
【Coze】【视频】炫酷书单工作流
这篇文章介绍了一个基于Coze平台的智能工作流,通过整合大语言模型、语音合成、图像生成和剪映插件,实现从书籍金句文案生成到成片制作的自动化流程。工作流包含文案生成、语音配音、字幕对齐、图像合成和剪映草稿生成等环节,核心由豆包1.5大模型和图像生成模型支撑。该方案适用于知识分享、短视频创作等场景,能帮助创作者高效产出专业且有深度的多媒体内容。
今天给大家演示一个基于 Coze 平台 的智能工作流,它整合了大语言模型、语音合成、图像生成以及剪映插件的能力,实现了从书籍金句文案生成,到音频配音、字幕对齐、图片合成,再到成片草稿的全流程自动化制作。通过这一工作流,我们可以直观地看到 AI 在文字、声音、画面上的联动协作,快速生成完整的多媒体内容。
工作流介绍
这个工作流的核心是通过 大模型文案生成 + 配音合成 + 图像与字幕处理 + 剪映草稿插件 的串联,形成一个从文字到视频的自动化生产链。大模型负责创作专业化书籍文案,配音节点将文字转为音频,字幕对齐工具同步语音和字幕,图像生成与素材组合代码实现画面渲染,最终调用剪映插件批量生成草稿、字幕、音频和图像,完成可直接预览的视频雏形。
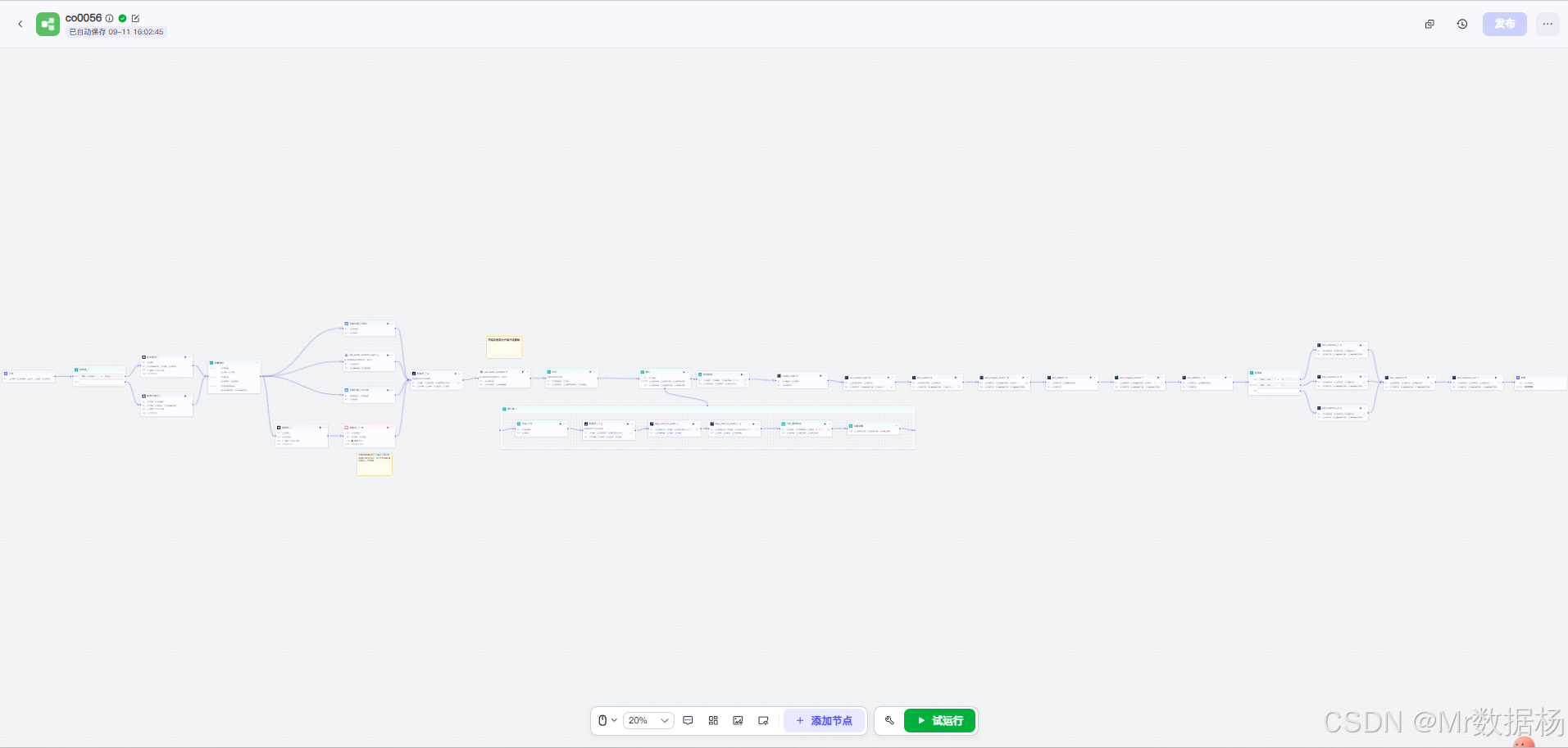
核心模型
核心部分由 大语言模型节点 和 图像生成节点 共同支撑。大语言模型(豆包·1.5·Pro·32k)通过提示词生成书籍文案和评论,确保内容具备文学性与深度。图像生成节点则通过描述生成封面或背景图片,使得视觉效果与内容保持一致。两者结合,既保证了文案表达的专业性,又兼顾了视觉呈现的多样性。
| 模型名称 | 说明 |
|---|---|
| 豆包·1.5·Pro·32k | 大语言模型,用于生成书籍金句评论文案 |
| 图像生成模型 | 根据文字提示生成插图或封面图 |
Node节点
该工作流包含多个节点,既有大模型类节点(写文案员工、绘画员工2),也有插件节点(语音合成、字幕对齐、批量添加素材),以及用于逻辑编排和数据处理的代码与循环节点。各节点紧密配合,从输入到成品形成一个闭环流程。
| 节点名称 | 说明 |
|---|---|
| 写文案员工 | 调用大语言模型生成书籍金句文案 |
| 绘画员工2 | 通过文字描述生成书籍插图或背景 |
| 配音员工 / 配音员工2 | 将文案内容转为音频 |
| 循环 | 控制字幕、音频的逐段生成与迭代 |
| 代码 / 代码_分句 / 代码_素材组合 | 用于处理素材分句、合成和时间线逻辑 |
| align_text_to_audio | 对齐字幕与音频,保证口型与文本一致 |
| create_draft | 创建剪映草稿文件 |
| add_audios | 向草稿批量添加音频 |
| add_images | 向草稿批量添加图片 |
| add_captions | 向草稿批量添加字幕 |
