
Agent框架系列:3-多智能体框架AutoGen、CrewAI、GraphRAG 深度解析
Agent框架工具系列:多智能体框架深度解析AutoGen、CrewAI、GraphRAG
智能体框架和工具系列总目录:
- 一、Agent框架工具系列:1-低代码智能体平台深度解析Dify、Coze、n8n
- 二、Agent框架工具系列:2-LangChain-LangGraph生态深度剖析
- 三、Agent框架工具系列:3-多智能体协作框架深度解析AutoGen、CrewAI、GraphRAG
- 四、Agent框架工具系列:4-企业级知识管理平台深度解析MaxKB、FastGPT、DB-GPT
- 五、Agent框架工具系列:5-框架全景对比分析、实战案例集、框架选择建议
本文深度解析三大多智能体协作框架,从对话协作到角色分工,再到知识图谱增强,全面展现智能体协作的技术演进路径。
目录
概述
多智能体协作是AI Agent技术的前沿领域,通过多个专业化智能体的协同工作,能够处理比单一智能体更复杂的任务。本文分析三种不同的协作模式:
- AutoGen:基于对话的动态协作模式
- CrewAI:基于角色分工的团队协作模式
- GraphRAG:基于知识图谱的增强检索模式
一、AutoGen:微软开发的多Agent对话框架
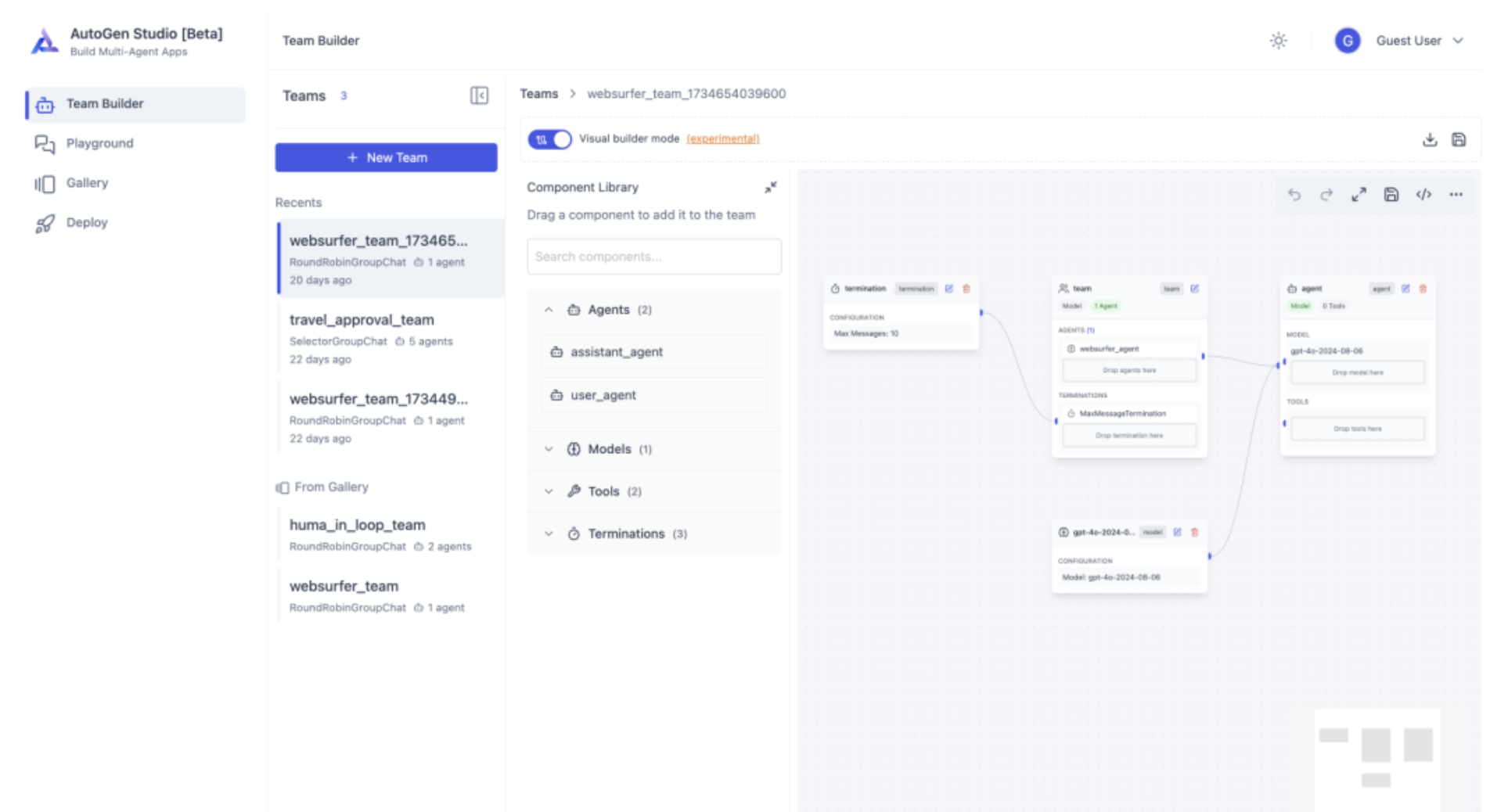
AutoGen是微软研究院开发的开源多智能体框架,专注于通过对话式协作实现复杂任务自动化。
项目地址:https://github.com/microsoft/autogen
技术架构深度解析
AutoGen采用对话驱动的多智能体架构:
1. 智能体类型体系
- AssistantAgent:具备代码执行和工具调用能力的助手智能体
- UserProxyAgent:代表人类用户的代理智能体
- GroupChatManager:管理多智能体群聊的协调智能体
- ConversableAgent:基础对话智能体,可自定义行为
2. 对话协调机制
- 轮转制对话:智能体按序发言和响应
- 条件路由:基于内容和规则的动态路由
- 人工介入:支持人类实时干预和指导
核心技术原理
多智能体对话协调算法
class GroupChat:
def __init__(self, agents, messages=None, max_round=10):
self.agents = agents
self.messages = messages or []
self.max_round = max_round
def select_speaker(self, last_speaker, selector):
"""智能体选择算法"""
if self._is_termination_msg(self.messages[-1]):
return None
# 基于上下文选择下一个发言者
candidates = [agent for agent in self.agents
if agent != last_speaker]
# LLM辅助选择最合适的智能体
selection_prompt = self._build_selection_prompt(
candidates, self.messages
)
selected = selector.generate_reply(selection_prompt)
return self._parse_selection(selected)
