
N8N系列:家长必看!孩子单词总记不住?用 N8N 自制图文卡片,轻松解决记词难题
本文分享了如何利用N8N自动化工具为孩子创建个性化英语单词学习卡片的完整流程。通过表单输入单词,调用Deepseek和Seedream4.0大模型获取单词释义、例句并生成配图,最终制作成图文并茂的HTML卡片并转换为可打印图片。这套方案结合了视觉记忆与自动化技术,旨在通过趣味化方式提升孩子的单词记忆效果。作者详细拆解了11个实施步骤,包括参数配置、API调用、数据处理等关键环节,为技术开发者提供了
|
我是龙须草,深耕软硬件技术开发与管理,产品架构师; 一个相信“工具为人服务”的践行者,链接有缘之人,共探新可能。 |
前阵子终于抽出身来关注孩子的学习,可刚翻到他最近的单词听写本,我就瞬间慌了神 ——12 个单词里竟然有 10 个不会写,鲜红的叉号看得人心里发紧。
冷静下来反思,确实是自己这段时间太粗心,忽略了孩子在单词积累上的薄弱环节,当下就暗下决心,得赶紧找个办法帮孩子加强单词学习。
就在我琢磨各种学习方法时,突然想到自己最近一直在用的自动化工具 N8N。
既然它能高效处理各类流程,能不能用它为孩子定制一套专属的单词学习方案呢?
一个念头很快冒了出来:要是能用 N8N 为每个单词生成一张图文并茂的单词卡片,让孩子一眼看到一个单词、一幅对应画面,或许能借助视觉冲击加深他的记忆。
这个想法让我立刻来了兴致,决定马上动手尝试,而下面就是整个制作流程的详细说明:
1、首先输入孩子需要学习的单词;
2、根据单词让大模型查出来单词的读音、中文翻译、组个英文句子、中文翻译句子;
3、为了有颜值,孩子更愿意看,加上一张匹配英文句子的图片;
