
从“最强大脑”到“最强小脑”:VLA 大模型如何让 AI 拥有“身体”?
视觉 (Vision): 这不仅仅是简单的“识别图片里有一只猫”。VLA 的视觉能力,是能够理解复杂的场景上下文。比如,它能看懂“桌子上的那个快要掉下去的苹果”,而不仅仅是“一个苹果”。语言 (Language): 这部分能力继承自我们熟悉的 LLM (大语言模型)。它能精准地理解人类发出的复杂、甚至带点模糊性的指令,比如“把那个红色的东西放到蓝色的盒子里”。行动 (Action): 这是 VLA
从“最强大脑”到“最强小脑”:VLA 大模型如何让 AI 拥有“身体”?
摘要:你是否想过,为什么能对答如流的智能音箱,却无法帮你从冰箱里拿一瓶可乐?因为它们只有“大脑”,却没有“身体”。本文将带你深入了解 VLA (Vision-Language-Action) 大模型——这项让 AI “知行合一”的关键技术。我们将用生动的比喻,为你清晰剖析 VLA 与 GPT-4V 等模型的本质区别,并一探 Google、特斯拉等巨头的前沿实践。读完本文,你将理解为何 VLA 正开启机器人领域的“iPhone 时刻”。
引言:当你的智能音箱突然“活”了过来
我们已经非常习惯与手机上的 Siri 或家里的智能音箱对话。它们是聪明的“大脑”,能陪你聊天,能帮你查天气,甚至能给你讲个冷笑话。但你有没有发现一个有趣的现象:无论它们多么智能,它们能做的,似乎仅限于“说”。
想象一个场景:周五晚上,你瘫在沙发上追剧,想喝瓶可乐。你对着智能音箱喊道:“嘿,帮我从冰箱里拿瓶可乐。”
它可能会回答:“好的,已将‘可乐’加入您的购物清单。”