工作流程
该工作流整体以 内容生成 → 配音与字幕 → 素材组合 → 剪映成片 为主线。首先通过大模型生成书籍金句文案,再将其转化为配音音频并进行字幕对齐。接着调用图像生成与素材组合代码形成视觉画面,最后使用剪映插件完成音频、字幕、图片的批量导入,自动生成草稿视频。整个过程环环相扣,实现了从文本到多模态视频的高效生产。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 文案生成 | 根据书籍名称调用大模型生成金句文案和评论 | 写文案员工 |
| 2 | 语音合成 | 将生成的文案内容转为配音音频 | 配音员工 / 配音员工2 |
| 3 | 字幕分句与对齐 | 将文案分句后与配音进行对齐,生成字幕时间线 | 代码_分句、align_text_to_audio |
| 4 | 图像生成与素材编排 | 根据描述生成插图/封面,结合代码逻辑合成画面与特效 | 绘画员工2、代码、代码_素材组合 |
| 5 | 循环控制 | 控制字幕与音频逐段处理,输出累积结果 | 循环、设置变量 |
| 6 | 剪映草稿生成 | 创建视频草稿,批量添加音频、字幕和图片素材 | create_draft、add_audios、add_images、add_captions |
| 7 | 成片输出 | 生成可直接预览和后期编辑的草稿视频 | 剪映草稿插件 |
大模型应用
书籍文案生成节点
该节点的职责是根据用户输入的书籍名称,生成富有文学感与思辨性的金句评论文案。它通过模拟书评人的表达风格,将输入信息转化为完整的书籍评论文本,并在输出中保留书籍名称和作者信息。这一过程确保了工作流的内容核心——高质量的文字表达。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 写文案员工(豆包·1.5·Pro·32k) | 书籍名称:《{{title}}》 # 经典书籍金句推荐 你是一位专业的书评人,清模仿董宇辉的风格,根据用户提供的书籍名称,撰写出专业且有深度的金句评论,输出 200字左右的顶级感悟文案。 #格式 输出文案,合理分段以数组列表输出每段内容 并给出书籍名称、作者名称 |
Prompt 的目标是让模型以书评人的身份生成精炼、深度的书籍评论,保证内容既有思想性又具备传播力。该节点在整个工作流中负责生产核心文案素材,是后续配音、字幕和图像生成的基础。 |
图像生成节点
该节点用于将用户提供的文字描述转化为图像,生成与文案主题相匹配的视觉素材。它通过自然语言提示词驱动图像生成模型,为最终视频提供封面或背景画面,使得作品不仅有声音和文字,还能有生动的视觉表现。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 绘画员工2(图像生成模型) | {{prompt}} | 该 Prompt 直接将用户输入作为图像生成提示,模型根据描述生成对应画面。设计目标是快速产出契合内容主题的封面或插图,用于视频的开场或背景,从而提升观感效果。 |
