
自然语言概述
本文概述了自然语言处理中的关键技术与模型发展。首先介绍了BPE、BBPE和WordPiece等分词算法,然后回顾了N-Gram等传统语言模型。随后详细分析了RNN、LSTM和GRU等循环神经网络的结构与优化,包括LSTM的输入门、遗忘门和输出门机制。接着讨论了BERT和GPT系列模型的演进,从GPT-1到GPT-3的规模扩展,以及InstructGPT引入的RLHF方法。最后简要提及了当前大语言模
自然语言概述
文章目录
Preliminaries
Tokenizer
参考:
BPE
BPE每一步都将最常见的一对相邻数据单位替换为该数据中没有出现过的一个新单位,反复迭代直到满足停止条件。
BBPE
BBPE算法在基于字节(Byte)进行合并过程和BPE一致、也是选取出现频数最高的字符对进行合并。
WordPiece
WordPiece的流程和BPE几乎一样,也是每次词表中选出两个Subword合并成新的Subword,不同点在于WordPiece基于语言模型似然概率的最大值生成新的Subword而不是BPE根据最高频字节对。
相关工作
马尔可夫
N-Gram
N-Gram是指一种简单有效的语言模型,基于独立输入假设:第 n 个词的出现只与前面 N-1 个词相关,而与其它任何词都不相关。整句出现的概率就是各个词出现概率的乘积。
具体来说,N-Gram模型是一种统计语言模型,它通过考虑文本中连续的n个词(或字符)的组合来预测下一个词(或字符)。这里的n可以是1、2、3等,分别对应Unigram(一元模型)、Bigram(二元模型)和Trigram(三元模型)等。例如,Bigram考虑的是当前词和前一个词的组合,而Trigram则考虑当前词和前两个词的组合。
N-Gram模型的核心思想是基于马尔科夫假设,即一个词的出现概率只依赖于它前面的几个词,这样可以大大简化计算。通过统计训练数据中各个N-Gram的出现频率,可以为每个N-Gram分配一个概率值,进而用于预测文本的生成或填补缺失的词。
