
51c大模型~合集186
9 月 25 日,生数科技新一代图生视频大模型 Vidu Q2 正式全球上线,打破了原有 AI 生成的表情太假,动作飘忽不定,运动幅度不够大,无法指哪打哪的行业问题,实现从 “视频生成” 到 “演技生成”,从 “动态流畅” 到 “情感表达” 的革命性跨越,标志着 AI 视频生成技术正式从追求 “形似” 进入追求 “神似” 的新纪元,将为内容创作、影视产业、广告营销等领域带来全新升级。然而,当前的原
我自己的原文哦~ https://blog.51cto.com/whaosoft/14180268
#UIPro
告别“人工”点点点!中科院等发布UIPro:一个更懂你的通用GUI智能体
朋友们,想象一下,如果你的手机或电脑能自己看懂屏幕上的内容,然后帮你完成各种操作,比如自动订票、比价购物、管理邮件……那该有多爽?这个让AI像人一样操作图形用户界面(GUI)的梦想,一直是人工智能领域的终极目标之一。
最近,来自中科院、上海AI Lab等多个顶尖机构的研究者们,在这个方向上迈出了重要一步,他们提出了一个名为 UIPro 的通用GUI智能体,并被计算机视觉顶会 ICCV 2025 接收。简单来说,UIPro就是一个更强大、更通用的“屏幕操作机器人”,它在多个平台的多种任务上都展现了卓越的能力。
- 标题:UIPro: Unleashing Superior Interaction Capability For GUI Agents
- 作者:Hongxin Li, Jingran Su, Jingfan Chen, Zheng Ju, Yuntao Chen, Qing Li, Zhaoxiang Zhang
- 机构:中国科学院大学、中国科学院、香港科技创新研究院、香港理工大学、上海人工智能实验室、StepFun
- 论文地址:https://arxiv.org/abs/2509.17328
- 项目地址:https://github.com/ZJULiHongxin/UIPro
- 录用信息:ICCV 2025
通用GUI智能体的“三座大山”
在介绍UIPro之前,得先聊聊,为什么开发一个“通用”的GUI智能体这么难?过去的很多尝试,虽然也取得了一些进展,但始终面临着三座大山:
- 场景受限:很多模型只能在特定的App或者网站上工作,换个环境就“失灵”了。
- 数据不足:训练AI也需要“教科书”,但高质量的GUI交互数据非常稀缺,导致模型学得不够好,不够通用。
- 动作空间异构:这是个更技术性的问题。不同的数据集对“点击”、“滑动”这些操作的定义和格式都不一样。这就好比教一个机器人开车,A教练说“踩油门”,B教练说“加速”,机器人就懵了。这种不统一导致很难把多个数据集整合起来,发挥“人多力量大”的优势。
UIPro的“两步走”修炼法
为了翻越这三座大山,UIPro采用了一套精心设计的“两步走”训练策略:先学理解,再学操作。
第一步:海量数据预训练,打下“理解”基础
一个智能体要操作GUI,首先得“看懂”屏幕上有什么。这个能力,研究者称之为“GUI Grounding”(GUI基础理解与定位)。为了让UIPro具备超强的理解能力,研究团队干了件大事:他们整理并清洗了一个高达2060万样本的超大规模GUI理解数据集!
这个数据集的规模和多样性在同类中是前所未有的。它包含了各种各样的任务,比如定位屏幕上的文字、识别图标、理解按钮功能等等,覆盖了网页、安卓、iPad等多种平台和分辨率。
通过在这个庞大的数据集上进行预训练,UIPro学会了准确地将用户指令与屏幕上的具体元素对应起来,为后续的“操作”打下了坚实的基础。CV君觉得,这种“大力出奇迹”的思路,在数据为王的今天,确实是提升模型能力最直接有效的方法之一。
值得一提的是,研究团队还发现原始数据中存在大量噪声(比如空白、无效的UI元素),并为此专门设计了一套去噪流程,大大提升了数据质量,这对最终模型的性能至关重要。
第二步:统一动作空间,学会“操作”
光会看还不行,还得会动手。为了解决前面提到的“动作空间异构”问题,UIPro提出了一个统一动作空间(Unified Action Space)。
他们为移动端、网页端和桌面端分别设计了一套标准化的动作定义。比如,把各种数据集中不一致的swipe和scroll操作,统一成包含起始点、方向、距离的标准格式。这样一来,来自不同来源的训练数据就可以无缝合并,形成一个更大、更多样化的“操作教科书”。
然后,在这个统一的数据集上对预训练好的UIPro进行微调,使其学会根据用户任务,准确地规划并预测出下一步应该执行哪个标准动作。
实验结果:全面超越,甚至击败GPT-4V
经过两阶段的“修炼”,UIPro终于出山了。研究者在多个覆盖安卓、网页等场景的公开基准上对它进行了严格的测试。
结果非常亮眼:
在AITW基准测试中,UIPro的表现全面超越了之前的各种方法,甚至比强大的闭源模型 GPT-4V-OmniParser 还要高出一大截!
在AndroidControl和GUIAct等其他移动端和网页端任务上,UIPro同样取得了SOTA(State-of-the-art)的成绩,无论是操作的成功率还是动作预测的准确率,都遥遥领先。
成功秘诀何在?
作者通过消融实验,进一步验证了他们方法的有效性。
实验证明,大规模的GUI理解预训练至关重要。模型的“理解”能力越强(Grounding准确率越高),后续学习“操作”的效果就越好,呈现出非常明显的正相关关系。
同时,“统一动作空间”和“多源数据融合”也功不可没。如果不进行统一,直接把异构数据混在一起训练,模型性能会急剧下降。这说明,UIPro提出的这套方法论是其成功的关键。
总结
总而言之,UIPro的成功为通往通用GUI智能体的道路扫清了几个关键障碍。它用“海量数据预训练”解决了理解不深的问题,用“统一动作空间”解决了数据无法融合的问题,最终打造出一个能力超群的通用GUI智能体。
这项工作不仅在技术上取得了突破,更重要的是,它提供了一套可行的、可扩展的范式,让人们离那个“AI助理能像人一样帮你操作一切”的未来又近了一步。
..
#Vidu Q2
AI视频生成走向「演技生成」时代,生数科技Vidu全球发布
当 AI 视频不再只像过去那样比拼高清像素,而是开始进入 “飙演技” 阶段,AI 视频才算正式迈入内容生产的最高级形式 —— 影视级叙事新阶段。
9 月 25 日,生数科技新一代图生视频大模型 Vidu Q2 正式全球上线,打破了原有 AI 生成的表情太假,动作飘忽不定,运动幅度不够大,无法指哪打哪的行业问题,实现从 “视频生成” 到 “演技生成”,从 “动态流畅” 到 “情感表达” 的革命性跨越,标志着 AI 视频生成技术正式从追求 “形似” 进入追求 “神似” 的新纪元,将为内容创作、影视产业、广告营销等领域带来全新升级。Vidu Q2 图生视频功能不仅能胜任复杂表情变化的文戏,常见的多人打斗场景的武戏,而且还能完美呈现大片中的炫酷特效。
据了解,相比于今年上半年发布的 Vidu Q1 模型,此次发布的 Vidu Q2 图生视频功能在极致细微表情生成、推拉运镜、语义理解、生成速度与时长选择方面都有了大幅提升,主要有 4 大亮点:
1、AI 演技更生动——不仅能生成视频,更有生动演技;
2、镜头语言更丰富——运镜自然流畅,创作更显张力;
3、语义理解更准确——创意直达画面,想象即刻成真;
4、时长选择更自由——时长选择灵活,满足更多场景。
以下视频来源于
生数ShengShu
,时长00:48
此外,为了满足用户对于生成速度和生成质量的不同需求,Vidu Q2 图生视频分为闪电模式和电影大片模式。闪电模型下 20 秒就能生成 5 秒 1080P 视频片段,满足极速出片的需求;电影大片模式则主要满足对于复杂表演、运镜等有更高要求的用户。
目前,Vidu Q2 图生视频功能已同步在其 Web 端、APP 端以及 API 上线。
AI 演技更生动
前不久的威尼斯电影节,辛芷蕾以极其精湛的演技获得了威尼斯国际电影节最佳女主角奖。对于演技派来说,最高的褒奖是演什么像什么,看了让人产生共鸣和代入感。而这种代入感往往是通过演员的细微情绪变化实现的,在短短几秒中突显人物情绪张力,表达人物性格,推动故事发展。
此前 AI 生成的短剧、长片或多或少都存在人物表情僵硬、不自然,演技浮夸的情形,很难表现角色复杂细腻的情绪。而此次发布的 Vidu Q2 图生视频则突破 “最后一道壁垒”,在细微表情生成中的技术被成功攻克,使数字角色能够展现出生动且充满感染力的演技,赋予了 AI 角色以生命力。
我们可以让 AI 演员和电影演员同台 PK 演技,复刻《甜蜜蜜》张曼玉经典片段,短短 5 秒时间呈现从微笑 —— 委屈 —— 难过三种复杂情绪。上边是电影原片段,下边是 Vidu Q2 图生视频生成的,人物演技非常自然,三种情绪之间的转换很有呼吸感,即使努力压抑,但是仍然流露出委屈和难过,对比来看 AI 生成的视频与原视频并无显著差别。

原视频
,时长00:05
Vidu Q2
真正的老戏骨每一个细胞都在演戏。这次 Vidu Q2 图生视频相比于 Q1,在细腻的情绪表达上有了明显提升,即使一个眼神也能述说故事。

输入图片
,时长00:08
Vidu Q2 图生视频
上述例子中,特写聚焦于一个金发碧眼老人的半边脸,周围的火焰将老人的脸照得通红,他轻轻地眨了眨眼,眼泪中饱含泪水,一滴眼泪从右眼中缓缓流下。即使没有任何言语和环境渲染,也让人对战争的残酷感同身受,AI 人的演技足可以媲美真人。
在动漫场景中,Vidu Q2 的表现也相当惊艳,表情惟妙惟肖更有代入感。在小狐狸的案例中,从瞪大眼睛的惊喜,到躲在石头后面的惊讶和害怕,耳朵竖了起来,再到稍微放松警惕后的无奈,表情的变化似乎在告诉观众好像有什么突如其来的大事发生。小狐狸灵动的演技有迪士尼动画那味了。
,时长00:08
在多个角色互动场景中,Vidu Q2 的表现也可圈可点。下面案例中,一男一女笑得合不拢嘴,之后女生捂着嘴笑,男生低头笑着擦了擦眼睛,两人再互相对视,真实得仿佛进入了某个播客的录制现场。
,时长00:08
再拿 Vidu Q2 图生视频和其他 AI 视频产品作对比。下面案例中,Vidu Q2 生成的视频每个表情都表现非常精准,从淡淡地微笑到嘴唇微张,眼神从微微向下看到望向远方。其他 AI 视频则完全没有表现出细微表情的变化,视线仅表现了看向远方。
提示词:视线微偏镜头下方,嘴角轻上扬但不露齿,下巴略收。随后瞳孔微放大,眼神越过镜头远点,嘴唇湿润轻启。

Vidu Q2

其他
下面古装戏场景中,其他家虽然也表现了表情凝重,但是演技比较单一,仅是完成了提示词要求,最后抬手也没有碰到额头,给人不真实的感觉。对比来看,Vidu Q2 的表情层次更加丰富,不仅严格遵循了提示词,而且 AI 自动设计了眼神和动作的变化,表演上 “更为走心”,首先男人边喘着粗气边表情凝重地看向远方,紧接着视线收回,嘴巴微闭,抬起手擦了擦额头,把凝重又疲惫的感觉演绎得非常到位。
提示词:这是一个美丽的夕阳场景,阳光照着古战场,空气中有着漂浮的灰尘,男人喘着粗气进行简单的休息,表情凝重,最后用手擦了一下额头
,时长00:08
Vidu Q2

其他
从 “AI 木头” 到 “AI 演技派”,从浮夸演技到内心戏,Vidu Q2 新一代 AI 演技的诞生,预测未来将在影视短剧、数字人、广告营销等多个领域有广泛应用。
不仅如此,Vidu Q2 还是个能文能武的全能型演技派,在武打戏上也是个 “老戏骨”。
此前 AI 视频普遍存在的问题是,运动飘忽不定,就连现实生活中常见的跑步和打篮球场景都很难实现,多人打戏更是需要依靠超高的提示词技巧和多次生成,即使这样打戏也是软弱无力,像是自动放了 2 倍慢速,毫无看点。
Vidu Q2 图生视频在运动幅度上有明显提升,即使是比较有挑战的连续运动(比如打架、打拳等)场面也能精准还原,实现真正的 “拳拳到肉”。
下面双人拳击场景中,红方迅速出拳,蓝方快速躲避并迅速来了个左勾拳,红方连续出拳后,红蓝方稍作停顿,双方都发起反攻,蓝方用双手防备后开启猛攻,连续三次攻打红方腹部后退回原地,瞬间带入拳击比赛现场,紧张气氛拉满。
,时长00:05
如果把真实场景中的人物换成动画中的小林和悟空,效果也同样惊人。悟空跳跃后放出大招冲击波,之后与小林连续多次出拳过招,双方打斗的同时也伴随着炫酷的动画特效,生成的视频兼具速度和力量感,让人看得十分过瘾。

Vidu Q2 甚至不需要复杂的提示词也能呈现非常精彩的打戏。
如下面案例中,长发女生手持光剑与周围的多个小型机器人进行激烈对战,女生奔跑,蹲下,站起来用光剑与迎面而来的小型机器人对抗,一跃而起后转而被其他机器人打击退回原地。如此复杂的打戏,提示词却相当简单,“流畅的奔跑,爽快的打斗,合理安排不同镜头,自由运镜”,这也意味着 Vidu Q2 对于动作的理解和生成能力已经进化到 Next level 了。
,时长00:08
更为值得一提的是,Vidu Q2 图生视频即使在如此大幅度的运动下,仍然能保持角色较高的一致性,不会出现人物模糊或者变脸的情况。这对于影视、动漫制作来说至关重要,背后得益于 Vidu 在一致性上的投入。去年 Vidu 在全球首个推出了参考生视频功能,将 AI 视频的可控一致性拉到了新的高度,而此次推出的 Vidu Q2 则延续了其作为一致性开创者的优势。
镜头语言更丰富
当其他家都在鼓吹好莱坞级别运镜时,一向低调务实的 Vidu 已经直接让新手小白做影视大片了。据了解,Vidu Q2 可轻松实现从宏观全景到微观特写的快速切换,以营造更具冲击力的视觉效果。
为了让 AI 视频更能满足广告电商、影视动漫等较为复杂的运镜需求,Vidu Q2 图生视频在复杂运镜上做到了秒级精准可控。
如下面的动画案例中,侠客挥舞着剑到变身闪电狼,中间有 6 个镜头切换,包括从特写直接切到大全景,同时还需要配合侠客转身同时腾空而起等动作,即使在现实拍摄场景中挑战也很大,但从实际生成效果来看, Q2 生成的画面镜头和 AI 人物配合默契,整个动作一气呵成,非常丝滑。
,时长00:08
在极速运动场景下的大幅度镜头切换非常考验空间理解能力和主体稳定性,对于 AI 视频来说极具挑战,但是 Vidu Q2 的表现却非常完美。从全景到赛车手眼神特写再到冲线后的观众席特写,Vidu Q2 在整个过程中对于推拉摇移镜头的调度极为流畅,跟随镜头下突显了赛车手全力冲刺的紧张感和速度感,同时也反映了赛场周围的热闹气氛。
提示词:颠簸镜头跟随
镜头一:全景推进跟随 FI 赛车前景
镜头二:切换戴 F1 赛车头盔的驾驶员紧张驾驶 F1 赛车眼神
镜头三:特写 F1 赛车加速仪表
镜头四:F1 赛车驾驶员第一人称视角,赛车加速前进
镜头五:F1 赛车快速行驶全景视角,冲向终点
镜头六,F1 赛车冲线后,看台上欢呼庆祝的观众特写视角
,时长00:08
语义理解更准确
无论是 AI 演技的提升还是运镜的精准拿捏,其实质上是 Vidu Q2 在动作理解、表情理解和镜头语言理解上的飞升。据了解,由于 Vidu Q2 在上下文推理、图像及语义理解和物理仿真能力上的提升,使其在提示词遵从上有了质的飞跃,有创作者评价为言出法随,指哪打哪。内容创作者不再需要像过去一样反复抽卡、反复调整提示词和输入画面,大幅减少了视频生成次数,可直接将创意转化为想要的视频画面。
在实际测试中发现,Vidu Q2 像是一位严格听话同时又具备合理想象力的 “AI 导演”。
下面的案例中,提示词要求在 8 秒中精确切换 4 个不同的镜头,完成从猫猫在街头弹古筝,到从古筝中飞出邪恶的骷髅战士的复杂叙事,可以看到生成的视频中不仅严格遵循了复杂的提示词的所有要求,而且骷髅战士从一团白气中突然出现的画面非常惊艳,镜头切换也很流畅。
提示词:第 1-2s:坐着的猫轻轻抚动古琴琴弦,镜头快速推近;3-4s:近距离大特写猫邪恶诡异的一笑,然后突然变得凶狠,镜头先推近拍摄同时向右环绕运镜拉远到侧面;5s:猫用力拨动琴弦;6-8s:琴弦释放出白色亮光魔法灵气,灵气向左冲刺,然后灵气幻化形成一个拿着刀的气态邪恶骷髅战士向左高速飞行,镜头高速跟踪拍摄同时推近运镜

Vidu Q2 在语义理解上质的突破,将过去因反复生成带来的时间、人力、成本以及效果的不确定性,变为高质量稳定输出的确定性,预计影视短剧、广告行业即将迎来 AI 视频大规模商业化拐点。
时长选择更自由
除了性能提升之外,一向对市场需求敏感的 Vidu 也推出了新功能,赋予创作者更多自由发挥的空间。
此前业内 AI 视频产品更多以 5 秒时长偏多,无法让内容创作者自由选择,具有一定的局限性。Vidu Q2 图生视频此次推出的 2-8 秒时长随心选,无论是 1 秒的特写镜头,还是 8 秒的连续长镜头或多个切换镜头,都可以任意选择,满足创作者不同场景的叙事需求。

此外,作为内容生产力工具,这次 Vidu Q2 的发布仍然继承了 Vidu 的优良传统,做到了极高性价比、极致画面质量、极快生成速度的平衡。
在同等画质和时长上,Vidu Q2 在生成速度上做到了行业领先。Vidu Q2 图生视频闪电模式下 1080P 5 秒视频仅为 20 秒,实现了高质量画面的极速生成。
当以 Vidu Q2 为代表的产品开始谈论 AI 演技时,我们知道下一个 AI 时代的内容新世界即将到来。
....
#Code World Model(CWM)
首个代码世界模型引爆AI圈,能让智能体学会「真推理」,Meta开源
大模型的架构,要彻底进化了?
昨晚开始,AI 圈都在研究一个神奇的新物种 ——Code World Model(CWM)。

Meta 重组后的 AI 部门推出的首个重磅研究,是一个世界模型,用来写代码的。
,时长00:34
它和「传统」的大语言模型(LLM)思路不同,理论是这样的:
当人类进行计划时,我们会在脑海中想象不同行动可能带来的结果。当我们推理代码时,我们会在心中模拟其部分执行过程。当前一代的大语言模型在这方面表现不佳,往往难以做到真正的推理和模拟。那么,一个经过显式训练的代码世界模型(Code World Model)是不是能够开启新的研究方向呢?

Meta 刚发布的这个 CWM,是一个 320 亿参数的开放权重 LLM,以推动基于世界模型的代码生成研究。
CWM 是一个稠密的、仅解码器结构的 LLM,支持最长 131k tokens 的上下文长度。独立于其世界建模能力,CWM 在通用编程与数学任务上表现出强大性能:
- SWE-bench Verified(含测试时扩展):pass@1 65.8%
- LiveCodeBench:68.6%
- Math-500:96.6%
- AIME 2024:76.0%

可见,虽然 CWM 的绝对性能还不算太高,但它在 30B 级别模型的横向对比上性能已算不错。

SWE-bench Verified pass@1 分数
为了提升代码理解能力,而不仅仅局限于从静态代码训练中学习,Meta FAIR CodeGen 团队在 Python 解释器和智能体式 Docker 环境中使用了大量观测 - 动作轨迹进行中间训练(mid-train),并在可验证编码、数学和多轮软件工程环境中进行了大规模多任务推理强化学习(RL)。
为支持进一步的代码世界建模研究,Meta 开放了模型在 中间训练(mid-training)、SFT 和 RL 阶段的检查点。

- 论文标题:CWM: An Open-Weights LLM for Research on Code Generation with World Models
- 论文链接:https://ai.meta.com/research/publications/cwm-an-open-weights-llm-for-research-on-code-generation-with-world-models/
- 模型权重:https://ai.meta.com/resources/models-and-libraries/cwm-downloads/
- HuggingFace:https://huggingface.co/facebook/cwm
借助 CWM,Meta 提出了一个强大的测试平台,以探索世界建模在改进代码生成时的推理与规划能力方面的机会。
该研究展示了世界模型如何有益于智能体式编码,使得 Python 代码执行能够逐步模拟,并展示了推理如何从这种模拟中受益的早期结果。
在该研究中,Meta 似乎从传统开发的过程中汲取了灵感。优秀程序员会在上手写代码之前先在脑内推演,而现在基于大语言模型的代码生成工具,是在基于海量数据生成对相关代码的「模仿」。看起来像是对的,和真正理解写出的代码之间总会有点 gap。
一个明确训练的代码世界模型,应该能够预测自己行为的后果,进而作出判断实现有效的决策。
有一个很有意思的例子,大模型总是会犯些低级错误,比如数不清楚「strawberry」里有几个「r」。
而采用 CWM,就可以对一段统计 "strawberry" 中字母 "r" 的代码执行过程进行追踪。可以将其类比为一个神经版的 pdb —— 你可以将其设置在任意初始帧状态下,然后推理过程就能够在 token 空间中调用这一工具来进行查询。

CWM 的 Python 跟踪格式。 在给定源代码上下文与跟踪起始点标记的情况下,CWM 预测一系列的调用栈帧,表示程序状态及相应的执行动作。
CWM 模型基于大量编码数据和定制的 Python + Bash 世界建模数据进行训练,使其能够模拟 Python 函数的执行以及 Bash 环境中的智能体交互。

在 Meta 进行的更多实验中,CWM 在有无测试时扩展(tts)的情况下均达到了同类最佳性能,分别取得了 65.8% 和 53.9% 的成绩。需要注意的是,GPT-oss 的分数是基于 500 道题中的 477 道子集计算得出的。

CWM 与基线模型在 Aider Polyglot 上的结果,取自官方排行榜。

在 SWE-bench Verified 上,结合本文提出的 best@k 方法与多数投票(majority voting)的测试时扩展(TTS),能够显著提升 CWM 的 pass@1 得分,如图(a)所示。
在 Aider Polyglot 基准上,采用整文件编辑格式(whole file edit format)时,CWM 在不同编程语言上的准确率表现如图(b)所示。

