
Agent框架系列:5-框架全景对比分析、实战案例集、框架选择建议
Agent框架工具系列:5-框架全景对比分析、实战案例集、框架选择建议
智能体框架和工具系列总目录:
- 一、Agent框架工具系列:1-低代码智能体平台深度解析Dify、Coze、n8n
- 二、Agent框架工具系列:2-LangChain-LangGraph生态深度剖析
- 三、Agent框架工具系列:3-多智能体协作框架深度解析AutoGen、CrewAI、GraphRAG
- 四、Agent框架工具系列:4-企业级知识管理平台深度解析MaxKB、FastGPT、DB-GPT
- 五、Agent框架工具系列:5-框架全景对比分析、实战案例集、框架选择建议
目录:
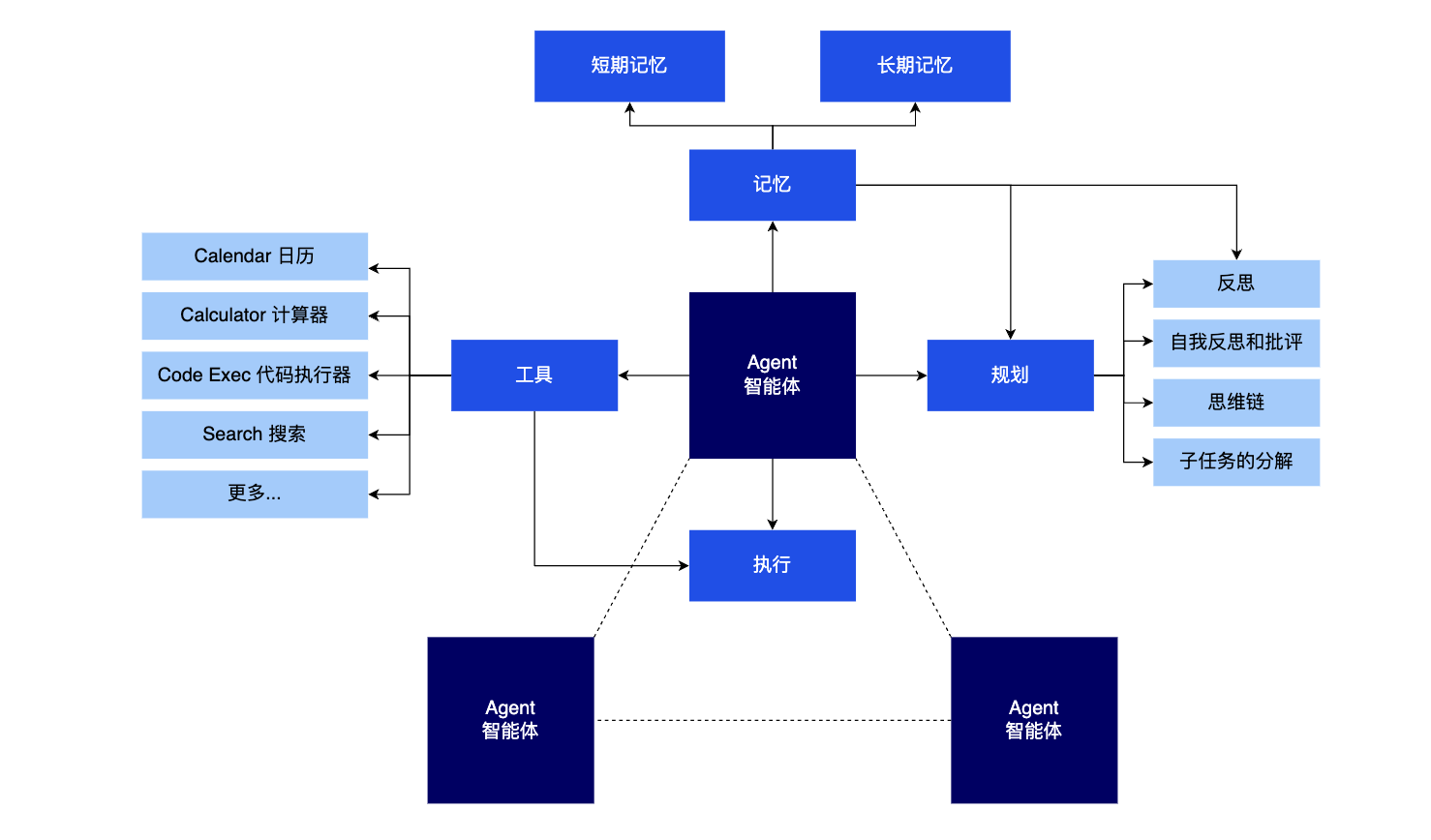
框架横向对比分析
1、技术架构和设计理念对比
| 框架 | 架构设计 | 设计理念 | 技术栈 | 适用规模 |
|---|---|---|---|---|
| Dify | 微服务架构 | 低代码平台 | Python + React | 中小企业 |
| Coze | 云原生微服务 | 零代码平台 | Golang + React | 个人到企业 |
| n8n | 前后端分离 | 工作流自动化 | Node.js + Vue | 中小团队 |
| AutoGen | 对话驱动架构 | 多Agent协作 | Python | 科研+企业 |
| LangChain | 模块化链式 | 组件化开发 | Python + JS/TS | 各种规模 |
| CrewAI | 角色驱动协作 | 团队协作模拟 | Python | 中小项目 |
| LangGraph | 有向图架构 | 状态化工作流 | Python | 复杂应用 |
| GraphRAG | 图谱+检索+生成 | 知识图谱增强 | Python | 知识密集型 |
| MaxKB | 企业级分层架构 | 知识库问答 | Python + Vue | 企业级 |
| FastGPT | 微服务+工作流 | 一站式AI平台 | TypeScript + React | 快速开发 |
| DB-GPT | 数据驱动+智能体 | 数据库智能助手 | Python | 数据分析 |
2、多Agent协作能力对比
| 框架 | 协作深度 | 协作模式 | 角色定义 | 任务编排 | 通信机制 |
|---|---|---|---|---|---|
| AutoGen | ★★★★★ | 对话式动态协作 | 灵活自定义 | 智能路由 | 自然语言+结构化 |
| CrewAI | ★★★★☆ | 角色分工协作 | 预设角色模板 | 序列/层级 | 任务传递 |
| LangGraph | ★★★★☆ | 图结构编排 | 节点定义 | 有向图 | 状态传递 |
| DB-GPT | ★★★☆☆ | 专家智能体协作 | 领域专家 | 流水线 | API调用 |
| Dify | ★★★☆☆ | 工作流串联 | 工具节点 | 可视化编排 | 数据流 |
| FastGPT | ★★★☆☆ | 节点协作 | 功能节点 | 工作流 | 输入输出 |
| Coze | ★★☆☆☆ | 插件协作 | 功能插件 | 线性流程 | 参数传递 |
| MaxKB | ★★☆☆☆ | 简单协作 | 固定角色 | 预设流程 | 接口调用 |
| LangChain | ★★☆☆☆ | 链式调用 | Chain抽象 | 顺序执行 | 数据链 |
| n8n | ★★☆☆☆ | 节点协作 | 功能节点 | 可视化流程 | HTTP/API |
| GraphRAG | ★☆☆☆☆ | 单一智能体 | 检索生成 | 固定流程 | 内部调用 |
3、开发门槛和学习曲线
| 框架 | 开发门槛 | 学习周期 | 技术要求 | 文档质量 | 社区支持 |
|---|---|---|---|---|---|
| Coze | ★☆☆☆☆ | 1-3天 | 零编程基础 | ★★★★☆ | ★★★★☆ |
| n8n | ★☆☆☆☆ | 3-7天 | 基础配置能力 | ★★★★☆ | ★★★★☆ |
| Dify | ★★☆☆☆ | 1-2周 | Python基础 | ★★★★☆ | ★★★★☆ |
| FastGPT | ★★☆☆☆ | 1-2周 | 前端基础 | ★★★☆☆ | ★★★☆☆ |
| MaxKB | ★★☆☆☆ | 1-2周 | Python基础 | ★★★☆☆ | ★★★☆☆ |
| LangChain | ★★★★☆ | 2-4周 | 深度Python | ★★★★★ | ★★★★★ |
| LangGraph | ★★★★☆ | 2-4周 | LangChain+图论 | ★★★★☆ | ★★★★☆ |
| AutoGen | ★★★★☆ | 3-6周 | 高级Python | ★★★☆☆ | ★★★☆☆ |
| CrewAI | ★★★★☆ | 2-4周 | Python+AI概念 | ★★☆☆☆ | ★★☆☆☆ |
| GraphRAG | ★★★★★ | 4-8周 | 图算法+NLP | ★★★☆☆ | ★★☆☆☆ |
| DB-GPT | ★★★★★ | 4-8周 | 数据库+Python | ★★★☆☆ | ★★☆☆☆ |
4、工具集成和扩展性
