
大模型离线部署docker(推荐) + dify部署(docker)
·
背景:离线环境安装大模型
在 Anolis OS NVIDIA GeForce RTX 4090 双卡上通过 Docker 离线部署 vLLM 和 DeepSeek-R1-Distill-Qwen-14B
准备工作
-
硬件要求:
- NVIDIA GeForce RTX 4090 GPU (24GB 显存两张)
- 2TGB 可用磁盘空间 (用于 Docker 镜像和模型 + dify)。 最少没算过,不过据查询至少100G
-
软件要求:
- linux 操作系统
- Docker 已安装
- NVIDIA Container Toolkit 已安装
部署步骤
1. 在有网络的环境中准备 Docker 镜像和模型
1.1 构建或下载 vLLM Docker 镜像
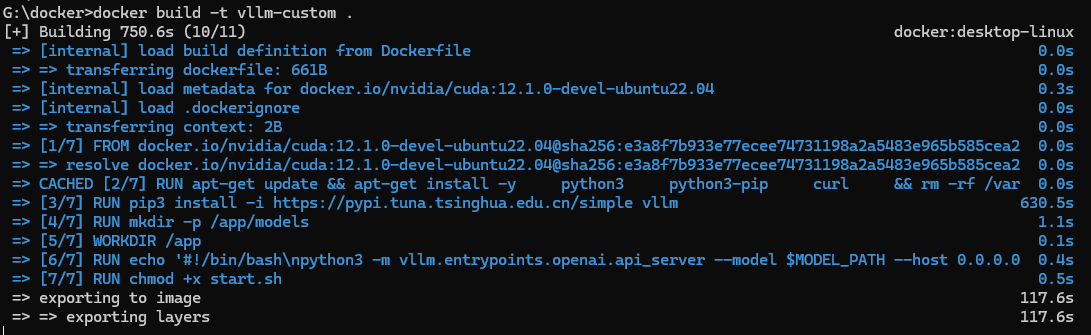
- 或者使用Dockerfile,注意Dockerfile的f要小写,Dockerfile文件中内容,
去掉文件后缀,windows如 .txt,注意: dockerfile文件中pip3 install vllm要指定镜像源,否则会链接超时错误
FROM nvidia/cuda:12.1.0-devel-ubuntu22.04
# 安装基础软件
RUN apt-get update && apt-get install -y \
python3 \
python3-pip \
curl \
&& rm -rf /var/lib/apt/lists/*
# 安装 vLLM
RUN pip3 install -i https://pypi.tuna.tsinghua.edu.cn/simple vllm
# 创建模型目录
RUN mkdir -p /app/models
# 设置工作目录
WORKDIR /app
# 设置默认环境变量
ENV MODEL_PATH=/app/models
# 创建启动脚本
RUN echo '#!/bin/bash\n\
python3 -m vllm.entrypoints.openai.api_server \
--model $MODEL_PATH \
--host 0.0.0.0 \
--port 8000' > start.sh
RUN chmod +x start.sh
# 暴露端口
EXPOSE 8000
# 启动命令
CMD ["./start.sh"]
- 构建镜像
# 保存镜像为离线文件
docker save vllm/vllm-openai:latest -o vllm-image.tar
# 或
docker save vllm-custom -o vllm-custom.tar
- 安装过程截图
- deepseek 容器启动脚本
# 导入镜像
docker load -i vllm-custom.tar
# 运行容器(需要指定模型路径)(已实操)
# --tensor-parallel-size 1
:张量并行数:1,含义:模型在单个 GPU 上运行(不进行多卡并行)如果有多张卡:可以设置为 GPU 数量,如 --tensor-parallel-size 2
:此命令是vLLM应用参数(在镜像名之后)
:解释:Docker 运行时参数(在镜像名之前),vLLM 应用参数(在镜像名之后)
# --shm-size=2g
:共享内存设置的大一些,开始没设置容器启动时会报错,应该默认会很小
# --max-model-len 32000
:也会进行设置,参数设置的会小一些,因为模型需要的序列Gpu没法完全提供,会报错
docker run -d \
--gpus all \
--shm-size=2g
-p 8000:8000 \
-v /data/soft/model/deepseek/deepseekR1-14B:/app/models/deepseek14b \
--name vllm-server \
vllm-custom \
python3 -m vllm.entrypoints.openai.api_server \
--model /app/models/deepseek-14b
--tensor-parallel-size 2
--gpu-memory-utilization 0.9
--max-model-len 32000
--api-key sk-test-123
# 可能会存在iptables规则问题,导致8000无法请求
iptables -A INPUT -p tcp --dport 8000 -j ACCEPT
# 检测端口
netstat -tulpn | grep 8000
# 记得重启docker服务
# 再重新docker run一下
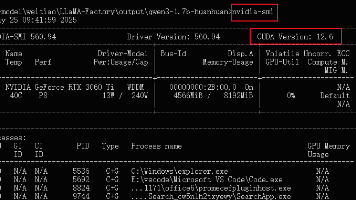
# 容器运行后稍等一会模型加载。可以通过命令监控gpn使用情况
watch -n -1 nvidia-smi
# 这是量化模型启动命令(未实操过)
docker run -itd --gpus all \
-p 8000:8000 \
-v /data/models:/models \
--name vllm-server \
vllm/vllm-openai:latest \
python3 -m vllm.entrypoints.openai.api_server \
--model /models/DeepSeek-R1-Distill-Qwen-14B-INT4 \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9
# MODEL_PATH的作用,可以指定不同模型运行
# 使用中文模型
docker run -e MODEL_PATH=/app/models/chinese-model ...
# 使用英文模型
docker run -e MODEL_PATH=/app/models/english-model ...
