
人形机器人专用大模型发布:会走、会坐、还能一键学新招!
作者认为,这一问题的根源在于缺乏跨任务的统一表述。受到其他领域中基础模型成功经验的启发,作者提出,如果能在大规模、多样化的行为数据上进行预训练,就有可能学习到广泛且可复用的行为知识,并应用于各种下游任务。为了解决这一挑战,作者重新审视了现有系统的设计,并提出一个关键观察:尽管控制模式不同,但这些系统的结果(无论是行走还是跳舞)在本质上都是人形机器人的行为。与以往局限在特定任务或控制模式的方法不同,
导读
如果说人形机器人要真正走向通用化,最关键的一点就是:它们必须具备像人一样灵活多变的行为能力。走路、坐下、站起,甚至翻滚、腾空——这些都属于全身控制(Whole-body Control, WBC)的范畴。然而,现有的方法往往是“专用型”的:要么只能响应速度指令,要么只能跟踪参考动作,切换任务时几乎需要重新训练,既费时又缺乏泛化性。
来自北京大学、港中大(深圳)、上海交大、复旦大学和上海人工智能实验室的研究团队提出了 Behavior Foundation Model (BFM),尝试为人形机器人打造“通用行为大模型”。它的核心思想是:无论是语言指令、VR 信号,还是动作参考,本质上都只是描述“行为”的不同方式。因此,研究者把各种任务统一到“行为生成”这个共同目标之下,并用大规模行为数据进行预训练。
BFM 融合了 掩码蒸馏(Masked Distillation) 与 条件变分自编码器(CVAE),不仅能应对任意控制模式,还能在不从头训练的情况下快速学会新动作。实验表明,无论是在仿真还是在真实的人形机器人平台上,BFM 都能稳定地展示跨任务的泛化能力,并且具备组合与调节行为的潜力。可以说,这为“通用人形机器人”的落地奠定了重要一步。

图1|行为基础模型(BFM)使人形机器人能够以零样本的方式完成多种动作,包括 (1) 游泳姿势、(2) 坐到地面、(3) 从地面站起、(4) 蝴蝶踢。同时,它还能高效习得新的动作,例如 (5) 前滚翻 和 (6) 侧空翻
论文出处:arXiv2025
论文标题:Behavior Foundation Model for Humanoid Robots
论文作者:Weishuai Zeng, Shunlin Lu, Kangning Yin, Xiaojie Niu, Minyue Dai, Jingbo Wang, Jiangmiao Pang

人形机器人能够执行广泛的全身控制任务,包括语言交互、远程操作以及全身动作跟踪。尽管在任务多样性方面已有显著进展,但现有的控制系统通常被设计为针对特定的控制模式。例如,动作跟踪策略只能接受参考动作输入,而步行策略则只能响应速度指令。这种对控制模式的刚性限定阻碍了跨任务的泛化能力:一个步行策略无法直接利用参考动作完成全身动作跟踪。近期有研究尝试通过掩码策略支持多控制模式,但这些方法要么仅限于简化的虚拟角色,要么局限于一组固定的控制模式,因此无法在真实人形机器人上支持任意控制模式。作者认为,这一问题的根源在于缺乏跨任务的统一表述。
