
高通数据集(1):交互式视频数据集
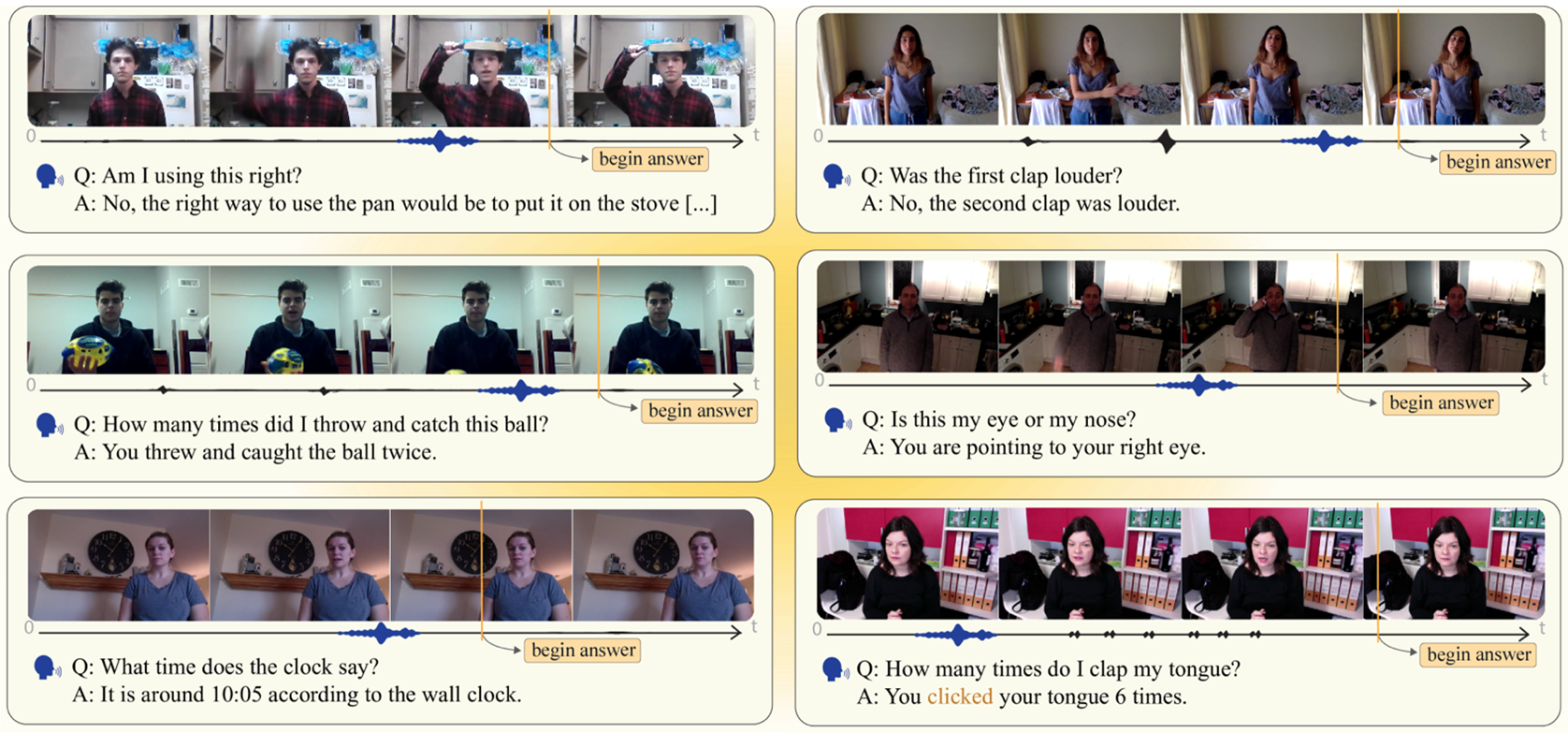
Qualcomm AI Research 推出了 QIVD 数据集,该数据集能够使用视觉语言模型 (VLM) 研究视觉理解,以回答有关视频中发生的事件的问题。人工智能领域的这一长期目标是现实世界的人工智能助手和人形机器人在日常生活中与人类互动的先决条件。这对于必须解释和响应实时视觉和音频输入,或与现实世界中的用户交互并了解正在发生的事情的 AI 系统非常有用。该数据集仅用于研究目的。如果您在研究中
·
QIVD 数据集
Qualcomm AI Research 推出了 QIVD 数据集,该数据集能够使用视觉语言模型 (VLM) 研究视觉理解,以回答有关视频中发生的事件的问题。人工智能领域的这一长期目标是现实世界的人工智能助手和人形机器人在日常生活中与人类互动的先决条件。
这对于必须解释和响应实时视觉和音频输入,或与现实世界中的用户交互并了解正在发生的事情的 AI 系统非常有用。
该数据集包含 2900 个数据项,其中每个项包含:
- 带有用户询问有关视频问题的音频的视频。
- 录制期间提出的人工生成问题的转录,以及该问题的人工生成答案
- 标记何时适合回答问题的地面实况时间戳
类别
每个项目都分配给 13 个预定义语义类别之一,这些语义类别表示不同的视觉推理功能:
| 属性 | 询问执行动作的方式,例如我用哪只手挥手? 或者 我跳得有多快?- 测试识别动态事件的细粒度特征的能力。 |
|---|---|
| 计数 | 有关动作重复频率的问题,例如我拍手了多少次?— 评估时间推理和事件分割能力 |
| 检测 | 标识执行的特定作,例如 “我现在在做什么?— 评估动态场景中的基本活动识别。 |
| 行动理解 | 质疑动作的目的或结果,例如这个手势是什么意思? 或者 我为什么要移动椅子?——测试更高层次的动作解释和意图识别。 |
| 对象属性 | 询问物体的特征,例如这本书是什么颜色的? 或者 这个杯子是空的还是满的?- 评估静态属性的细粒度视觉感知。 |
| 对象计数 | 确定存在的对象数量,例如桌子上有多少笔?——测试定量推理和对象个性化。 |
| 物体检测 | 标识场景对象,例如 “这个房间里有灯吗?- 评估基本对象识别能力。 |
| 对象引用 | 间接指向场景中的对象,例如 “我指向什么? 或者 我身后有什么?- 评估空间推理和指示参考分辨率。 |
| 对象理解 | 有关对象的性质或功能的问题,例如这个工具的用途是什么?——测试超越单纯识别的物体的语义知识。 |
| 场景理解 | 有关环境的查询,例如我在哪个房间? 还是 白天还是晚上?— 评估整体场景解释。 |
| 视听 | 需要音频信息才能获得完整答案的问题,例如我发出的声音是什么? 或者 我说话是大声还是小声?—测试跨模态集成能力。 |
| OCR | 从对象中提取文本,例如 “这个标志说什么?- 评估在现实世界和对话上下文中识别文本的能力。 |
| 主观 | 征求有关物体或场景的一般意见,例如这件衣服好看吗?——测试模型对主观问题做出合理反应的能力。 |
数据集详细信息
| 大小 | 2900 影片 |
|---|---|
| 平均长度 | 5.10 秒 |
| 总帧数 | 443350 |
| 平均 FPS | 30 |
| 帧的平均图像分辨率 | 640 x 382.29 |
| 词汇量 | 3624 字 / 3072 代币 |
| 语义类别总数 | 13 |
| 平均问题长度(字数) | 6.09 |
| 平均答案长度(字数) | 7.23 |
| 平均简答题长度(字数) | 1.38 |
| 平均答案时间戳 (%) | 81.47% |
| 总问题 | 1661 |
| 带有“地点”的问题 | 47 |
