
基于CrewAI与DeepSeek的测试用例自动生成实践
核心目标:通过多智能体协作(CrewAI)+专业代码模型(DeepSeek),实现从需求文档到结构化测试用例的全流程自动化,提升复杂模块用例设计效率80%+通过CrewAI实现多智能体协作,结合DeepSeek的文本理解与生成能力,可构建“需求解析→用例生成→场景补全→质量校验”的全自动化流水线。该方案尤其适合业务复杂、迭代频繁的测试团队,是测试左移与智能化转型的关键实践。用例设计Agent生成基
·
基于CrewAI与DeepSeek的测试用例自动生成实践指南
核心目标:通过多智能体协作(CrewAI)+专业代码模型(DeepSeek),实现从需求文档到结构化测试用例的全流程自动化,提升复杂模块用例设计效率80%+
一、技术方案架构:多智能体协作的测试用例生成流水线
1. 核心组件与分工
| 智能体(Agent) | 角色定位 | 工具/能力支撑 | 输出产物 |
|---|---|---|---|
| 需求解析Agent | 从PRD/需求文档中提取核心测试点 | DeepSeek-R1(长文本理解)+ 规则引擎 | 结构化测试需求清单(功能点/边界/异常场景) |
| 用例设计Agent | 基于测试需求生成标准化用例 | DeepSeek-Coder(代码/用例生成)+ 测试方法论库 | 初版测试用例(含步骤/预期结果/优先级) |
| 场景补全Agent | 补充边缘场景与异常用例 | 历史缺陷库(GraphRAG)+ 领域知识图谱 | 异常场景用例(如网络超时、数据冲突) |
| 质量校验Agent | 校验用例完整性、一致性、可执行性 | 用例模板规则库 + LLM自校验(DeepSeek) | 优化后最终用例集(Markdown/Excel格式) |
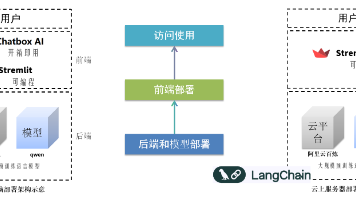
2. 协作流程(CrewAI Pipeline)
二、关键实现步骤:从需求到用例的全流程落地
Step 1:环境配置与工具集成
- CrewAI框架搭建:
# 安装依赖
pip install crewai deepseek-sdk python-dotenv pandas
# 配置智能体基础参数
from crewai import Agent, Task, Crew
from langchain.tools import Tool
import deepseek
- DeepSeek API接入:
- 申请DeepSeek API密钥(DeepSeek开放平台),配置
DEEPSEEK_API_KEY到环境变量。 - 初始化代码生成模型(
deepseek_coder = deepseek.ChatCompletion(model="deepseek-coder"))和文本理解模型(deepseek_r1 = deepseek.ChatCompletion(model="deepseek-r1"))。
Step 2:需求解析Agent——从非结构化文档提取测试需求
- 核心能力:
- 用DeepSeek-R1解析PRD文档,识别“功能点-输入输出-业务规则-约束条件”;
- 输出标准化测试需求清单(如“用户支付模块需覆盖:正常支付、余额不足、支付超时”)。
- 代码示例:
requirement_analyzer = Agent(
role="需求解析专家",
goal="从需求文档中提取测试需求,包括功能点、边界条件、异常场景",
backstory="你熟悉软件测试理论,擅长从产品需求中挖掘潜在测试点...",
tools=[Tool(
name="DeepSeek文本理解",
func=lambda x: deepseek_r1.create(prompt=x).choices[0].message.content,
description="用DeepSeek-R1解析需求文档,提取测试需求"
)],
llm=deepseek_r1
)
# 定义任务:解析支付模块PRD
task1 = Task(
description="解析附件PRD中“支付模块”章节,输出测试需求清单(含功能/边界/异常)",
agent=requirement_analyzer,
expected_output="结构化测试需求JSON,如:{\"功能点\": [...], \"边界值\": [...], \"异常场景\": [...]}"
)
Step 3:用例设计Agent——基于测试需求生成基础用例
- 核心能力:
- 调用DeepSeek-Coder,基于测试需求生成符合IEEE 829标准的测试用例(用例ID、标题、前置条件、步骤、预期结果);
- 支持多格式输出(Excel/Markdown/TestRail导入格式)。
- 代码示例:
case_designer = Agent(
role="测试用例设计师",
goal="基于测试需求生成标准化、可执行的测试用例",
backstory="你精通等价类划分法、边界值分析,能设计覆盖全面的测试用例...",
tools=[Tool(
name="DeepSeek用例生成",
func=lambda x: deepseek_coder.create(prompt=x).choices[0].message.content,
description="用DeepSeek-Coder生成结构化测试用例"
)],
llm=deepseek_coder
)
# 定义任务:生成支付模块基础用例
task2 = Task(