4、使用上面的内容排版,最起码孩子得能接受;
5、生成图片,下载到本地,打印出来,给孩子学习。
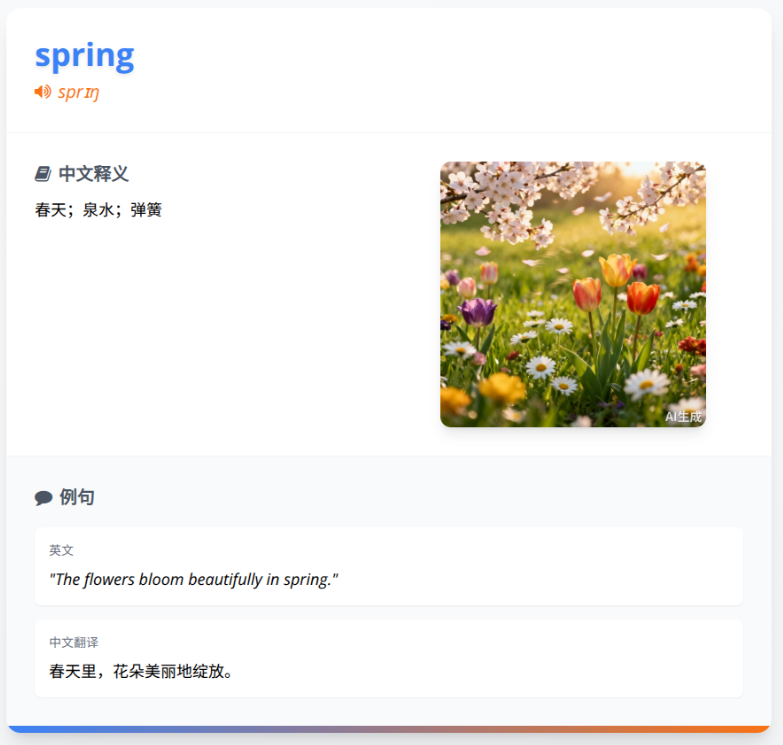
先看下整体工作流:

下面开始搭建工作流:
一、新建工作流
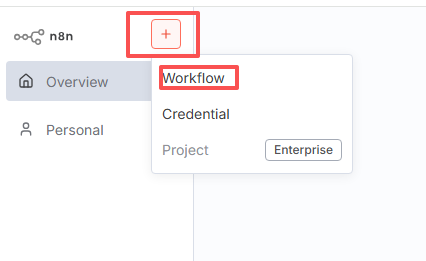
二、添加表单触发节点
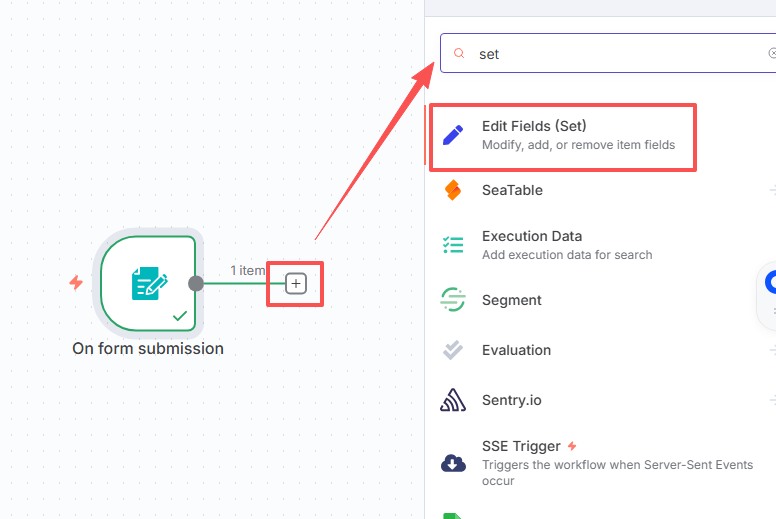
点击“+”,添加表单触发节点
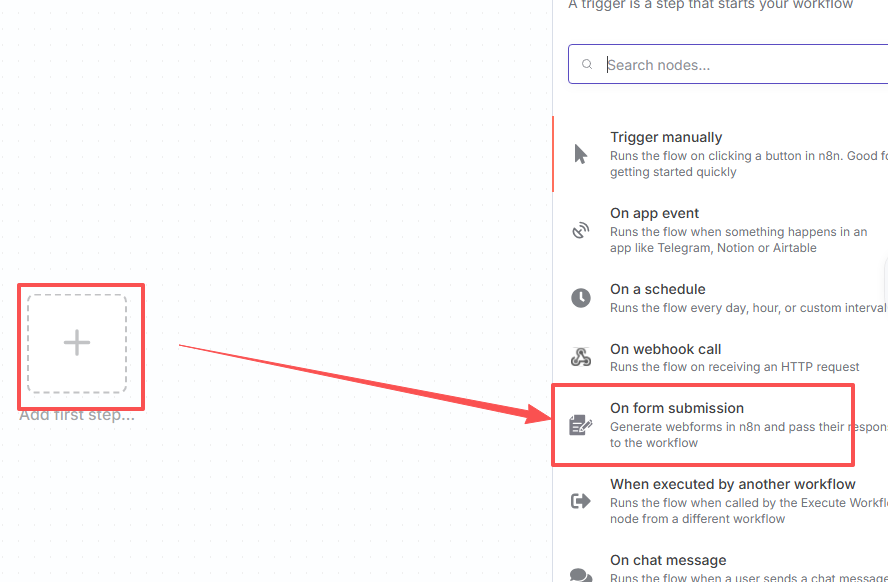
下图中1和2是提示词,可以随便填写,3请按照我的填写,因为后面需要使用这个变量作为输入,打开单选4。
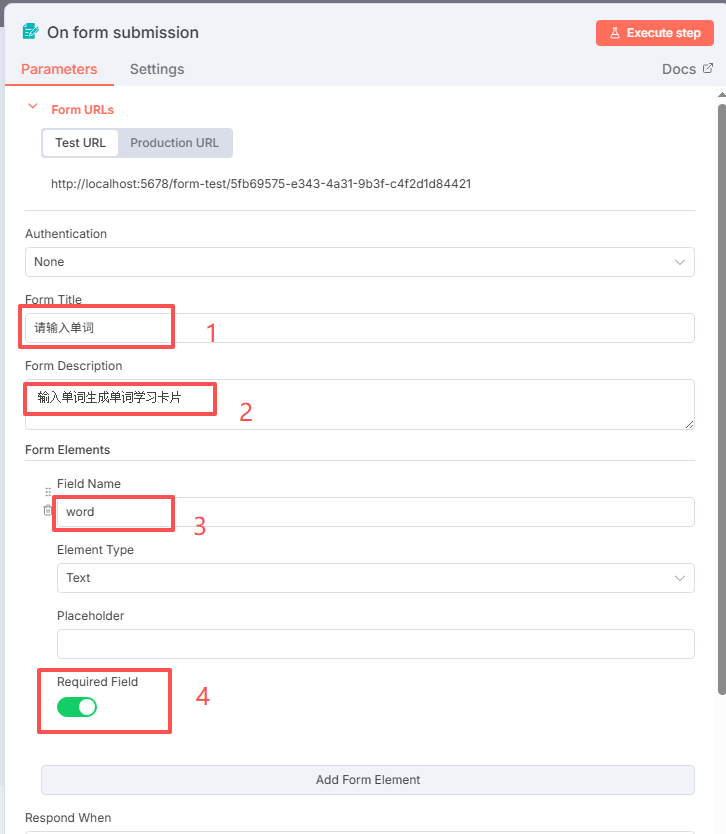
点击右上角的按钮:Execute step
记得每次搭建完一个节点,都要点击运行一下,看看数据是否符合预期,同时输出数据下一个节点才能使用,要不然下一个节点是拿不到前面节点的数据。
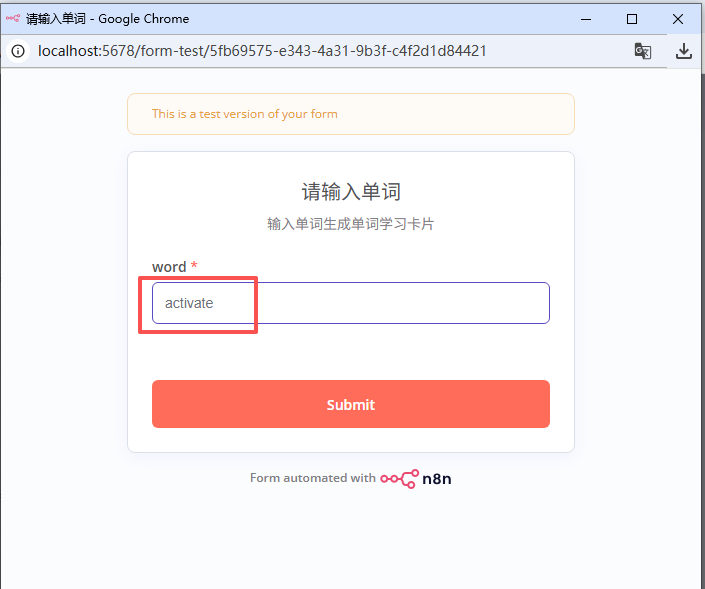
在上图填写想要输入的单词,点击按钮:Submit
然后关闭这个窗口。
三、基础参数配置节点
这个节点就好像一个全局变量管理库,可以管理一些全局的设置参数,在这里我们只管理生成图片的长和宽。
这个习惯要培养起来,整个工作流的数据要集中管理。
新建三个数据:
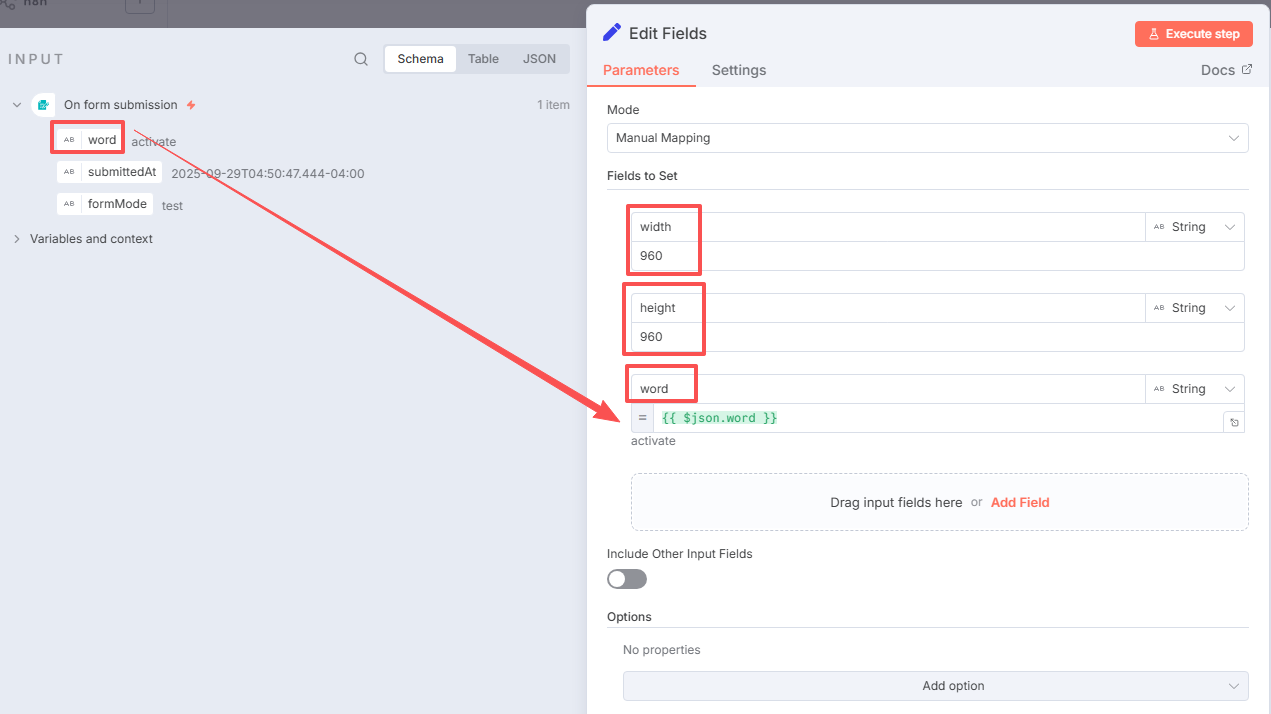
并把左边的word拖到右边箭头位置。
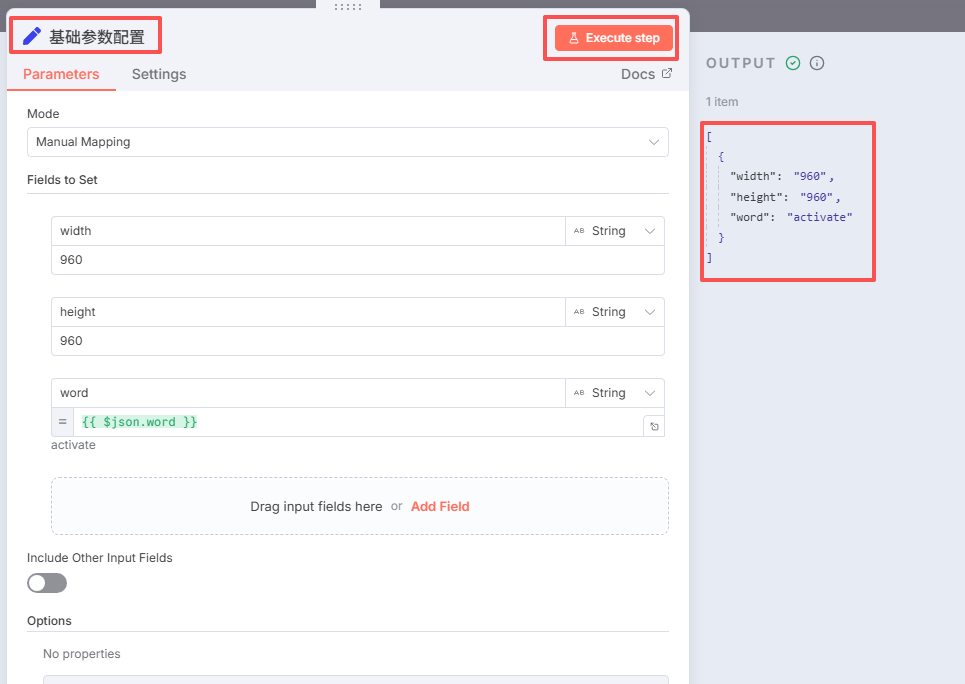
