
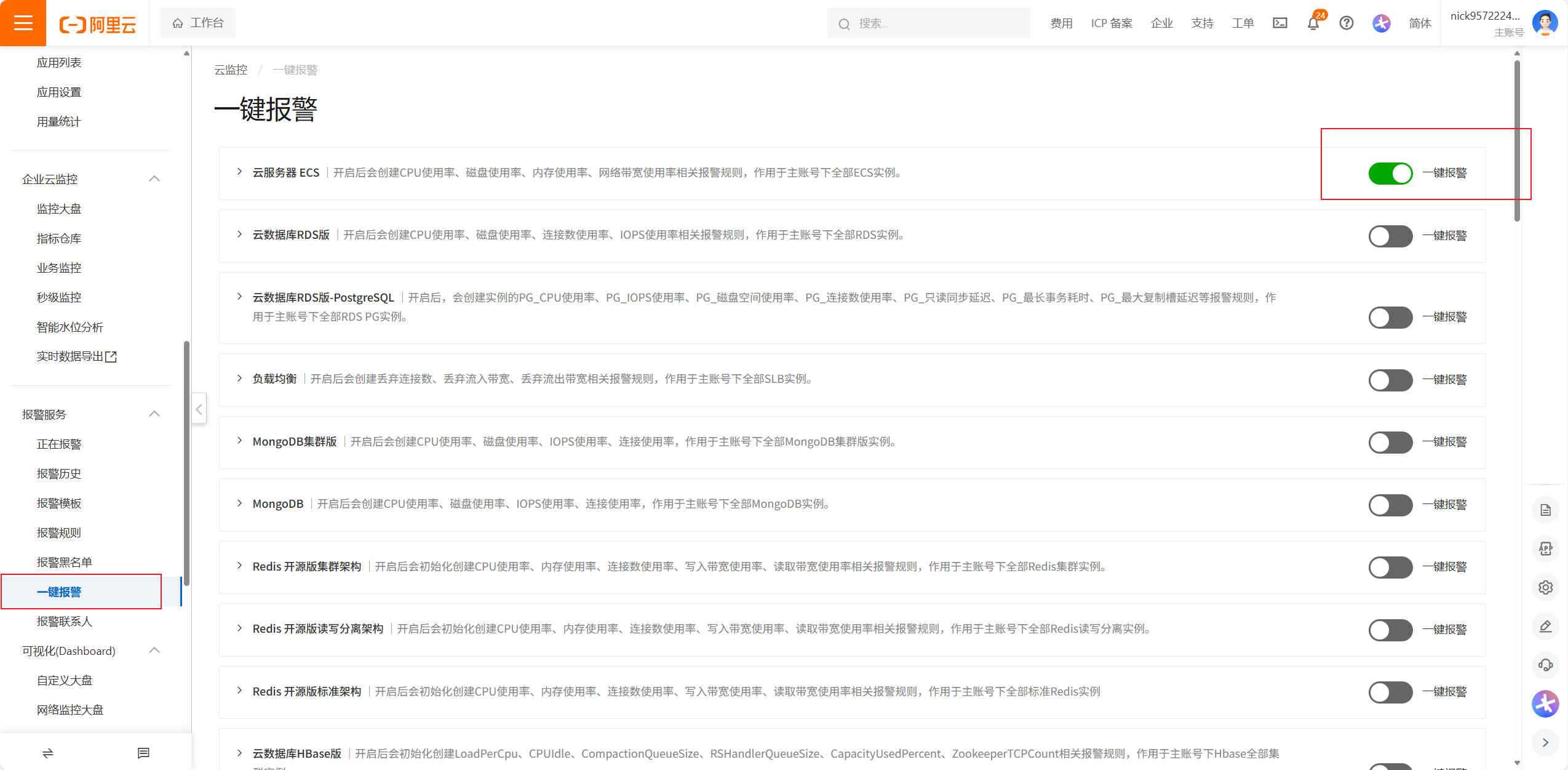
开通阿里云云主机监控策略、以及系统报警服务配置、以及阿里云云服务的一键告警
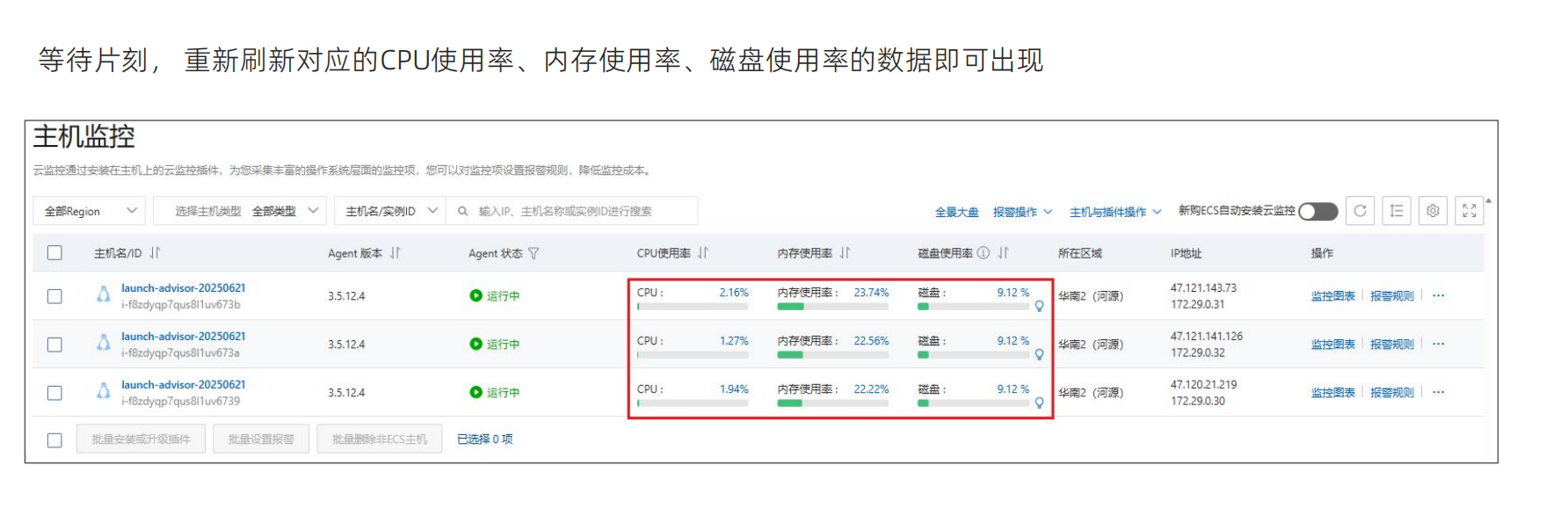
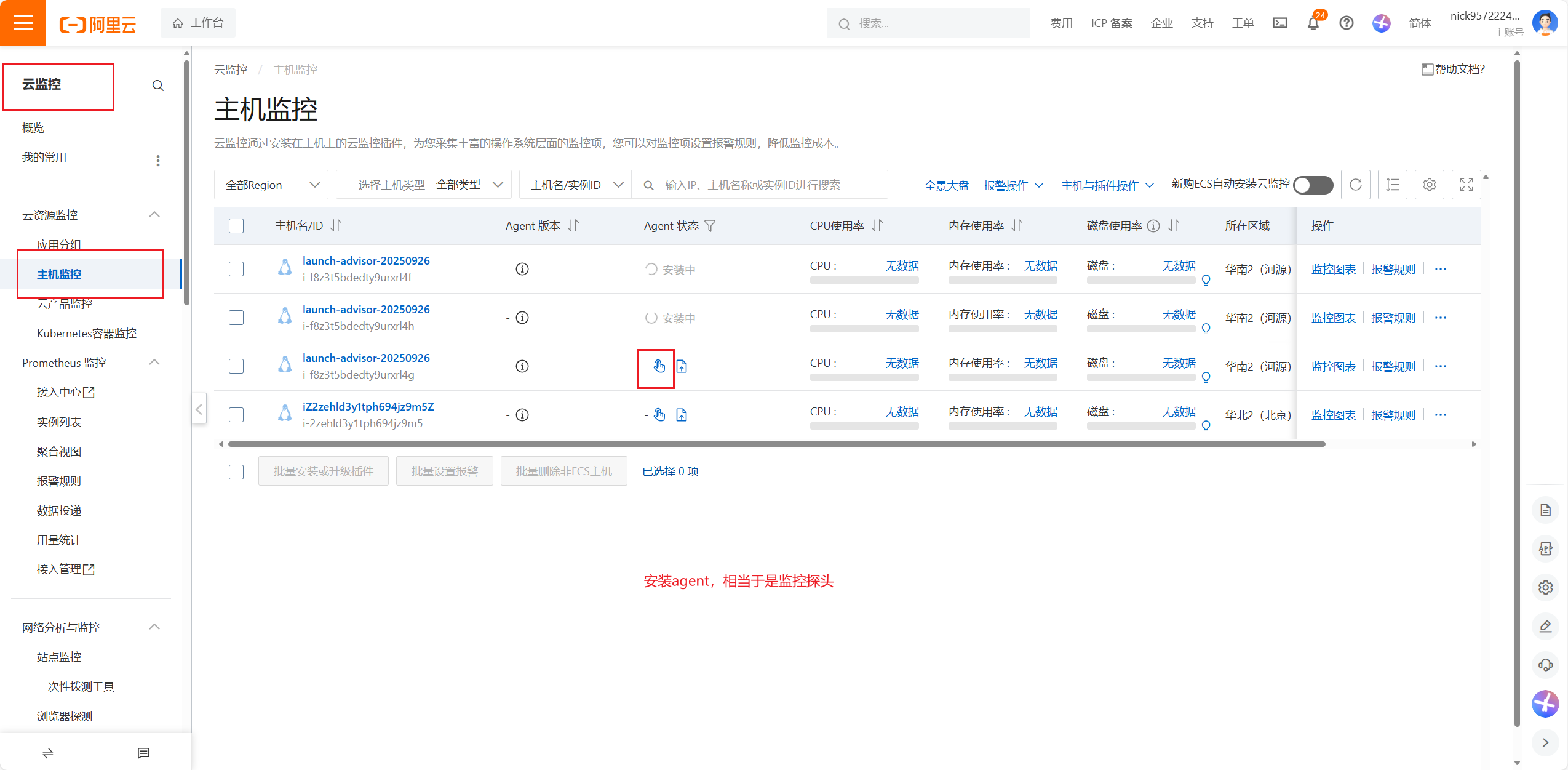
Agent可以连接成是监控探头,要在各个服务器安装一个监控探头,看一下服务器的状态以及网络CPU内存磁盘都可以检测到,所以这个Agent安装到各个节点上就可以做监控了这样就监控到了各个节点点开之后还可以看到服务器各种各样的监控情况,如CPU的使用率,内存的使用率,系统平均负载情况,磁盘监控指标,读写的情况,以及公网的流量,公网磁盘的一些参数数据,以及进程的监控网络的监控,云盘的监控以及GPU的监控
