
转:MCP说明手册
MCP说明手册
个人理解:
- MCP:Model Context Protocol,模型上下文协议。-- 由Anthropic推出的开源协议,旨在实现大语言模型与外部数据源和工具的集成,用来在大模型和数据源之间建立安全双向的连接
- MCP 是一个开放标准框架,简化 LLM 与外部数据源和工具的集成 -- RAG?
- MCP就是让AI模型无缝与外部工具交互的标准化接口和框架,类似USB-C 为电子设备统一连接标准
- 通过相同的协议处理资源和工具,标准化了应用程序向 LLM 提供上下文的方式
- 大语言模型应用的标准化和去中心化
去中心化:AI 的知识和能力去中心化,LLM(知识+训练+输出) --> MCP(外部知识库以 resource和tool的形式注册) - MCP对LLM的扩展:Resources(知识扩展)、Tools(执行函数,调用外部系统)、Prompts(预编写提示词模板)
- LLM通过Perception & Reasoning 层将全方面的人类物理环境信息解析成为 tokens,交结MCP完成任务
- AI application(Pormpt) <--> LLM <-M-N-> MCP [ HOST <-> MCP client <--> MCP Server <-N-N-> Resource / Tool ]
MCP是LLM的增强?通过MCP调用resource/tool获得结果,LLM将MCP结果与Prompt结合后输出最终结果? - MCP+LLM:带工具的LLM?
┌───────────────────────────────────────────────────────┐
│ **Host 环境** │
│ ┌───────────────────────────────────────────────┐ │
│ │ **Client 端** │ │
│ │ ┌─────────────┐ ┌───────────────────────┐ │ │
│ │ │ User Input │───▶│ Prompt Template │ │ │
│ │ └─────────────┘ └───────────────┬───────┘ │ │
│ │ │ │ │
│ │ ┌───────────────────────────────────▼────────┐ │ │
│ │ │ **Prompt Engineering** │ │ │
│ │ │ - 填充 Template 变量 │ │ │
│ │ │ - 添加 System/User Prompt │ │ │
│ │ └───────────────────────────────────┬────────┘ │ │
│ │ │ │ │
│ └───────────────────────┬──────────────▼────────────┘ │
│ │ **LLM API Call** │
│ ┌───────────────────────▼───────────────────────┐ │
│ │ **Server 端** │ │
│ │ ┌───────────────────────────────────────────┐ │ │
│ │ │ **LLM 核心** │ │ │
│ │ │ - 接收 Prompt │ │ │
│ │ │ - 生成 Response │ │ │
│ │ │ - 调用 Tools (通过 Tool Call API) │ │ │
│ │ └───────────────┬─────────────────┬─────────┘ │ │
│ │ │ │ │ │
│ │ ┌───────────────▼────────┐ ┌────▼─────────────┐ │ │
│ │ │ **Tool 生态** │ │ **External API**│ │ │
│ │ │ - 数据库查询 │ │ - 天气服务 │ │ │
│ │ │ - 计算器 │ │ - 支付接口 │ │ │
│ │ └──────────────────────────┘ └─────────────────┘ │ │
│ └───────────────────────────────────────────────┘ │
└───────────────────────────────────────────────────────┘
MCP说明手册
参考:
- MCP:AI 的去中心化革命与以太坊的完美融合
- LLM中的MCP是什么,它的底层原理怎么理解?
- 关于 LLM 的 MCP 协议
MCP就像万能翻译,让AI模型通过统一接口无缝连接外部工具和数据,将复杂的M×N集成难题简化为M+N,彻底打破信息孤岛,实现智能协作。

第一部分:模型上下文协议(MCP)
什么是 MCP ?
就好像你只会说英语,想从只会说法语、德语等外语的人那里获取信息,你得学对应外语。
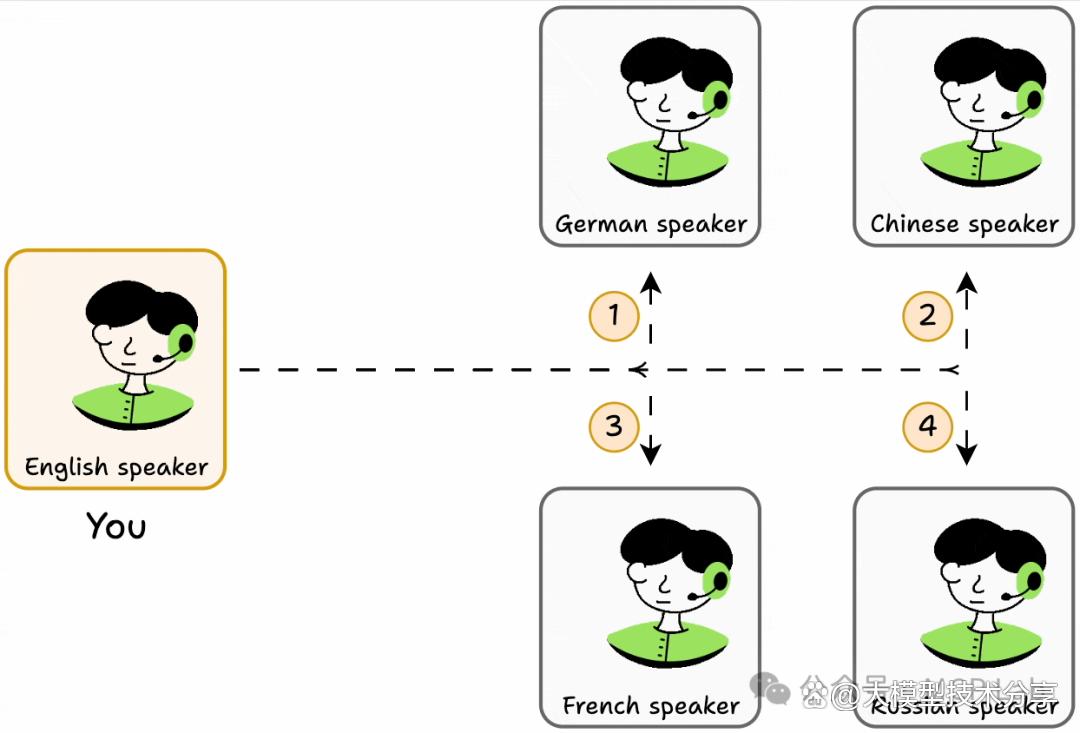
但要是有个能理解所有语言的翻译,问题就简单了,MCP就像这个翻译,让代理能通过单一接口与其他工具或能力交流。
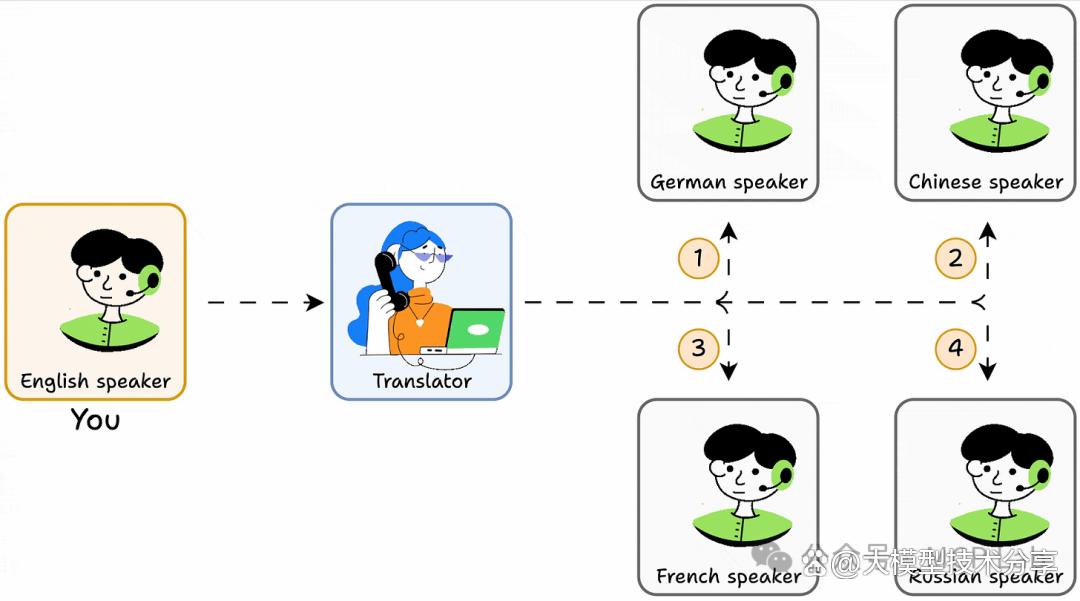
实际上,大型语言模型(LLMs)虽知识丰富、推理能力强,能完成复杂任务,但知识局限在初始训练数据内。
若需实时信息,就得用外部工具,而MCP就是让AI模型无缝交互的标准化接口和框架,类似USB-C 为电子设备统一连接标准。
为何要创造 MCP ?