为了解决这一挑战,作者重新审视了现有系统的设计,并提出一个关键观察:尽管控制模式不同,但这些系统的结果(无论是行走还是跳舞)在本质上都是人形机器人的行为。因此,行为可以自然地作为跨任务的统一表述。在这一视角下,任务特定的控制模式(如速度指令、VR 信号或参考动作)都可以理解为对行为的不同描述方式。
此外,一个行为往往可以通过多种控制模式来指定。例如,“向前行走”这一行为既可以在运动控制设置下学习,也可以在动作跟踪设置中学习。这表明,尽管控制模式多样,但现有系统最终追求的目标是一致的:生成合适的机器人行为。这一观点促使作者提出将行为与控制模式解耦,从而实现由“孤立任务学习”向“统一行为学习”的范式转变。受到其他领域中基础模型成功经验的启发,作者提出,如果能在大规模、多样化的行为数据上进行预训练,就有可能学习到广泛且可复用的行为知识,并应用于各种下游任务。
基于这一思路,作者提出了 Behavior Foundation Model (BFM),这是一个为人形机器人设计的生成式模型,能够在大规模行为数据集上进行预训练,从而捕获广泛的可复用行为知识。BFM 可以直接通过多样化的控制模式驱动完成相应任务,同时也能在无需从零训练的情况下高效学习新行为。总体而言,BFM 建立了一个灵活且可泛化的人形机器人控制框架,展示了其作为下一代系统设计基础的潜力。
为实现这一愿景,作者首先采用动作模仿作为通用的行为抽象,在仿真环境中训练Agent模型。随后,结合掩码在线蒸馏框架与条件变分自编码器(CVAE)进行预训练,从而获得既能支持多控制模式,又具备结构化潜在空间的模型,为行为组合与调节提供了可能。此外,作者还将残差学习引入框架,使得模型能够在已有知识的基础上快速习得新行为。正如图 1 所示,该框架在真实部署中展现了高度的多样性与鲁棒性。
总之,本文的主要贡献包括:
1. 提出 Behavior Foundation Model (BFM),将人形机器人控制的范式从任务学习转向统一的行为学习;
2. 展示了融合掩码在线蒸馏与 CVAE 的框架,能够直接驱动多样化的任务,并通过残差学习高效获取新行为,无需从头训练;
3. 在仿真与真实人形机器人上的大量实验验证了 BFM 的表现力与有效性,凸显了其作为通用人形机器人基础模型的潜力
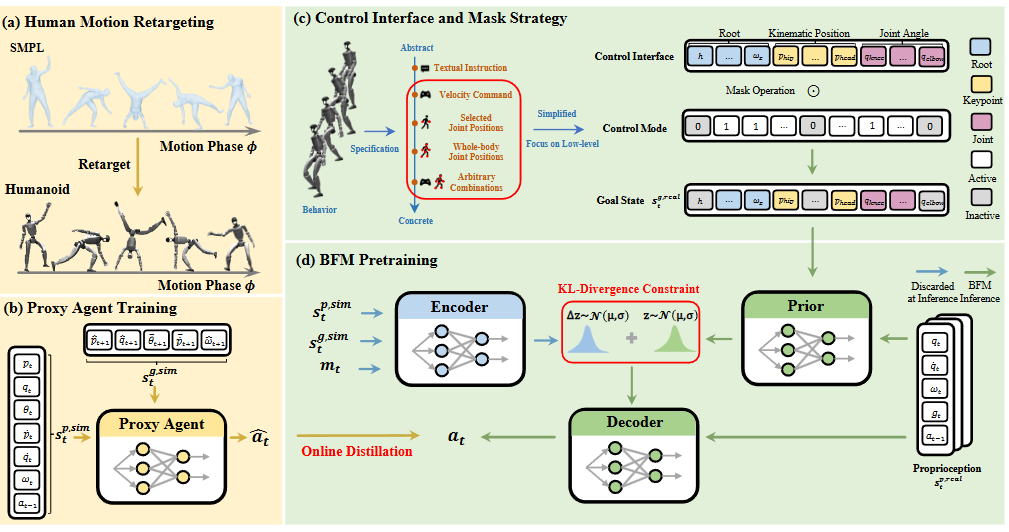