看到没?这就是当今大多数 AI 的现状——一个被困在数字世界里的“最强大脑”。它能理解你的意图,但无法执行物理世界的动作。
这个从“说到”到“做到”的巨大鸿沟,正是 AI 发展的下一片星辰大海。而今天我们要聊的主角——VLA (Vision-Language-Action) 大模型,正是为了填补这一鸿沟而生的关键钥匙。它不仅能看懂世界、听懂人话,更能将这份理解转化为实实在在的行动。
读完本文,你将清晰地理解:
- VLA 大模型究竟是什么,以及它的核心工作流程。
- VLA 与我们熟知的 LLM (如 GPT-3)、多模态大模型 (如 GPT-4V) 的本质区别与演进关系。
- 为什么说 VLA 技术可能是机器人领域的一次“iPhone 时刻”。
准备好了吗?让我们一起进入这个让 AI “动起来”的全新世界。
一、VLA 大模型:一个“知行合一”的智能体
VLA,全称 Vision-Language-Action,即视觉-语言-行动模型。单看名字可能有点抽象,我们把它拆开来看,就像解构一个超能力组合。
1.1 定义拆解:Vision + Language + Action = 超能力
- 视觉 (Vision): 这不仅仅是简单的“识别图片里有一只猫”。VLA 的视觉能力,是能够理解复杂的场景上下文。比如,它能看懂“桌子上的那个快要掉下去的苹果”,而不仅仅是“一个苹果”。
- 语言 (Language): 这部分能力继承自我们熟悉的 LLM (大语言模型)。它能精准地理解人类发出的复杂、甚至带点模糊性的指令,比如“把那个红色的东西放到蓝色的盒子里”。
- 行动 (Action): 这是 VLA 的革命性所在,也是它与前辈们的最大区别!模型在理解了视觉和语言信息后,不再是生成一段文字作为回应,而是输出一个机器人可以理解并执行的动作序列。例如:
[move_gripper(x, y, z), close_gripper(), move_gripper(a, b, c), open_gripper()]。
简单来说,VLA 模型就是一个翻译大师,它把**“人类的想法”翻译成了“机器人的动作”**。
1.2 核心工作流:从“看懂、听懂”到“学会做”
VLA 模型的核心工作流程非常直观,就像一个人的反应过程:
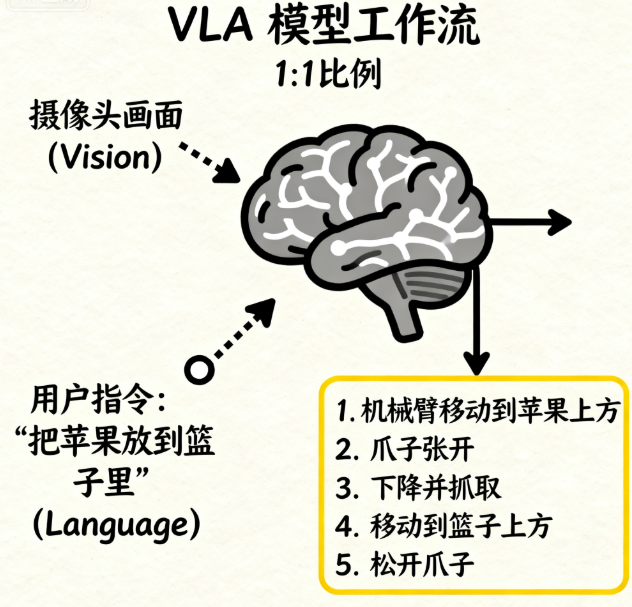
这个“行动”的输出,是打通虚拟智能与物理现实的最后一公里。
二、VLA 不是换汤不换药:它在大模型宇宙的坐标
“等一下,”你可能会问,“又是 V,又是 L,这听起来和 GPT-4V、Gemini 这些多模态模型差不多嘛?”
好问题!为了搞清楚 VLA 的独特性,让我们开启一场大模型宇宙的演进之旅。
2.1 第一站:语言的王者——LLM
想象一个被关在小黑屋里的博学哲学家。他读完了人类所有的书籍,满腹经纶,能写诗、能推理、能和你聊任何话题。但他没有眼睛,没有耳朵(输入只有文本),也没有手脚。
这就是 LLM (Large Language Model),如 GPT-3。它的世界里只有文字。
- 输入: 文本
- 输出: 文本
2.2 第二站:睁开眼睛看世界——多模态大模型 (MLLM)
现在,我们给这位哲学家的黑屋开了一扇明亮的窗户。他第一次看到了世界!你给他看一张图片,他能精准地描述画面的内容,甚至能看图写诗。
这就是 MLLM (Multimodal Large Language Model),如 GPT-4V。它打通了视觉和语言,学会了“看图说话”。
- 输入: 文本 + 图像
- 输出: 文本
但是,注意关键点:他依然被困在屋子里,看到桌上的苹果,他能描述它的颜色、形状,却无法触碰到它。
2.3 终点站:获得“双手”——VLA 大模型
旅程的最后一站,我们给了这位哲学家一双可以远程控制的机械臂。现在,当他看到桌上的苹果,并听到你说“把那个苹果给我”时,奇迹发生了:他不仅能理解指令,还能操作机械臂,精准地把苹果抓起来递给你。
这就是 VLA (Vision-Language-Action) 大模型。它在 MLLM 的基础上,增加了最关键的维度——行动。
- 输入: 文本 + 图像 (或视频流)
- 输出: 动作序列 (Action)
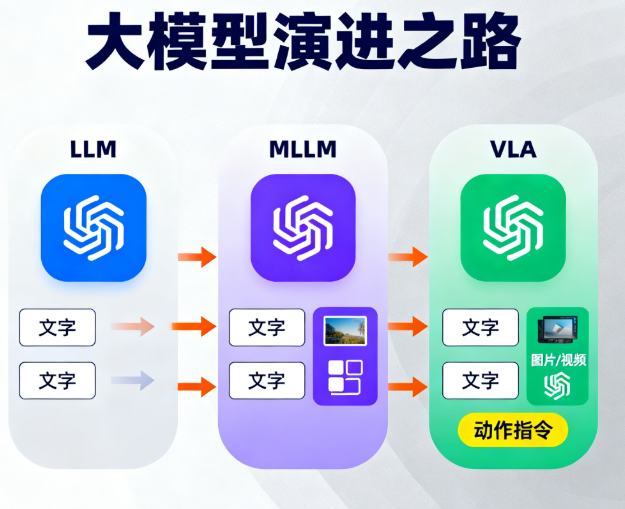
所以,VLA 和 MLLM 的本质区别在于输出的模态。一个是“说给你听”,另一个是“做给你看”。这个从“描述世界”到“改变世界”的飞跃,意义非凡。
三、VLA 如何炼成?揭秘背后的技术魔法
让一个模型学会“动手”,听起来就像魔法。这背后的秘密武器是什么?
3.1 关键养料:从“看图说话”到“看视频学操作”
答案是数据。
- 训练 MLLM,我们需要海量的
(图片, 描述)数据对。 - 而训练 VLA,数据的形式发生了根本性的变化,它需要的是
(世界状态, 人类指令, 机器人动作序列)这样的三元组。
通俗地讲,就是让模型观看海量的机器人操作视频,视频里包含了当时的环境画面 (State)、收到的指令 (Command),以及机器人执行的每一步具体动作 (Action)。通过学习这些数据,模型逐渐建立起语言、视觉和物理动作之间的映射关系。

3.2 明星项目巡礼:巨头们在做什么?
- Google DeepMind 的 RT-2: 这是 VLA 领域的一个里程碑。它的核心思想极具想象力:直接将在互联网海量的文本和图片上学到的“常识”(比如,“香蕉是一种水果”,“垃圾应该扔进垃圾桶”)无缝迁移到机器人控制任务上。结果令人震惊,机器人展现出了前所未有的泛化和推理能力,能完成很多它从未被专门训练过的任务。
- Tesla Optimus (擎天柱): 特斯拉则展示了另一条路径。他们通过“影子模式”,让机器人在后台模拟学习人类员工的操作,不断积累数据。这种“边看边学”的方式,让擎天柱的进化速度非常惊人。
这些项目的成功,都指向了一个共同的未来:一个由 VLA 大模型驱动的通用机器人时代。
结尾:欢迎来到物理智能时代
好了,我们的旅程暂告一段落。让我们简单回顾一下:
- VLA 大模型是 AI 的一个新物种,它融合了视觉、语言和行动能力。
- 它与 MLLM 的核心区别在于,它的输出不再是文本,而是可以驱动机器人的动作指令。
- 它就像为 AI 安装了“小脑”,让聪明的“大脑”终于有了可以支配的“身体”,实现了从“知”到“行”的统一。
VLA 大模型的成熟,可能预示着一个科幻般的未来不再遥远。它将深刻改变制造业的流水线、家庭里的琐碎家务,甚至是实验室里的科学研究。我们正站在一个物理智能 (Physical Intelligence) 新时代的入口。
最后,留一个开放性问题:
如果你拥有一个搭载了 VLA 大模型的机器人,你最想让它做的第一件事是什么?
在评论区留下你的脑洞吧!
更多推荐

 15
15 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)