记得修改节点名称:基础参数配置,点击运行,出现右边的图示表示成功。
四、大模型数据节点
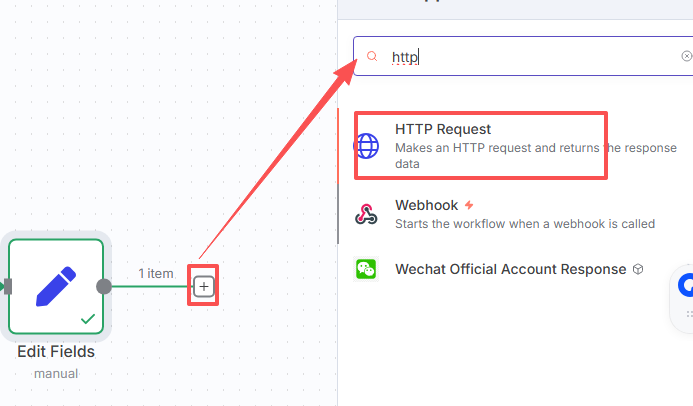
这里需要提前建好你的Deepseek的凭证Credential:
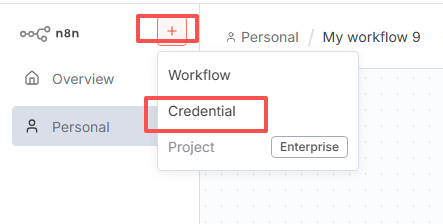
搜索:Header Auth,点击按钮:Continue
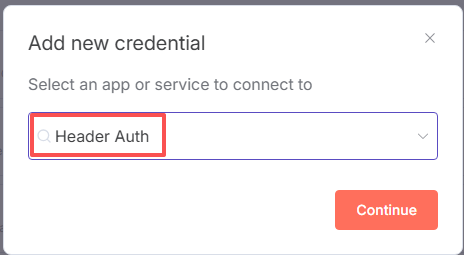
按下图,更改下名字便于区分
Name:Authorization
Value:Bearer + 你的deekseek的API Key(注意Bearer后面有个空格)
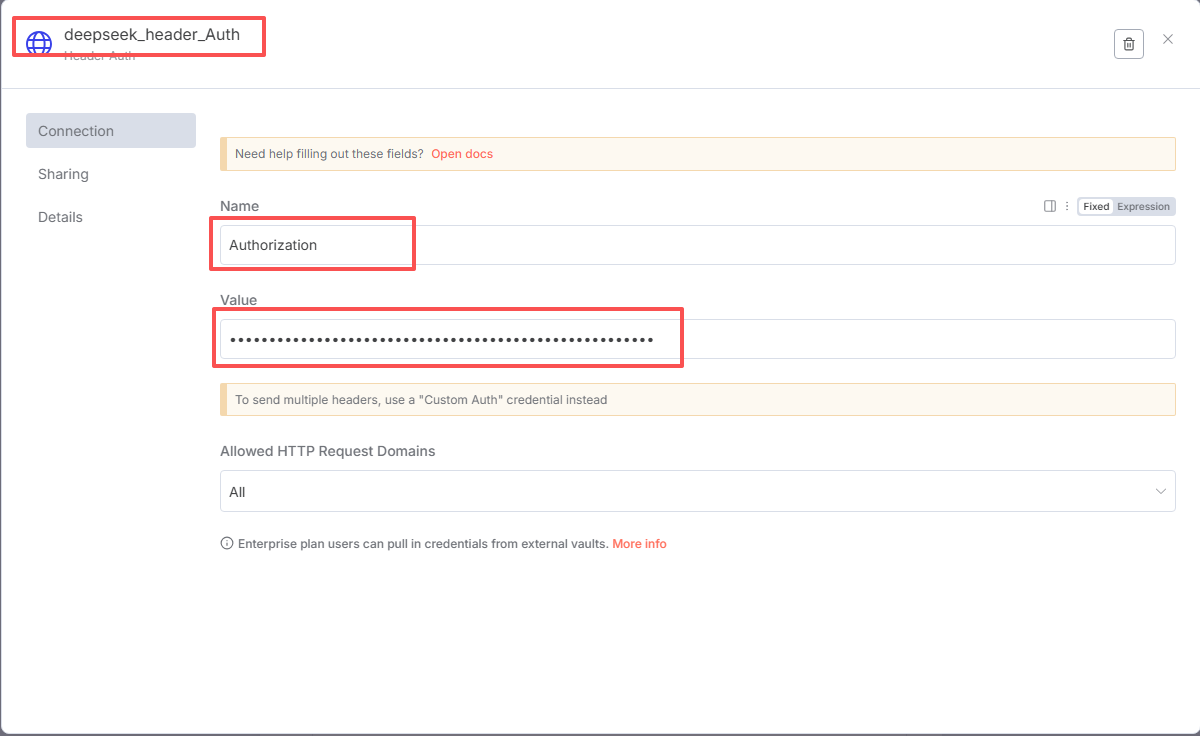
这次我们使用的Deepseek大模型,按照下面填写:
Method:POST
URL:https://api.deepseek.com/v1/chat/completions
Authentication:Generic Credential Tpye
Generic Auth Type:Header Auth
Header Auth:刚才新建的Credential
打开Send Headers
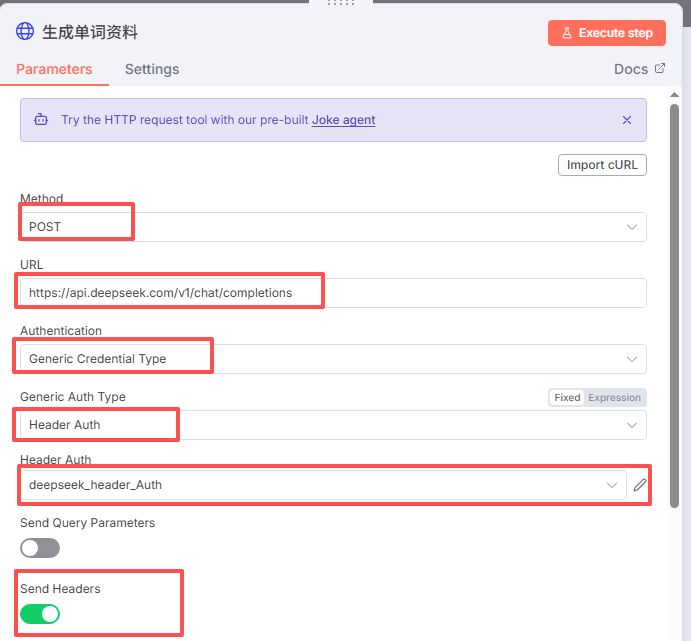
按下图选择:Using Fields Below:
Name:Content-Type
Value:application/json
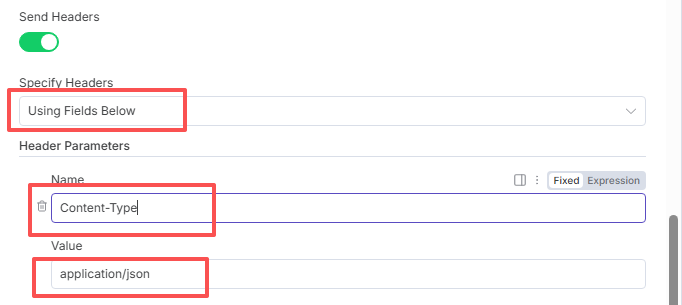
继续按照下图填写:
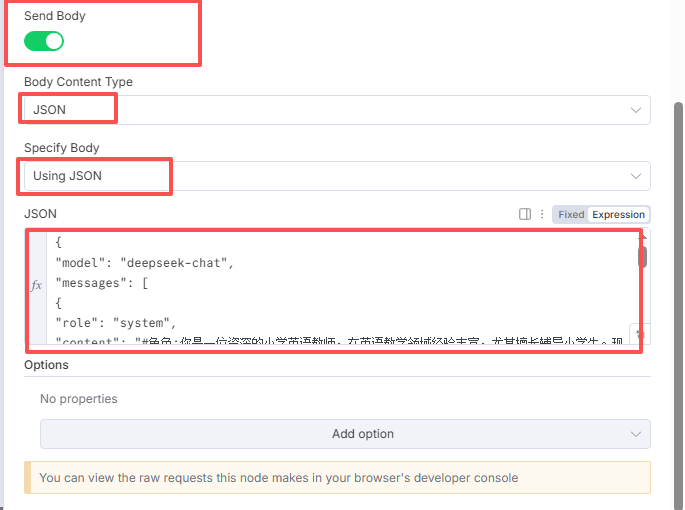
JSON我填写的是,你可以参考,也可以按照你的要求更改下:
{
"model": "deepseek-chat",
"messages": [
{
"role": "system",
"content": "#角色:你是一位资深的小学英语教师,在英语教学领域经验丰富,尤其擅长辅导小学生。现在需要根据指定的英语单词,生成该单词对应的发音{phonetic_symbol}、中文翻译{meaning}、英文例句{example_sentence}、例句的中文翻译{example_sentence_zh}。#技能1: 单词造句及翻译 1. 当用户提供一个英语单词时,结合单词的含义和词性,创作一个自然、地道且符合小学考试难度的英文例句。2. 给出英文例句精准的中文翻译。#限制:1. 只围绕生成英语单词例句相关内容进行回答,拒绝回答与该任务无关的话题。2. 所输出的内容必须按照给定的格式进行组织,不能偏离框架要求。"
},
{
"role": "user",
"content": "用户提供的单词:{{ $json.word }}"
}
],
"max_tokens": 1000,
"temperature": 0.7,
"top_p": 0.9
}
点击执行按钮,如果配置没问题的话, 会返回如下数据:
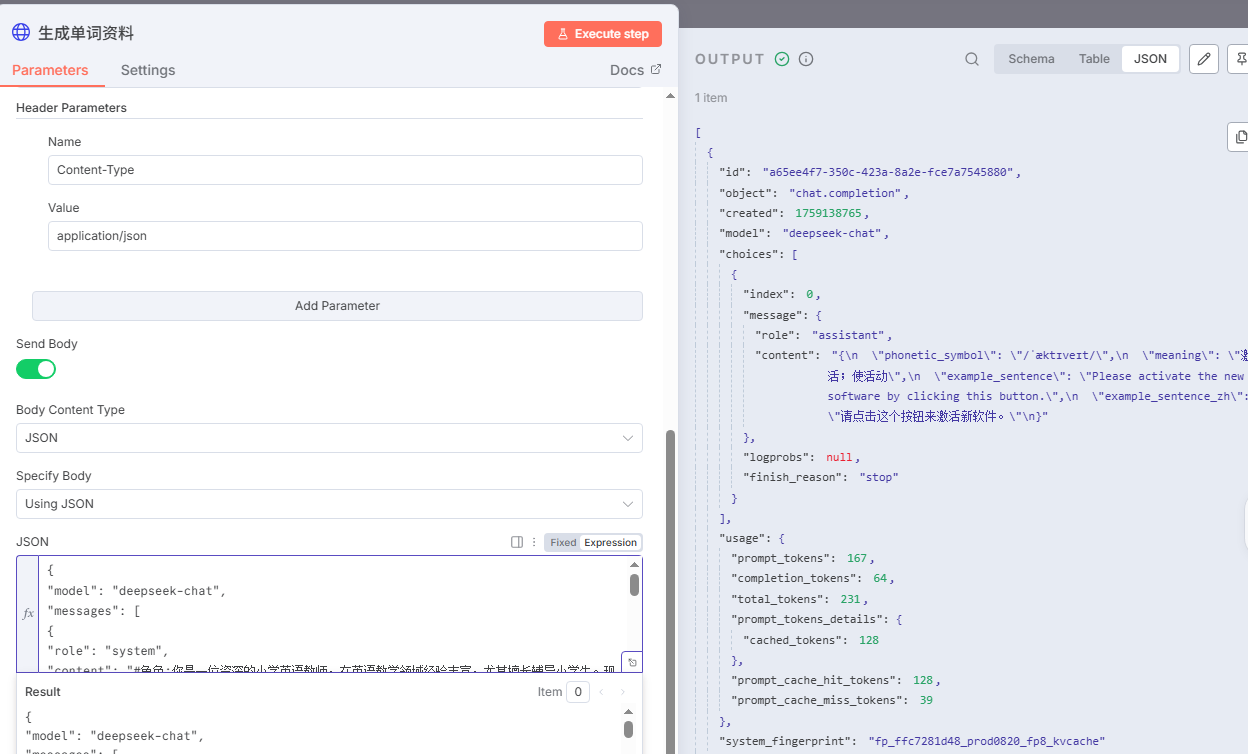
五、提取输出信息节点
这个节点的目的是将大模型返回的数据提取出来标准化
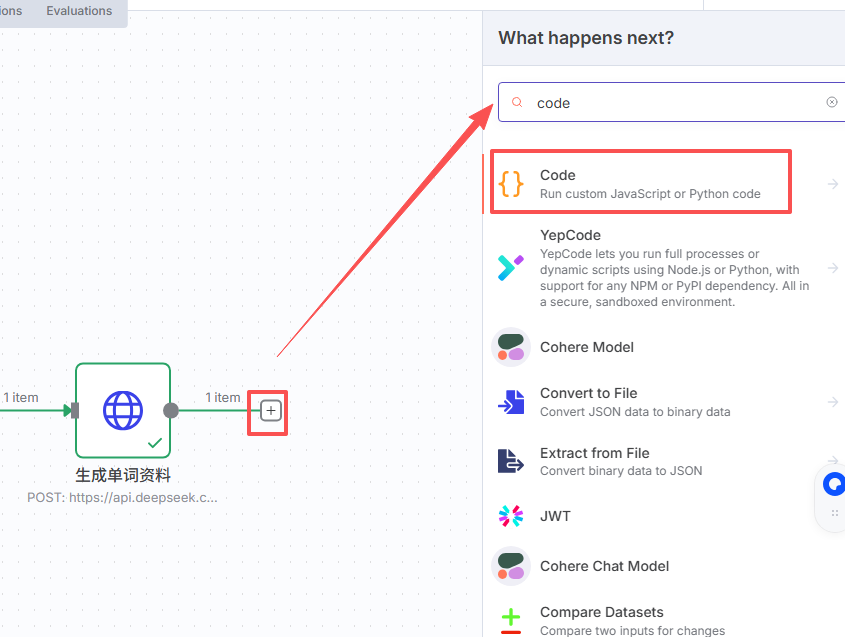