RNN
参考:
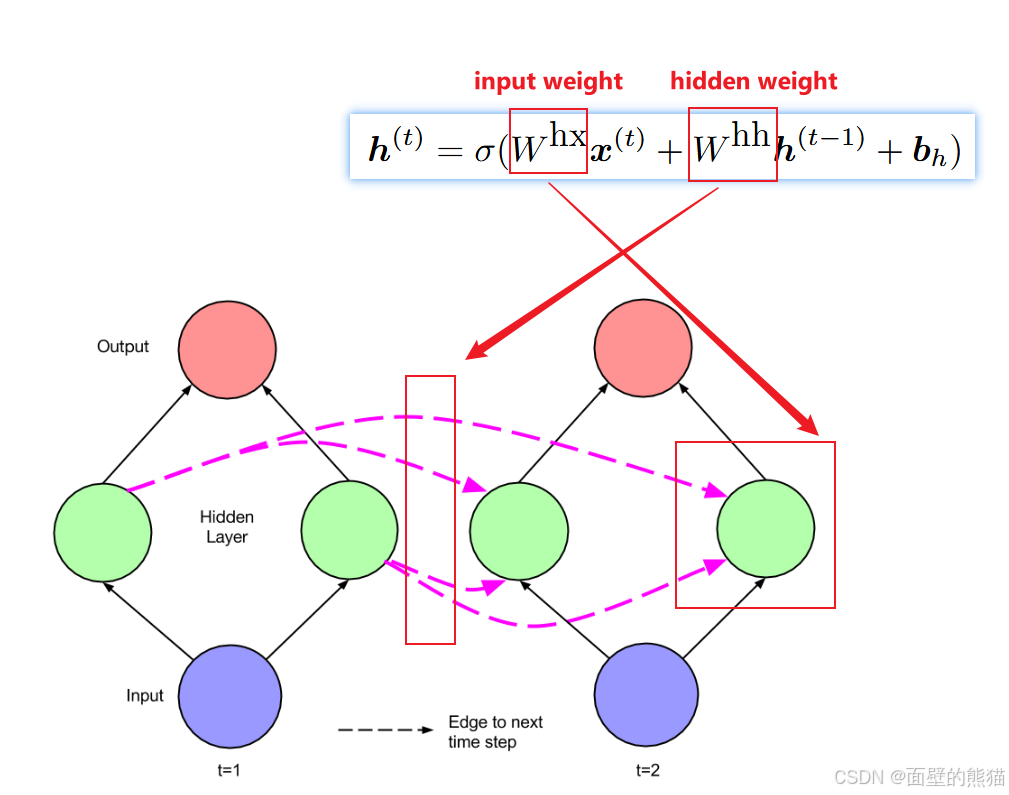
RNN也存在很多问题:
- 梯度消失或梯度爆炸
- 短期记忆
LSTM
参考:
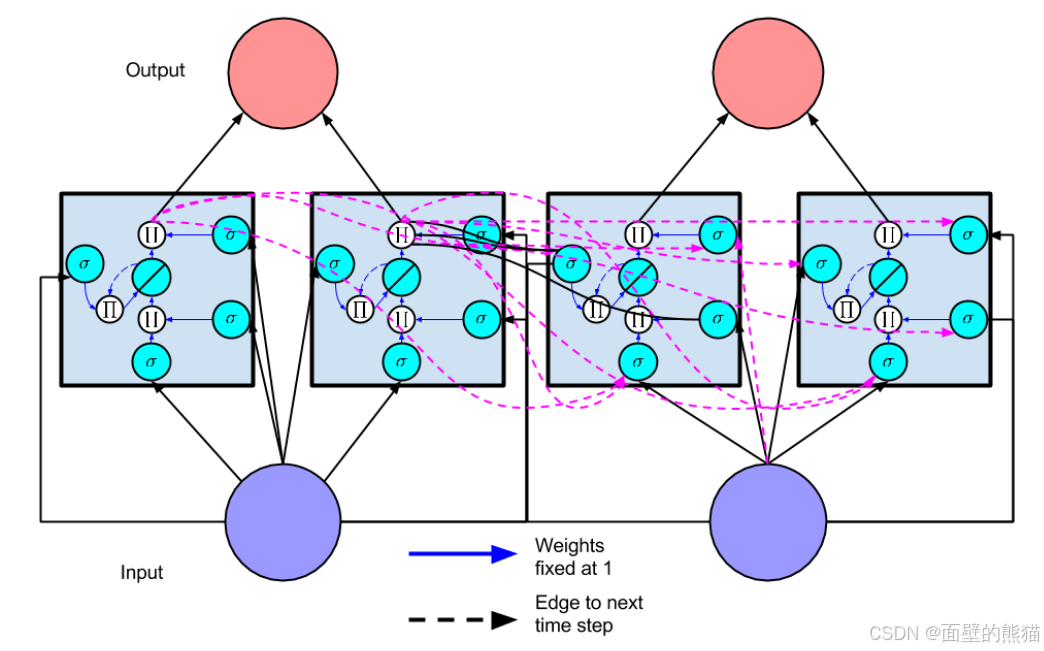
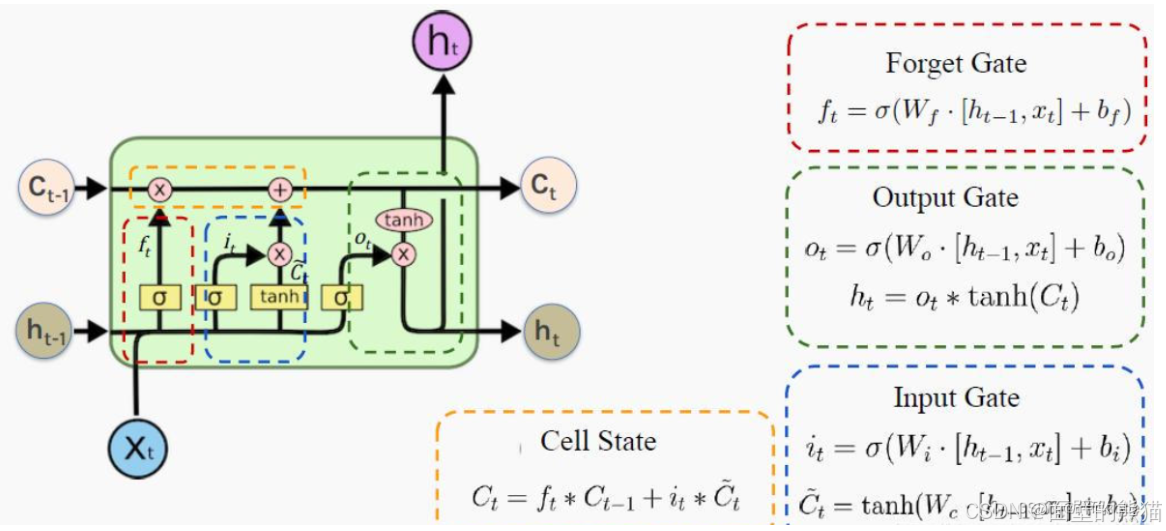
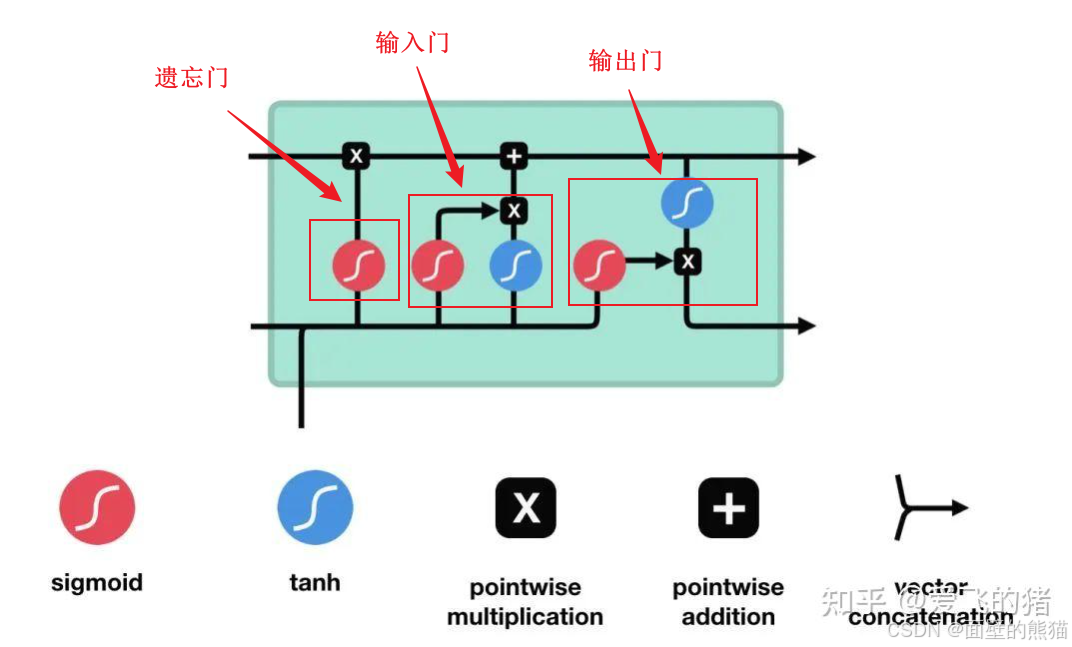
引入乘法输入门单元以保护存储在j中的记忆内容免受不相关输入(输入门作用)的扰动,并引入乘法输出门单元以保护其他单元(输出门作用)免受当前存储在j中的不相关记忆内容的扰动。
输入门:
- 作用:决定哪些新信息应该被添加到记忆单元中。
- 组成:输入门由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些信息是重要的,而tanh函数则生成新的候选信息。