在MCP出现前,连接AI与外部数据和操作的方式要么是为每个工具硬编码逻辑,要么是管理不够稳健的提示链。
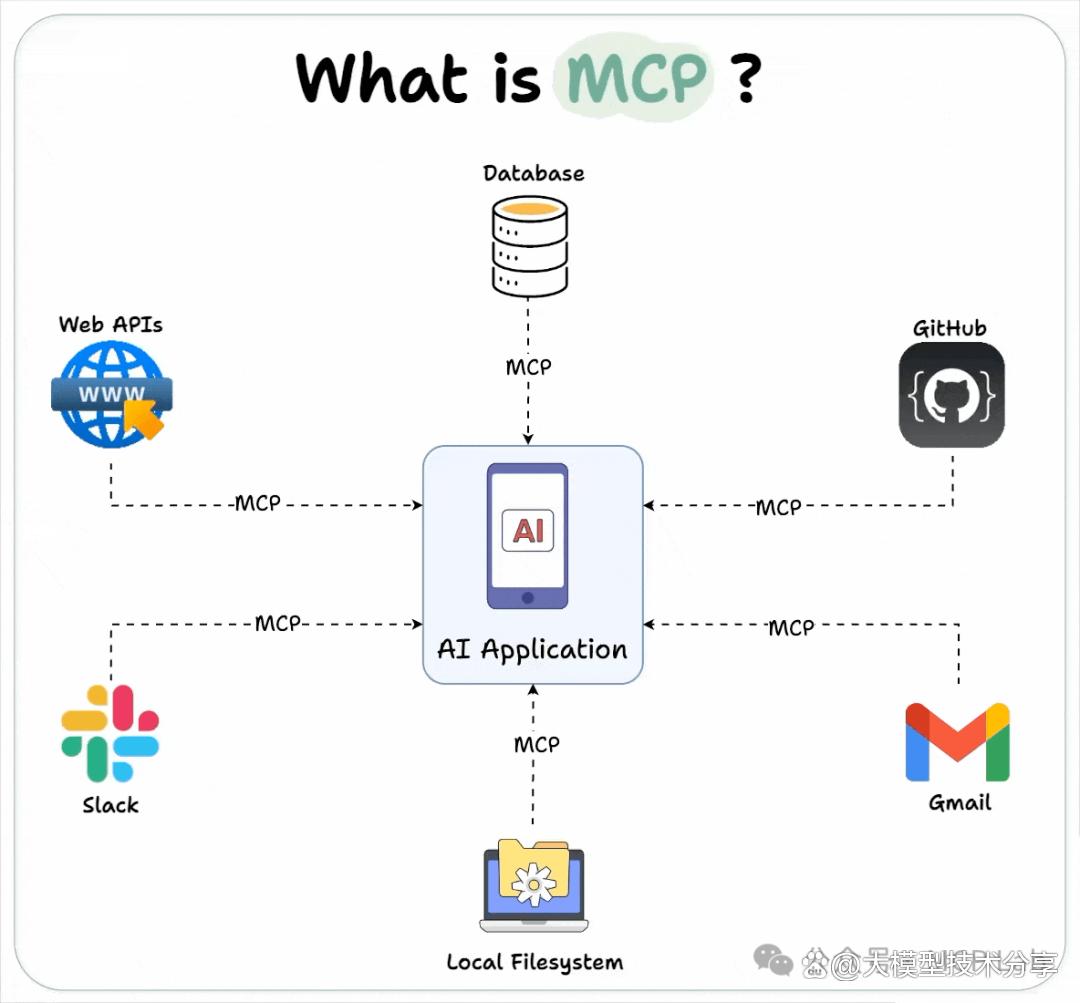
要么是用特定供应商的插件框架,导致出现 M×N 集成难题,例如,若有M个AI应用和N个工具 / 数据源,可能需要 M×N 个定制集成。
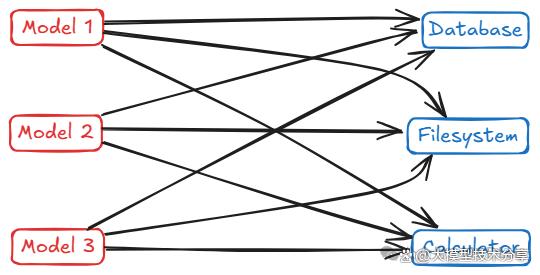
而MCP通过引入中间的标准接口解决此问题,将 M×N 直接集成变为 M+N 个实现。
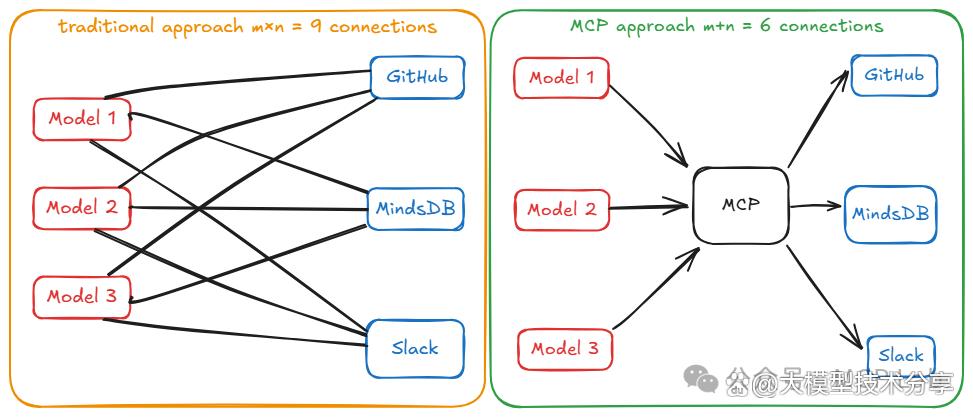
即每个 AI 应用实现一次 MCP 客户端,每个工具实现一次 MCP 服务器,简化了连接。
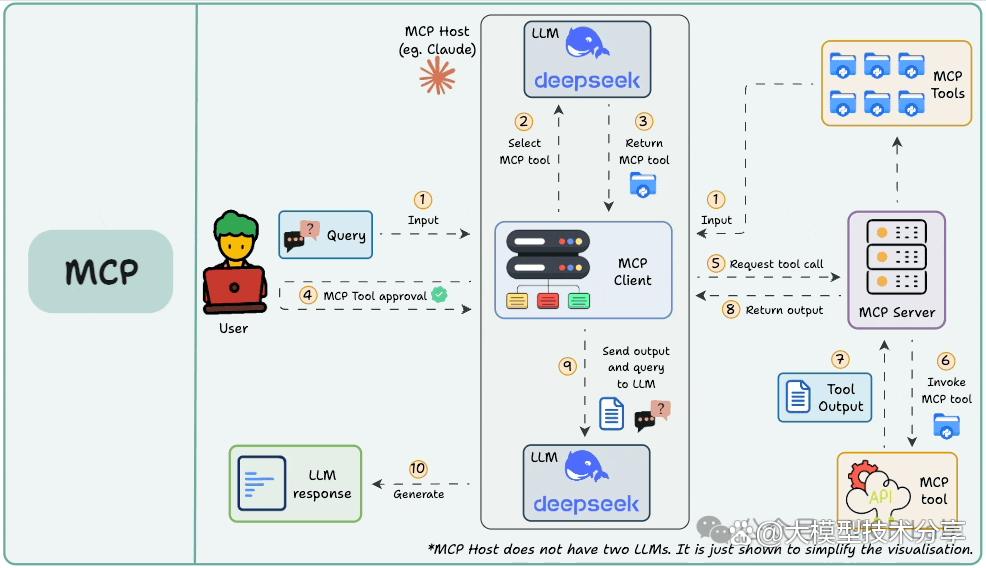
MCP 架构概览
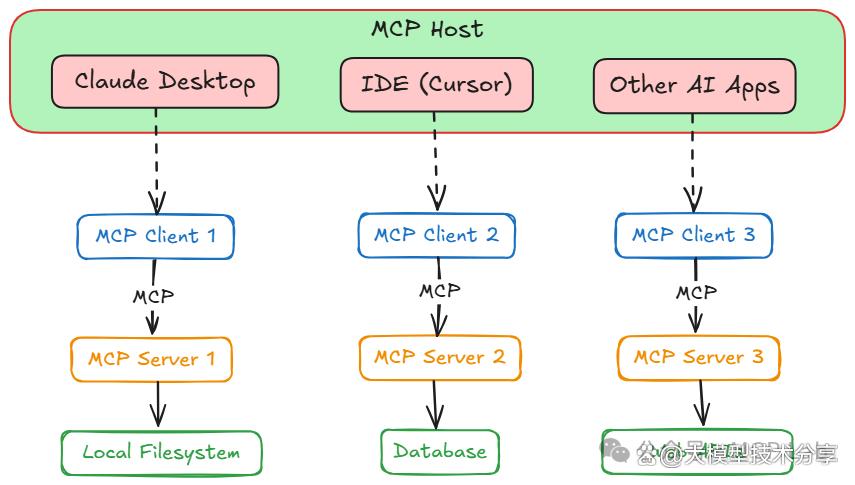
宿主(Host):是面向用户的 AI 应用,如聊天应用、AI 增强型 IDE 等。它发起与 MCP 服务器的连接,捕获用户输入,保留对话历史并显示模型回复。
