
大模型论文研读 WHEN LLMS MEET CYBERSECURITY: A SYSTEMATICLITERATURE REVIEW(1)
这篇综述论文探讨了大模型(LLMs)在网络安全领域的应用,涵盖300+篇论文、25个模型和10个应用场景。文章主要研究三个问题:网络安全领域LLMs的构建、应用及面临的挑战。首先介绍了开源和闭源LLMs的特点,强调代码类LLM更适合安全任务。随后详细分析了LLMs在威胁情报、漏洞检测、恶意软件分析等10个安全场景的应用。论文还系统阐述了构建网络安全领域LLM的方法:从基础模型选择、评估指标(安全知
这篇文章讲述了大模型在网安领域的应用的综述,适合补充基础知识。(202401)
论文链接:https://arxiv.org/abs/2405.03644
文章包含了300+论文,25个模型,10个下游场景。
主要讨论三个问题:the construction of cybersecurity-oriented LLMs, the application of LLMs to various cybersecurity tasks, the challenges and further research in this area.
文章定期维护一个Github链接,其中包含了论文涉及到的多篇论文的相关Link,方便查阅:https://github.com/tmylla/Awesome-LLM4Cybersecurity![]() https://github.com/tmylla/Awesome-LLM4Cybersecurity
https://github.com/tmylla/Awesome-LLM4Cybersecurity
第二章
1、LLMs分为开源闭源两种,开源提供权重,可根据安全需求进行微调和定制化(如 Llama, Mixtral)。闭源如ChatGPT, Gemini,性能更前沿但不透明。
2、网络安全领域需要能理解、分析、生成 安全代码 的智能工具。所以比起文字类LLM,更需要代码类 LLM(如 CodeLlama, StarCoder):在大规模代码语料上专门训练,理解语法、语义和常见模式。能执行多种任务:代码补全、漏洞检测、自动化代码审查。在安全场景下可用于:识别潜在漏洞、推荐安全编码实践、修复漏洞。
3、LLMs可以应用于网络安全领域的各个方向
> Threat Intelligence: It is very difficult to extract information from a large number of threat intelligence documents. Some researchers turn to LLMs to organize and analyze these massive and cluttered data.
威胁情报:从大量威胁情报文档中提取信息非常困难。一些研究人员转向 LLM,用它们来组织和分析这些庞大而杂乱的数据。(CTI 提取、自动生成攻击知识图谱、辅助安全专家决策)
> Vulnerability Detection: This is a critical task in cybersecurity, and has seen novel approaches emerge through the integration of LLMs.
漏洞检测:网络安全中的关键任务(SQL 注入、缓冲区溢出、智能合约漏洞等,结合 prompt engineering / RAG)
> Malware Detection: LLMs can serve as both the static analysis assistant and the dynamic debugging assistant, improving the efficiency and effectiveness of the process.
恶意软件检测:LLM 可以同时作为静态分析助手和动态调试助手,从而提高这效率和有效性。
(静态分析 + 动态调试辅助,npm 恶意包检测、勒索软件分析)
> Anomaly Detection: It mainly refers to security anomalies such as malicious traffic in the flow, virus files in the system, anomalies in logs, etc.
异常检测:主要指各种安全异常,例如流量中的恶意流量、系统中的病毒文件、日志中的异常等。
> Fuzz: Traditional fuzzing techniques are effective in discovering software vulnerabilities, but their inherent limitations can affect their efficiency and effectiveness. The LLM-based approach for fuzzing is a promising area of research.
模糊测试:传统的模糊测试技术在发现软件漏洞方面是有效的,但其固有的局限性会影响效率和效果。基于 LLM 的模糊测试方法是一个很有前景的研究方向。(从随机变异到 LLM 引导式变异)
> Program Repair: Program repair is task-intensive and patching defects requires sufficient experience and knowledge. Many studies have proved the effectiveness of LLMs about this issue.
程序修复:程序修复任务强度高,而修补缺陷需要足够的经验和知识。许多研究已经证明了 LLM 在这一问题上的有效性。(自动补丁生成、辅助代码审计)
> LLM-Assisted Attacks: Many are not satisfied with LLMs’ positive applications. They have discovered the effectiveness of LLMs in launching network attacks such as phishing emails and penetration testing.
LLM 辅助攻击:很多人并不满足于 LLM 的积极应用。他们发现 LLM 在发起网络攻击(如钓鱼邮件、渗透测试)中同样有效。(CTF、钓鱼、payload 生成、自动渗透测试)
> (In)secure Code Generation: Is there a risk in the code generated by LLMs? Moreover, can LLMs correct their code through some strategies?