Terminal-Bench 上 CWM 与各基线模型的结果,取自官方排行榜。

BigOBench 结果
在时间与空间复杂度的预测和生成两类任务上,将 CWM 与 Qwen3-32B(带推理能力)、Qwen3-coder-30B 以及 Gemma-3-27B 进行了对比。在时间复杂度预测与生成的全部指标上,CWM 均超越了基线模型。在空间复杂度生成方面,CWM 在仅代码模式下的 pass@1 上取得最佳成绩,并在其余指标中排名第二。
Meta 团队的愿景是让代码世界模型弥合语言层面的推理与可执行语义之间的鸿沟。
消融实验已经表明,世界建模数据、Python 执行轨迹以及可执行的 Docker 环境,能够直接提升下游任务表现。更广泛地说,CWM 提供了一个强有力的试验平台,支持未来在零样本规划、xx的链式思维、以及稀疏且可验证奖励的强化学习等方向的研究。
世界模型应当能够改进强化学习,因为那些已经熟悉环境动态的智能体,可以更专注于学习哪些动作能够带来奖励。尽管如此,要在预训练阶段跨任务地持续发挥世界模型的优势,仍需要进一步研究。最终,能够推理自身动作后果的模型,将在与环境的交互中更为高效,并有望扩展其能够处理的任务复杂度。
更多细节,请参阅原论文。
....
#RoboBrain-Audio(FLM-Audio)
xx智能从此「边听边说」,智源研究院开源原生全双工语音大模型
语音交互作为人机通信的关键接口,长期以来受限于高延迟、低自然度的交替式对话架构。为突破这一瓶颈,北京智源人工智能研究院联合 Spin Matrix 与新加坡南洋理工大学,正式发布 RoboBrain-Audio(FLM-Audio) —— 首个支持 “自然独白 + 双训练范式” 的原生全双工语音对话大模型。
RoboBrain-Audio 对话样例,xxx,1分钟
在一段自然对话音频中,用户连续提出多个不同问题,并多次在模型回答过程中打断。RoboBrain-Audio 始终能够迅速停顿当前输出、准确理解新的问题并即时作答,展现出真实交流中所需的全双工、强鲁棒性与高自然度。
RoboBrain-Audio 采用原生全双工 (Native Full-duplex) 架构,相比传统的 TDM(时分复用)模型在响应延迟、对话自然度上实现飞跃式提升,同时语言理解能力显著强于其他原生全双工模型,标志着xx智能体从 “能听会说” 向 “边听边说” 的交互能力跃迁。
根据公开数据,当前业界训练音频基座模型时使用的数据量已达到上千万乃至上亿小时,这些模型在音色克隆和长回复生成上更具优势,而 RoboBrain-Audio 仅使用 100 万小时 (业界数据量的 1%) 数据训练,不但回复质量满足日常交互需求,而且具有响应模式更为敏捷自然等优势,尤其适配xx场景。RoboBrain-Audio(FLM-Audio)相关论文已公开发布,模型与代码均已开源。
- 论文链接:https://arxiv.org/abs/2509.02521
- Hugging Face 模型页:https://huggingface.co/CofeAI/FLM-Audio
- GitHub 代码库:https://github.com/cofe-ai/flm-audio
为什么必须是 “原生全双工”?
从 TDM 到同步对话的演进
现有的语音对话模型,例如 Kimi-Audio, MiMo-Audio 等,多采用时分复用(TDM) 架构,即将听、说、文本等多个通道的输入和输出交织在同一序列中处理。虽然实现简单,但这种交织会使主模型总序列长度过长,计算开销随通道数急剧增加。同时,TDM 不善于处理实际、开放场景中快速变化的输入:当用户频繁打断时,模型的反应延迟受限于外部 chunk 机制,通常高达 2 秒,更无法实现 “边听边说” 等更类人的响应模式。这些因素都限制了 TDM 架构的实时交互体验。
相反,原生全双工(Native Full-Duplex )架构(如 Moshi)将多通道信息在每一时间步合并处理,也就是支持 “边听,边想,边说”,不但避免了序列长度爆炸,而且可以将打断响应的延迟降至最低 80ms 级别。然而,当前的原生全双工模型依赖词级对齐策略,需为每个词标注精确的语音时间戳,并将连续的文本 token 打散。该策略不仅成本高昂,还会破坏预训练语言模型的能力,导致指令跟随性能下降。
RoboBrain-Audio(FLM-Audio) 在采用最先进的原生全双工架构的基础上,彻底摆脱了 “词级对齐” 的工程枷锁,不再依赖高成本、易出错的精细时间标注,为模型训练效率与泛化能力打开新空间。

核心创新:自然独白对齐 + 双训练
1. 自然独白:从 “词对齐” 到 “句对齐”
RoboBrain-Audio 弃用词级时间戳,创新性地在全双工实时框架下引入 “自然独白(Natural Monologue)” 对齐机制:
- 完整句子先生成 → 让语言模型自由发挥,不被 special token 阻断;
- 语音通道异步生成 → 按句异步朗读,类比人类 “先想后说”;
- 等待机制与打断处理 → 可被中断、可并发听说,支持真正的全双工交互;
- 只需句级标注 → 降低训练数据成本、避免精细对齐误差;
这一设计保留了语言大模型在生成连贯性和指令理解上的天然优势,使模型更自然、更强大。此外,自然独白机制还有效解决了部分词语(尤其是数字)的上下文依赖性发音问题。在传统词级对齐策略中,模型往往需要在词刚被解码时立即输出对应语音,这会导致在缺乏完整上下文时出现错误发音(如 “2025” 可能读作 “两千零二十五” 还是 “二零二五” 需依语境判断)。而自然独白允许模型先完成整个句子的文本生成,再统一决定最自然的语音表达方式,从而提升发音准确性和语言连贯性,避免 “听感割裂”。

2. 语音新训练范式:后训练 + 有监督微调,构建 “听说能力” 全闭环
模型训练分为两个阶段,共四个子阶段,分别模拟语音识别(ASR)、语音合成(TTS)及交互对话任务:
后训练阶段(Post-Training):赋予模型 “听” 和 “说” 的基础能力
- 数据:在第一子阶段使用约 100 万小时音频 - 文本对,在第二子阶段额外引入开源人工精标对齐数据。
- 双格式组织:同一份数据被组织成两种格式交替训练:
- TTS 风格(文本领先):文本通道先出现完整句子,语音通道延迟 2 个 token 开始输出。模拟语音合成(TTS) 任务。
- ASR 风格(语音领先):语音通道先出现输入音频,文本通道随后输出完整转录文本。模拟语音识别(ASR) 任务。
- 目的:让模型同时掌握 “听写”(ASR)和 “朗读”(TTS)这两项核心技能,为后续的对话任务打下坚实基础。
有监督微调阶段(SFT):塑造对话与全双工能力
- 数据:使用 20 万条合成的高质量多轮对话数据,语音由 700 + 种人声通过 TTS 系统生成。
- 核心子阶段:
- SFT-1(半双工过渡阶段):采用 “ASR-Response-TTS” 格式。模型先听完用户整句输入,将其转写为文本(ASR),再生成文本回复并转换为语音(TTS)。此阶段巧妙地融合了后训练学到的 ASR 和 TTS 能力。
- SFT-2(全双工最终阶段):采用 “Response-TTS” 格式。隐藏 ASR 监督信号,模型必须直接从音频输入理解用户意图,并生成回复。在此基础上,引入用户随机打断,模型学会在 0.5 秒内停止当前输出并响应新输入,从而获得全双工交互能力。
系统实验:ASR、TTS、对话性能在原生双工模型中全面领先
通过系列实验,科研人员系统性地评估了 RoboBrain-Audio 在音频理解、音频生成和全双工对话三个核心任务上的性能,并通过消融实验验证了其关键设计选择的有效性。
1. 音频理解
该工作通过自动语音识别(ASR)和语音问答(Spoken QA)两项任务,在 benchmark 上进行评测,实验结果表明,RoboBrain-Audio 在中文 ASR(Fleurs-zh)上优于非全双工架构的 Qwen2-Audio;在均使用原生全双工架构的前提下,RoboBrain-Audio 使用更少的后训练数据在 LibriSpeech-clean 上显著优于 Moshi,印证了自然独白和双训练的优势。

2. 音频生成
该工作通过文本转语音(TTS)任务,对模型的音频生成能力进行评测。分别在 Seed-TTS-en(英文)、Seed-TTS-zh(中文)两个数据集上进行模型能力的评估。RoboBrain-Audio 的 WER 与专业 TTS 模型(如 Seed-TTS、CosyVoice2)接近,表现优秀。SIM 分数较低,原因是其未针对音色克隆进行专门优化。

3. 全双工对话
该工作通过多轮语音对话任务,采取自动评估(使用 DeepSeek-V3 对回答质量评分(0–10))和人工评估(5 名标注员从 4 个维度评分(1–10))两种方式,与 Qwen2.5-Omni 模型(非原生双工)进行对比。RoboBrain-Audio 在生成文本内容质量接近的前提下,在流畅度、响应速度等用户体验相关指标上取得领先,体现了自然独白设计能够弥补原生全双工模型的文本能力短板,同时充分发挥其天然架构优势。

RoboBrain-Audio 的生态意义:
丰富 RoboBrain 全栈体系,迈向xx智能体
对于 “原生全双工” 框架而言,RoboBrain-Audio 的自然独白策略是对音频 - 文本对齐方式的根本性革新,而双训练范式则是确保这一策略成功实现的工程保障。两者结合,使模型在数据效率(更少的数据)、性能表现(更强的语言能力与更低的延迟)和用户体验(更自然的对话)上实现了全面突破,为构建真正智能的xx语音交互 Agent 提供了新的可复制范式。
RoboBrain-Audio 并非孤立产品,是智源 RoboBrain 系列面向 “xx智能” 的关键能力载体:
- 已有的 RoboBrain 系列模型专注于xx感知、规划与操作;
- RoboBrain-Audio 赋能语音理解与自然语言交互;
- 两者结合,将加速构建 “听懂人话、看懂世界、动手做事” 的机器人智能体。
未来,团队将持续深度整合 RoboBrain-Audio 的强语音交互能力与 RoboBrain 在任务规划、物体感知等方面的能力,实现自然语音交互驱动下复杂任务的执行,持续提升机器人在导览导购、家庭等场景的服务效能。
...
#TC-Light
面向xx场景的生成式渲染器TC-Light来了
TC-Light 是由中科院自动化所张兆翔教授团队研发的生成式渲染器,能够对xx训练任务中复杂和剧烈运动的长视频序列进行逼真的光照与纹理重渲染,同时具备良好的时序一致性和低计算成本开销,使得它能够帮助减少 Sim2Real Gap 以及实现 Real2Real 的数据增强,帮助获得xx智能训练所需的海量高质量数据。
,时长00:43
它是如何实现的呢?本文将为你揭秘 TC-Light 背后的黑科技!本工作已中稿 NeurIPS2025,论文与代码均已公开,欢迎大家试用和体验,也欢迎大家到 Project Page 体验 Video Demo。
- 论文题目:TC-Light: Temporally Coherent Generative Rendering for Realistic World Transfer
- 项目主页: https://dekuliutesla.github.io/tclight/
- 论文链接: https://arxiv.org/abs/2506.18904
- 代码链接: https://github.com/Linketic/TC-Light
研究背景
光线及其与周围环境的交互共同塑造了人类以及xx智能体感知数字世界和现实世界的基本方式,在不同光照条件下对世界的观测使得我们理解光线与物质的交互关系,使得我们形成对周边环境物质和几何属性的基本判断,并且也使得我们能够在不同的光照条件下都能够鲁棒且正确地完成与世界的交互。
然而,在现实环境中采集不同光照与场景条件下的数据代价高昂,而仿真环境中尽管可以获得近乎无限的数据,但受限于算力资源,通常需要对光线的多次折射衍射以及纹理精度进行近似和简化,使得视觉真实性无可避免地受到损失,在视觉层面产生 Sim2Real Gap。而如果能够借助生成式模型根据所需的光照条件对现实或仿真环境下采集到的视频数据进行重渲染,不仅能够帮助获得增加已有真实数据的多样性,并且能够弥合计算误差带来的 CG 感,使得从仿真器中得到视觉上高度真实的传感器数据,包括 RL-CycleGAN 在内的许多工作已经证实,这一策略能够帮助减少将xx模型迁移到真实环境中所需微调的数据量和训练量。
尽管这一任务意义重大,但实际解决过程面临许多挑战。用于训练的视频数据往往伴随复杂的运动以及前景物体的频繁进出,同时视频序列有着较长的长度以及较高的分辨率。我们的定量和定性实验证据(参见论文实验部分及 Project Page)表明,在这些复杂且困难的输入条件下,已有的算法要么受制于训练所用视频数据的分布(如 COSMOS-Transfer1,Relighting4D),要么难以承受巨大的计算开销(如 Light-A-Video, RelightVid),要么难以保证良好的时序一致性(如 VidToMe, RAVE 等)。

图 1 TC-Light 效果展示
为了推动这一问题的解决,我们提出了 TC-Light 算法,在提升视频生成模型计算效率的同时,通过两阶段在线快速优化提升输出结果的一致性,如图 1 和视频Demo所示所示,本算法在保持重渲染真实性的同时,时序一致性和真实性相比于已有算法取得了显著提高。下面对算法细节进行详细介绍。
二、TC-Light 算法介绍
零样本时序模型扩展
TC-Light 首先使用视频扩散模型根据文本指令对输入视频进行初步的重渲染。这里我们基于预训练好的 SOTA 图像模型 IC-Light 以及 VidToMe 架构进行拓展,同时引入我们所提出的 Decayed Multi-Axis Denoising 模块增强时序一致性。具体而言,VidToMe 在模型的自注意力模块前后分别对来自不同帧的相似 token 进行聚合和拆分,从而增强时序一致性并减少计算开销;如图 2 中 (a) 所示,类似 Slicedit,Decayed Multi-Axis Denoising 模块将输入视频分别视作图像 (x-y 平面) 的序列和时空切片(y-t 平面)的序列,分别用输入的文本指令和空文本指令进行去噪,并对两组噪声进行整合,从而使用原视频的运动信息指导去噪过程。不同于 Slicedit,我们在 AIN 模块对两组噪声的统计特性进行了对齐,同时时空切片部分的噪声权重随去噪步数指数下降,从而避免原视频光照和纹理分布对重渲染结果的过度影响。

图 2 TC-Light 管线示意图
两阶段时序一致性优化策略
尽管通过引入前一小节的模型,视频生成式重渲染结果的一致性得到了有效改善,但输出结果仍然存在纹理和光照的跳变。因此我们进一步引入两阶段的时序一致性优化策略,这同时也是 TC-Light 的核心模块。在第一阶段,如图 2 中 (b) 所示,我们为每一帧引入 Appearance Embedding 以调整曝光度,并根据 MemFlow 从输入视频估计的光流或仿真器给出的光流优化帧间一致性,从而对齐全局光照。这一阶段的优化过程非常快速,A100 上 300 帧 960x540 分辨率只需要数十秒的时间即可完成。
在第二阶段,我们进一步对光照和纹理细节进行优化。如图 2 中 (c) 所示,这里我们首先根据光流以及可能提供的每个像素在世界系下的位置信息,快速将视频
![]()
压缩为码本
![]()
(也即图中的 Unique Video Tensor),即:

其中 κ(x,y,t) 为视频帧给定像素依据光流及空间信息得到的码本索引,这一基于时空先验的压缩方式在原视频上近乎可以保持无损。不同于 Vector Quantization 仅考虑颜色相似性的做法,这一压缩方案保证了被聚合的像素之间的时空关联性,使得对应同一个码本值的不同像素具有相似的时空一致性优化目标和梯度。随后,我们以码本
![]()
作为优化目标,以解码后的帧间一致性作为主要优化目标,并且以 TV Loss 抑制噪声,同时以 SSIM Loss 使得与一阶段优化结果保持一定程度的结构相似性。实验结果表明,这一阶段的优化能显著改善时序一致性,同时非常快速,A100 上 300 帧 960x540 分辨率通常只花费 2 分钟左右,且由于以压缩后的码本作为优化目标,不仅避免了以往工作以 NeRF 或 3DGS 为载体带来的 10-30 分钟的训练代价,显存开销上也能得到优化。
三、实验与分析

表 1 与主流算法的定量性能比较,其中 VidToMe 和 Slicedit 的基模型都换成了 IC-Light 以进行公平比较。Ours-light 指不用 Multi-Axis Denoising 模块的结果,相当于对 VidToMe 直接应用两阶段优化算法。
为了验证算法在长动态序列的重渲染表现,我们从 CARLA、Waymo、AgiBot-DigitalWorld、DROID 等数据集收集了 58 个序列进行综合评测,结果如表 1 所示。可以看到我们的算法克服了已有算法在时序一致性和计算开销等方面的问题,取得了最佳的综合性能表现。图 3 的可视化对比也表明,我们的算法在保持内容细节的同时得到了高质量的重渲染性能表现。

图 3 一致性与生成质量可视化对比。TC-Light 避免了 (a) 中像 Slicedit 和 COSMOS-Transfer1 那样不自然的重渲染结果和 (b) 中展现出的模糊失真,或 (c) 中像 IC-Light 和 VidToMe 那样的时序不一致性。
此外,我们也在有 GT 数据的仿真数据集 Virtual KITTI 上进行了比较,从而可以使用 SSIM 和 LPIPS 等指标替换 CLIP-T 等代理指标获得更客观的性能评估。表 2 的结果同样表明,我们的算法很好地取得了计算开销和性能之间的平衡,取得了最佳的重渲染效果。

表 2 Virtual KITTI 数据集上与主流算法的定量性能比较
四、总结
TC-Light 作为一种新的生成式渲染器,克服了xx环境下视觉传感器数据重渲染面对的时序一致性和长序列计算开销两大挑战,在性能表现上优于现有技术,不仅为 Sim2Real 和 Real2Real 数据扩展带来了新的思路,也为视频编辑领域带来了新的模型范式。TC-Light 的论文和代码均已开源,希望能够相关领域带来不同的思考和启发。
....
#Meta 的 AI 梦之队组成了?
刚刚,Meta挖走OpenAI清华校友宋飏,任超级智能实验室研究负责人
Meta 的 AI 梦之队组成了?
扎克伯格又从 OpenAI 挖走了一位华人科学家,而且这位称得上是「超级大脑」。
本周四午间传来消息,原 OpenAI 战略探索团队负责人宋飏(Yang Song)加入 Meta,他成为了新成立的 Meta 超级智能实验室(MSL)研究负责人。
据多方消息称,宋飏现在将向赵晟佳(Shengjia Zhao)汇报工作。赵晟佳是另一位刚刚从 OpenAI 转来的老同事,后者自 6 月宣布加入 Meta 。
今年 6 月起,Meta 发起了一场 AI 人才的争夺战,目标覆盖行业领先的 OpenAI,到谷歌、Anthropic 等公司的团队,给出的薪资条件极高。据说迄今为止,顶尖研究人员至少已挖来了 11 人。
宋飏自 2022 年起加入 OpenAI。他的研究重点是构建多模态大模型、生成模型架构、优化、训练目标和数据效率的改进。此前,他在 Google Brain、Uber ATG、微软工作和实习过。
在机器学习学术领域,宋飏一直是知名的学者。他 14 岁保送清华大学,本科获数学和物理学学士学位,曾跟随朱军等人做研究,后于 2016 年赴斯坦福大学读博。
在斯坦福大学期间,他提出的突破性技术《Score-Based Generative Modeling through Stochastic Differential Equations》通过估计数据分布的梯度,在图像生成质量上实现了对当时主流技术 GAN 的超越。

该工作被评为 ICLR 2021 杰出论文,为 OpenAI DALL-E 2,以及 Stable Diffusion 等如今主流的图像生成模型奠定了关键理论和技术基础。
值得一提的是,宋飏和赵晟佳本科都就读于清华大学。他们在斯坦福大学攻读博士学位期间,师从同一位导师 Stefano Ermon。
今年夏天,扎克伯格在一份发给全体员工的备忘录中,盛赞了赵晟佳令人印象深刻的履历,称其是 OpenAI ChatGPT、GPT-4、所有迷你模型、4.1 和 o3 的共同创造者 —— 但他并未具体说明赵晟佳在 Meta 的新职位。
7 月份,扎克伯格在 Threads 的一篇帖子中写道,虽然赵晟佳「是实验室的联合创始人」,并且「从第一天起就是我们的首席科学家」,但 Meta 决定「正式确立他的领导角色」,担任实验室的首席科学家。

此前,据《连线》杂志报道,赵晟佳曾威胁要重返 OpenAI,甚至已经签署了雇佣文件。
不过自调整 AI 研究团队,提出新研究,再到持续的人才引进动作看来,Meta 的大模型探索正在步入正轨。
Meta 日益复杂的 AI 部门已经挤满了大牌 AI 人才,宋飏的加入无疑为该部门增添了新的活力。
参考内容:
https://www.wired.com/story/meta-poaches-openai-researcher-yang-song/
.....
#看懂“空间智能”硬核全栈
李飞飞 World Labs 热潮之后
李飞飞World Labs牵头发布90页3D/4D世界模型综述,首次把VideoGen、OccGen、LiDARGen按“原生3D/4D表示”统一梳理,给出五类评测指标和开源工具,让闭环仿真、感知-决策-生成一体化真正“有图可循”。
视频生成卷到 2D 天花板”的热度刚降温,李飞飞 World Labs 又带着 Marble 平台把舆论拉进 3D 世界。一周过去,当时刷屏的 Demo 已经沉淀为 arXiv 上 90 页、300 篇文献的综述——《3D and 4D World Modeling: A Survey》。
我们把时间线拉回来看:Marble 的“空间智能”究竟只是炫酷 GIF,还是自动驾驶、机器人、XR 与数字孪生的下一座基建?