# 使用代码模型
docker run -e MODEL_PATH=/app/models/code-model ...
- gpt-oss-20b模型启动脚本
# --served-model-name gpt-oss-20b
:调用接口时,需要指定的模型名称
# python3 -m vllm.entrypoints.openai.api_server
:-m 表示运行一个模块
docker run -d --name gpt-oss-20b \
--gpus device=0 \
--shm-size=16g \
-p 8000:8000 \
-v /data/models:/models \
vllm-custom \
python3 -m vllm.entrypoints.openai.api_server \
--model /app/models/gpt-oss-20b \
--served-model-name gpt-oss-20b \
--tensor-parallel-size 1 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
# 推荐的精确配置
docker run -d --name gpt-oss-20b \
--gpus device=0 \
--shm-size=16g \
-p 8000:8000 \
-v /data/models:/models \
vllm/vllm-openai:latest \
python3 -m vllm.entrypoints.openai.api_server \
--model /models/GPT-OSS-20B \
--served-model-name gpt-oss-20b \
--tensor-parallel-size 1 \
--max-model-len 16384 \
--kv-cache-dtype auto \
--kv-cache-memory 11665470464 \
--disable-custom-all-reduce
- 请求
- 监控解释
watch -i 1 nvidia-smi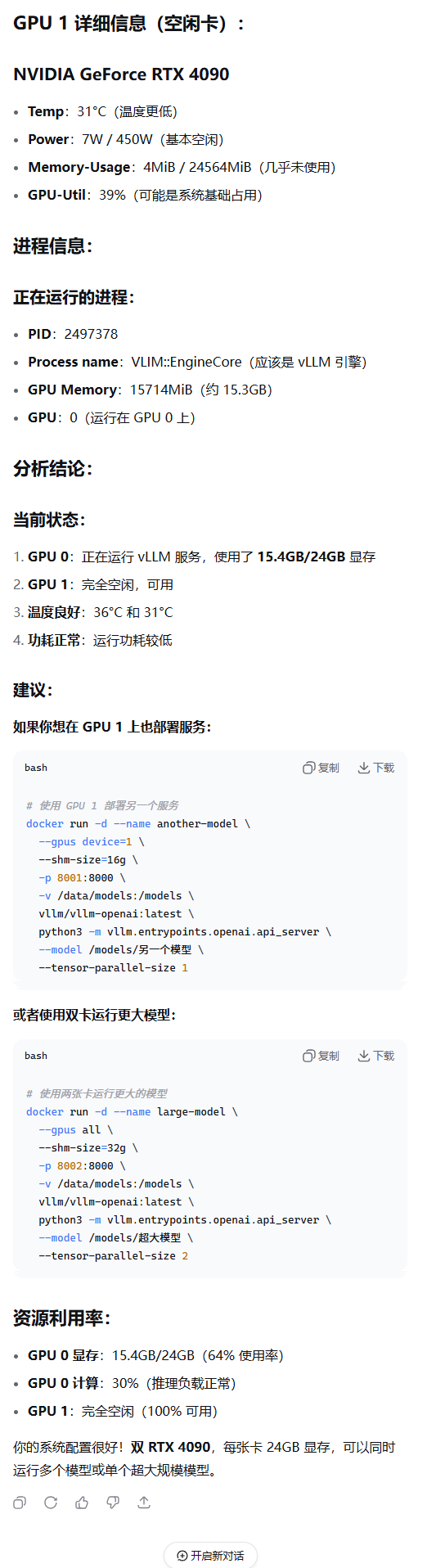
1.2 下载模型文件
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B-INT4
2. 将文件传输到离线环境
将以下文件复制到离线机器:
vllm-image.tar或vllm-custom-image.tarDeepSeek-R1-Distill-Qwen-14B-INT4整个目录
3. 在离线环境中加载 Docker 镜像
# 加载 Docker 镜像
docker load -i vllm-custom-image.tar
# 验证镜像加载
docker images
6. 验证服务
# 检查容器日志
docker logs vllm-server
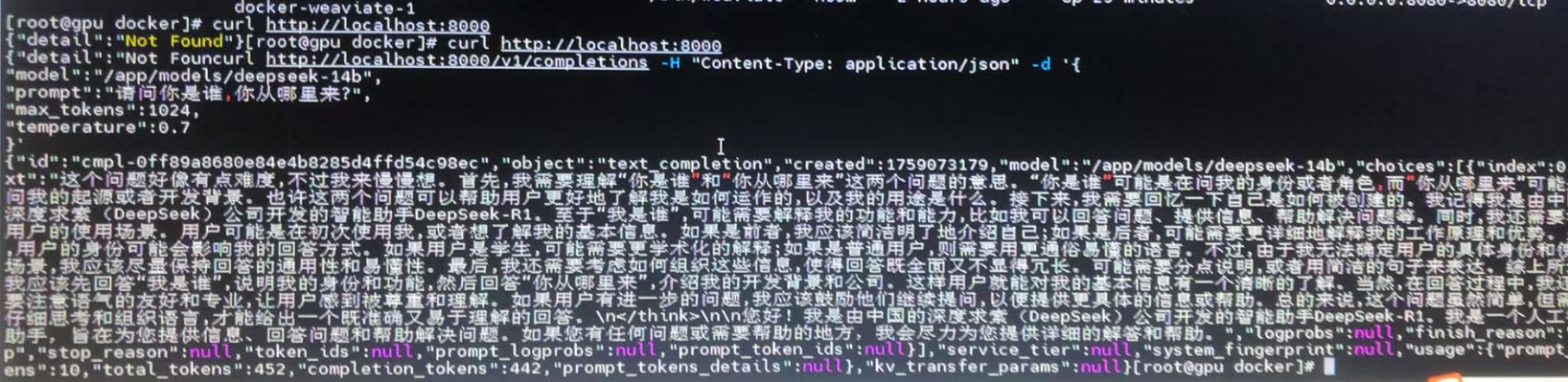
# 测试API (在容器内部或从主机)
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/models/DeepSeek-R1-Distill-Qwen-14B-INT4",
"prompt": "请介绍一下人工智能的发展历史",
"max_tokens": 100,
"temperature": 0.7
}'
替代方案:使用预构建的启动脚本
创建 start_vllm.sh 脚本:
#!/bin/bash
MODEL_PATH="/models/DeepSeek-R1-Distill-Qwen-14B-INT4"
docker run -itd --gpus all \
-p 8000:8000 \
-v $(dirname $MODEL_PATH):/models \
--name vllm-server \
vllm/vllm-openai:latest \
python3 -m vllm.entrypoints.openai.api_server \
--model $MODEL_PATH \
--tensor-parallel-size 1 \
--gpu-memory-utilization 0.9 \
--quantization awq
然后运行:
chmod +x start_vllm.sh
./start_vllm.sh
在 openEuler A40 单卡上离线部署 vLLM 和 DeepSeek-R1-Distill-Qwen-14B INT4
准备工作
-
硬件要求:
- NVIDIA A40 GPU (48GB显存)
- 足够的内存和存储空间
-
系统要求:
- openEuler 操作系统
- 已安装 NVIDIA 驱动和 CUDA
安装步骤
1. 安装依赖
# 安装基础依赖
sudo yum install -y python3 python3-devel git cmake gcc-c++
# 安装CUDA相关工具包
sudo yum install -y cuda-toolkit-11-8 # 根据实际CUDA版本调整
# 创建Python虚拟环境
python3 -m venv vllm-env
source vllm-env/bin/activate
2. 离线安装 vLLM
由于是离线环境,需要提前在有网络的环境中下载好所有依赖:
# 在有网络的环境中下载vLLM及其依赖
mkdir vllm-offline && cd vllm-offline
pip download vllm
