
大模型学习日记(二)--微调成功模型的本地部署
本文详细介绍了将微调后的大语言模型部署到本地的四个步骤:1.准备Python、Git和llama.cpp环境;2.从LLamaFactory导出模型;3.关键步骤是将模型转换为GGUF格式,包括创建虚拟环境、安装依赖、执行格式转换和量化;4.最后在Ollama中创建Modelfile并运行模型。重点解决了依赖安装和格式转换的技术难点,为本地部署大模型提供了清晰指导。
先给大家道个歉,学校里最近刚刚开学,学习上事情有点多,导致更新可能不及时,都不好意思叫日记了。
言归正传,今天带来的是微调成功后模型的本地部署,步骤不难,其实只需要四个步骤就可以,我也有看别的博主的教程,像他们那种下载MSYS2什么的有点太复杂了,但是这一次的教程就不需要这么麻烦。
1:环境的准备,保证你的Windows有必要的工具和环境。
2:模型的转换,从LLamafactory中导出我们微调成功的模型。
3:格式转化,将模型格式转化为Ollama 使用的 GGUF 格式。(最重要)
4:Ollama的部署
现在我会依次介绍这四个步骤。
1. 环境准备
1.1 准备python环境
这一步大家应该都没有问题,只需要去python官网https://www.python.org/downloads/windows/上下载就可以了,不过要注意的就是在安装的时候把Add python.exe to PATH选项给勾选上,这样安装下来就ok了。
1.2 下载git
git主要是为了使用pip安裝某些 Python 插件时,需要用 Git 从 GitHub 下载。前往 https://git-scm.com/download/win 下载并安装 Git for Windows,使用预设选项就可以了。
不过这一步其实也可以不用管他,因为网络时常会有波动导致下载出现错误,我们可以直接从github上download zip就可以了。
1.3 下载llama.cpp
这一个软件是我们必须使用到的,因为我们需要使用它来转化我们的模型格式。
前往 https://github.com/ggerganov/llama.cpp下载,依旧是点击download zip就可以(大家一定要注意一下,我们需要下载的是Source code,这个版本稳定一些),然后解压缩安装到你自己认识的路径即可。
到这里,我们的第一步就算完成了。
2 模型准备
2.1 从llama factory中导出模型
这一步比较简单,我应该在前一次的总结中说到过。点击LLama Factory中的export就可以导出模型,参数使用默认的即可。这一步也同理,一定一定要记住自己导出模型的路径。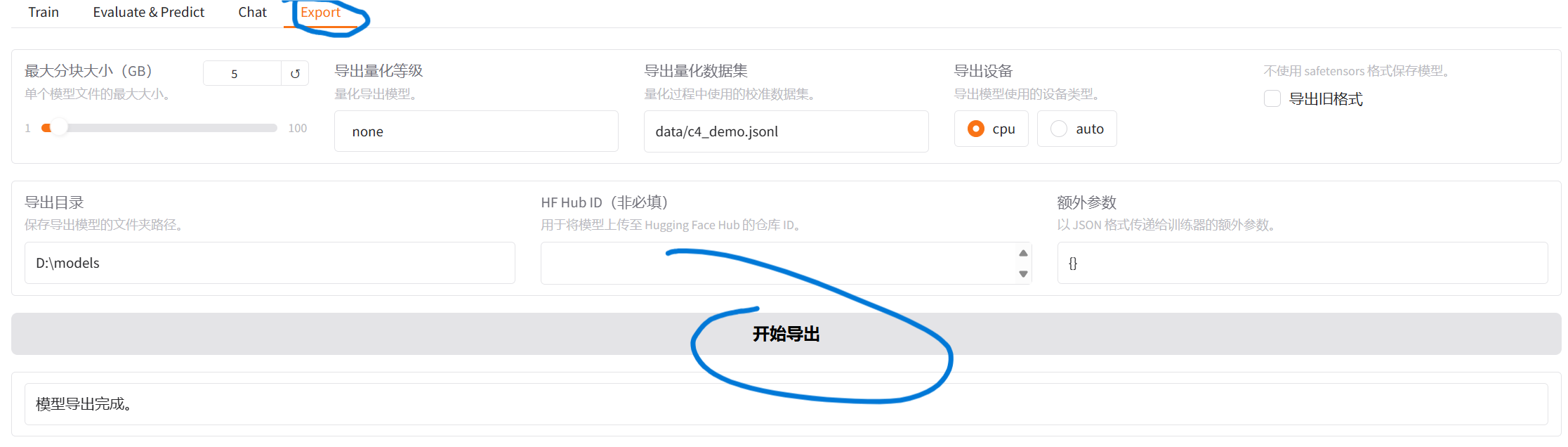
3 格式转化
现在我们准备将导出的模型转化为.gguf格式。
3.1 建立并启用python的虚拟环境
从Windows功能列表中加载powershell或win+r,输入cmd打开。
然后在窗口中输入下列代码:
# 进入我们下载的 llama.cpp 路径
例如:cd D:\llama.cpp-master
# 建立一個名为 .venv 的虚拟环境
python -m venv .venv
# 启用这个虚拟环境
.\.venv\Scripts\activate成功后,命令行的前面就会出现(.venv)的字样。
3.2 安装所有python所需的依赖
这一步所需的依赖比较多,我自己试了好多次才最终可以成功运行,现在我来列一下所需要的依赖。
3.2.1 升级 pip 本身
这个大家应该都比较熟悉,在上面的环境中输入下列代码即可。
python.exe -m pip install --upgrade pip3.2.2 安装 llama.cpp 的基础依赖项
我们可以直接运行下列代码:
pip install -r requirements.txt但是还是因为要连到github上,网络不稳定就很容易断开连接,导致下载失败,所以这里我还是推荐大家去github上下载压缩包然后解压缩到本地,放到本地去下。
