
AIGC 大模型实践总结
大模型代表一个新的技术 AI 时代的来临,大模型展现出的强大的语义理解,内容生成以及泛化能力正在逐渐改变我们的工作与生活方式(AI+)、工作方式和思维方式。AIGC 技术的核心优势是能够大大减轻人类创作者的负担,提高内容生产的效率和规模,同时也能够创造出全新的、创意性的作品。一个预训练模型,在处理下游任务时,不微调模型参数,只需要在输入时加一些示例,就能有 SOTA(state-of-the-ar

AI 时代
2022 年 11 月 30 号,OpenAI 推出 ChatGPT 后随即爆火,五天注册用户数过百万,2 个月用户破 1 亿,成为史上增长最快的消费者应用。随后各大厂也纷纷卷入 AIGC 领域,迎来国产 GPT 大模型发布潮以及 AI 创业公司成立潮。
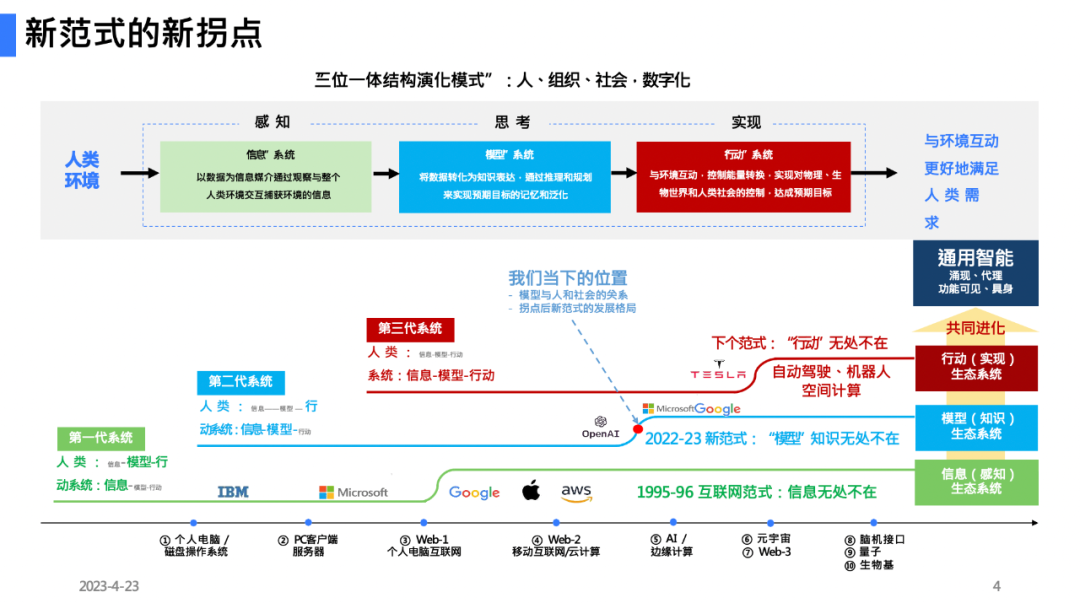
大模型代表一个新的技术 AI 时代的来临,大模型展现出的强大的语义理解,内容生成以及泛化能力正在逐渐改变我们的工作与生活方式(AI+)、工作方式和思维方式。正如《陆奇的大模型观》所讲,当前我们正迎来新范式的新拐点,从信息系统到模型系统过渡,"模型" 知识无处不在。人工智能的浪潮正在引领新的技术革命,或许可称为第五次工业革命。
2024 年 2 月 16 日,OpenAI 正式发布文生视频模型 Sora 引发全球关注。Sora 可以根据用户的文本提示快速制作长达一分钟的逼真视频,这些视频可以呈现具有多个角色、特定类型的动作、主题和背景等准确细节的复杂场景。而像 Pika 等其他主流的视频生成模型大多只能维持 5s 左右的动作和画面一致性,而 Sora 可在长达 17s 的视频中保持动作和画面的一致性。
优势:60s 超长时间、运动镜头下内容一致性、现实场景真实感。
2024 年 3 月 13 日,明星机器人创业公司 Figure,发布了全新 OpenAI 大模型加持的机器人 demo。视频中 Figure demo 机器人展示与人类的对话,没有任何远程操作。机器人的速度有了显著的提升,开始接近人类的速度。引起对机器人的发展速度感到震惊,我们似乎正处在这场汹涌的进化浪潮中。甚至有人感叹,已经准备好迎接更多的机器人了。

大模型基础知识
