
from clip to dino论文阅读
论文阅读想法:了解了dino这种视觉基础大模型的论文,又阅读了clip的文章,想着能不能替换clip中的image encoder部分,于是就找到了这一篇文章。
论文阅读想法:了解了dino这种视觉基础大模型的论文,又阅读了clip的文章,想着能不能替换clip中的image encoder部分,于是就找到了这一篇文章。
实验结论:
替换image encoder后的实验结果如下:
图1
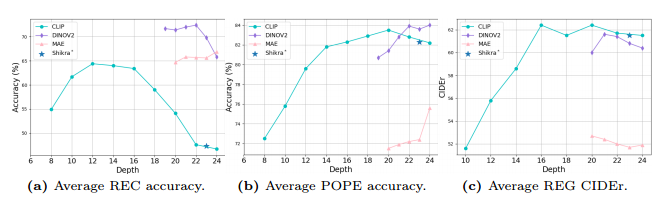
指标含义:
Average REC accuracy
任务:Referring Expression Comprehension (指代表达理解) → 给定一段文字,模型要在图中找到对应的物体(定位任务)。
Average POPE accuracy
任务:POPE (Object hallucination benchmark) → 测试模型会不会“幻觉”出不存在的物体。指标越高说明效果越好,幻觉越少
Average REG CIDEr
任务:Referring Expression Generation (指代表达生成) → 给定物体,生成一句话描述它。
说明MAE训练的模型不适用于我们的多模态对齐
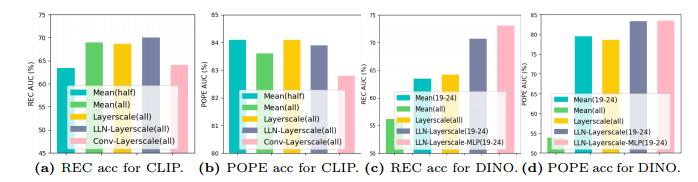
AUC 是衡量二分类模型整体判别能力的指标,越接近 1 越好。
上图介绍:
-
对 REC (定位任务):可能融合 中层 + 高层特征 会最好,因为既有空间细节又有语义。
-
对 POPE (幻觉任务):可能 深层特征占优,但融合中层信息也有帮助。
dino作为image encoder的实验:
由上述的实验结果可知(图一)dino在深层特征上有显著成效
作者参考 LLN-Layerscale 方法,在特征融合中加入 MLP 模块,形成 LLN-Layerscale-MLP
LLN-Layerscale-MLP
我们来讲解一下LLN-Layerscale-MLP方法
首先我们讲解一下LN,通俗来说我们会注意到LN和BN差异在于LN是同一样本不同特征之间的归一化,但是BN是不同样本相同特征下的归一化,batc h size较大时BN较好,batch size较小时,LN较好。这都是我们已有的基础知识。
我们给一个LN的例子


我们再来看LLN(低秩版本),即为linear layer normalization

后续的layerscale

通过这两个部分进行对齐。
文章中采取的其他策略:

Mean
layerscale

Conv-Layerscale(all)

后续:MAE与监督训练Deit模型作为image encoder的实验:
实验结果:MAE对于一般的定位实验中会好一些,但是在POPE (Prompted Object Probing Evaluation) 和 REG (Referring Expression Generation) 上表现效果非常差。作者给出的解释为,MAE的训练方法更关注局部特征而不是全局特征,而监督训练在任何任务上都很差,因为在家读的训练下,难以嵌入到空间一致的视觉空间
本文的提出的新型架构:COMM (CLIP and DINOv2 with Multi-level feature Merging)
以上为融合的框架很浅显易懂了,我就不讲解了了
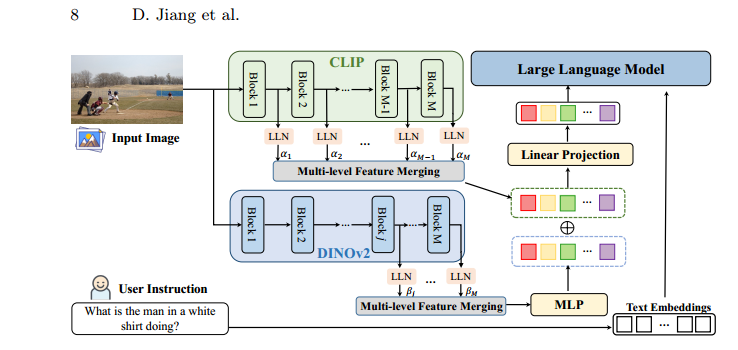
对齐和融合的方法:



更多推荐

 14
14 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)