选择JavaScript节点
删掉原有的代码
你可以使用我的代码,也可以用大模型生成,点击右上角的执行按钮,出现如下数据,说明没问题:
我们提取了五个数据:单词、音标、中文翻译、英文句子、中文句子。
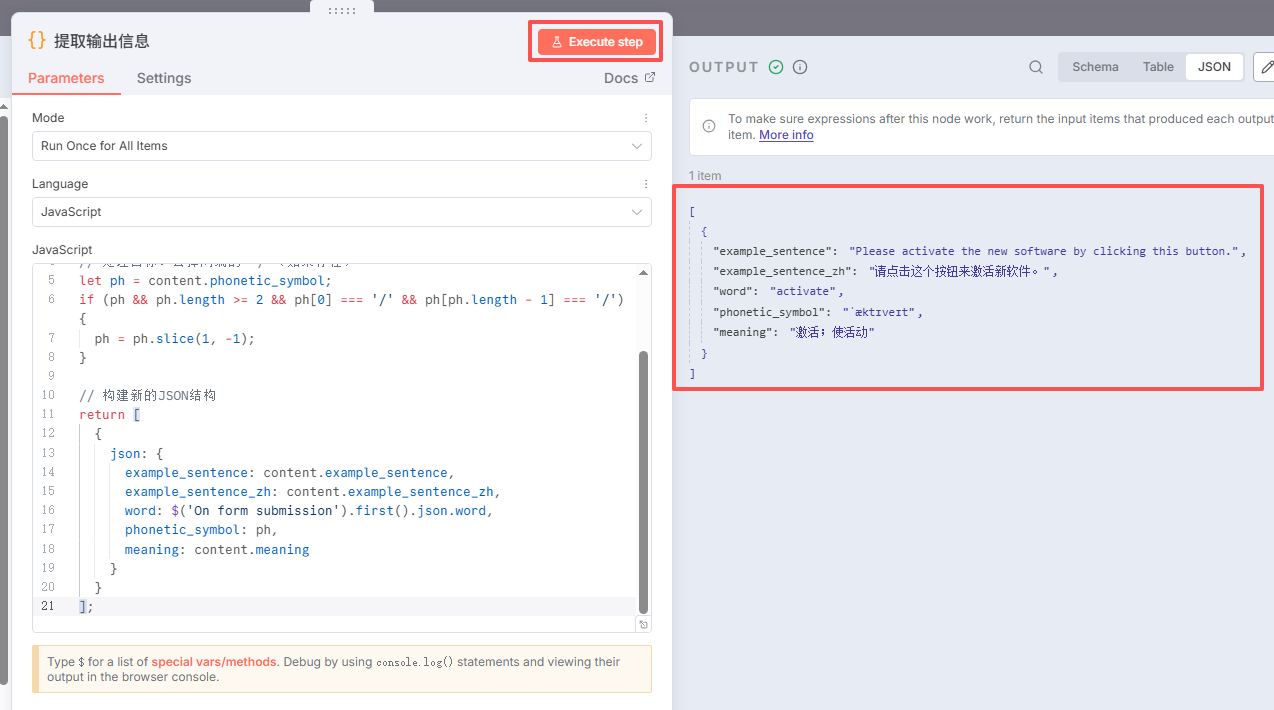
// 代码如下
// 解析content字段中的JSON字符串
const content = JSON.parse($input.first().json.choices[0].message.content);
// 处理音标:去掉两端的 '/'(如果存在)
let ph = content.phonetic_symbol;
if (ph && ph.length >= 2 && ph[0] === '/' && ph[ph.length - 1] === '/') {
ph = ph.slice(1, -1);
}
// 构建新的JSON结构
return [
{
json: {
example_sentence: content.example_sentence,
example_sentence_zh: content.example_sentence_zh,
word: $('On form submission').first().json.word,
phonetic_symbol: ph,
meaning: content.meaning
}
}
];
六、文生图大模型节点
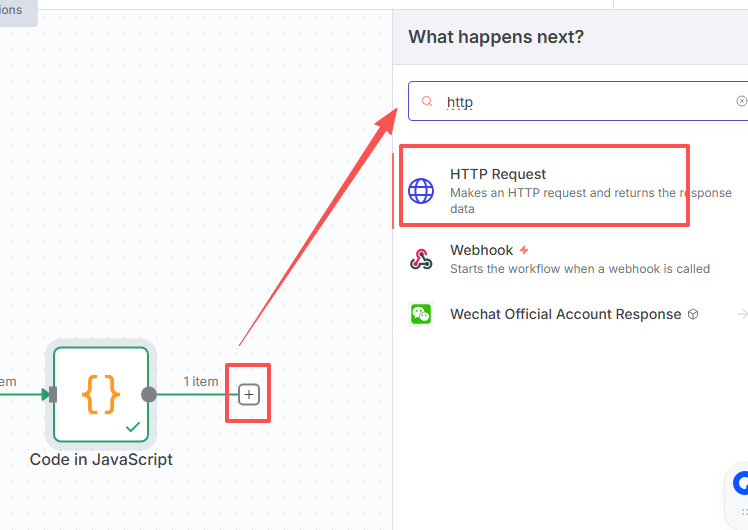
这里我们使用Seedream4.0,这里就不一步一步说明了,具体可以参考:
N8N系列:Seedream4.0 热度冲顶!教你 2 步接入 N8N,小白能入门、老手能落地,这篇实操文看完就会用
最后的配置如下:
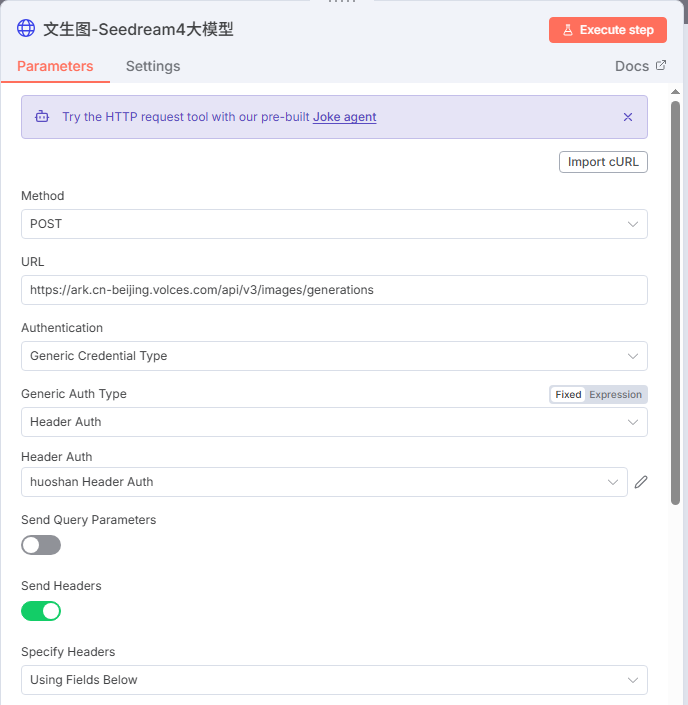
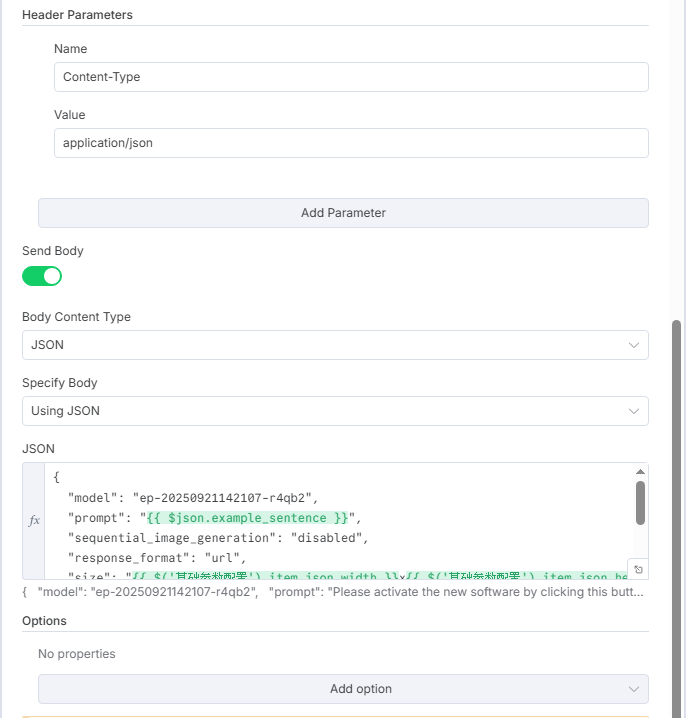
JSON数据如下:
{
"model": "ep-20250921142107-r4qb2",
"prompt": "{{ $json.example_sentence }}",
"sequential_image_generation": "disabled",
"response_format": "url",
"size": "{{ $('基础参数配置').item.json.width }}x{{ $('基础参数配置').item.json.height }}",
"stream": false,
"watermark": true
}
点击运行,如下图:
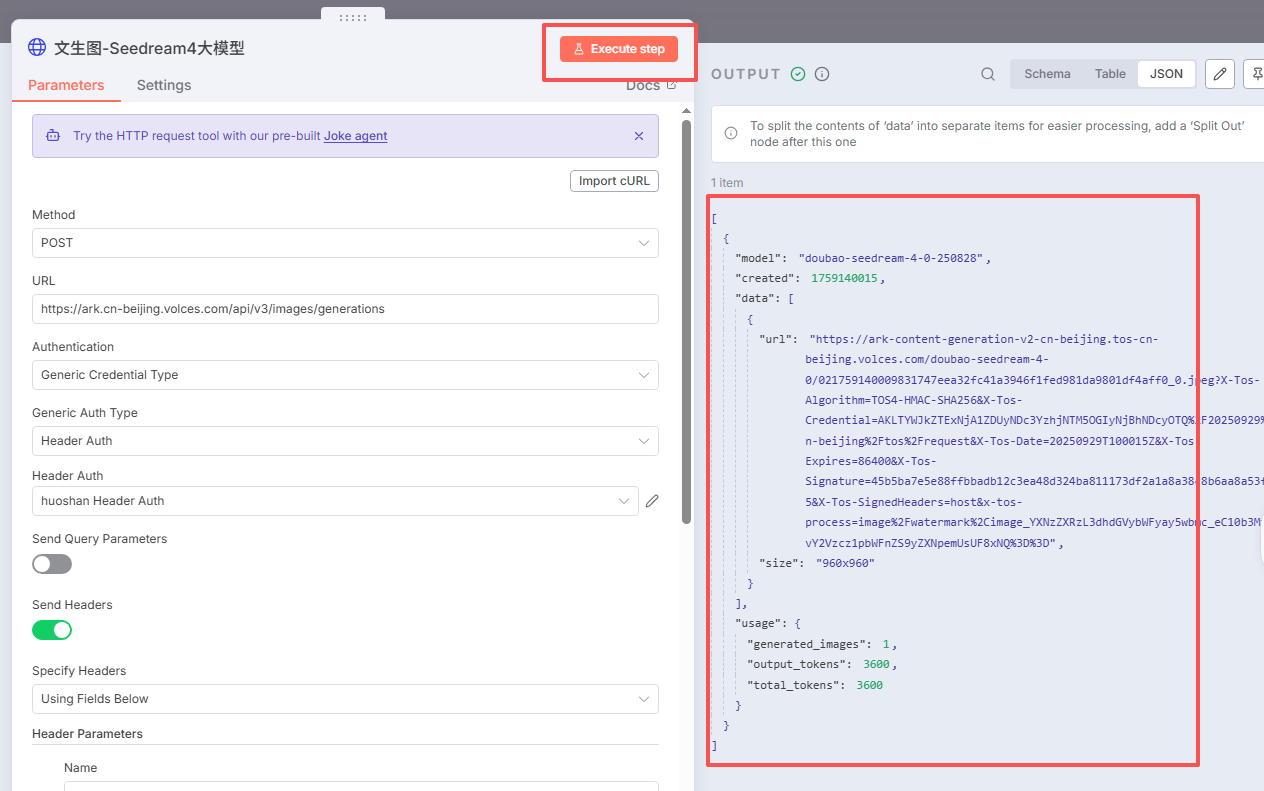
七、下载文生图的图片节点
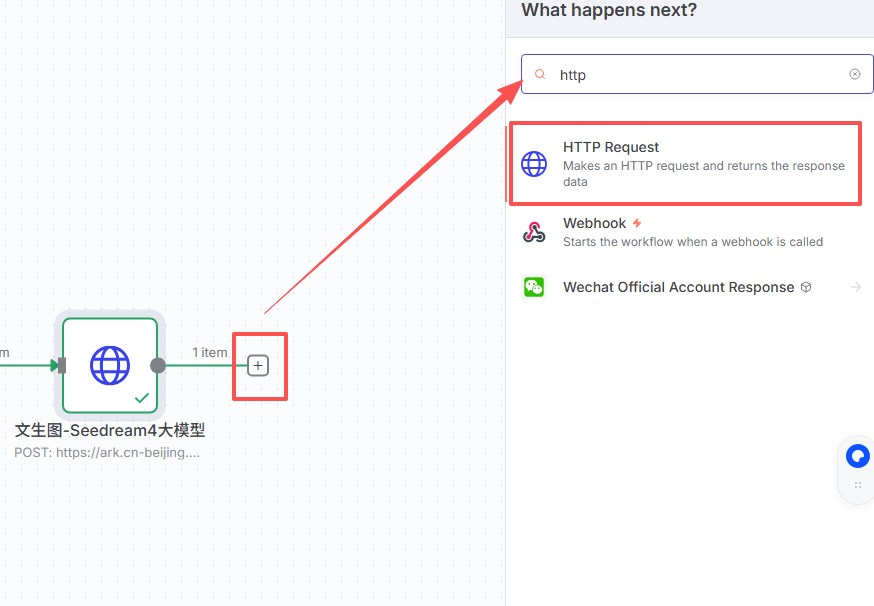
这个节点比较简单,Method使用Get,然后将做的url用鼠标拖到右侧箭头位置。
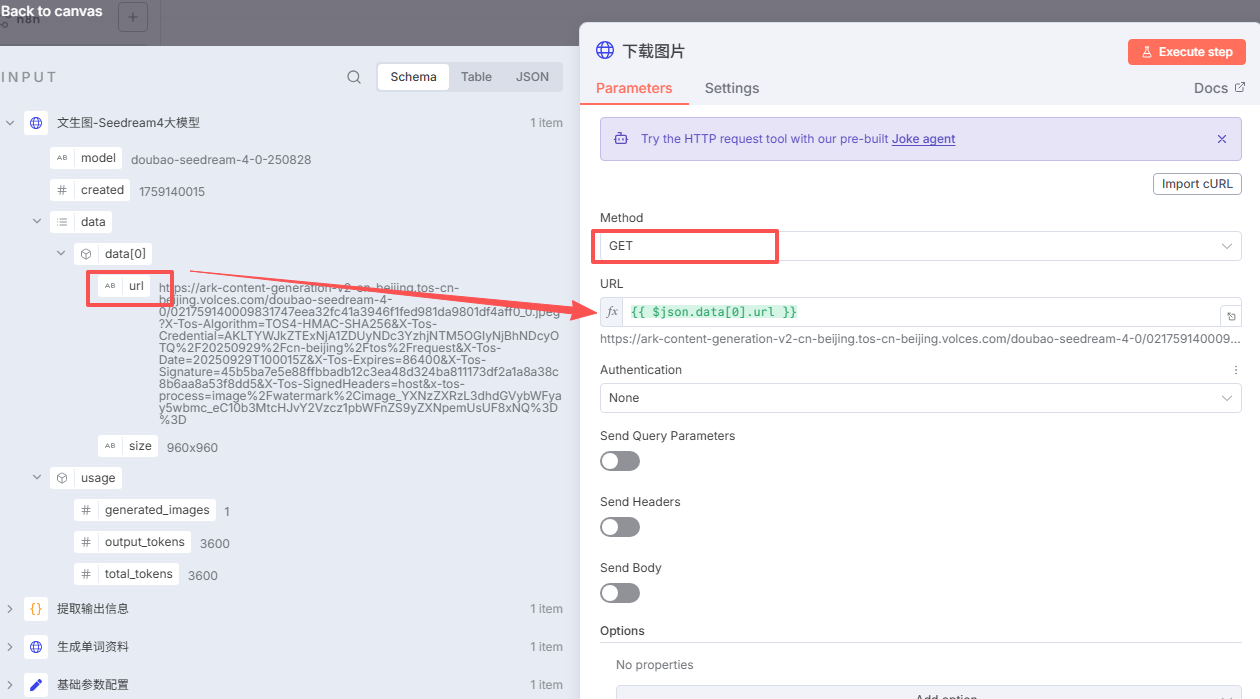
然后点击:Add option,添加:Response
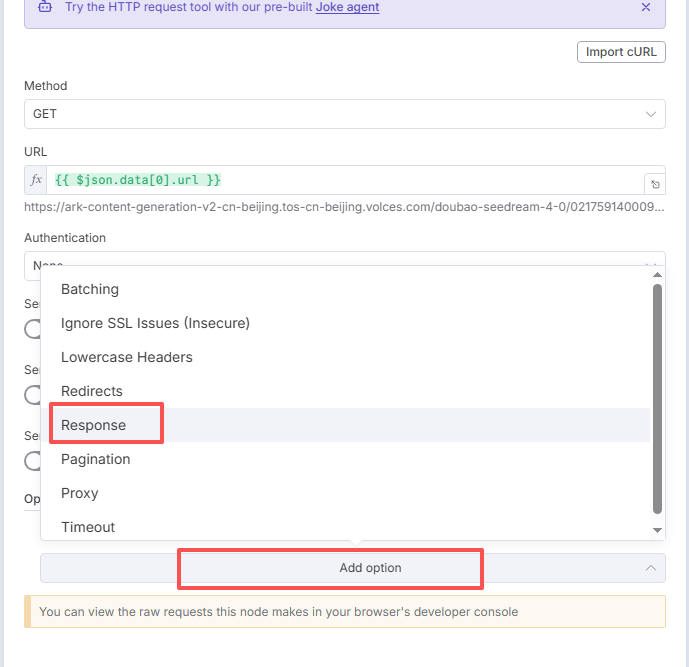
下面的选择:File