今天分享一篇最新3D、4D世界模型技术最新全面系统性综述

- 2D 视频生成卷到头了,但真实物理世界天生是 3D+时间维度的。
- 自动驾驶、机器人、XR、数字孪生都需要几何一致、可交互、长时序的时空场景。
- 缺乏统一术语 & 碎片化严重:同样叫“world model”,有人指视频生成,有人指预测器,有人指闭环仿真器。
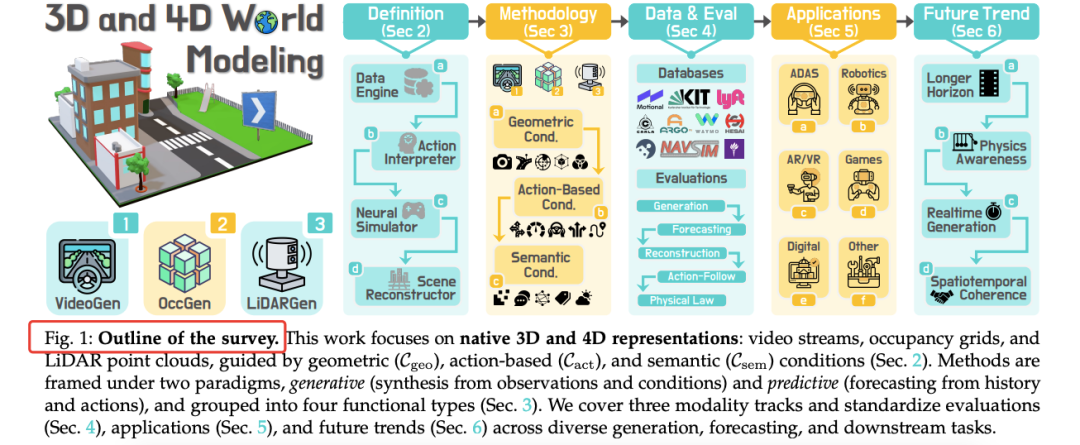
综述整体框架
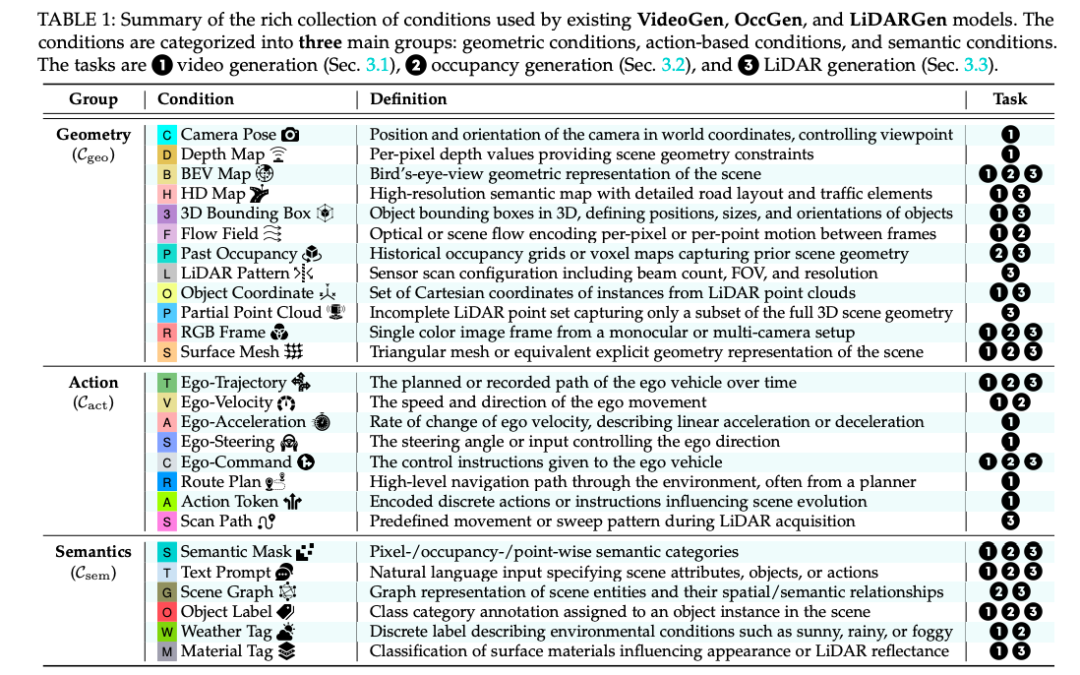
- 本综述首次系统梳理 3D/4D 原生表示(RGB-D、Occupancy Grid、LiDAR Point Cloud)的世界模型,给出明确定义、分层分类法、数据集与评测指标,并开源持续维护。
01 分层分类法
3D/4D World Model = 在原生三维或四维表示上,生成(Generative)或预测(Predictive)几何合理、语义可控、时空一致的场景,以支持感知-决策-仿真全链路任务。
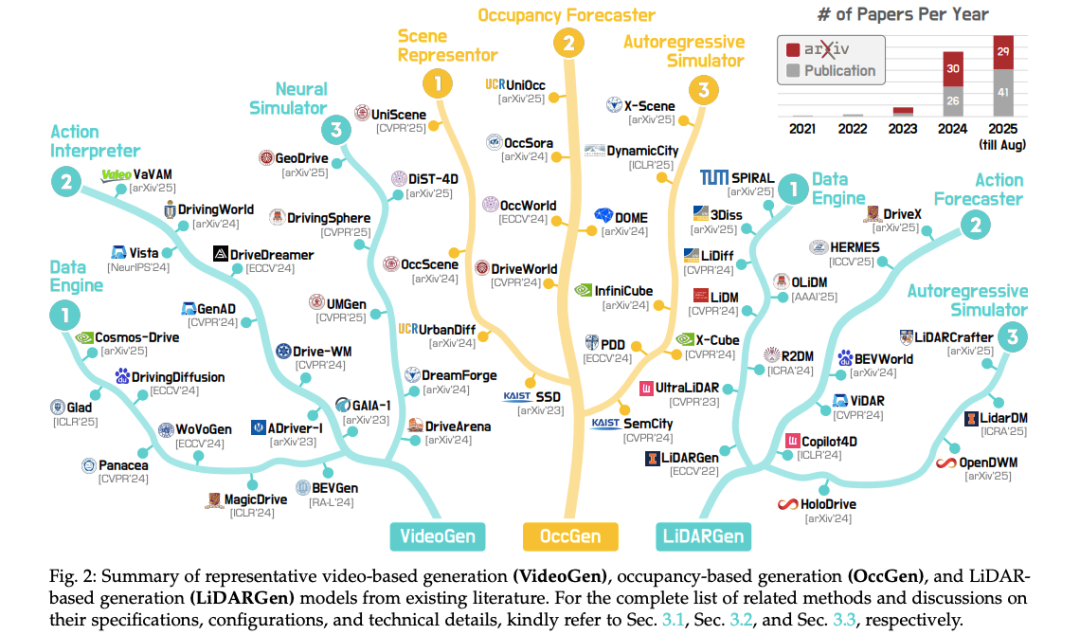
三模态 × 四功能全景图(来源:论文 Figure 2)

02 各模态深度拆解2.1 VideoGen——把视频生成做成“时空编剧”

典型方法时间线(2021-2025)VideoGen 代表方法逐年汇总(来源:论文 Figure 3)
- Data Engine:MagicDrive、DiVE、DreamForge 等用 BEV/HD-Map 做几何约束,生成多视角长视频,解决长尾数据稀缺。
- Action Interpreter:GAIA-1/2、DriveWM、Vista 把“转向+速度”映射到未来帧,实现动作-结果可微分仿真。
- Neural Simulator:DriveArena、DreamForge 在闭环里交替“生成-决策”,替代传统游戏引擎渲染管线。
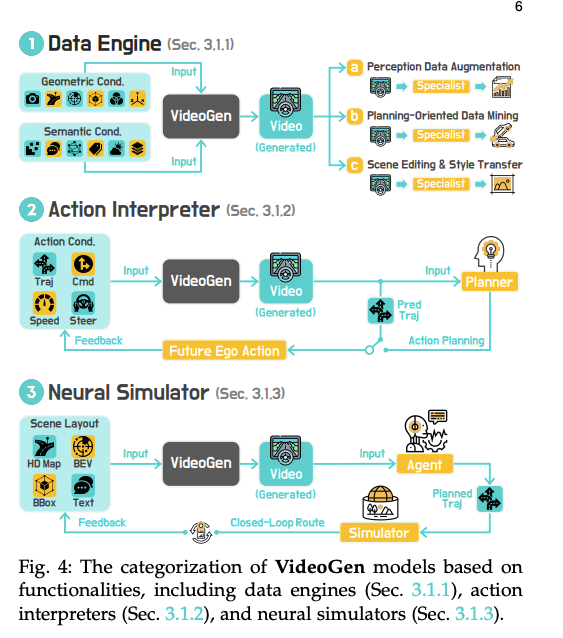
VideoGen模型分类
关键挑战:长时序一致性(InfinityDrive)、多视角几何对齐(DiST-4D)、稀疏标注下的可控性(MaskGWM)。
2.2 OccGen——把世界变成“可交互的乐高”
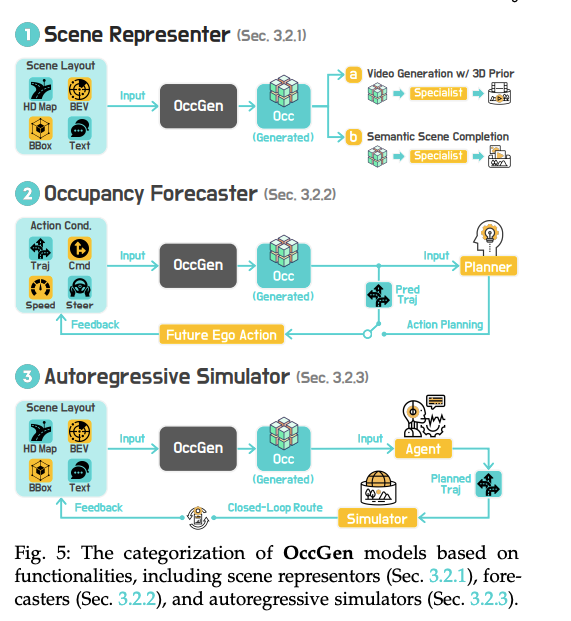
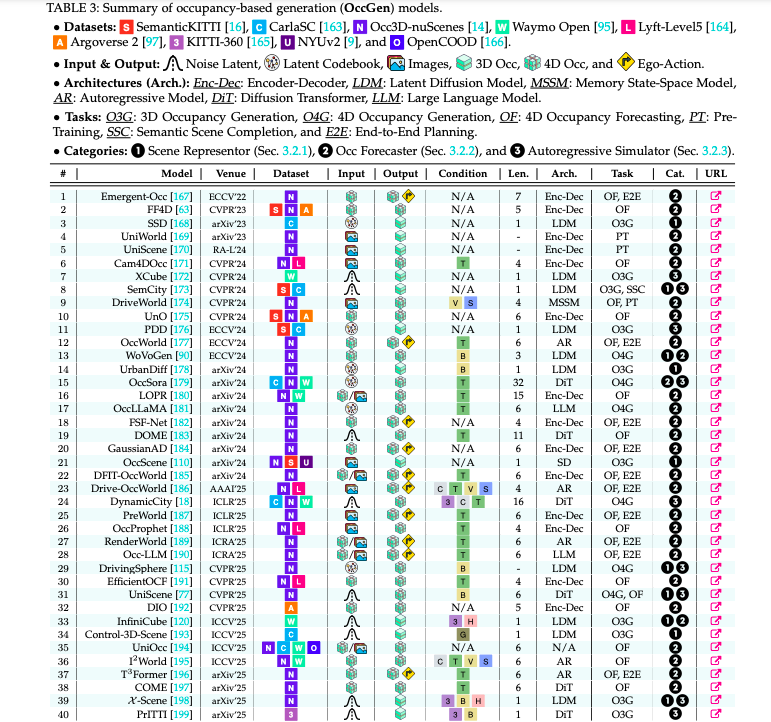
OccGen 三功能分类(来源:论文 Figure 5)
- Scene Representor:SSD、SemCity 用扩散模型把稀疏 occupancy 补全为稠密语义体素,提升感知鲁棒性。
- Occupancy Forecaster:OccWorld、OccSora、T3Former 以 ego-action 为条件,预测未来 3s 的 4D occupancy,误差 < 30 cm。
- Autoregressive Simulator:DynamicCity、UniScene 支持“布局→时序体素→多传感数据”一条龙,实现可编辑的大型开放世界。
OccGen
关键挑战:细粒度动态物体(自行车、行人)补全、长时序误差累积、与下游规划器端到端联合训练。
2.3 LiDARGen——直接“点云编剧”
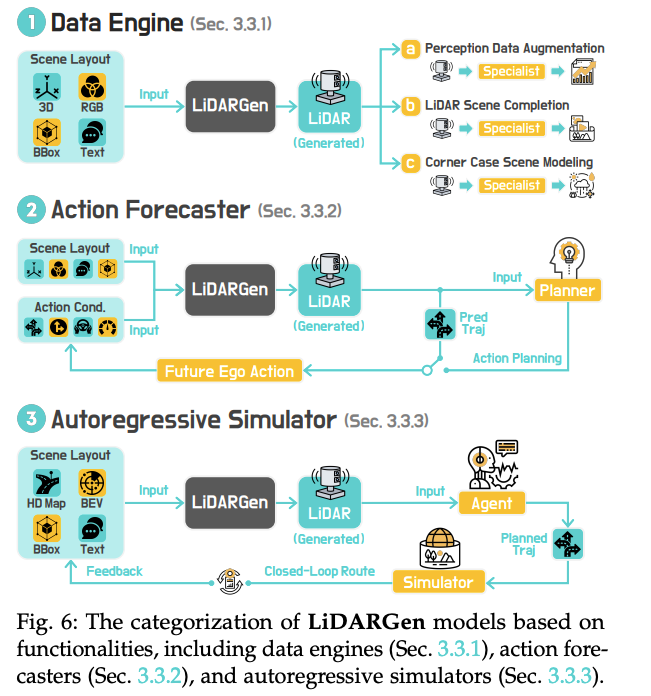
LiDARGen 三功能分类(来源:论文 Figure 6)
- Data Engine:R2DM、LiDM、WeatherGen 用扩散/流匹配生成逼真点云,解决恶劣天气、稀有场景数据不足。
- Action Forecaster:Copilot4D、ViDAR 把“历史点云 + 未来轨迹”映射到未来点云,实现点云级别的动作推演。
- Autoregressive Simulator:LiDARCrafter、LidarDM 支持4D 点云序列闭环生成,可直接喂给下游检测/规划网络做训练。
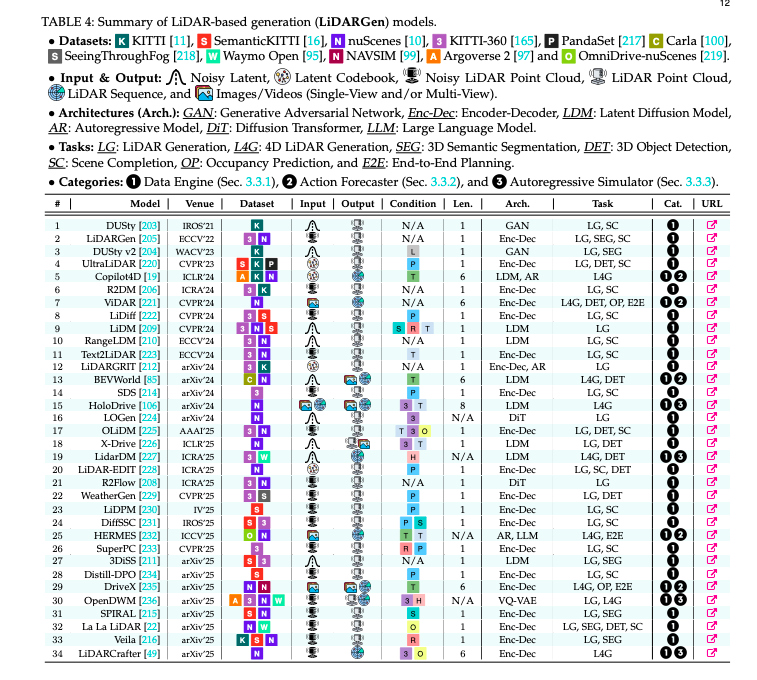
关键挑战:保持扫描线结构、处理点云稀疏性、跨模态与图像语义对齐。
03 统一评测体系——不再“各玩各的”
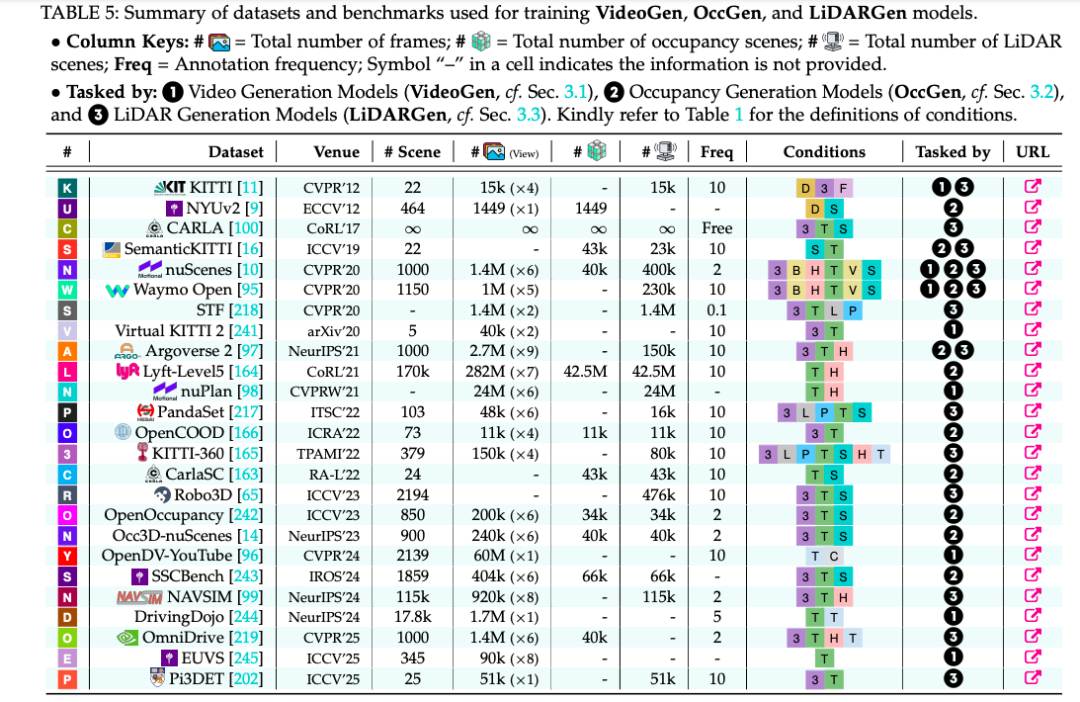
五类评测指标总表(来源:论文 Table 14)
- Generation Quality:FID/FVD、FRD/FPD、Consistency、Controllability、Human Preference
- Forecasting Quality:IoU@1s/2s/3s、Chamfer Distance、Temporal Consistency
- Planning-Centric:Open-Loop L2/碰撞率、Closed-Loop PDMS/ADS
- Reconstruction Quality:PSNR/SSIM/LPIPS、Novel-View IoU
- Downstream:3D Det mAP、BEV 分割 mIoU、VQA Top-1
https://arxiv.org/pdf/2509.07996
3D and 4D World Modeling: A Survey
https://github.com/worldbench/survey....
#GPT-5首次通过「哥德尔测试」
破解三大数学猜想
GPT-5在“哥德尔测试”中零提示破解三大开放数学猜想,其中一道还推翻原有结论,证明1−e^{−γ}近似比,展现组合优化领域的原创推理力,也暴露整合多证明路径的短板。
AI迎来历史性一刻!
GPT-5成功破解三大猜想,通过了「哥德尔测试」。
OpenAI科学家Sebastien Bubeck惊叹地表示,这类开放性问题,顶尖博士生往往耗费数日才能解决。
不同以往,这项由海法大学和思科主导的研究,首次让AI直面「开放性数学猜想」的挑战。
论文地址:https://arxiv.org/pdf/2509.18383
论文中,团队设计了五项「组合优化」领域的测试任务,每项任务提供1-2篇文献作为了解。
在三个相对简单的问题上,GPT-5给出了近乎完美的解法,证明了其强大的逻辑推理水平。
令人惊喜的是,在猜想二中,它不仅成功求解,还推导出与研究人员预期不同的有效解法,颠覆了原有猜想。
这一突破,标志着顶尖AI正从「学习数学」迈向「真正做数学」的关键跨越。
不难看出,AI正为数学发现做出实质性贡献,提前预演了2030年代科研范式的深远变革。
AI单挑「哥德尔测试」
远超陶哲轩想象
此前,陶哲轩曾分享了自己与OpenAI o1合作经验,生动地将其比作「指导一名平庸,但并非完全无能的研究生」。
在他看来,LLM虽能在大量提示后,逐步得出解决方案,但无法独立生成关键概念性想法。
不过,经过一两次迭代,结合工具,AI就能达到「合格研究生」的水平。
OpenAI和谷歌均宣称,自家前沿LLM无需外部工具,即可拿下IMO金牌。
但这个具有挑战性的问题,毕竟是为高中生设计的。
在最新论文中,研究焦点不同:让AI处理更高级的数学猜想,即「哥德尔测试」。
这些猜想要求的不只是解题能力,还需要整合背景知识和创新思维。
为此,研究人员从「组合数学」的子领域——子模最大化中挑选问题。这类问题具体、有明确动机,且控制在能展示数学推理范围内。
与陶哲轩实验不同,团队没有提供大量提示或指导。
论文中,他们精心设计了五大猜想。
只给每个问题一个最小化描述,外加上1-2篇参考文献。
难度设定为:优秀本科生、研究生,有望在一天内解决所有问题,同时确保大部分问题,存在明确猜想及已知解决路径。
GPT-5的任务是,基于有限输入,生成完整证明。
这模拟了真实研究场景:数学家往往从少量线索出发,独立探索。
在测试中,GPT-5表现既有亮点,也有短板,一起看看具体的解题能力。
GPT-5破解三大猜想
猜想一:「单调+非单调」的子模函数在凸多面体上取最大
这个要求好像是,让「两个互相掣肘的收益」加在一起最大化:
一部分收益G会越加东西越大(单调),另一部分 H 可能先涨后跌(非单调),而选择必须落在一个「不能超过上限」的凸集合里。
GPT-5做法是套用连续Frank-Wolfe思路,从零开始,每一步朝着「此刻最能涨分」的方向挪一小步,并使用「遮罩」保证不越界。
它把参考论文里「凹函数」的位置换成 H,推了个递推式,最后得到一个拆分保证——
至少拿到约63%的G(o),再加上37%的H(o)(若H也单调则也是63%),外加一个随步长参数ε线性衰减的小误差。
猜想二:p-system约束下的「双指标」算法
这题允许「价值几乎最优(1−ε)」,但在可行性上稍微超一点(放宽倍数g(ε)),目标是在越广泛的p-system约束下把g(ε)压到尽量小。
GPT-5提了个朴素而有效的流程,每一轮都在当前解的基础上,再做一次「在约束里尽可能有价值」的贪心选集(greedy),最后把若干轮的结果并起来。
证明关键是:每一轮都能把「距离最优」的差距按p/(p+1)的比例缩小,多滚几轮差距就指数式消退,于是只要做 ℓ≈ln(1/ε)/ln((p+1)/p)轮,就能把价值推到1−ε。
这也意味着,放宽倍数 g_p(ε)=⌈ln(1/ε)/ln((p+1)/p)⌉。
部分解题过程如下:
令人意想不到的是,猜想二中,GPT-5甚至推导出不同的近似保证,经核查后推翻原有猜想,并提供了有效解。
猜想三:γ-弱DR子模+凸约束的最大化
这个猜想把「边际收益递减」的连续版放宽为一个强度参数 γ(γ=1即标准情形;γ越小,递减越弱)。
GPT-5还是用Frank-Wolfe:步步解一个「沿梯度的线性子问题」,用小步长前进,并靠平滑性控制离散化误差。
核心一步是把经典证明中的关键不等式按γ缩放,于是把著名的1−1/e近似比提升为更一般的1−e^{−γ},再加上一个可调的L/(2K)级别误差项(K为迭代轮数)。
在研究人员看来,结论与推理主体靠谱。
只是GPT-5多假设了「向下封闭」这种其实用不上的条件、以及对「步长总和=1」的细节有点不一致。
可以看出,如果题目有明确的、单一的推理路径,GPT-5表现不错——五道题里有三道能给出几乎正确的证明。
一旦需要把不同证明结合起来,比如4和5,GPT-5就搞不定了。
猜想五中,GPT-5倒是识别出了和作者设想一样的算法,但分析得不对。
他们后来复盘发现,这个证明其实有可能做出来,只是难度比预想的高。比起早期模型,GPT-5在组合优化这种专业领域里,数学能力明显进步,偶尔还会冒出一点小创新。
这恰恰说明了,它现在还缺乏「整合性推理」能力,这是个主要短板。
作者介绍
Moran Feldman
Moran Feldman是海法大学计算机科学系的教授。
在此之前,他曾担任以色列开放大学的教职,并在洛桑联邦理工学院(EPFL)担任博士后研究员,师从Ola Svensson教授。
Amin Karbasi
Amin Karbasi思科基金会AI负责人,曾任Robust Intelligence首席科学家,耶鲁大学教授,谷歌工程师。
参考资料:
https://arxiv.org/abs/2509.18383 https://x.com/tunedgradient/status/1970955153361850606
....
#AI视频进入蒸汽机时代
AI 视频生成行业天花板再次被拉高。
百度杀入 AI 视频生成赛道后,就一直加班加点卷个不停。
7 月初,百度第一次正式官宣蒸汽机 1.0 模型,以极致指令遵循能力惊艳亮相;8 月底,百度又发布全球首个中文音视频一体化模型百度蒸汽机 2.0,实现生成视频中人物口型、表情、动作的毫秒级同步。
而现在,距离上次发布仅短短一个月,百度蒸汽机 2.0 又迎来重磅升级,推出了行业首个通用 AI 长视频生成功能。
此次升级,百度蒸汽机不仅突破了 5 秒和 10 秒的生成时长限制,理论上可生成任意长度的长视频,还引入交互式需求表达功能,允许在生成过程中实时更新提示词。这意味着创作者可以随时调整视频内容,创作体验更为灵活高效。
,时长00:20
长视频生成对 AI 模型提出了更高要求,模型需要具备对时间、空间的深度理解能力,同时要能精确控制信息密度和视觉连贯性,这一直是该领域的技术难点。
为延长视频时长,业内普遍采用「首尾帧续写」技术,或者视频延长的简单续写能力,虽然能勉强填补时长空白,但容易导致视频缺乏连贯性,画质和细节呈现不稳定,难以承载复杂的创作需求。同时首尾帧续写需要用户每个镜头需要上传图片以及提示词,一个镜头普遍 1-6 秒,生成几十秒成片可能需要 10 组以上图片和提示词描述,操作门槛非常高,且很难实现无限时生成。
与这一浅层技术方案不同,百度蒸汽机采用流式生成技术,用户只需输入图像和提示词,就能生成任意时长的视频,并可以在生成过程中随时调整提示词,实时续写内容或指定任意帧继续生成,用户无需复杂操作,只需要一张图 + 提示词,即可完成无限时视频生成。如果对于前面的内容不满意,可以马上暂停调整,不需要完整推理过程结束,区别于行业其他长视频技术能力,百度蒸汽机的长视频生成能力不仅仅大幅度提升了创作效率,还可以实现灵活、流畅的创作体验。

