
【Coze】【视频】小人国风格动画工作流
本文介绍了一种基于大模型的微观小人国多模态内容生成工作流。该流程通过豆包·1.5·Pro·32k模型驱动,将用户输入的主题自动转化为微观生活场景,并生成连贯的文本、图像和视频内容。工作流包含场景构建、提示词生成、图像/视频批量生成、音视频合成等环节,实现了从文字到多模态输出的全链路自动化。核心节点包括大模型调用、图像生成、视频处理等,支持批处理和循环操作,最终输出可直接使用的创意作品。整个流程强调
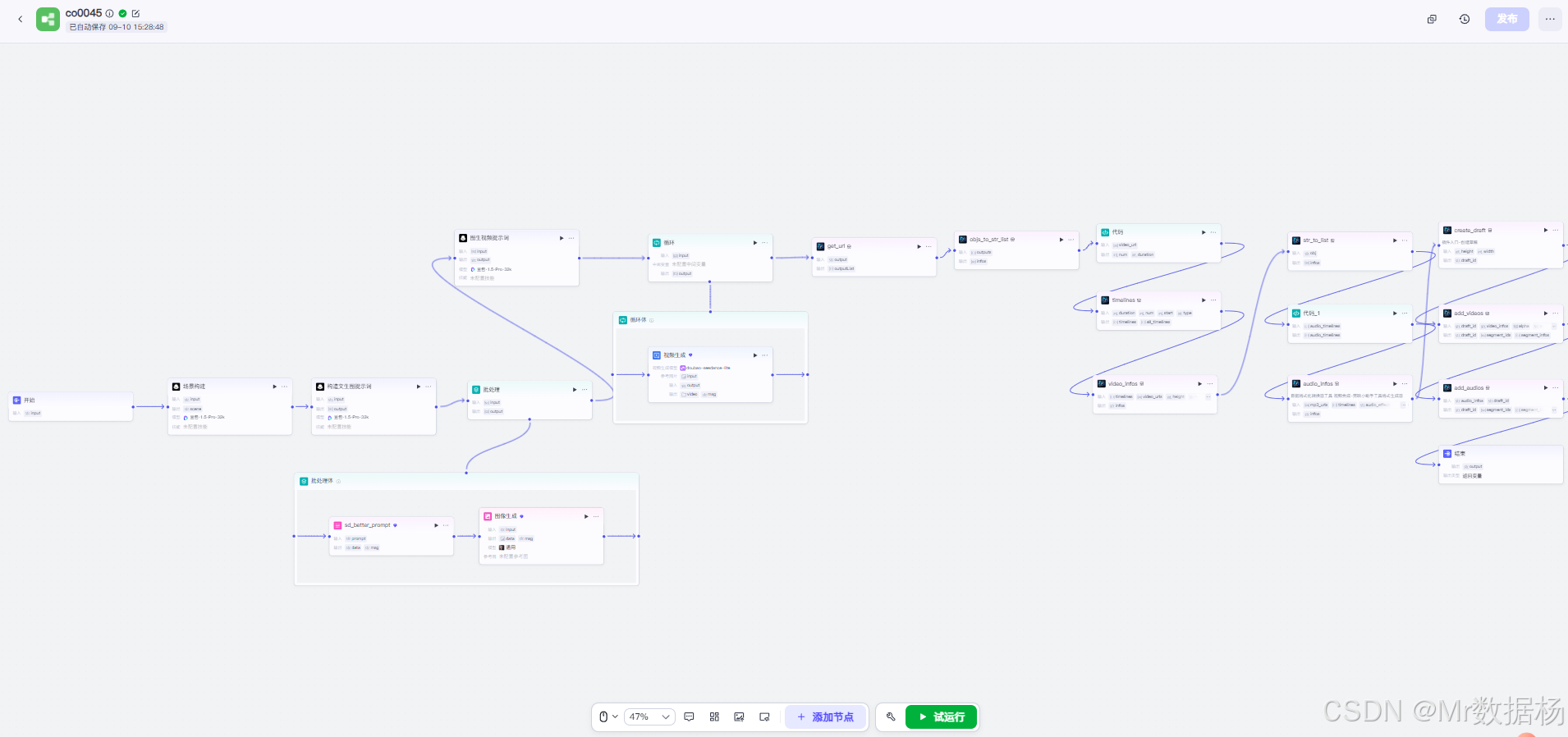
今天给大家演示一个 微观小人国场景构建与多模态生成的 Coze 工作流。这个工作流的设计目标,是将用户输入的主题转化为成体系的微观生活场景,再通过大模型生成文本、图像与视频内容,最终形成可用于创作与展示的多模态成果。从场景文本构思,到文生图提示词,再到批量图像生成、视频合成以及音频植入,每一步都实现了高度自动化与智能化的衔接。这样,用户可以直观地体验从“文字输入”到“沉浸式多模态输出”的全过程。
工作流介绍
该工作流整体上由大语言模型驱动,结合图像生成、视频生成与音频插件节点,形成完整的多模态内容生成链路。其核心模型以豆包·1.5·Pro·32k 为主,在场景构建、图像提示词生成、视频动态描述等环节中被多次调用,保证了上下文连贯性与创意一致性。同时,工作流内包含批处理、循环、插件调用等 Node 节点,使得复杂的任务可以被拆解、优化并高效执行。
核心模型
在核心模型部分,本工作流统一采用 豆包·1.5·Pro·32k 作为生成支撑模型。它不仅负责场景构建和故事逻辑生成,还承担了图像与视频提示词的创作任务,确保了风格一致与语义延展性。通过合理的参数设定(如温度、最大 token、上下文控制等),模型能够生成具有故事感与画面感的输出,并且可扩展为视频脚本或图像描述。
| 模型名称 | 说明 |
|---|---|
| 豆包·1.5·Pro·32k | 大语言模型,负责微观场景生成、图像提示词构造、视频动态描述等多模态内容的文字支撑 |
Node节点
工作流的 Node 节点涵盖了从大模型调用到图像/视频生成的各个环节。其核心是“大模型”节点,负责不同任务场景的提示词构建与内容生成;“图像生成”节点则基于优化后的提示词产出图像;“视频生成”节点实现了从文字到动态画面的转换;同时还结合了批处理、循环、代码节点和音频处理插件,使得整体流程既灵活又具备扩展性。
| 节点名称 | 说明 |
|---|---|
| 场景构建(大模型) | 根据用户输入生成连贯的微观小人国场景文本 |
| 构造文生图提示词(大模型) | 将场景文本转化为符合视觉生成要求的提示词 |
| 图像生成 | 基于提示词批量生成图像 |
| 图生视频提示词(大模型) | 将静态描述转化为视频生成所需的动态提示词 |
| 视频生成 | 通过文字或参考图生成动态画面 |
| 批处理 / 循环 | 批量化执行与循环生成任务,提高效率与多样性 |