(不)安全代码生成:由 LLM 生成的代码是否存在风险?此外,LLM 是否能够通过某些策略纠正它们自己的代码?(评估 LLM 生成代码的漏洞风险,研究防御性代码生成)
> Others: In addition to the aspects mentioned above, we have also collected some researches which prove the importance of LLMs in the field of cybersecurity, there are fewer application studies of LLM in its field.
除了上述方面,我们还收集了一些研究,证明了 LLM 在网络安全领域的重要性。然而,关于 LLM 在该领域的应用研究仍然相对较少。(IoT/SoC/蜜罐/补丁检测等)
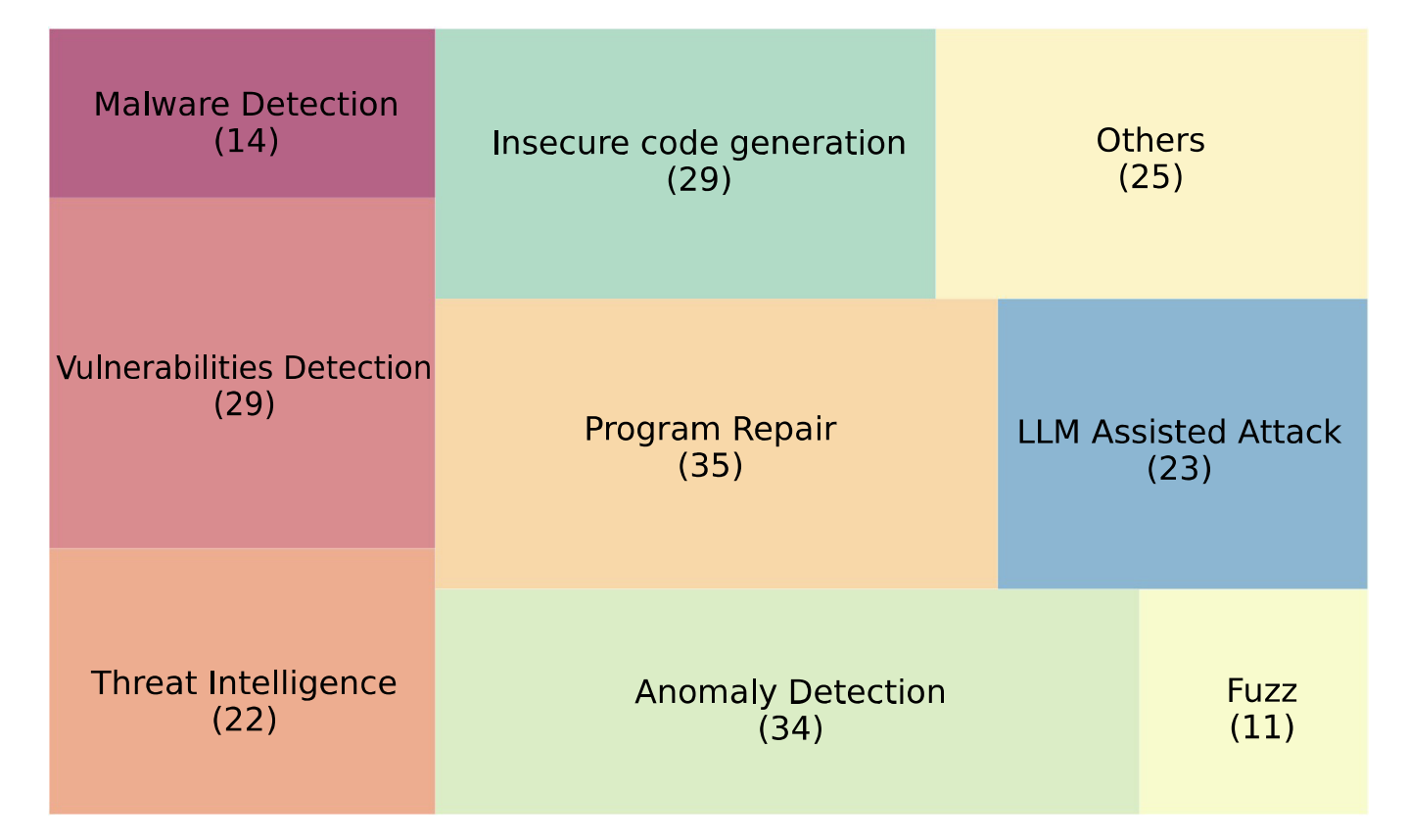 LLMs在网络安全领域应用的类别
LLMs在网络安全领域应用的类别
第三章 RQ1: How to construct cybersecurity-oriented domain LLMs?
如何建造面向网络安全领域的大模型?