遗忘门:
- 作用:决定哪些旧信息应该从记忆单元中遗忘或移除。
- 组成:遗忘门仅由一个sigmoid激活函数组成。
输出门:
- 作用:决定记忆单元中的哪些信息应该被输出到当前时间步的隐藏状态中。
- 组成:输出门同样由一个sigmoid激活函数和一个tanh激活函数组成。sigmoid函数决定哪些信息应该被输出,而tanh函数则处理记忆单元的状态以准备输出。
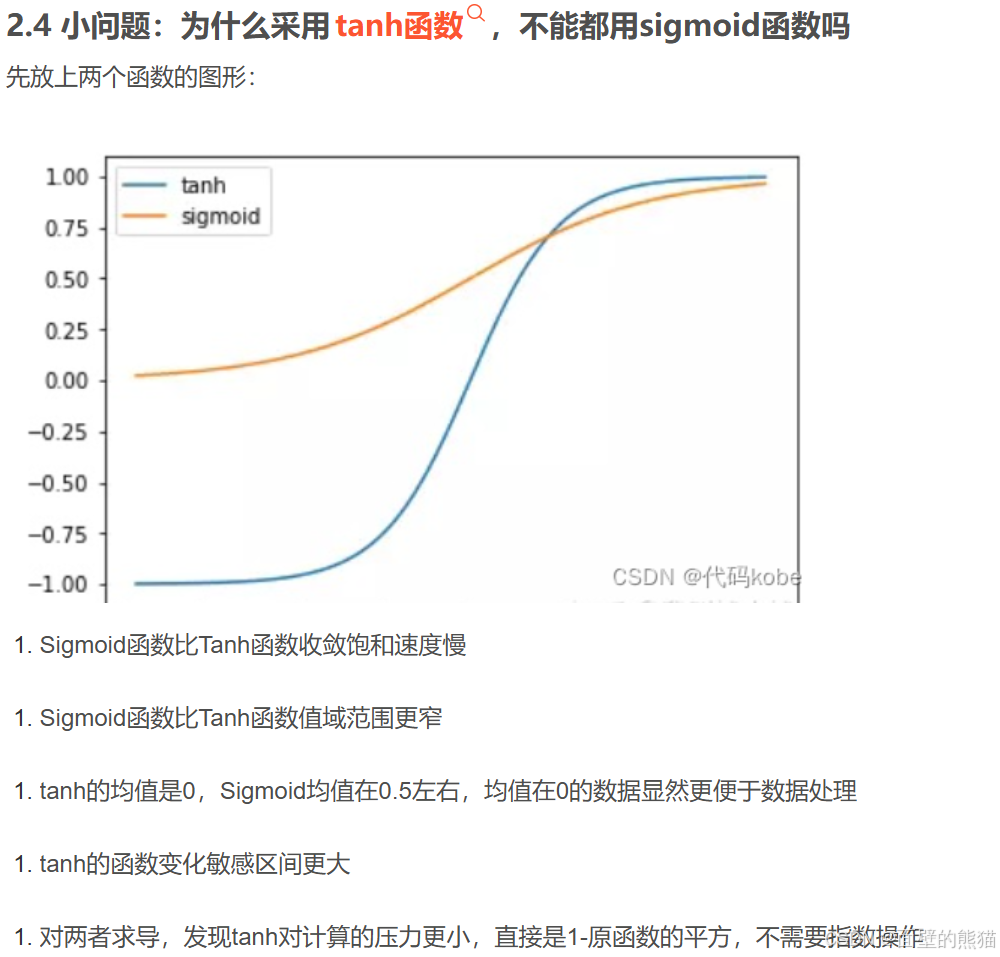
Q&A:
GRU
提出基于RNN的Encoder-Decoder结构来解决文本翻译任务,同时在LSTM上提出GRU提高训练效率和memory能力。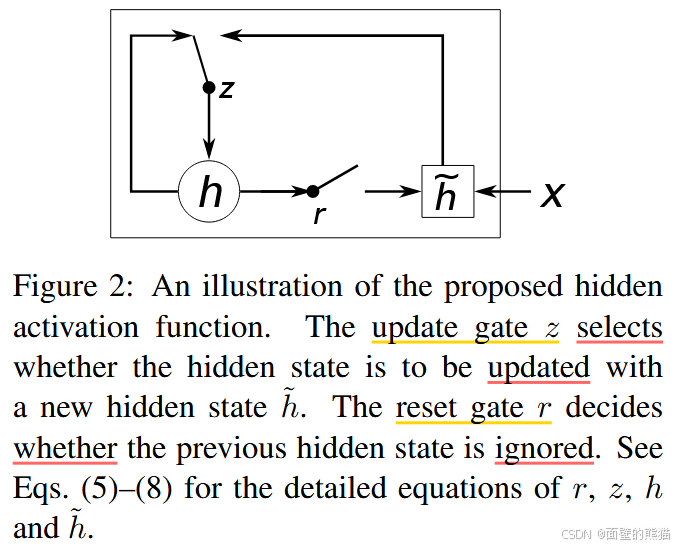
-
Encoder-Decoder结构