pip download torch torchvision torchaudio --extra-index-url https://download.pytorch.org/whl/cu118 # 根据CUDA版本调整
将下载的包(*.whl和*.tar.gz文件)复制到离线机器上,然后安装:
pip install --no-index --find-links=/path/to/vllm-offline vllm
3. 下载 DeepSeek-R1-Distill-Qwen-14B INT4 模型
在有网络的环境中下载模型:
git lfs install
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B-INT4
将整个模型目录复制到离线机器上。
4. 运行推理
创建推理脚本inference.py:
from vllm import LLM, SamplingParams
# 初始化模型
llm = LLM(model="/path/to/DeepSeek-R1-Distill-Qwen-14B-INT4")
# 设置采样参数
sampling_params = SamplingParams(temperature=0.7, top_p=0.9, max_tokens=200)
# 推理
prompt = "请介绍一下人工智能的发展历史"
outputs = llm.generate([prompt], sampling_params)
# 输出结果
for output in outputs:
print(f"Prompt: {output.prompt}")
print(f"Generated text: {output.outputs[0].text}")
运行脚本:
python inference.py
注意事项
-
显存限制:A40有48GB显存,对于14B INT4模型应该足够,但如果遇到OOM错误,可以尝试:
- 减少
max_tokens - 使用
enable_prefix_caching=True参数
- 减少
-
性能优化:
llm = LLM( model="/path/to/DeepSeek-R1-Distill-Qwen-14B-INT4", tensor_parallel_size=1, # 单卡设置为1 gpu_memory_utilization=0.9 # 可以调整以优化显存使用 ) -
模型路径:确保模型路径正确,且模型文件完整。
-
量化版本:INT4模型需要确保vLLM支持该量化格式,如有问题可能需要使用特定分支或版本的vLLM。
如需进一步优化性能或解决特定问题,可能需要根据实际环境调整参数。
注意事项
- 模型量化格式:确保使用正确的量化参数,INT4 模型通常是 AWQ 或 GPTQ 量化
- 显存限制:A40 有 48GB 显存,14B INT4 模型应该足够,但可以调整
--gpu-memory-utilization - 性能优化:可以尝试添加
--enforce-eager参数减少内存使用 - Docker 权限:确保当前用户有权限访问 GPU (在 docker 用户组中)
如果遇到问题,可以检查容器日志:
docker logs -f vllm-server
dify的离线安装
-
有个前提在联网状态将需要的插件进行安装,避免环境依赖问题,安装后将docker-plugin-deamon提交并重新打成镜像使用
- windows上使用docker启动dify时会遇到80端口限制权限问题。需要修改docker目录下.env文件中EXPOSE_NGINX_PORT和NGINX_PORT端口号为18080不是1024以下端口即可,这两个变量会用于docker-compose.yaml中
- 打包镜像
# 下面这几步适用于升级也可以修复
# 1. 将容器docker-plugin_daemon容器创建为镜像langgenius/dify-plugin-daemon:0.0.6-local-15
docker commit docker-plugin_daemon-1 langgenius/dify-plugin-daemon:0.0.6-local-15
# 2.移除现有容器内容
docker compose down
# 3.创建新镜像的引用。这样在docker-compose时可以找到新的镜像,就无需修改镜像名了,只需要创建一个引用名称与原镜像名称即可。执行此步骤前记得删除原镜像docker rmi <镜像id>
docker tag langgenius/dify-plugin-daemon:0.0.6-local-15 langgenius/dify-plugin-daemon:0.0.6-local
# 4. 启动
docker compose up -d
- 已经将需要的镜像上传到了服务器。

- 安装步骤
- 指南
#
涉及docker安装及操作均为root dify可以通过普通用户操作 需要加入docker组
#docker安装
1. 解压并安装
tar xzvf docker-24.0.7.tgz
sudo cp docker/* /usr/bin/
2. 配置 Docker 服务
# 创建 systemd 服务
sudo tee /etc/systemd/system/docker.service <<EOF
[Unit]
Description=Docker Application Container Engine
After=network.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP \$MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