https://github.com/huggingface/transformers/archive/refs/tags/v4.56.0-Embedding-Gemma-preview.zip
下载完成后,输入下列代码就可以完成下载,地址不要忘记改成你下载transformers的地址。
例:pip install "D:\Download\transformers-4.56.0-Embedding-Gemma-preview"然后再次执行 pip install -r requirements.txt 就可以完成。
3.2.3 安裝 PyTorch
这里的pytorch其实只需要安装CPU版本的就可以了,因为只是用来转化模型格式,用不到GPU的。这个也简单,输入下面的代码就可以了:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu3.2.4 安装其它一些琐碎的依赖
这一些还是看自己的电脑需要什么就下载什么就行了,我下面列了一个我出现错误的地方,大家应该也都差不多。还有其它的大家可以自行安装。
#安裝 SentencePiece
pip install sentencepiece3.3 开始执行转换
3.3.1 转换为F16 GGUF
在已经启动好的 (.venv) 命令窗口中,执行下列代码:
# 将 "D:\My-Finetuned-Model" 我们在第二步导出模型的那个路径。
python .\convert_hf_to_gguf.py "D:\My-Finetuned-Model" --outfile "D:\models\my-model-f16.gguf" --outtype f16这一步会产生一个比较大的文件,这是正常的。
3.3.2 将 F16 GGUF 量化为 Q4_K_M
这一步是将模型的大小调小,类似于压缩过程。
这一步我们需要先准备好 llama-quantize.exe 工具。
https://github.com/ggerganov/llama.cpp/releases,大家从这一个网址中找到最新的版本并下载,把解压缩后的文件命名为llama-tools,这里包含了我们所需要的所有工具。
然后在D盘中新建一个新的文件夹-----models(用来存放转化格式后的模型),并打开一个新的、普通的 Powershell 窗口(不需要虚拟环境)执行:
# 使用 D:\llama-tools 中的 llama-quantize.exe
D:\llama-tools\llama-quantize.exe D:\models\my-model-f16.gguf D:\models\my-model-q4_K_M.gguf q4_K_Mf16 gguf格式与q4_k_m格式大小的对比

在完成这步后,我们的模型格式转化完成,现在就可以进去ollama部署阶段了。
4 在Ollama中部署
4.1 建立 Modelfile
首先在 D:\models 文件夹中,建立一個名为 Modelfile 的文本文件。
然后用记事本打开,输入下列文本:
# 指向我们在阶段 3.3 第二步的最终 GGUF 文件
FROM D:\models\my-model-q4_K_M.gguf4.2 建立并运行 Ollama 模型
到这一步后,我们打开一个新的powershell窗口。
转换路径到我们存放 Modelfile 的目录:
cd D:\models然后执行 ollama create 指令来建立模型:
ollama create my-awesome-model -f ./Modelfile最后就可以输入下面的代码来运行我们的模型啦!
ollama run my-awesome-model大家输出的结果应该是这样的:
ok,最后总结一下。
我们这次做了微调模型的本地部署。
这一次的难点主要是在python依赖的安装以及将模型格式转换为ollama所需的格式。
还是希望这一次的日记对大家有点作用,更欢迎大家一起来和我探讨大模型的一些知识。
更多推荐
 21
21 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)