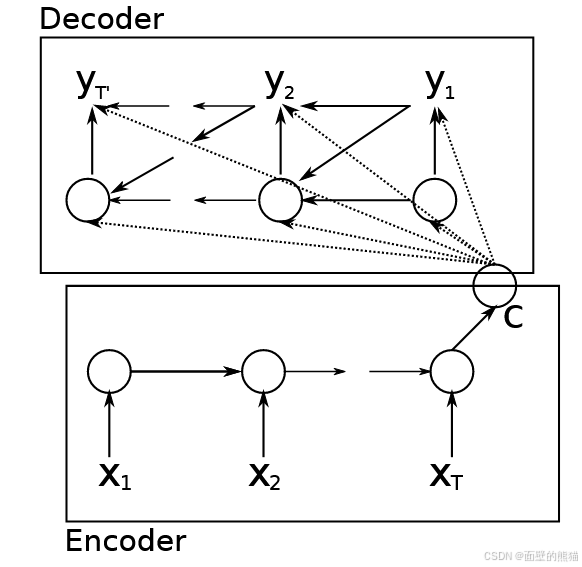
-
GRU
重置门 R j R_j Rj计算如下: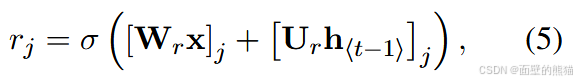
其中 σ 是逻辑 sigmoid函数, [ . ] j [.]_j [.]j 表示向量的第 j 个元素。x 和 h t − 1 h_{t−1} ht−1分别是输入和先前的隐藏状态。 W r W_r Wr 和 U r U_r Ur 是学习的权重矩阵。更新门 Z j Z_j Zj 由下式计算得到。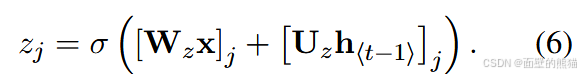
重置门有效地允许隐藏状态在以后删除任何发现不相关的信息,从而允许更紧凑的表示。更新门控制将有多少信息从以前的隐藏状态转移到当前隐藏状态。
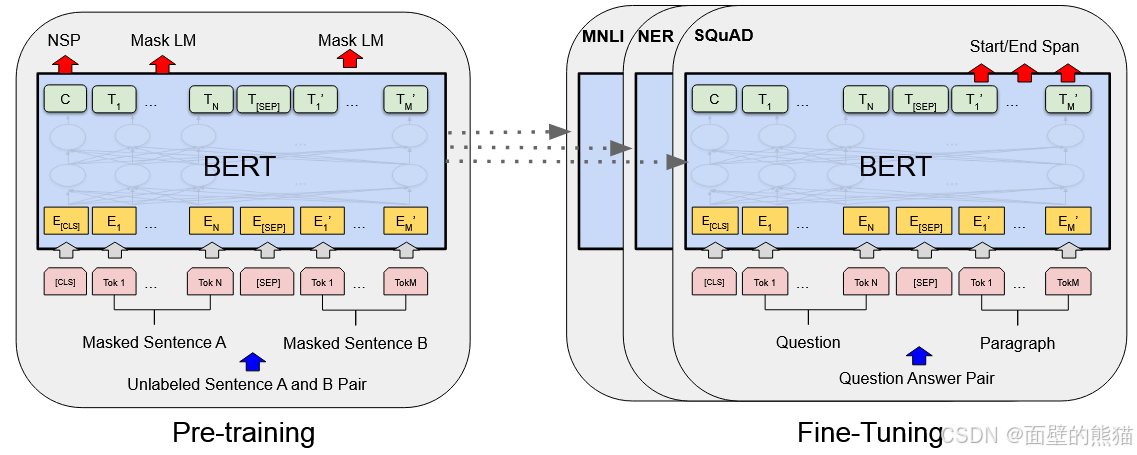
BERT
GPT系列
参考:
GPT1
