
分布式推理服务(策略:数据并行、张量并行、流水线并行、专家并行)技术分析
摘要:分布式推理突破单GPU内存和算力限制,支持大模型部署。四种核心策略包括: 数据并行:复制模型拆分数据,提升吞吐但内存效率低; 流水线并行:模型分阶段执行,支持超大模型但存在计算气泡; 张量并行:拆分层内矩阵运算,延迟低但通信开销大; 专家并行:动态激活MoE模型专家,计算高效但路由复杂。实际应用中常组合策略(如3D并行),需权衡模型规模、硬件条件与性能目标。
概述:为什么需要分布式推理?
随着大模型参数规模从百亿级迈向万亿级,单个GPU设备的内存和算力已无法满足推理需求。分布式推理通过将模型或数据拆分到多个设备上协同工作,突破了单机瓶颈,是实现大模型高效、高可用服务的核心技术。
下面这张图清晰地展示了四种并行策略如何对模型和数据进行划分:
flowchart TD
A[输入数据] --> A1[数据并行<br>复制模型,拆分数据]
A --> A2[流水线并行<br>拆分模型,数据按阶段流动]
A --> A3[张量并行<br>将模型层内矩阵拆分]
A --> A4[专家并行<br>根据输入激活不同专家]
subgraph B1[数据并行示例]
B1_1[GPU 0<br>完整模型副本] --> B1_2[输出 0]
B1_3[GPU 1<br>完整模型副本] --> B1_4[输出 1]
end
subgraph B2[流水线并行示例]
B2_1[GPU 0<br>模型前几层] --> B2_2[GPU 1<br>模型中间层] --> B2_3[GPU 2<br>模型最后层] --> B2_4[输出]
end
subgraph B3[张量并行示例]
B3_1[GPU 0<br>矩阵分块A] <--> B3_2[GPU 1<br>矩阵分块B]
B3_1 & B3_2 --> B3_3[合并结果]
end
subgraph B4[专家并行示例]
