
深度学习与大脑的关系是“模拟-验证-超越”的迭代循环
深度学习作为人工智能的核心技术,其设计灵感直接来源于人类大脑的神经网络结构与信息处理机制。通过模拟大脑的分层学习、并行计算和自适应调整能力,深度学习实现了对复杂数据的自动化特征提取与模式识别。:计算输出层与目标值的损失函数(如交叉熵损失),通过链式法则将误差反向传播至各层,更新权重以最小化损失。:引入动量(Momentum)、Adam等优化算法模拟大脑的学习率动态调整,加速收敛并避免局部最优。大脑
深度学习与人类大脑的关系解析
深度学习作为人工智能的核心技术,其设计灵感直接来源于人类大脑的神经网络结构与信息处理机制。通过模拟大脑的分层学习、并行计算和自适应调整能力,深度学习实现了对复杂数据的自动化特征提取与模式识别。
一、结构模拟:分层网络与神经元连接
人类大脑由约1000亿个神经元通过突触形成复杂网络,信息通过多层次神经元传递实现高效处理。深度学习模型通过构建多层神经网络(如卷积神经网络CNN的卷积层、池化层、全连接层)模拟这一分层结构:
- 低层网络:对应大脑的初级感知区(如枕叶处理视觉信号),负责提取边缘、纹理等基础特征。例如,CNN的卷积层通过滤波器捕捉图像的局部模式。
- 高层网络:模拟大脑的关联区(如顶叶整合空间信息),通过非线性变换组合低层特征,形成抽象概念。例如,ResNet通过残差连接实现深层特征融合,接近大脑对复杂场景的理解。
这种分层结构使模型能够自动学习从简单到复杂的特征表示,减少对人工特征工程的依赖。
二、功能映射:感知、推理与决策的数字化实现
大脑的功能模块(如运动皮层、语言中枢)为深度学习提供了任务分解的范式。不同网络架构针对特定功能进行优化:
- 感知任务:
- 视觉:CNN通过局部感受野和权重共享模拟视网膜到视觉皮层的信息处理流程,在ImageNet分类任务中准确率超过人类。
- 听觉:循环神经网络(RNN)及其变体(如LSTM)处理时序依赖性,应用于语音识别(如WaveNet模型)和音乐生成。
- 认知任务:
- 语言理解:Transformer模型通过自注意力机制模拟大脑对上下文的动态关注,在机器翻译(如Google Translate)和问答系统中达到人类水平。
- 推理决策:强化学习结合深度网络(如DeepMind的AlphaGo)模拟大脑的试错学习机制,通过奖励信号优化策略。
三、学习机制:数据驱动与神经可塑性
大脑通过突触强度的动态调整实现学习(神经可塑性),深度学习通过反向传播算法模拟这一过程:
-
误差修正:计算输出层与目标值的损失函数(如交叉熵损失),通过链式法则将误差反向传播至各层,更新权重以最小化损失。这一过程类似于大脑通过多巴胺等神经递质调节突触效率。
-
自适应优化:引入动量(Momentum)、Adam等优化算法模拟大脑的学习率动态调整,加速收敛并避免局部最优。例如,动态学习率公式:
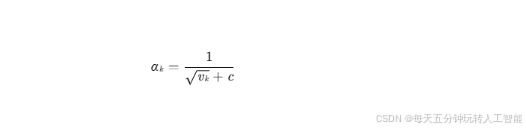
其中 vk 为梯度平方的移动平均,实现学习率的自适应衰减。
- 无监督预训练:受大脑自发活动启发,自编码器(Autoencoder)和生成对抗网络(GAN)通过无监督学习提取数据内在结构,缓解对标注数据的依赖。
四、差异与挑战:从模拟到超越的路径
尽管深度学习在特定任务上超越人类(如图像分类、围棋),但其与大脑仍存在本质差异:
- 数据效率:人类通过少量样本即可学习新概念(如识别一只猫),而深度学习需海量数据(如ImageNet含1400万张标注图像)。迁移学习和小样本学习技术(如MAML算法)试图缩小这一差距。
- 能耗与硬件:大脑功耗仅约20瓦,而训练GPT-3需消耗1287兆瓦时电力。神经形态计算(如Intel的Loihi芯片)通过模拟脉冲神经元(SNN)降低能耗。
- 可解释性:大脑的决策过程可通过fMRI等技术部分解码,而深度学习的“黑箱”特性限制了其在医疗等关键领域的应用。可解释AI(XAI)通过特征可视化(如Grad-CAM)和注意力权重分析提升透明度。
五、未来融合:脑机接口与通用人工智能
- 脑机协同:通过脑电信号(EEG)或功能磁共振(fMRI)数据训练深度学习模型,实现意念控制外骨骼或解码梦境内容。例如,Neuralink的植入式设备已实现猴子通过脑电玩电子游戏。
- 通用人工智能(AGI):结合大脑的全局工作空间理论(Global Workspace Theory),构建具备跨模态学习与推理能力的AGI系统。例如,GPT-4通过多模态预训练展现初步的通用性。
- 神经科学启发的新架构:脉冲神经网络(SNN)模拟神经元的脉冲发放机制,在时序数据处理中展现潜力;胶囊网络(Capsule Network)通过动态路由机制模拟大脑的视角不变性。
更多推荐

 16
16 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)