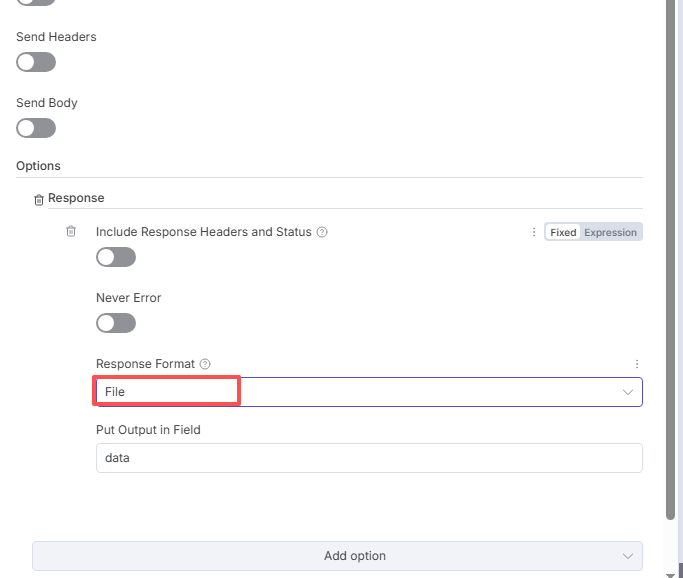
然后点击运行该节点,如下图,下载图片完成
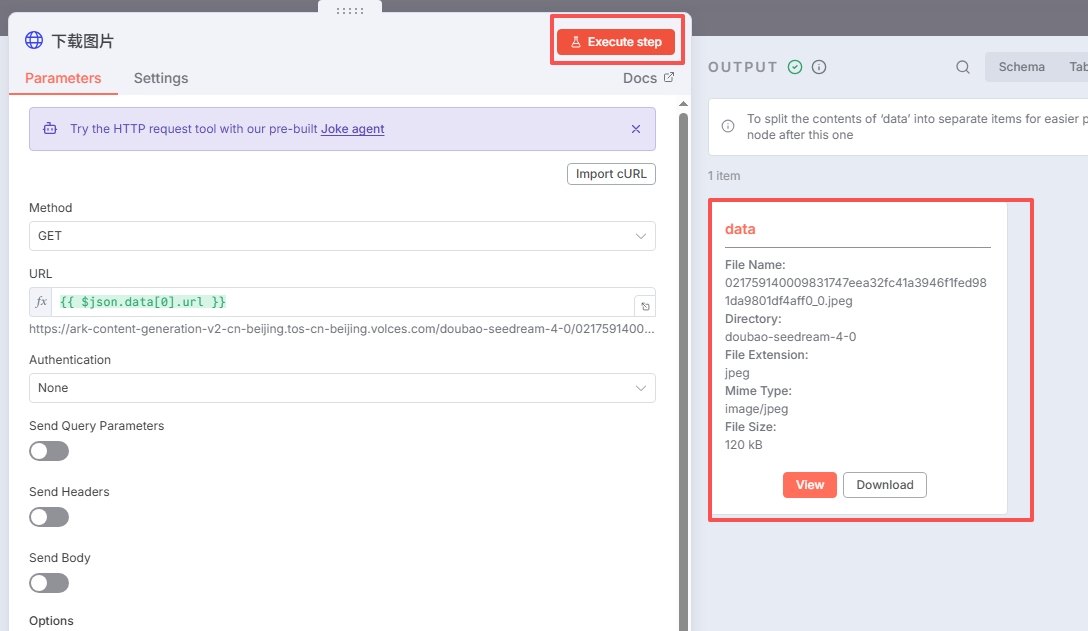
八、生成卡片节点
这个节点的作用是将前面提取的五个数据:单词、音标、中文翻译、英文句子、中文句子,还有刚刚下载的图片一起做成一个有颜值的卡片。
这个节点生成的是HTML格式,可以使用大模型生成,也可以参考我的代码。
选择JavaScript语言
主要注意下这三个地方:
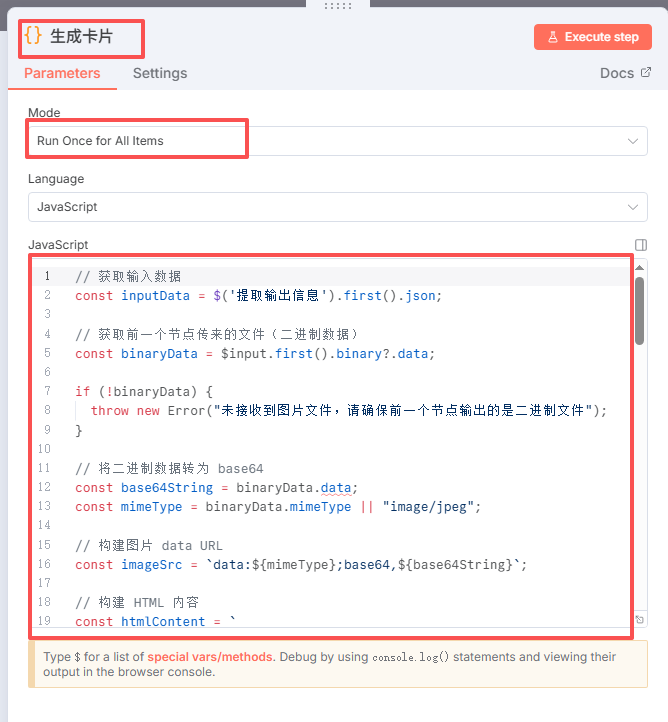
点击运行本节点:
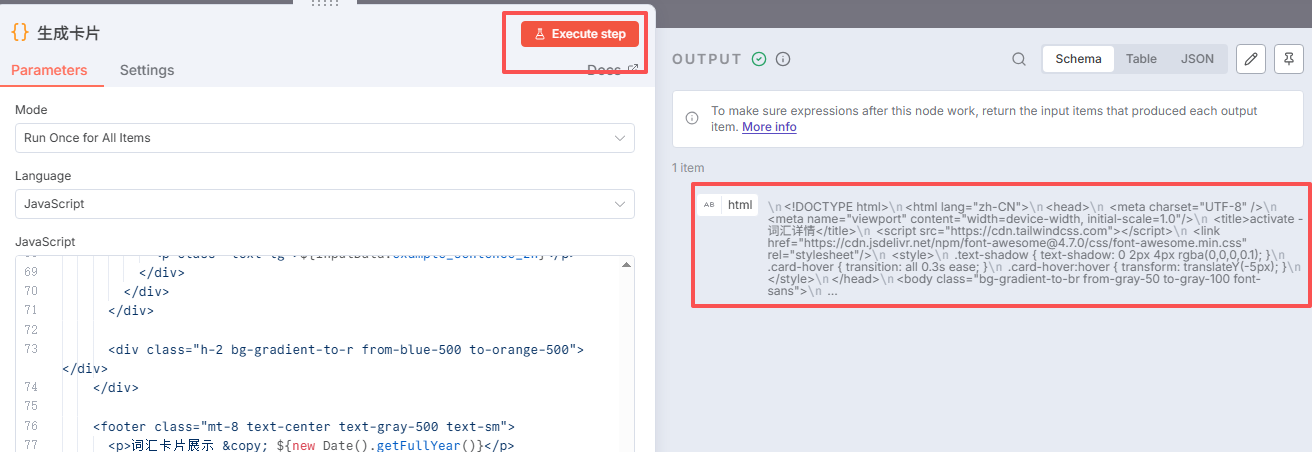
九、HTML转图片节点
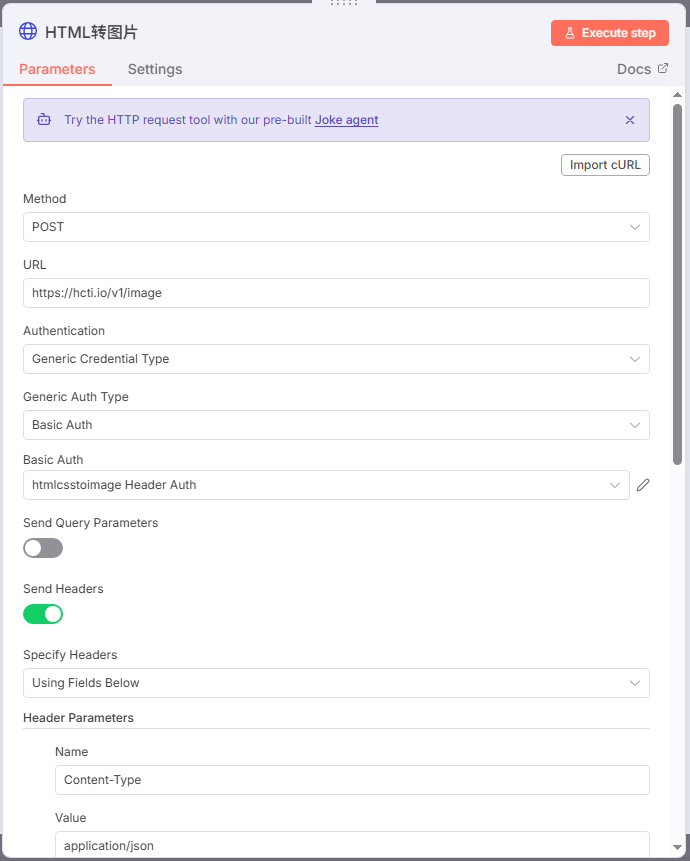
登录https://htmlcsstoimage.com/,获取API KEY
按照第四节方式添加这个平台的凭证:Header Auth
主要配置参数如下:
METHOD:POST
URL: https://hcti.io/v1/image
SEND HEADER里面:
NAME:Content-Type,VALUE: application/json。
其他根据图下配置选即可:
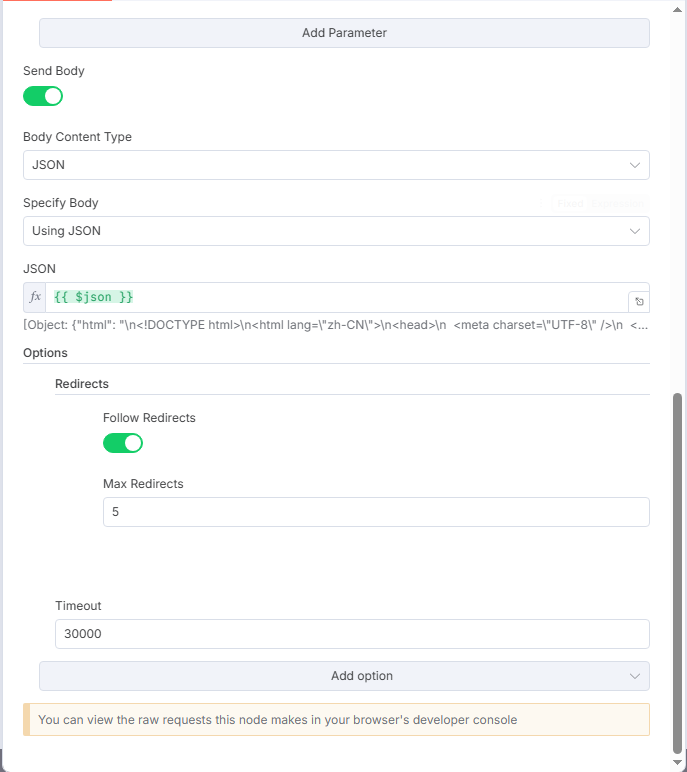
点击运行本节点,输出如下图:
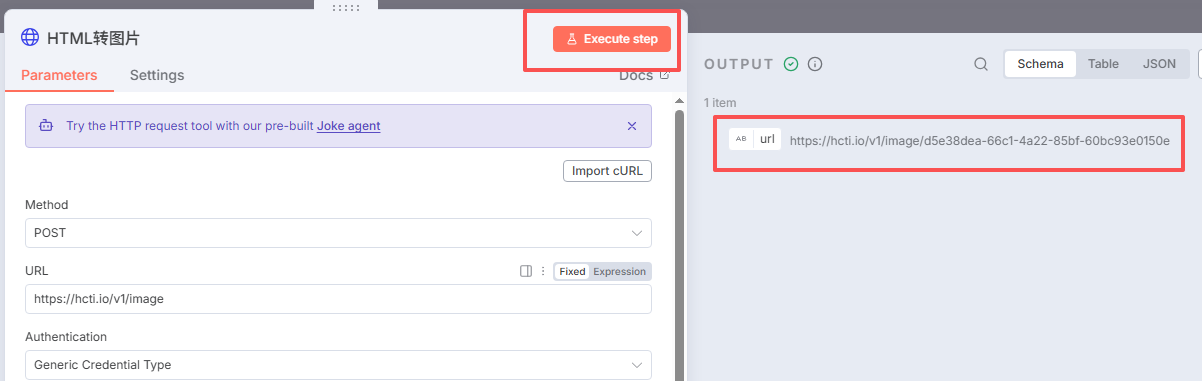
输出有url说明生成成功。
十、下载图片节点
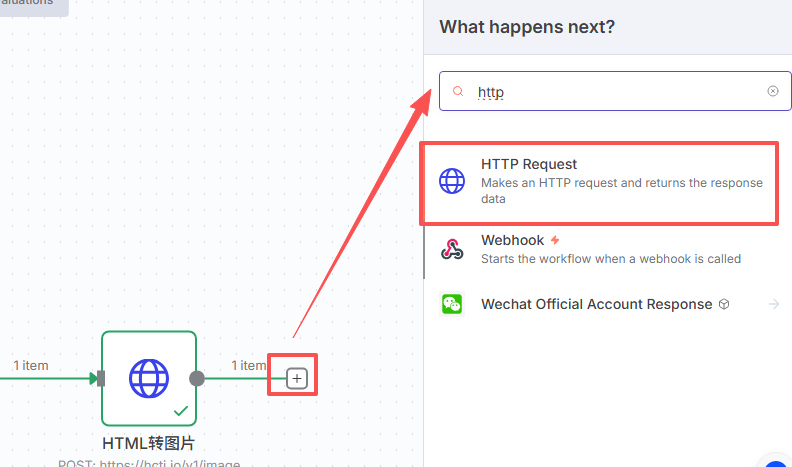