| 关于“如何”的问题 | 512 |
| 带有“什么”的问题 | 1102 |
| 总指示参考 | 78932 |
| 带有“这里”的问题 | 32 |
| 带有“这些”的问题 | 39 |
| 带有“那个”的问题 | 45 |
| 带有“那里”的问题 | 105 |
| 带有“this”的问题 | 568 |
| 平均答案时间戳和总样本数 | 81.47% 2900 |
| 作属性 | 84.31% 155 |
| 作计数 | 92.22% 225 |
| 作检测 | 85.46% 440 |
| 行动理解 | 81.47% 110 |
| 对象属性 | 79.52% 562 |
| 对象计数 | 78.41% 286 |
| 物体检测 | 76.95% 211 |
| 对象引用 | 79.18% 706 |
| 对象理解 | 80.63% 79 |
| 场景理解 | 79.91% 38 |
| 视听 | 90.09% 22 |
| OCR | 83.04% 23 |
| Subjective 主观 | 77.39% 43 |
| 源 | 基准测试中的所有视频都是众包的,然后由非专家注释者进行注释。在此之后,视频会经过严格的质量检查过程和语义分类过程。 |
| 语言 | 英语 |
数据格式
数据集分布在两个文件中:
- videos.zip:2,900 个.mp4 格式的 视频文件。
- annotations.zip: 包含所有视频注释的单个 .json 文件。此文件的结构为 2,900 个字典条目的列表,其中每个词条对应一个视频,并包含以下元数据和标签:
- video:视频文件名(例如“ 00000000.mp4”)
- 问题 :视频中提出的问题(例如, “我左手拿着什么?
- 答案 :问题的完整答案(例如, “你左手拿着魔方。
- short_answer:答案的简明版本,仅包含关键信息(例如, “魔方”)。
- 时间戳 :视频中回答问题的最佳时间(例如, “00:04.4”)。
- category:问题的类别(例如, “对象引用”)。
数据集引文说明
该数据集仅用于研究目的。如果您在研究中使用此数据集,请引用我们的论文
下载地址
@misc{pourreza2025visionlanguagemodelsanswerface,
title={Can Vision-Language Models Answer Face to Face Questions in the Real-World?},
title={视觉语言模型可以在现实世界中回答面对面的问题吗?
author={Reza Pourreza and Rishit Dagli and Apratim Bhattacharyya and Sunny Panchal and Guillaume Berger and Roland Memisevic},
author={Reza Pourreza 和 Rishit Dagli 和 Apratim Bhattacharyya 和 Sunny Panchal 和纪尧姆·伯杰和罗兰·梅米塞维奇},
year={2025}, 年={2025},
eprint={2503.19356}, eprint={2503.19356},
archivePrefix={arXiv}, 存档前缀={arXiv},
primaryClass={cs.CV}, primaryClass={cs。CV},
url={https://arxiv.org/abs/2503.19356},
网址={https://arxiv.org/abs/2503.19356},
}
更多推荐
 15
15 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)