
5分钟带你搞懂从0打造一个ChatGPT
换工作和业余时间ALL IN AI了。不管你是否承认,AI时代已经来了,依然埋头研究前端的那一亩三分地和源码在未来可能就是蒸汽时代被淘汰的纺织女工。今年大家多多少少都有接触到AI相关的项目了,从前端的角度来看以前是调用后端的接口,现在改成了调用大模型提供的接口,本质依然没变。但是按照大家卷的程度来看,在未来的不久不管你是前端还是后端,大模型底层原理将会是和源码一样成为面试中的热门话题。所以欧阳打算
前言
欧阳上一次写文章还是4个月前,之所以断更有两个原因:换工作和业余时间ALL IN AI了。不管你是否承认,AI时代已经来了,依然埋头研究前端的那一亩三分地和源码在未来可能就是蒸汽时代被淘汰的纺织女工。
今年大家多多少少都有接触到AI相关的项目了,从前端的角度来看以前是调用后端的接口,现在改成了调用大模型提供的接口,本质依然没变。但是按照大家卷的程度来看,在未来的不久不管你是前端还是后端,大模型底层原理将会是和源码一样成为面试中的热门话题。所以欧阳打算写一个关于大模型底层原理系列的文章,包括热门的
什么是生成式大模型
大家平时接触的AI基本都是生成式大模型,比如我们熟知的ChatGPT、DeepSeek等。在ChatGPT还没火之前,判别式模型是最热门的,也就是国内的科技公司花了大精力去研究的领域,从现在的上帝视角来看只有OpenAI走了正确的路。
判别式模型的作用主要是分类,在我们的生活中到处都是判别式模型的影子,比如:
- 垃圾邮件分类器: 判断一封邮件是"垃圾邮件"还是"正常邮件"。
- 情感分析: 分析一个商品评价是"积极"、"消极"还是"中性"。
- 人脸识别: 判断一张脸属于数据库中的哪个人。
- 图像识别: 识别一张图片中的物体是什么。
判别式模型做的事情只能是一个辅助工具,不能执行一些创造性的任务,比如写文章、写代码等。
但是生成式大模型就能突破判别式模型的天花板,不仅可以做判别式模型能够做到的所有事情,还能执行一些大家熟知的创造性的任务,比如写文章、写代码等。
生成式大模型的主要特点就是大,这里的大指的是模型的规模。主要体现在两个方面:参数数量和训练数据量。
现在的那些大模型基本都是以B为单位,比如DeepSeek R1最小的是2B,最大的是685B。这里的B是指Billion,也就是10亿。2B的意思是20亿个参数,685B的意思是6850亿个参数。