B4_1[GPU 0<br>专家A]
B4_2[GPU 1<br>专家B]
B4_3[GPU 2<br>专家C]
B4_1 & B4_2 & B4_3 --> B4_4[路由网关] --> B4_5[输出]
end
A1 --> B1
A2 --> B2
A3 --> B3
A4 --> B4
策略一:数据并行
核心原理
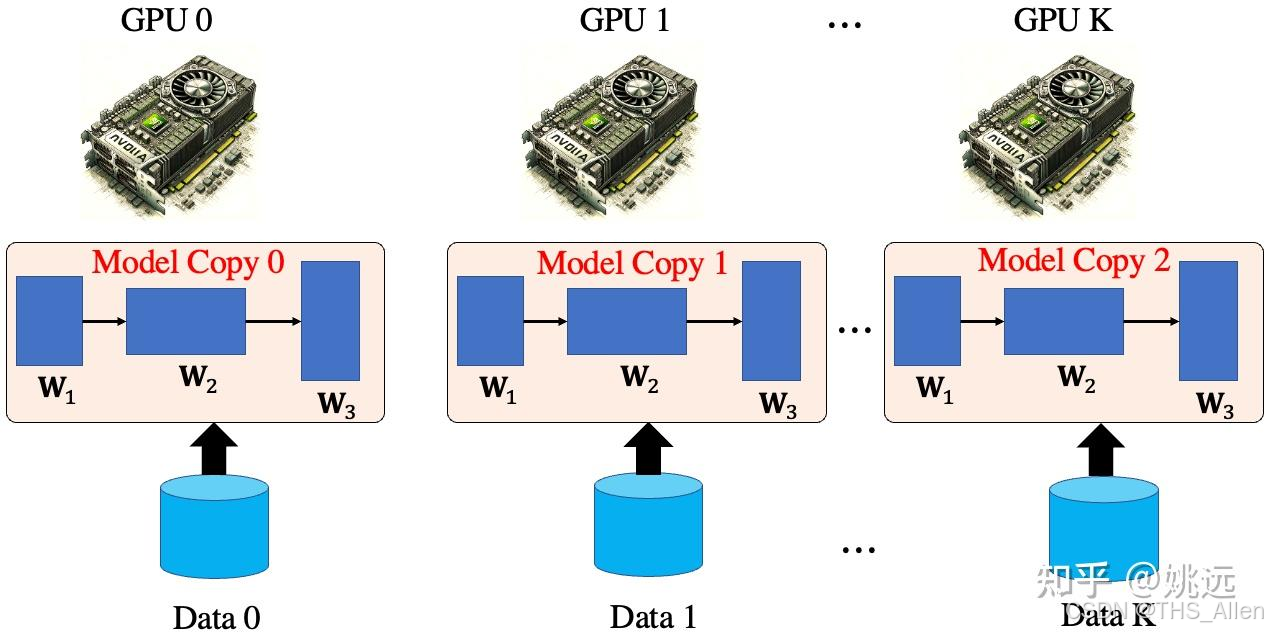
复制模型,拆分数据。在每个计算设备(如GPU)上都部署一个完整的模型副本,然后将一个批次的输入数据平均分配到所有设备上并行处理。
工作流程
- 分发:主节点将模型参数广播到所有Worker节点,并将一个批次的输入数据切分。
- 并行计算:每个Worker节点用完整的模型处理自己分到的数据。
- 结果收集:所有Worker将计算结果(如损失、梯度-用于训练/输出logits-用于推理)返回给主节点进行同步(训练)或直接作为最终输出(推理)。
技术剖析
- 通信模式:All-Reduce(用于训练时同步梯度)或 Gather(用于推理时收集结果)。
- 内存开销:每个设备都需存储一份完整的模型参数,内存效率低。
- 计算效率:理想情况下,N个设备可使吞吐量提升近N倍。
优点与局限
- 优点:实现简单,适用于模型能完全放入单卡显存的场景,能有效提升吞吐量。
- 局限:无法解决大模型单卡放不下的问题。在推理时,如果每个请求的输入序列很长,Batch Size很小,则设备利用率低。
适用场景
- 模型规模适中,单GPU显存可以容纳。
- 高吞吐量推理场景,如公众开放的ChatBot服务,需要同时处理大量并发请求。
策略二:流水线并行
核心原理
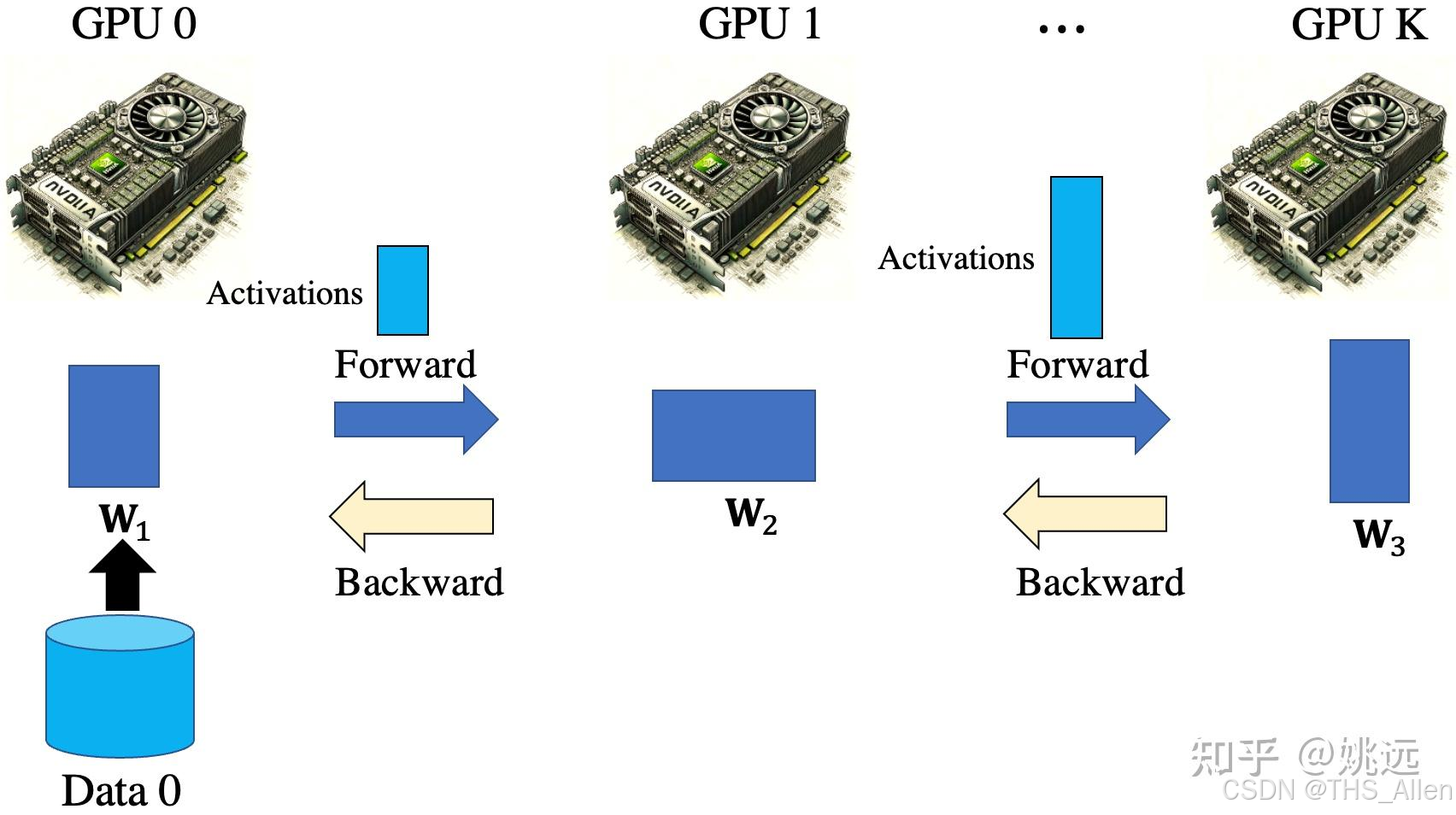
拆分模型,数据按阶段流动。将模型按层(Layer)切分成多个阶段(Stage),每个阶段部署在不同的设备上。一个批次的数据像在流水线上一样,依次经过每个阶段。