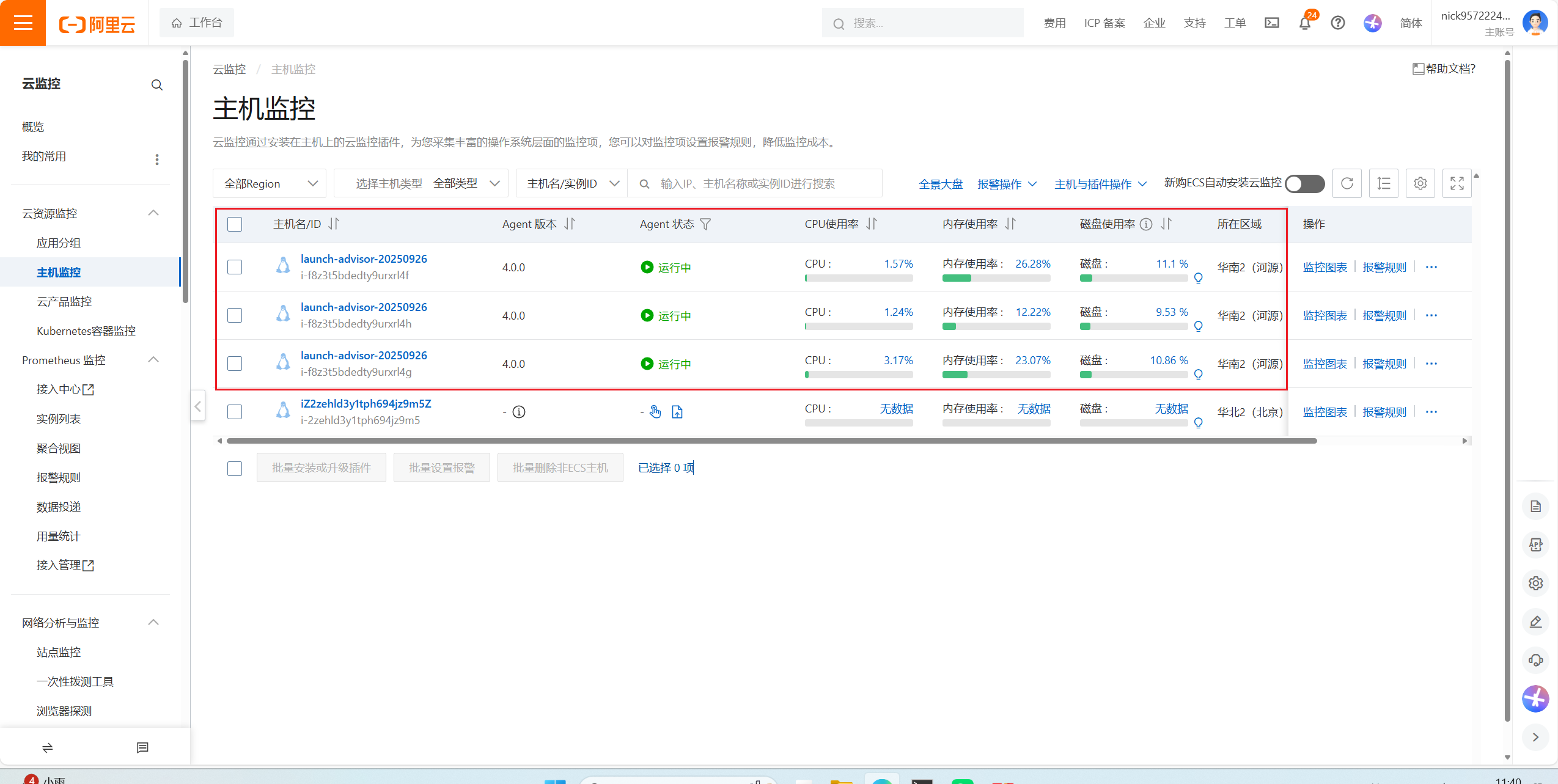
阿里云云主机监控策略
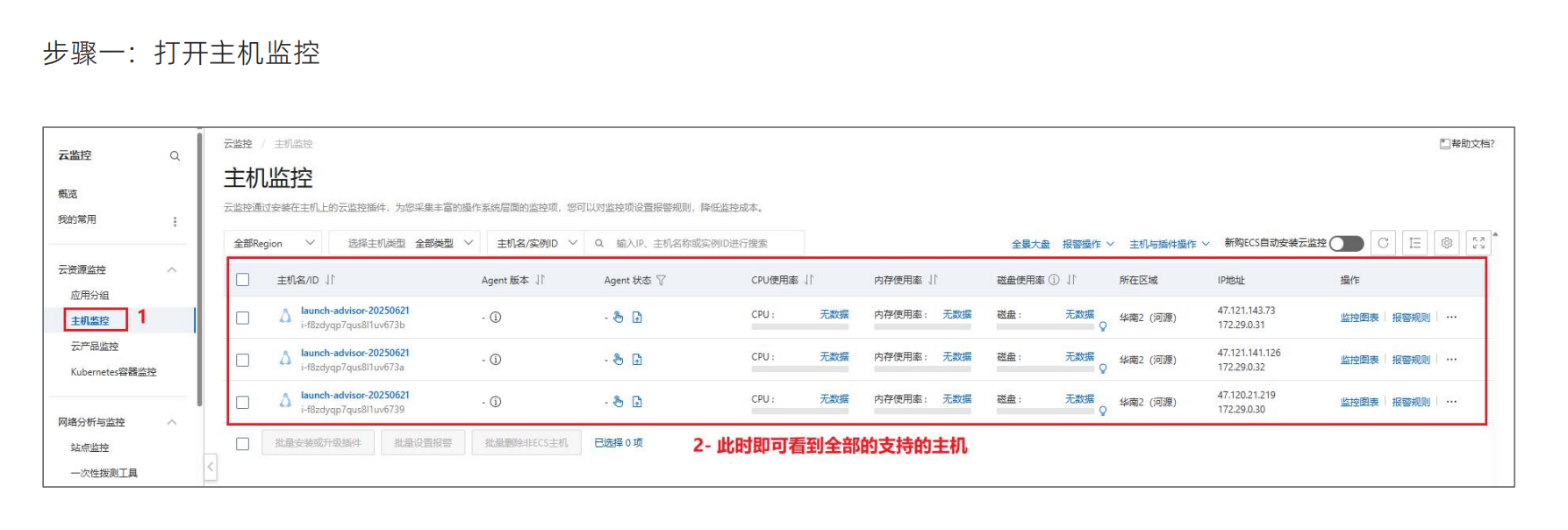
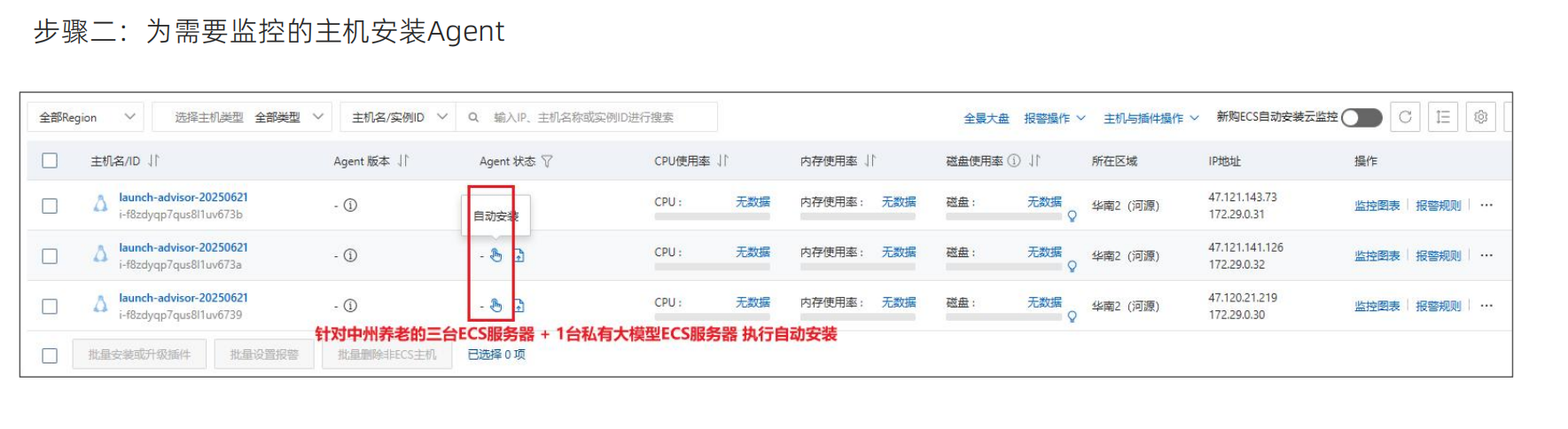
Agent可以连接成是监控探头,要在各个服务器安装一个监控探头,看一下服务器的状态以及网络CPU内存磁盘都可以检测到,所以这个Agent安装到各个节点上就可以做监控了
这样就监控到了各个节点
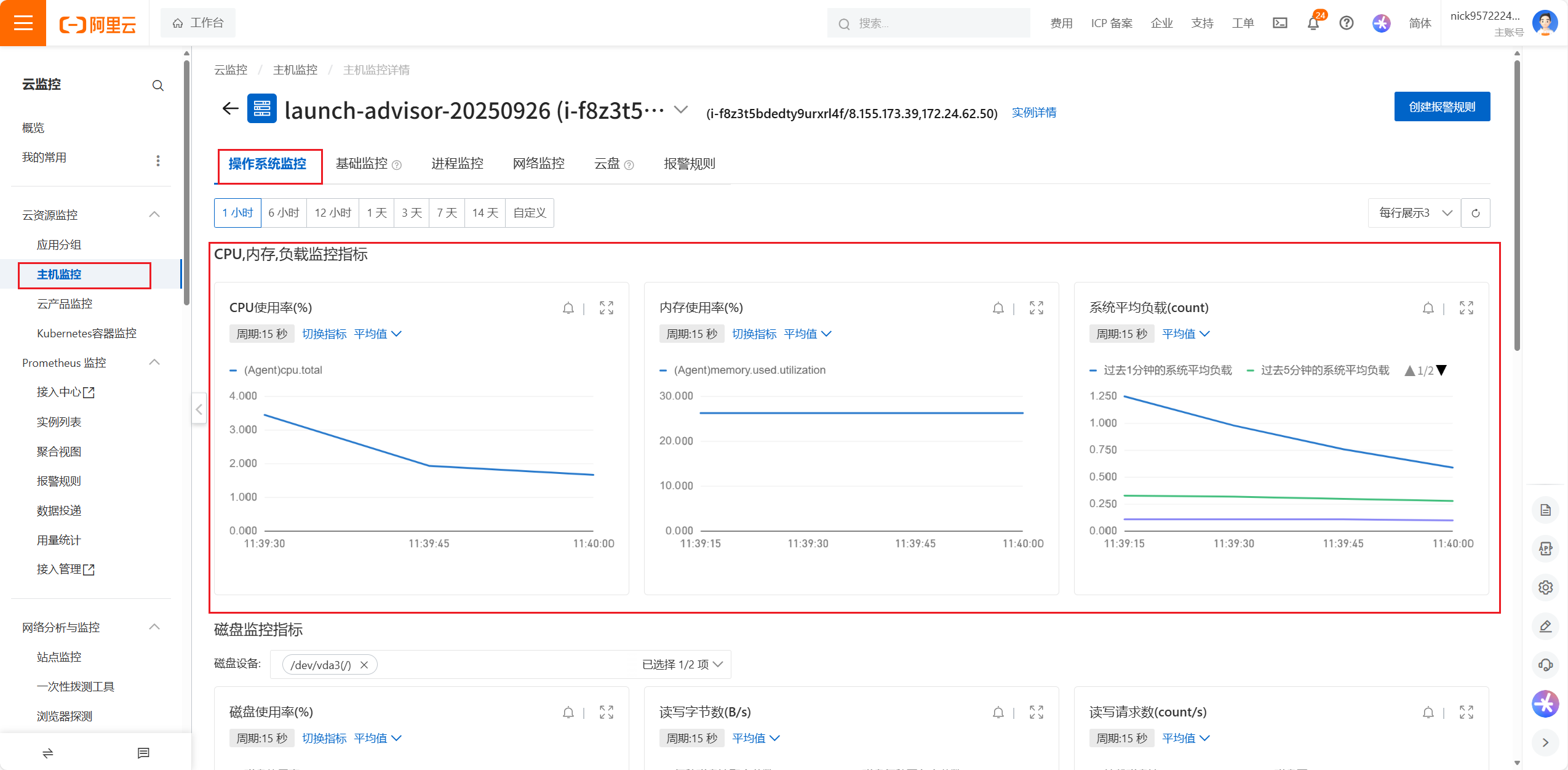
