
智源发布统一开源大模型系统软件栈,不同大模型不同芯片兼容并包,性能还更快
北京智源人工智能研究院(BAAI,Beijing Academy of Artificial Intelligence)发布了众智FlagOS 1.5,一套能让大模型在二十多种不同AI芯片上随便跑的开源系统软件。大模型这把火越烧越旺,科技的边界天天都在被刷新,但背后有个比较尴尬的事,就是算力基础设施太“碎片化”了。就好比智能手机刚出的时候,你买了个手机,发现充电口五花八门,苹果的、安卓的、诺基亚的
北京智源人工智能研究院(BAAI,Beijing Academy of Artificial Intelligence)发布了众智FlagOS 1.5,一套能让大模型在二十多种不同AI芯片上随便跑的开源系统软件。

大模型这把火越烧越旺,科技的边界天天都在被刷新,但背后有个比较尴尬的事,就是算力基础设施太“碎片化”了。
就好比智能手机刚出的时候,你买了个手机,发现充电口五花八门,苹果的、安卓的、诺基亚的,各搞一套。
AI芯片的世界差不多就是这样,各家芯片厂商都有自己的一套软件生态系统,互不联通。你想把一个在A芯片上训练好的模型,挪到B芯片上去跑,那可不是复制粘贴那么简单,差不多得重写半个项目,费时费力费钱,极大地拖慢了创新的脚步。
为了把这些“墙”推倒,北京智源人工智能研究院携手学术界与产业界的众多伙伴,在过去两年多的时间里,持续投入研发了面向多种AI芯片的系统软件栈——众智FlagOS。