3. 启动 Docker
sudo systemctl enable docker
sudo systemctl start docker
4. 验证安装
docker --version
#docker-compose安装
cp docker-compose-linux-x86_64 /usr/local/bin/docker-compose
# 赋予执行权限
sudo chmod +x /usr/local/bin/docker-compose
# 验证安装
docker-compose --version
# 手动创建 docker 组
sudo groupadd docker
授权devuser加入docker组
sudo usermod -aG docker devuser
# 以下的tar都是在本地dify源码目录docker文件夹中使用docker-compose -f docker-compose.yaml -f docker-compose.middleware.yaml up -d 执行安装后进行打包生成的(使用docker save命令)
# 在github下载最新版源码使用main分支即可
# 离线镜像导入
docker load -i nginx.tar
docker load -i dify-plugin-daemon.tar
docker load -i dify-web.tar
docker load -i dify-api.tar
docker load -i postgres.tar
docker load -i dify-sandbox.tar
docker load -i redis.tar
docker load -i weaviate.tar
docker load -i squid.tar
# 或使用脚本导入
for tarfile in *.tar; do docker load -i "$tarfile"; done
重启docker
sudo systemctl restart docker
修改并替换IP
.env docker-compose.middleware.yaml docker-compose.yaml middleware.env
192.168.100.105 替换为部署服务器IP
# 此处的docker目录在dify源文件中,一定要进入目录后启动应用,否则会报错
加入docker组的用户 上传dify源文件 并进入docker目录
启动应用
docker-compose -f docker-compose.yaml -f docker-compose.middleware.yaml up -d
检查
docker ps
登录dify首页
http://ip
首次登录需要注册 记住用户名和密码
- 解压tar文件
# 打包
tar -czvf filename.tar.gz C:\My Folder
# 解压缩
tar -xzvf filename.tar.gz
- 执行
# 批量导入所有镜像
docker load -i dify-api.tar
docker load -i dify-web.tar
docker load -i nginx.tar
docker load -i postgres.tar
docker load -i redis.tar
docker load -i weaviate.tar
docker load -i dify-sandbox.tar
docker load -i dify-plugin-daemon.tar
docker load -i squid.tar
# 查看导入的镜像
docker images
# 给执行权限(如果需要)
chmod +x docker-compose-linux-x86_64
# 直接运行
./docker-compose-linux-x86_64 up -d
# 等基础服务正常后,再单独处理 nginx
./docker-compose-linux-x86_64 up -d nginx
# 指定启动
./docker-compose-linux-x86_64 -f docker-compose.yml up -d
# 直接使用 docker ps 查看,按名称过滤
docker ps --filter "name=$(basename $(pwd))" --format "table {{.Names}}\t{{.Status}}\t{{.Ports}}"
# 查看服务状态(格式化看的更清楚)
./docker-compose-linux-x86_64 ps
# 查看日志
./docker-compose-linux-x86_64 logs redis
# 查看所有服务的完整日志
./docker-compose-linux-x86_64 logs --tail=20
# 停止所有服务,但保留容器和数据
./docker-compose-linux-x86_64 stop
# 停止并移除所有容器(但保留数据卷和镜像)
./docker-compose-linux-x86_64 down
# 强制快速停止
./docker-compose-linux-x86_64 down --timeout=0
# 检查是否所有服务都停止了
./docker-compose-linux-x86_64 ps
http://你的服务器IP
# 检查所有容器是否正常运行
docker ps
# 检查服务健康状态
curl http://localhost/v1/health
- 如果使用docker compose 二进制文件直接运行需要知道volumn映射的位置