| 框架 | 内置工具数量 | 自定义工具难度 | API集成能力 | 插件生态 | 扩展性评分 |
|---|---|---|---|---|---|
| n8n | 400+ | ★☆☆☆☆ | ★★★★★ | ★★★★★ | ★★★★★ |
| Coze | 60+ | ★★☆☆☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ |
| LangChain | 100+ | ★★★☆☆ | ★★★★★ | ★★★★★ | ★★★★★ |
| Dify | 50+ | ★★☆☆☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ |
| FastGPT | 30+ | ★★★☆☆ | ★★★★☆ | ★★★☆☆ | ★★★☆☆ |
| AutoGen | 20+ | ★★★★☆ | ★★★★☆ | ★★★☆☆ | ★★★★☆ |
| LangGraph | 集成LangChain | ★★★★☆ | ★★★★☆ | ★★★★☆ | ★★★★☆ |
| MaxKB | 20+ | ★★★☆☆ | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ |
| CrewAI | 15+ | ★★★★☆ | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ |
| DB-GPT | 数据库专用 | ★★★★☆ | ★★★☆☆ | ★★☆☆☆ | ★★★☆☆ |
| GraphRAG | 图谱专用 | ★★★★★ | ★★☆☆☆ | ★★☆☆☆ | ★★☆☆☆ |
实战案例集
案例1:智能客服系统(多框架对比实现)
使用Coze实现(零代码方案)
- 实现时间:2小时
- 技术难度:零编程
- 维护成本:低
- 扩展能力:中等
# Coze配置示例
bot_config:
name: "智能客服机器人"
persona: "专业、友善的客服代表"
skills:
- skill_type: "knowledge_base"
kb_name: "产品FAQ"
search_mode: "hybrid"
- skill_type: "intent_recognition"
intents: ["产品咨询", "订单查询", "技术支持", "投诉处理"]
- skill_type: "workflow"
workflow_name: "客服处理流程"
plugins:
- name: "订单查询插件"
api_url: "https://api.company.com/orders"
- name: "工单创建插件"
api_url: "https://api.company.com/tickets"
使用AutoGen实现(多智能体方案)
- 实现时间:2-3天
- 技术难度:高级Python
- 维护成本:中等
- 扩展能力:高
# AutoGen多智能体客服系统
import autogen
class CustomerServiceTeam:
def __init__(self):
# 客服接待员
self.receptionist = autogen.AssistantAgent(
name="客服接待员",
system_message="负责初步接待,识别客户需求并分流到对应专员",
llm_config={"config_list": config_list}
)
# 技术支持专员
self.tech_support = autogen.AssistantAgent(
name="技术支持专员",
system_message="负责解决技术问题,提供专业技术指导",
llm_config={"config_list": config_list}
)
# 销售顾问
self.sales_consultant = autogen.AssistantAgent(
name="销售顾问",
system_message="负**:支持复杂的逻辑推理链
- **答案合成**:生成结构化的最终答案
### 核心技术原理
**知识图谱构建算法**
```python
from graphrag.index import create_llm_derive_kg
from graphrag.query import GlobalSearch, LocalSearch
import pandas as pd
class GraphRAGSystem:
def __init__(self, documents_path: str):
self.documents = self.load_documents(documents_path)
self.knowledge_graph = None
self.global_searcher = None
self.local_searcher = None
def build_knowledge_graph(self):
"""构建知识图谱"""
# 实体和关系抽取
entities_df, relationships_df = create_llm_derive_kg(
documents=self.documents,
entity_extraction_prompt="提取文本中的关键实体",
