
人工智能发展简史7:技术基石——Transformer 架构的突破性创新
NLP技术经历了从低效到高效的突破性发展。传统RNN和LSTM处理序列数据缓慢且效果有限,而2017年提出的Transformer架构通过自注意力机制实现了并行计算,能高效捕捉长距离依赖关系。该架构让AI像人类一样"抓重点",理解上下文关联,为GPT等大模型奠定了基础。尽管存在计算复杂度高、资源需求大等局限,但通过改进位置编码、注意力机制等方式不断优化,推动了大语言模型的快速发
1 从 "蜗牛爬行" 到 "闪电飞驰":NLP 技术的困境与突破
在大模型 "说话" 之前,AI 处理语言的方式就像蜗牛爬行 —— 缓慢且低效。传统的循环神经网络 (RNN) 和长短期记忆网络 (LSTM) 虽然能处理序列数据,但训练速度慢,难以并行化,尤其是对于长文本的理解能力非常有限。想象一下,当 AI 读到 "西湖的风景很美,我在那里吃了东坡肉,它的味道真是太棒了" 这句话时,根本无法理解 "它" 指的是东坡肉还是西湖的风景。
2017 年,谷歌的一篇论文《Attention Is All You Need》彻底改变了这一局面。他们提出了Transformer 架构,通过自注意力机制,AI 能够高效处理序列数据,捕捉长距离依赖关系和上下文信息。这种架构就像给 AI 装上了 "重点抓取器",让它能够快速识别句子中的关键信息,理解上下文关联。

图 1《Attention Is All You Need》
Transformer 的核心优势在于并行计算能力。以前的 AI 模型需要按顺序逐个处理单词,就像一个一个地吃豆子,而 Transformer 可以同时处理整个句子,大大提高了训练和推理速度。这一突破为后续大语言模型的发展提供了核心框架,彻底改变了自然语言处理的格局。
2 自注意力机制:让 AI 真正 "理解" 上下文
Transformer 的核心是自注意力机制,它让 AI 能够像人类一样 "抓重点"。当 AI 处理 "昨天在西湖边吃的东坡肉超香" 这句话时,自注意力机制会自动锁定 "昨天(时间)、西湖边(地点)、东坡肉(事物)" 的关联,不用逐字梳理就能理解上下文。
这种机制的工作原理可以简单理解为:AI 在处理每个单词时,会同时关注其他所有单词,并计算它们之间的相关性。例如,当处理 "猫坐在垫子上" 这句话时,"猫" 和 "垫子" 之间的相关性会被加强,从而帮助 AI 更好地理解句子的意思。
Transformer架构主要由编码器(Encoder)和解码器(Decoder)两部分组成,适用于序列到序列的任务,如机器翻译。编码器负责将输入序列转换为连续表示,解码器则根据编码器的输出和之前生成的输出生成下一个输出元素。
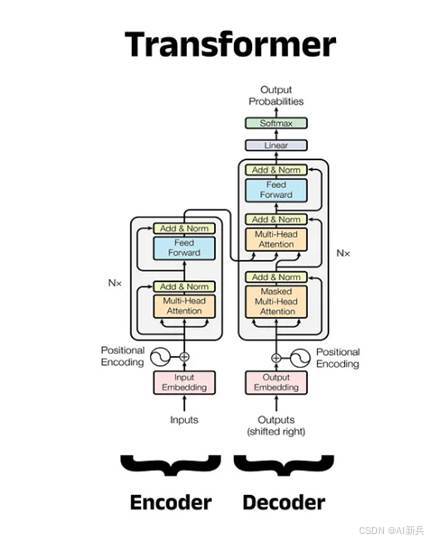
图 2 Transformer 架构
Transformer架构的提出对深度学习领域产生了深远影响。它不仅在机器翻译任务上取得了显著的性能提升,还为后续大模型技术的发展提供了基础框架。Transformer的并行化特性使得训练更深、更大的模型成为可能,为大规模预训练模型的出现奠定了基础。
然而,Transformer架构也存在一些局限性。首先,自注意力机制的计算复杂度与序列长度的平方成正比,这使得处理长序列时计算量巨大。其次,标准Transformer中的位置编码是固定的,难以适应不同长度的序列。此外,Transformer在训练过程中需要大量的数据和计算资源,这增加了研究和应用的门槛。
为了解决这些问题,研究人员提出了多种改进方案,如引入可学习的位置编码、改进注意力机制以降低计算复杂度、设计更高效的训练方法等。这些改进进一步推动了Transformer架构的发展和应用,为后续GPT、BERT 等一系列革命性大模型的出现创造了条件。
更多推荐

 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)