图2|BFM 的实现概览。(a) 将人体动作数据集重定向到人形机器人,用于Agent训练。(b) Agent通过动作模仿进行训练,并在仿真器中获取完整信息。(c) 同一个行为可以通过多种控制模式来指定,从抽象的文本指令到具体的全身关节位置,均可形成不同的目标状态。作者将不同控制模式的激活简化为对统一控制接口施加掩码。该接口仅涵盖根部控制、关键部位位置以及关节角度,突出了本文聚焦于低层次人形控制的目标。(d) 使用 CVAE 对 BFM 进行建模,并结合 DAgger 框架完成预训练,从而在结构化潜在空间中编码丰富的行为知识

Agent训练(Proxy Agent Training)
1. 强化学习下的行为建模
作者将人形机器人控制问题形式化为一个基于目标的强化学习任务。在该任务中,策略需要根据机器人自身的状态以及给定的目标状态来选择关节动作,从而推动机器人朝着目标前进。
● 状态由机器人本体感知(如关节位置、速度、角速度等)和目标状态组成。
● 动作为关节的期望位置,随后通过 PD 控制器转化为实际力矩,驱动机器人关节。
● 奖励函数根据当前状态与目标状态之间的差异来定义,从而引导策略逐步逼近参考动作。
在此定义下,行为被描述为机器人感知状态和动作随时间的轨迹。需要注意的是,作者刻意将任务相关的目标状态排除在轨迹定义之外,因为这些目标被视为驱动行为生成的外部动机。这样处理能够避免在训练初期就对控制模式进行预设,使“行为”成为跨任务的统一表述。
为了区分真实部署与仿真中的信息,作者将仿真环境中可见的“特权状态”与真实机器人可观测的状态进行了区分。在实际应用中,行为轨迹由真实可感知的状态和相应动作构成。
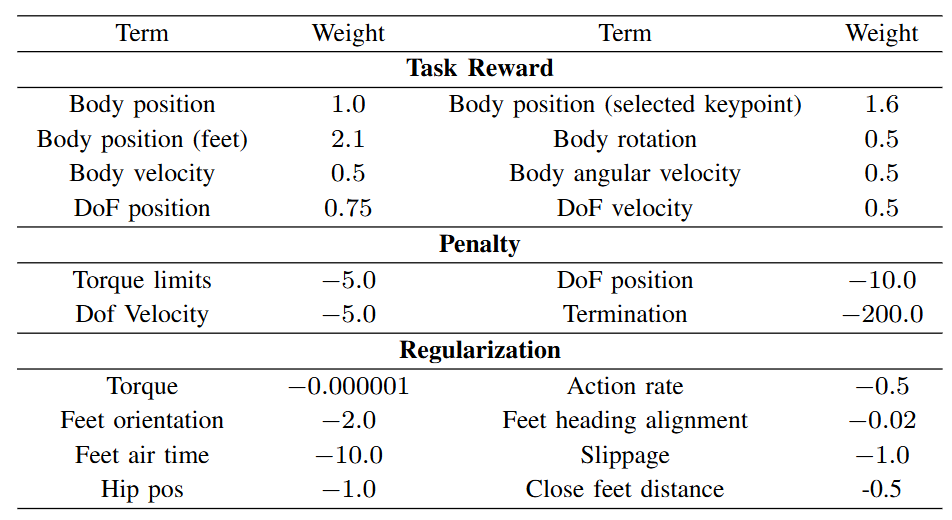
图3|Agent训练中的奖励设计
2. 人体动作的重定向
高质量的人体动作数据是构建机器人行为数据集的重要来源。作者选择了 AMASS 数据集,其中的动作基于 SMPL 人体模型进行参数化。由于 SMPL 模型与人形机器人在形体和结构上存在差异,作者采用两阶段的重定向方法:
1. 首先优化 SMPL 模型的形状参数,使其在静止姿态下尽可能贴合机器人关节与肢体。
2. 随后优化机器人在整个动作序列中的根部平移、旋转和关节位置,使其能够最大限度地贴近人体动作轨迹。
为了保证动作自然,作者在优化过程中引入了正则化约束,以避免过于激进的动作并维持时序平滑性。与部分依赖模仿器过滤数据的方法不同,这里直接使用了原始数据集来进行预训练准备。
3. 通过动作模仿训练Agent
不同于将行为数据整理为离线轨迹直接用于预训练,作者先训练了一个Agent策略(proxy agent),通过动作模仿来生成可用的行为数据。该Agent能够根据当前状态与目标状态输出关节动作,从而通过在线滚动的方式产生大量行为轨迹。
● 状态设计:Agent的输入包含仿真环境中的完整本体信息(位置、关节、姿态、速度等),以及目标状态(即参考动作与当前动作之间的差值)。