def _build_selection_prompt(self, candidates, messages):
context = "\n".join([msg["content"] for msg in messages[-3:]])
return f"""
基于对话历史:{context}
从以下智能体中选择最适合继续对话的:
{[agent.name for agent in candidates]}
"""
核心能力
- 动态对话协作:支持智能体间的自然语言交流和任务协商
- 灵活编程控制:通过Python代码定义终止条件和工具执行逻辑
- 多模型支持:兼容OpenAI、Anthropic、Microsoft等多种大模型服务
- 人机协作:支持人工介入和实时指导
- 性能评估:提供AutoGenBench工具进行智能体性能评估
实战案例:代码审查自动化系统
import autogen
# 配置智能体
config_list = [{
"model": "gpt-4",
"api_key": "your-api-key",
}]
# 创建代码审查智能体团队
senior_developer = autogen.AssistantAgent(
name="senior_developer",
llm_config={"config_list": config_list},
system_message="""你是资深开发工程师,负责:
1. 检查代码逻辑和架构设计
2. 识别潜在的性能问题
3. 提供改进建议"""
)
security_expert = autogen.AssistantAgent(
name="security_expert",
llm_config={"config_list": config_list},
system_message="""你是安全专家,负责:
1. 检查安全漏洞和风险点
2. 验证输入验证和权限控制
3. 提供安全加固建议"""
)
qa_engineer = autogen.AssistantAgent(
name="qa_engineer",
llm_config={"config_list": config_list},
system_message="""你是测试工程师,负责:
1. 评估代码的可测试性
2. 识别边界条件和异常场景
3. 提供测试用例建议"""
)
human_proxy = autogen.UserProxyAgent(
name="human_reviewer",
human_input_mode="TERMINATE",
code_execution_config={"work_dir": "coding"}
)
# 创建群聊进行代码审查
groupchat = autogen.GroupChat(
agents=[human_proxy, senior_developer, security_expert, qa_engineer],
messages=[],
max_round=20
)
manager = autogen.GroupChatManager(groupchat=groupchat, llm_config={"config_list": config_list})
# 启动代码审查流程
human_proxy.initiate_chat(
manager,
message="""请审查以下Python代码:
def user_login(username, password):