# 如果有 docker-compose.yml 文件
cat docker-compose.yml | grep -A 10 -B 2 volumes
# 或者查看完整的 compose 配置
./docker-compose-linux-x86_64 config
- 查看特定服务的 volume
# 查看 postgres 的 volume 映射
docker inspect $(./docker-compose-linux-x86_64 ps -q postgres) | grep -A 10 -B 5 Mounts
# 或者使用 format
docker inspect $(./docker-compose-linux-x86_64 ps -q postgres) --format='{{range .Mounts}}{{.Source}}:{{.Destination}}{{end}}'
- 假设你想查看 Dify 项目的 volume 映射
# 1. 首先启动服务(如果还没启动)
./docker-compose-linux-x86_64 up -d
# 2. 查看所有服务的 volume 映射
echo "=== 所有服务的 Volume 映射 ==="
./docker-compose-linux-x86_64 ps -q | while read container_id; do
container_name=$(docker inspect --format='{{.Name}}' $container_id)
echo "容器: $container_name"
docker inspect --format='{{range .Mounts}}源: {{.Source}} -> 目标: {{.Destination}} (类型: {{.Type}})
{{end}}' $container_id
echo "---"
done
# 3. 查看创建的 volumes
echo "=== Docker Volumes ==="
docker volume ls | grep $(basename $(pwd))
# 4. 查看 compose 配置中的 volume 定义
echo "=== Compose 文件中的 Volume 配置 ==="
./docker-compose-linux-x86_64 config | grep -A 20 volumes
- 装好后需要从桌面直接访问http://ip即可,会跳转至http://ip/apps页面。
- 关注点版本号。如果用于测试,本地与生产环境尽可能一致。经测试。1.9版本dify导出的工作流文件也能够在1.5.1版本dify上导入并成功打开。待运行测试
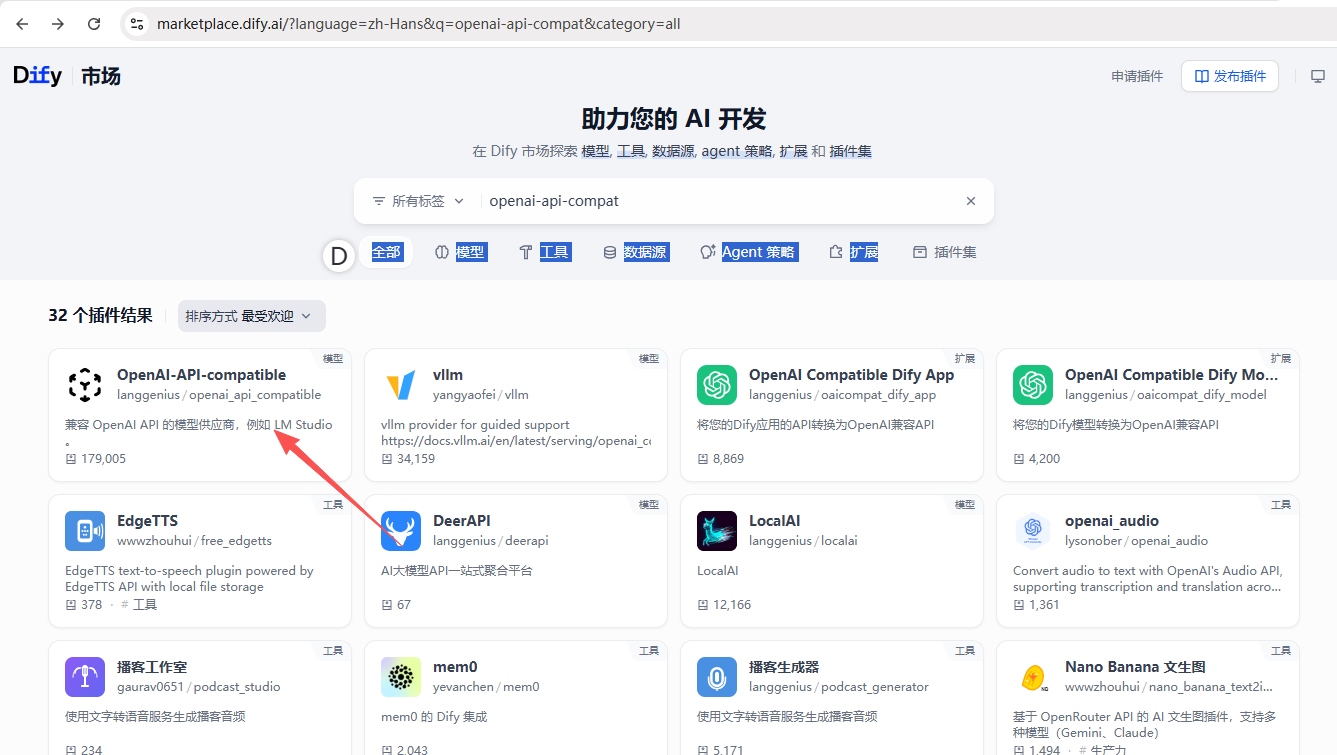
配置大模型访问地址
- 下载后是后缀为difypkg的文件

- 再进行插件安装
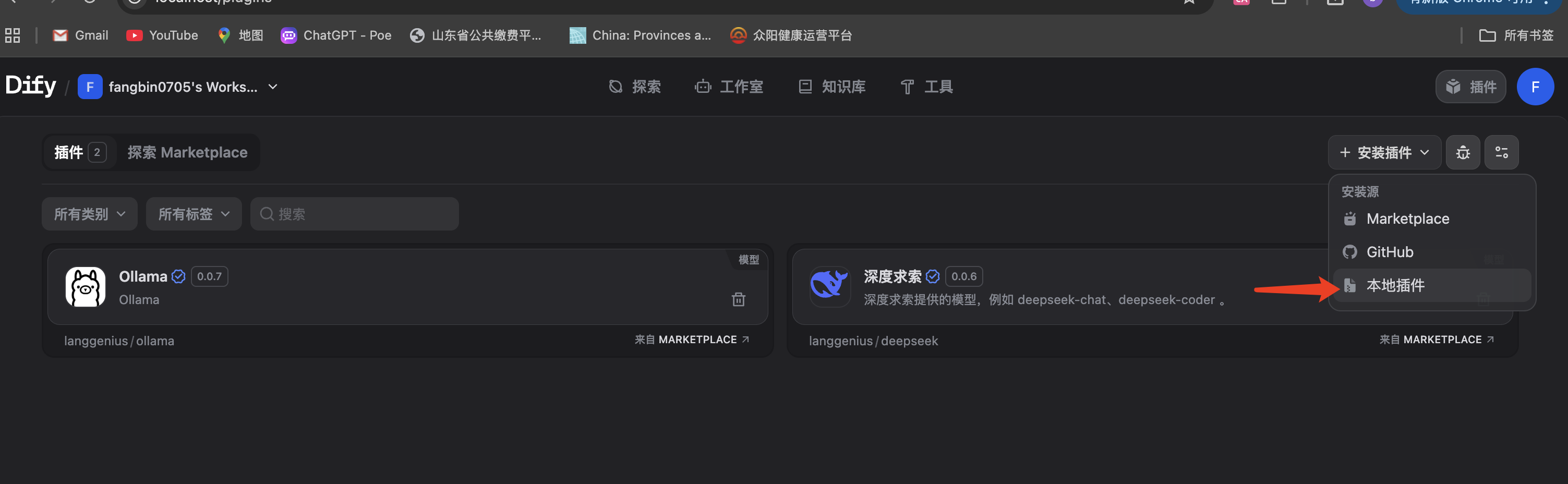
处理无法像插件中添加模型
# 实时跟踪 vLLM 服务器日志
# 查看最近100行并实时跟踪(推荐)
docker logs -ft--tail 50 vllm-server
# 若遇到模型报错,进到后台日志发现网络问题,可以进入docker容器测试
docker exec -it <容器名> /bin/bash
curl http://ip:8000
# 为了测试,docker run时增加了api-key
docker run -itd --gpus all --shm-size=2g -p 8000:8000 -v /data/soft/model/deepseek/deepseekR1-14B:/app/models/deepseek-14b --name vllm-server vllm-custom python3 -m vllm.entrypoints.openai.api_server --model /app/models/deepseek-14b --served-model-name deepseek-14b --tensor-parallel-size 2 --gpu-memory-utilization 0.9 --max-model-len 32000 --api-key sk-test-123
# 增加了api-key部署vllm后,这样测试
curl -H"Authorization: Bearer sk-test-123" http://<可达地址>:8000/v1/models
两个模型使用docker-compose切换使用测试
- 启动
docker-compose up -d deepseek-r1 - 停止
docker-compose stop deepseek-r1 - 查看状态
watch -n 1 docker ps -a - 插卡显卡状态
watch -n 1 nvidia-smi
version: "3.8"
services:
deepseek-r1:
image: vllm-custom
container_name: vllm-server-deepsk
ports:
- "8000:8000"
volumes:
- /data/soft/model/deepseek/deepseekR1-14B:/app/models/deepseek14b
shm_size: "2g"
command: >
python3 -m vllm.entrypoints.openai.api_server
--model /app/models/deepseek14b