工作流程
- 模型划分:将模型的L层划分为K个阶段(K通常等于设备数),每个阶段包含L/K层。
- 流水执行:
- GPU 0 完成第1个Micro Batch的计算后,立即将中间结果(激活值)传递给GPU 1,同时开始处理第2个Micro Batch。
- 以此类推,多个Micro Batch同时在流水线的不同阶段上处理,形成流水线。
技术剖析
- 通信模式:点对点通信(Peer-to-Peer),相邻阶段间传递激活值。
- 关键挑战:流水线气泡(Pipeline Bubble)。即某些设备必须等待上游设备传递数据而造成的空闲时间。通过引入更多的Micro Batch可以减小气泡,提高设备利用率。
优点与局限
- 优点:能够支持单卡无法容纳的超大模型。
- 局限:存在流水线气泡,设备利用率非100%;对模型结构有要求,需要容易划分;单个请求的延迟(从开始到输出第一个Token的时间)会因流水线而增加。
适用场景
- 模型极大,无法通过张量并行完全分解。
- 模型是线性的序列结构(如Transformer),易于划分。
策略三:张量并行
核心原理
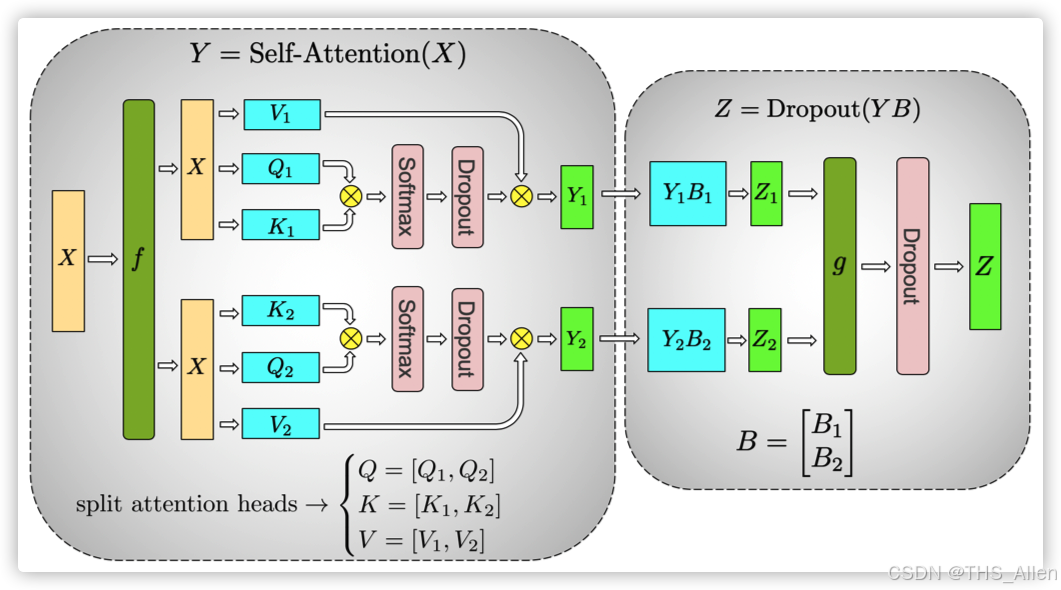
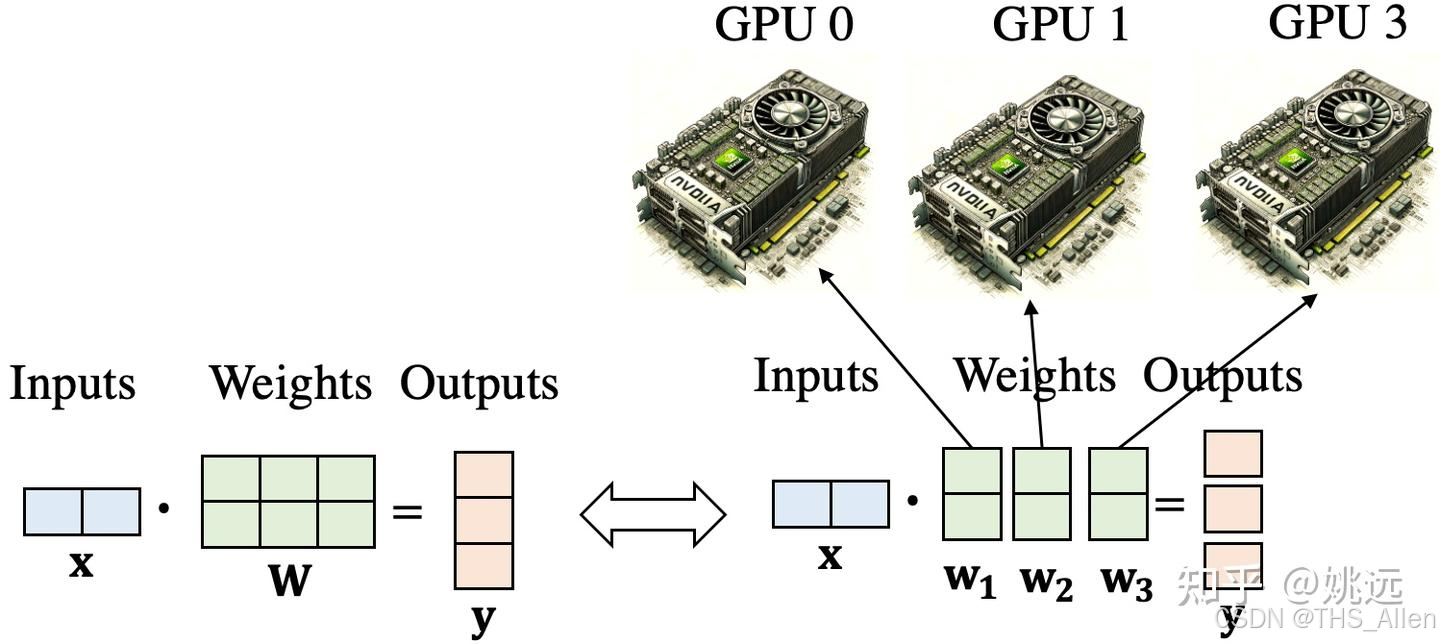
将模型层内的矩阵运算进行横向或纵向拆分。它不是在不同设备上运行不同的层,而是将一个层(如Linear层或Attention层)的计算和参数拆分到多个设备上。
工作流程(以Linear层为例)
- 拆分权重矩阵:假设一个Linear层的权重矩阵
W为[M, N]维。可以按行或按列拆分。例如,按列拆分为W1 [M, N/2]和W2 [M, N/2],分别放在GPU 0和GPU 1上。 - 并行计算:输入
X同时发送给两个GPU。GPU 0 计算Y1 = X * W1,GPU 1 计算Y2 = X * W2。 - 结果同步:通过 All-Reduce 操作将