● 奖励函数:由三部分组成,包括模仿任务奖励、正则化项和惩罚项。任务奖励衡量动作与参考动作的一致性;正则化用于约束控制信号;惩罚项则避免过大力矩或姿态失衡。
● 域随机化:在训练中引入动力学参数扰动和外部推力,以提升策略的泛化能力。
● 初始化与终止:采用随机起始状态初始化,并在轨迹偏离过大时提前终止,以避免无效数据收集。
● 难样本挖掘:在大规模数据集上训练时,Agent容易忽略难以模仿的动作。为此,作者动态调整样本采样概率,对失败样本增加权重,并最终过滤掉始终无法学会的动作序列。
BFM 预训练(BFM Pretraining)
1. 基于强化学习的预训练目标
BFM 被定义为一个生成模型,目标是学习演示行为的分布。具体而言,就是在给定机器人状态的情况下,预测最合理的动作分布。
● 原始目标是最大化整套数据中状态–动作对的对数似然。
● 为了建模任务的通用性,作者将目标状态作为额外条件引入,使策略能够在不同控制模式下灵活生成动作。
● 通过数学推导,最终的训练目标转化为对条件似然的下界进行最大化,从而使预训练过程可行。
2. 真实环境的状态设计
在真实机器人中,可用的感知状态有限。作者将状态定义为:过去若干时间步内的关节位置、关节速度、根部角速度、重力方向以及最近一次的动作指令。这些信息被堆叠后作为输入,以补充时序上下文。
3. 控制接口与掩码策略
不同的控制模式会导致不同的目标状态。例如,“前进”这一行为可以通过文本指令、速度命令或关节角度来指定。为了统一处理,作者设计了一个低层次的控制接口,包含根部控制、关键部位位置控制和关节角度控制。
● 通过对接口中的元素施加二进制掩码,可以激活或关闭不同的控制模式。
● 与以往需要两阶段掩码的做法不同,这里直接采用随机采样方式,使系统能够自然支持任意控制模式。
● 为了稳定训练,作者引入了“掩码课程”,即在初始阶段使用确定性掩码,随后逐渐过渡到随机采样。
4. 基于条件变分自编码器(CVAE)的建模
为了获得结构化的潜在空间,作者采用了条件变分自编码器(CVAE)。
● CVAE 的目标是最大化条件下动作生成的对数概率。
● 模型包含先验分布、编码器和解码器,均假设为高斯分布。
● 在设计中,解码器不直接接收目标状态输入,以鼓励潜在空间捕捉更丰富的行为知识。
● 编码器被设计为对先验的残差,并接收当前掩码作为额外输入,从而提高潜在变量的区分能力。
5. 在线蒸馏
利用Agent策略作为教师,作者采用 DAgger 框架进行在线蒸馏。
● 在仿真中运行 BFM,采集轨迹,并通过Agent生成的参考动作进行监督。
● 损失函数由两个部分组成:重建误差(当前 BFM 动作与参考动作之间的差异)和 KL 散度(潜在空间与先验的差异)。
● 在训练过程中,仍保持与Agent相同的随机化和终止条件,以保证一致性。

作者围绕三个核心问题展开实验验证:
1. BFM 是否能够在多种控制模式下统一建模,并展现跨任务的泛化能力?
2. BFM 是否具备行为组合与调节能力?
3. BFM 能否在仿真和真实机器人中快速适应新任务?
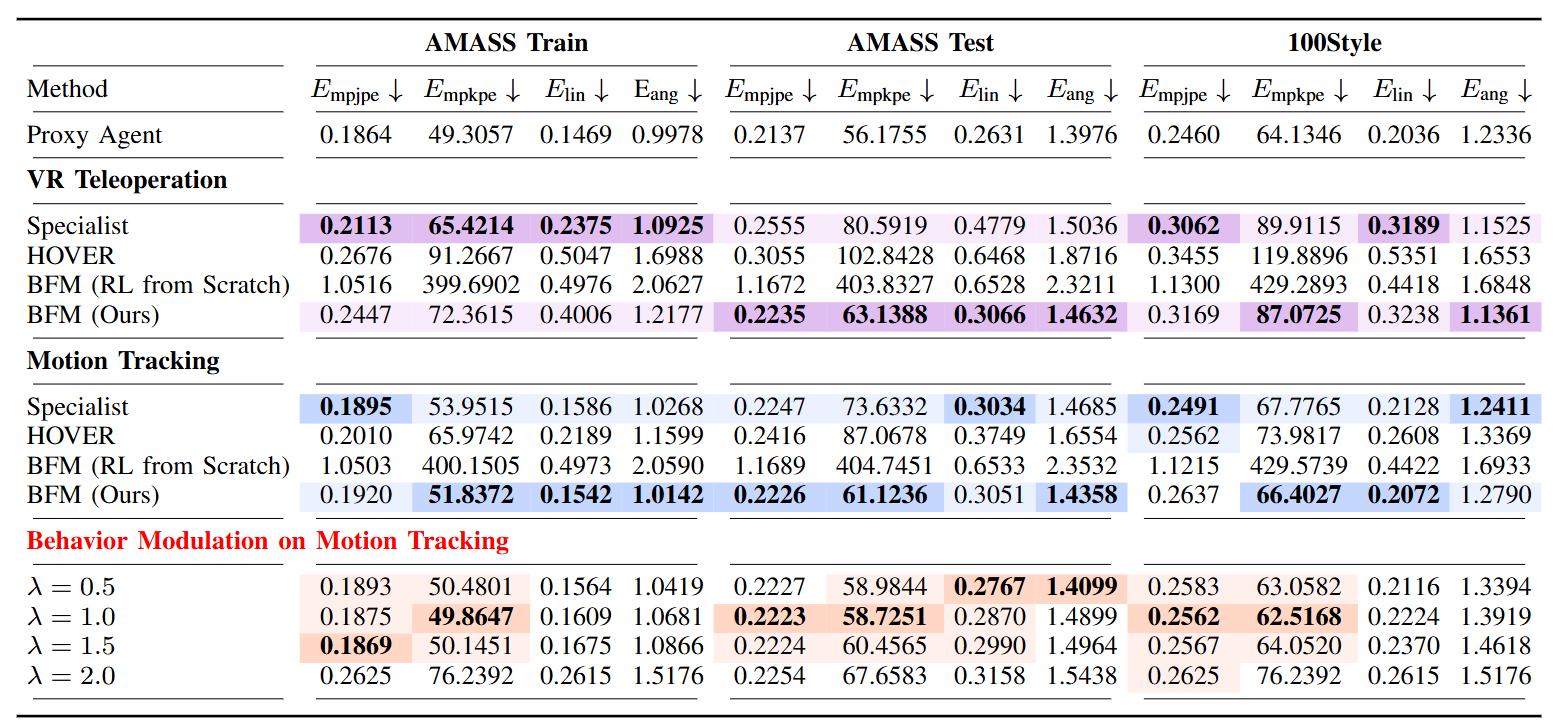
图4|在 VR 远程操作和动作跟踪任务中对 BFM 与基线方法的仿真评估。最优结果以加粗形式显示并用深色背景标记,次优结果则用浅色背景标记。在动作跟踪任务的行为调节实验中,相较于 BFM 提升幅度最大的结果以加粗并深色背景标记,存在提升但并非最优的结果则以浅色背景标记
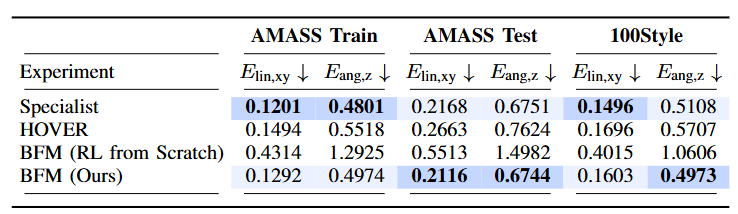
图5|在三个数据集上的运动任务中,对 BFM 与基线方法的仿真评估。最优结果以加粗形式显示并用深色背景标记,次优结果则用浅色背景标记
1. 多控制模式的泛化能力
● 对比方法:作者将 BFM 与现有的 WBC 系统(如速度指令跟踪、动作模仿等单任务策略)进行比较。
● 评估指标:成功率、动作误差、姿态稳定性。
● 结果:
○ BFM 在多任务场景中保持了高成功率和低误差,性能显著超过单任务基线。
○ 在动作跟踪、速度指令和混合控制三种模式下,BFM 都能稳定生成合理的动作。
● 消融实验:去掉掩码机制或 CVAE 结构后,模型的跨模式表现明显下降。
2. 行为组合与调节
● 作者展示了 BFM 在结构化潜在空间下的特性:
○ 不同潜在变量对应不同的动作风格,线性插值可以自然地生成过渡动作。
○ 在“跳跃+旋转”的任务中,BFM 能够通过潜在空间的组合生成全新的复合行为。
○ 在速度控制任务中,调节潜在变量的取值可以实现不同幅度的步态切换。
● 直观效果:实验视频显示,BFM 能够在“跑步”与“挥手”等任务之间实现流畅的过渡,而不需要额外训练。
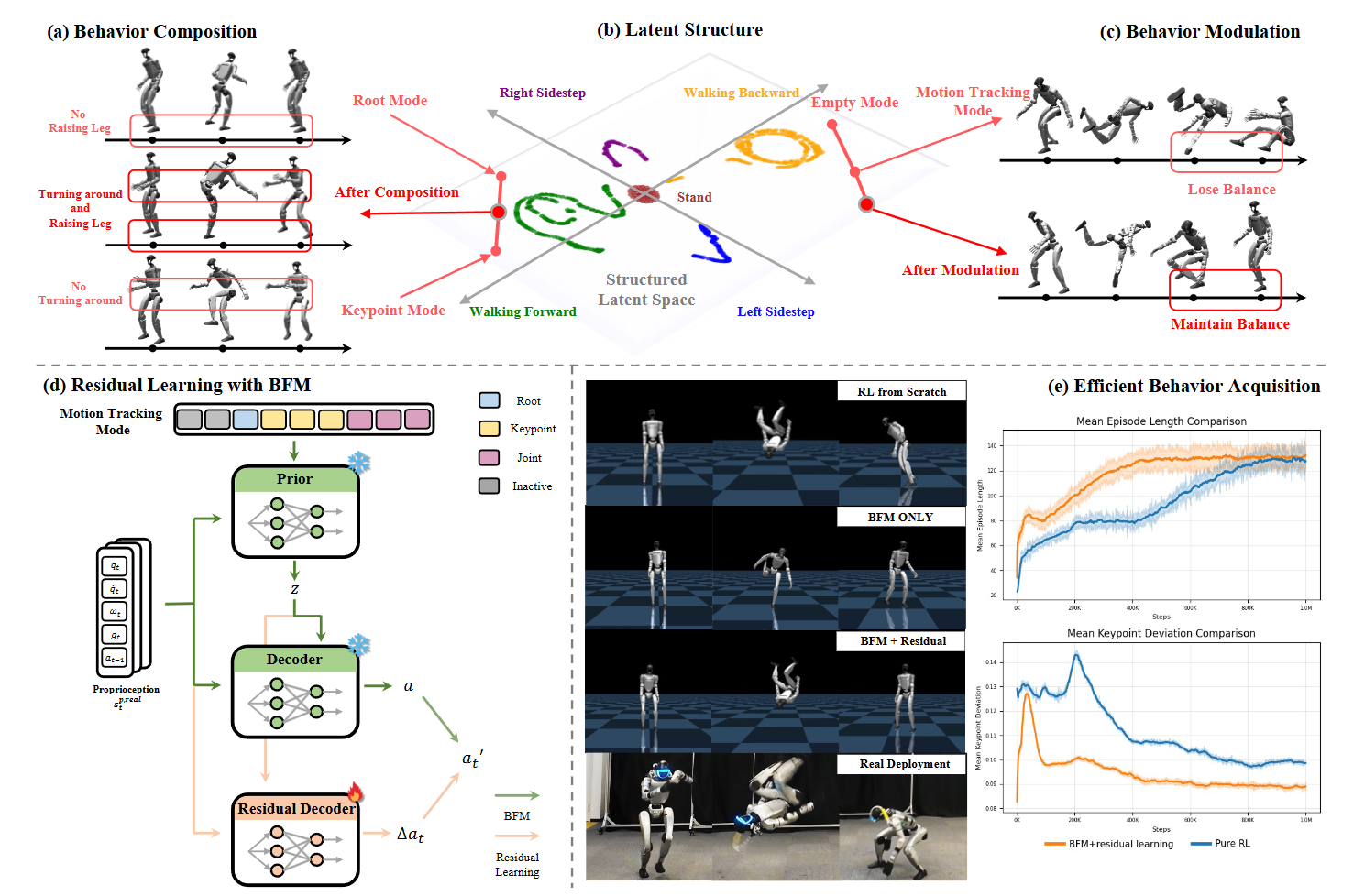
图6|综合实验结果:(a) BFM 通过对来自两种不同控制模式的潜在变量进行线性插值,实现新行为的组合。(b) T-SNE 可视化结果(棕色表示站立,绿色表示前进,黄色表示后退,蓝色表示左侧步,紫色表示右侧步)表明 BFM 提供了具有清晰方向性和对称性的结构化潜在空间。(c) BFM 可以通过在潜在空间中的线性外推实现行为调节,使生成的行为更好地符合期望的控制模式。(d) 在预训练的 BFM 基础上采用残差学习,以高效获取新的行为。(e) 选取侧空翻作为具有挑战性的案例,将所提方法与从零训练强化学习策略的方法进行对比
3. 高效新行为学习
● 方法:通过残差学习在已有模型的基础上快速适应新任务(如特定舞蹈动作或复杂翻滚)。
● 对比:与从零开始训练相比,残差学习收敛速度更快,所需样本更少。
● 结果:
○ 在仿真环境中,残差学习能显著缩短训练时间,并保持与原模型一致的稳定性。
○ 在真实 Unitree G1 上,BFM 可以通过少量数据快速学会新行为,并成功迁移到物理机器人中执行。