--tensor-parallel-size 2
--gpu-memory-utilization 0.9
--max-model-len 32000
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
20b:
image: vllm-custom
container_name: vllm-server-20b
ports:
- "8000:8000"
volumes:
- /data/soft/model/gpt-oss-20b:/app/models/gpt-oss-20b
shm_size: "2g"
command: >
python3 -m vllm.entrypoints.openai.api_server
--model /app/models/gpt-oss-20b
--tensor-parallel-size 2
--gpu-memory-utilization 0.9
--max-model-len 32000
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
gpt-oss-20b部署问题记录
- 网上gpt-oss-20b部署踩坑记录(管用)
- 这里粘贴相关问题记录
- 20b模型启动报错记录(docker)
vllm-server-20b | INFO 09-30 13:00:40 [__init__.py:216] Automatically detected platform cuda.
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:00:44 [api_server.py:1896] vLLM API server version 0.10.2
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:00:44 [utils.py:328] non-default args: {'model': '/app/models/gpt-oss-20b', 'max_model_len': 8192, 'block_size': 16}
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:00:56 [__init__.py:742] Resolved architecture: GptOssForCausalLM
vllm-server-20b | (APIServer pid=1) `torch_dtype` is deprecated! Use `dtype` instead!
vllm-server-20b | (APIServer pid=1) ERROR 09-30 13:00:56 [config.py:278] Error retrieving safetensors: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/app/models/gpt-oss-20b'. Use `repo_type` argument if needed., retrying 1 of 2
vllm-server-20b | (APIServer pid=1) ERROR 09-30 13:00:58 [config.py:276] Error retrieving safetensors: Repo id must be in the form 'repo_name' or 'namespace/repo_name': '/app/models/gpt-oss-20b'. Use `repo_type` argument if needed.
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:00:59 [__init__.py:2764] Downcasting torch.float32 to torch.bfloat16.
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:00:59 [__init__.py:1815] Using max model len 8192
vllm-server-20b | (APIServer pid=1) WARNING 09-30 13:01:01 [_ipex_ops.py:16] Import error msg: No module named 'intel_extension_for_pytorch'
vllm-server-20b | (APIServer pid=1) WARNING 09-30 13:01:01 [__init__.py:1217] mxfp4 quantization is not fully optimized yet. The speed can be slower than non-quantized models.
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:01:02 [scheduler.py:222] Chunked prefill is enabled with max_num_batched_tokens=2048.
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:01:02 [config.py:284] Overriding max cuda graph capture size to 1024 for performance.