使用方法
开始节点
在开始节点中,用户需提供书籍相关的输入信息,例如书籍标题、封面图片、背景图片等基础素材。这些信息将作为后续大模型生成文案、语音合成和图像生成的输入。
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| title | 用户输入的书籍名称,用于文案生成 | str.String |
| pic | 封面图片链接 | str.String |
| bg_pic | 背景图片链接 | str.String |
| bgm | 背景音乐文件 | str.String |
结束节点
结束节点将生成的视频草稿信息输出,供用户在剪映中直接使用或后期编辑。输出数据主要包含草稿的链接和 ID,确保用户能快速定位成品视频。
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| draft_id | 剪映生成的草稿 ID,用于后续访问和编辑 | str.String |
| draft_url | 草稿的在线访问链接 | str.String |
应用场景
该工作流主要面向 书籍解读、知识分享、短视频内容创作 的自动化场景。它通过大模型生成文案,再结合语音、字幕、图像生成与视频编辑插件,能够帮助创作者快速产出完整视频。典型用户包括知识博主、教育机构以及新媒体运营人员,他们可以使用此流程批量化生产高质量的解读视频,既保证了内容的专业性,也兼顾了视觉和听觉的体验。最终效果是让文字、声音、画面自然融合,形成有深度又有观赏性的多模态视频内容。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 书籍金句解读 | 将书籍文案转化为视频内容 | 知识博主、自媒体创作者 | 文案评论 + 配音 + 字幕 + 图像 | 快速生成有声有画的书籍解读短视频 |
| 教育讲解视频 | 将教学文案自动转化为课程视频 | 教育机构、教师 | 教学文案 + 配音 + 多图演示 | 提升内容输出效率,降低视频制作成本 |
| 知识分享短片 | 将长文本拆分为多段知识点解读 | 短视频运营者 | 知识点字幕 + 配音解说 | 批量化生成短视频,增强传播力 |
| 营销推广 | 将产品介绍文案转化为营销短片 | 品牌方、营销团队 | 宣传文案 + 背景音乐 + 动画效果 | 快速生成宣传视频,提升用户吸引力 |
开发与应用
更多 AIGC 与 Agent工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用
更多推荐

 19
19 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)