首尾帧续写长视频能力

百度蒸汽机流式生成长视频能力
百度蒸汽机的这次迭代升级,不仅是技术上的一次革新,也在商业应用层面带来新的可能性。创作者可以在短时间内完成高质量长视频制作,降低了创作成本,提高内容产出效率,为各行业内容创作提供了新的工具和商业价值。
在下面这段蒸汽机长视频生成的视频中,小鸭子划水、上岸等动作连贯流畅,没有出现卡顿或不自然的现象,水面的涟漪、小鸭子的羽毛等细节也都处理得细腻逼真。
,时长00:17
提示词:小鸭子在水中嬉戏,有几只喝水,有几只划水,接下来排着队往前游,游到了岸边,拍打着小翅膀,往前边的草地上走去。
再比如,蒸汽机长视频模型还成功生成了一段西部牛仔风格视频,效果堪比电影大片。
该模型能够精准执行复杂的镜头运动与人物动作,在提示词的指引下,以一镜到底的方式呈现出牛仔走向马车、推门而入等场景转换。
镜头跟随、人物动作以及视角切换的衔接都很丝滑,尤其是在人物向前走和镜头右摇的场景中,模型能够精确控制镜头的角度与人物的位置变化,保持画面的自然过渡。
,时长00:20
提示词:1-5s 镜头跟随,牛仔走向右方马车。6-10s 人物向前走,镜头跟随。11-15s 人物向前走,镜头跟随,右摇 16-20s 镜头跟随,牛仔推开门进去。
在另一段长视频中,蒸汽机 2.0 真实还原了水流的动态变化以及小纸船在水面上漂动的轨迹,画面没有任何破绽或失真的情况,细节把控也很到位。
,时长00:26
提示词:小纸船在小河里漂流。
本次百度蒸汽机还发布了首尾帧功能,支持用户提供首尾帧2张图片和提示词可完成图片的理解和5S视频生成,为创作者提供更便利的视频片段生成能力。
,时长00:05
提示词:黄色折纸在工作台上逐步折叠,变形为彩色折纸猴,定格动画逐帧展现折纸过程,固定镜头。
我们只需上传首尾帧图片并输入提示词,蒸汽机 2.0 便能「脑补」出中间的剧情,实现完整的画面衔接。
比如一段电影风格的镜头中,平静的水面突然冒出三个全副武装、手持冲锋枪的士兵,生成的画面几乎可以以假乱真:
,时长00:05
提示词:固定镜头,平静的水面荡起波纹,三个士兵慢慢露出水面,他警惕的看着四周。
还有这个动漫风格的镜头,即使二次元小姐姐转个圈也能保持前后人物一致性,角色面部不会崩坏:
,时长00:05
提示词:镜头环绕着人物
首尾帧功能特别适用于延时摄影。蒸汽机生成了一段树木从秋季黄叶到冬季积雪的自然变化,季节过渡平滑自然,树叶飘落与雪花覆盖的细节也处理得很细腻。
,时长00:05
提示词:固定镜头大延时摄影,天⽓变化到冬天,背景云雾变化。
在商业化场景中,百度蒸汽机还能制作各类广告大片。在下面的案例中,只见镜头慢慢拉远,光泽感十足的耳机被拿在手中,流线型的反射效果显得极具质感,生成的手部非常自然,手指与物体的衔接部分也毫无违和感。
,时长00:05
提示词:耳机合上盖子,伸出一只手拿着耳机。
此外,百度蒸汽机在 8 月还率先推出「多人对话音视频一体化生成」能力,也是全球首个中文音视频一体化生成模型,该模型基于多模态信息的精准同步与自然交互,支持多角色自然对话,并保持高画质输出、大师级运镜。依托海量中文语料深度训练,中文语音细节还原度超 98%。
,时长01:03
现在,所有用户都可以通过百度搜索、百度 APP 或访问「绘想」平台进行体验。
体验链接:https://huixiang.baidu.com
可交互长视频生成的难点在哪?
现阶段,AI 视频生成虽然发展迅猛,目前行业内视频生成均集中在 5s/10s,且由于视频生成多采用基于 transformer 的扩散模型,在生成时长和实时性方面仍然存在很大的局限(生成时间长,且生成成本随生成时长呈平长级膨胀,不支持实时生成也无法交互)。较短的视频在应用上主要在工具层面,集中在视频片段、视频素材制作上,而互动视频、直播场景对视频时长和实时性都提出了更高的要求。同时,可交互的长视频生成技术可能重塑人类与媒介的互动方式,从「被动消费」转向「共同创作」,甚至催生全新的艺术形式与商业模式。
挑战 1 :时长
长视频生成中存在长上下文记忆难题,模型需在长时间范围内有效保留和检索关键事件,同时避免信息崩溃或漂移。
遗忘的问题:模型在生成长视频时,难以长期记忆早期帧的内容,导致时间维度上存在不一致
漂移的问题:生成过程中误差逐帧累积,导致生成的视觉质量逐渐下降。随着生成时长的增加,简单续写的方式,累积误差问题逐渐加剧,生成视频质量不断衰减,主体一致性逐渐下降。
挑战 2 :成本
由于视频生成模型中 Transformer 的二次复杂度,导致计算成本随着视频生成时长呈平方级增长。直接训练或推理更长视频,对 GPU 显存和计算效率提出更高要求,成本膨胀严重。
蒸汽机的解法与思考:
从分治到全局,引入自回归扩散模型
结合自回归长序列能力和扩散一致性强的优点
1.引入长时间一致性建模技术,解决长的问题:连续性 + 一致性
- 从全局整体生成到局部生成
动态缓冲区管理:通过「移动缓冲区」机制实时管理多帧画面,允许模型同时处理模糊草图、半完成帧与高精度画面,实现「边生成边调整」的实时交互。
- 阶梯独立噪声构造
独立噪声:基于时间步采样,为视频扩散模型的每一帧添加不同强度的噪声。根据噪声调度器曲线,每一个预测 chunk 被分配不同的噪声级别(与推理期间使用的噪声调度保持一致)
2.引入历史参考帧,保障片段生成与前序内容的连续性,让动作像「接力赛」一样流畅
- 引入 History 序列的训练
「零」噪声片引入:Diffusion Forcing 给了我们启发,基于 noise as masking 的思路。训练过程中可直接将历史参考帧引入与生成目标帧一起训练,提升生成的连续性。

- History 增强策略,历史帧越来越多,如何选择好的是核心优化点
多样性与鲁棒性:进行历史帧的概率扰动,提升模型的自我纠错能力,缓解自回归模型的累积误差问题。
历史帧压缩:a) 按时间临近性、帧重要度进行采样,提升全局 history 对当前视频生成的有效控制。b) 注意力门控机制:模型根据当前帧内容动态选择相关历史帧进行参考,避免无关信息的干扰,提升记忆效率。

- 训练中引入指导帧,引导模型不跑偏,缓解视频遗忘的问题
抗偏移的方法:在生成中同时生成首尾的部分帧,后续一起用来预测后续帧,逐步往后生成。
以上技术的突破让蒸汽机长视频生成能力变得更大,正如百度商业体系商业研发总经理刘林所表示的:长时一致性和实时性问题的解决,使得用户可以随时进行交互,并且在交互过程中,用户可以不断调整输入 prompt,直到生成自己满意的视频为止。
在中文场景适配层面,如前文所述,百度蒸汽机 2.0 在语音还原度上超过 98%,这对用户而言意味着可以获得更自然、更沉浸的交互体验。无论是在长视频配音、虚拟角色对白,还是个性化讲解,用户都能听到几乎与真人无异的中文表达。同时,高精度的语音还原也让情绪(如喜悦、惊讶)传递更加细腻。对于内容创作者而言,这不仅降低了后期配音和剪辑的门槛,还大幅提升了成品的质量与效率。
值得一提的是,百度蒸汽机 2.0 在画质和运镜上也不输专业团队。通过多条件协同建模,端到端人物生成,以及百万级专业运镜数据微调,从而实现电影级画质、大师级复杂运镜。这也意味着过去需要庞大团队与昂贵设备才能实现的镜头效果,如今只需一段提示即可完成。毫不夸张地说,百度蒸汽机 2.0 让人人都能拍电影成为可能。
可以看出,百度蒸汽机 2.0 此次升级,并不是单点突破,而是在多个维度优化与创新的结果,它不仅解决了传统视频生成中短时长、不连贯、缺乏叙事的痛点,还将专业团队级别的影像表现力带到普通创作者手中。
结语
前段时间,香港老牌电视台 TVB 掀起了一场「AI 风暴」。
他们推出了香港电视界首部全 AI 生成的青春爱情短剧《在我心中,你是独一无二》,从男女主角到剧情,再到场景、配音,100% 由 AI 生成,这直接让制作成本节省了约 98%,相当于节省了近 5.65 亿港元的开支。由此可见,AI 技术在影视制作中有着巨大潜力和经济价值。
百度蒸汽机长视频能力得升级推出,则进一步推动了这一趋势。
作为行业首个通用 AI 长视频生成模型,蒸汽机打破了时长限制,实现了任意时长的长视频生成。这种跨越式提升,使得 AI 视频生成不再只是炫技式的片段演示,而是真正具备了内容生产力,既能满足广告、影视预演等专业场景的需求,也能为大众创作者释放出前所未有的创作自由度。
....
#Generalizable Geometric Image Caption Synthesis
给几何图片写标题就能让AI更聪明,UIUC发布高质量可泛化几何数据集
随着多模态大语言模型(MLLMs)在视觉问答、图像描述等任务中的广泛应用,其推理能力尤其是数学几何问题的解决能力,逐渐成为研究热点。
然而,现有方法大多依赖模板生成图像 - 文本对,泛化能力有限,且视觉与文本信息之间存在严重不对齐问题,制约了模型在复杂几何推理任务上的表现。

来自 UIUC 的作者团队的研究提出了一种基于强化学习与可验证奖励 RLVR 数据生成与优化框架 ——Geo-Image-Textualization,并发布了首个完全对齐的高质量几何图像 - 文本数据集 GeoReasoning-10K,包含 1 万对精心构建的图像与描述。
并且,为了促进社区发展,作者团队已公开 GeoReasoning-10K 数据集及相关代码。
- 数据集地址:https://huggingface.co/datasets/ScaleMath/GeoReasoning
- 代码地址:https://github.com/MachinePhoenix/GeoReasoning
- 论文链接:https://arxiv.org/abs/2509.15217
- 论文标题:Generalizable Geometric Image Caption Synthesis
数据集与方法介绍
该框架的核心创新包括:
- 强泛化性:训练后的模型不仅在几何任务上表现优异,还能泛化至算术、代数、数值推理等非几何任务,甚至处理非几何图像输入。
- 高质量:经过 GeoReasoning 训练过的模型,在下游任务上性能超过其他同类型数据集,并且具有良好的缩放性质。
- 可扩展性:生成的样本由模板集中的字句组合而成,可以组合出任意复杂度的几何题。
图像 - 标题 - 问题 / 答案的生成流程如下图所示:

生成的几何图示例如下:

训练流程和强化学习阶段的奖励函数如下:


实验结果
在权威数学推理基准 MathVista 和 MathVers 上与其他几何字幕标注数据集(如 AutoGeo、GeoPeP)和解题数据集(如 GeoGPT4, Geo170K)相比,GeoReasoning-10K 在相同数据量下均取得最优效果,展现出卓越的数据质量与扩展性:

左:MathVista;右:MathVerse
在 MMMU 测评基准上,使用 GeoReasoning-10K 微调后的 Gemma3-4B 模型显著提升多项能力:

MMMU 实验结果
最后展示 MathVista 中的一些具体样例:



以及 MMMU 的一些样例:



总结
在多模态大语言模型快速发展的今天,Geo-Image-Textualization 框架和 GeoReasoning-10K 数据集为解决几何推理瓶颈提供了全新思路。通过确保视觉和文本信息的完全对齐,本文的方法不仅提升了模型在几何问题上的表现,还实现了向更广泛数学领域的泛化。
正如实验结果所示,给几何图片写标题可以让 AI 变聪明,不仅能解决几何问题,还能增强其整体数学推理能力,为多模态 AI 在教育、科学计算等领域的应用铺平道路。
感谢作者团队的辛勤工作和开源贡献,期待更多研究者加入这一领域,共同推动多模态 AI 技术的边界不断扩展。
...
#高通祭出全球最快移动SoC!
卢伟冰携全球首发小米17Pro现身
今天上午,在古北水镇举办的 2025 骁龙峰会·中国会场,高通最新、最强、最快的移动旗舰 SoC 正式问世!

本代 SoC 被命名为「第五代骁龙 8 至尊版移动平台」(骁龙 8 Elite Gen 5),采用台积电 3nm(N3P)制程工艺,在性能、能效和终端 AI 能力方面较前代有了脱胎换骨的提升。
更具体地讲,第五代骁龙 8 至尊版的整体 SoC 性能提升了16%,SoC 整体续航延长高达 1.8 小时。

本代芯片的首发机型依然给了小米。小米集团合伙人、总裁卢伟冰现身活动现场并宣布,「今晚即将发布的全新小米 17 系列将全球首发第五代骁龙 8 至尊版」。

卢伟冰现场使用小米 17ro 的「妙享背屏」拍照。
另外,中兴、vivo、索尼、三星、ROG、红魔、REDMI、realme、POCO、OPPO、一加、努比亚、iQOO、荣耀等全球 OEM 厂商和智能手机品牌也将在各自的旗舰产品中搭载第五代骁龙 8 至尊版。
性能「狂战士」
高通旗舰 SoC 新王者登场
之所以能够成为最快、最强,第五代骁龙 8 至尊版在「CPU、GPU、NPU」等多个核心维度均实现了跨越式的突破。
在 CPU 方面,第五代骁龙 8 至尊版搭载自研的第三代 Oryon CPU,在架构上依旧采用 2 个超大核 + 6 个性能核的配置。
此次,CPU 超大核的最高主频达到了 4.6GHz,性能核的主频也达到了 3.62GHz,实现了同类产品中速度最快。

得益于架构上的进一步优化,第三代 Oryon CPU 单核性能提升 20%,多核性能提升 17%,响应速度提升 32%,能效提升了 35%。

性能全方位提升的同时,峰值功耗最多降低了 43%,实现真正意义上的「更强、更快、更省」,让旗舰设备同时保持顶级性能和更持久的稳定表现。

根据 Geekbench 6.4 的跑分成绩,第五代骁龙 8 至尊版的单核跑分超过了 3800,多核跑分超过了 12000,足可见性能之强悍。

图源:https://www.notebookcheck.net/
这些指标使第三代 Oryon CPU 成为全球最快的移动 CPU,具备了桌面级处理器性能和超高能效。无论多复杂的多任务处理、沉浸式游戏,还是 AI 推理与生产力应用,它都能以极低的功耗提供澎湃的性能输出。

在 GPU 方面,第五代骁龙 8 至尊版搭载全新架构的下一代 Adreno GPU,主频高达 1.2GHz,带来了前所未有的图形渲染能力。同时,它采用 Adreno 独立高速显存(HPM),开创性地引入了 18MB 独立高速显存。

相比前代,下一代 Adreno GPU 整体性能提升 23%,光线追踪性能提升 25%,能效提升 20%,大幅增强了图形处理效率与能效表现。
这意味着,它不仅能轻松应对最复杂的 3D 场景与高帧率游戏,还能在光影、反射、全局光照等特效中呈现更真实、更细腻的画面。
同时,得益于显著提升的能效表现,设备在长时间运行大型游戏或高强度图形任务时依旧能够保持流畅稳定,并有效控制发热和功耗,为玩家带来持久的沉浸式体验。

终端侧 AI 核心引擎
全新 NPU「鲨疯了」
如今,旗舰 SoC 的 NPU(神经网络处理单元)作为核心算力单元,是终端侧 AI 的关键赋能者。
在手机、PC、可穿戴设备等终端中,NPU 的加入让 AI 能够「本地运行」,实现实时响应和更好的隐私保护,不必完全依赖云端算力。
通过架构与指令集层面的优化,NPU 可以在并行计算、深度学习和自然语言处理等方面展现出前所未有的速度与效率。

此次,第五代骁龙 8 至尊版搭载的 Hexagon NPU 实现了 37% 的整体性能提升,每瓦特性能提升达到了 16%,带来了更强大的 AI 算力支持。

Hexagon NPU 的推理速度高达 220 Tokens / 每秒,并支持高达 32K 2-bit 的超大上下文窗口,能够在终端侧高效运行复杂的大模型任务。
同时,首次引入对 INT2 与 FP8 等新精度格式的支持,保证高精度的同时显著降低能耗,实现性能与能效的双重飞跃。
此外,64-bit 内存虚拟化可以让系统突破传统的 32-bit 限制,支持更大规模的物理和虚拟内存寻址。对于需要加载庞大参数的 AI 大模型或复杂图形任务,可以避免因内存不足导致的性能瓶颈。
更重要的是,Hexagon NPU 首次具备终端侧 AI 持续学习的能力,能根据用户的使用习惯不断优化模型表现,支持更加个性化、智能化的交互体验。
无论是实时语音翻译、多模态内容生成,还是更自然的人机交互,本代 Hexagon NPU 都能提供前所未有的流畅与高效,成为移动端 AI 体验的核心引擎。
其他能力提升
除了更强大的 CPU、GPU 与 NPU,第五代骁龙 8 至尊版在影像、音频和 5G 通信等其他维度也实现了巨大飞跃。
在影像方面,第五代骁龙 8 至尊版首次引入 20-bit ISP,动态范围提升四倍,能够捕捉更多亮部与暗部细节,让画面层次更丰富。

第五代骁龙 8 至尊版还引入了全球首个硬件 APU 编解码器,在视频处理上实现了跨代革新,不仅大幅提升影像数据的运算效率,更能在拍摄、编码和播放环节中实现更低功耗与更高画质。

此外,全新的 Dragon Fusion 超域融合视频功能,在多帧合成与低光处理上表现更加出色。结合 Night Vision 3.0 技术,让拍摄在暗光和复杂环境下依旧清晰细腻。无论是夜景拍摄还是逆光环境,都能呈现清晰锐利的画面效果。
在音频方面,第五代骁龙 8 至尊版搭载了骁龙音频感知(Snapdragon Audio Sense),支持专业级录音、降风噪和音频变焦功能,提供了清晰、高品质的音频体验,在录音、直播等多种场景更加得心应手。

在连接性能上,第五代骁龙 8 至尊版搭载了全球最先进的 AI 赋能 5G 调制解调器,融合 FastConnect AI 优化的邻近感知技术,带来更加智能、稳定且无缝的网络体验。

它支持高达 12.5Gbps 的 5G 峰值下载速度,在移动网络环境下也能实现极速传输与超清内容流畅播放。同时,整体 AI 推理速度提升 30%,赋予 5G 调制解调器更强的「自感知」能力,可根据使用场景实时优化网络连接,在高负载下依旧保持稳定。
在 Wi-Fi 方面,得益于 50% 的 AI 能力增强,无线网络的稳定性与传输效率进一步提升,游戏时延降低达 50%,为电竞级体验提供坚实保障。
正如高通高级副总裁兼手机业务总经理 Chris Patrick 所言:「凭借第五代骁龙 8 至尊版,用户真正成为移动体验的核心。该平台赋能的个性化 AI 智能体能够看你所看、听你所听,实时与用户同步思考。第五代骁龙 8 至尊版将突破个人 AI 的边界,让用户现在就能体验到的移动技术的未来。」