if username == 'admin' and password == '123456':
return True
return False
请从代码质量、安全性、可测试性等角度进行全面审查。"""
)
适用场景
AutoGen最适合需要复杂多Agent协作的场景:
- 代码开发协作:多个专家角色协同进行代码开发和审查
- 科研项目:不同专业背景的研究员协作解决复杂问题
- 动态任务分解:根据任务复杂度动态分配给合适的智能体
- 教育场景:模拟多人讨论和思辨过程
局限性
- 主要支持Python:其他语言支持有限
- 复杂配置:对开源LLM的集成较为复杂
- 学习成本高:需要深度理解对话机制
- 调试困难:多智能体交互的调试相对复杂
二、CrewAI:基于角色的智能体协作框架
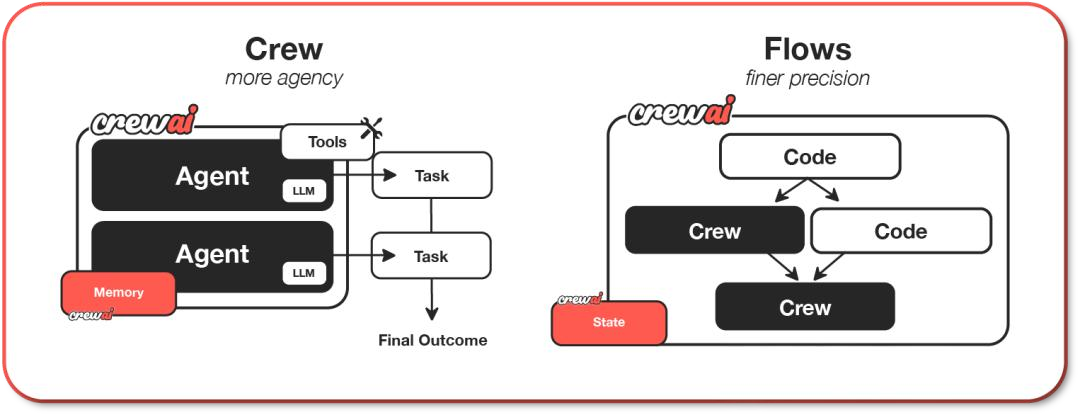
CrewAI是由葡萄牙开发者João Moura创建的开源多智能体协调框架,专为构建复杂任务自动化系统设计。
项目地址:https://github.com/crewAIInc/crewAI
技术架构深度解析
CrewAI采用角色驱动的协作架构:
1. 角色定义系统
- Role:定义智能体的专业领域和职责
- Goal:设定智能体的工作目标
- Backstory:提供角色背景和工作风格
- Tools:配置角色可使用的工具集
2. 任务编排机制
- Sequential Tasks:顺序任务执行
- Hierarchical Tasks:层级任务分解
- Consensus Tasks:协商决策任务
核心技术原理
角色协作算法
from crewai import Agent, Task, Crew
class ContentCreationCrew:
def __init__(self):
# 定义研究员角色
self.researcher = Agent(
role='内容研究员',
goal='收集和分析相关主题的最新信息',
backstory="""你是一名经验丰富的研究员,
擅长从多个可靠来源收集信息,
具有批判性思维和信息验证能力。""",
verbose=True,
allow_delegation=False,
tools=[search_tool, scrape_tool]
)
# 定义写作者角色
self.writer = Agent(
role='内容创作者',
goal='基于研究结果创作高质量的内容',
backstory="""你是一位才华横溢的作家,
能够将复杂的信息转化为引人入胜的内容,
注重内容的逻辑性和可读性。""",
verbose=True,
allow_delegation=True,
tools=[writing_tool]
)
# 定义编辑者角色
self.editor = Agent(
role='内容编辑',
goal='审查和完善内容质量',
backstory="""你是一名资深编辑,
具有敏锐的语言感知力和内容优化能力,
确保内容的准确性和专业性。""",
verbose=True,
allow_delegation=False,
tools=[grammar_tool, fact_check_tool]
)
def create_content(self, topic: str, target_audience: str):
# 定义研究任务
research_task = Task(