点开之后还可以看到服务器各种各样的监控情况,如CPU的使用率,内存的使用率,系统平均负载情况,磁盘监控指标,读写的情况,以及公网的流量,公网磁盘的一些参数数据,以及进程的监控网络的监控,云盘的监控以及GPU的监控,报警的规则,也就是看板
系统报警服务配置
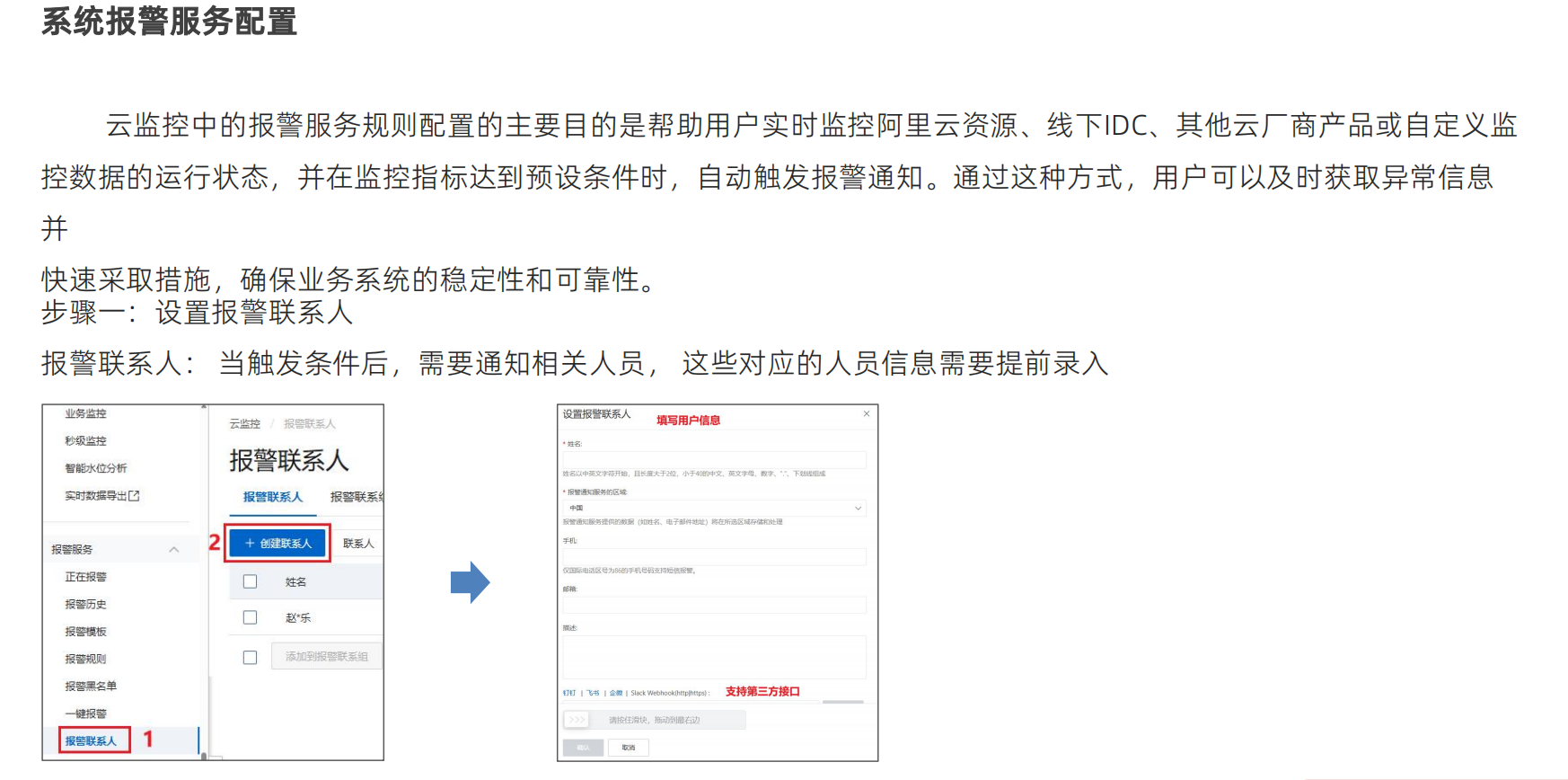
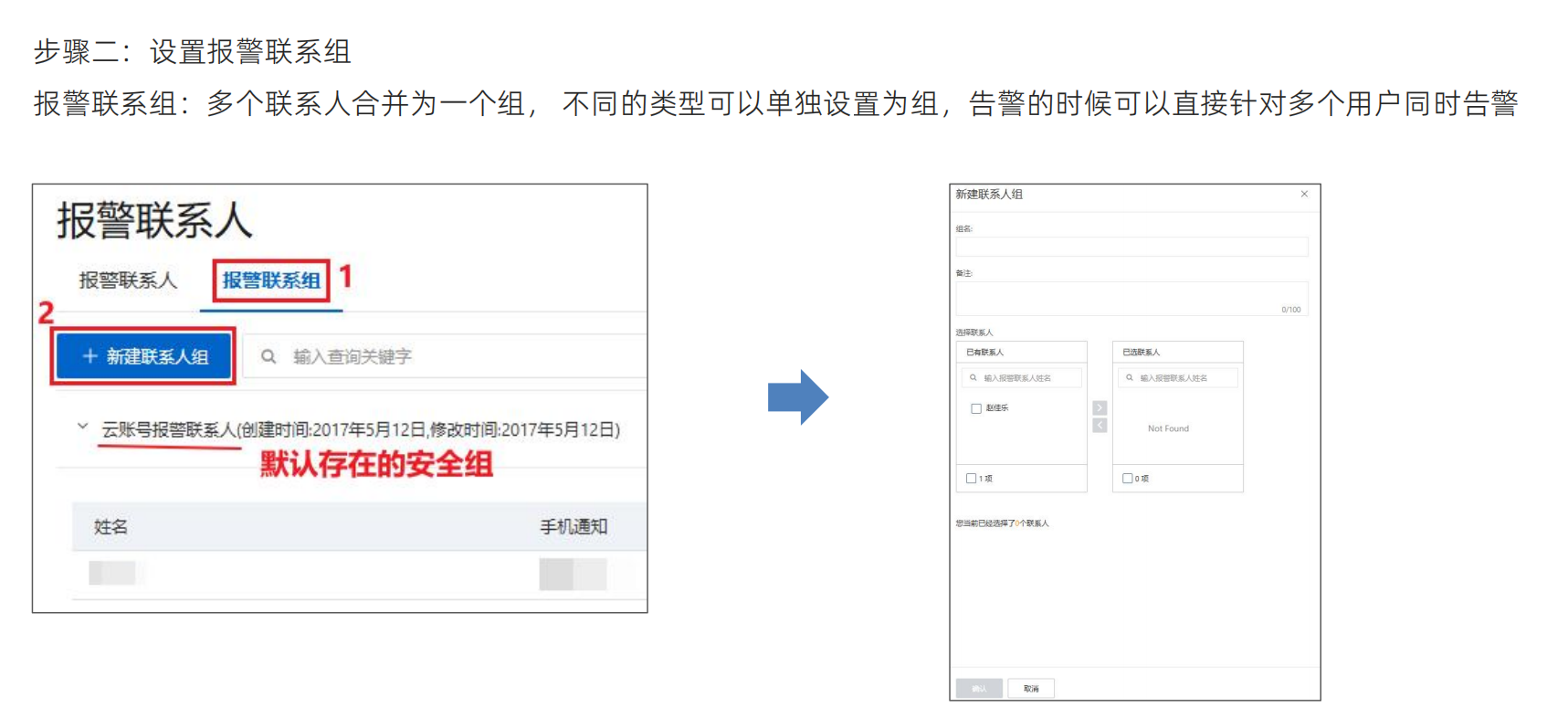
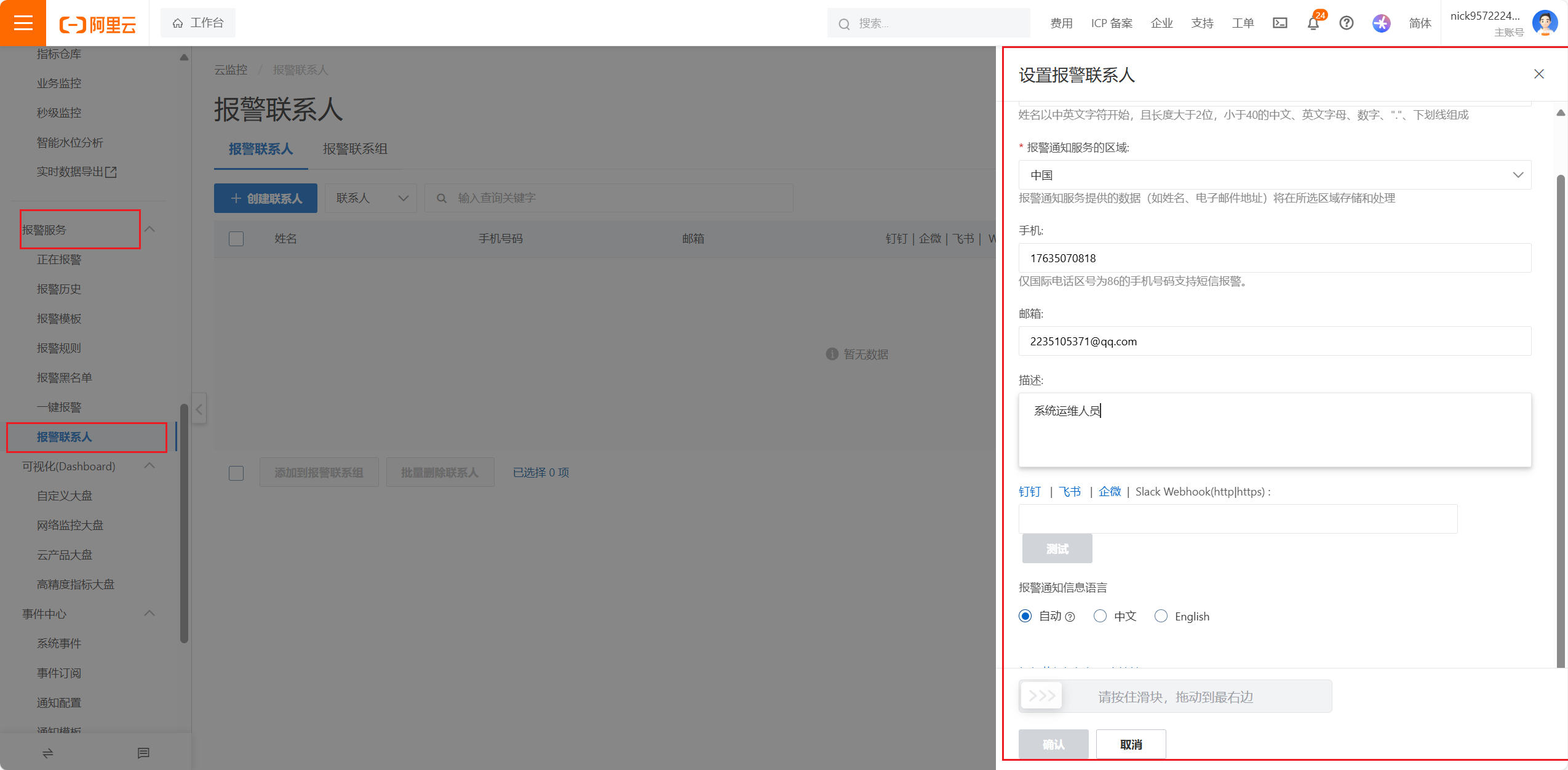
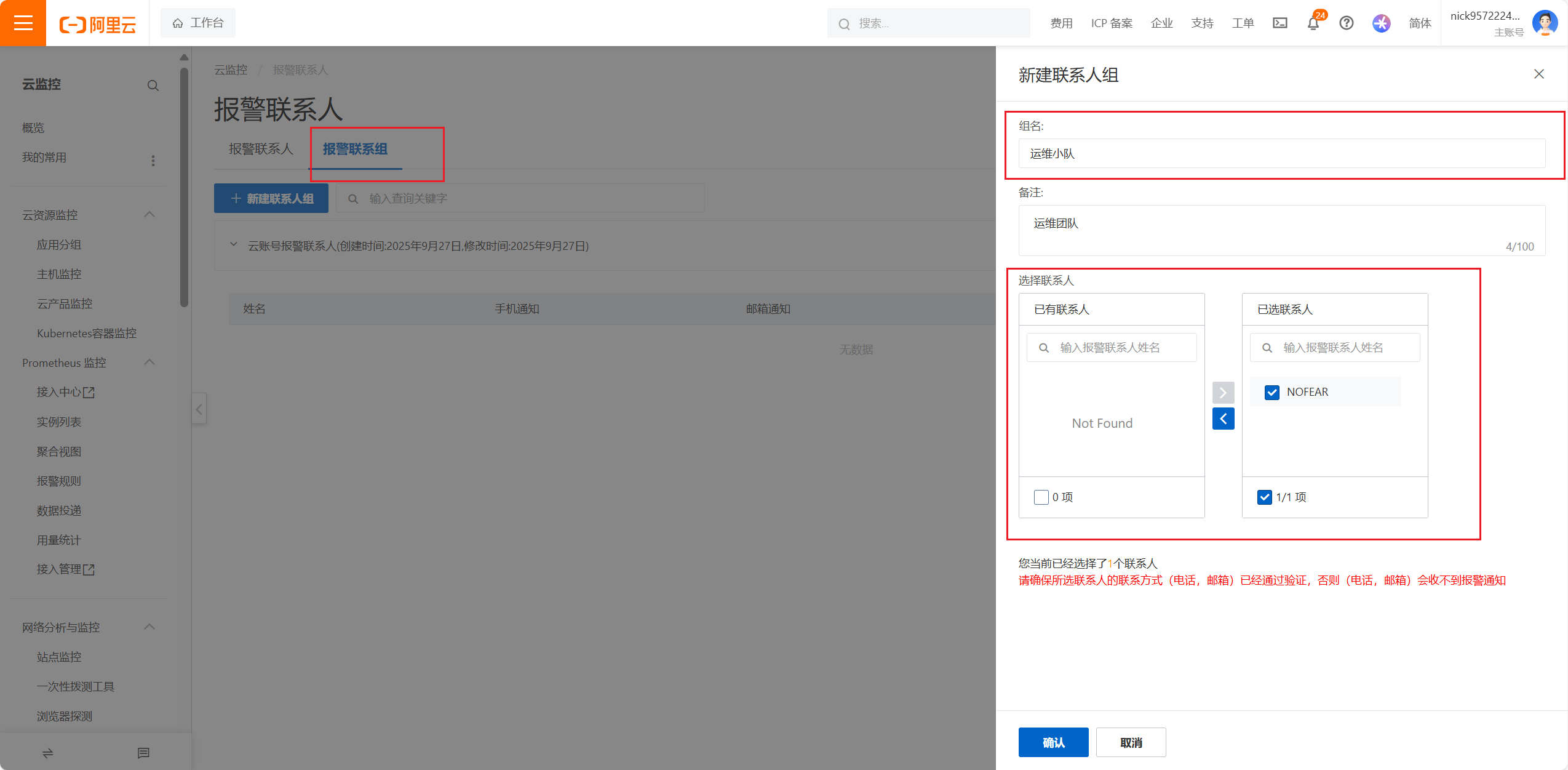
设置告警联系人,还要设置告警组,因为很多时候不光要通知一个人,还需要通知一个团队,如运维组的工作人员以及领导,所以多个人要设置成一个组,告警的时候可以根据这个组统一进行告警工作