vllm-server-20b | INFO 09-30 13:01:07 [__init__.py:216] Automatically detected platform cuda.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:10 [core.py:654] Waiting for init message from front-end.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:10 [core.py:76] Initializing a V1 LLM engine (v0.10.2) with config: model='/app/models/gpt-oss-20b', speculative_config=None, tokenizer='/app/models/gpt-oss-20b', skip_tokenizer_init=False, tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=False, dtype=torch.bfloat16, max_seq_len=8192, download_dir=None, load_format=auto, tensor_parallel_size=1, pipeline_parallel_size=1, data_parallel_size=1, disable_custom_all_reduce=False, quantization=mxfp4, enforce_eager=False, kv_cache_dtype=auto, device_config=cuda, decoding_config=DecodingConfig(backend='auto', disable_fallback=False, disable_any_whitespace=False, disable_additional_properties=False, reasoning_backend='openai_gptoss'), observability_config=ObservabilityConfig(show_hidden_metrics_for_version=None, otlp_traces_endpoint=None, collect_detailed_traces=None), seed=0, served_model_name=/app/models/gpt-oss-20b, enable_prefix_caching=True, chunked_prefill_enabled=True, use_async_output_proc=True, pooler_config=None, compilation_config={"level":3,"debug_dump_path":"","cache_dir":"","backend":"","custom_ops":[],"splitting_ops":["vllm.unified_attention","vllm.unified_attention_with_output","vllm.mamba_mixer2","vllm.mamba_mixer","vllm.short_conv","vllm.linear_attention","vllm.plamo2_mamba_mixer","vllm.gdn_attention"],"use_inductor":true,"compile_sizes":[],"inductor_compile_config":{"enable_auto_functionalized_v2":false},"inductor_passes":{},"cudagraph_mode":1,"use_cudagraph":true,"cudagraph_num_of_warmups":1,"cudagraph_capture_sizes":[1024,1008,992,976,960,944,928,912,896,880,864,848,832,816,800,784,768,752,736,720,704,688,672,656,640,624,608,592,576,560,544,528,512,496,480,464,448,432,416,400,384,368,352,336,320,304,288,272,256,248,240,232,224,216,208,200,192,184,176,168,160,152,144,136,128,120,112,104,96,88,80,72,64,56,48,40,32,24,16,8,4,2,1],"cudagraph_copy_inputs":false,"full_cuda_graph":false,"pass_config":{},"max_capture_size":1024,"local_cache_dir":null}
vllm-server-20b | [W930 13:01:11.557528969 ProcessGroupNCCL.cpp:981] Warning: TORCH_NCCL_AVOID_RECORD_STREAMS is the default now, this environment variable is thus deprecated. (function operator())
vllm-server-20b | [Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
vllm-server-20b | [Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
vllm-server-20b | [Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
vllm-server-20b | [Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
vllm-server-20b | [Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
vllm-server-20b | [Gloo] Rank 0 is connected to 0 peer ranks. Expected number of connected peer ranks is : 0
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:11 [parallel_state.py:1165] rank 0 in world size 1 is assigned as DP rank 0, PP rank 0, TP rank 0, EP rank 0
vllm-server-20b | (EngineCore_DP0 pid=224) WARNING 09-30 13:01:11 [topk_topp_sampler.py:69] FlashInfer is not available. Falling back to the PyTorch-native implementation of top-p & top-k sampling. For the best performance, please install FlashInfer.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:11 [gpu_model_runner.py:2338] Starting to load model /app/models/gpt-oss-20b...
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:11 [gpu_model_runner.py:2370] Loading model from scratch...
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:11 [cuda.py:357] Using Triton backend on V1 engine.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:11 [triton_attn.py:266] Using vllm unified attention for TritonAttentionImpl
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:11 [mxfp4.py:93] Using Marlin backend
Loading safetensors checkpoint shards: 0% Completed | 0/3 [00:00<?, ?it/s]
Loading safetensors checkpoint shards: 33% Completed | 1/3 [00:01<00:02, 1.03s/it]
Loading safetensors checkpoint shards: 67% Completed | 2/3 [00:02<00:01, 1.04s/it]
Loading safetensors checkpoint shards: 100% Completed | 3/3 [00:02<00:00, 1.10it/s]
Loading safetensors checkpoint shards: 100% Completed | 3/3 [00:02<00:00, 1.06it/s]
vllm-server-20b | (EngineCore_DP0 pid=224)
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:14 [default_loader.py:268] Loading weights took 2.89 seconds
vllm-server-20b | (EngineCore_DP0 pid=224) WARNING 09-30 13:01:14 [marlin_utils_fp4.py:196] Your GPU does not have native support for FP4 computation but FP4 quantization is being used. Weight-only FP4 compression will be used leveraging the Marlin kernel. This may degrade performance for compute-heavy workloads.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:15 [gpu_model_runner.py:2392] Model loading took 13.7164 GiB and 3.603766 seconds
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:20 [backends.py:539] Using cache directory: /root/.cache/vllm/torch_compile_cache/9da7fc8693/rank_0_0/backbone for vLLM's torch.compile
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:20 [backends.py:550] Dynamo bytecode transform time: 4.94 s
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:01:24 [backends.py:194] Cache the graph for dynamic shape for later use
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:01 [backends.py:215] Compiling a graph for dynamic shape takes 40.35 s
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:02 [marlin_utils.py:353] You are running Marlin kernel with bf16 on GPUs before SM90. You can consider change to fp16 to achieve better performance if possible.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:02 [monitor.py:34] torch.compile takes 45.30 s in total
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:03 [gpu_worker.py:298] Available KV cache memory: 5.70 GiB
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:03 [kv_cache_utils.py:1028] GPU KV cache size: 124,528 tokens
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:03 [kv_cache_utils.py:1032] Maximum concurrency for 8,192 tokens per request: 23.98x
Capturing CUDA graphs (mixed prefill-decode, PIECEWISE): 100%|██████████| 83/83 [00:04<00:00, 16.72it/s]
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:09 [gpu_model_runner.py:3118] Graph capturing finished in 6 secs, took 0.80 GiB
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:09 [gpu_worker.py:391] Free memory on device (23.2/23.64 GiB) on startup. Desired GPU memory utilization is (0.9, 21.28 GiB). Actual usage is 13.72 GiB for weight, 1.84 GiB for peak activation, 0.02 GiB for non-torch memory, and 0.8 GiB for CUDAGraph memory. Replace gpu_memory_utilization config with `--kv-cache-memory=5101933056` to fit into requested memory, or `--kv-cache-memory=7165956608` to fully utilize gpu memory. Current kv cache memory in use is 6121148928 bytes.
vllm-server-20b | (EngineCore_DP0 pid=224) INFO 09-30 13:02:09 [core.py:218] init engine (profile, create kv cache, warmup model) took 53.96 seconds
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:02:10 [loggers.py:142] Engine 000: vllm cache_config_info with initialization after num_gpu_blocks is: 15566
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:02:10 [async_llm.py:180] Torch profiler disabled. AsyncLLM CPU traces will not be collected.