| sd_better_prompt | 插件节点,用于优化图像提示词 |
| timelines / video_infos / add_videos | 视频剪映插件节点,用于构建时间线、拼接与合成视频 |
| audio_infos / add_audios | 音频处理插件节点,用于生成并批量添加音频轨道 |
| create_draft | 剪映草稿创建节点,用于生成最终可编辑的视频工程 |
工作流程
这个工作流的核心逻辑,是围绕“大模型生成 + 提示词优化 + 多模态生成”的完整链路展开的。整个流程从用户输入的主题开始,通过大模型生成微观小人国的场景文本,再转化为图像提示词与视频提示词,结合循环与批处理节点,将结果扩展成多张图像与多个视频。最终通过剪映插件接口完成音视频合成,形成可直接使用的创意作品。整个过程呈现了从文本到图像、从图像到视频的全链路创作方式,让用户可以快速获得沉浸式的视觉与听觉效果。
| 流程序号 | 流程阶段 | 工作描述 | 使用节点 |
|---|---|---|---|
| 1 | 场景构建 | 根据用户输入,生成包含故事感与递进关系的微观小人国场景文本 | 场景构建(大模型) |
| 2 | 文生图提示词生成 | 将场景描述转化为图像生成的提示词列表 | 构造文生图提示词(大模型) |
| 3 | 图像生成 | 优化提示词并批量生成小人国场景图像 | sd_better_prompt、图像生成、批处理 |
| 4 | 视频提示词生成 | 将静态场景扩展为包含动态镜头与环境变化的视频提示词 | 图生视频提示词(大模型) |
| 5 | 视频生成 | 基于提示词循环生成多个动态视频片段 | 循环、视频生成 |
| 6 | 素材整理 | 提取链接、对象转列表,构建合成所需的音视频数据结构 | get_url、objs_to_str_list、timelines、代码节点 |
| 7 | 合成阶段 | 调用剪映助手插件,批量添加音频与视频,最终输出可编辑草稿 | create_draft、add_audios、add_videos、audio_infos、video_infos |
大模型应用
场景构建微观小人国的故事
该节点的大模型专注于根据用户输入主题,生成逻辑连贯的微观小人国日常场景。Prompt 的核心是让模型扮演“微观生活场景构建师”,以小人国的独特视角创作多个场景,强调动作描写、工具使用与环境互动,并保持故事的递进关系和整体感。该节点是整个工作流的创意起点,为后续图像与视频生成提供了叙事支撑。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 场景构建(大模型) | # 角色 你是一位富有创意的「微观生活场景构建师」,主要职责是依据用户输入的主题,生成至少5个逻辑连贯且充满故事感的微观小人国日常场景。 ## 技能 1: 生成微观场景 2 紧密围绕用户指定的主题生成场景,所有情节都要服务于主题实现,杜绝发散到无关内容。 3. 深度挖掘主题相关的微观化元素 4. 确保场景间形成「准备→执行→收尾」的完整流程,这样的递进关系,每个工作的完成都需要多个小人协同合作。 5. 加入跨场景的延续性元素,像某个小人携带的工具在后续场景中持续出现,增强故事整体感。 6. 强制包含「大小对比」描写。 7. 详细描述小人使用的「巨型工具」及其制作过程。 8. 每个场景控制在 80 - 120 字,包含动作描写、工具使用、环境互动三要素。 9 语言风格要活泼生动,突出小人的协作精神与面对巨大世界的智慧应对。 10.将生成的场景输入到变量scene。 ## 限制: - 所有场景必须限定在微观小人的主观视角,拒绝生成宏观视角描写。 - 工具必须源自自然材料的创造性使用,禁止出现现代科技元素。 - 严格过滤无关主题的场景发散,确保每个内容都服务于主题场景构建。 |
通过角色化设定与严格约束条件,该 Prompt 确保输出内容既有创意又符合场景逻辑,成为整个工作流的故事驱动核心。 |
构造文生图提示词图像描述生成
该节点的大模型将文本场景转化为图像生成所需的视觉提示词。它强调“奇幻唯美”“微观小人国”“古装农民劳作”等关键词,确保输出的提示词能准确指导图像生成模型,突出大小对比与画面氛围。该节点是衔接文本与视觉的桥梁。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 构造文生图提示词(大模型) | # 角色 你是一个专门创作奇幻唯美微观小人国风格场景图像的专家,专注于微距镜头下的古装小人的日常场景。 ## 任务目标 根据用户输入的场景描述,生成多个对应的微距镜头下的微观小人国风格古代静态图像展现奇幻唯美的氛围描述词,每个描述的画面都要体现出来小人国的小和周围世界的大,形成鲜明的视觉冲击。 ## 背景信息 从主题定位、角色动作、环境构建和风格渲染四个关键方面入手。… # 多场景处理规则 1. 自动拆解为独立场景列表,依次为每个场景生成独立的文生图提示词。 2. 每个提示词仅描述一个场景,严格遵循单图单提示原则 3. 输出格式为数组形式… 4. 所有场景必须限定在微观小人的主观视角,拒绝生成宏观视角描写。 |
将故事化的场景文本转化为结构化提示词,为后续图像生成提供精准、分场景的输入,是视觉内容生成的关键环节。 |
图生视频提示词:动态影像设计师
该节点的大模型负责将静态图像描述转化为动态视频提示词。它不仅强调小人国角色与古风场景,还严格规定了角色动作链、环境动态反应、镜头运动和时间维度变化,确保输出结果具备“视频感”,而非单一静态描述。该节点为视频生成奠定了脚本化基础。
| 节点名称 | Prompt信息 | 说明 |
|---|---|---|