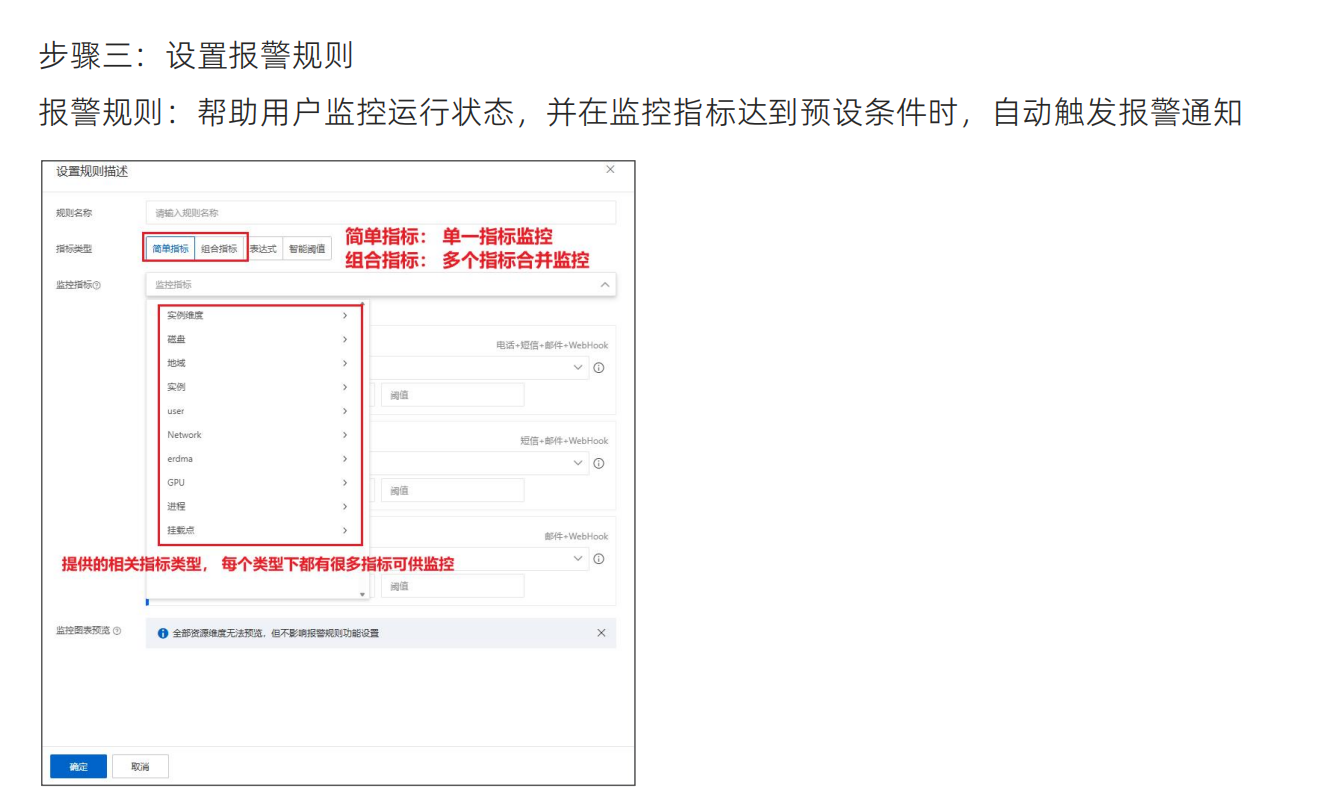
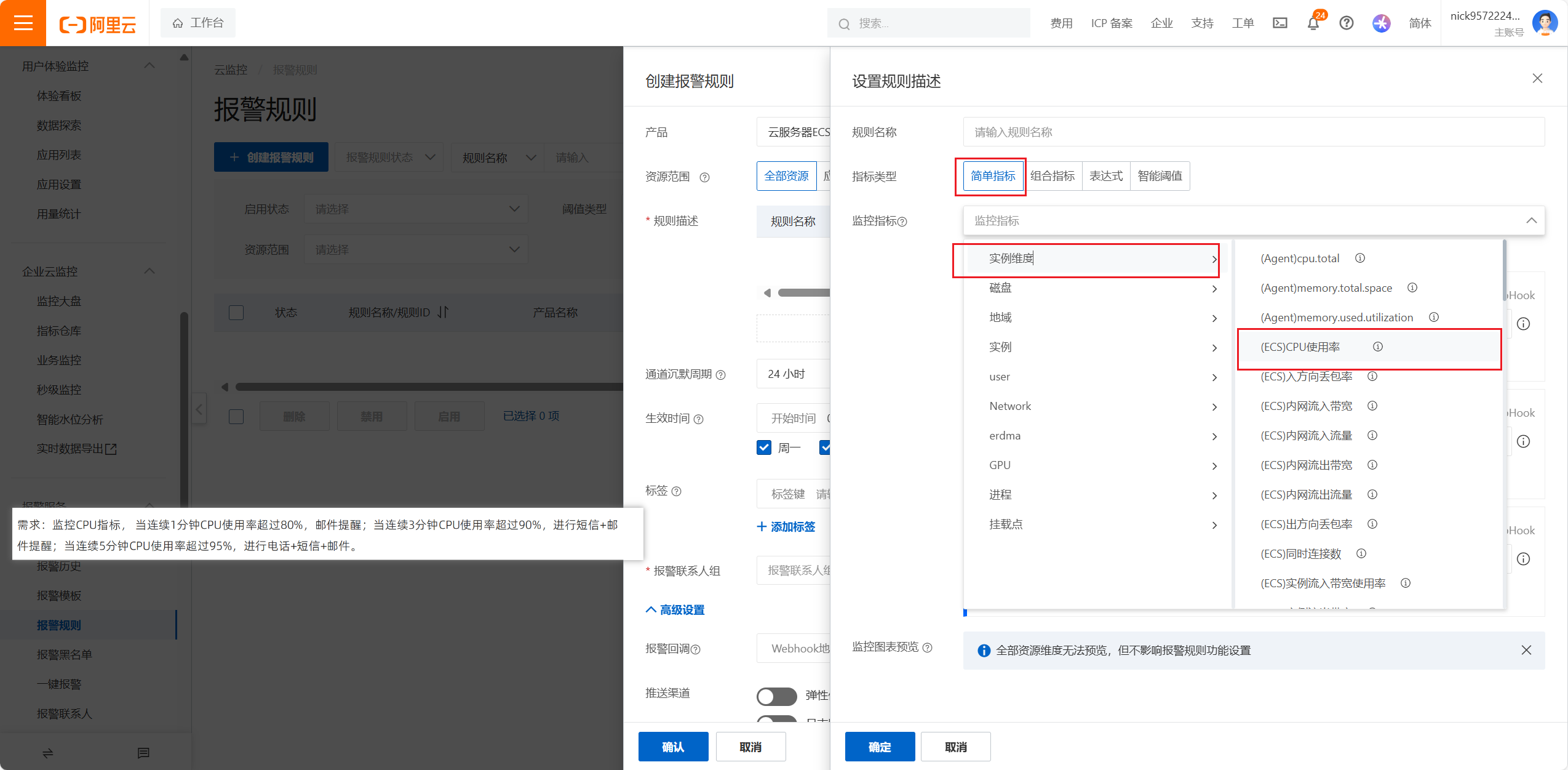
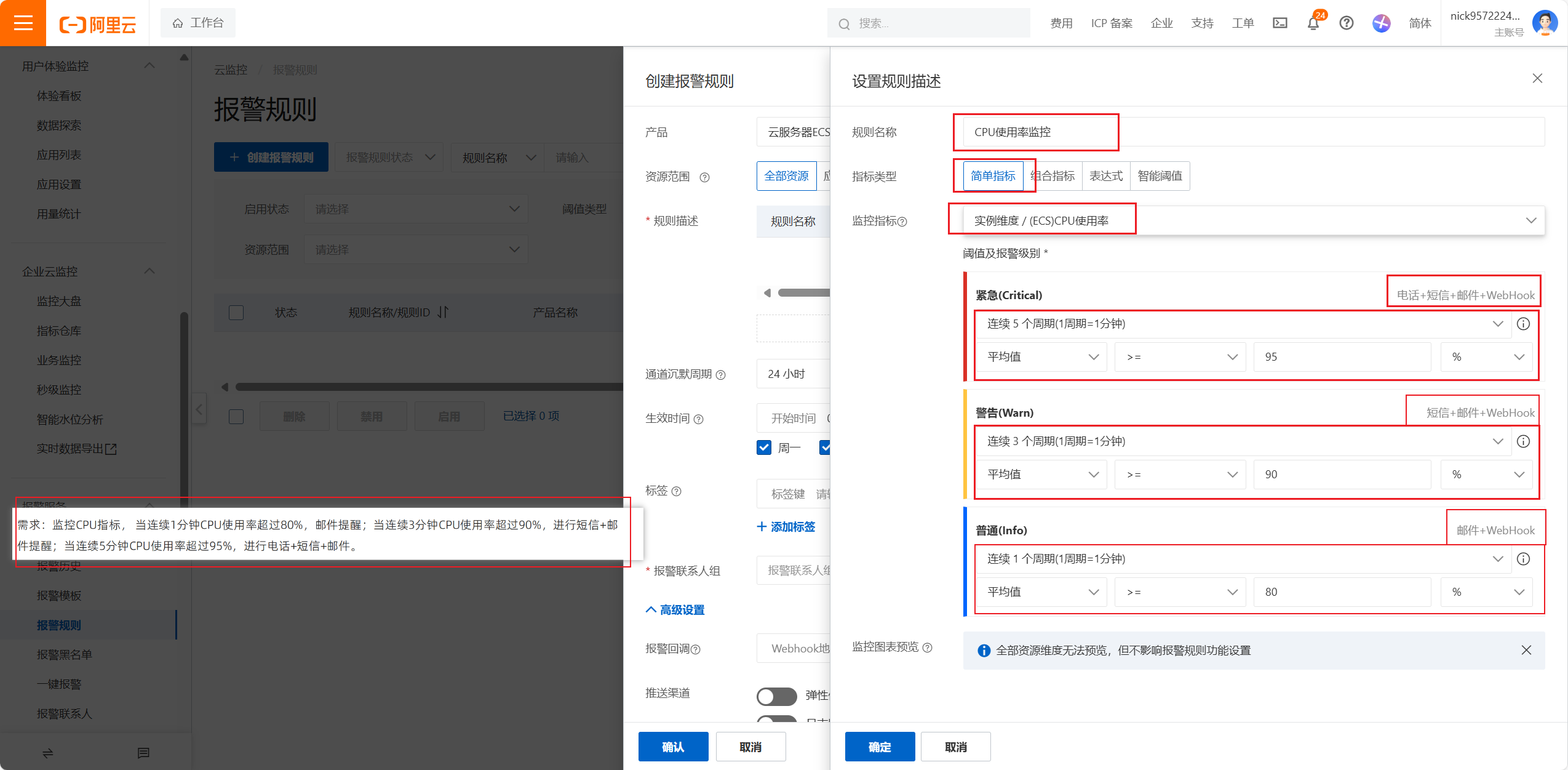
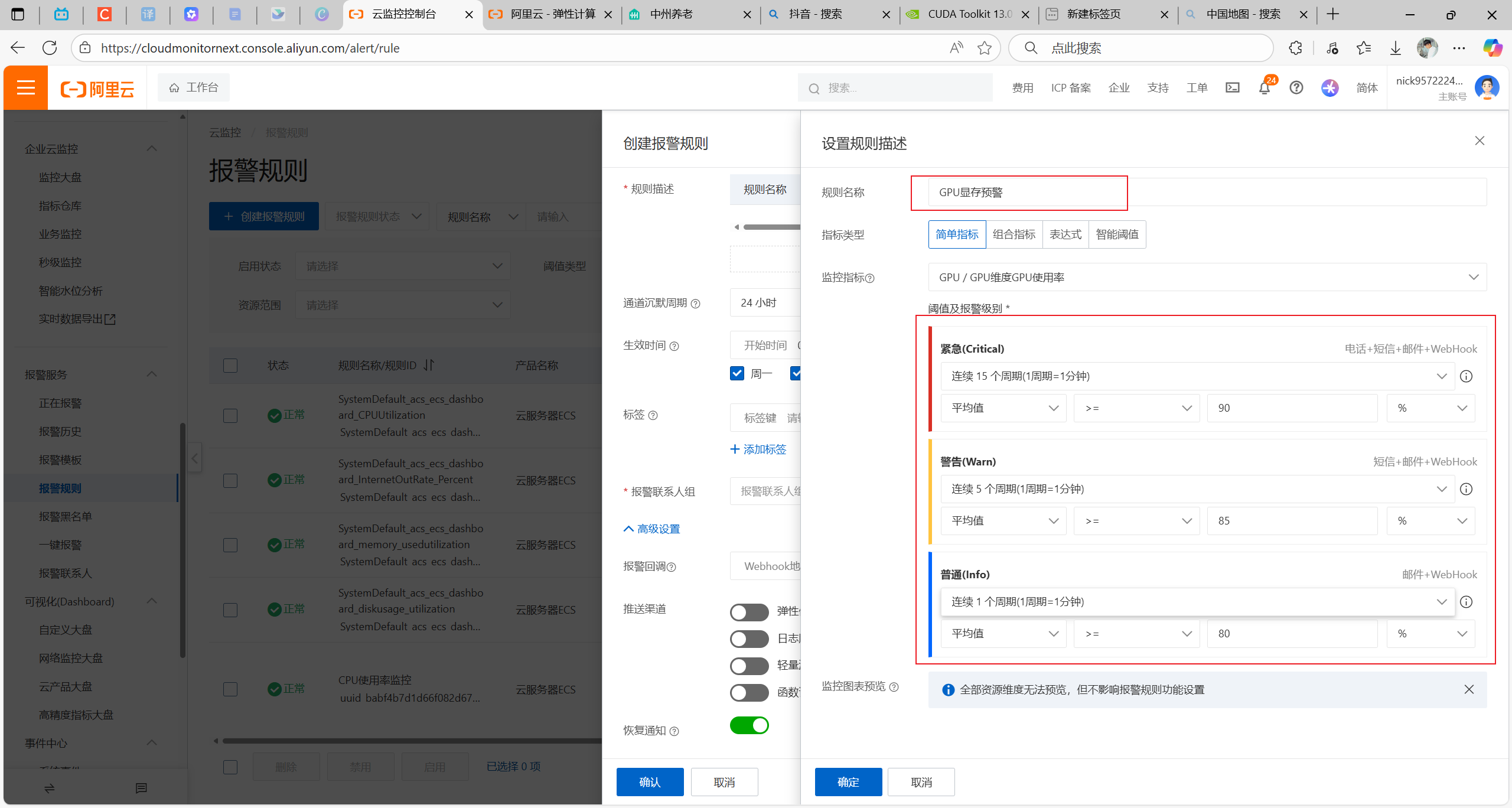
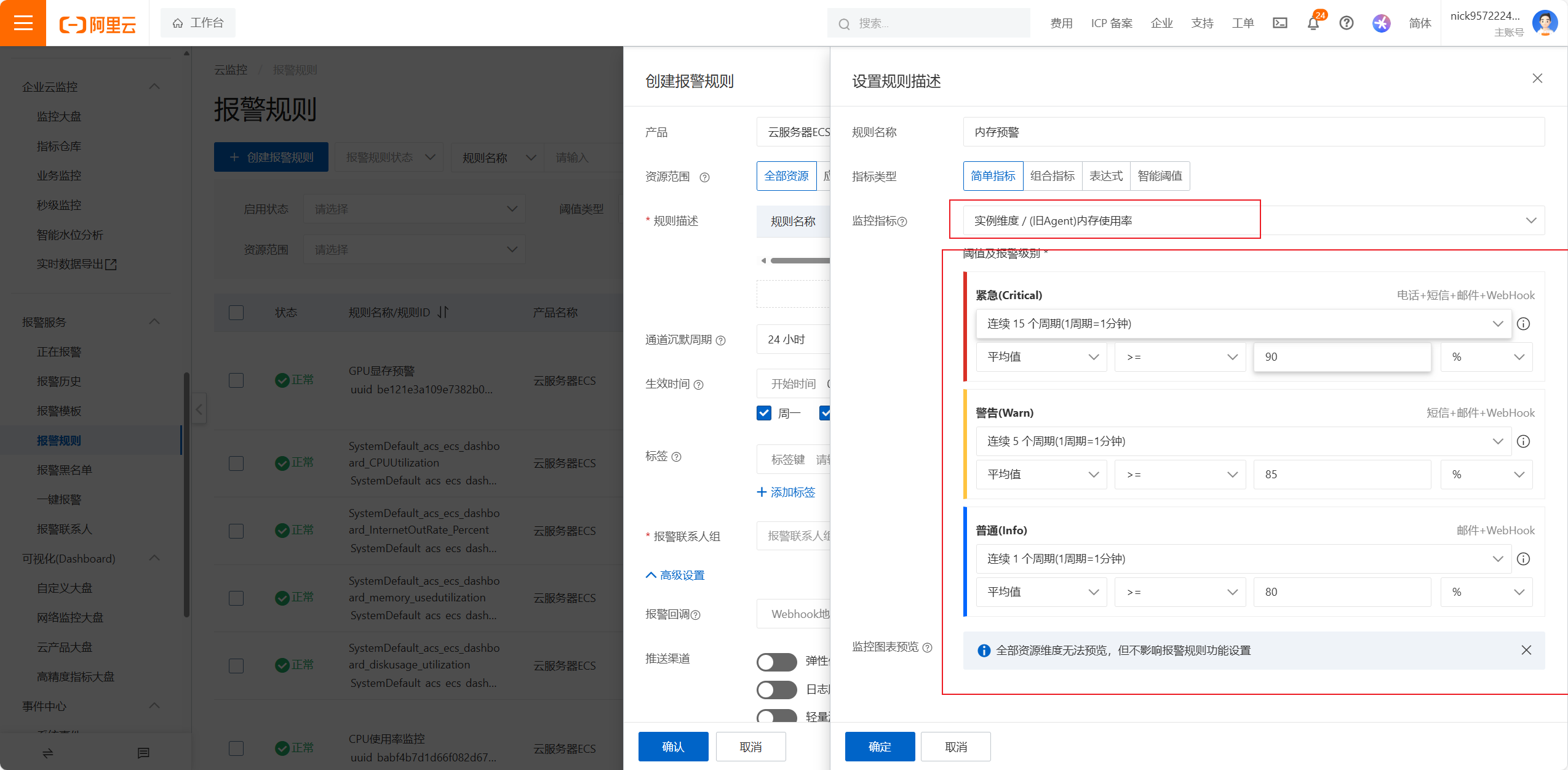
监控的指标可以有多个维度:比如实例维度磁盘维度地域维度实例维度用户维度网络维度GPU维度进程维度挂载的磁盘的维度都可以进行监控,提供了n多种监控的方式
这样告警联系人和告警组就都设置好了
简单指标是对某一项指标进行监控