relationship_extraction_prompt="识别实体间的关系",
llm_config={
"model": "gpt-4o-mini",
"temperature": 0.1
}
)
# 构建图结构
self.knowledge_graph = self.build_graph_structure(
entities_df, relationships_df
)
# 社区检测和层次聚类
communities = self.detect_communities(self.knowledge_graph)
# 创建搜索索引
self.global_searcher = GlobalSearch(
knowledge_graph=self.knowledge_graph,
communities=communities,
llm_config={"model": "gpt-4o-mini"}
)
self.local_searcher = LocalSearch(
knowledge_graph=self.knowledge_graph,
entities=entities_df,
relationships=relationships_df,
llm_config={"model": "gpt-4o-mini"}
)
def query_global(self, question: str, search_type="global"):
"""全局查询:适合需要综合多个社区信息的问题"""
if search_type == "global":
# 全局社区搜索
context = self.global_searcher.search(question)
# 生成答案
response = self.generate_response(
question=question,
context=context,
search_type="global"
)
return {
"answer": response,
"context": context,
"reasoning_path": self.extract_reasoning_path(context)
}
def query_local(self, question: str, entities: list = None):
"""局部查询:适合针对特定实体的详细问题"""
# 局部实体搜索
context = self.local_searcher.search(
question=question,
entities=entities or []
)
response = self.generate_response(
question=question,
context=context,
search_type="local"
)
return {
"answer": response,
"context": context,
"related_entities": self.extract_related_entities(context)
}
def multi_hop_reasoning(self, question: str, max_hops: int = 3):
"""多跳推理查询"""
reasoning_chain = []
current_entities = self.extract_entities_from_question(question)
for hop in range(max_hops):
# 获取当前实体的邻居
neighbors = self.get_entity_neighbors(current_entities)
# 评估推理相关性
relevant_paths = self.evaluate_reasoning_paths(
question, current_entities, neighbors
)
reasoning_chain.append({
"hop": hop + 1,
"entities": current_entities,
"paths": relevant_paths
})
# 更新当前实体集合
current_entities = self.update_entity_set(relevant_paths)
# 检查是否找到答案
if self.has_sufficient_context(question, reasoning_chain):
break
# 合成最终答案
final_answer = self.synthesize_multi_hop_answer(
question, reasoning_chain
)
return {
"answer": final_answer,
"reasoning_chain": reasoning_chain,
"hops_used": len(reasoning_chain)
}
# 使用示例
graph_rag = GraphRAGSystem("./documents")
graph_rag.build_knowledge_graph()
# 全局查询示例
global_result = graph_rag.query_global(
"人工智能技术对各个行业的影响趋势是什么?"