X客户端(Client):在宿主内,负责处理底层事务,像适配器或信使,负责按 MCP 协议执行宿主指令。
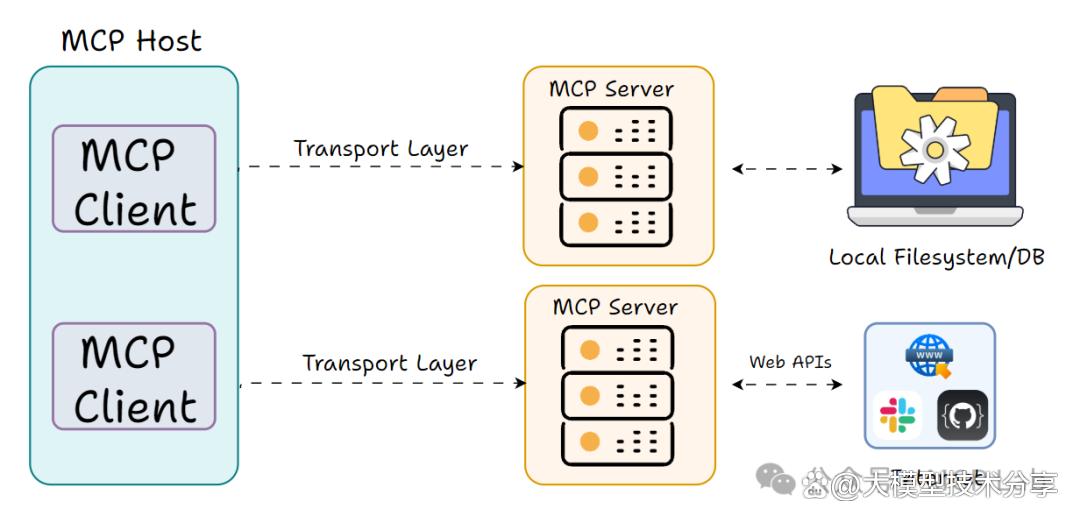
服务器(Server):是提供功能(工具等)的外部程序或服务,可本地或远程运行,关键是以标准格式告知能做什么,执行客户端请求并返回结果。
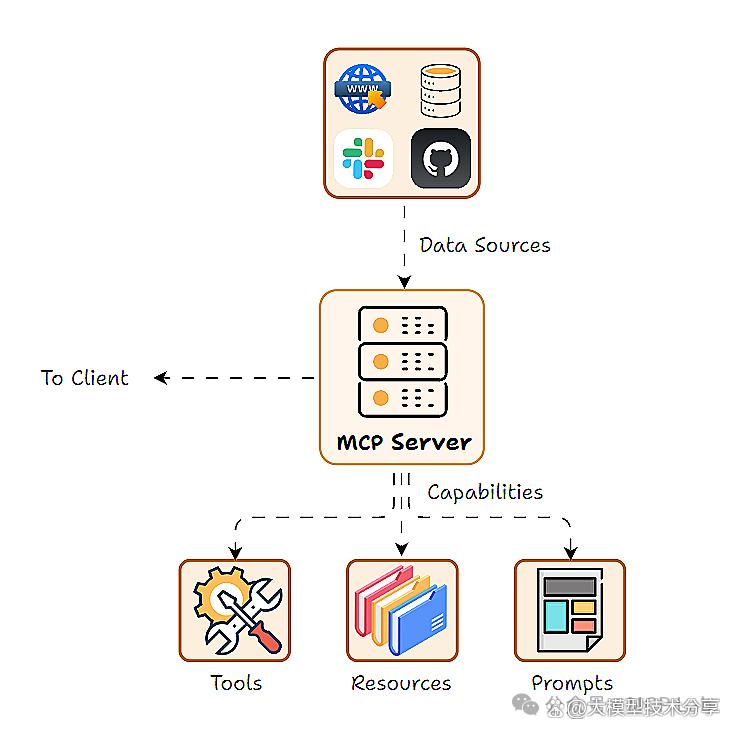
MCP 基于客户端 - 服务器架构,主要有三个角色:
- 工具(Tools):是AI可调用的可执行动作或函数,通常由 AI 模型选择触发,常涉及文件 I/O 或网络调用等副作用或需额外计算的操作。
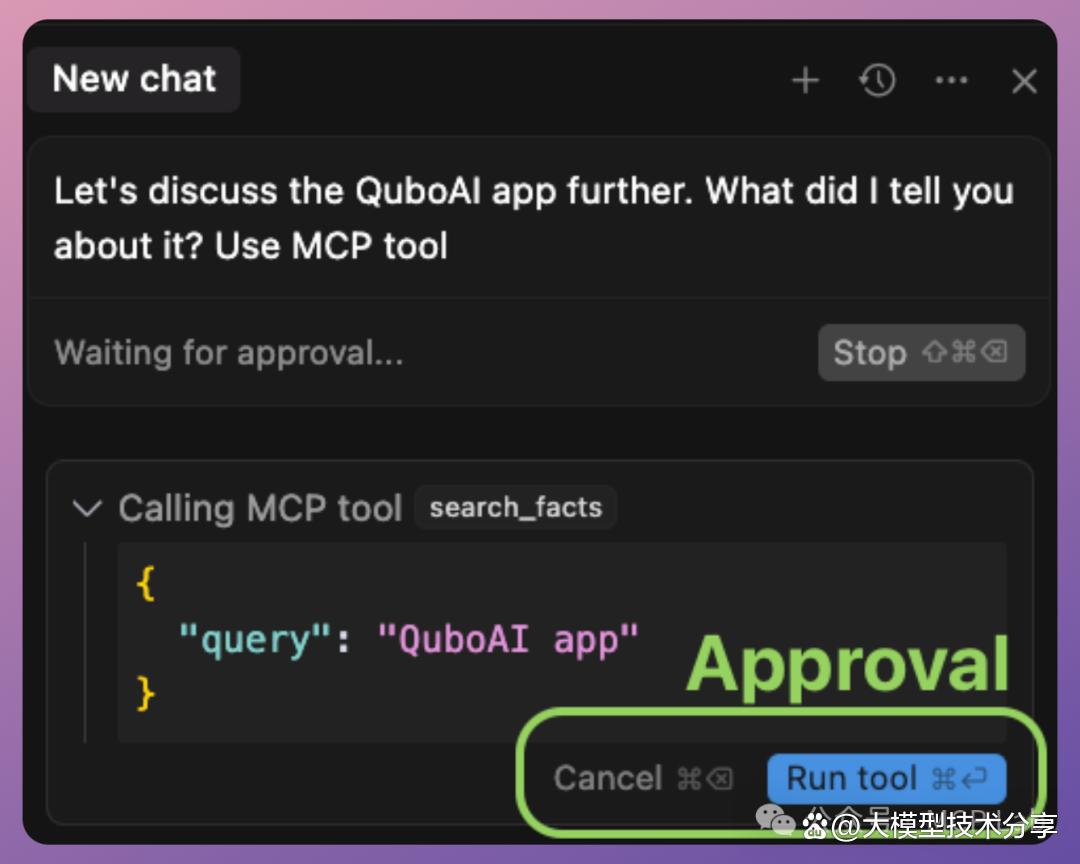
例如:一个获取天气信息的简单工具,AI 可通过调用该工具。
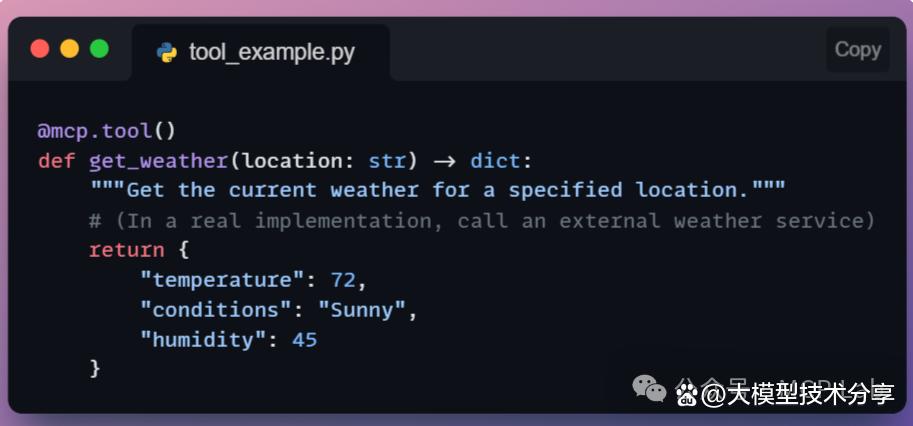
传入地点参数,服务器执行后返回结果,客户端获取并供 AI 使用。
- 资源(Resources):为 AI 提供只读数据,类似数据库或知识库,AI 可查询获取信息,但不能修改。