...
#ChatGPT新功能Pulse
GPT-5主动给你推消息,大家玩得停不下来
网友:ChatGPT 最大的一次尝试。
这是 OpenAI CEO 山姆・奥特曼迄今为止最喜欢的 ChatGPT 功能。

本周五凌晨,OpenAI 宣布推出 ChatGPT 新功能「Pulse」的预览版,首先向 Pro 订阅用户开放。
ChatGPT 现在会每天晚上主动进行研究,根据你每天的聊天记录、反馈以及日历等关联应用提供个性化更新。每天清晨,你都会收到一组自定义生成的,可能感兴趣的内容,出现在手机 App 上。
这是一个基于智能体(Agent)的新功能,奥特曼表示:「想象一下把 ChatGPT 视为一个超级私人助理:有时你会询问当前需要的东西,但如果你分享一般偏好,它会主动为你做好工作。这会是我想象 ChatGPT 的未来:从完全被动转变为主动,提供高度个性化服务。」
除了 AI 的全自动总结外,你也可以管理 ChatGPT 的研究内容,告知它哪些内容有用,哪些内容无用。研究结果以主题可视化卡片的形式呈现在 Pulse 中,供人们快速浏览或打开查看更多详情,每天从一组全新且针对性的更新开始。
OpenAI 表示,这是 ChatGPT 走向实用化的第一步,它将主动为人们提供所需,让你重返生活,Pulse 的下一步目标是推广至 Plus 级别的用户。

更具体来看,ChatGPT 现在可以代表你进行异步搜索。每晚,它会综合你的记忆、聊天记录和直接反馈了解最相关的内容,然后在第二天提供个性化、有针对性的更新。这些更新可能包括你经常讨论的话题的后续内容、当晚在家快速健康晚餐的创意,或者诸如铁人三项训练等长期目标的后续步骤。
你可以链接自己的 Gmail 和 Google 日历,以便提供更多上下文信息,从而提供更相关的建议。连接日历后,ChatGPT 可能会起草示例会议议程、提醒你购买生日礼物,或推荐即将到来的旅行的餐厅。这些集成功能默认处于关闭状态,你可以随时在设置中开启或关闭。
当然,Pulse 中显示的主题也经过安全检查,以避免显示有害内容。

除了总结之外,用户还可以请求 ChatGPT 每天搜索互联网上的内容。点击「精选」即可请求你希望在未来版本中看到的内容 —— 例如请求周五本地活动综述、学习新技能的技巧,或者请求「明天关注职业网球动态」之类的具体内容。有 OpenAI 工程师表示,他会通过 Pulse 跟踪最新的 AI 领域论文。
你还可以通过点赞或踩赞来快速提供反馈,并轻松查看或删除反馈历史记录。随着时间的推移,人类的指导将使 Pulse 更加个性化和实用。

该功能刚刚推出,已有大量用户收到了推送,网上充斥着各式各样的使用体会。有不少人认为挺有用的,发现其中呈现的内容不仅是宽泛的主题,而是非常具体,有关之前你和 ChatGPT 聊过的具体话题。
Pulse 的推送包含数个主题卡片,有 AI 生成的配图,然后在你滚动浏览时,它会继续提供其他功能的指引,比如优化推送、发送电子邮件通知或访问你的电子邮件和日历。感觉就像你能想象到的最个性化的新闻推送。
这也会让你更想要把更多的信息、上下文和应用程序连接都放到 ChatGPT 里,以获得更好的每日推送。

显然,这也是 OpenAI 开放 Pulse 功能想要实现的效果,主动的 AI 可能会影响人们获取新闻和社交媒体消费的习惯。而且这也为 OpenAI 提供了一个非常清晰的平台,可以在未来插入广告,甚至可能围绕它构建社交网络。
但至少目前为止,它还是专注于提供有用的信息。有人发现这个 Pulse 是真的实诚,一会向你推荐 Claude,一会让你使用 Gemini。

OpenAI 的工程师们表示,ChatGPT 的下一步目标是做「更多有意义的事」,从 Pulse 开始,ChatGPT 会主动帮你实现目标,这个新功能只是个开始。
参考内容:
https://openai.com/index/introducing-chatgpt-pulse/
https://x.com/sama/status/1971297661748953263
....
#从现有主流 RL 库来聊聊RL Infra架构演进
在大模型的发展进程中,强化学习(RL)已从一项辅助技术,跃升为驱动模型能力跃迁的核心动力。当前,RL发展正经历一场关键范式转移:从单轮、静态任务(如独立的数学题求解等),全面转向多轮、交互式智能体训练。这一新范式的目标,是让大模型真正成为能在复杂、动态环境中,通过多步观察、思考、行动与反馈来完成任务的Agent。这不仅是技术上的巨大挑战,更是通往AGI的关键一步。
总而言之,强化学习正在重塑大模型的能力边界。它不仅是弥补数据瓶颈的利器,更是构建下一代通用智能体的核心方法论。而支撑这一切的,正是背后日益成熟和强大的RL基础设施生态。
本文结合A Survey of Reinforcement Learning for Large Reasoning Models和Anyscale blog对现有主流RL库进行简单整理。
1. 现代RL基础设施的架构范式
现代RL基础设施的核心通常围绕以下两个基本组件展开。
- • Generator:负责让LLM与环境交互,生成Trajectory并计算奖励。这是计算开销特别大的部分,其设计灵活性(如是否支持自定义采样、分支搜索)和环境抽象能力至关重要。
- • Trainer:负责根据生成阶段收集的轨迹数据,使用优化算法(主要是PPO和GRPO等)更新模型参数。其性能取决于所采用的分布式训练后端(如FSDP, DeepSpeed, Megatron)。
上述的生成器-训练器架构,配合以Ray为代表的分布式协调层,构成了大模型强化学习系统的“黄金标准”。RL 训练计算成本极高,涉及上述大规模并行推理和参数更新。一个优秀的 RL 库必须能高效、稳定、可扩展地协调这两个阶段。
本文梳理了支撑大规模RL for LRM(Large Reasoning Models)训练的软件栈和工程框架,并将RL基础设施分为两大类:Primary Development和 Secondary Development
2. Primary Development
这些是构建RL训练管线的“基石”框架。它们通常不直接提供完整的端到端解决方案,而是提供核心的算法实现和与底层训练/推理引擎的集成,供研究者和工程师在此基础上进行定制化开发。
2.1. TRL (Transformer Reinforcement Learning)
定位:Hugging Face官方推出的、最“开箱即用”的RL框架。它更像是一个“训练器集合”,而非一个复杂的分布式系统。
https://github.com/huggingface/trl
github.com/huggingface/trl核心能力:
- • 算法支持:SFT, PPO, DPO, GRPO, IPO, KTO, Online DPO, REINFORCE++ 等。
- • 集成:紧密集成 transformers 库,支持与 vLLM 的集成以加速Rollout。
- • 训练后端:依赖accelerate 库,支持 DDP, DeepSpeed ZeRO, FSDP。
- • 特点:API设计简洁,文档丰富,非常适合快速原型验证和中小规模实验。但对于超大规模、异步、多智能体等复杂场景支持有限。但是不支持环境交互,并且生成与训练耦合紧。
2.2 OpenRLHF
定位:由OpenLLMAI,字节,网易等的一个联合团队开发,旨在提供一个高效、可扩展的RLHF和Agentic RL框架。
https://github.com/OpenRLHF/OpenRLHF
github.com/huggingface/trl核心能力:
- • 算法支持:PPO, GRPO, REINFORCE++, RLOO, DPO, IPO, KTO 等。
- • 架构:支持异步Pipeline RLHF和异步Agentic RL模式。后者通过Agent类API支持多轮对话。
- • 集成:深度集成 vLLM 用于高吞吐Rollout。
训练后端:基于 DeepSpeed ZeRO-3 + Auto Tensor Parallelism (AutoTP)。 - • 特点:代码结构清晰,是许多二次开发框架的基础。
2.3. veRL
定位:功能最全面、算法支持最广泛的框架之一,由字节Seed团队开发。
https://github.com/volcengine/verl
github.com/volcengine/verl核心能力:
- • 算法支持:极其丰富,包括 PPO, GRPO, GSPO, ReMax, REINFORCE++, RLOO, PRIME, DAPO, DrGRPO 等。
- • 架构:采用 HybridFlow 控制器,支持多轮训练和工具调用,目前生成与训练耦合,后续规划会支持异步解耦。
- • 集成:支持 vLLM 和 SGLang 等作为推理后端。
- • 训练后端:同时支持 FSDP/FSDP2和 Megatron-LM。
- • 奖励:支持模型奖励和函数/规则奖励(如数学/代码)。
- • 特点:追求“全能”,几乎涵盖了当前所有主流RL算法和应用场景。是进行前沿算法研究和复杂任务(如多模态、多智能体)实验的理想选择。相比 TRL/OpenRLHF等,配置更复杂
2.4. AReaL (Asynchronous Reinforcement Learning)
定位:蚂蚁开源,专为大规模、高吞吐的推理模型RL训练而设计,核心是完全异步架构。
https://github.com/inclusionAI/AReaL
github.com/inclusionAI/AReaL核心能力:
- • 架构:核心创新是完全异步设计。通过可中断的Rollout Worker、经验回放缓冲区和并行奖励服务,将生成与训练彻底解耦。
- • 集成:使用 SGLang等 进行Rollout,并使用Ray进行集群管理。
- • 训练后端:主要使用 PyTorch FSDP,也支持 Megatron。
- • 特点:为追求极致训练效率和可扩展性而生。其“轻量版” AReaL-lite 提供了更易用的API。
2.5. NeMo-RL (NVIDIA NeMo)
定位:NVIDIA官方推出的、面向生产的RL框架,集成在其庞大的NeMo生态系统中。
https://github.com/NVIDIA-NeMo/RL
github.com/NVIDIA-NeMo/RL核心能力:
- • 算法支持:SFT, DPO/RPO/IPO/REINFORCE, PPO, GRPO 等。
- • 架构:强调可扩展性和生产级编排,支持异步 Rollout,非Colocate放置等。
- • 训练后端:支持 Megatron-Core和DTensor (FSDP2)
- • 集成:支持使用 TensorRT-LLM 和 vLLM 进行rollout。
- • 特点:与NVIDIA硬件(GPU)和软件栈(CUDA, TensorRT)深度集成,提供了从RM训练到PPO的端到端Pipeline。设计优雅,接口定义清晰,性能和扩展性兼顾。
2.6. ROLL (Reinforcement Learning Optimization for Large-Scale Learning)
定位:阿里开源的,一个专注于大规模LLM RL的框架,同样强调异步和Agentic能力。
https://github.com/alibaba/ROLL
github.com/alibaba/ROLL核心能力:
- • 算法支持: 集成了 GRPO, PPO, REINFORCE++, TOPR, RAFT++, GSPO 等多种先进 RL 算法。
- • 架构: 采用基于 Ray 的多角色分布式设计,将策略生成、价值评估、奖励计算等任务解耦到独立的 Worker 角色中,实现灵活的资源调度、异步训练和复杂任务编排。
- • 集成: 深度集成 SGLang 和 vLLM 作为高性能推理后端,加速策略生成(Rollout)。
- • 训练后端: 主要基于 DeepSpeed (ZeRO) 和 Megatron-LM (5D 并行),未来将支持 FSDP2。
- • 奖励: 通过模块化的“奖励工作者”(RewardWorker)处理奖励计算,支持验证器、沙盒、LLM-as-judge 等多种奖励源,构建灵活的奖励路由机制。
- • 特点:面向多样化用户,高度可配置,接口丰富。
2.7. slime (SGLang-native post-training framework for RL scaling)
定位:清华,智谱开源的一个轻量级、专注于将 SGLang 与 Megatron 无缝连接的框架。
https://github.com/THUDM/slime核心能力:
- • 架构:Ray 进行资源管理和分布式任务调度,Rollout和训练解耦。
- • 训练后端:默认使用 Megatron-LM,也支持FSDP和xtuner。
- • 特点:通过自定义数据生成接口和服务端引擎(server-based engine),slime 可以实现任意的训练数据生成流程。支持异步训练和Agentic工作流。追求极简主义与高性能。
除论文中总结的,还有其他的强化学习库:
SkyRL (UC Berkeley)
https://github.com/NovaSky-AI/SkyRL
github.com/NovaSky-AI/SkyRL定位:追求设计灵活性和未来兼容性的新锐选择。支持同步/异步、Colocate/解耦、外部/内置推理,接口灵活,但生态未成熟,社区支持弱于 Verl/OpenRLH等
RAGEN(Northwestern University)
https://github.com/RAGEN-AI/RAGEN
github.com/RAGEN-AI/RAGEN定位:基于Verl构建,旨在为其添加更明确的环境接口和更好的智能体/多轮RL支持,生态尚在成长中。
Verifiers(William Brown等人):用于构建自定义多轮交互协议的强化学习环境框架,专为 LLM 的评估、训练和数据生成而设计。
定位:TRL 的升级版,基于 HF Trainer + 增加多轮环境交互,支持vLLM等。轻量灵活,适合快速原型 Agentic 实验。代码结构清晰,易修改
https://github.com/willccbb/verifiers
github.com/willccbb/verifiers3. Secondary Development
这些框架通常是基于上述主干框架(尤其是 veRL)构建的,针对特定的下游应用场景(如多模态、多智能体、GUI自动化)进行了深度定制和功能扩展。
3.1. Agentic RL (智能体强化学习)
背景:Agentic RL的核心挑战是模型需要与外部环境(如搜索引擎、Python解释器等)进行多轮、异步的交互。这要求框架支持动态工作流和状态管理。
框架:
- • verl-agent:基于
veRL 构建,专门为Agentic RL优化,支持异步Rollout和训练。
https://github.com/langfengQ/verl-agent
github.com/langfengQ/verl-agentagent-lightning:实现了训练与推理的解耦,更容易支持多智能体训练。
https://github.com/microsoft/agent-lightning
github.com/langfengQ/verl-agent关键技术:异步生成、经验回放、环境接口标准化。
3. 2. Multimodal RL (多模态强化学习)
背景:将RL应用于视觉-语言模型(VLM)。主要挑战在于数据处理(图像/视频编码)和损失函数设计(如何对齐文本和视觉信号)。
框架:
VLM-R1 和 EasyR1:基于 veRL 开发,用于训练视觉-语言推理模型。
https://github.com/om-ai-lab/VLM-R1
github.com/om-ai-lab/VLM-R1DanceGRPO:专门用于扩散模型(如文生图)的RL训练。
https://github.com/XueZeyue/DanceGRPO关键技术:多模态数据加载器、跨模态奖励设计(如CLIP分数)、针对扩散模型的特殊采样策略(ODE/SDE转换)。
3.3 Multi-Agent RL (多智能体强化学习)
背景:训练多个LLM智能体进行协作或竞争。挑战在于Credit Assignment和通信协调。
框架:
- •
MARTI:论文作者团队(清华C3I)提出的首个高性能、开源的LLM多智能体强化训练与推理框架。通过统一框架整合多智能体推理与强化学习,结合高性能引擎与灵活架构,为复杂协作任务提供高效、可扩展的解决方案。兼容单智能体RL框架(如 OpenRLHF、veRL),支持vLLM
https://github.com/TsinghuaC3I/MARTI
github.com/TsinghuaC3I/MARTIAgent-Lightning:其解耦设计也便于扩展到多智能体场景。
关键技术:集中训练分散执行(CTDE)、基于自然语言的信用分配(如LLaMAC)、多智能体策略优化(如MAGRPO)。
4. 总结与趋势
1.标准化与模块化:RL基础设施正从“手工作坊”走向“标准化流水线”。框架设计越来越模块化,将Rollout、Reward、Train等环节解耦,便于复用和扩展。比如,库不再绑定单一推理后端,而是支持 vLLM、SGLang等。
2.异步化是王道:为了应对Rollout和Train之间巨大的计算不对称性,异步架构(AReaL, OpenRLHF, slime等)已成为大规模RL的必备特性。
3.推理引擎至关重要:vLLM 和 SGLang 等高性能推理引擎的出现,极大地加速了Rollout过程,成为现代RL框架的标配。
4.从 RLHF 向 Agentic RL 演进:早期的库(如 TRL等)主要为单步任务设计。新一代库都内置了强大的环境抽象,以支持复杂的多步交互。
5.分布式训练框架选择:Megatron-LM 在超大规模模型训练中性能最佳,FSDP/FSDP2 因与 PyTorch 集成好而广受欢迎,DeepSpeed 则在内存优化上表现出色。成熟的库通常会支持多种方案
6.场景驱动的二次开发:通用框架(如 veRL, OpenRLHF)为生态奠定了基础,而针对特定场景(多模态、多智能体、GUI)的二次开发框架则在解决垂直领域的独特挑战。
7.Orchestrator重要性:由于 RL 涉及多个分布式组件(训练框架、推理框架、环境),使用 Ray等进行任务编排、资源管理和容错已成为行业共识。
总而言之,RL Infra是推动大型推理模型发展的“幕后英雄”。选择合适的框架,可以事半功倍,让研究者和工程师能够更专注于算法和数据本身,而非底层的工程细节。随着RL for LRM领域的持续火热,我们可以预见,这些基础设施将变得更加成熟、高效和易用。
....
#ROS-Cam(RGB-Only Supervised Camera Parameter Optimization in Dynamic Scenes)
运动遮挡都不怕,0先验、一段视频精准预测相机参数
论文一作李放,美国伊利诺伊大学香槟分校 (UIUC) 博二学生,研究方向为 4D 视觉定位、重建/新视角合成以及理解。第二作者为美国伊利诺伊大学香槟分校博四学生张昊。通讯作者是 Narendra Ahuja, 美国伊利诺伊大学香槟分校 Donald Biggar Willet Professor(Ming-hsuan Yang, Jia-bin Huang 博士导师)。这篇工作为作者在博一期间完成。
研究背景
在三维重建、NeRF 训练、视频生成等任务中,相机参数是不可或缺的先验信息。传统的 SfM/SLAM 方法(如 COLMAP)在静态场景下表现优异,但在存在人车运动、物体遮挡的动态场景中往往力不从心,并且依赖额外的运动掩码、深度或点云信息,使用门槛较高,而且效率低下。
纵使在 3R 时代下,三维与四维前馈模型可以高效产出相机相对位姿与点云结构,但 3R 模型本质上仍存在很多痛点。3R 模型对部署硬件容量需求大 (大 GPU), 对丰富高精度训练数据需求大,易发生场景漂移。而且目前基于 3R 模型的衍生品们仍无法做到同时解决这些问题。Per-scene optimization 的方法常常依赖多种监督和先验,同时优化效率低下。
这让作者重新思考:有没有一种方法可以从动态场景视频准确、高效、稳定地预测相机参数,不受前景运动物体的影响,且仅用一段 RGB 视频作为监督呢?
方法概览
为了实现这一目的,他们提出了 ROS-Cam(RGB-Only Supervised Camera Parameter Optimization in Dynamic Scenes),已被 NeurIPS 2025 接收为 Spotlight 论文。代码即将开源。
- 论文标题:RGB-Only Supervised Camera Parameter Optimization in Dynamic Scenes
- 论文链接: https://arxiv.org/abs/2509.15123
- Github链接:https://github.com/fangli333/ROS-Cam

从第一性原理出发,作者分析并将这个挑战拆解为几部分:
- 如何高效、准确地建立帧与帧之间的联系?
- 如何有效降低动态场景中移动点对视觉定位损失回归的影响?
- 能否做到仅用 RGB 视频进行监督(理论上所需的最少监督),且不加入其他任何先验,但依旧高效和准确?