1、选择基础模型(Selection of Base Model, §3.1)
挑选一个已有的通用 LLM 作为起点,然后再做微调。核心思想:选择 具备较强网络安全能力 或在 安全相关任务上表现较好的 LLM。现有评估体系把安全能力分为三类:
-
Cybersecurity knowledge(安全知识)
-
Secure code generation(安全代码生成)
-
IT operations capability(IT 运维能力)
Cybersecurity Knowledge 评测
-
关注 LLM 对网络安全知识的理解和推理能力。相关banchmarks:
-
CyberBench:一个通用化的测试框架,解决了传统评估中不一致的问题。
-
SecEval:包含 2000+ 道多选题,覆盖 9 大安全领域(软件安全、应用安全、系统安全、Web安全、密码学、内存安全、网络安全、权限提升等)。
-
CyberMetric:基准数据集,1000 道问题,主要测试知识问答。
-
SecQA:专门设计的安全问题集,难度分层,既能当作评测工具,也能促进 LLM 在安全场景的应用。
-
SECURE:6 个数据集,用于测试模型在真实工业控制系统场景下的知识抽取、理解与推理。
-
这一部分强调 评估 LLM 是否真正掌握网络安全基础知识和原则。
Secure Code Generation 评测
-
测试 LLM 生成代码的安全性,不仅看功能,还要看是否符合安全编码规范。涉及的基准与工作:CyberSecEval:检测 LLM 生成代码是否引入潜在风险。
-
LLMSecEval:基于 MITRE CWE(常见漏洞枚举),对 LLM 生成代码逐项对比,评估是否安全。
-
SecurityEval:基于 Stack Overflow 的真实代码场景,检测漏洞代码生成比例。PythonSecurityEval:测试 LLM 在 Python 代码中的安全漏洞修复能力。
-
DebugBench:大规模调试数据集(4253 个实例,18 类代码错误),用于测试 LLM 在调试中的表现。
-
EvilInstrucCoder:测试在攻击者诱导下 LLM 是否会生成有害/攻击性代码。Eyeball:评估漏洞检测能力,含 24,000+ 个漏洞样本,5000+ 个代码仓库。
-
这一部分强调 LLM 在代码生成、调试、修复、漏洞检测等任务中的安全性与鲁棒性。
IT Operations Capability
-
测试 LLM 在 IT 运维安全中的表现:安全事件管理、威胁情报分析、告警信息总结等。典型基准:
-
NetEval:5732 道与 IT 运维相关的选择题,覆盖 5 个子领域。
-
OpsEval:7184 道选择题 + 1736 道问答,测试运维场景中的告警总结、脚本生成、故障定位等。
-
NYU CTF Dataset 和 CybChen:测试 LLM 在 CTF(夺旗赛)中的表现,评估其解决实际攻击任务的能力。
进阶评估与研究方向
-
AttackER:基于 18 类攻击实体,研究 LLM 在攻击归因、溯源中的能力。
-
SevenLLM:提供一个框架,用来系统地基准测试 LLM 在安全响应中的表现。
结果表明,即使不微调,LLM 在网络安全中已经展现一定能力。但同时我们仍旧需要更多高质量的标准,才能更全面地检验LLMs能力,当前研究既能帮助发现 LLM 的优势,也能揭示其局限。
2、关键微调技术(Key Technologies to Fine-tuning, §3.2)
(1)持续预训练 (Continual Pre-training, CPT):
使用大量 未标注的领域数据 进行进一步训练。提升模型对领域知识的理解与泛化能力。即在原模型语义理解能力的基础上,继续让模型“读安全领域的书”。通常作为 fine-tuning 前的准备阶段;适合构建通用安全模型(如安全知识问答)。
典型步骤:选择能代表目标领域特征的数据集,确定持续训练策略;进行再预训练,调整模型结构和超参数,这一步一般是让模型执行与原始LLM相同的预训练任务,自我监督任务(语言模型目标-LM Objective-预测下一个 token。或者掩码语言模型目标-MLM-如 BERT-预测被掩盖的词。)
这里我用查询GPT-5了,他告知了几个运用这个思路的相关工作,没有验证他是否总结的正确,这里先留一个坑,后续如果做这个方面,再详细阅读写读书笔记。
-
CyberLLaMA (2023):以 LLaMA 为基础;使用安全论文 + CVE + CTF writeups + 安全博客继续预训练;训练目标:安全术语理解、漏洞溯源、代码推理;成果:在漏洞检测任务中提升 10–15%
-
SecGPT (2024):基于 GPT-Neo;使用安全威胁报告(APT、IoCs)语料;CPT 后再做 SFT;实现自动化威胁情报摘要
-
RepairLLaMA (ICSE 2024):先 CPT:用 GitHub 代码 + 漏洞修复 commit;再 SFT:对“漏洞 → 修复”指令数据微调;成果:修复成功率提升 20%
(2)监督式微调 (Supervised Fine-tuning, SFT)
使用 标注好的安全领域数据(labeled data) 进行训练。提升模型在特定任务(如漏洞检测、程序修复)上的性能。ChatGPT 就是一种典型的 “SFT + instruction tuning” 模式。
改善任务导向的学习模式。利用高质量的 指令 + 响应 (instruction-response) 数据集;通过任务特定的损失函数优化;
SFT 训练其实是一个经典的 语言建模目标(Causal LM):即最小化模型输出(response)与参考答案的交叉熵损失。“Causal” 在这里不是“因果关系”的意思,而是指:模型在预测第 t 个词时,只能看到它之前的词(不能偷看未来)。也就是:
-
模型输入:x₁, x₂, ..., xₜ₋₁
-
模型目标:预测 xₜ

举个小例子:假设模型要学习这样一句话——"The malware connects to a remote server."