description=f'研究关于"{topic}"的最新信息和趋势',
agent=self.researcher,
expected_output='详细的研究报告,包含关键信息点和数据'
)
# 定义写作任务
writing_task = Task(
description=f'基于研究结果,为{target_audience}创作内容',
agent=self.writer,
expected_output='结构清晰、内容丰富的文章初稿'
)
# 定义编辑任务
editing_task = Task(
description='审查和完善文章,确保质量',
agent=self.editor,
expected_output='经过精心编辑的最终文章'
)
# 创建工作团队
crew = Crew(
agents=[self.researcher, self.writer, self.editor],
tasks=[research_task, writing_task, editing_task],
verbose=2
)
# 执行任务
result = crew.kickoff()
return result
# 使用示例
content_crew = ContentCreationCrew()
article = content_crew.create_content(
topic="人工智能在医疗领域的应用",
target_audience="医疗专业人士"
)
核心能力
- 角色分工机制,支持研究员、编辑、校对员等不同角色的Agent协同
- 可视化任务编排,便于理解复杂工作流
- 高度灵活性和定制能力,适合复杂业务场景
- 与开源语言模型兼容性良好
- 内置任务依赖管理和结果传递机制
实战案例:市场调研分析系统
import os
from crewai import Agent, Task, Crew, Process
from crewai_tools import SerperDevTool, ScrapeWebsiteTool
# 初始化工具
search_tool = SerperDevTool()
scrape_tool = ScrapeWebsiteTool()
class MarketResearchCrew:
def __init__(self):
# 数据收集专家
self.data_collector = Agent(
role="数据收集专家",
goal="收集目标市场的全面数据",
backstory="""你是市场调研领域的专家,
擅长从多个渠道收集准确、相关的市场数据,
包括竞争对手分析、消费者行为、市场趋势等。""",
tools=[search_tool, scrape_tool],
verbose=True
)
# 数据分析师
self.analyst = Agent(
role="数据分析师",
goal="分析市场数据并提取关键洞察",
backstory="""你是经验丰富的数据分析师,
能够从复杂的市场数据中识别模式、趋势和机会,
提供可操作的商业洞察。""",
verbose=True
)
# 报告撰写者
self.report_writer = Agent(
role="报告撰写者",
goal="撰写专业的市场调研报告",
backstory="""你是专业的商业报告撰写者,
能够将复杂的数据分析结果转化为
清晰、有说服力的商业报告。""",
verbose=True
)