基于上述思考,作者提出了一种仅 RGB 监督,高效,准确的动态场景相机参数估计的新方法。该方法涵盖了三个部分:
1)补丁式跟踪滤波器
他们发现现有方法都依赖预训练的密集预测模型(深度,光流,点跟踪)建立帧间联系作为伪监督。但这种密集预测模型经常由于准确性无法保证而引入噪声伪监督,影响模型损失回归。但是,准确且鲁棒的帧间关系的建立理论上并不需要密集预测,相反,密集预测除了引入噪声外还会增加模型处理数据的负担,降低模型优化效率。因此,他们提出补丁式跟踪滤波器,用来高效,准确的建立视频帧之间的铰链式稀疏点跟踪联系。

2)异常值感知联合优化
由于不使用任何运动先验,部分伪监督会包含移动点(outlier)轨迹,对模型损失回归造成负面影响。不同于与现有方法对每一帧的每一个像素赋予一个不确定性参数不同,作者认为每一条提取出的点跟踪轨迹表示场景中的一个点(他们称之为校准点),且对每一个校准点赋予一个不确定性参数。相比较现有工作,他们所提出的方法可以使模型需要学习的不确定性参数量随着帧数增加趋于线性增长,从而加快优化效率。
作者用柯西分布中的 scale 参数来代表不确定性参数,并引入 softplus 来保证不确定参数大于 0。此外,他们引入全新的「平均积累误差」和「柯西损失函数」来对模型进行监督,有效避免移动点对相机参数回归的影响。

3)双阶段训练策略。
由于不确定性参数的引入,同时优化所有参数会导致模型倾向于收敛至局部最小值。为了避免这种情况,经过对新引入损失函数中的 Softplus 的极限与凸最小值分析,作者设计了双阶段训练策略,在第一阶段实现模型快速收敛,在第二阶段实现模型稳定高效 fine-optimization。
实验结果
- 运行时间趋势对比(随帧数增加呈线性增长)

- 不同相机参数估计的新视角合成效果对比(iphone 数据集)

- 不同相机参数估计的新视角合成效果对比(nerf-ds 数据集)

- 相机 pose 对比(mpi-sintel 数据集)

- 其他 quantitative 结果 (更多结果请见论文及 Appendix)

.....
#LIMI
创智&交大发现AI能动性新规律, 78样本胜GPT5实现软件+科研自动化
AI 能动性的时代要求系统不仅能思考,更要能干活:包括协同编程(人机协作开发)和自动化科学研究。LIMI 仅用 78 个样本就超越 GPT-5 达 14.1%,并发现了能动性效率原则: AI 能动性不仅来源于数据丰富性,更来自于战略性构建。
本文来自于上海创智学院和上海交大刘鹏飞老师团队,团队专注于构建最前沿 AI 系统。核心作者来自于香港理工大学,上海交通大学,以及中国科学技术大学。
从 ChatGPT 到 Claude,从 Codex 到 Claude Code,全球科技公司正在 "能动性" 领域展开激烈竞争。这一趋势反映了产业界的关键认知:能动性能力正成为 AI 系统的核心竞争力,决定着 AI 能否从简单的对话工具演进为真正的工作伙伴。具备能动性的 AI 系统将重新定义人机协作模式,成为推动各行各业智能化转型的关键技术。
什么是 "能动性"?它是 AI 系统主动发现问题、制定假设,并通过与环境和工具的自主交互执行解决方案的能力。这种能力的重要性在于,它使 AI 从被动响应工具转变为主动执行的智能助手,能够独立完成复杂的知识工作任务。例如,让模型从零开始开发一个完整的五子棋游戏需要模型具备需求理解、架构设计、代码实现、调试优化等完整的自主执行能力。这种协作编程场景代表了现代知识工作的典型需求,而具备这种能力的 AI 系统将能够承担大量现实世界的复杂任务。
同样,在科研工作流程中,模型需要完成从文献调研到实验设计,从数据分析到洞察生成的完整链路。能动性使 AI 能够独立推进科学研究进程,这对于加速科学发现具有重大意义。
能动性能力的培养难度远超传统 AI 能力,因为它要求模型具备长期规划、多步推理、工具协调和自主纠错等高阶认知能力。当前主流方法普遍认为复杂的能动性能力需要大量训练数据支撑,遵循传统的规模化定律。这导致了资源密集型的训练流程:收集数万甚至数十万个训练样本,消耗大量计算资源,但效果往往不尽如人意。
LIMI 的研究结果表明,仅使用 78 个复杂多轮交互轨迹样本,模型就能在能动性基准测试 AgencyBench 上达到开源模型的最佳表现,还超越了 GPT-5 的性能。相比使用 10,000 个样本训练的模型,LIMI 实现了 53.7% 的性能提升,数据使用量却仅为其 1/128。
,时长00:58
如图展示了一个模型从头开发的完整可运行的五子棋游戏,这种端到端的自主执行能力正是未来 AI 系统的核心价值所在,证明了其在实际工作场景中的巨大应用潜力。
LIMI 的发现挑战了 "数据规模决定能力上限" 的传统认知,提出了能动性效率原则:模型能动性的发展更依赖于对能动性本质的理解和高质量数据的精准构造,而非简单的数据堆叠。这一发现为大规模部署具备真正工作能力的 AI 系统开辟了可行路径,表明理解能动性的核心机制比盲目扩大数据规模更为重要。

- 论文标题:LIMI: Less is More for Agency
- 论文地址:https://arxiv.org/pdf/2509.17567
- 代码地址:https://github.com/GAIR-NLP/LIMI
- 数据集地址:https://huggingface.co/datasets/GAIR/LIMI
- 模型地址:https://huggingface.co/GAIR/LIMI
- AgencyBench:https://agencybench.opensii.ai/
- SII CLI:https://www.opensii.ai/cli/
从被动响应到主动工作:能动性能力时代的到来
能动性大语言模型(Agentic LLMs)的出现,那些能够推理、行动并自主交互的系统,代表着从被动 AI 助手向具备主动能力模型的范式转变。研究团队将能动性定义为 AI 系统作为自主代理运作的新兴能力:主动发现问题、制定假设,并通过与环境和工具的自主交互执行解决方案。
这一根本能力标志着 "AI 能动性时代" 的到来,其驱动力来自一个关键的行业转变:迫切需要不仅会思考,更会工作的 AI 模型。虽然当前 AI 在推理和生成响应方面表现出色,但产业界需要能够执行任务、操作工具并推动现实世界成果的能动性模型。
然而,能动性模型的训练面临着关键挑战。当前方法普遍假设更多数据能让模型产生更强的能动性能力,遵循语言建模的传统扩展定律(scaling laws)。这种范式导致了日益复杂的训练流程和大量资源需求,但一个根本假设仍未得到检验:模型的能动性能力是否真的需要接触大量训练数据,还是可以通过战略性方法更高效地涌现?
相邻领域的新兴证据暗示了一个令人信服的替代范式。LIMA 仅用 1,000 个精心策划的样本就实现了有效的模型对齐,而 LIMO 证明复杂数学推理能力能够从仅 817 个战略性选择的训练样本中涌现。这些发现表明,战略性数据构造可能在培养复杂 AI 能力方面比数据集规模根本上更强大。
研究团队的 LIMI 给出了答案:模型的能动性能力遵循着与传统扩展方法根本不同的发展原则。通过战略性聚焦协作软件开发和科学研究工作流程,这些领域涵盖了大多数知识工作场景,研究表明复杂的能动性能力可以从少量但精心构造的高质量数据中涌现。
如图 1 所示,LIMI 仅用 78 个训练样本就让模型在 AgencyBench 上达到 73.5% 的性能,不仅超越了所有基线模型,更令人震撼的是,相比使用 10,000 个样本训练的模型实现了 53.7% 的性能提升,用 128 倍更少的数据让模型获得了卓越的能动性能力,彻底颠覆了 "更多数据 = 更强能动性" 的传统认知。

核心领域聚焦:协作编程与科学研究工作流
为了验证 LIMI 提出的战略性数据构造方法,该研究聚焦于两个需要完整能动性能力谱系并涵盖大多数知识工作场景的基本领域。
协作编程代表 LLMs 与人类开发者在上下文丰富环境中协作的软件开发模式。这个领域需要:跨现有代码库的代码理解和生成,通过复杂工具生态系统的开发环境导航,通过调试和优化循环的迭代问题解决,以及技术协调的协作沟通。复杂性在于对开发上下文的整体理解和在不断变化需求下的原则性决策制定。
科学研究工作流程涵盖复杂科学研究过程,包括文献搜索、数据分析、实验设计和洞察生成。这些工作流程需要:对多样化信息来源进行综合,采用适当方法论的实验设计,复杂结果的数据分析和解释,以及跨不同利益相关者格式的知识沟通。
这些任务展现出显著的时间复杂性,表现为需要连贯状态跟踪和累积推理的多轮交互。它们需要战略规划能力,将复杂目标分解为可管理的子目标,同时基于环境反馈适应性调整策略。工具编排能力变得至关重要,因为现实世界的能动性任务需要模型协调调用多个不同工具来完成复杂任务。
如图 2 所示的用户查询示例展现了单个查询的巨大复杂性 —— 从基础到专家级递进的五子棋开发任务涵盖 Web 前端开发、数据过滤、状态管理、规则启发式 AI 和高级搜索算法等多个相互关联的子任务。这种复杂性覆盖了规划、执行和协作等维度,展现了高质量演示中学习信号的密集性。

图 2:用户查询示例,展示了单个查询如何在规划、执行和协作维度上包含多个相互关联的子任务,证明了高质量数据中学习信号的密集性。
精准数据构建:战略策划的系统化方法
LIMI 方法的有效性根本依赖于战略性数据构造,通过真实世界协作任务捕捉本质的能动性行为。该研究团队围绕能动性交互的基本要素形式化数据构建过程,将每个完整交互定义为元组 < 用户查询,能动性轨迹 >,其中用户查询启动协作工作流程,轨迹捕获完整交互序列。
如图 3 所示,LIMI 的训练数据展现了显著的高质量特征:轨迹长度分布广泛,平均达到 42.4k tokens,最长可达 152k tokens,远超传统训练样本的长度。右侧的领域覆盖图显示了数据在协作编程和科学研究工作流程两个核心领域的广泛分布,涵盖了从前端开发、调试、工具调用到论文搜索、深度学习、实验工作流程等多个细分方向。

图 3:LIMI 训练数据的特征。左图:轨迹长度分布显示交互复杂性(平均 42.4k tokens)。右图:涵盖 vibe 编程和研究工作流的全面覆盖。
用户查询池构建:真实性与系统性的结合
查询收集策略系统性地结合真实世界场景与战略性覆盖扩展,确保生态有效性和充足的训练多样性。
真实世界用户查询收集: LIMI 从专业开发者和研究者在协作环境中遇到的实际场景收集 60 个查询。这些查询代表跨两个核心领域的真实挑战,具有自然复杂性和上下文丰富性。值得注意的是,大量研究查询来自真实学术论文,确保收集的用户查询具有可信的代表性。
基于 GitHub PR 的查询合成:为了在保持真实性的同时系统性扩展查询池,团队开发了使用 GPT-5 从 GitHub Pull Requests 合成额外查询的流水线。这种方法利用真实代码更改的丰富上下文,采用 GPT-5 的先进推理能力生成反映真实开发需求的协作场景。
系统性策划过程涉及多个质量保证阶段:
(1)选择具有超过 10,000 GitHub stars 的高质量代码仓库,(2)确保软件开发领域的综合覆盖,(3)基于复杂性和实质性进行过滤,(4)采用四名计算机科学博士生作为专家标注员评估合成查询的质量,确保语义对齐和上下文准确性。
通过这种系统化方法,团队最终构建了包含 78 个高质量用户查询的综合池,每个查询都代表来自协作编程或科学研究工作流程的真实协作场景。
轨迹收集:捕获最优能动性行为
为了生成展示最优能动性行为的训练轨迹,研究需要能够支持真实人机协作的复杂执行环境。这个环境必须支持复杂工具交互、维护详细交互日志,并提供现实能动性智能评估所需的操作上下文。
团队选择 SII CLI 作为执行环境,基于其几个关键优势:(1)支持协作编程和研究工作流程的全面工具集成,(2)对高质量训练数据收集至关重要的详细轨迹日志能力,(3)启用自然交互模式的灵活人机协作界面,(4)对需要协调工具使用的复杂多步任务的强大支持。
在 SII CLI 环境内,四名博士生标注员作为人类协作者,与 GPT-5 作为能动性模型协作,在真实协作场景中完成 78 个用户查询的轨迹收集。
对于每个查询,采用迭代收集方法,持续收集轨迹直到任务成功完成。这种持续性方法确保收集的轨迹捕获真实人机交互模式,包括自然的来回沟通、迭代细化过程和表征有效能动性行为的协作问题解决策略。
正如图 3 左侧轨迹长度分布所示,这种方法产生了内容极其丰富、交互高度复杂的高质量训练轨迹数据,平均长度达到 42.4k tokens,远超常规训练数据的复杂度,为模型提供了密集的能动性学习信号。
突破性实验结果:颠覆认知的发现
实验设置与评估框架
为了验证 LIMI 假设并证明战略性数据构造方法的有效性,团队采用了全面的实验框架,跨多个评估维度将方法与强基线模型进行比较。
基线模型评估:团队评估了多样化的最先进基础模型,确保全面比较:GLM-4.5、GLM-4.5-Air、Qwen3-235B-A22B-Instruct、DeepSeek-V3.1、Kimi-K2-Instruct。这个选择涵盖了具有不同架构设计和训练方法的开源模型,支持对能动性能力的严格评估。
模型训练与对比实验:为了系统评估策划训练数据的影响,团队使用收集的数据对 GLM-4.5 和 GLM-4.5-Air 进行微调。所有微调实验使用 slime 框架进行,确保一致的训练条件、超参数优化和公平比较。
此外,为了评估数据策划策略的质量和有效性,团队通过在三个替代数据集上微调 GLM-4.5 进行比较实验:CC-Bench-trajectories、AFM-WebAgent-SFT-Dataset 和 AFM-CodeAgent-SFT-Dataset。这种实验设计支持战略性策划数据与现有大规模能动性训练数据集的直接比较。
评估框架:评估包含两个互补策略,全面验证 LIMI 方法的有效性:
(1)在 AgencyBench 上的主要评估,专门设计用于评估协作场景中的能动性能力;(2)在涵盖工具使用、编程和科学计算的多个基准上的泛化能力评估,确保发现能够泛化到核心领域之外。
AgencyBench 上的卓越表现
如表 1 所示,在 AgencyBench 基准测试中,LIMI 取得了令人震撼的成绩:

表 1: LIMI 系列模型在 AgencyBench 上的综合比较。模型按评估目的分组:基线比较、泛化能力评估和数据效率验证。
LIMI 达到了 73.5% 的平均得分,显著超越了所有基线模型:GLM-4.5(45.1%)、Kimi-K2-Instruct(24.1%)、DeepSeek-V3.1(11.9%)和 Qwen3-235B-A22B-Instruct(27.5%)。
性能差距在首轮功能完整性(FTFC)方面特别明显,LIMI 达到 71.7%,相比 GLM-4.5 的最佳基线性能 37.8% 实现了显著的 33.9 个百分点改进。类似地,LIMI 以 74.6% 的成功率展示了卓越的任务完成可靠性,大幅超越了最强基线模型 GLM-4.5 的 47.4%。
数据效率的极致体现
最震撼的发现是数据效率对比结果,为核心 LIMI 假设提供了令人信服的实证证据:战略性数据策划在开发能动性智能方面根本上比简单扩展训练数据量更有效。
LIMI 使用仅 78 个精心策划的训练样本就达到了卓越性能,大幅超越了在数量级更大数据集上训练的模型。最引人注目的是与在 AFM-CodeAgent-SFT-Dataset 上训练的 GLM-4.5-Code 的比较:LIMI 的 73.5% 平均 AgencyBench 性能戏剧性地超越了大规模方法实现的 47.8%,尽管使用的数据集小 128 倍(78 vs. 10,000 样本)。
关键数据效率对比:
- LIMI (78 样本) vs GLM-4.5-Code (10,000 样本):25.7 个百分点优势,数据量仅 1/128
- LIMI vs GLM-4.5-Web (7,610 样本):23.5 个百分点优势,数据量仅 1/97
- LIMI vs GLM-4.5-CC (260 样本):18.0 个百分点优势,数据量仅 30%
这些一致的改进证明了战略性数据策划能够比大规模数据收集实现更有效的能力迁移,确立了能动性智能开发中 "少即是多" 范式的广泛适用性。
跨领域泛化验证
如表 2 所示,LIMI 的优势扩展到涵盖工具使用、编程和科学计算的多样化基准测试中,证明了方法的广泛适用性。LIMI 达到 57.2% 的平均性能,超越了所有基线模型,包括 GLM-4.5(43.0%)、Kimi-K2-Instruct(37.3%)、DeepSeek-V3.1(29.7%)和 Qwen3-235B-A22B-Instruct(36.7%)。
值得注意的是,LIMI 在关键编程基准上达到了最高性能(EvalPlus-HumanEval:92.1%,EvalPlus-MBPP:82.3%),并在工具使用任务上展示了竞争性结果(TAU2-bench-airline:34.0%,TAU2-bench-retail:45.6%)。
跨多样化评估领域的一致性能优势证明了战略性数据策划方法产生的广泛模型能力改进,确立了核心协作编程和研究工作流程之外强大的性能表现,表明 LIMI 不是简单的任务记忆,而是真正掌握了可迁移的能动性思维模式。

表 2:泛化基准测试的综合性能比较。HE 代表 EvalPlus-HumanEval,MP 和 SP 分别代表 SciCode 的主要问题和子问题指标。平均值包含了 AgencyBench 的表现。
能动性效率原则
基于实验结果,研究建立了能动性效率原则:
模型能动性的涌现并非来自简单数据的堆砌,而是来自高质量能动性数据的精心构造。
这一发现根本重塑了开发能动性大模型以及 AI Agent 的方式,表明掌握能动性需要理解其本质,而不是简单的扩大训练数据规模。
LIMI 促成了能动性训练范式的根本性转换:从 "更多简单数据→更强能动性" 的旧范式,转向 "更高质量的能动性数据→更强能动性" 的新范式。LIMI 认为:能动性本质上是 "潜伏" 于预训练模型中的,关键挑战不是训练新能力,而是找到激活路径。
产业影响与未来展望
对 AI 产业生态的重塑
LIMI 的发现对整个 AI 产业生态具有深远影响:
研发效率革命:小团队凭借精准方法可以与大公司竞争,降低了能动性技术的门槛,促进更多创新性方法的涌现。
资源配置优化:将投入重点从数据收集转向高质量样本设计和生成,从 "资源竞赛" 转向 "数据构造方法竞赛"。
应用落地加速:为实际能动性系统的开发提供了高效可行的路径,在实际应用中提供了具体的指导原则:专注核心场景、完整流程轨迹、质量优先策略。
商业化前景与技术普惠
LIMI 方法的商业化前景广阔:降低开发成本,减少对大规模数据和计算资源的依赖;缩短开发周期,通过精准方法快速获得能动性突破;提高应用效果,在特定领域达到更好的性能表现;普惠化应用,让更多中小企业能够负担得起能动性技术。
未来发展方向
虽然 LIMI 目前主要验证了协作软件开发和科学研究两个领域,但其原理有望扩展到医疗诊断能动性、教育辅导能动性、商业分析能动性等更广阔的认知领域。
未来的能动性系统将发展为多模态能动性,融合视觉、语言、行动等多种模态;自主学习能动性,从被动激活发展到主动进化;以及更完善的理论体系,建立能动性激活的数学模型和评估框架。
结语:开启能动性新时代
LIMI 不仅是一项技术突破,更是 AI 发展理念的根本性转变。它证明了在能动性开发中,理解本质比扩大规模更重要,质量比数量更关键。
78 个精心设计的样本击败万级数据的事实,确立了能动性发展的全新原则:模型能动性来自精心构造,而非数据堆砌。当模型从思考型 AI 转向工作型 AI 时,LIMI 为真正能动性的可持续培养提供了新范式,开启了能动性发展的新纪元,未来充满无限可能。
.....
#学三年动画被AI秒杀
OpenAI要拍电影,好莱坞不敢买账
OpenAI要「干趴」好莱坞。
这是网友学了三年动画做出来的《泰坦尼克号》,不知道大家是啥想法,反正我看完就精神分裂了。
,时长03:25
视频来自学了三年的动画,毕业只能去电子厂打螺丝的 B 站 up 主 MAX - 小仙女
一边是李云龙附体:开炮,开炮!赶紧把杰克和露西轰海里,一个也别活。

一边眼睛又很诚实,对着这丑的清新脱俗、美的人神共愤的小视频反复观看。
实在太鬼畜了。涂着死亡芭比粉的女主不仅能高抬腿风骚走位,还能穿墙而过,人都 360 度旋转飞了头发还在原地。

男主顶着鸟窝头咧着大嘴,突然劈腿壁咚那下,把我脑子都干宕机了。

果然努力在天份面前一文不值,学了三年动画还不如 AI 的一哆嗦。
X 博主 @fofrAI 拿字节的 Seedance Pro 模型,使用图生视频功能,制作了一个延时摄影的动画短片。
其中图片提示词:A woman is working at her chill desk in a large home living room in a rooftop penthouse, wearing large headphones, a photo of a city outside.
视频提示词:A woman is casually working during a very fast timelapse, as the day turns to night and the city lights turn on
,时长00:10
除了时长稍短了点、把墙上的照片也纳入了延时效果外,其他没毛病。瞅瞅这效果,不比吭哧吭哧学了好几年动画的 up 主强多了。
前段时间谷歌的 Nano Banana 火的一塌糊涂,网友 Framer 用它和 Seedance 1.0 花了不到 2 个小时打造了一个宫崎骏风格的 AI 动漫。
,时长00:29
制作流程并不复杂,Seedance 为镜头添加了动画效果,而 Nano Banana 使得惊人的跳切效果成为可能。
第一步:下面这张原始图像定义了动画中的角色、风格和环境,我们将它上传至豆包或即梦,输入提示词:Man fixes his motorcycle.[Cut] Man fits a missing part onto the side of the motorcycle.[Cut] Close-up shot: the man's face satisfied as he is looking at the motorcycle.(男人修理他的摩托车。[跳切] 男人将一个缺失的部件装上摩托车。 [跳切] 特写镜头:男人看着摩托车,脸上露出满意的表情。)

Seedance 很快就能将其处理成动画效果。
,时长00:05
第二步轮到 Nano Banana,生成同一个动漫人物骑摩托穿过街道的场景。
继续上传原始图像并输入提示词:Create an image of this same character riding his motorcycle at high speed through the streets of New York City during the daytime. Keep the same detailed anime-inspired art style, color palette, and atmosphere. Generate side shot of the man riding through the street.
,时长00:14
Nano Banana 可以完美复刻原始图像的风格,并保持人物一致性。

完成后重新切换回 Seedance 1.0 ,让它生成一个多镜头场景:he rides through the street + a close-up of his face.(他骑车穿行在街头 + 他的脸部特写镜头)
继续重复以上工作流生成下一个跳切场景。使用 Nano Banana 上传刚刚生成的图像,输入提示词:Use the style of this image and create a side shot of a police car parked on the side of the street, parallel to the curb with a policeman standing next to the car by its side and looking at the street.(使用这张图片的风格,创建一个警车停在街道旁边,平行于路缘,警察站在车旁边看着街道的侧面镜头。)
,时长00:12
还有博主 Rich Klein 用 HeyGen Avatar IV 生成唇形同步动画。
,时长02:43
《华尔街日报》前段时间报道称,OpenAI 正力捧一部名为《Critterz》的动画电影,不仅给它提供 AI 工具,还砸计算资源,为的就是向好莱坞「示威」:生成式 AI 可以更快、更便宜地制作电影。
影片讲述的是一群森林生物在村庄遭遇陌生人干扰后展开冒险的故事,由 OpenAI 创意专家 Chad Nelson 构思并启动。Nelson 于三年前开始构思角色,并在当时尝试利用 OpenAI 的 DALL-E 图像生成工具制作一部短片。

Nelson 还与伦敦和洛杉矶的制作公司合作,目标是将电影制作周期从传统的三年缩短至约九个月。电影的预算不到 3000 万美元,远低于传统动画制作的费用。
制作团队计划为角色配音招募人类演员,并聘请艺术家绘制草图,这些草图将输入 OpenAI 的 AI 工具,包括最新的 GPT-5 和图像生成模型。


该电影计划于 2026 年全球上映,并有望在戛纳电影节首次亮相。
OpenAI 认为,如果电影成功,它将加速好莱坞行业对 AI 技术的采用,降低创作门槛,使更多创作者能够借助 AI 工具实现他们的创作梦想。
不过,尽管 AI 工具在创作中展现出强大的潜力,娱乐行业对于 AI 的全面采纳仍持谨慎态度。
许多公司担心,AI 工具可能会威胁到演员和编剧的工作岗位,并且存在知识产权和创作自主权的担忧。为保护版权,迪士尼、华纳兄弟等公司已对 AI 提供商 Midjourney 提起诉讼,指控其侵犯了版权。但《Critterz》的创作方式通过结合人类艺术家的手工创作和 AI 的辅助,避免了这些版权争议,并为影片的版权保护提供了保障。
参考链接:
https://x.com/fofrAI/status/1958539728971526280
https://x.com/0xFramer/status/1963193458954326448
https://x.com/0xFramer/status/1960720090921623636
.....
#京东AI「结果」
深度应用已成当下,万亿生态瞄准未来
谁最懂场景,谁赢得未来。
9 月 25 日,北京,深秋的气息逐渐浓烈,即便太阳高悬,空气中还是流露出些许凉意,而在中关村国际创新中心,一墙之隔的里面,却是喧哗而热闹。
人形机器人前一刻还在台上与碳基生物酷酷斗舞,下一秒便转头向观众说「hi」;数字人歌手与人类歌手隔着屏幕互动,吟唱着同一首歌;可爱的玩偶不再沉默,变身「话痨」与大家聊起了天;让打工人挠破了脑袋想创意的营销海报,现在直接「秒级」生成;不管是人还是动物,甚至一个动漫角色,只需要上传一张图就直接拥有一个数字分身……
这是「2025 京东全球科技探索者大会 (JDD 大会)」的现场,也是京东大模型品牌升级后的首次 JDD,而这些都是京东 AI 应用最为沉浸、直观的展示。
满屏满眼的科技感、未来感,似乎都在诉说着一个事实:京东「JoyAI」大模型已经走向产业深度应用,进入人们生活的细枝末节,且「无处不在」……
而根据会上京东发布的 AI 全景图来看,以及围绕升级后的大模型品牌 JoyAI,正式发布的三大全新 AI 产品、四大场景深度 AI 应用,以及多个技术平台的「秀肌肉」式操作,更是印证这一事实:在落地应用成为大模型主流叙事的当下,在其他玩家还在进行场景与路径的摸索中,AI 已在京东供应链全链路、全场景应用中「结出了果」。
京东 AI,已然进入「深度应用」。