AI、AIGC、AGI、ChatGPT 的基本概念在人工智能的领域里面,以上四个词是四个不同的概念。
▐ AI (人工智能):artifical intelligence
人工智能(AI)是最广泛的概念,泛指通过机器模拟和执行人类的智能功能的技术。指的是由人制造出来的系统或软件,这些系统或软件能够执行通常需要人类智能才能完成的任务,如视觉感知、语音识别、决策制定和翻译等。泛 AI 概念包括的内容很大,包括狭义和广义定义的 AI。
狭义的 AI 即弱人工智能,指可以执行特定任务的智能系统,只能在特定的场景和范围内体现智能行为。比如语音识别、图片识别、智能驾驶;
广义的 AI 即强人工智能,值得是具备和人类一样的智能水平和认知能力的系统。能够在复杂的环境下自主学习、推理、理解、适应,有更高级的智能表现。
▐ AGI (通用人工智能):artifical general intelligence
通用人工智能(AGI)是广义 AI 的一个子集,指能在各个领域和方面都能达到人类智能水平的系统,具备人类的多样性和灵活性。AGI 是 AI 研究的终极目标之一,AGI 能够跨领域执行多种任务,具备自我学习和适应的能力,可以进行各类的学习和推理任务,并且具备自我意识和通用智能。
▐ AIGC (人工智能生成内容):AI generated content
AIGC,全名 “AI generated content”,又称生成式 AI,意为人工智能生成内容,是利用 AI 技术自动创作出新的内容,这包括但不限于文字、图像、音乐、视频等。AIGC 技术的核心优势是能够大大减轻人类创作者的负担,提高内容生产的效率和规模,同时也能够创造出全新的、创意性的作品。
可以简单理解为,AIGC 的水位,介于弱 AI 与 AGI 之间,是 AGI 在特定领域(内容生成)的一个削弱型应用。AIGC 目前已经有很多广泛的应用,而相反,AGI 则处于研究阶段,且在实际落地过程中,肯定会面临严格的机器人伦理问题。
▐ LLM (大语言模型):large language model
大语言模型一般指在大规模的文本语料上训练,包含百亿甚至更多参数的语言模型。大语言模型采用的架构目前基本是基于 transformer 的架构。那么 LLM 近期爆火,在之前却没有很好的表现的一个很重要原因是,只有语言模型的规模达到一定量级的时候,某些能力才会出现。(称之为涌现能力)。代表性的包括:上下文学习、指令遵循、逐步推理等等。