def conduct_research(self, company_name: str, industry: str):
# 数据收集任务
data_collection_task = Task(
description=f"""
收集{company_name}在{industry}行业的市场数据:
1. 竞争对手分析
2. 市场规模和增长趋势
3. 消费者行为和偏好
4. 技术发展趋势
5. 监管环境变化
""",
agent=self.data_collector,
expected_output="结构化的市场数据收集报告"
)
# 数据分析任务
analysis_task = Task(
description=f"""
基于收集的数据,进行深入分析:
1. SWOT分析
2. 市场机会识别
3. 威胁和挑战评估
4. 竞争优势分析
5. 发展建议
""",
agent=self.analyst,
expected_output="详细的市场分析报告,包含图表和关键指标"
)
# 报告撰写任务
report_task = Task(
description=f"""
撰写{company_name}的市场调研最终报告:
1. 执行摘要
2. 市场概况
3. 竞争分析
4. 机会与挑战
5. 战略建议
6. 实施路径
""",
agent=self.report_writer,
expected_output="专业的市场调研报告,适合高层决策参考"
)
# 组建团队执行
crew = Crew(
agents=[self.data_collector, self.analyst, self.report_writer],
tasks=[data_collection_task, analysis_task, report_task],
process=Process.sequential,
verbose=2
)
result = crew.kickoff()
return result
# 使用示例
research_crew = MarketResearchCrew()
report = research_crew.conduct_research("特斯拉", "电动汽车")
适用场景
CrewAI最适合需要多角色Agent协作的复杂任务自动化场景,如内容创作、数据分析和跨系统任务处理等。其角色分工机制使其在需要多步骤协作的场景中具有独特优势。
局限性
对多模态任务或硬件为中心的场景支持较弱;文档资料不够详尽,上手难度较大;社区活跃度和生态支持相对有限。
三、GraphRAG:微软开源的图谱增强检索框架
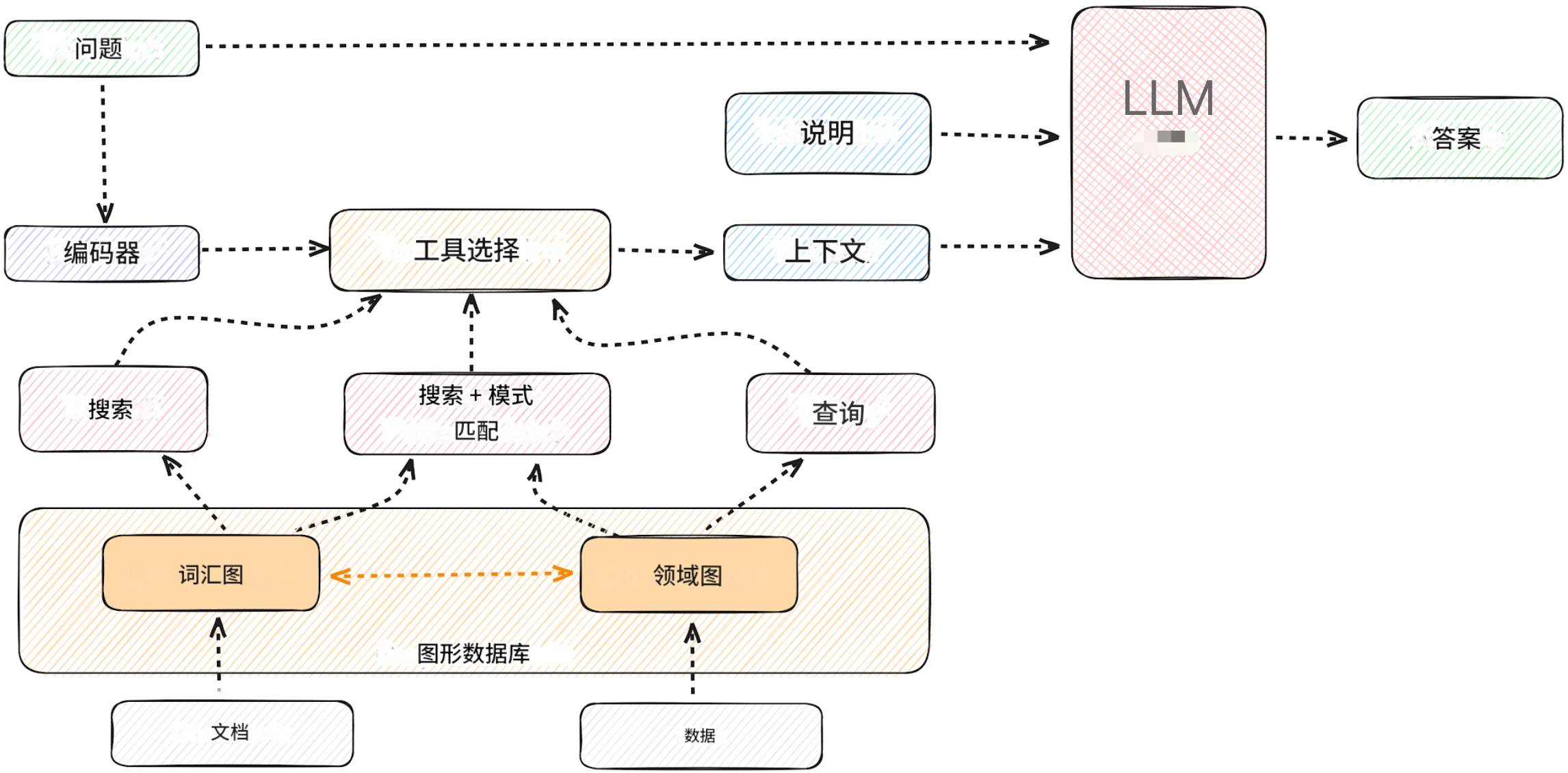
GraphRAG是微软开源的知识图谱增强检索框架,通过构建知识图谱来提升大模型的推理和问答能力,特别适合处理复杂的多跳推理问题。
项目地址:https://github.com/microsoft/graphrag
技术架构深度解析
GraphRAG采用图谱+检索+生成的三层架构:
1. 知识图谱构建层
- 实体抽取:从文本中识别关键实体
- 关系提取:构建实体间的语义关系
- 图谱构建:生成结构化知识图谱
- 社区检测:识别实体集群和社区结构
2. 图谱检索层
- 子图检索:基于查询提取相关子图
- 路径搜索:寻找实体间的推理路径
- 上下文聚合:整合图谱信息为文本上下文
3. 增强生成层
- 上下文注入:将图谱信息注入到生成过程
- 多跳推理任务:如"A公司的技术如何影响B行业,进而影响C公司?"