它的核心任务就一个,解决异构算力环境下,各种AI芯片互不兼容的头疼问题,让大模型可以在各种硬件上跑得欢,构建一个开放、坚实的智能计算底座。
9月26日,在以“筑基开放燎原”为主题的人工智能计算大会上,正式发布众智FlagOS 1.5。
一套系统,朋友遍天下
FlagOS的首要使命就是消除硬件之间的隔阂,做AI芯片界的“和平使者”。
到了1.5这个版本,它的朋友圈又扩大了。现在已经能支持超过12家国内外主流芯片厂商的20多种不同型号的芯片。这意味着开发者不用再为“站队”哪家芯片而烦恼,适配硬件的复杂性被大大降低了。
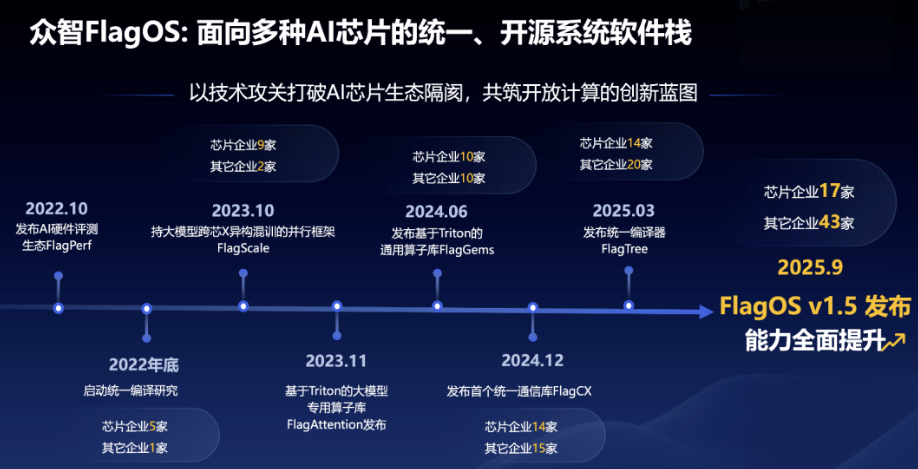
更重要的是,系统内部的各个组件之间配合得更默契了。从底层的算子库(FlagGems)、负责编译优化的编译器(FlagTree)、管理数据传输的通信库(FlagCX)到指挥分布式训练的并行框架(FlagScale),这一整套工具链协同工作,给上层应用提供了一个稳定又一致的开发环境。
这里得单独说说它的算子库FlagGems。
这东西已经发展成了全世界体量最大的Triton语言算子库,核心算子数量超过了200个。成了唯一被纳入PyTorch官方生态的跨芯片算子库。
智源研究院副院长兼总工程师林咏华谈到:有了FlagOS,不同的大模型就能在装载不同芯片的服务器或电脑上运行。只要是基于FlagOS 1.5的技术发布的模型,都可以无忧无虑地在不同的芯片上进行训练或者推理。
统一兼容,不代表要牺牲性能。恰恰相反,FlagOS 1.5在追求极致效率上一点没含糊。
通过一系列深度优化,在一些典型的大模型任务中,它的训练速度最高能提升36.8%,推理速度也能加快20%。
在大规模集群训练里,数据通信是个关键环节,经常成为瓶颈。新版的通信库FlagCX通过优化Pipeline,把通信效率最高提升了2.5倍。
它还率先支持了跨芯片的异构混合训练。
这是一个很有意思的突破。它意味着,你可以把不同架构的芯片,放在一个集群里,共同训练同一个模型。这极大地提高了计算资源的利用率,让训练部署变得非常灵活。
在浪潮信息元脑超节点SD200上,基于FlagOS的部署,成功让这个硬件系统成为第一个实现DeepSeek-R1模型每token推理延迟低于10毫秒的系统。在海光Nebula超节点上,FlagOS的自动优化能力,能在几分钟内就搜索出最佳策略,在千卡规模的集群上获得了超过98%的弱扩展效率。
这些实打实的案例,证明了FlagOS 1.5在真实场景里的性能表现是过硬的。
除了速度快,它在资源利用率上也下了功夫。通过智能调度和内存优化,同样的硬件配置,现在能支持更大规模的模型训练,或者用更少的资源完成同样的任务,实实在在地帮用户省钱。
开发自动化,还走进了机器人
FlagOS 1.5干了一件更酷的事,它开始尝试用AI的能力,来开发AI系统软件本身。
比如在算子开发上,前面提到的那个全球最大的Triton算子库,还配套推出了一个叫Triton-Copilot的工具。这个工具利用AI技术,可以自动生成、验证和优化算子代码。
以前需要一个领域专家花上一两天才能写好的高性能算子,现在一个刚入门的开发者或者研究生,一两个小时就能搞定。
模型迁移也变得更自动化了。一个叫FlagRelease的平台,结合了AI Agent技术,能把主流开源模型在不同芯片上的迁移、验证和发布流程自动化。测试下来,效率比传统手动方式提升了4倍。
这个平台通过智能化的代码转换、性能测试和兼容性检查,大大减少了人工操作,让模型跨平台部署变得更可靠、更高效。
FlagOS 1.5的应用范围,还从云端的大模型,拓展到了更前沿的具身智能领域。
系统现在全面支持机器人“大脑”,比如智源的RoboBrain模型,和机器人“小脑”,比如VLA模型,的开发与部署。它打通了从预训练到终端侧推理的整个链条,给更智能的机器人提供了强大的系统支撑。
林咏华副院长解释说,这一升级让机器人系统能更好地整合感知、决策和控制能力,推动具身智能技术真正落地。
机器人“大脑”负责高层决策和任务规划,而“小脑”负责感知环境和执行具体动作。通过FlagOS的统一支持,这两个模型可以在异构硬件上高效地协同工作,形成一个完整的智能闭环。
这种端云协同的架构,为未来智能机器人的研发铺平了道路。
此外,在北京市科委推动的国产高性能算力互联集群“北京方案”中,FlagOS 1.5也扮演了关键角色。浪潮和海光的超节点成功部署,验证了它在大规模异构计算环境下的适应性和优化能力。
它的应用场景还在不断延伸,包括科学计算、智能制造、智慧医疗等等。有了这个统一的软件栈,这些领域可以更方便地部署和优化AI模型,加速AI技术的产业化。
开源,是为了建一个更大的生态
从立项第一天起,众智FlagOS就选择了开源。
构建一个“社区共研发-芯片共适配-模型共受益”的,真正通用、高效的AI系统生态,光靠任何一个机构的力量都是远远不够的。这需要开放的标准、透明的协作,和全世界开发者的共同智慧。
为了从源头上培养人才,智源还发布了“众智FlagOS”高校计划,联合了北大、清华、北航等十多家高校院所,一起开设FlagOS系列课程,培养真正懂智算系统软件的开源人才。
与此同时,产业环境也在不断完善。大会上,《超节点智算应用“北京方案”》正式发布,北京市人工智能标准化技术委员会、可重构算力软硬件协同技术创新中心也相继成立。中关村科学城还公布了新的算力补贴政策,用真金白银支持AI企业的发展。
国产算力生态,正在通过全球协作,为智能时代构建一个更加坚实、开放的智算底座。
参考资料:
https://hub.baai.ac.cn/view/49250
https://github.com/flagopen
END
更多推荐

 5
5 0
0- 0



 已为社区贡献26条内容
已为社区贡献26条内容

所有评论(0)