三大产品重磅发布,面向个人用户把 AI「做实」
今年,京东 AI 的大动作之一,就是在围绕内部大模型的进化成果整体梳理后,将大模型品牌全新升级为「JoyAI」,跟千行百业一起「Enjoy AI」。
大会上,京东发布全新 JoyAI 大模型,实现从 3B 到 750B 全尺寸覆盖,并推出数字人大模型 JoyAI LiveHuman 与语音大模型 JoyAI LiveTTS。JoyAI 语言大模型提出了三大算法创新,产业知识注入及高智力密度思维链数据合成,提升数据的智力密度;基于渐进式自我博弈的混合思考算法,提升模型的思考深度;基于同态变分推断的强化学习推理算法,提升模型的推理速度。
推理层面,JoyAI 大模型采用稀疏 MOE 训推一体架构,自研 Q-EPLB 加速机制通过混合精度量化与通信优化,使推理速度与传统方法相比提升了 1.8 倍,单卡吞吐量达 3000 tokens / 秒,在保障精度的同时显著降低部署成本。

数据显示,JoyAI 大模型在权威综合评测榜单 Rbench0924 上,结果为 76.3,推理能力国内第一,全球第二。在 LiveBench 上,深度思考结果为 75.7,超越了 DeepSeek-R1。在反映深度思考能力的 AIME、GPQA 等数学、生物、物理,以及化学等科学研究数据集上,也处于业内第一梯队。
此次,依托 JoyAI 大模型能力,京东发布了三大重磅 AI 产品,京犀 App、他她它」、JoyInside2.0,更为直观地向外展示京东 AI 的实力。
京犀 App—— 下一代购物和生活服务的超级入口
作为一款 AI 原生应用产品,京犀 App 定位为下一代购物和生活服务的超级入口,不仅能够与用户对答如流,还懂得用户需求,深度理解商品,为用户选出最合适的物品,且结算下单过程更为智能、顺畅。不管是购物,还是点餐、买机票、订酒店等,用语音「一句话」即可实现。

京东做大模型多年,但在个人用户层面缺乏一个直观感受入口,而定位为下一代购物和生活服务的超级入口的京犀 App,既可视为京东大模型能力的一次「外显」,也「藏着」京东想要定义 AI 时代「超级入口」的野心。
从传统互联网时代开始的「入口」之争,如今底层逻辑早已升级,谁能为用户提供一站式的精准服务,谁才有可能成为「超级入口」。京犀 App 在 JoyAI 大模型能力基础上,深度耦合了京东多年形成的电商生态,聚焦购物和生活服务深耕,或将成为京东布局「超级入口」的差异化优势。
据负责人透露,目前京犀 App 已开启「疯狂」内测阶段,预计 10 月份上线。
「他她它」— 万能数字人助手
「他她它」是京东首款数字人助手产品,以数字人智能体「万能博士」为核心载体,既能满足用户的各种工具类服务需求,又能提供更多更为人性化的新玩法,是一款综合性的 AI 产品。
「万能博士」几乎能回答用户任何问题,可以与用户像老朋友一样聊天气、聊新闻,也可以进行医疗问诊、点外卖等;「他她它」还支持用户自己创建智能体,搭建「AI 朋友圈」,交朋友;另外,用户还可以把「他她它」装进智能设备中,如机器狗、AI 玩具等,给这些硬件设备赋予「灵魂」。
会前,相关负责人在接受xxx采访时聊到,相较于市场上豆包、DeepSeek 等产品,「万能博士」的差异性关键点在于它是一个基于视频实时互动的产品,交互方式更友好,而前者更偏文本型对话。
会上,京东集团 SEC 副主席、京东集团 CEO 许冉直接现场带着观众体验了「万能博士」的点外卖功能。从「万能博士,帮我给会场的朋友点杯咖啡吧」,下达点餐指令,到短暂思考后给出推荐平台和咖啡款式,再到确认口味、数量、备注外卖放置点,最后完成支付,整个过程极为「丝滑」。
附身智能 JoyInside 2.0
今年的 WAIC 期间,京东发布一个全新的品牌 ——JoyInside 附身智能,可以将角色大模型驱动的对话智能体植入智能硬件载体,比如机器人、机器狗、AI 玩具、智能眼镜等,赋予它们「灵魂」和「智慧」,通过与用户进行更好的拟人化对话,以言行协同提供更好的产品体验,从而提升产品竞争力和用户粘性。
此次,该品牌迎来了全新升级,京东正式发布 JoyInside 2.0。
数据显示,接入 Joyinside 的智能硬件,用户会更加主动发起对话,对话次数平均提升超 120%。目前,JoyInside 2.0 已陆续接入超过 30 家头部品牌的硬件产品,并和众擎、宇树等超 10 家领先的机器人品牌合作,并上线京东售卖。
就连凯叔讲故事全新推出的AI硬件产品「AI鸡飞飞」,也即将搭载 JoyInside2.0,给孩子提供基于深度故事内容的交互体验,创造优质的内容和体验,让孩子成为成长的主角。

可以说,JoyInside 一方面是京东大模型能力在落地实体硬件上的具体展现,另一方面也可看作是京东布局xx智能智能领域的关键一步。
当下xx智能作为承载大模型技术的最佳终端载体,热度居高不下,大厂纷纷布局。目前看,京东并没有做硬件,而是通过向机器人、AI 玩具等合作伙伴提供「大脑」进行技术赋能,让自身模型能力以更丰富形态触达用户,布局未来入口。此外,通过流量倾斜,吸引合作伙伴产品上线京东售卖,让用户形成「买机器人上京东」心智。
不仅如此,京东还已投资多家xx智能企业。整体看来,京东正通过「自研 + 投资 + 生态共建」的布局来深度切入xx智能领域。
从零售、物流,到工业、健康,京东 AI 重构供应链
此次,京东还集中展示了全新升级后的 JoyAI 大模型,是如何深入零售、物流、工业、健康等诸多业务场景,并成为切实「提升效率、传递信任」的生产力工具的。
零售场景,此次京东首次对外公布电商创新 AI 架构体系 Oxygen,依托包括 JoyAI 在内的通用大模型层技术能力,打造了丰富的系统能力和多元化智能体。这是京东最为核心的场景之一,自然也是 AI 落地最为广泛、深入的场景之一。
消费者侧,京东新推出智能搜索推荐功能「爱购」,采用语义可控生成式推荐模型 OxygenRec 和电商多模态理解大模型 OxygenVLM 作为快慢思考结合的核心支撑技术,通过自然语言交互精准理解用户需求,实现对传统购物方式颠覆性的效率突破,为用户提供真正的个性化购物体验。

显然,京东正在基于 AI 对购物过程进行重构,探索未来电商新形态可能性。据了解,「爱购」新功能将于 10 月在京东 App16.0 版本中发布。
商家侧,Oxygen 也已深度介入内容生成、营销投放、供应链管理、客服服务等关键商家端采销环节。以京点点 (Oxygen Vision)为例,它作为零售行业首个面向运营人员的设计智能体,通过行业领先的商品一致性保持、精细设计元素可控,以及由AB实验数据驱动的目主迭代能力,帮助零售商家将素材精细化迭代效率提升千倍以上。数据显示,基于 Oxygen 的 50+AI 应用,已服务 300 多万商家,每周提供超 3000 万次经营决策。
物流场景,全新升级的物流超脑大模型 2.0 全面走向多模态,意味着物流的「超脑」正在从辅助决策来到xx执行,实现智能设备的自主决策。通过多智能设备协作,物流供应链作业效率成倍提升。全场景监控方面,员工操作标准化水平提升 15%;人车货场资源调度方面,一线效率提升近 20%;在人机协同场景,实现自主学习灵活调整执行策略,效率提升超 20%。
此外,基于超脑大模型,京东还孵化出了智狼、天狼、地狼等自研「狼族」产品,覆盖仓库存储、搬运、分拣、运输及零售终端等物流供应链全场景。
数据显示,目前「狼族」智能设备已覆盖全球四大洲,规模化部署应用仓库突破 500 个。
工业场景,京东打造出行业首个工业供应链大模型 JoyIndustrial,基于 5710 万工业品 SKU,以及 40 多个细分行业的数据积累,覆盖工业供应链全场景,可提供 6 大类、40 多个智能体应用,以「数据 + 智能」 驱动工业供应链效率革命,为各行业降本增效提供核心引擎,助力超 1 万家重点工业企业、数百万中小企业实现供应链数智化升级。
健康场景,面向复杂专病诊疗,京东推出「京医千询 2.0」,这是行业首个能看懂医学报告、听懂病情描述的医疗大模型,也是首个突破可信推理的医疗大模型。它能够严格模拟医生临床诊疗思维路径,深度融合医学知识体系与真实诊疗逻辑,模型可在推理过程中主动引入并对齐外部的循证医学证据,确保推理符合医学共识。
「可信」,这也正是京东提出在效率提升之外,AI 重构供应链的另一个落脚点 ——AI 传递信任。
提升效率方面已不必多说,而信任这一块,结合在产业场景的多年深耕,京东认为,「可信」源于「专业」,只有做到对行业、对场景有足够认知,对用户需求、偏好足够了解,才能提供精准的推荐与服务,确保 AI 可信可靠。
这体现在健康场景,是提供具有专业度的药品或诊疗建议,在电商零售等场景,是为用户推荐最符合用户真实需求的商品,从流量零售转变到信任零售。
最核心的诉求就是,京东不仅想让用户感受到 AI 已经深入到生活的细枝末节,还希望用户感知到 AI 的可信。
谁最懂场景,谁就掌握了领先权
为什么是京东先「跑」出了「深度应用」?
答案很明显,京东有着完善的供应链和广阔的产业场景优势,不同于大多数玩家先卷技术再卷应用的演进路线,京东大模型本身就是「生」于产业、「长」于产业。
早期,通过拼算法、囤算力、堆数据来获得模型性能曲线陡峭攀升的「暴力美学」受到各路玩家追捧,大模型主流发展路线无非两种:「做大」,尽全力卷基础大模型;「做小」,专门聚焦某一垂类大模型。
但京东走出「第三种」路径:既做「大」也做「小」,力求通过 70% 通用数据和 30% 供应链原生数据,面向行业有实际需求的场景落地。可以说,京东从做大模型第一天起,就在围绕场景需求寻求落地方案。
因此当大模型技术演进失去「性感叙事」,其他玩家开始摸索模型落地时,京东 AI 已然进入「深度应用」成果检验阶段。
而结合京东 AI 实践成果,给整个行业的重要启示就是,新一轮大模型竞争中,谁最懂场景,谁就掌握了领先权。
未来 AI 不再由单一技术指标定义,而是由「行业场景」主导,因为 AI 落地的核心命题在于解决真实场景痛点,并非「为了 AI 而 AI」,这不是一蹴而就的事情。因此,只有那些真正深入行业场景的玩家,才能更好进行 AI 落地应用。
正如许冉提及的,经过这两年在 AI 上的实践探索,京东认为 AI 的价值 = 模型 × 体验 × 产业厚度的平方。而产业厚度,涵盖了零售、物流、健康、工业等十多个领域的真实场景与数据。
无疑,京东已经「跑」出 AI 深度应用新范式。更重要的是,在 AI 已经全面渗透内部业务后,京东在试着将 AI 技术积累与能力向外释放。
大会上,京东全面升级三个深度应用平台,包括京东数字人平台 4.0,实现数字人从替身执行到面向个性创造,让数字人转变为具备个性与创造力的品牌资产,以在营销代言、文旅宣传等更为复杂的创意场景中发挥出更大的价值;智能体平台 JoyAgent3.0,基于 JoyCode 自编码能力、多模态 RAG 能力,以及 DataAgent 能力,融合企业内部的工作流、结构化和半结构化的知识库以及企业数据库,已经成为企业的「智能决策中枢」,且全面开放、持续深度开源;代码平台 joycode2.0,全面融合智能体,持续推动下一代开发范式……
另外,还有一个更潮、更有意思的玩法就是,恩雅吉他(Enya Music)和京东一起创造出一个符合其年轻、赛博、富有创造力品牌调性的数字人代言人 Aura。从视频来看,Aura 不仅可以生成准确自然的手部弹吉他细节,还可以在科幻空间飞天遁地,放开品牌诠释的视觉想象。作为品牌完全拥有的商业化 IP,Aura 可以被深度、长久、且无限制地运用于各种宣传物料和互动场景中。
京东JoyAI
,赞30
而基于京东乐器品类和恩雅吉他的深入合作,在火星赛博联名款吉他的首发中,当日成交额突破 100 万元,带动品牌整体交易提升了 65%。数字人 Aura 还和恩雅品牌全球代言人华晨宇同框出现,引发热议。

其实,不止是这些,包括新发布的三大 AI 产品,以及四大场景中的应用成果展示等,一切都是京东在将经过内部场景验证的能力,转化为外部商业解决方案,以形成生态扩张动能,从而促进整个产业加速走向更为智能化的未来。
京东始终坚信,技术再炫酷,要能真实落地才是关键,只有让大模型在整个产业里「跑」起来,才是最有价值的事情。「京东不片面追求运动式的 AI,追求的是可持续发展、真正为产业创造价值的 AI」。
在此次大会上,京东也宣布,未来三年将持续投入,带动形成万亿规模人工智能生态……
...
#闭源旗舰模型 KAT-Coder 与 开源 32B 参数模型 KAT-Dev-32B
Agentic Coding表现创新高,全新KAT系列模型强势霸榜SWE-Bench
近期,快手 Kwaipilot 团队推出了 KAT 系列两款突破性 Agentic Coding 大模型:开源 32B 参数模型 KAT-Dev-32B 与闭源旗舰模型 KAT-Coder。
这两款模型在 Code Intelligence 领域分别体现出轻量级的超强表现和极致性能。其中,在 SWE-Bench Verified 上,KAT-Dev-32B 展现出强劲性能并取得了 62.4% 的解决率,在所有不同规模的开源模型中排名第 5。与此同时,KAT-Coder 以 73.4% 的解决率在 SWE-Bench Verified 上取得了极佳的单模型表现,比肩全球顶尖闭源模型。

图 1:在 SWE-Bench Verified 上,和全尺寸开源模型对比,KAT-Dev 用极小的模型尺寸取得了第一梯队的性能

图 2:在 SWE-Bench Verified 上,KAT-Coder 取得极佳的单模型表现,比肩全球顶尖闭源模型性能
模型开源和 API 开放
KAT-Dev-32B 已在开源模型托管平台 Hugging Face 上线,可供进一步研究和开发使用。KAT-Coder 模型的 API 密钥近期也在 “快手万擎” 企业级大模型服务与开发平台上开放申请,用户将能够通过 Claude Code 等工具直接访问并进行编码。
- 快手 Kwaipilot 团队的官方技术 Blog:https://kwaipilot.github.io/KAT-Coder/
- KAT-Dev-32B 模型开源地址:https://huggingface.co/Kwaipilot/KAT-Dev
- KAT-Coder 开发工具接入指南:https://www.streamlake.com/document/WANQING/me6ymdjrqv8lp4iq0o9
- KAT-Coder API Key 申请:https://console.streamlake.com/wanqing/
核心贡献点摘要
KAT-Dev-32B 和 KAT-Coder 在多个训练阶段进行了创新和优化,包括 Mid-Training 阶段、监督微调 (SFT) 阶段、强化微调 (RFT) 阶段,以及大规模智能体强化学习 (RL) 阶段,具体如下:
- Mid-Training:Kwaipilot 团队发现,在这一阶段大量增加工具使用能力、多轮交互和指令遵循的训练,虽然在当前结果上(例如在 SWE-bench 等排行榜)可能不会带来显著的性能提升,但对后续的 SFT 和 RL 阶段具有重大影响。
- SFT & RFT:团队在 SFT 阶段精心策划了八种任务类型和八种编程场景,以确保模型的泛化能力和综合能力。此外,在 RL 之前,创新性地引入了 RFT 阶段,使用人类工程师标注的 "教师轨迹" 作为训练期间的指导。
- 大规模 Agentic RL:当前,扩展智能体 RL 面临三个挑战:非线性轨迹历史的高效学习、利用内在模型信号以及构建可扩展的高吞吐量基础设施。对此,Kwaipilot 团队通过对数概率计算的前缀缓存(Log-Probability Prefix Caching)、基于熵的轨迹剪枝(Entropy-based Tree Pruning)和自研的工业级规模强化学习训练框架 SeamlessFlow 来解决这些问题。
KAT 系列模型的核心技术路线
一、Mid-Training
Kwaipilot 团队对经过预训练的模型进行了两阶段训练,该阶段被称为 Mid-Training。在其中的第一个阶段,增强了模型与 “LLM-as-Agent” 相关的全方位能力,包括但不限于以下几种能力:
- 工具调用能力:构建了在沙盒环境真实执行工具的调用方法以及执行结果的交互数据,用于提升模型的工具调用能力;
- 多轮交互能力:构建了最长数百轮的人类、模型、工具的交互数据,用于提升在长文本情况下模型的多轮交互能力;
- 编码知识注入:加入了高质量的与编码相关的领域知识数据,用于进一步增强模型在编码场景下的性能;
- Git Commit 数据:加入了大量来自于真实 Git 仓库的 PR 数据,用于进一步提升模型在真实编程任务下的表现;
- 指令跟随数据:收集了 30 + 类常见的用户指令,用于增强模型对用户指令的理解能力;
- 通用及思考数据:构建了多类通用数据,用于增强模型在通用领域以及在调用工具时进行思考的能力。
二、监督微调 (Supervised Fine-Tuning, SFT)
在第二阶段,Kwaipilot 团队收集了大量人类工程师标记的真实需求交付轨迹,并基于此合成了大量的轨迹数据,进一步对模型进行训练,以增强其端到端需求交付的能力。其中覆盖了多种任务类型:
八大用户任务类型:
- Feature Implementation(功能实现)
- Feature Enhancement(功能增强)
- Bug Fixing(缺陷修复)
- Refactoring(结构优化)
- Performance Optimization(性能优化)
- Test Case Generation(测试用例生成)
- Code Understanding(代码理解)
- Configuration & Deployment(配置与部署)
八大用户编程场景:
- Application Development(应用开发)
- UI/UX Engineering(界面与用户体验工程)
- Data Science & Engineering(数据科学与工程)
- Machine Learning & AI(机器学习与人工智能)
- Database Systems(数据库系统)
- Infrastructure Development(基础设施开发)
- Specialized Programming Domains(专业编程领域)
- Security Engineering(安全工程)
三、强化微调(Reinforcement Finetune,RFT)
在这一阶段,Kwaipilot 团队在强化学习流程的基础上,额外引入了多个 ground truth 用于轨迹探索的指导,提升 rollout 效率,从绝对 reward 到衡量与 ground truth 的差异,提升了强化学习阶段的效率和稳定性。
从直接给定绝对 reward 更新为衡量 rollout 样本和 ground truth 之间的相对差异给了强化学习更稳定和更准确的奖励信号,同时也会在 rollout 阶段实时监督样本的正确性,并及时终止与 ground truth 有明显偏离的样本生成,这也给强化学习带来了更高的样本效率。

图 3:在强化微调(RFT)流程中,引入教师轨迹作为指导
经过三阶段的训练,团队获得了为 RL 阶段准备的冷启动模型,RFT 的加入也为 SFT 和 RL 之间构建了桥梁。
- Mid-Training:首先,团队教会大模型各种基本技能,包括如何使用工具、如何理解用户意图等;
- SFT:其次,用高质量的轨迹数据,让模型学习如何执行真实的下游任务;
- RFT:最后,在模型准备 “自由探索” 之前,先由教师轨迹手把手教会模型如何探索,保障了模型后续在 RL 阶段的稳定性。
四、大规模 Agentic RL
1、基于熵的树剪枝(Entropy Based Tree Pruning)
Kwaipilot 团队发现,即便使用上述技术,对完整树中的所有 token 进行训练的成本仍然过高,因此亟需设计一种能够优先聚焦于携带最强训练信号节点的机制。
为此,团队将轨迹压缩成一个前缀树,其中每个节点表示一个共享前缀,每条边对应一段 token。在固定的计算预算下,目标是只保留最有价值的节点进行训练。团队基于树中聚合的熵信号和节点被到达的可能性来估计节点的信息量,并按照重要性顺序扩展节点来剪枝树,直到预算耗尽。额外的启发式方法确保保留结构上的重要区域(例如,工具或内存事件),并维护局部上下文以稳定训练。这种基于熵的剪枝大幅减少冗余计算,同时保留大部分有效的训练信号,从而实现显著的吞吐量提升和更低的总体成本。
2、RL infra:自研 SeamlessFlow 框架

图 4:Kwaipilot 团队自研的 RL 训练框架 SeamlessFlow 架构
为扩展 RL,必须将 RL 训练与智能体的多样化内部逻辑完全解耦,同时最大化异构计算架构的利用率。遵循 SeamlessFlow 的设计,Kwaipilot 团队在智能体和 RL 训练之间设计了一个专门用于轨迹树管理的中间层,确保两者之间的严格分离。此外,采用提出的标签驱动调度机制来协调异构集群中的任务分配,从而最小化管道气泡并维持高吞吐量训练。
3、统一环境接口和企业级 RL 数据构建
Kwaipilot 团队还通过统一不同 RL 执行环境的部署和评估接口,使任何新添加的环境都能以低成本无缝集成。这种统一设计为跨异构数据源和任务类型扩展 RL 训练奠定了坚实基础。具体到软件开发场景,团队聚集于三个基本组件:与相应分支代码配对的问题描述、可执行环境和可验证的测试用例。
Kwaipilot 团队从开源仓库收集拉取请求和相关问题,并根据这些仓库的星标、PR 活动和问题内容过滤低质量数据,随后系统地为每个收集的实例构建可执行环境镜像并生成单元测试用例。除了软件工程数据,团队还纳入了其他可验证领域,如数学和推理任务,进一步丰富了 RL 信号的多样性。
更重要的是,除了开源数据,团队还进一步收集并利用来自真实世界工业系统的匿名企业级代码库进行 RL 训练。与仅在公共仓库(如 GitHub 上的仓库)上训练不同,这些仓库通常包含较简单的项目,而这些大规模、复杂的代码库 —— 跨越多种编程语言并代表真实的业务逻辑 —— 让模型接触到更具挑战性的开发场景,为 RL 提供了高价值的资产。训练智能体解决这些真实世界的工业问题不仅增强了学习的鲁棒性,还将所得模型的编程能力建立在现实的生产级环境中。