组合指标主要是对多项指标联合进行监控,比如CPU占有率90%加上内存90%才会进行预警
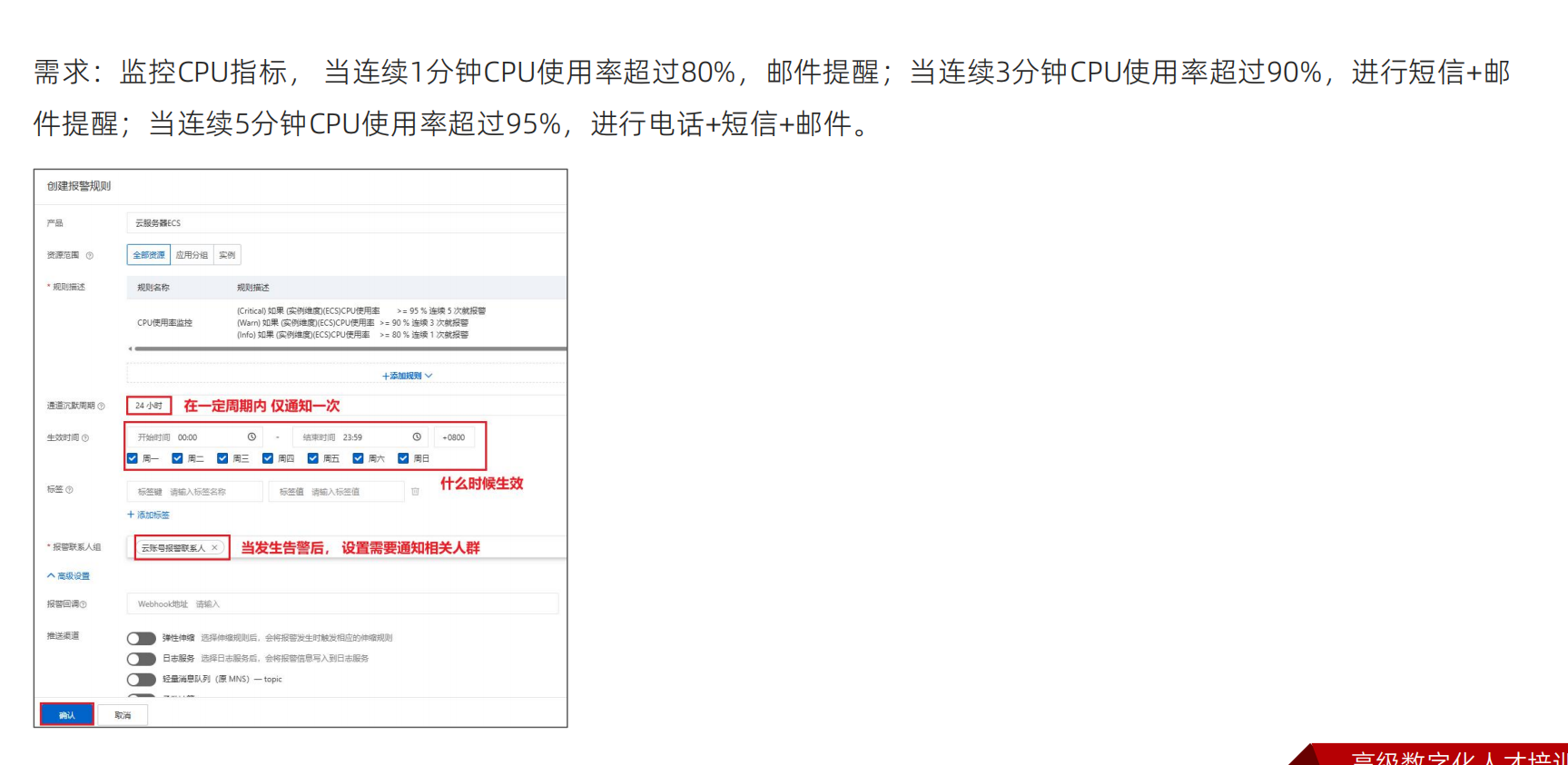
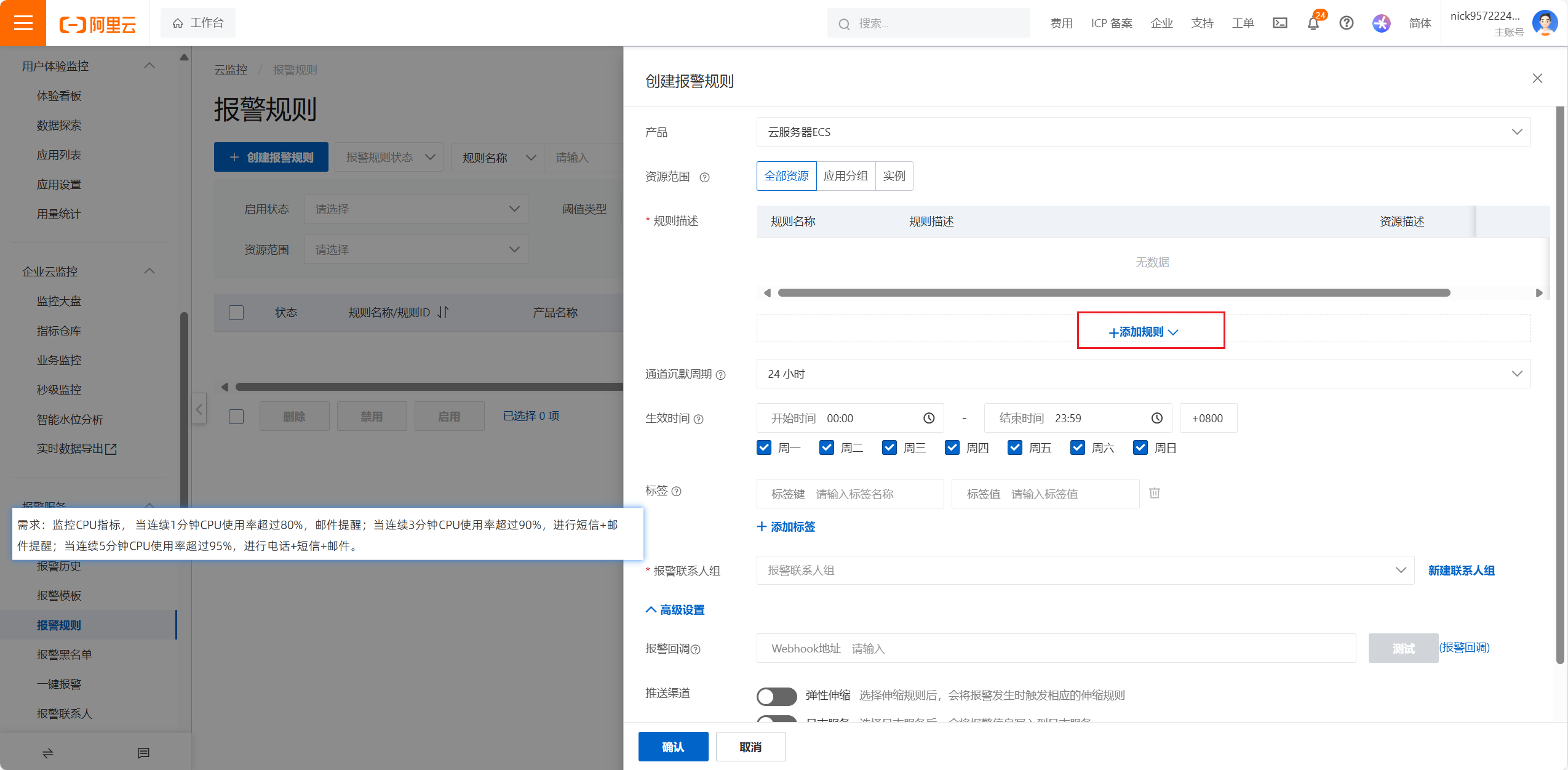
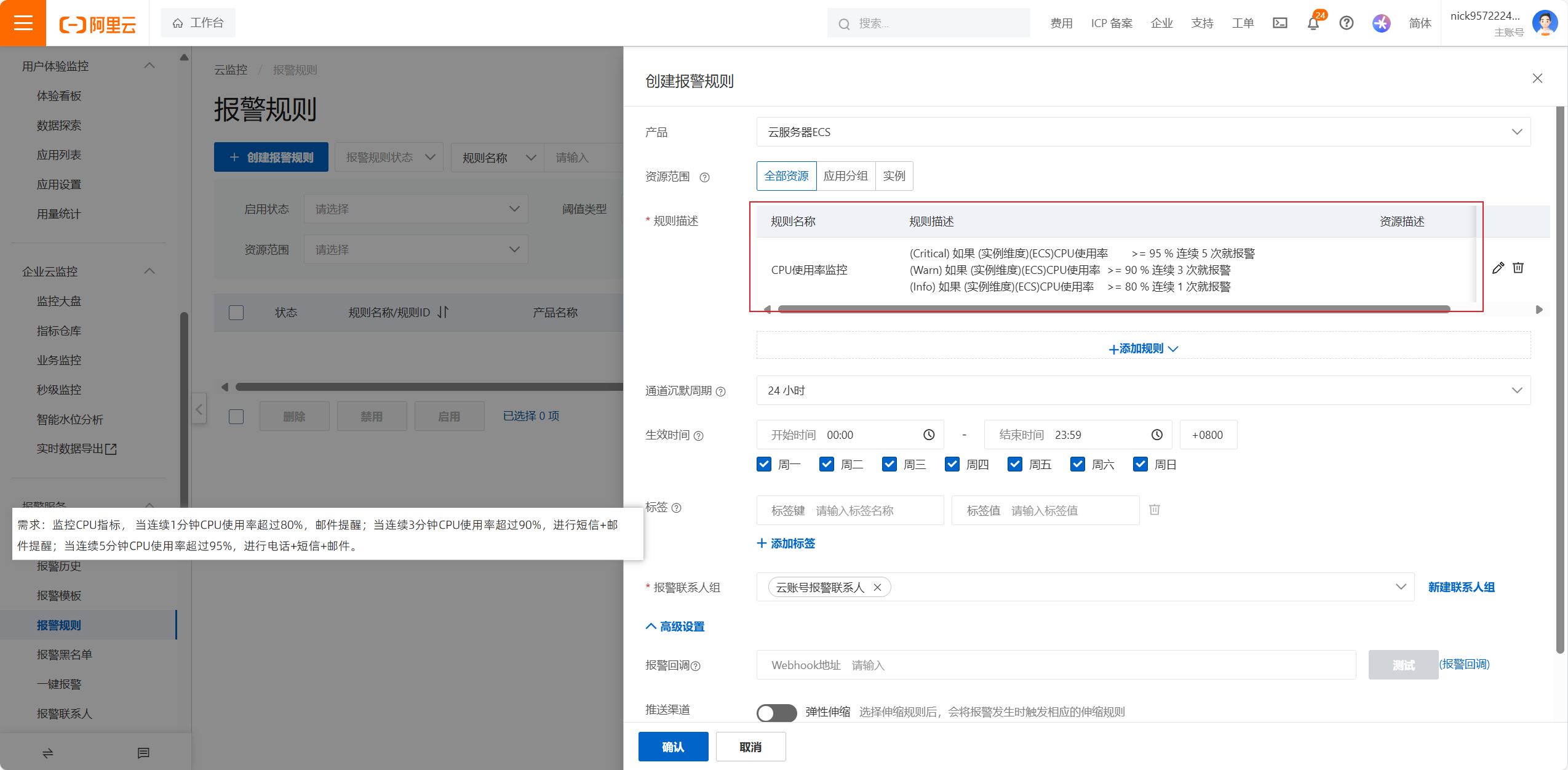
通道沉默周期表示:在一定范围内,同样的告警只会发送一次,不会重复发送,要根据服务器的重要程度以及能接受的最长时间进行选择
生效时间为:周一到周日00:00-23:59,意味着7*24小时监控
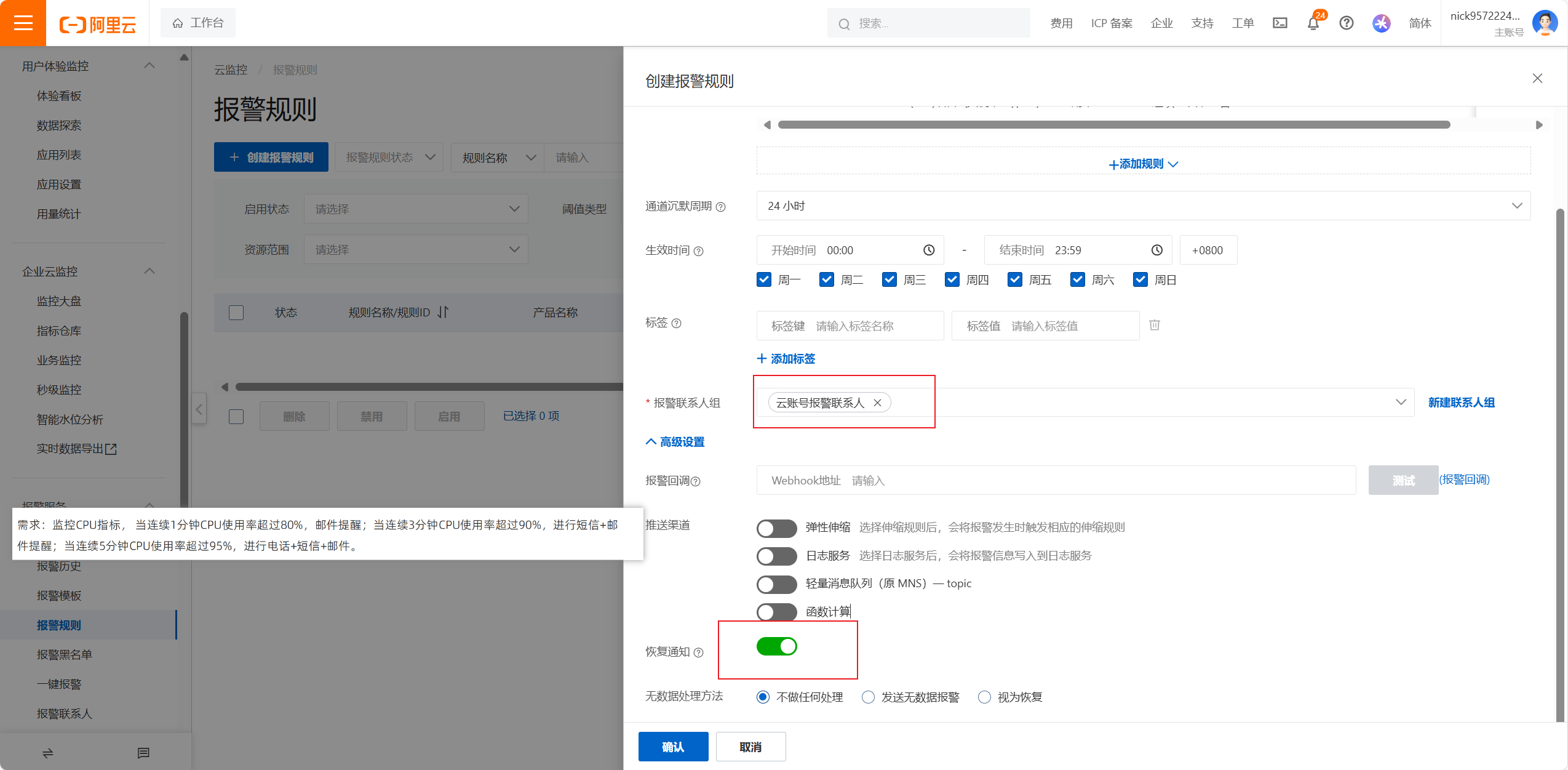
报警回调可以做一些告警的系统,通过回调告诉告警信息