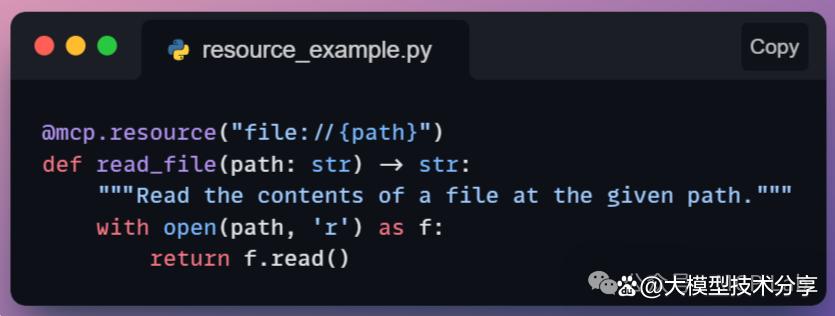
与工具不同,资源通常在宿主控制下访问,避免模型随意读取。示例:从本地文件、知识库片段、数据库查询结果(只读)等获取内容。
- 提示(Prompts):是预定义的提示模板或对话流程,可注入以引导 AI 行为。
例如,代码审查的提示模板,服务器提供后,宿主可调用并插入用户代码,供模型生成回复前使用。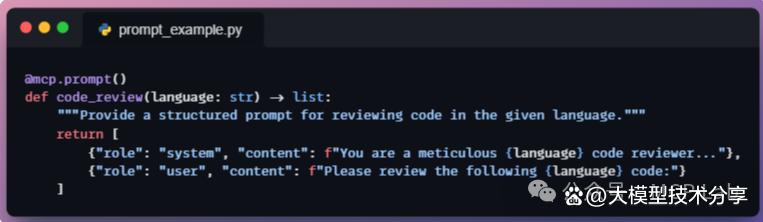
上面这三者构成了MCP框架的核心能力。
第二部分:MCP 实操项目案例讲解
100%完全本地MCP客户端
MCP 客户端就是AI应用(例如 Cursor)中的一个组件,用于与外部工具建立连接。下面我们讲解如何完全在本地构建一个MCP项目。
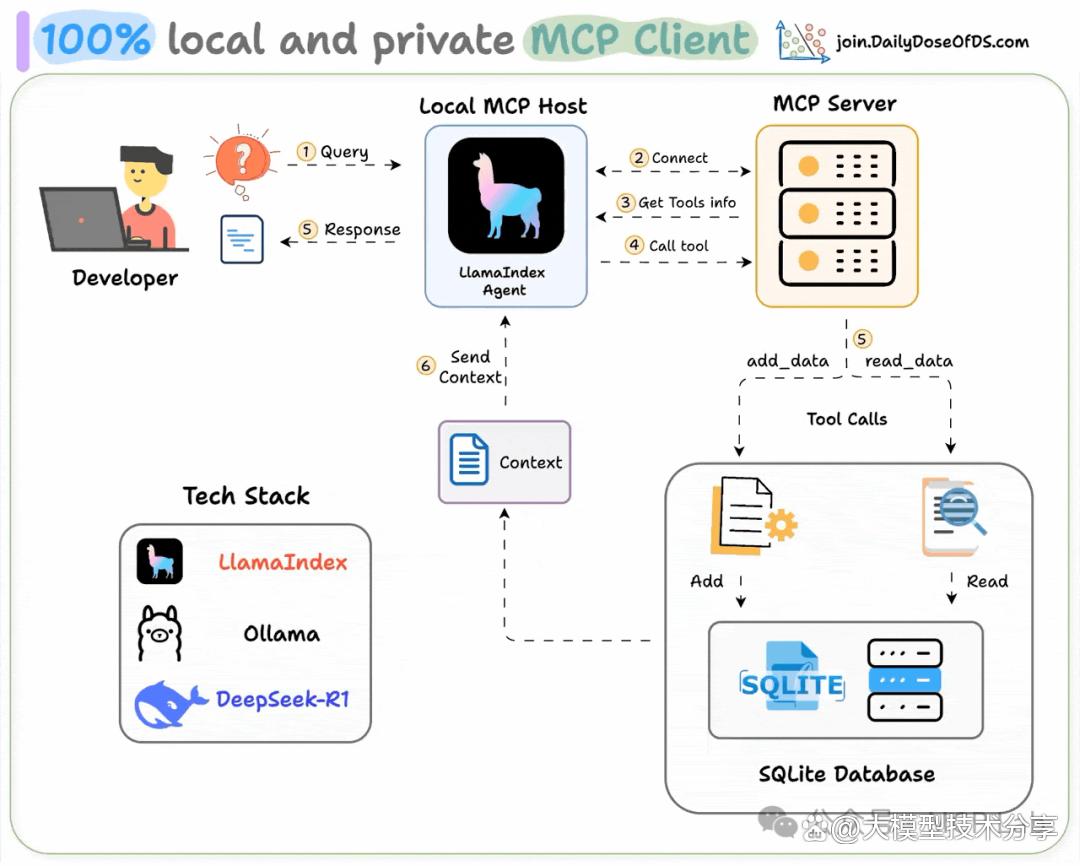
构建本地MCP客户端,技术栈涉及LlamaIndex构建MCP驱动的代理、Ollama本地部署Deepseek-R1、LightningAI 用于开发和托管。