(3)全参数微调 (Full-parameter fine-tuning)
在训练时更新 模型所有参数,可以让模型在特定任务上达到最优性能。但开销极大,不利于扩展和部署,对于学术团队而言代价太高,适合商业模型或大机构定制安全大模型时使用。
(4)参数高效微调 (Parameter-efficient fine-tuning, PEFT)
只更新模型中极少量参数(冻结绝大部分),从而显著减少计算成本。
-
Adapter Tuning:在注意力层之间插入小模块;
-
P-Tuning:自动学习 prompt 向量;
-
Prefix Tuning:添加可训练的前缀;
-
Prompt Tuning:微调提示词;
-
LoRA / QLoRA:用低秩矩阵近似参数更新,减少显存开销。
3. 微调后的领域模型(Fine-tuned Domain LLMs, §3.3)
(1)漏洞检测:识别并分类安全漏洞(如代码漏洞、合约漏洞)
-
WizardCoder:在 CodeLLaMA 上用 LoRA 微调,执行 Java 漏洞二分类;
-
FalconLLM + SecureFalcon:用全参数微调区分漏洞样本 vs 正常样本,检测准确率高达 96%,并能进一步修复;
-
LLMAO:提出“局部定位 + 双向编码”方法,用语言模型定位漏洞代码区;
-
DetectLlama:在 1.7 万个漏洞样本上微调 CodeLLaMA,在智能合约漏洞检测上超过 GPT-4
(2)安全代码生成:让 LLM 生成符合安全标准的代码,而非有漏洞的实现。
-
Vulnerability-Constrained Decoding:在训练中引入“漏洞标签”,强制模型规避潜在风险
-
Fine-tuning on GPT-J:使用标注数据集训练,显著减少生成漏洞代码的概率。
-
CodeLLaMA + SafeCoder:在安全/不安全代码对上监督微调,平均减少漏洞约 30
(3)程序修复:让模型自动修复含漏洞代码(无需人工干预)。
-
RepairLLaMA:在 CodeLLaMA 上进行 LoRA 微调,在 Java 缺陷数据集(Defects4J、HumanEval-Java)上表现优异,最终性能超过 GPT-4。
-
使用 “APR-INSTRUCTION” 指令数据,结合多种 PEFT方法对LLMs进行微调,提高模型自动修复能力。
(4)二进制分析:让 LLM 理解和分析二进制文件(无源代码情况下)
-
StarCoder / Nova / Nova+:在大规模二进制语料上进行持续预训练;
-
任务包括:代码相似性检测、二进制翻译、补丁恢复;
-
微调后模型在多项任务上超过传统静态分析工具。
(5)IT 运维:帮助安全运维人员自动化完成告警、日志分析、应急响应等任务。
-
Owl:专门用于 IT 运维的 LLM,在 Owl-Instruct 数据集上微调,能进行安全事件总结、日志异常检测,在 Owl-Bench 基准上优于通用 LLM。
(6)网络安全知识问答等:像 ChatGPT 那样,帮助用户理解、分析、应对攻击。
-
Hackmentor:在安全对话数据集上微调LLaMA / Vicuna;
-
CyberPal:基于 SecKnowledge 数据集(领域知识驱动)微调,建立一个能够回答和遵循复杂的安全相关指令的专门的安全LLM。
-
能理解并执行安全指令、回答安全问题、辅助溯源与防御。
Q1答案:对于研究人员来说,通过CPT、SFT等方法,利用网络安全数据对一般LLM进行微调,构建域LLM是可行的,实现技术取决于具体的应用场景、资源可用性和预期的性能提升水平。
更多推荐

 22
22 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)