)
# 多跳推理示例
reasoning_result = graph_rag.multi_hop_reasoning(
"特斯拉的自动驾驶技术如何影响传统汽车制造商的战略决策?"
)
核心能力
- 知识图谱自动构建:从非结构化文本自动抽取实体和关系
- 多层次检索:支持全局和局部两种检索模式
- 多跳推理:处理需要多步逻辑推理的复杂问题
- 社区发现:自动识别知识图谱中的概念聚类
- 可解释性强:提供完整的推理路径和证据链
案例2:内容创作系统
使用CrewAI实现团队协作创作
class ContentCreationCrew:
def __init__(self):
# 市场研究员
self.market_researcher = Agent(
role='市场研究员',
goal='深入研究目标市场和用户需求',
backstory="""你是资深的市场研究专家,
擅长分析市场趋势、用户画像和竞争对手策略。
你的研究为内容创作提供数据支撑。""",
tools=[search_tool, data_analysis_tool],
verbose=True
)
# SEO专家
self.seo_expert = Agent(
role='SEO专家',
goal='优化内容的搜索引擎表现',
backstory="""你是SEO领域的专家,
深谙搜索引擎算法和关键词策略,
能够让内容获得更好的自然流量。""",
tools=[keyword_tool, seo_analyzer],
verbose=True
)
# 内容创作者
self.content_writer = Agent(
role='内容创作者',
goal='创作吸引人的高质量内容',
backstory="""你是经验丰富的内容创作者,
擅长将复杂信息转化为易懂、有趣的内容,
注重内容的逻辑性和感染力。""",
tools=[writing_assistant, grammar_checker],
verbose=True
)
# 视觉设计师
self.visual_designer = Agent(
role='视觉设计师',
goal='为内容设计配套的视觉元素',
backstory="""你是创意十足的视觉设计师,
能够为文字内容配上合适的图片、图表和视觉元素,
提升内容的视觉冲击力。""",
tools=[image_generator, chart_creator],
verbose=True
)
def create_comprehensive_content(self, topic: str, target_audience: str,
content_type: str):
"""综合内容创作流程"""
# 1. 市场研究任务
research_task = Task(
description=f"""
针对主题"{topic}"进行深入的市场研究:
1. 分析目标受众"{target_audience}"的需求和痛点
2. 研究同类内容的表现和用户反馈
3. 识别内容创作的机会点和差异化策略
4. 提供数据驱动的内容方向建议
""",
agent=self.market_researcher,
expected_output="详细的市场研究报告,包含用户洞察和内容策略建议"
)
# 2. SEO优化任务
seo_task = Task(
description=f"""
基于市场研究结果,进行SEO优化策略制定:
1. 分析主题"{topic}"的关键词竞争度和搜索量
2. 制定主关键词和长尾关键词策略
3. 优化内容标题和元描述
4. 提供内容结构和内链建议
""",
agent=self.seo_expert,
expected_output="SEO优化方案,包含关键词列表和优化建议"
)
# 3. 内容创作任务
writing_task = Task(
description=f"""
基于前期研究和SEO策略,创作{content_type}内容:
1. 围绕主题"{topic}"创作原创内容
2. 融入目标关键词,保持内容自然流畅
3. 针对"{target_audience}"调整语言风格和内容深度
4. 确保内容结构清晰,逻辑性强
5. 添加引人入胜的开头和有力的结尾
""",
agent=self.content_writer,
expected_output="高质量的原创内容,符合SEO要求和用户需求"
)
# 4. 视觉设计任务
design_task = Task(
description=f"""
为创作的内容设计配套视觉元素:
1. 设计吸引眼球的封面图片
2. 创建支撑内容要点的信息图表
3. 选择或生成相关的配图
4. 设计内容的视觉布局和排版建议
""",
agent=self.visual_designer,
expected_output="完整的视觉设计方案,包含图片、图表和布局建议"
)
# 组建创作团队
content_crew = Crew(
agents=[self.market_researcher, self.seo_expert,
self.content_writer, self.visual_designer],
tasks=[research_task, seo_task, writing_task, design_task],
process=Process.sequential,
verbose=2
)
# 执行创作流程
result = content_crew.kickoff()
# 整理最终输出
final_content = {
"topic": topic,
"target_audience": target_audience,
"content_type": content_type,
"market_research": research_task.output,
"seo_strategy": seo_task.output,
"written_content": writing_task.output,
"visual_design": design_task.output,
"creation_date": datetime.now().isoformat(),
"team_collaboration_log": result.tasks_outputs
}
return final_content
# 使用示例
content_team = ContentCreationCrew()
# 创作科技博客文章
tech_article = content_team.create_comprehensive_content(
topic="人工智能在智慧城市建设中的应用",
target_audience="城市规划师和技术决策者",
content_type="深度技术分析文章"
)
print("=== 内容创作结果 ===")
print(f"文章标题:{tech_article['written_content']['title']}")
print(f"关键词策略:{tech_article['seo_strategy']['keywords']}")