和前面一样,将url拖到箭头位置
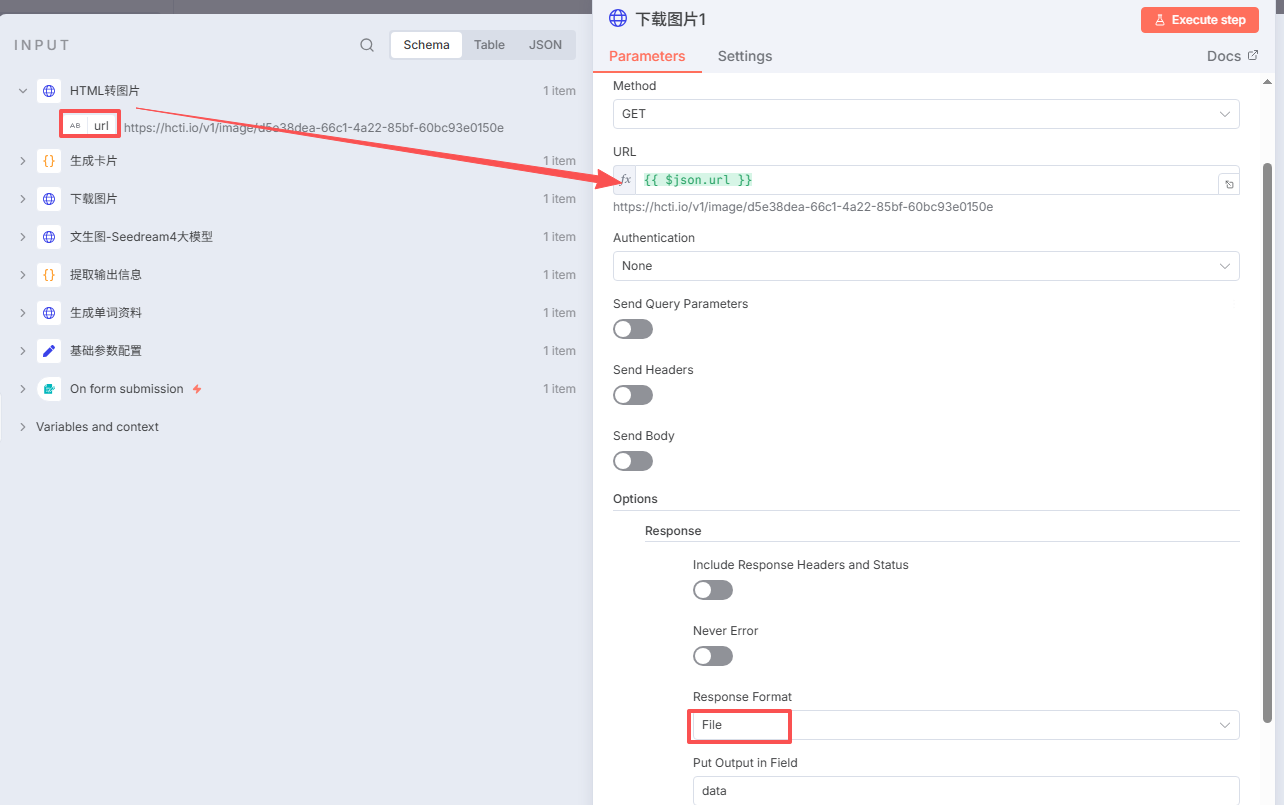
并添加Response,输出格式为File,请参考第七节。
点击运行本节点,如下图:
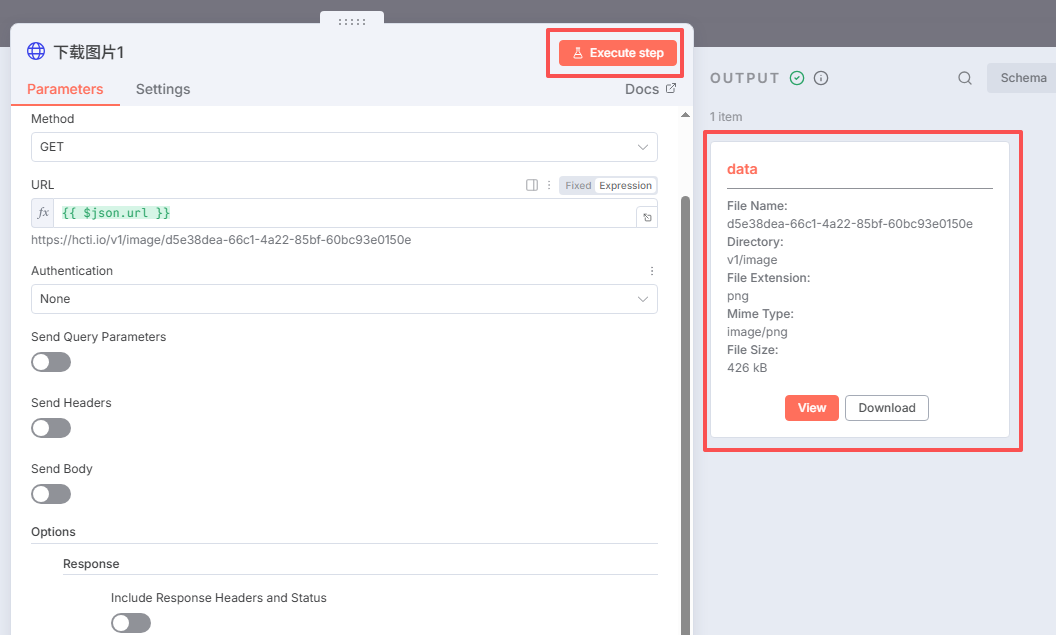
十一、保存英语卡片节点
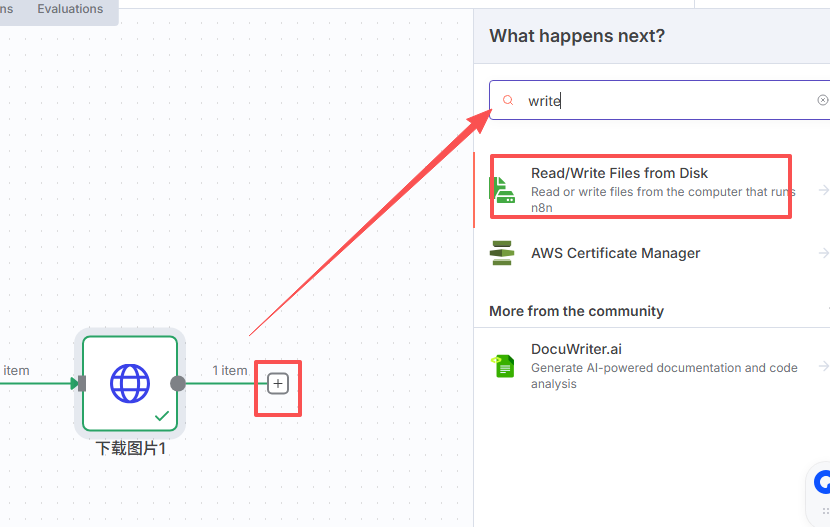
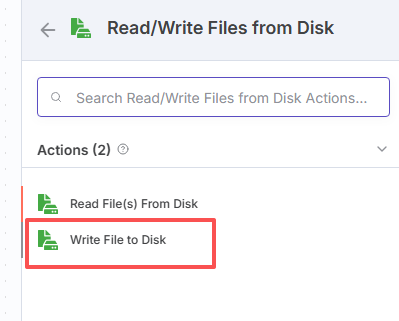
选择:Write Fike to Disk
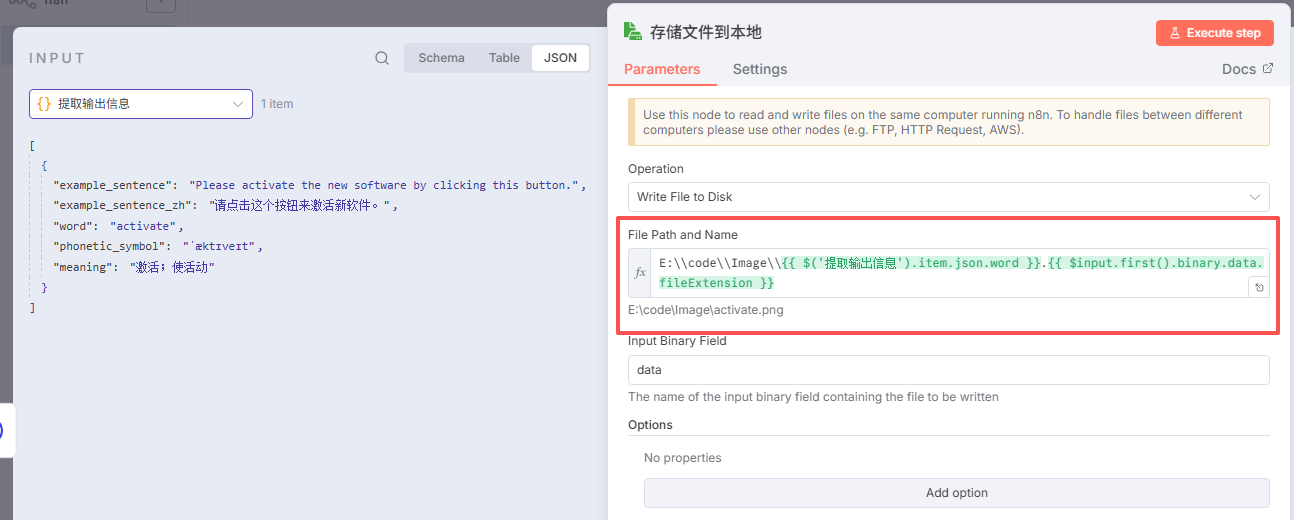
输出的文件名称,我们使用单词作为名称,后缀使用前面自动下载的文件后缀。你可以直接复制:
E:\\code\\Image\\{{ $('提取输出信息').item.json.word }}.{{ $input.first().binary.data.fileExtension }}
点击运行本节点
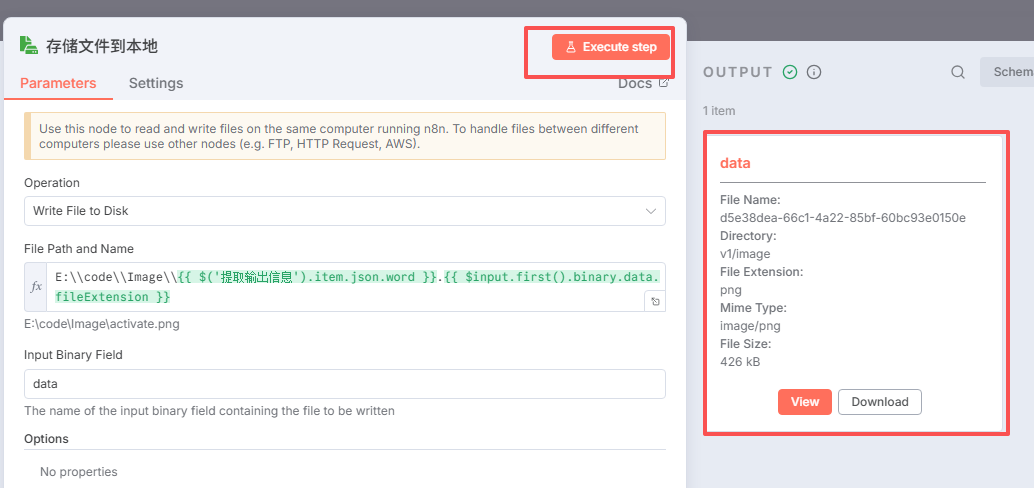
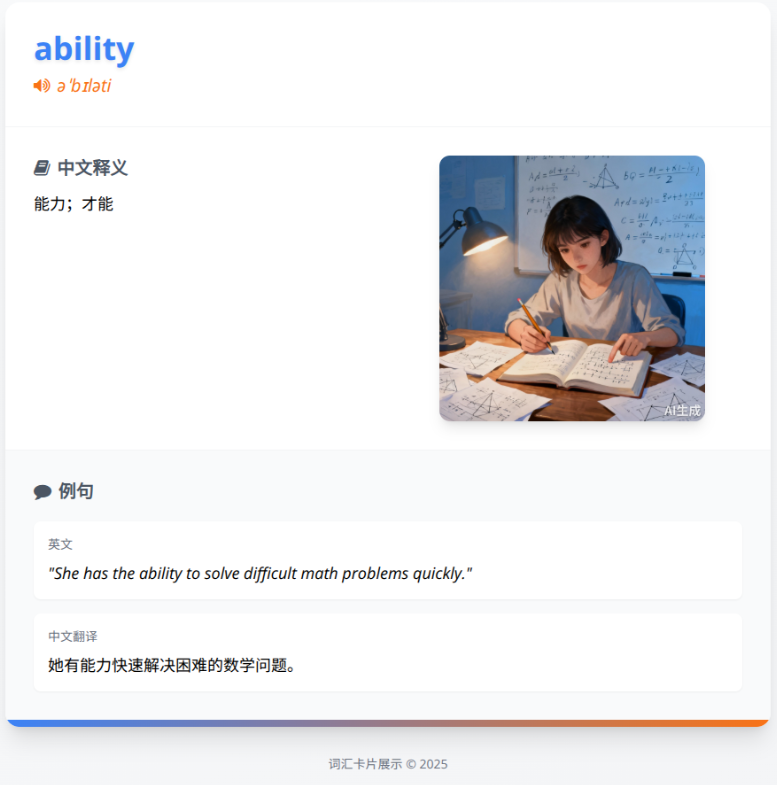
效果如下图:
以上就是今天的分享,希望能够有效果,提升孩子的英语学习成绩。
希望对你有帮助。
本文适合所有正在尝试或计划使用N8N进行开发的朋友。
技术可以变,但底层逻辑永远重要。
如对你有帮助,请关注我,持续分享给懂得思考的您。
更多推荐
 6
6 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)