-
如 Transformer 架构的 GPT-3、BERT、T5 等模型。这些模型通过在海量数据上进行训练,能够学习到丰富的语言和知识表示,并展现出强大的自然语言处理能力。
▐ ChatGPT:Chat Generative Pre-trained Transformer
ChatGPT 是 "Chat Generative Pre-trained Transformer” 的缩写,ChatGPT 是一种基于人工智能技术的聊天机器人,能够进行自然语言理解和生成,提供流畅且类人的对话体验。是史上增长最快的消费者应用,可以应用于各种场景,能用于问答、文本摘要生成、机器翻译、分类、代码生成和对话。

大模型架构
2017 年前,transformer 架构前的部分经典架构如下:
-
N 元文法(n-gram)
-
多层感知器(MLP)
-
卷积神经网络(CNN),常见于计算机视觉;
-
循环神经网络(RNN,Recurrent Neural Network),一个很强大的神经网络模型,能预测序列数据,比如文本、语音和时间序列。
▐ Transformer 架构
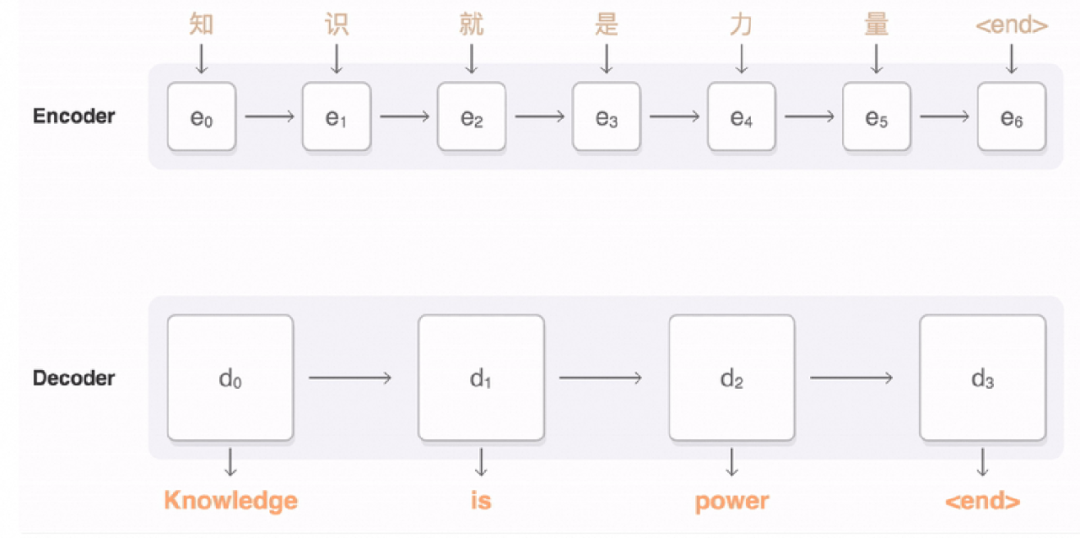
当下最火的当属 2017 年的 transformer 架构,Transformer 是目前最常见的语言模型的基本结构。transformer 架构涉及大量的概念和应用,比如编码 - 解码(encoder-decoder),注意力机制(attention),kqv(key、Querry、value)等。
Transformer 模型的核心架构可分为编码器和解码器。即编码器将输入序列编码成一个向量,而解码器则从该向量中生成输出序列。
简单的工作流程如下:
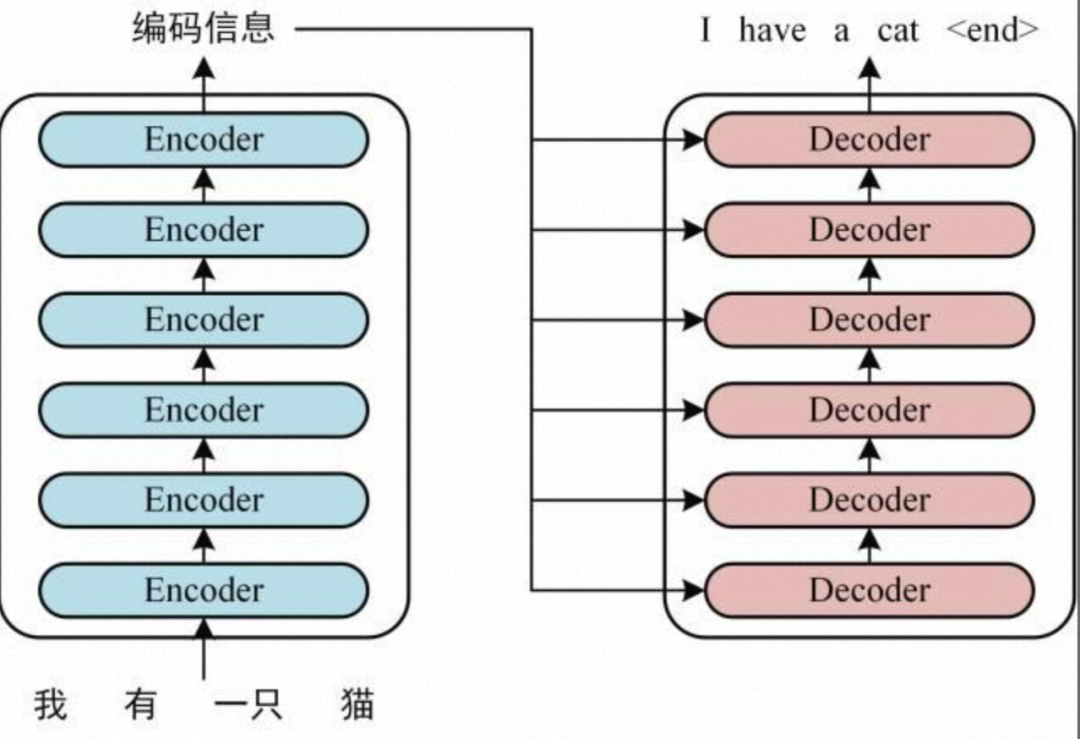
1、获取输入句子的每一个单词的表示向量 X,X 由单词的 Embedding(Embedding 就是从原始数据提取出来 Feature) 和单词位置的 Embedding 相加得到。
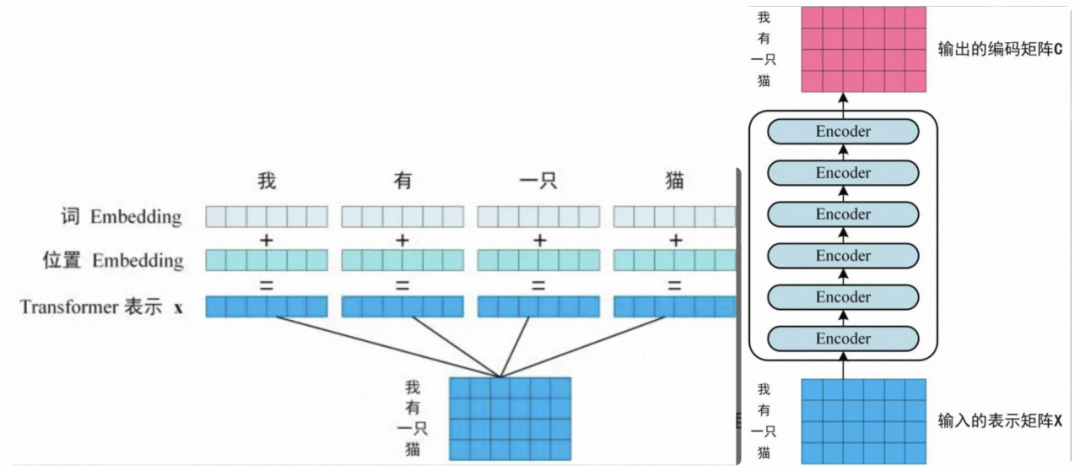