print(f"目标用户洞察:{tech_article['market_research']['user_insights']}")
案例3:数据分析报告自动化
使用GraphRAG + DB-GPT实现智能数据分析
class IntelligentDataAnalysisPlatform:
def __init__(self):
# GraphRAG用于复杂关联分析
self.graph_rag = GraphRAGSystem("./business_documents")
self.graph_rag.build_knowledge_graph()
# DB-GPT用于数据库查询分析
self.db_gpt = DBGPTMultiAgentSystem({
"sales_db": {"url": "mysql://localhost/sales"},
"marketing_db": {"url": "postgresql://localhost/marketing"},
"finance_db": {"url": "mongodb://localhost/finance"}
})
# 数据科学智能体
self.data_scientist = DataScienceAgent()
self.report_writer = ReportWriterAgent()
def comprehensive_business_analysis(self, business_question: str):
"""综合业务分析流程"""
# 第一阶段:问题分解和数据查询
print("🔍 阶段1:问题分解和数据收集")
# 使用GraphRAG进行复杂关联分析
knowledge_insights = self.graph_rag.multi_hop_reasoning(
business_question, max_hops=3
)
# 使用DB-GPT进行数据库查询
data_insights = self.db_gpt.comprehensive_data_analysis(
business_question
)
# 第二阶段:高级数据科学分析
print("📊 阶段2:高级数据分析")
advanced_analysis = self.data_scientist.perform_analysis({
"question": business_question,
"structured_data": data_insights,
"knowledge_context": knowledge_insights,
"analysis_types": [
"trend_analysis",
"correlation_analysis",
"predictive_modeling",
"anomaly_detection"
]
})
# 第三阶段:洞察提取和预测
print("🎯 阶段3:洞察提取和预测")
key_insights = self.extract_key_insights({
"knowledge_analysis": knowledge_insights,
"data_analysis": data_insights,
"advanced_analysis": advanced_analysis
})
# 生成预测和建议
predictions = self.generate_predictions(key_insights)
recommendations = self.generate_recommendations(
business_question, key_insights, predictions
)
# 第四阶段:报告生成
print("📝 阶段4:智能报告生成")
executive_report = self.report_writer.generate_executive_report({
"business_question": business_question,
"key_insights": key_insights,
"predictions": predictions,
"recommendations": recommendations,
"supporting_data": {
"knowledge_insights": knowledge_insights,
"data_insights": data_insights,
"advanced_analysis": advanced_analysis
}
})
return {
"business_question": business_question,
"analysis_summary": key_insights,
"predictions": predictions,
"recommendations": recommendations,
"executive_report": executive_report,
"detailed_analysis": {
"knowledge_insights": knowledge_insights,
"data_insights": data_insights,
"advanced_analysis": advanced_analysis
},
"confidence_scores": self.calculate_confidence_scores(key_insights),
"next_steps": self.suggest_next_steps(recommendations)
}
def real_time_monitoring_system(self, kpi_definitions: list):
"""实时监控系统"""
monitoring_results = {}
for kpi in kpi_definitions:
# 实时数据查询
current_data = self.db_gpt.databases[kpi["database"]].natural_language_to_sql(
f"获取{kpi['name']}的最新数据和趋势"
)
# 异常检测
anomaly_analysis = self.data_scientist.detect_anomalies(
kpi_name=kpi["name"],
current_value=current_data["result"],
historical_data=current_data["context"]
)
# 预警判断
alert_status = self.evaluate_alert_conditions(
kpi_definition=kpi,
current_data=current_data,
anomaly_analysis=anomaly_analysis
)
monitoring_results[kpi["name"]] = {
"current_value": current_data["result"],