图 5:在 SWE-Bench Verified 上,各阶段训练对模型的性能影响
模型效果展示
KAT-Coder 模型具备强大的代码生成能力,可独立完成完整的项目开发,通过调用编程工具可实现从交互式游戏到代码重构等多样化编程任务。用户仅需描述需求,模型即可交付完整的代码解决方案。
1、星空效果

2、水果忍者🥷

3、代码重构

大规模 Agentic RL 后的涌现能力
对经过大规模 Agentic RL 训练后的模型进行分析,Kwaipilot 团队观测到了两个显著的涌现现象:
- 对话轮次显著降低:模型倾向于用更少的交互轮次完成任务,相较于 SFT 模型,平均对话轮次下降了 32%;
- 多工具并行调用:模型展现出同时调用多个工具的能力,而非传统的串行调用。
团队推测,这源于轨迹树结构带来的隐式优化压力,使模型自然形成效率偏好与并行调用能力。
- 效率偏好的形成:在轨迹树结构中,较短的路径(更少的对话轮次)会被更多的训练样本共享。这创造了一个隐式的优化压力:模型倾向于学习更高效的解决方案;
- 并行化的自然选择:在树结构中,多工具并行调用创造了更多的分支可能性,这些分支在训练时被独立处理,使得模型能够同时探索多个工具组合。同时熵剪枝机制(Long-term Entropy Pruning)保留了信息量较大的节点,而多工具调用节点往往具有更高的熵值,使模型逐渐学会了 "批处理" 思维。
未来展望
Kwaipilot 团队将持续探索代码智能的前沿领域,开拓创新可能:
- 增强工具集成:与流行的 IDE、版本控制系统和开发工作流深度集成,创建无缝的编码体验。
- 多语言扩展:扩展 KAT 模型能力以覆盖新兴的编程语言和框架,确保全面的语言支持。
- 协作编码:探索多智能体系统,让 KAT 模型能够在复杂的软件项目上协同工作,实现前所未有的协作。
- 多模态代码智能:集成视觉理解能力,处理架构图、UI 设计、调试截图和文档图像以及代码,使开发过程更加直观和高效。
原文链接:https://kwaipilot.github.io/KAT-Coder/
...
#DKP++(Distribution-aware Knowledge Aligning and Prototyping for Non-exemplar Lifelong Person Re-Identification)
北京大学提出分布驱动的终身学习范式,用结构建模解决灾难性遗忘
近日,北京大学王选计算机研究所周嘉欢助理教授与彭宇新教授合作在人工智能重要国际期刊 IEEE TPAMI 发布一项最新的研究成果:DKP++(Distribution-aware Knowledge Aligning and Prototyping for Non-exemplar Lifelong Person Re-Identification)。该工作针对终身学习中的灾难性遗忘问题,提出分布建模引导的知识对齐与原型建模框架,不仅有效增强了对历史知识的记忆能力,也提升了模型的跨域学习能力。
本文的第一作者为北京大学北京大学王选计算机研究所助理教授周嘉欢,通讯作者为北京大学王选计算机研究所教授彭宇新。目前该研究已被 IEEE TPAMI 接收,相关代码已开源。
- 论文标题:Distribution-aware Knowledge Aligning and Prototyping for Non-exemplar Lifelong Person Re-Identification
- 论文链接:https://ieeexplore.ieee.org/abstract/document/11120364
- 代码链接:https://github.com/zhoujiahuan1991/TPAMI-DKP_Plus_Plus
行人重识别(Person Re-Identification, ReID)旨在针对跨相机视角、跨地点、跨时间等场景中,基于视觉特征实现对同一行人图像的匹配与关联。该技术在多摄像头监控、智能交通系统、城市安全管理以及大规模图像视频检索等实际场景中具有广泛应用价值。然而,在现实环境中,由于采集地点、拍摄设备和时间条件的不断变化,行人图像的分布会随之发生迁移,导致测试数据与模型训练时所依赖的源数据之间存在显著的域偏移。这一分布漂移问题使得传统 “静态训练 - 固定推理” 的 ReID 范式在长期动态环境中的适应性不足。
为应对这一挑战,研究者提出了更具现实意义的任务设定,终身行人重识别(Lifelong Person Re-ID, LReID)。该任务要求模型在持续接收新域数据的过程中,能够高效地增量学习新知识,同时保持对先前已学习域中身份信息的辨识能力,从而实现跨时间与跨域的长期学习与知识保留。
研究现状
终身行人重识别任务的核心挑战是灾难性遗忘问题,即模型在学习新域知识后,对旧域中行人数据的检索性能大幅降低。为解决该问题,现有方法主要通过保留历史样本或采用知识蒸馏策略来缓解遗忘。然而,保留历史样本的方法存在数据隐私风险和存储开销持续增长的问题;知识蒸馏方法因强制新旧模型输出一致性,制约了模型的可塑性,限制了新知识学习能力。尽管原型学习技术在类增量学习任务中取得了较高性能,但现有方法仅为每个类别保留单一特征中心,忽略了类内分布差异,导致行人的细粒度知识丢失,难以适用于依赖细粒度匹配的终身行人重识别任务。
研究动机
动机 1:分布原型学习。为实现无历史样本存储条件下有效保留历史知识,我们提出通过实例级分布建模挖掘数据中的细粒度信息,进而构建分布原型,提升对不同域数据信息的表征和保存能力。

图 1 分布原型学习动机
动机 2:跨域分布对齐。虽然分布原型可有效缓解遗忘问题,由于新旧域数据存在分布鸿沟,造成历史原型对新数据学习的引导和约束作用较弱,导致模型的新知识学习能力和抗遗忘能力仍然受限。为克服该挑战,我们提出引入输入端分布建模并构建跨域样本对齐机制,提升历史分布信息对新域特征学习的引导作用,从而在大幅提升模型对历史知识巩固能力的同时,保障了对新数据知识的学习能力。

图 2 跨域分布对齐动机
方法设计:分布建模引导的知识对齐与原型建模框架

图 3 DKP++ 模型
(1)实例级细粒度建模:提出实例分布建模网络,动态捕捉行人实例的局部细节信息,为细粒度匹配奠定基础;


(2)分布感知的原型生成:设计分布原型生成算法,将学习到的实例级分布信息聚合为更鲁棒的类别级分布原型,克服了单一特征中心的局限性,保留类内差异知识。

(3)分布对齐:引入输入端分布建模机制,弥合新旧数据特征分布鸿沟,提升模型对历史知识的利用能力。

(4)基于原型的知识迁移:提出基于原型的知识迁移模块,利用生成的分布原型和有标注的新数据协同指导模型学习,在促进新知识吸收的同时,实现了对旧知识的记忆。

实验分析
1. 数据集与实验设置
论文的实验采用两个典型的训练域顺序(Order-1 与 Order-2),包含五个广泛使用的行人重识别数据集(Market1501、DukeMTMC-ReID、CUHK03、MSMT17、CUHK-SYSU)作为训练域。分别评估模型在已学习域(Seen Domains)上的知识巩固能力和在未知域(Unseen Domains)上的泛化能力。评测指标采用行人 ReID 任务的标准指标:平均精度均值(mAP)和 Rank-1 准确率(R@1)。


2. 实验结果:
综合性能分析:在两种不同的域顺序设定下,DKP++ 的已知域平均性能(Seen-Avg mAP 和 Seen-Avg R@1)相比于现有方法提升 5.2%-7%。同时,DKP++ 在未知域的整体泛化性能(UnSeen-Avg mAP 和 UnSeen-Avg R@1)上相比于现有方法提升 4.5%-7.7%。

学习趋势分析:与现有方法相比,随着已学习域的数量增加,DKP++ 呈现了更高的历史知识巩固能力。同时,DKP++ 也呈现了更高的未知域泛化性能增长速度,验证了其所积累知识的鲁棒性。

基础模型适配能力分析:在以不同的重识别基础模型(VF-Res,VF-ViT)作为预训练模型时,DKP++ 均保持了对现有方法的优势,说明其对不同的预训练模型均具备良好的适配能力。
总结与展望
1. 技术创新
本项被 IEEE TPAMI 2025 接收的工作聚焦于终身行人重识别(LReID)任务,提出了以下创新性设计:
分布原型建模与表征:提出基于实例级分布建模构建分布原型,增强了模型对历史信息的表达能力;
样本对齐引导的原型知识迁移:通过域分布建模与样本分布对齐克服新旧域数据的分布鸿沟,增强历史原型的利用能力。・
2. 未来展望
DKP++ 为无样本保留的终身学习技术提供了新范式,未来在多个方面仍有改进空间:
1. 基于大模型的分布对齐。本方法的分布对齐通过简单的卷积网络实现,未来可基于 Diffusion 等架构促进分布对齐以进一步提升模型的抗遗忘能力。
2. 知识主动遗忘机制。由于缺乏显式的引导,模型中往往包含冗余知识,在引入抗遗忘机制时容易干扰新知识的学习,因此构建模型的主动遗忘机制对进一步增强模型的知识巩固和学习能力具有重要研究价值。
3. 多模态终身学习机制。实际场景中存在红外、点云、音频、文本等多模态信息,增强模型的多模态数据持续学习能力,可促进模型充分利用多元化信息以增强复杂环境的感知能力。
...
#TrajBooster
轨迹为中心的学习促进人形机器人全身操控
TrajBooster把轮式人形机器人的6D臂轨迹跨身重定向到双足Unitree G1,再用「协调在线DAgger」训练全身控制器,仅需10分钟真机数据即可完成后训练;实测176个任务、1960段模拟流,VLA成功率显著提升,让双足机器人也能下蹲、跨高作业,摆脱对昂贵同构数据的依赖。
25年9月来自浙大、西湖大学、上海交大和上海创新研究院的论文“TrajBooster: Boosting Humanoid Whole-Body Manipulation via Trajectory-Centric Learning”。
近期的视觉-语言-动作 (VLA) 模型展现出跨xx泛化的潜力,但在高质量演示稀缺的情况下,难以快速与新机器人的动作空间匹配,尤其是对于双足类人机器人而言。 TrajBooster,这是一个跨xx框架,利用丰富的轮式类人机器人数据来提升双足 VLA 的性能。核心理念是将末端执行器轨迹用作与形态无关的接口。
TrajBooster (i) 从现实世界的轮式人形机器人中提取 6D 双臂末端执行器轨迹;(ii) 在模拟中将它们重定位到 Unitree G1,并使用通过启发式增强型协调在线 DAgger 训练的全身控制器,将低维轨迹参考提升为可行的高维全身动作;(iii) 形成异构三元组,将源视觉/语言与目标人形机器人兼容的动作耦合,对 VLA 进行预训练,之后仅需 10 分钟即可在目标人形机器人领域进行远程操作数据收集。策略部署在 Unitree G1 上,实现超越桌面的家务任务,支持下蹲、跨高度操作和协调的全身运动,并显著提高鲁棒性和泛化能力。
结果表明,TrajBooster 允许现有的轮式人形机器人数据有效地增强双足人形机器人 VLA 性能,减少对昂贵的相同xx数据的依赖,同时增强动作空间理解和零样本技能迁移能力。
近期进展显著推动人形机器人操控技术的发展。在此基础上,视觉-语言-动作 (VLA) 模型使人形机器人能够自主执行各种家务,并提高可靠性和泛化能力。
其中,轮式人形机器人尤其擅长执行需要协调全身运动的家务,例如下蹲和跨越不同高度的伸展动作,这凸显实际家居环境中对机器人实际伸展性和灵活性的要求。Agibot-World Beta 数据集的证据表明,末端执行器的运动轨迹集中在 0.2 至 1.2 米之间(如图所示),这凸显日常家务需要在广阔的工作空间内进行灵活操控,而不仅仅是在桌面上。相比之下,双足人形机器人必须用上半身进行操控,同时保持下半身的动态平衡,这使得这种大范围的全身操控尤其具有挑战性。
与此同时,先前的 VLA 研究主要集中在复杂环境中的运动或桌面操控,这留下了一个关键的空白:如何实现双足类人机器人的大范围全身操控。
实现这一目标需要大规模的演示,而数据收集仍然是瓶颈。现有的远程操作流程需要昂贵的基础设施和专业的操作员,并且通常产生的数据集规模较小,并且在不同场景和任务中的多样性有限。因此,VLA 在训练后阶段难以与新的类人机器人平台的动作空间保持一致。虽然在异构机器人语料库上进行预训练有所裨益,但它无法取代高质量、与类人机器人相关的、具有足够覆盖范围的全身演示。因此,当前的系统仍然不足以实现大范围操控。
01 类人机器人全身控制
近年来,现实世界中类人机器人全身控制的研究取得了长足的进步,许多研究主要通过基于远程操作的方法推动了该领域的发展。Humanoid-VLA和 Leverb等许多研究探索了利用 VLA 模型生成全身运动的自主策略。然而,这些研究主要集中在粗粒度控制上,例如坐下、挥手或行走。
相比之下,类人机器人操作任务的研究探索了通过视觉运动策略或 VLA 模型生成动作,但这些研究大多局限于桌面场景。这种场景没有充分利用类人机器人下肢的运动能力,从而限制了机器人的操作空间。虽然 Homie通过其视觉运动控制策略在解决这一限制方面取得了显著进展,但其实际应用仍然受限于需要为每个任务训练单独的策略,从而限制了其在不同任务场景中的可扩展性。
02 跨xx学习
跨xx学习旨在在形态各异的智能体之间迁移知识。一些方法使用修复、分割或基于物理的渲染来缓解感知差异,有效地对齐观察结果,但仍然局限于感知层面。除了感知之外,研究人员还探索了xx不变的动作抽象。潜在动作表征提供粗粒度的隐式编码,而基于轨迹的方法则将操作技巧提取为显式形式。例如,DexMV 将人类的 3D 手势映射到机器人的轨迹。这些方法虽然有效,但主要解决灵巧的手部与物体的交互,无法扩展到全身运动迁移。近期的研究可以生成全身动作;然而,其适用性受到四足机器人工作空间配置的限制。
本文利用 TrajBooster 解决提出的那些问题。这是一个跨xx框架(如图所示),它利用末端执行器轨迹与形态无关的特性,将演示从轮式机器人迁移到双足人形机器人,从而缓解双足 VLA 微调中的数据稀缺问题,从而提升 VLA 动作空间理解能力和任务泛化能力,以便在目标双足人形机器人上进行全身操控。
关键洞察在于,尽管形态上存在差异,但末端执行器轨迹提供一个共享接口,可以弥合xx之间的关节空间差距。利用来自轮式人形机器人 Agibot G1 的大规模数据,通过“真实-模拟-真实”的流程,间接增强双足机器人 Unitree G1 的 VLA 训练。
03 真实轨迹提取
用 Agibot-World 测试数据集中的操作数据作为真实机器人数据源。该数据集包含超过一百万条真实机器人轨迹,涵盖多视角视觉信息、语言指令和 6D 末端执行器姿态。然而,由于 Agibot 和 Unitree G1 之间的工作空间差异,直接基于末端执行器位置和方向轨迹进行重定向并不合适。例如,Agibot 的臂展在完全伸展时可达 1.8 米,而 Unitree G1 的臂展仅为 1.2 米。
为了解决这个问题,将 Agibot 数据集的轨迹映射到 Unitree 官方 G1 操作数据集 ,后者包含 7 个桌面级任务的 2,093 个场景。具体来说,通过基于后者应用 z-分数归一化,将 Agibot 数据的 x 轴与 G1 对齐,使用与手臂长度成比例的缩放因子 β = 0.6667 重新缩放 y 轴,并将 z 轴裁剪至 [0.15,1.25] 范围内,并设置安全边界。
04 仿真中的重定向
4.1 模型架构
鉴于 Agibot-World 数据集包含大量家务任务,其 z 坐标主要分布在 0.2 至 1.2 米之间,成功的全身操控需要协调的下肢运动(例如下蹲)。为了解决这个问题,提出一个用于全身操控重定向的复合分层模型(如图所示)。具体而言:
手臂策略 (P_IK) :通过 Pinocchio使用闭环逆运动学 (CLIK) 计算目标关节角度。
工作者策略 (P_worker) :一种目标条件强化学习策略,遵循 [17] 进行训练,使用上肢运动课程,以增强抗干扰鲁棒性。它输出 12-自由度下肢的目标关节位置。
管理者策略(P_manager):根据手腕姿势生成下半身命令。
复合层次模型 H 集成以下组件:
(a^leg^_t, a^arm^_t) = H(T_BE) = P_worker (P_manager (T_BE)), P_IK(T_BE))。
该模型以末端执行器相对于机器人基座的位姿 T_BE 作为输入,输出由 PD 控制器执行的 Unitree G1 关节指令。
4.2 分层模型训练
分层模型训练包含两个阶段:P_worker 训练,以及通过启发式在线学习进行 P_manager 训练(如下算法 1)。
P_manager 训练的关键步骤如下:
- 种子轨迹收集:在 MuJoCo 中,初始化 Unitree G1 站立模型,重放包含 2,093 个 episode 的上肢运动数据集,并记录生成的轨迹。
- 轨迹增强:对种子轨迹应用 PCHIP(分段三次 Hermite 插值多项式)插值,生成高度变化 ∈ [0.15m,1.25m],从而实现不同高度的全身操控。
- 启发式目标指令 (a^∗^ ) 生成:启发式真实高度目标 h^∗^ 由种子轨迹的 PCHIP 插值高度得出。启发式速度指令 (v^∗^_x , v^∗^_y , v^∗^_yaw ) 是根据人形机器人在 Isaac Gym 中相对于其初始位置的基准位移计算得出的,假设规划范围为 1 秒。
- 协调在线 DAgger:为简便起见,P_manager 和状态 s_t(代表 T_BE)分别表示为 P_m 和 s_t。在每次迭代中,P_m 在 Isaac Gym 中的 N 个并行环境中执行 T 步展开(T = 50)。最小化损失记为 L_rollout。
为了缓解持续学习中的灾难性遗忘,实现一种协调的数据集聚合 (DAgger) 策略。与每次迭代都聚合数据的标准 DAgger 不同,对聚合过程进行子采样,来平衡数据效率和计算效率——具体来说,每 M = 10 次迭代仅合并一次新的演示。随后,最小化聚合数据集损失 L_DA。
至关重要的是,该流程利用实际部署中无法获得的特权信息。具体而言,在模拟中,可以访问与当前目标 6D 操作轨迹相对应的躯干高度,以及人形机器人相对于相应身体位置的基准位移。这些特权信息使得启发式目标命令 a^∗^ 能够高效生成,从而促进 P_manager 的有效训练。
4.3 使用重定向数据进行后预训练
后预训练 (PPT) 是预训练和后训练之间的中间阶段,是大语言模型 (LLM)和视觉-语言模型 (VLM)中广泛采用的技术。同样,对于 VLA,预计该方法也将增强模型对下游任务的快速适应能力,并增强对动作空间的适应和理解能力,如图所示。
在本研究中,将重定向动作数据与来自原始 Agibot-World 数据集的语言指令和视觉观察相结合,构建多模态数据三元组。这些三元组用于对预训练的 GR00T N1.5 模型进行后预训练。
后预训练阶段采用的目标函数与中描述的后训练阶段相同。给定一个真实动作块 A_t 和采样噪声 ε,构建一个带噪声动作块:A^τ^_t = τ A_t + (1 − τ )ε,其中 τ ∈ [0,1] 表示流匹配时间步长。模型 V_θ (φ_t , A^τ^_t , q_t ) 通过最小化流匹配损失 L_fm(θ) 来预测去噪矢量场 ε − A_t。
在推理过程中,用 4 个去噪步骤生成跨越 16 个时间步长、频率为 20Hz 的动作块。每个块包含手臂和手的关节位置命令,以及用于 P_worker 模块的下半身控制命令 (v_x, v_y, v_yaw, h),从而使 VLA 模型能够实现对人形机器人的全身控制。
4.4 后训练
远程操作数据收集。采用与 P_worker 相同的训练方法来生成下半身运动。然而,与分层模型 H 不同,P_worker 的控制命令来自人类操作员通过遥控器操纵杆发出。对于上半身运动(包括手臂和手部运动),采用基于 Apple Vision Pro 的远程操作框架来实现运动学映射。用两个腕部 RGB 摄像头(左、右)和一个头部 RGB 摄像头收集视觉数据。
在目标人形机器人上微调 VLA。收集到的远程操作数据用于对预训练后的 VLA 模型进行后训练,方法是最小化前面提到的流匹配损失 L_fm(θ)。
05 重定向模型评估
基线。使用 Harmonized Online DAgger 训练分层模型。为了验证该方法在追踪模型训练中的有效性和效率,与几个基线进行比较:基于奖励的 PPO、标准 DAgger、在线学习(M = 1,不使用 DAgger)、标准在线 DAgger(M = 1,使用 DAgger)。
实施细节。所有实验均采用 512 个并行环境,进行 200 次训练迭代,但 PPO 除外,它使用 800 次迭代来解释其附加的值模型训练。训练和推理均在配备 Intel Core i9-14900K CPU 的单块 RTX 4090 GPU 上进行。
06 使用后预训练在 VLA 上进行评估
数据集。对于 Agibot-World 测试版数据集中的每个任务,随机抽取 10 个 episodes。涉及灵巧手和平行夹持器的任务则进行单独抽样,每种末端执行器类型选择 10 个 episodes。对于 episodes 少于 10 个的任务,所有有效 episodes 均纳入其中,而出现帧错误的 episodes 则被系统地排除。此过程产生一个包含 176 个不同任务和 1960 个 episodes 的数据集,相当于大约 35 小时的模拟交互。然后对这些数据进行预处理。利用 Isaac Gym 的环境并行性,在几十分钟内对所有 episodes 进行分层身体运动重定向。基于这些重定位的身体运动,实现末端执行器映射:Agibot-World 使用夹爪(85% 的轨迹)和手(15%),因此将拇指/食指的张开映射到夹爪空间;对于目标末端执行器 Unitree Dex-3(7 自由度手),预收集的开/闭关节位置作为重定位目标。重定位的 Unitree G1 运动取代了原始的执行器命令,生成多模态(动作、语言、视觉)数据三元组。对于后续的后训练,使用 Unitree G1 人形机器人在四种不同的高度配置下收集 28 个真实世界的全身操作数据,如图所示。该数据集包含大约 10 分钟的操作时间。
基线。建立无需进行后预训练的 VLA 作为基线:在预训练的 GR00T N1.5 上直接对模型进行 3K 和 10K 步后训练。将这些结果与训练后 3K 步的 VLA 后预训练结果进行比较。
实施细节。预训练后在双 A100 80GB GPU 上使用重定位的动作-视觉-语言三元组(批次大小=128,60K 步);训练后在单个 A100 GPU 上使用真实世界的全身操控数据(批次大小=16,3K 步)。同时,从 GR00T N1.5 检查点(仅使用真实世界数据)训练两个控制模型:一个 3K 步变型和一个 10K 步变型,均在单个 A100 GPU 上训练,批次大小为 16。
更多推荐
 17
17 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)