2、将得到的单词表示向量矩阵 (如上图所示,每一行是一个单词的表示 x) 传入 Encoder 中,经过 6 个 Encoder block 后可以得到句子所有单词的编码信息矩阵 C
3、将 Encoder 输出的编码信息矩阵 C 传递到 Decoder 中,Decoder 依次会根据当前翻译过的单词 1~ i 翻译下一个单词 i+1 。
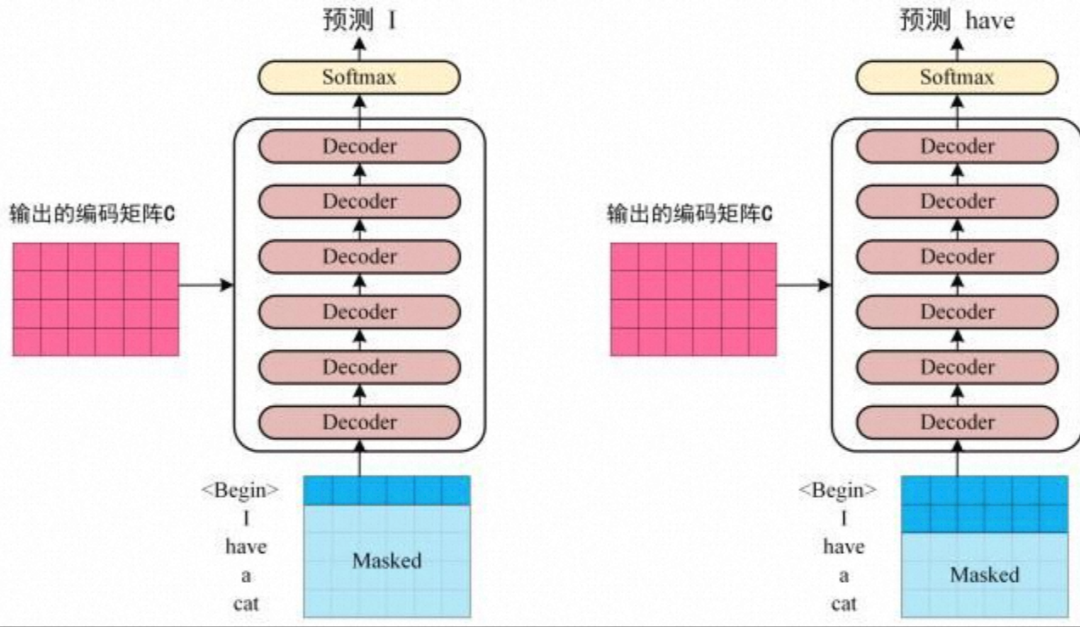
使用 ChatGPT 的时候会发现输出结果是一个字一个字蹦出来的,这是 Transformer 的结构导致的。
简单理解:可以将 Transformer 模型学习和预测的过程看成是语言翻译。如果模型是将 A 语言翻译成 B 语言,那么 Transformer 模型结构中的编码器是将输入的 A 语言翻译成模型语言,而解码器则是将模型语言翻译成 B 语言。
▐ 注意力机制
Transformer 模型之所以具备强大的功能,可以归功于模型中应用的注意力机制。何为注意力机制?对于一张图,我们并不会同等地查看图中的每个位置,而会自动提取 “重要的位置”。
Attention = 注意力,从两个不同的主体开始。(两个主体互相注意,我注意到他,他注意到我)
NLP 领域最开始用于翻译任务,天然是 source、target,D 翻译第一个词的时候,有个 attention 的机制关注到前面的所有词,但是权重不一样。简单理解:计算词之间的相近关系。
注:颜色粗细代表权重大小
以上图片可以解读为:一段自然语言内容,其自身就「暗含」很多内部关联信息。例如上面这句话,如果用 “自注意力” 机制,应该给与 “知识” 最多的注意力,因此可以认为:
一段自然语言中,其实暗含了:为了得到关于某方面信息 Q,可以通过关注某些信息 K,进而得到某些信息(V)作为结果。(Q 就是 query 检索 / 查询,K、V 分别是 key、value。所以类似于我们在图书检索系统里搜索「NLP 书籍」(这是 Q),得到了一本叫《自然语言处理实战》的电子书,书名就是 key,这本电子书就是 value。只是对于自然语言的理解,我们认为任何一段内容里,都自身暗含了很多潜在 Q-K-V 的关联。)【qkv 机制后续在图片领域也有大量的应用,可以熟悉一下这个机制】