工作流程包括,用户提交查询、代理连接 MCP 服务器发现工具、调用工具获取上下文并返回响应。
案例1:SQLite MCP服务器
下面我们看看如何实现SQLite MCP服务器、设置 LLM、定义系统提示、定义代理、定义代理交互、初始化 MCP 客户端和代理以及运行代理等步骤。
步骤1:构建SQLite MCP服务器:在本次演示中,我们搭建了一个简单的SQLite 服务器,用到下面两个工具:
● 添加数据
● 获取数据
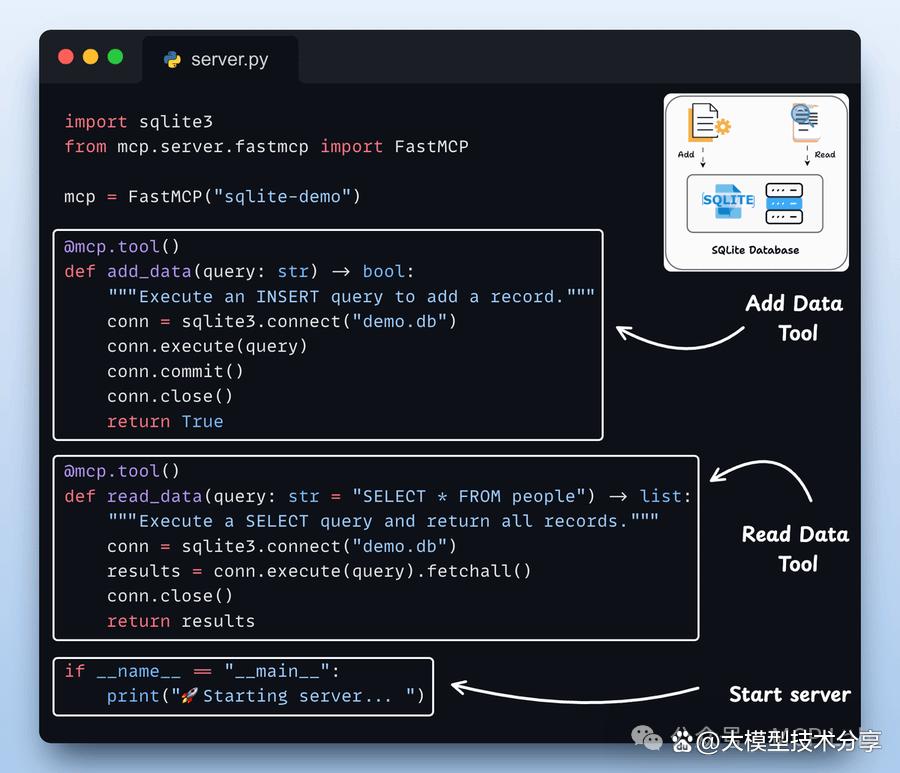
步骤2:设置大型语言模型(LLM) 我们将通过 Ollama 本地部署 Deepseek-R1,将其用作 MCP 驱动代理的 LLM。
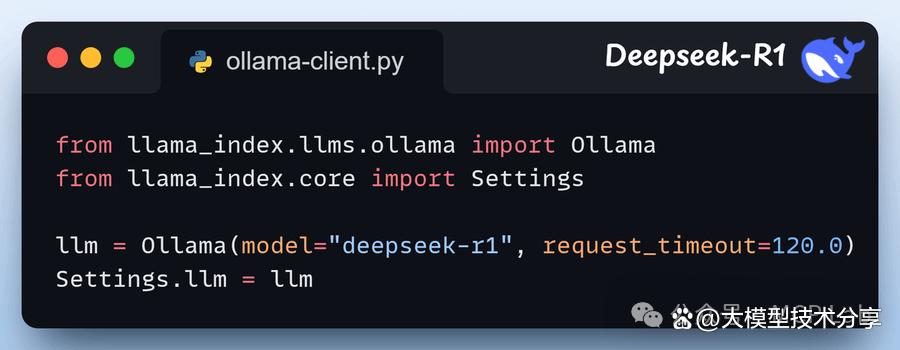
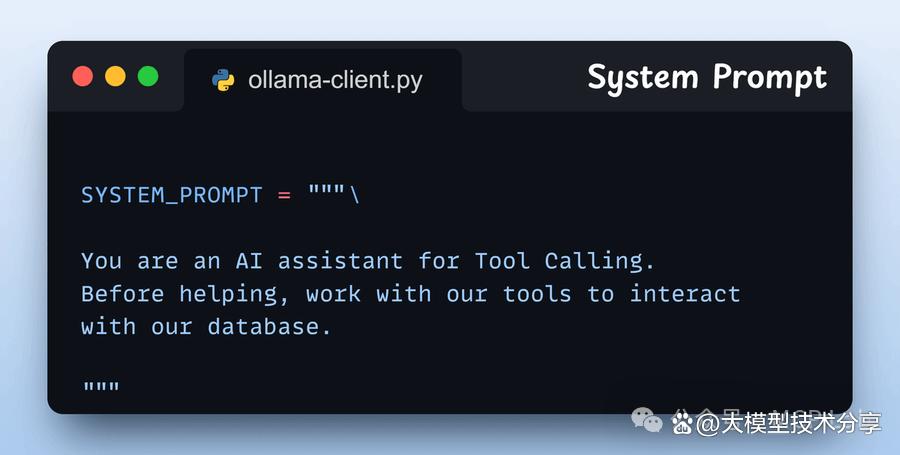
步骤3:定义系统提示 我们为代理设置了指导性指令,使其在回应用户查询前能够使用工具。 可根据实际需求灵活调整此设置。
步骤4:定义代理 我们定义了一个函数,用于构建一个典型的 LlamaIndex 代理,并为其提供合适的参数。