属于高级配置
恢复通知也要加上,服务器恢复正常也会通知
设置完成
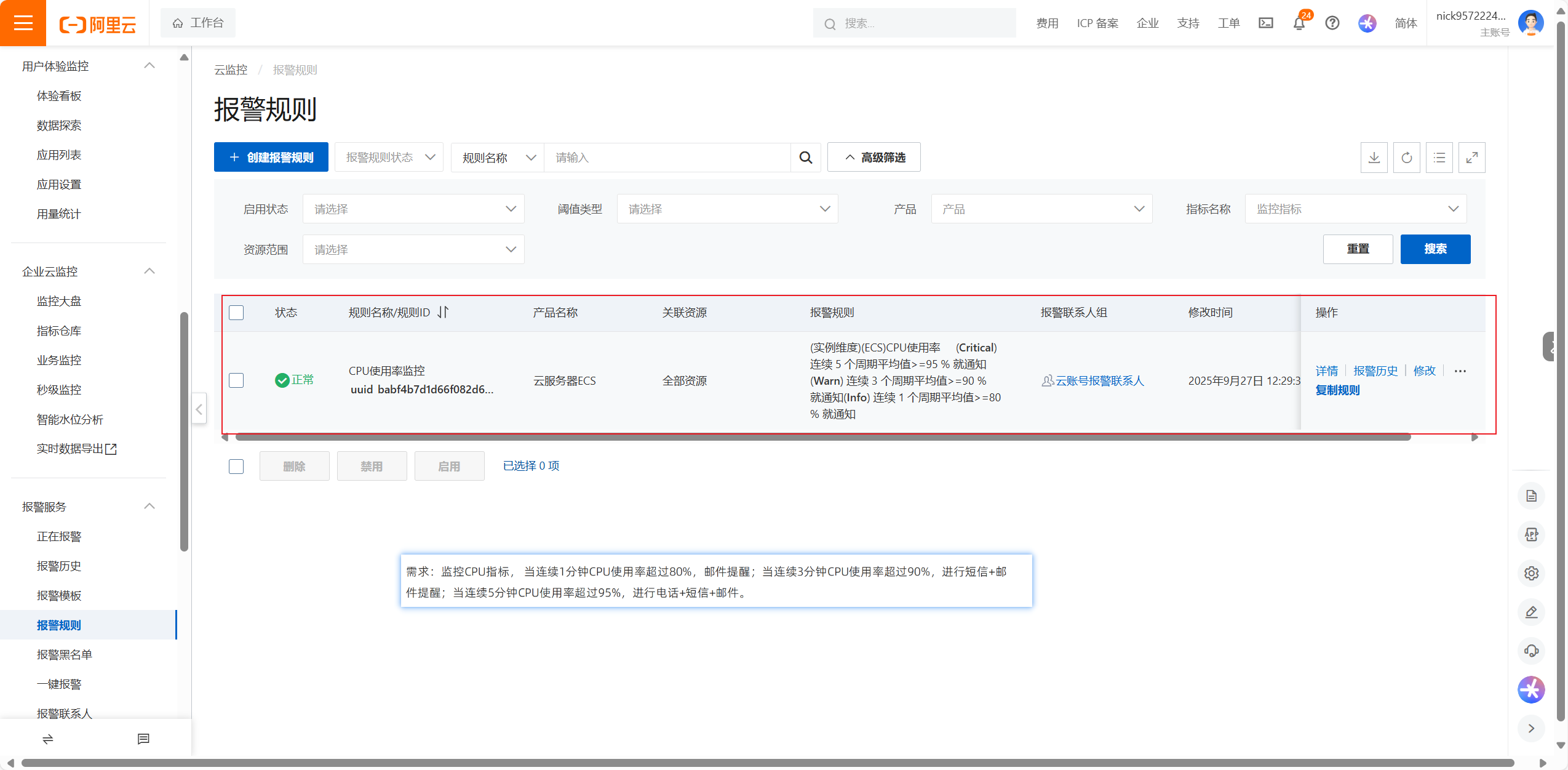
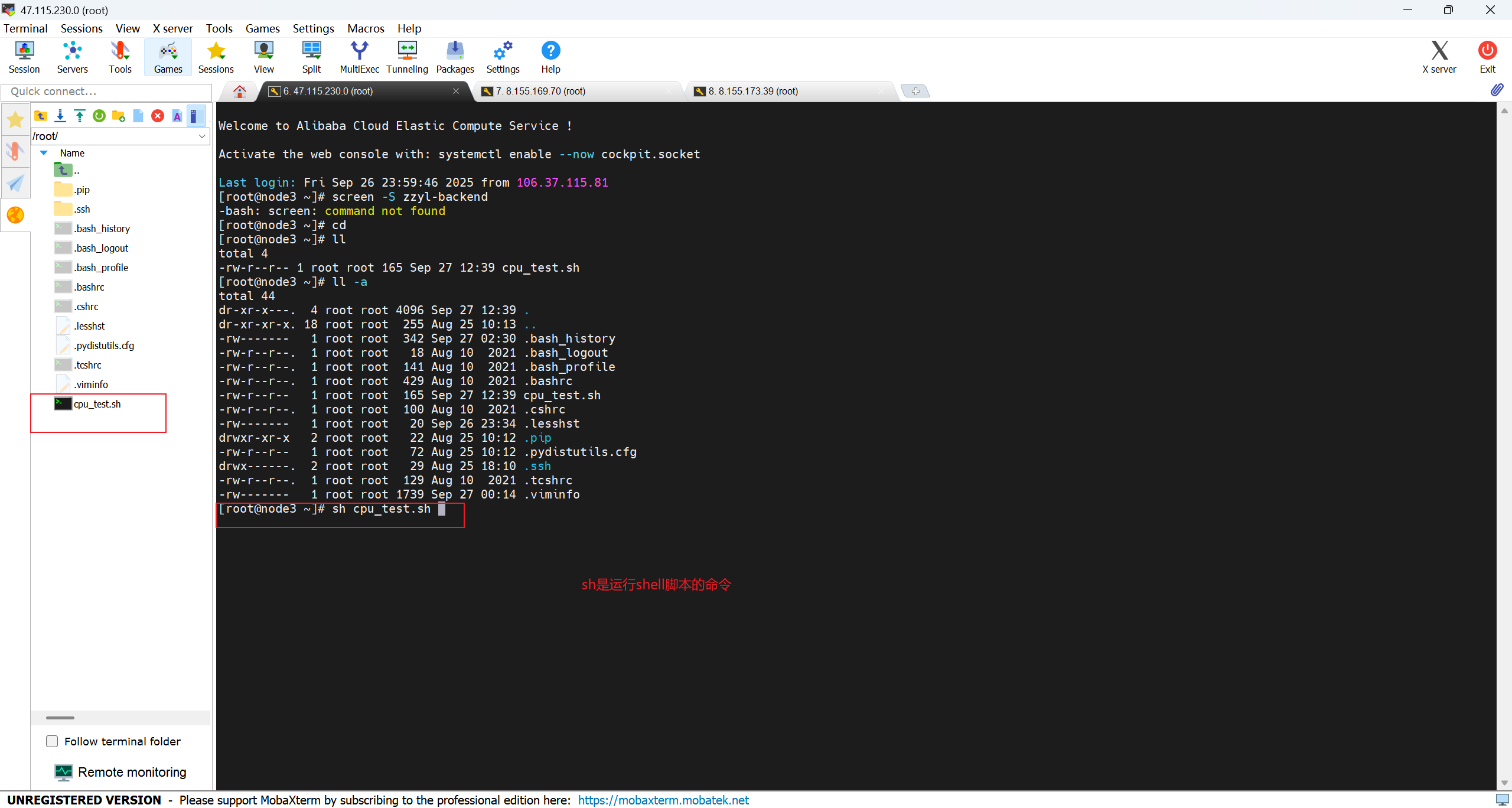
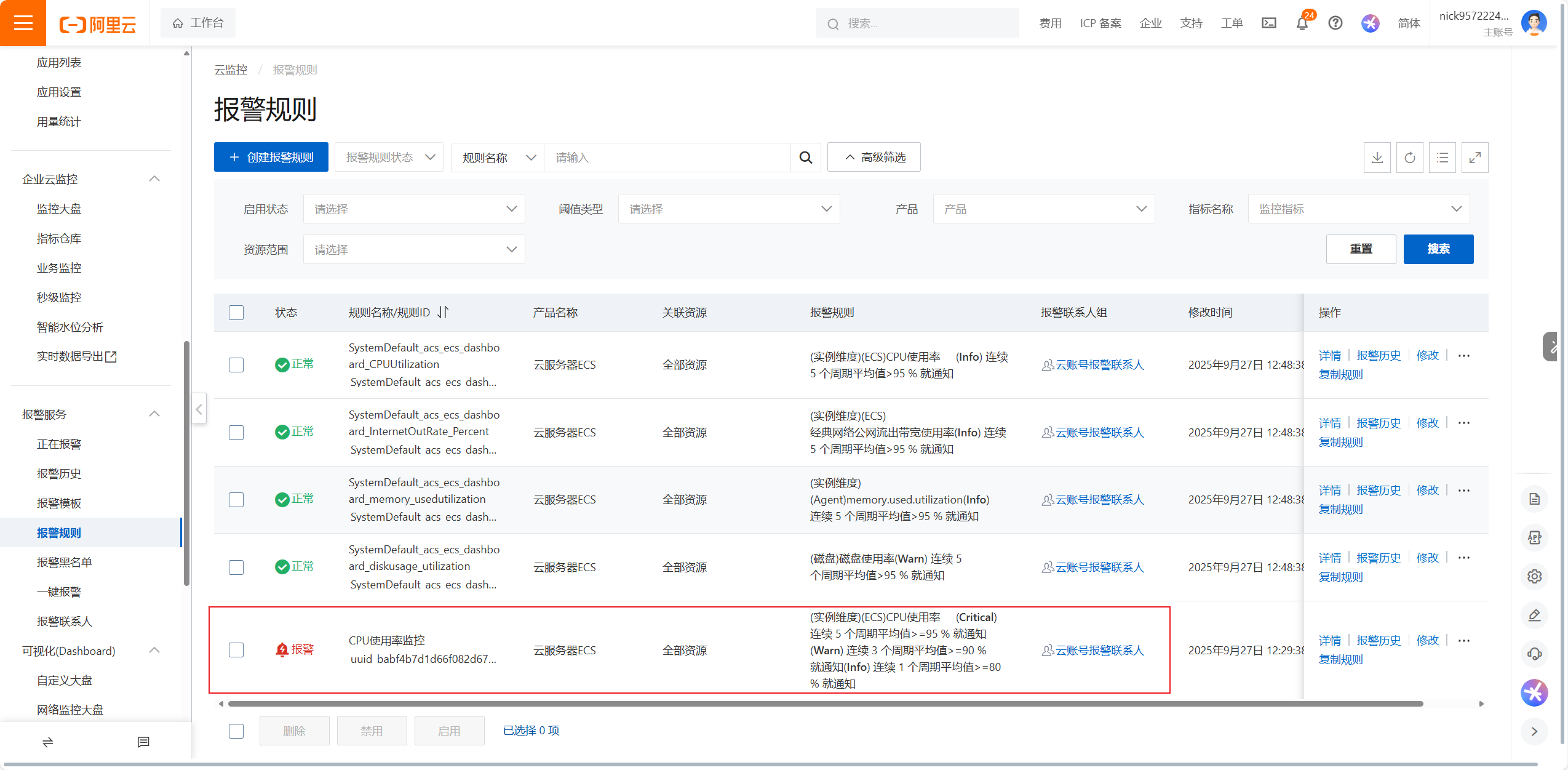
有三台ECS服务器,但是这个配置是针对所有的ESC服务器的,要进行测试CPU达到阈值是否可以预警,只需要测试一台服务器的就可以
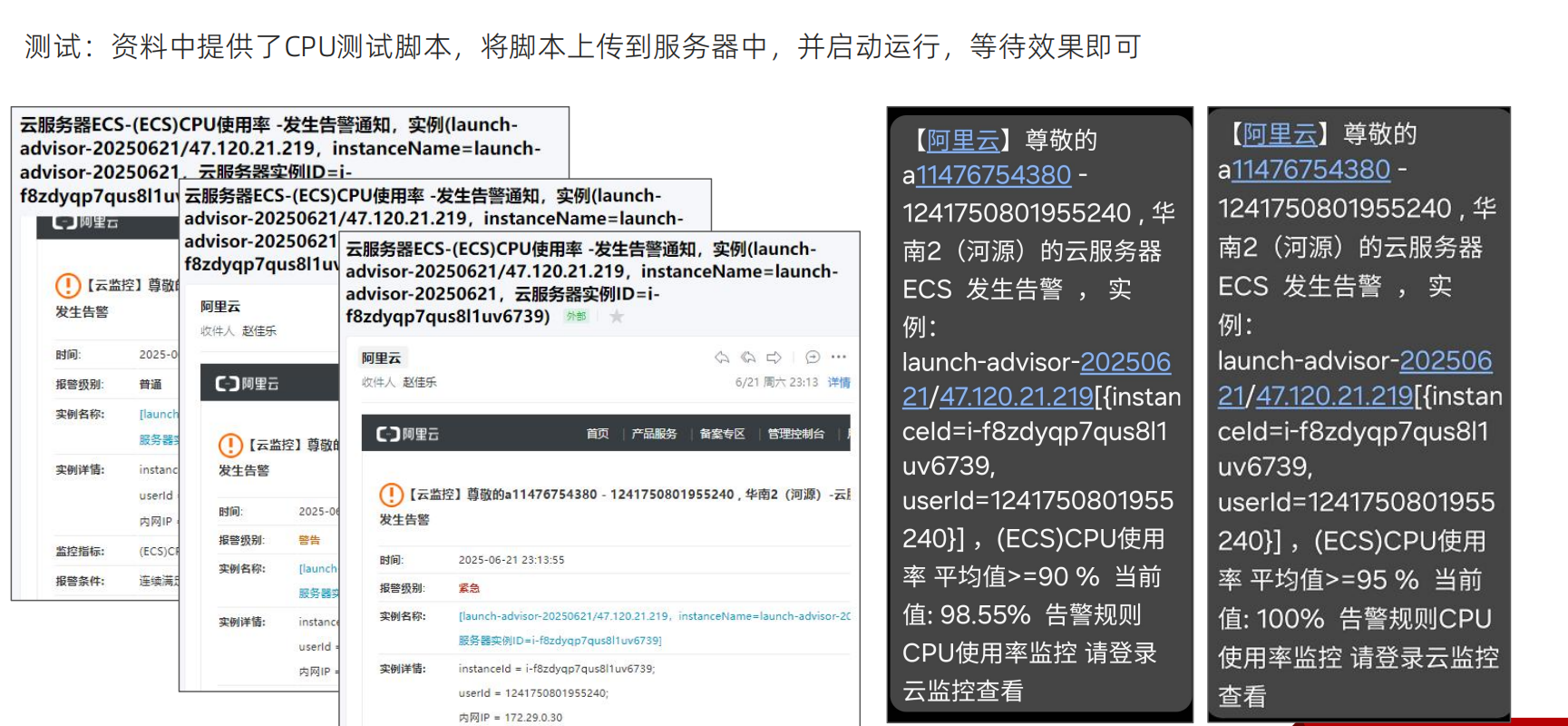
sh是运行shell脚本的命令
这个shell脚本里执行的是一个连续且不断触发的命令,这个命令会疯狂的占用CPU的资源,直到占用100%的资源