"trend": anomaly_analysis["trend"],
"alert_status": alert_status,
"explanation": current_data["explanation"]
}
return monitoring_results
def automated_insight_discovery(self, data_sources: list,
discovery_scope: str = "comprehensive"):
"""自动化洞察发现"""
discovered_insights = []
for source in data_sources:
print(f"🔍 正在分析数据源:{source}")
# 探索性数据分析
exploratory_analysis = self.data_scientist.exploratory_data_analysis(
data_source=source,
scope=discovery_scope
)
# 模式识别
patterns = self.identify_patterns(exploratory_analysis)
# 异常值检测
anomalies = self.detect_data_anomalies(exploratory_analysis)
# 关联分析
correlations = self.analyze_correlations(exploratory_analysis)
# 趋势预测
trend_predictions = self.predict_trends(exploratory_analysis)
discovered_insights.append({
"data_source": source,
"patterns": patterns,
"anomalies": anomalies,
"correlations": correlations,
"predictions": trend_predictions,
"business_impact": self.assess_business_impact(
patterns, anomalies, correlations
)
})
# 跨数据源洞察整合
integrated_insights = self.integrate_cross_source_insights(discovered_insights)
return {
"individual_insights": discovered_insights,
"integrated_insights": integrated_insights,
"actionable_recommendations": self.generate_actionable_recommendations(
integrated_insights
),
"discovery_summary": self.summarize_discoveries(discovered_insights)
}
# 实战使用示例
analysis_platform = IntelligentDataAnalysisPlatform()
# 高级业务分析
business_analysis = analysis_platform.comprehensive_business_analysis(
"过去一年我们的市场份额变化如何?主要驱动因素是什么?未来6个月的趋势预测?"
)
print("=== 综合业务分析报告 ===")
print(f"核心洞察:{business_analysis['analysis_summary']}")
print(f"预测结果:{business_analysis['predictions']}")
print(f"行动建议:{business_analysis['recommendations']}")
print(f"置信度:{business_analysis['confidence_scores']}")
# 实时KPI监控
kpi_definitions = [
{
"name": "日活跃用户数",
"database": "marketing_db",
"threshold": {"warning": 10000, "critical": 8000},
"trend_period": "7d"
},
{
"name": "订单转化率",
"database": "sales_db",
"threshold": {"warning": 0.05, "critical": 0.03},
"trend_period": "1d"
}
]
monitoring_result = analysis_platform.real_time_monitoring_system(kpi_definitions)
print("\n=== 实时监控结果 ===")
for kpi_name, result in monitoring_result.items():
print(f"{kpi_name}: {result['current_value']} ({result['alert_status']})")
# 自动洞察发现
insight_discovery = analysis_platform.automated_insight_discovery(
data_sources=["sales_db", "marketing_db", "finance_db"],
discovery_scope="comprehensive"
)
print("\n=== 自动发现的洞察 ===")
print(f"发现的模式:{len(insight_discovery['individual_insights'])}")
print(f"整合洞察:{insight_discovery['integrated_insights']}")
print(f"可行动建议:{insight_discovery['actionable_recommendations']}")
不同场景下的框架选择建议
1、快速原型开发与概念验证
推荐框架排序:Dify > FastGPT > Coze > n8n
选择理由:
- Dify:低代码平台,图形化界面友好
- FastGPT:可视化工作流,内置模板,快速部署
- Coze:零代码开发,1天创建AI Bot,适合快速验证想法
- n8n:强大的集成能力,适合工作流验证
典型场景:
场景描述: 快速验证AI客服可行性
时间要求: 2天内完成
技能要求: 无编程基础
预期结果: 功能演示和效果评估
推荐方案:
首选: Dify
配置时间: 1天
测试时间: 0.5天
部署时间: 0.5天
成功标准:
- 能够回答基本客服问题
- 集成现有FAQ知识库
- 支持多轮对话
- 提供基础数据统计
2、企业级应用开发
推荐框架排序:LangChain > LangGraph > Dify > DB-GPT
选择理由:
- LangChain:成熟的企业级框架,丰富的组件和社区支持