4. 真实机器人实验
● 平台:Unitree G1,人形机器人。
● 实验内容:
○ 多控制模式任务(动作模仿、速度指令);
○ 复合任务(组合与调节);
○ 新任务学习(通过残差学习快速习得)。
● 结果:BFM 在真实环境中成功展示了跨模式与跨任务的泛化能力,验证了其作为基础模型的可行性。

这项工作提出的 Behavior Foundation Model (BFM),为人形机器人带来了一种全新的“通用行为生成”范式。与以往局限在特定任务或控制模式的方法不同,BFM 将各种行为抽象为统一的表示,并在大规模数据上预训练,从而让机器人具备了跨任务的泛化能力。
通过引入 掩码机制,同一个行为可以用速度、参考动作甚至语言等不同方式来驱动;借助 CVAE 的结构化潜在空间,行为可以自然地组合和调节;再结合 残差学习,机器人能够在已有技能的基础上高效学习新动作。实验不仅验证了 BFM 在仿真中的多任务表现,还在真实的人形机器人(Unitree G1)上成功展示了“零样本泛化 + 高效新技能习得”的潜力。
可以说,BFM 为人形机器人的未来打开了一扇新门:从“任务专用”走向“行为通用”。这意味着未来的人形机器人或许不再需要为每一个任务单独训练,而是像人类一样,拥有可迁移、可组合、可扩展的“行为基础库”。
更多推荐
 19
19 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)