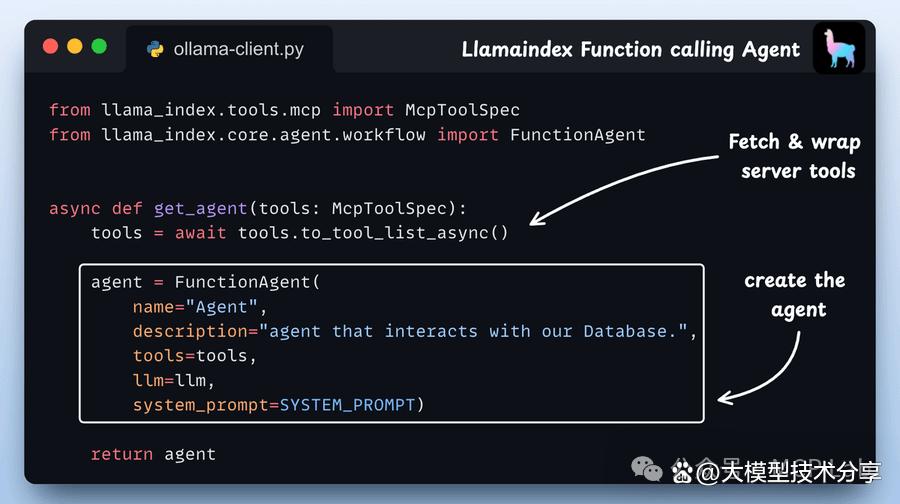
传递给代理的工具是 MCP 工具,这些工具会被 LlamaIndex 封装为原生工具,从而能够被我们的函数代理轻松使用。
步骤5:定义代理交互 我们将用户消息传递给函数代理,并附带一个共享的上下文以实现记忆功能,同时流式处理工具调用并返回其回复。
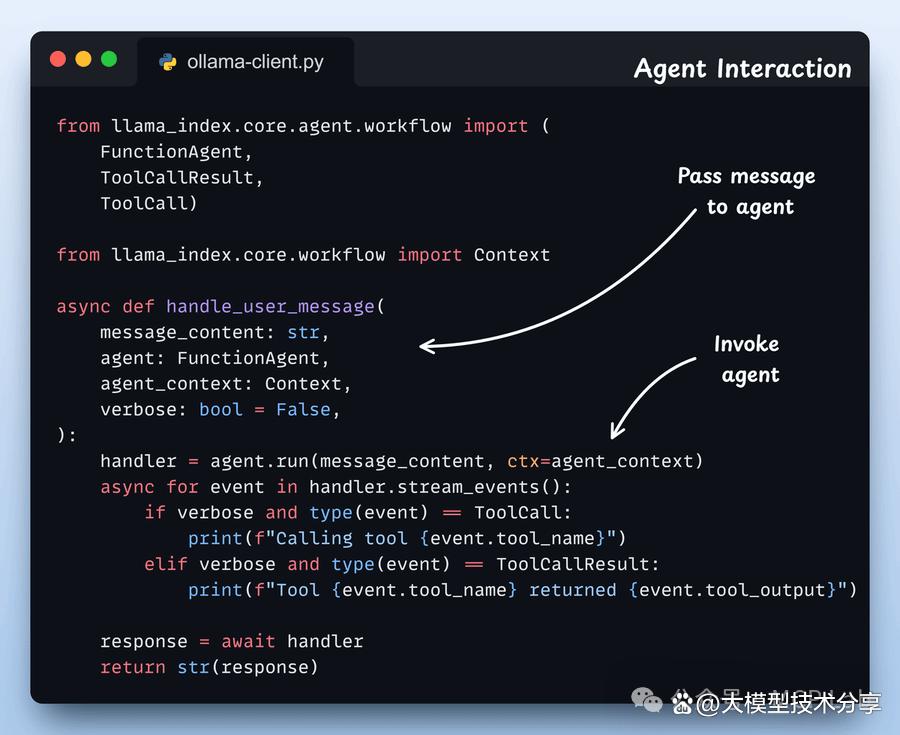
在这里,我们管理所有的聊天历史记录和工具调用。
步骤6:初始化 MCP 客户端和代理
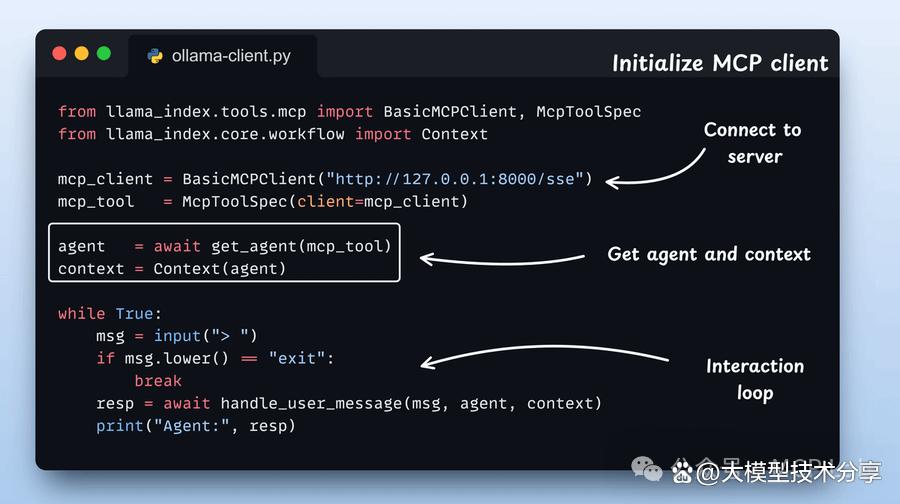
启动 MCP 客户端,加载其工具,并将它们封装为 LlamaIndex 中函数调用代理可用的原生工具。然后,将这些工具传递给代理,并添加上下文管理器。
步骤7:运行代理:最后,我们开始与代理进行交互,并获取SQLite MCP服务器中的工具。
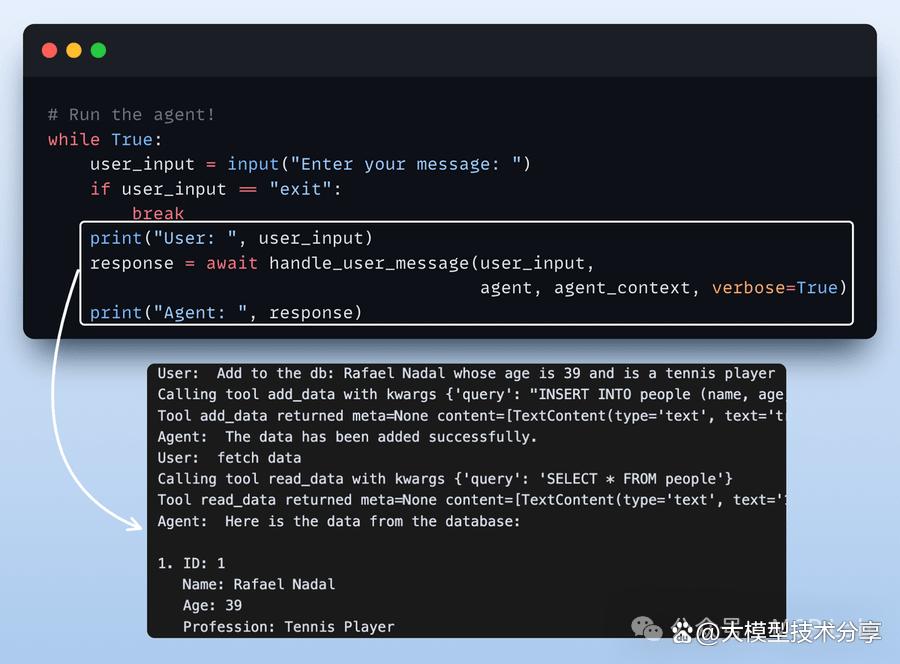
以上就是我们完全本地化SQLite MCP演示部分,大家感兴趣可以自行尝试!