为什么这些大模型的参数数量会这么大呢?
答案是ChatGPT发现当模型的参数数量达到一个临界点后,模型突然就开悟了一样,能够理解人类语言的含义,并且能够生成符合人类语言习惯的回答,这就是大家常说的模型的涌现能力。量变引起质变,大力出奇迹(手动狗头)。
在接下来的文章中我们讲的大模型都是指生成式大模型,因为判别式模型和生成式大模型比起来完全就是弟弟,人们的注意力现在基本都放在了生成式大模型上。
文字接龙
大模型所做的事情本质就是文字接龙,所以在讲如何训练出一个ChatGPT之前我们来聊聊文字接龙。
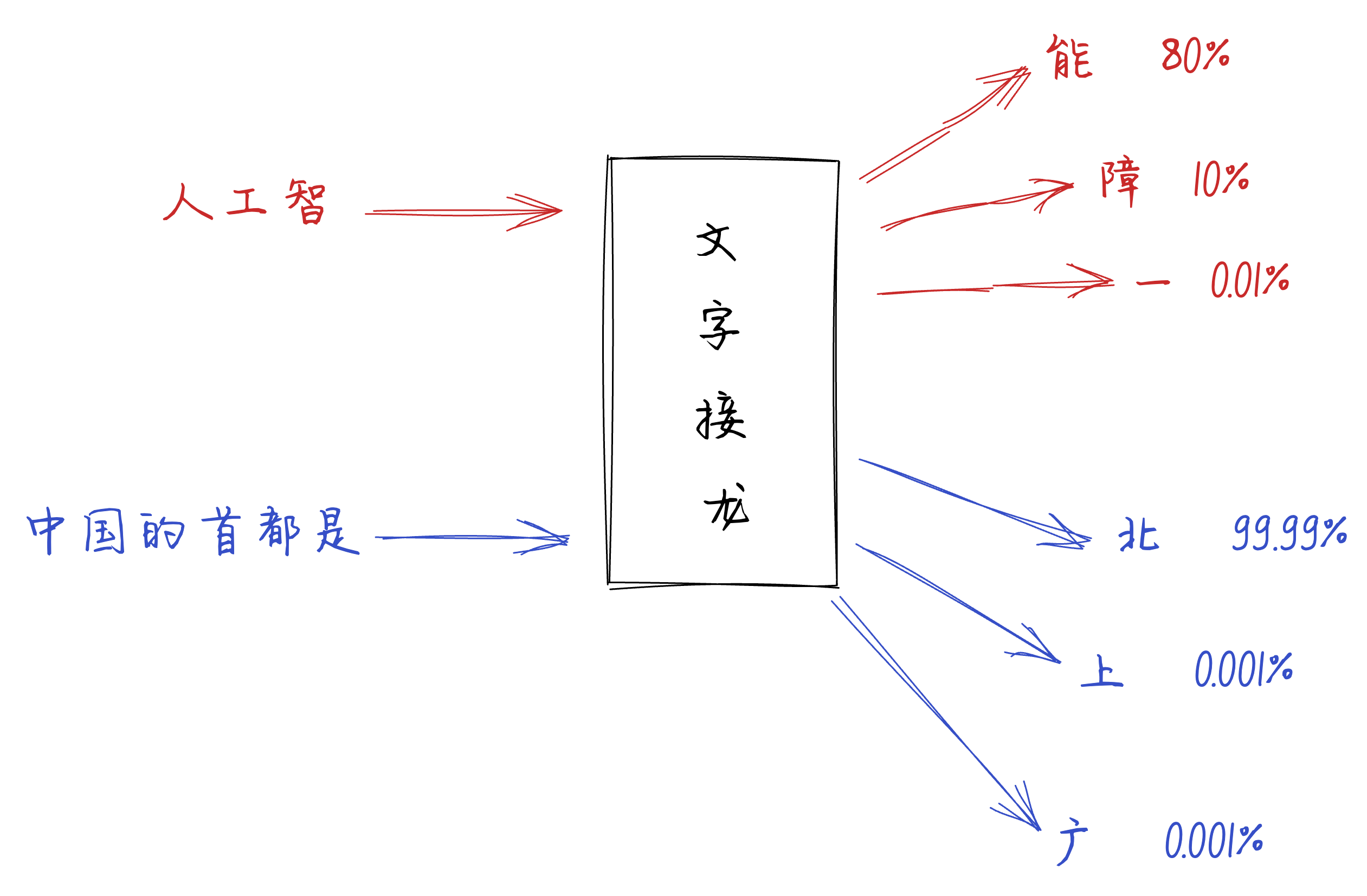
人类在做文字接龙的时候会结合自己掌握的知识去思考下一个字应该接什么。
比如,输入是人工智时,大部分人都会接成能,组合成人工智能这个词,他的概率是80%(我瞎说的)。当然有人会觉得下一个字应该是障,组合成人工智障这个词,他的概率是10%。还有一些情况下会接一,组合成人工智能一,这种就是非常少见的情况,所以他的概率是0.01。
如果我们将文字接龙抽象化成一个函数,那么这个函数就是:
function textJieLong(input) {
let arg1, arg2, arg3, arg4, arg5, arg6, arg7, arg8, arg9, arg10,...
if (路人A) {
return '能'
} else if (路人B) {
return '障'
} else if (路人C) {
return '一'
} else {
return '...'
}
}
// 输出:能 概率:80%
// 输出:障 概率:10%
// 输出:一 概率:0.01%
// 输出:.. 概率:...
textJieLong('人工智')
这个textJieLong函数就可以被看作是一个大模型,函数的输出结果就是大模型的输出结果。
函数中的一系列arg1、arg2等参数就是大模型的参数,我们常说的8B就是说明有80亿个参数,也就是有80亿个arg参数。
那么模型训练的作用是干嘛呢?
模型训练就是我们给textJieLong函数一堆输入和输出的数据,然后根据这些输入和输出的数据去反推arg1、arg2等参数。
输入:人工智
输出:能
输入:中国的首都是
输出:北京
输入:今天天气适合在家
输出:打游戏
很多组输入和输出...