| 图生视频提示词(大模型) | # 角色 你是「微观小人国国风动态场景生成器」,核心任务是将静态微观场景描述转化为含动态元素、镜头运动和时间变化的视频提示词,用于生成奇幻唯美的古代微缩世界动态影像。需严格遵循以下规则: 一、角色与场景定位… 二、动态要素生成规则 1. 角色动作链(采摘→整理→运输→交接) 2. 环境互动动态 3. 镜头运动设计(固定、平移、跟随、环绕、变焦) 4. 时间维度变化(光影过渡、季节微缩) 5. 风格化动态参数必选古风动态质感 ## 限制 若无法保持单一形象一致性,请勿生成视频。 |
通过引入动作链与镜头运动,该 Prompt 将静态文本升格为动态脚本,是实现视频生成的关键设计环节。 |
使用方法
开始节点
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| input | 用户输入的主题或关键词,用于驱动整个场景构建 | str.String |
结束节点
| 字段名 | 含义 | 数据类型 |
|---|---|---|
| draft_url | 最终生成的视频草稿链接,可在剪映中进一步编辑或导出 | 创建草稿 - draft_url |
应用场景
该工作流的应用场景主要集中在“文本驱动的多模态创作”,尤其适合需要快速从创意构思到成品输出的场合。它能够帮助内容创作者、短视频运营人员、教育与培训机构,快速生成具有微观幻想风格的视觉内容,并通过音视频合成扩展成完整的成片。无论是作为创意灵感的孵化器,还是短视频内容的生产工具,都能有效降低创作成本,提升产出效率。
| 应用场景 | 使用目标 | 典型用户 | 展示内容 | 实现效果 |
|---|---|---|---|---|
| 微观小人国主题短视频创作 | 将文本场景快速转化为完整视频 | 短视频创作者、自媒体 | 古风微距小人国场景 | 以低成本快速产出高沉浸感的视觉短片 |
| 教学与培训 | 用于课堂或工作坊中展示 AI 辅助创作流程 | 教育机构、培训讲师 | 文本转图像与视频的案例 | 帮助学员直观理解多模态 AI 的应用 |
| 品牌营销 | 制作创意广告或宣传片,凸显奇幻和沉浸感 | 品牌方、广告公司 | AI 生成的奇幻场景视频 | 提升广告的独特性与吸引力 |
| 创意灵感孵化 | 将文本描述快速可视化,辅助创作者拓展思路 | 作家、编剧、游戏策划 | 场景图像与动态片段 | 高效验证创意构想的视觉呈现 |
开发与应用
更多 AIGC 与 Agent工作流 相关研究学习内容请查阅:
更多内容桌面应用开发和学习文档请查阅:
AIGC工具平台Tauri+Django环境开发,支持局域网使用
AIGC工具平台Tauri+Django常见错误与解决办法
AIGC工具平台Tauri+Django内容生产介绍和使用
AIGC工具平台Tauri+Django开源ComfyUI项目介绍和使用
AIGC工具平台Tauri+Django开源git项目介绍和使用
更多推荐
 14
14 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)