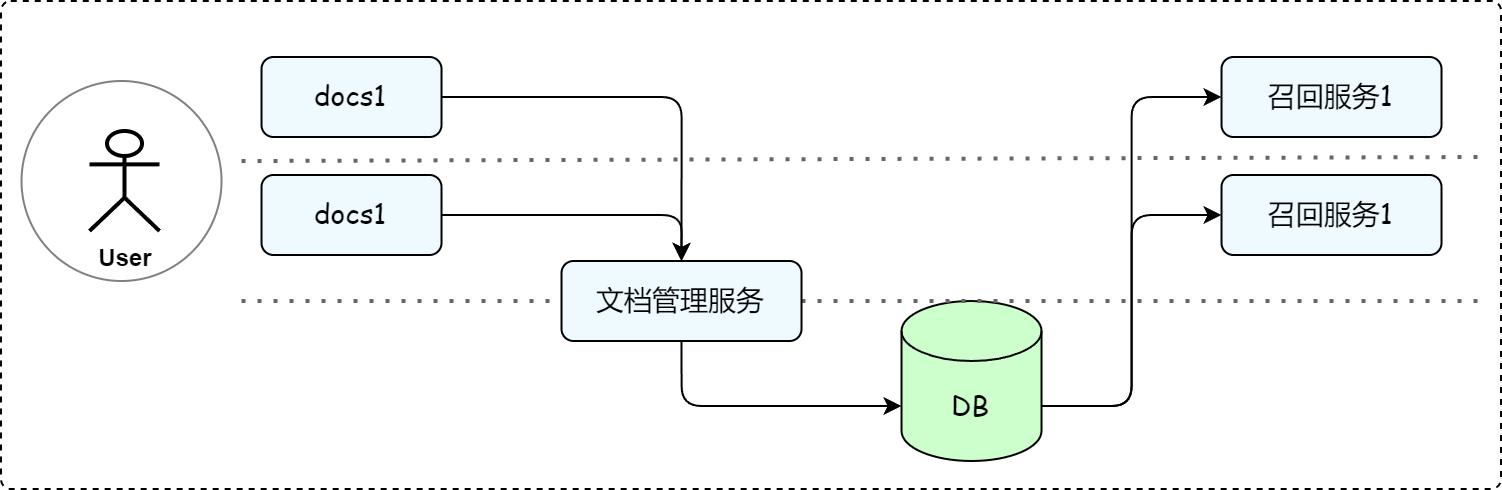
具体实现起来,仅需以下两步骤,可搭建多知识库管理和召回流程。
步骤一:初始化知识库
from lazyllm.tools import Document
from lazyllm import OnlineEmbeddingModule
import time
# =============================
# 方法1.通过定义路径的方式
# =============================
law_data_path = "path/to/docs/law"
product_data_path = "path/to/docs/product"
support_data_path = "path/to/docs/support"
law_knowledge_base = Document(law_data_path, name='法务知识库',embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
product_knowledge_base = Document(product_data_path,name='产品知识库',embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
support_knowledge_base = Document(support_data_path,name='客户服务知识库',embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
# =============================
# 方法2.通过文档上传方式
# =============================
data_path = "path/to/docs"
law_knowledge_base = Document(data_path, name='法务知识库', manager="ui",embed=OnlineEmbeddingModule(source="glm", embed_model_name="embedding-2"))
# 通过法务知识库的 manager 共享管理器
product_knowledge_base = Document(
data_path,
name='产品知识库',
manager=law_knowledge_base.manager,
)
law_knowledge_base.start()步骤二:启用 RAG 召回服务
from lazyllm import Retriever,SentenceSplitter
# 配置和定义数据处理算法, 可根据业务需要自定义
Document.create_node_group(name="sentences", transform=SentenceSplitter, chunk_size=1024, chunk_overlap=100)
# 组合法务 + 产品知识库,处理与产品相关的法律问题
retriever_product = Retriever(
[law_knowledge_base, product_knowledge_base],
group_name="sentences", # 分组名(根据业务需求选择)
similarity="cosine", # 相似度参数(根据模型配置)
topk=2 # 召回前2个最相关的结果
)
product_question = "A产品功能参数和产品合规性声明"
product_res_nodes = retriever_product(product_question)
# 组合法务 + 客户知识库,处理客户支持相关问题
retriever_support = Retriever(
[law_knowledge_base, support_knowledge_base],
group_name="sentences",
similarity="cosine",
topk=2
)
support_question = "客户投诉的处理方式以及会导致的法律问题"
support_res_nodes = retriever_support(support_question)只需两步,快速搭建支持多知识源联合召回的高可用系统。
对话管理:支持历史记忆 × 多用户并发
一个真正实用的 RAG 系统,不只是 “你问我答”,而是能记得住你说过的话、分得清谁在对话、回得上用户的速度。
LazyLLM 提供了强大的 对话管理机制,覆盖从上下文记忆到多用户隔离的全流程。
历史对话管理:让助手 “懂上下文”
在用户提出 “那苹果呢?” 时,系统能自动联想上轮 “香蕉的英文是什么?” 并回复 “apple” 而不是困惑地问 “你说什么苹果?”
这背后的关键,是通过 globals 全局上下文管理器,实现每个用户的独立历史记录维护:
from lazyllm import globals
# 初始化历史记录
def init_session_config(session_id, user_history):
globals._init_sid(session_id)
globals["global_parameters"]["history"] = user_history or DEFAULT_FEW_SHOTS系统支持:
- ✅ few-shot 示例初始化对话风格
- ✅ 自动记录历史问答并更新
- ✅ 支持上下文汇总、改写等复合任务
📸 示例:
用户1:香蕉的英文?
助手:banana
用户1:那苹果呢?
助手:apple ✅(准确关联历史)
用户2:机器学习是什么?
助手:...(定义)
用户2:它有什么用?
助手:...(回答应用) ✅多用户隔离:50 路并发也不乱
在企业应用中,系统必须支持多个用户同时提问、独立上下文、不卡顿不串线。
LazyLLM 通过线程池 + slot 管理机制,实现:
- 每个会话绑定一个独立 session_id
- 会话上下文
globals自动隔离 - 使用
@with_session装饰器确保上下文正确切换
@with_session
def handle_request(session_id: str, user_input: str):
chat = SessionResponder()
for chunk in chat.respond_stream(session_id, user_input):
print(chunk, end='', flush=True)✔️ 多用户并发对话,历史不混、响应实时,体验如微信聊天般流畅自然。
更多推荐
 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)