MCP 驱动的代理式 RAG
案例2:MCP 驱动的代理式 RAG,实现够搜索向量数据库
下面我们讲解如何创建一个MCP 驱动的代理式 RAG,实现够搜索向量数据库,并在需要时回退到网络搜索!
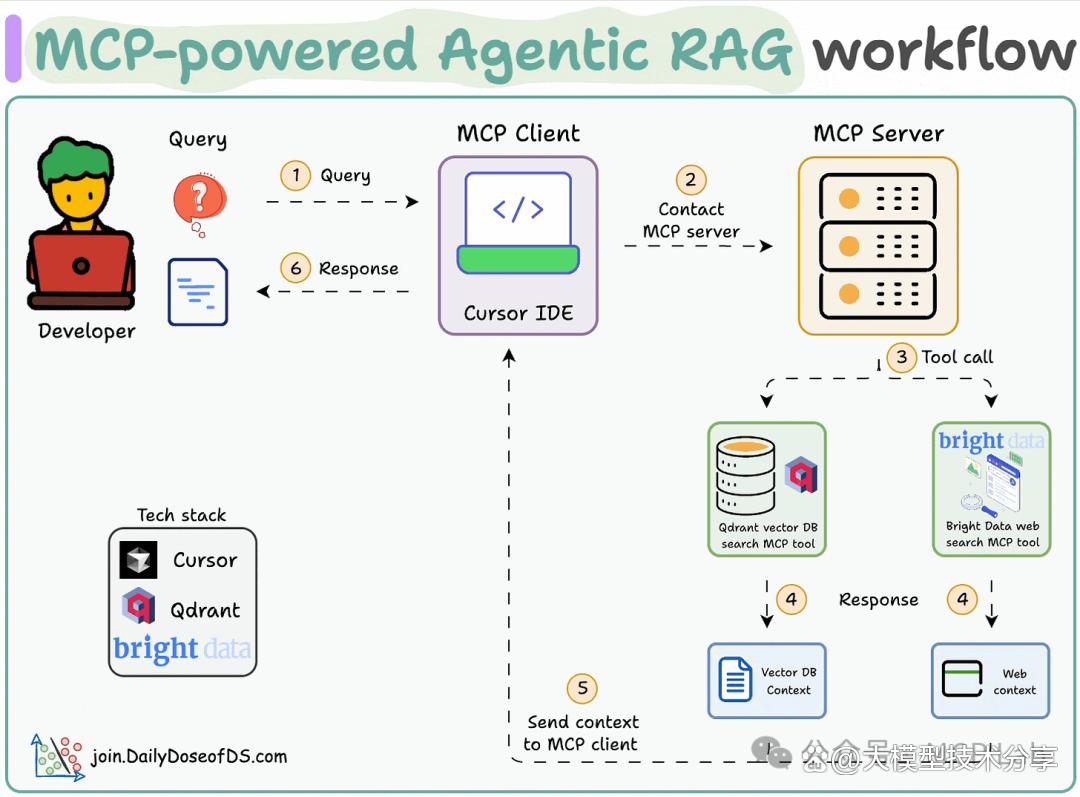
技术栈:
使用 Bright Data 进行大规模网页抓取。
采用 Qdrant 作为向量数据库。
选择 Cursor 作为 MCP 客户端。
流程:
用户通过 MCP 客户端(Cursor)输入查询。
客户端联系 MCP 服务器以选择相关工具。
工具输出返回给客户端以生成响应。
步骤1:启动 MCP 服务器 首先,我们需要定义一个 MCP 服务器,指定其主机 URL 和端口。
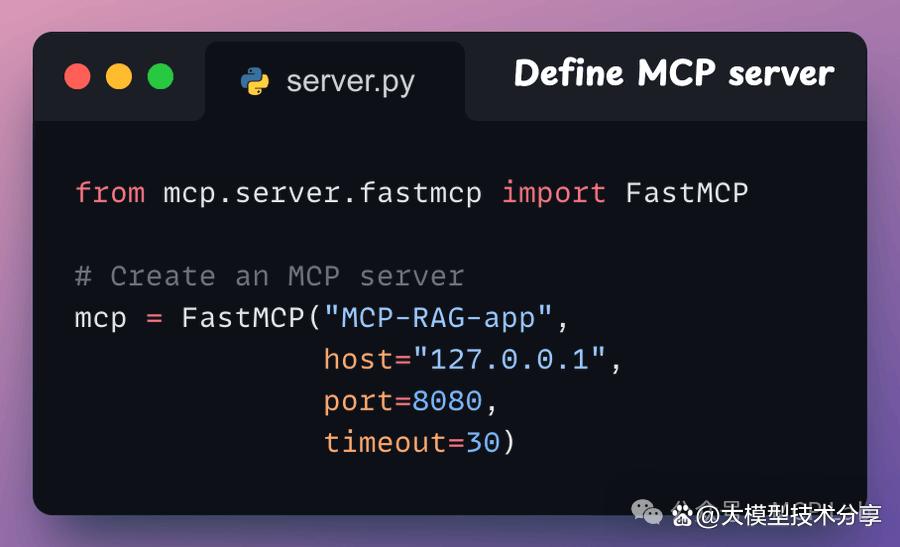
步骤2:向量数据库MCP工具 通过 MCP 服务器暴露的工具需满足两项要求:
● 必须使用 “tool” 装饰器进行装饰。
● 必须具备清晰的文档字符串。
下面,我们展示了一个用于查询向量数据库的 MCP 工具示例,该数据库存储了与机器学习相关的常见问题。
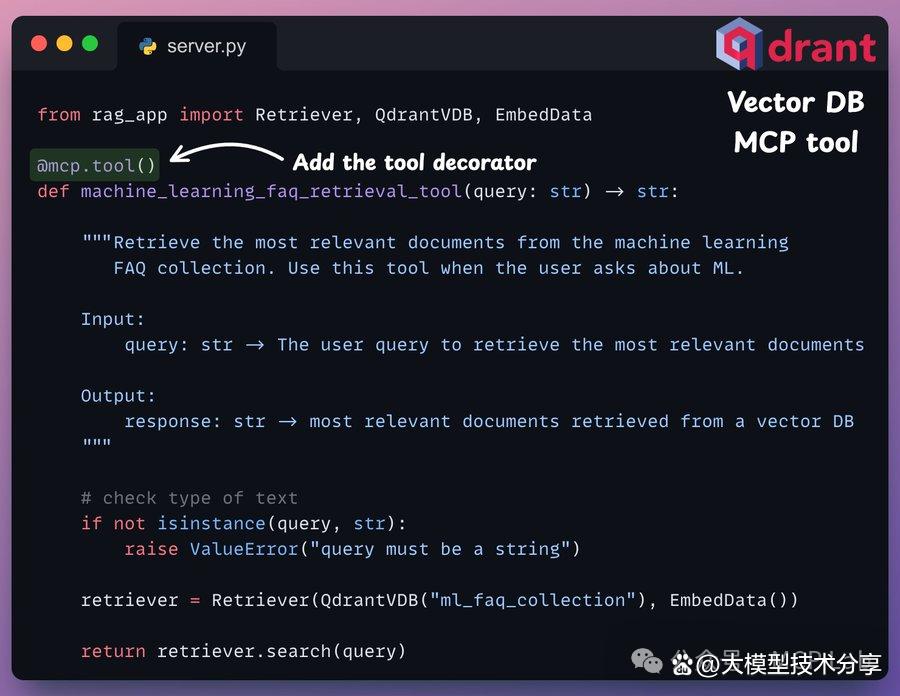
步骤3:网络搜索MCP工具 当查询与机器学习无关时,我们使用 Bright Data 的 SERP API 进行网络搜索,以从多个来源抓取数据并获取相关上下文。
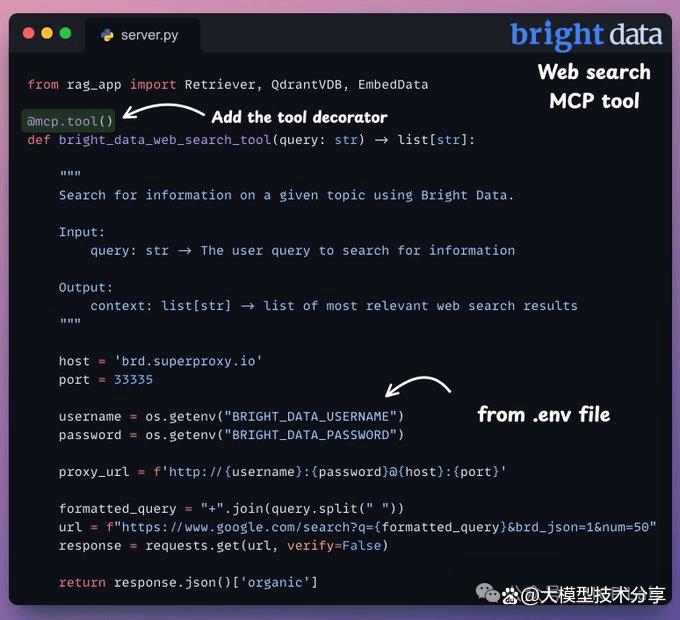
以下是实现网络搜索 MCP 工具的示例代码(仅供参考):
from fastmcp import FastMcPimport requestsimport asyncio
# 创建 MCP 服务器mcp = FastMcP("web-search-demo")
# 定义网络搜索工具@mcp.tool()def bright_data_web_search_tool(query: str) -> list[str]: """ 使用 Bright Data 的 SERP API 搜索了一些信息。
输入: query (str):要搜索的信息。