vllm-server-20b | (APIServer pid=1) INFO 09-30 13:02:10 [api_server.py:1692] Supported_tasks: ['generate']
vllm-server-20b | (APIServer pid=1) WARNING 09-30 13:02:10 [serving_responses.py:147] For gpt-oss, we ignore --enable-auto-tool-choice and always enable tool use.
vllm-server-20b | [rank0]:[W930 13:02:27.416970756 ProcessGroupNCCL.cpp:1538] Warning: WARNING: destroy_process_group() was not called before program exit, which can leak resources. For more info, please see https://pytorch.org/docs/stable/distributed.html#shutdown (function operator())
vllm-server-20b | (APIServer pid=1) Traceback (most recent call last):
vllm-server-20b | (APIServer pid=1) File "/usr/lib/python3.10/runpy.py", line 196, in _run_module_as_main
vllm-server-20b | (APIServer pid=1) return _run_code(code, main_globals, None,
vllm-server-20b | (APIServer pid=1) File "/usr/lib/python3.10/runpy.py", line 86, in _run_code
vllm-server-20b | (APIServer pid=1) exec(code, run_globals)
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 2011, in <module>
vllm-server-20b | (APIServer pid=1) uvloop.run(run_server(args))
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 82, in run
vllm-server-20b | (APIServer pid=1) return loop.run_until_complete(wrapper())
vllm-server-20b | (APIServer pid=1) File "uvloop/loop.pyx", line 1518, in uvloop.loop.Loop.run_until_complete
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/uvloop/__init__.py", line 61, in wrapper
vllm-server-20b | (APIServer pid=1) return await main
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1941, in run_server
vllm-server-20b | (APIServer pid=1) await run_server_worker(listen_address, sock, args, **uvicorn_kwargs)
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1969, in run_server_worker
vllm-server-20b | (APIServer pid=1) await init_app_state(engine_client, vllm_config, app.state, args)
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/api_server.py", line 1752, in init_app_state
vllm-server-20b | (APIServer pid=1) state.openai_serving_responses = OpenAIServingResponses(
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/openai/serving_responses.py", line 154, in __init__
vllm-server-20b | (APIServer pid=1) get_stop_tokens_for_assistant_actions())
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/harmony_utils.py", line 398, in get_stop_tokens_for_assistant_actions
vllm-server-20b | (APIServer pid=1) return get_encoding().stop_tokens_for_assistant_actions()
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/vllm/entrypoints/harmony_utils.py", line 56, in get_encoding
vllm-server-20b | (APIServer pid=1) _harmony_encoding = load_harmony_encoding(
vllm-server-20b | (APIServer pid=1) File "/usr/local/lib/python3.10/dist-packages/openai_harmony/__init__.py", line 689, in load_harmony_encoding
vllm-server-20b | (APIServer pid=1) inner: _PyHarmonyEncoding = _load_harmony_encoding(name)
vllm-server-20b | (APIServer pid=1) openai_harmony.HarmonyError: error downloading or loading vocab file: failed to download or load vocab file
vllm-server-20b exited with code 1
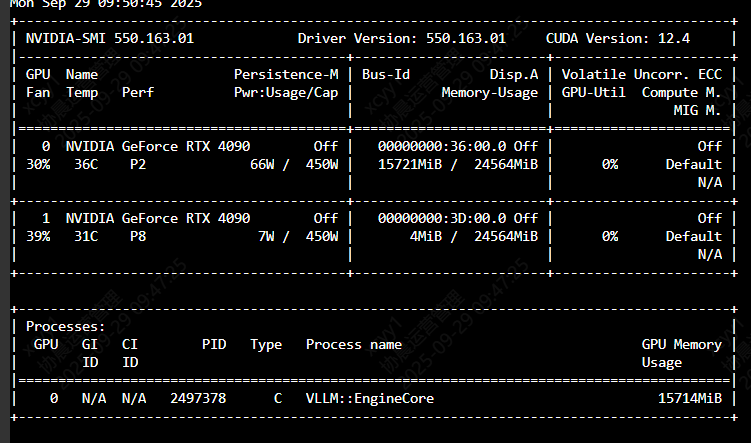
- 显卡信息
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.163.01 Driver Version: 550.163.01 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:36:00.0 Off | Off |
| 30% 38C P0 66W / 450W | 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 4090 Off | 00000000:3D:00.0 Off | Off |
| 39% 37C P0 60W / 450W | 1MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| No running processes found |
+-----------------------------------------------------------------------------------------+
- 模型信息
-rw-r--r-- 1 root root 17068 9月 28 15:43 chat_template.jinja
-rw-r--r-- 1 root root 1882 9月 28 15:43 config.json
-rw-r--r-- 1 root root 73 9月 28 15:43 configuration.json
-rw-r--r-- 1 root root 188 9月 28 15:43 generation_config.json
-rw-r--r-- 1 root root 2175 9月 28 15:43 .gitattributes
-rw-r--r-- 1 root root 11558 9月 28 15:43 LICENSE
-rw-r--r-- 1 root root 4792272488 9月 28 16:07 model-00000-of-00002.safetensors
-rw-r--r-- 1 root root 4798702184 9月 28 16:32 model-00001-of-00002.safetensors
-rw-r--r-- 1 root root 4170342232 9月 28 16:54 model-00002-of-00002.safetensors
-rw-r--r-- 1 root root 36355 9月 28 15:43 model.safetensors.index.json
-rw-r--r-- 1 root root 7276 9月 28 16:54 README.md
-rw-r--r-- 1 root root 103 9月 28 16:54 special_tokens_map.json
-rw-r--r-- 1 root root 4383 9月 28 16:54 tokenizer_config.json
-rw-r--r-- 1 root root 27868174 9月 28 16:54 tokenizer.json
-rw-r--r-- 1 root root 201 9月 28 16:54 USAGE_POLICY
更多推荐
 8
8 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)