关于 transformer 架构,还有很多的逻辑和知识,不做枚举。且后续大量的逻辑会基于向量和矩阵展开,不易理解。简单的罗列下为什么这个架构后面带来了大量的变革。即架构的优势:
-
快:比起 2017 年前的 rnn,transformer 并行性更好;
-
记忆力好:词间距缩短为 1,长文本的时候,可以有更多的容量;
-
处理不同长度的序列:不需要输入的数据序列是固定长度的。
▐ 上下文学习(In-Context Learning)
一个预训练模型,在处理下游任务时,不微调模型参数,只需要在输入时加一些示例,就能有 SOTA(state-of-the-art,即最优秀的模型) 的表现,这就是模型的上下文学习(In-Context Learning,ICL)能力。
-
ICL 能力的直接应用:Prompt Engineering
-
-
2022 期间很多学界人士的研究重点都转向了 Prompt。首先一般性地「Pretrain, Prompt」到了 Prompt 环节,可能是给模型输入 x 期望得到输出 y。但是如果我们对使用者给出的 x 进行二次加工(比如把这个加工表示为一个函数 f(x)),是否能在输出上获得更好的结果 y 呢?甚至可以优化输出的结构,得到更好的结果。
-
举个例子。比如模型的使用者想问「自驾去杭州周边两天一夜玩,有什么推荐的地方吗?」,模型返回了「南浔古镇」。而如果通过 Prompt Engineering 优化一下可以这样:

-
这样 f (x) 就是 Prompt Engineering,而 g (x) 其实是 Answer Engineering。
-
ICL 的数学原理和底层逻辑其实目前没有明确定论,也比较复杂。简单对 ICL 总结用于指导后续应用,包括:
-
在 prompt 里带上 demo 是很重要的,而且 demo 在形式上 input 和 label 都需要。
-
对于 demo 中的 input,不要乱来,要给出比较合理的 input。
-
对于 demo 中的 label,只要它属于正确的值域空间 label space 就可以了,是否与 input 有 correct mapping 不重要。
▐ Prompt Framework
更多推荐
 3
3 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)