输出: context (list[str]):最相关的网络搜索结果列表。 """ # 获取环境变量中的 Bright Data 凭证 username = os.getenv("BRIGHT_DATA_USERNAME") password = os.getenv("BRIGHT_DATA_PASSWORD")
# 设置代理 URL proxy_url = f'http://{username}:{password}@brd.superproxy.io:33335'
# 格式化查询 formatted_query = "+".join(query.split()) url = f"https://www.google.com/search?q={formatted_query}&brd_json=1&num=50"
# 发送请求 response = requests.get(url, verify=False, proxies={"http": proxy_url, "https": proxy_url})
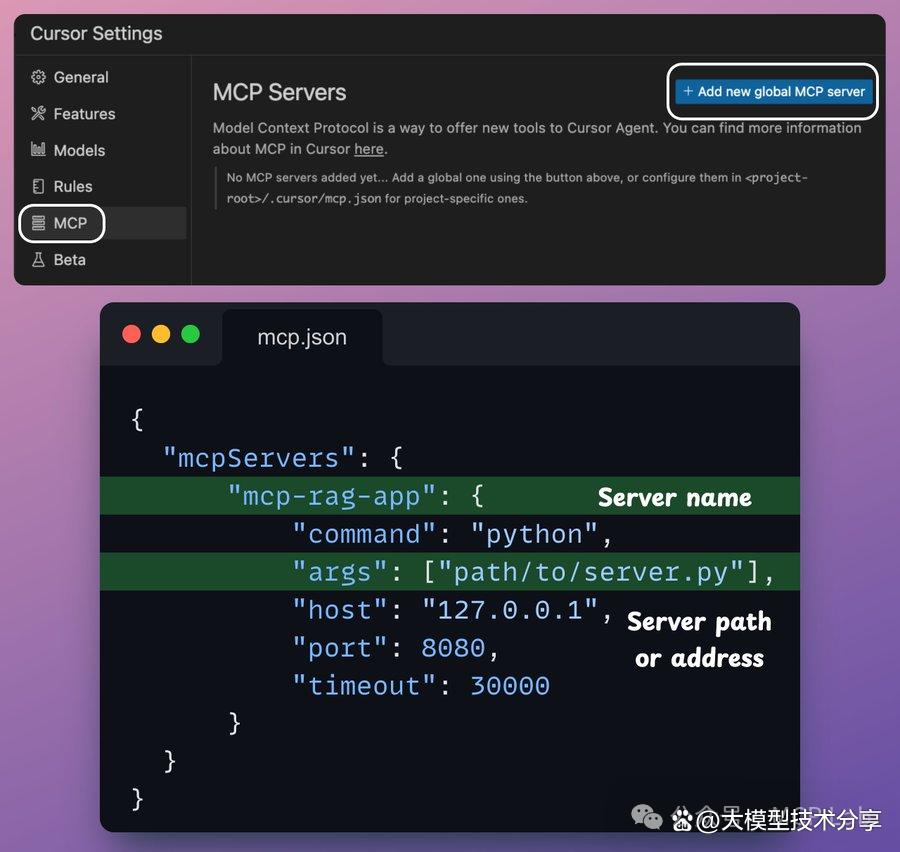
# 返回结果 return response.json()['organic']步骤4:将MCP服务器与 Cursor 集成 转到设置 → MCP → 添加新的全局 MCP 服务器。在 JSON 文件中添加以下内容:
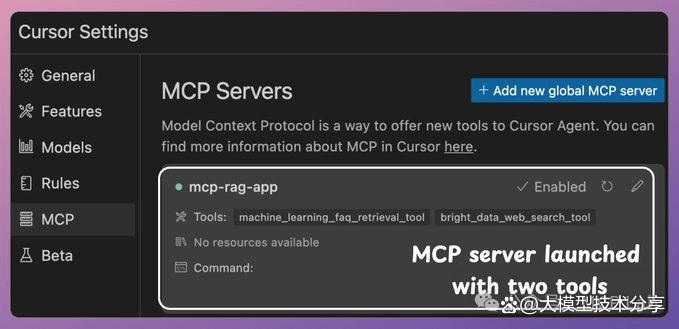
步骤5:完成啦!你的本地MCP服务器已成功上线,并与 Cursor 完成了连接。
目前,该服务器提供了以下两个 MCP 工具:
● Bright Data 网络搜索工具,可用于大规模抓取数据。
● 向量数据库搜索工具,可用于查询相关文档。
接下来,我们就可以与 MCP 服务器进行交互。
● 当我们提出与机器学习(ML)相关的问题时,它会调用向量数据库工具。
● 但当我们提出一个泛化问题时,它会调用 Bright Data 网络搜索工具,从各个来源大规模地收集网络数据,这就体现了代理的主动性!
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)