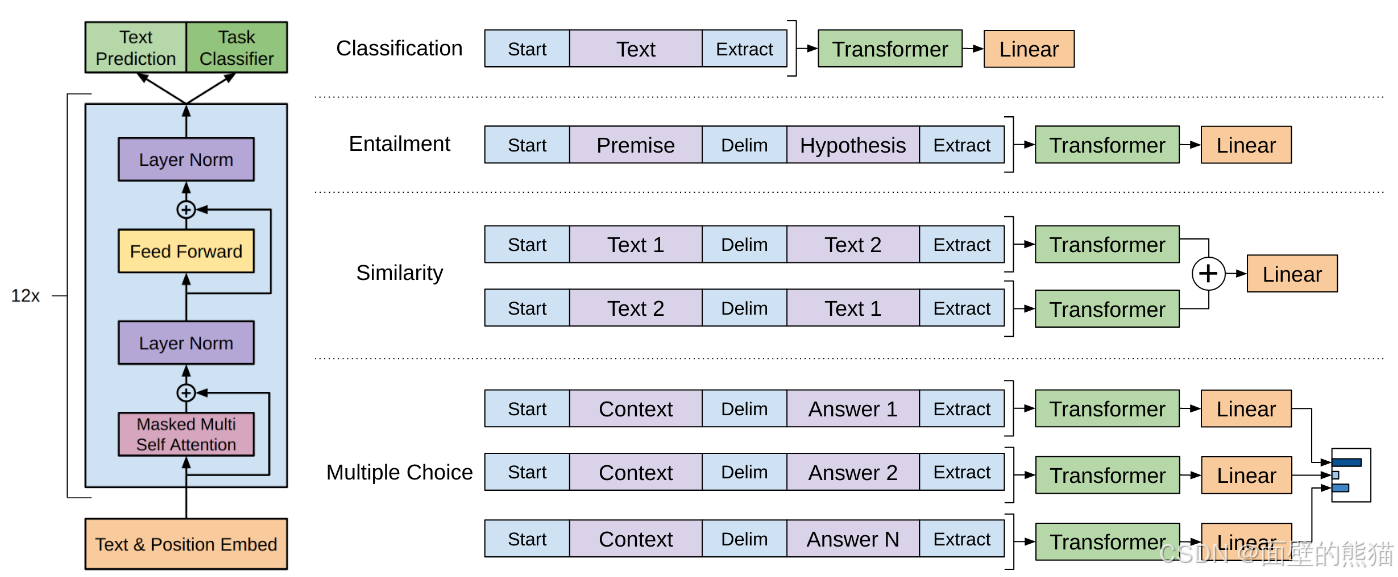
- 半监督训练范式:unsupervised pretraning + suprevised training
GPT2
与GPT-1模型不同之处在于,GPT-2模型使用了更大的模型规模和更多的数据进行预训练,同时增加了许多新的预训练任务。
GPT3
继续把模型扩大了百倍以上达到了惊人的1750亿的参数级别!并且继续探索了在不对下游任务进行适配(模型结构更改和参数更新)的情况下,模型的表现。
InstructGPT
InstructGPT使用来自人类反馈的强化学习方案RLHF(reinforcement learning from human feedback),通过对大语言模型进行微调,对齐人类偏好。
LLM
参考:
更多推荐
 7
7 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)