- LangGraph:支持复杂状态管理,适合大型系统
- Dify:企业级部署支持,安全性好
- DB-GPT:专门针对数据驱动的企业应用
典型场景:
# 企业级知识管理系统架构
class EnterpriseKnowledgeSystem:
def __init__(self):
# 使用LangChain构建核心框架
self.document_processor = LangChainDocumentProcessor()
self.vector_store = EnterpriseVectorStore() # 企业级向量数据库
self.security_layer = SecurityManager() # 权限和安全管理
self.audit_system = AuditLogger() # 审计日志
def enterprise_features(self):
return {
"multi_tenant_support": True, # 多租户支持
"rbac_permission": True, # 角色权限控制
"data_encryption": True, # 数据加密
"audit_trail": True, # 审计追踪
"high_availability": True, # 高可用性
"disaster_recovery": True, # 灾备恢复
"performance_monitoring": True, # 性能监控
"compliance_reporting": True # 合规报告
}
3、科研与复杂协作项目
推荐框架排序:AutoGen > CrewAI > LangGraph > GraphRAG
选择理由:
- AutoGen:最先进的多智能体协作机制,适合复杂研究
- CrewAI:角色分工清晰,适合团队协作模拟
- LangGraph:复杂工作流编排能力强
- GraphRAG:知识图谱增强,适合知识密集型研究
典型场景:
# 科研论文自动化生成系统
class AcademicResearchSystem:
def __init__(self):
self.research_team = {
"literature_reviewer": AutoGenAgent("文献调研员"),
"data_analyst": AutoGenAgent("数据分析师"),
"methodology_expert": AutoGenAgent("方法学专家"),
"paper_writer": AutoGenAgent("论文撰写者"),
"peer_reviewer": AutoGenAgent("同行评议者")
}
def automated_research_pipeline(self, research_topic: str):
# 多智能体协作研究流程
research_phases = [
"literature_review", # 文献综述
"hypothesis_generation", # 假设生成
"methodology_design", # 方法设计
"data_analysis", # 数据分析
"result_interpretation", # 结果解释
"paper_writing", # 论文撰写
"peer_review" # 同行评议
]
return self.execute_research_phases(research_phases)
4、数据分析与商业智能
推荐框架排序:DB-GPT > GraphRAG > LangChain > MaxKB
选择理由:
- DB-GPT:专门为数据库和数据分析设计
- GraphRAG:复杂关联分析和多跳推理
- LangChain:灵活的数据处理链路
- MaxKB:结构化数据的知识库管理
典型场景:
-- DB-GPT自然语言查询示例
用户问题: "分析上个季度销售表现最好的产品类别,以及对应的客户群体特征"
自动生成SQL:
WITH quarterly_sales AS (
SELECT
p.category,
SUM(o.amount) as total_sales,
COUNT(DISTINCT o.customer_id) as unique_customers
FROM orders o
JOIN products p ON o.product_id = p.id
WHERE o.created_at >= DATE_SUB(NOW(), INTERVAL 3 MONTH)
GROUP BY p.category
),
top_categories AS (
SELECT category
FROM quarterly_sales
ORDER BY total_sales DESC
LIMIT 3
)
SELECT
tc.category,
c.age_group,
c.location,
COUNT(*) as customer_count,
AVG(o.amount) as avg_order_value
FROM top_categories tc
JOIN orders o ON o.product_id IN (
SELECT id FROM products WHERE category = tc.category
)
JOIN customers c ON o.customer_id = c.id
GROUP BY tc.category, c.age_group, c.location
ORDER BY tc.category, customer_count DESC;
5、内容创作与营销自动化
推荐框架排序:CrewAI > Coze > FastGPT > n8n
选择理由:
- CrewAI:角色分工明确,适合内容创作团队协作
- Coze:丰富的内容处理插件
- FastGPT:内容工作流编排友好
- n8n:强大的营销工具集成能力
典型场景:
# 全渠道内容营销自动化
class ContentMarketingAutomation:
def __init__(self):
self.content_crew = CrewAIContentTeam()
self.distribution_engine = n8nWorkflowEngine()
def automated_content_campaign(self, campaign_theme: str):
# 内容创作阶段
content_assets = self.content_crew.create_multi_format_content(
theme=campaign_theme,
formats=["blog_post", "social_media", "email", "video_script"]
)
# 自动分发阶段
distribution_results = self.distribution_engine.execute_workflow({
"content": content_assets,
"channels": ["website", "social_media", "email_list", "youtube"],