有没有觉得这个和小学的方程式很像,一堆输入,一堆输出,然后求解方程式里面的未知数,这些未知数就是模型的参数。
其实训练模型的过程就是计算求解这些参数的过程!! 每一次的训练都会去不断的更新这些参数,直到模型吐出的结果满足我们的预期。
训练模型会经历哪些阶段
训练一个模型会经历三个阶段,对应下面的这张图的三个阶段:

第一张图为:自我学习,累计实力(预训练 Pre-training)
第二张图为:名师指点,发挥潜力(监督微调 SFT)
第三张图为:参与实战,打磨技巧(强化学习 RLHF)
这三个阶段都是大模型在学习如何进行文字接龙,只是训练的资料不同。
第一阶段:自我学习,累计实力(预训练 Pre-training)
在讲预训练之前,我们先来聊聊在进行预训练之前的模型是什么样的?
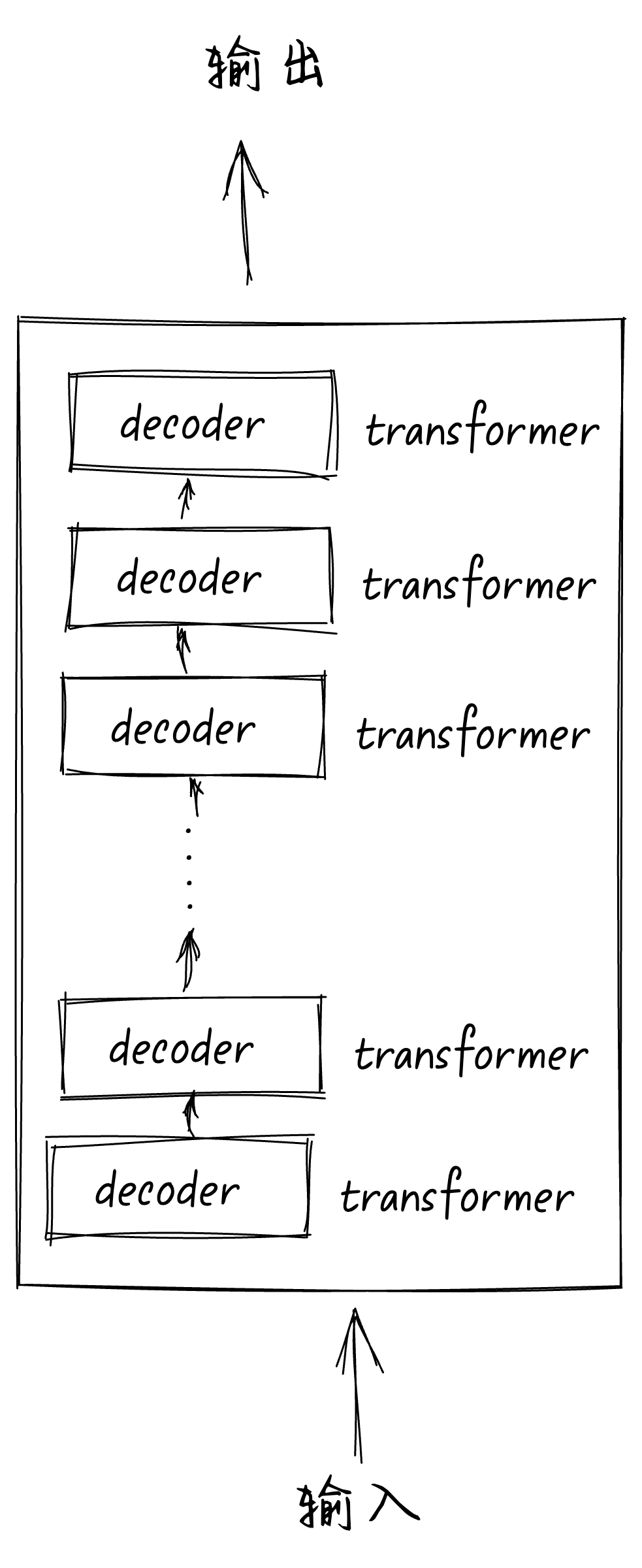
一个大模型的结构大概是下面这样的:
更多推荐


 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)