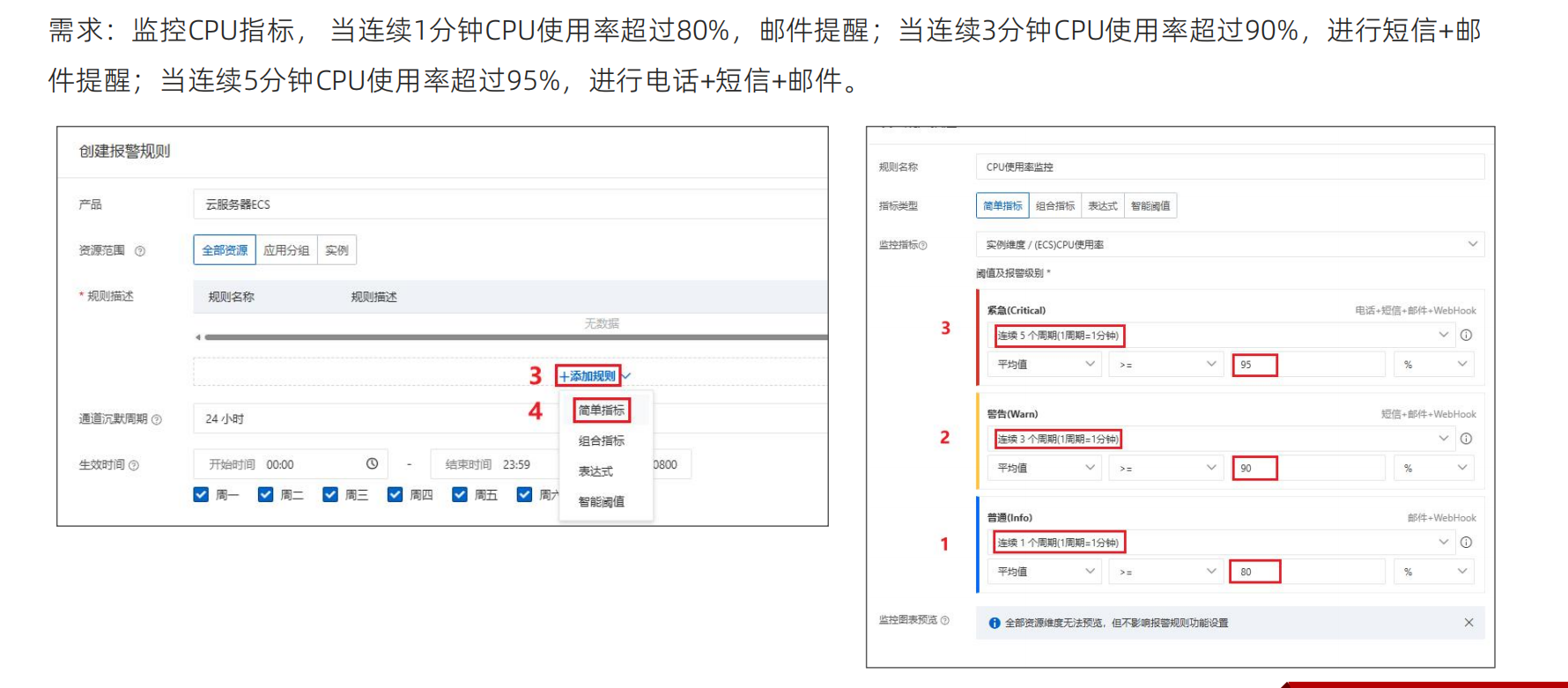
1分钟内是发短信,3分钟才是短信,这个是普通预警,然后是警告,最后是晋级
告警短信
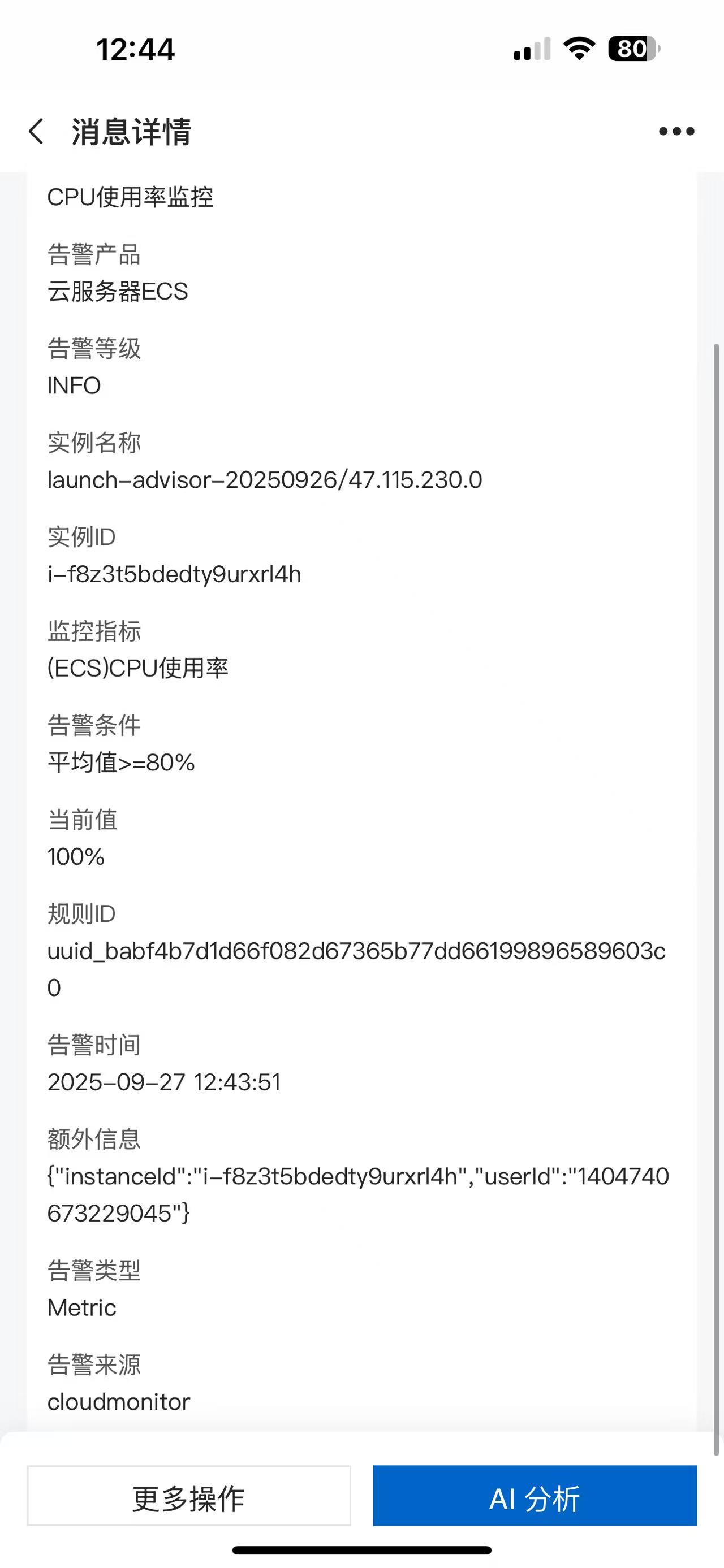

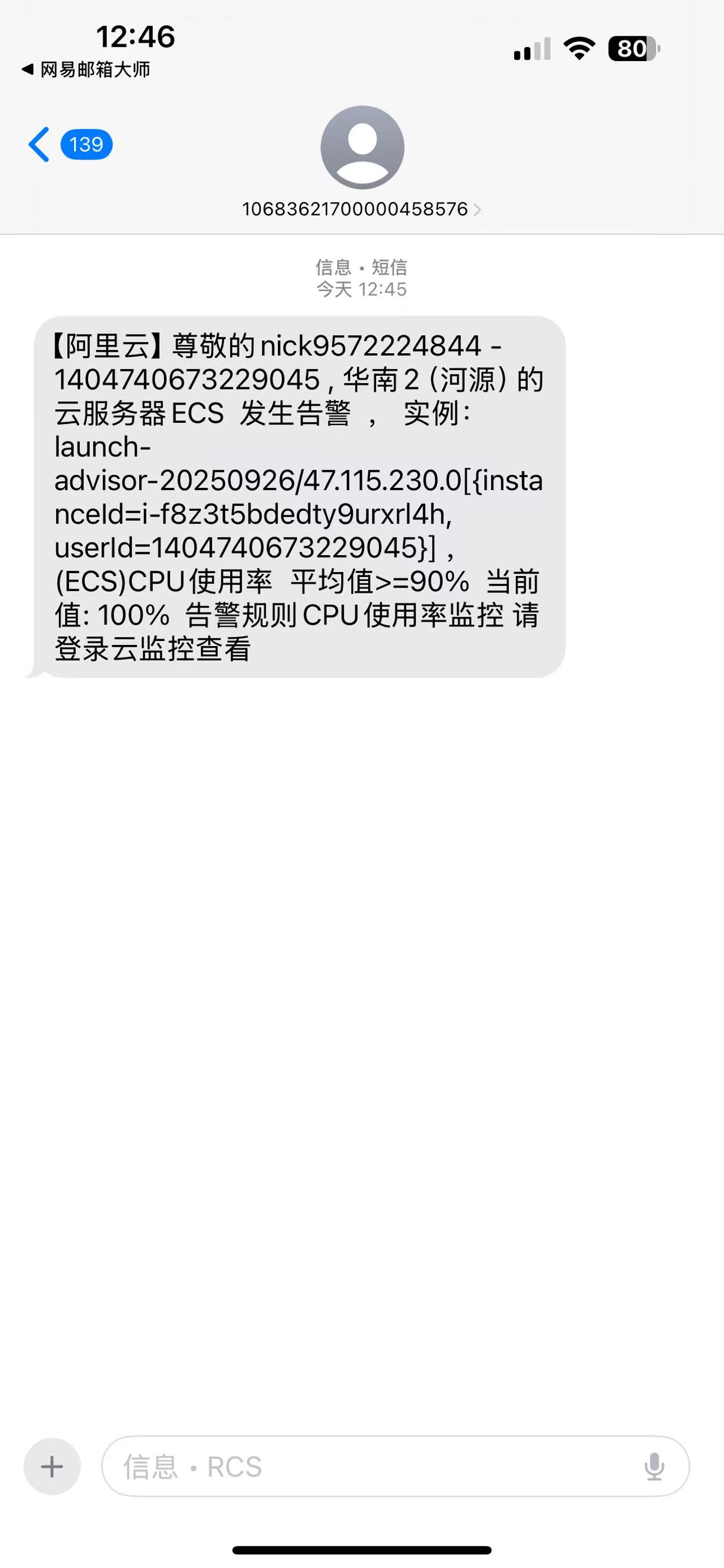

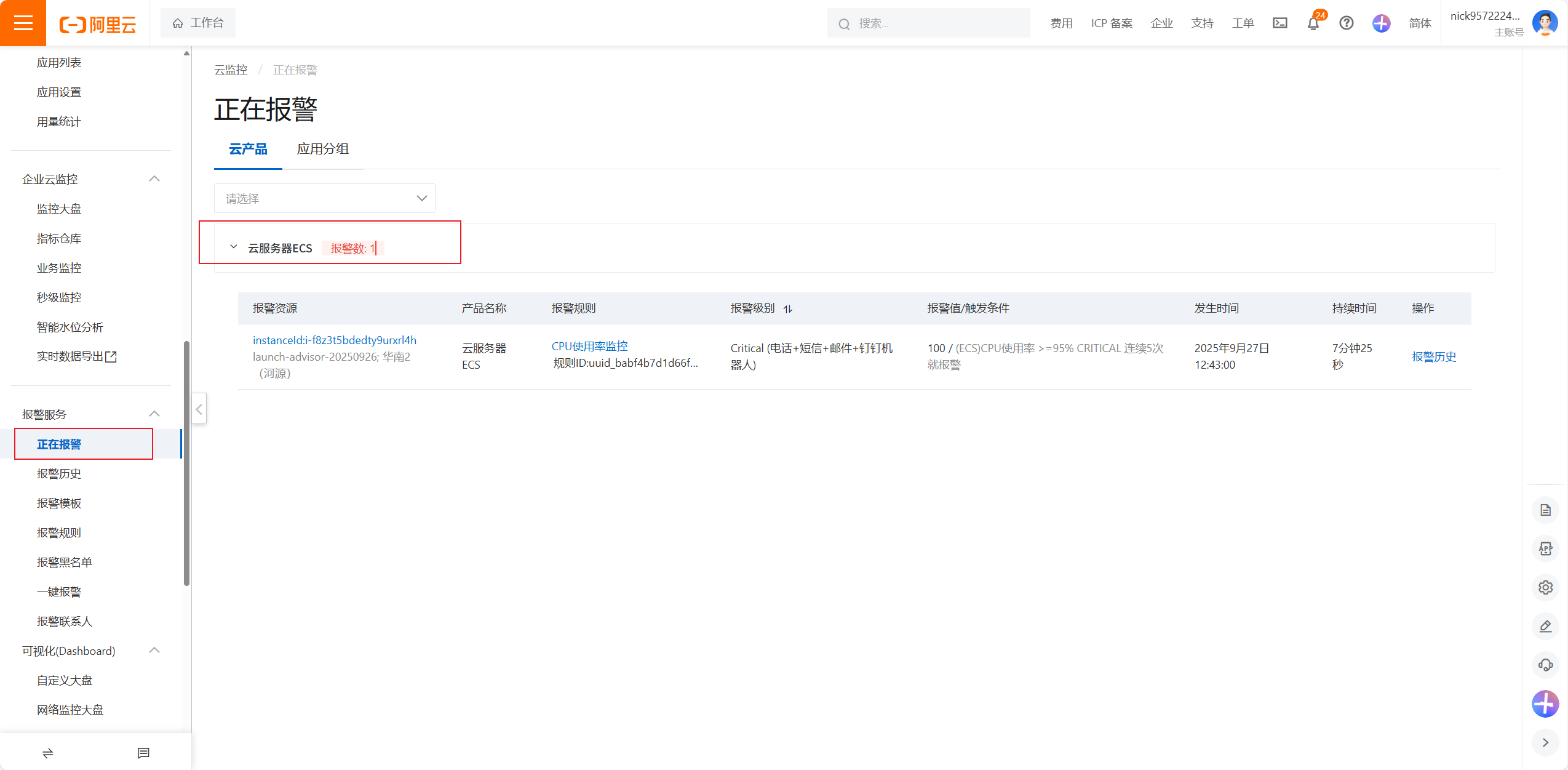
正在报警的
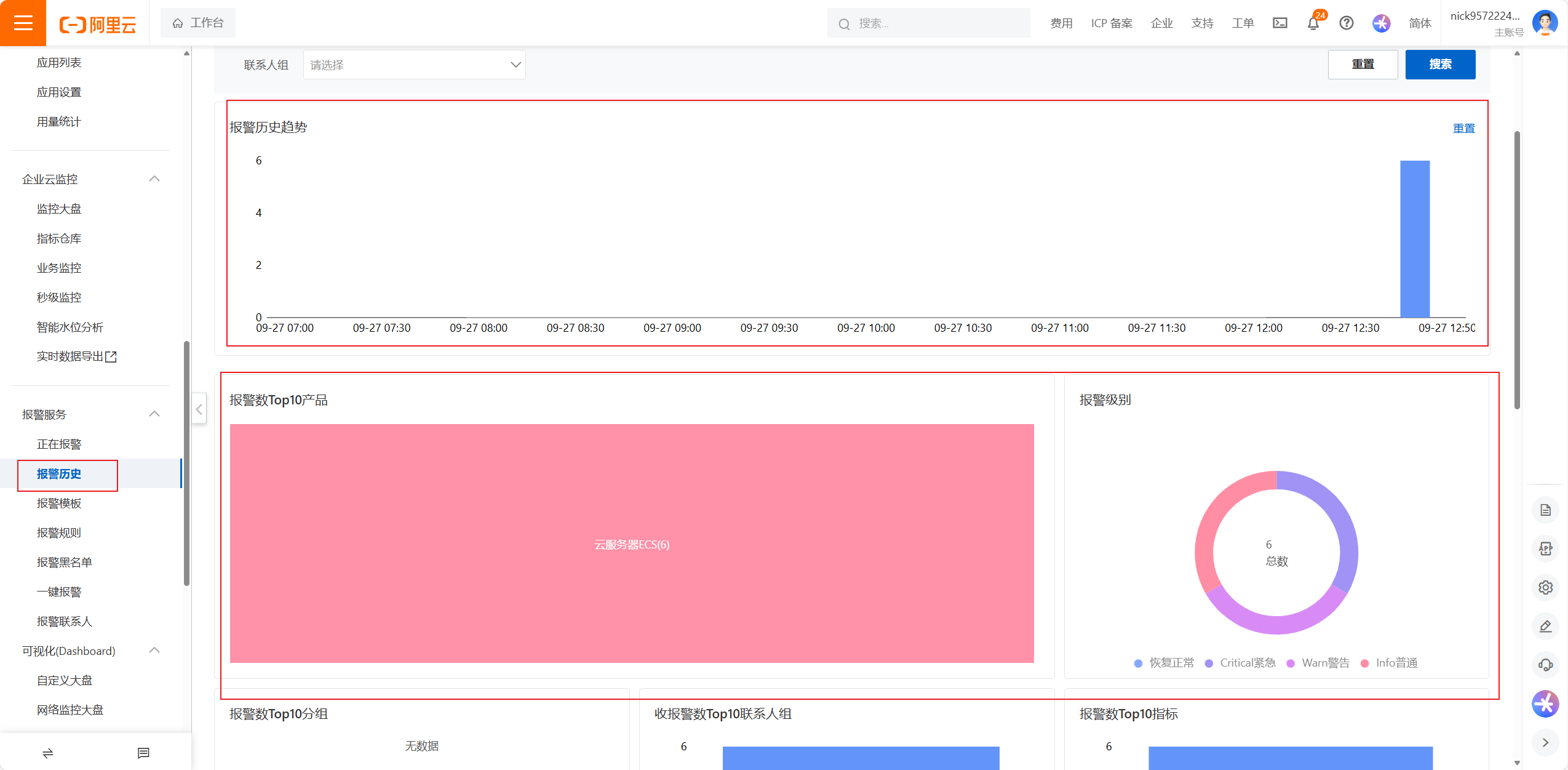
以及报警历史
私有化大模型需要对GPU做各种各样的优化
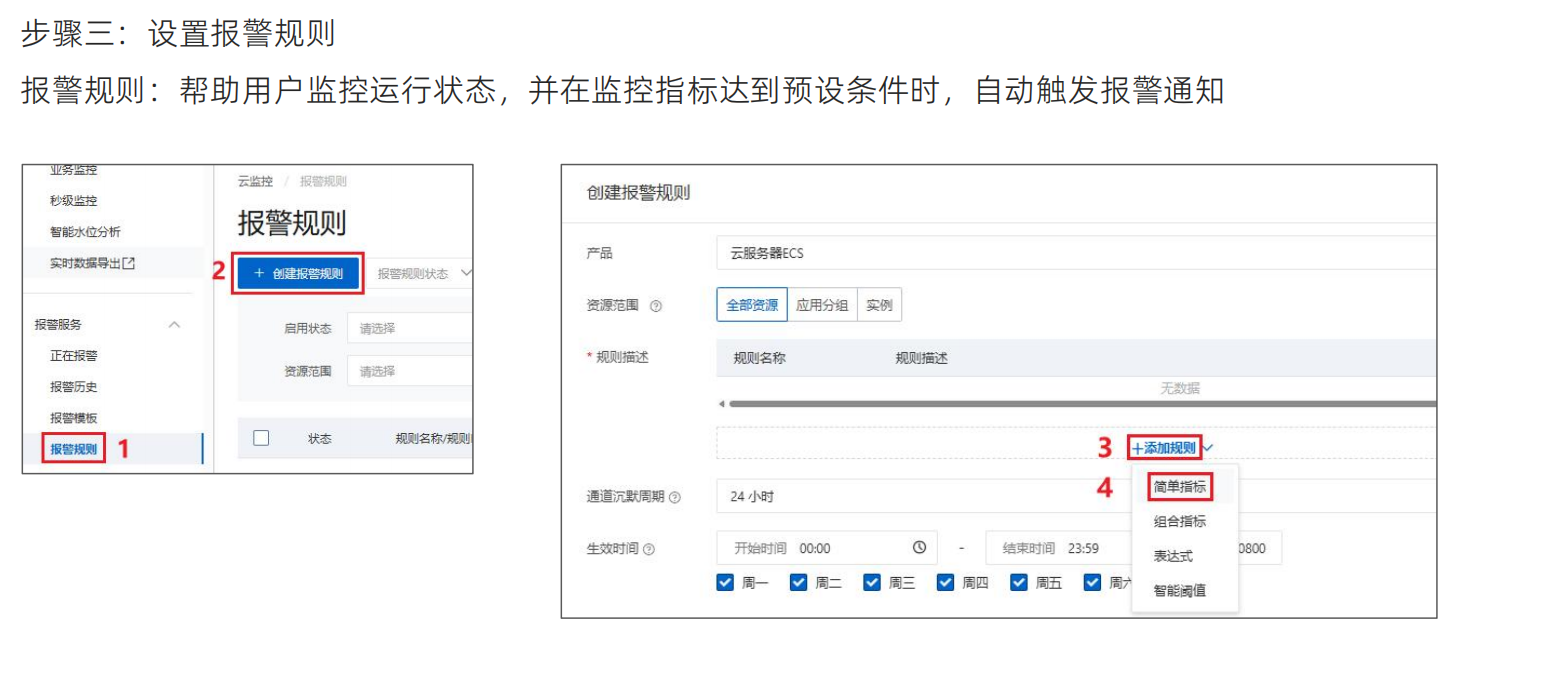
设置报警规则分为:
1.设计报警联系人和组
2.设置报警规则
3.选择监控指标和设置报警方案
4.设置告警周期和联系人
测试完成后要退出这个shell脚本
✅ 立即解决方案:杀死这些
yes进程方法 1:逐个杀死(推荐)
kill 1936 1937 1938 1939方法 2:一键杀死所有
yes进程pkill yes或
killall yes
🔄 验证是否成功
执行完
kill或pkill yes后,再次运行:top -n 1你应该会看到:
%Cpu(s):使用率大幅下降(比如降到 1%~5%)yes进程消失load average开始下降

更多推荐
 5
5 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)