"schedule": self.optimize_posting_schedule(),
"personalization": self.audience_segmentation()
})
return {
"content_created": content_assets,
"distribution_results": distribution_results,
"performance_tracking": self.setup_analytics_tracking()
}
6、教育培训系统
推荐框架排序:MaxKB > Dify > FastGPT > LangChain
选择理由:
- MaxKB:专业的知识库管理,适合教学内容组织
- Dify:良好的多模态支持,适合教学场景
- FastGPT:快速构建教学应用
- LangChain:灵活的教学流程设计
典型场景:
# 智能化教学系统
class IntelligentTutoringSystem:
def __init__(self):
self.knowledge_base = MaxKBSystem()
self.personalization_engine = PersonalizationEngine()
self.assessment_system = AssessmentSystem()
def adaptive_learning_path(self, student_profile: dict):
# 个性化学习路径生成
learning_objectives = self.extract_learning_objectives(student_profile)
current_knowledge_level = self.assess_current_level(student_profile)
adaptive_path = self.generate_learning_path(
objectives=learning_objectives,
current_level=current_knowledge_level,
learning_style=student_profile["learning_style"],
available_time=student_profile["available_time"]
)
return {
"learning_path": adaptive_path,
"estimated_duration": self.calculate_duration(adaptive_path),
"milestones": self.define_milestones(adaptive_path),
"assessment_schedule": self.schedule_assessments(adaptive_path)
}
def intelligent_tutoring_session(self, student_id: str, topic: str):
# 智能辅导会话
student_context = self.get_student_context(student_id)
topic_knowledge = self.knowledge_base.retrieve_topic_content(topic)
tutoring_session = {
"personalized_explanation": self.generate_explanation(
topic_knowledge, student_context["learning_style"]
),
"interactive_examples": self.create_examples(
topic, student_context["difficulty_preference"]
),
"practice_questions": self.generate_practice_questions(
topic, student_context["current_level"]
),
"hints_and_tips": self.provide_learning_hints(topic, student_context)
}
return tutoring_session
7、框架选择决策树
写在最后
技术趋势与发展方向
从技术演进的角度看,智能体框架正朝着以下几个方向发展:
1. 多模态融合成为标配
未来的智能体框架将原生支持文本、图像、音频、视频等多种模态的处理能力,实现更自然的人机交互。
2. 边缘计算与本地部署
随着模型小型化技术的进步,越来越多的框架将支持边缘设备部署,减少对云服务的依赖,提升响应速度和数据安全性。
3. 自适应学习与持续优化
智能体将具备从用户交互中学习的能力,通过强化学习等技术不断优化自身表现。
4. 行业垂直化深入
针对特定行业(医疗、金融、教育等)的专业化智能体框架将大量涌现,提供更精准的行业解决方案。
选择框架的最佳实践
1. 明确项目目标和约束
- 技术团队能力水平
- 项目时间和预算限制
- 性能和扩展性要求
- 安全和合规要求
2. 进行小规模概念验证
在大规模开发前,使用不同框架进行小规模测试,验证技术可行性和开发效率。
3. 考虑长期维护成本
- 社区活跃度和技术支持
- 文档完善程度
- 升级和迁移便利性
- 技术债务管理
4. 混合使用策略
根据不同模块的特点,选择最合适的框架,而不是强求使用单一框架解决所有问题。
未来发展
对于开发者:
- 保持技术视野开放:关注多个框架的发展,避免技术栈固化
- 重视基础能力建设:深入理解AI、图结构、工作流等核心概念
- 实践驱动学习:通过实际项目积累各框架的使用经验
- 关注行业应用:结合具体业务场景,选择最合适的技术方案
对于企业:
- 建立技术评估体系:制定框架选择的标准化评估流程
- 投资团队能力建设:培养既懂业务又懂技术的复合型人才
- 构建技术生态:建立内部技术分享和协作机制
- 平衡创新与稳定:在追求新技术的同时确保系统稳定性
结语
智能体技术正处于快速发展期,各种框架百花齐放,为开发者提供了丰富的选择。没有最好的框架,只有最合适的框架。关键是要根据具体的应用场景、团队能力和项目要求,选择最匹配的技术方案。
随着AI技术的不断进步,智能体框架也将持续演进。开发者应该保持学习的心态,关注技术发展趋势,在实践中不断提升自己的技术能力。同时,也要避免盲目追求新技术,而是要以解决实际问题为导向,选择成熟、可靠的技术方案。
**最终,成功的AI应用不仅仅取决于所选择的框架,更取决于对业务需求的深度理解、对用户体验的精心设计,以及对技术实现的精益求精。**希望本文能够为你在智能体框架选择和应用开发的道路上提供有价值的参考和指导。
本文由大模型算法工程师基于多年实战经验总结而成,涵盖了当前主流的11大智能体框架的深度解析。如有更新或补充,欢迎交流讨论。
参考资源:
更多推荐

 7
7 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)