description=f"基于任务1输出的测试需求,生成支付模块基础用例,格式如下:\n用例ID | 标题 | 前置条件 | 步骤 | 预期结果",
agent=case_designer,
context=[task1]# 依赖需求解析结果
)
Step 4:场景补全Agent——补充异常与边缘场景
- 核心能力:
- 通过GraphRAG检索历史缺陷库(如“支付成功但订单状态未更新”),自动补充同类异常用例;
- 结合领域知识图谱(如“支付流程→第三方接口调用→超时重试”),生成业务规则相关边缘场景。
- 代码示例:
scenario_enricher = Agent(
role="场景补全专家",
goal="补充异常场景和边缘用例,提升用例覆盖率",
backstory="你熟悉系统架构与历史缺陷,能挖掘未覆盖的风险场景...",
tools=[Tool(
name="历史缺陷检索",
func=lambda x: graph_rag.query(f"查找{x}相关的历史缺陷,生成测试用例"),
description="从GraphRAG知识库检索同类缺陷,补充测试场景"
)],
llm=deepseek_r1
)
task3 = Task(
description="基于任务2的用例,补充异常场景(如网络超时、重复支付、账户冻结)和边缘场景(如金额为0、币种转换)",
agent=scenario_enricher,
context=[task2]
)
Step 5:质量校验Agent——用例优化与格式化
- 核心能力:
- 校验用例完整性(是否覆盖所有测试需求)、一致性(步骤与预期结果匹配)、可执行性(步骤无歧义);
- 通过DeepSeek自校验+规则引擎(如“步骤需包含操作对象和动作”)优化用例。
- 输出示例(支付模块用例片段):
| 用例ID | 标题 | 前置条件 | 步骤 | 预期结果 | 优先级 |
|---|---|---|---|---|---|
| PAY-001 | 正常支付(微信) | 用户余额≥100元,已登录 | 1. 选择商品,点击“支付” 2. 选择“微信支付” |
支付成功,订单状态更新为“已支付”,跳转订单详情页 | P0 |
| PAY-008 | 支付超时(30s未完成) | 用户余额≥100元 | 1. 发起支付,30s内不操作 | 系统自动取消支付,订单状态回滚为“待支付” | P1 |
三、关键优化策略:提升用例质量与生成效率
1. 提示工程(Prompt Engineering)优化
- 需求解析Prompt模板:
你需要从以下需求文档中提取测试需求,输出格式为JSON:
{"功能点": ["功能1", "功能2"], "边界条件": ["金额≤0", "商品数量≥10"], "异常场景": ["网络超时", "权限不足"]}
需求文档:{prd_content}
- 用例生成Prompt模板:
基于测试需求:{test_requirements},用等价类划分法设计测试用例,步骤需具体到点击按钮/输入值,预期结果需包含界面反馈和数据状态。
2. 知识库构建(GraphRAG)
- 数据来源:历史测试用例、缺陷库(JIRA)、系统架构文档、业务规则手册;
- 实体关系示例:
- 实体:支付模块、订单状态、第三方接口、Redis缓存;
- 关系:支付模块→依赖→第三方接口;订单状态→包含→待支付/已支付/已取消。
3. 多模型协作优化
- DeepSeek-R1:擅长长文本理解(需求解析、场景补全);
- DeepSeek-Coder:擅长结构化代码/表格生成(用例格式化);
- CrewAI任务调度:通过
context参数传递中间结果,避免信息丢失。
四、落地效果与适用场景
1. 效率与质量提升
- 用例设计周期:复杂模块(如支付/订单)从人工5天→AI协作8小时(提效85%);
- 场景覆盖率:异常场景覆盖度从人工60%→AI生成92%(基于历史缺陷库验证);
- 维护成本:需求变更时,通过CrewAI重新执行流水线,用例更新成本降低70%(无需人工逐行修改)。
2. 适用场景
- 复杂业务模块:支付、订单、权限管理(规则多、异常场景复杂);
- 需求频繁变更:互联网产品迭代(每周1-2次需求更新);
- 标准化测试团队:需统一用例格式与质量标准的中大型团队。
五、工具链与部署建议
| 组件 | 推荐工具/框架 | 说明 |
|---|---|---|
| 多智能体协作 | CrewAI | 定义Agent角色、任务依赖与协作流程 |
| 大模型 | DeepSeek-R1(理解)+ DeepSeek-Coder(生成) | 处理需求解析、用例生成与优化 |
| 知识库 | GraphRAG + Neo4j | 存储历史缺陷与业务规则,支持场景补全 |
| 输出管理 | Excel/TestRail/TestLink | 用例导入与管理平台 |
| 部署方式 | Docker + FastAPI | 封装为API服务,支持测试平台集成 |
总结
通过CrewAI实现多智能体协作,结合DeepSeek的文本理解与生成能力,可构建“需求解析→用例生成→场景补全→质量校验”的全自动化流水线。核心价值在于:
- 降本提效:将测试工程师从重复劳动中解放,聚焦高价值的用例评审与风险分析;
- 质量保障:通过历史知识库与多模型协作,覆盖人工易遗漏的异常场景;
- 敏捷适配:需求变更时快速响应,用例维护成本大幅降低。
该方案尤其适合业务复杂、迭代频繁的测试团队,是测试左移与智能化转型的关键实践。
更多推荐
 14
14 0
0- 0



 已为社区贡献13条内容
已为社区贡献13条内容

所有评论(0)