- 金融风险分析:分析复杂的风险传导链和关联关系
- 科研文献分析:理解概念间的复杂关联和演进关系
- 法律案例推理:基于先例和法条进行多步推理
实战案例
# 依赖:sentence-transformers, faiss, neo4j, openai/其他LLM SDK
from sentence_transformers import SentenceTransformer
import faiss
from neo4j import GraphDatabase
import openai # 或其他 LLM SDK
# 1. 嵌入模型与向量库(初始化)
embed_model = SentenceTransformer('all-MiniLM-L6-v2')
# 假设已建好 FAISS 索引并有文档映射 doc_id -> text,meta
# 2. 起点向量召回
def vector_recall(query, k=10):
qvec = embed_model.encode([query])
D, I = faiss_index.search(qvec, k)
return [doc_store[i] for i in I[0]]
# 3. 图起点定位与子图扩展(Neo4j 示例)
driver = GraphDatabase.driver("neo4j://localhost:7687", auth=("neo4j","pw"))
def find_graph_start_nodes(query):
# 简单做法:把 query 中候选实体按关键词匹配,或用 NER 先提取实体
with driver.session() as s:
# 示例:若 query 含 "E17"
res = s.run("MATCH (n:FaultCode {code:$code}) RETURN n", code="E17")
return [r["n"] for r in res]
def expand_subgraph(start_node_id, depth=2, max_nodes=50):
with driver.session() as s:
q = """
MATCH (start) WHERE id(start)=$sid
CALL apoc.path.subgraphNodes(start, {maxLevel:$depth}) YIELD node
RETURN collect(node) as nodes
"""
res = s.run(q, sid=start_node_id, depth=depth)
return res.single()["nodes"]
# 4. 合并上下文并调用 LLM
def build_context_and_answer(query):
vect_docs = vector_recall(query, k=8)
start_nodes = find_graph_start_nodes(query)
sub_nodes = []
for n in start_nodes:
sub_nodes += expand_subgraph(n.id, depth=2)
# 把节点转为文本(从节点元数据取 source/paragraph)
node_texts = [node['summary'] for node in sub_nodes]
# 合并、去重、排序
context = "\n\n".join(vect_docs + node_texts)
prompt = system_prompt + "\n\nContext:\n" + context + "\n\nUser Query:\n" + query
resp = openai.ChatCompletion.create(model="gpt-5-mini", messages=[{"role":"system","content":system_prompt},{"role":"user","content":prompt}], max_tokens=400)
return resp.choices[0].message.content
适用场景
GraphRAG 适合 需要跨文档、多跳推理、强关系型检索 的场景,比如 科研文献、金融风控、医疗、企业知识库。
而对于只需要简单语义匹配的 FAQ、聊天机器人,普通 RAG 就够了。
局限性
知识图谱构建成本较高;对计算资源要求较大;图谱质量直接影响最终效果;主要适用于知识密集型场景。
更多推荐

 23
23 0
0- 0



 已为社区贡献28条内容
已为社区贡献28条内容

所有评论(0)