Y1和Y2合并为完整的输出Y。
技术剖析
- 通信模式:All-Reduce。通信非常频繁,每层的前向和反向传播都需要一次All-Reduce。
- 通信开销:极大。通信量与模型隐藏层维度(Hidden Size)的平方成正比。因此,张量并行通常在一个高速互联的节点内使用(如通过NVLink连接的多个GPU),而不适合跨节点。
优点与局限
- 优点:比流水线并行有更低的延迟,因为一个层的计算是所有设备同时参与的。
- 局限:通信开销巨大,限制了其扩展性(通常在一个节点内4或8卡使用效果最佳)。
适用场景
- 单个层非常巨大,即使使用流水线并行,一个阶段也无法放入单卡。
- 在单个服务器节点内,GPU间有高速互联(NVLink),用于减少通信延迟。
策略四:专家并行
核心原理
基于输入动态选择专家。这是混合专家模型(MoE) 的专属并行策略。MoE模型由多个“专家”(通常是结构相同但参数不同的FFN层)和一个“门控网络”组成。对于每个输入,门控网络只选择少数(如1或2个)专家进行计算。
工作流程
- 路由:门控网络根据输入计算每个专家的权重,选出Top-K个专家。
- 分发:将输入数据发送到这些专家所在的设备上。
- 计算:每个被选中的专家独立处理输入。
- 聚合:将各个专家的输出按门控权重加权求和,得到最终结果。
技术剖析
- 通信模式:All-to-All。输入数据需要根据路由结果分发到不同设备,计算结果也需要收集回来。这是通信模式最复杂的一种。
- 核心优势:“激活”的参数稀疏性。虽然模型总参数量巨大(如万亿参数),但每次推理只激活一小部分参数,因此计算成本与一个稠密小模型相当。
优点与局限
- 优点:能以较低的计算成本获得超大规模模型的知识容量和性能。
- 局限:路由和通信开销大;需要复杂的负载均衡策略防止“专家极化”(即某些专家总是被选中,而另一些从未被使用)。
适用场景
- MoE模型的推理,如Mixtral 8x7B, DeepSeek-V2, Grok-1等。
总结与组合使用策略
| 策略 | 核心思想 | 通信模式 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|---|
| 数据并行 | 复制模型,拆分数据 | All-Reduce / Gather | 实现简单,提升吞吐 | 无法解决大模型显存问题 | 模型能放单卡,高吞吐推理 |
| 流水线并行 | 拆分模型,数据流水 | P2P | 支持极大模型 | 有流水线气泡,增加延迟 | 线性结构的大模型 |
| 张量并行 | 拆分层内矩阵 | All-Reduce | 延迟低,支持大层 | 通信开销大,扩展性差 | 节点内,层巨大的模型 |
| 专家并行 | 动态激活专家 | All-to-All | 计算成本低,模型容量大 | 路由复杂,负载均衡难 | MoE模型 |
在实际生产环境中,几乎没有单一策略打天下的情况,总是组合使用以发挥各自优势:
-
3D并行:流水线并行(跨节点) + 张量并行(节点内) + 数据并行(跨流水线组)。这是训练和推理超大规模模型(如GPT-3, PaLM)的黄金标准。
- 先用张量并行在一个节点内尽可能分解模型。
- 如果模型还是太大,再用流水线并行跨节点分解。
- 最后,为了提升吞吐量,可以复制多个这样的流水线组,组间使用数据并行。
-
MoE模型的典型组合:专家并行 + 数据并行。专家并行负责扩大模型容量,数据并行负责提高处理吞吐量。
选择哪种策略,取决于模型大小、硬件条件(设备数量、互联拓扑)和性能目标(延迟 vs. 吞吐量)。 对于推理服务,还需要特别考虑冷启动时间、资源利用率和服务成本。
更多推荐
 20
20 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)